A Deep Learning Model for Estimation of Patients with Undiagnosed Diabetes

 ,
,  , and
, and 
Abstract
:1. Introduction
2. Materials and Methods
2.1. Study Design
2.2. Analysis Methods
3. Experimental Results
Comparison of Basic Characteristics among NG, IFG, and UDG
4. Discussion
5. Conclusions
Author Contributions
Funding
Conflicts of Interest
Data and DLM Sharing Statement
References
- World Health Organization. Global Report on Diabetes 2016; World Health Organization. Available online: https://apps.who.int/iris/handle/10665/204871 (accessed on 5 January 2020).
- World Health Organization. Classification of Diabetes Mellitus 2019; World Health Organization. Available online: https://apps.who.int/iris/handle/10665/325182 (accessed on 5 January 2020).
- Lee, Y.H.; Bang, H.; Kim, H.C.; Kim, H.M.; Park, S.W.; Kim, D.J. A simple screening score for diabetes for the Korean population: Development, validation, and comparison with other scores. Diabetes Care 2012, 35, 1723–1730. [Google Scholar] [CrossRef] [Green Version]
- Colagiuri, S.; Cull, C.A.; Holman, R.R.; UKPDS Group. Are lower fasting plasma glucose levels at diagnosis of type 2 diabetes associated with improved outcomes?: U.K. prospective diabetes study 61. Diabetes Care 2002, 25, 1410–1417. [Google Scholar] [CrossRef] [Green Version]
- Chung, S.; Azar, K.M.; Baek, M.; Lauderdale, D.S.; Palaniappan, L.P. Reconsidering the age thresholds for type II diabetes screening in the U.S. Am. J. Prev. Med. 2014, 47, 375–381. [Google Scholar] [CrossRef] [Green Version]
- Pippitt, K.; Li, M.; Gurgle, H.E. Diabetes Mellitus: Screening and Diagnosis. Am. Fam. Physician 2016, 93, 103–109. [Google Scholar]
- Kim, M.J.; Lim, N.K.; Choi, S.J.; Park, H.Y. Hypertension is an independent risk factor for type 2 diabetes: The Korean genome and epidemiology study. Hypertens Res. 2015, 38, 783–789. [Google Scholar] [CrossRef] [PubMed]
- Zhou, H.; Li, Y.; Liu, X.; Xu, F.; Li, L.; Yang, K.; Qian, X.; Liu, R.; Bie, R.; Wang, C. Development and evaluation of a risk score for type 2 diabetes mellitus among middle-aged Chinese rural population based on the RuralDiab Study. Sci. Rep. 2017, 7, 42685. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Aekplakorn, W.; Bunnag, P.; Woodward, M.; Sritara, P.; Cheepudomwit, S.; Yamwong, S.; Yipintsoi, T.; Rajatanavin, R. A risk score for predicting incident diabetes in the Thai population. Diabetes. Diabetes Care 2006, 29, 1872–1877. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Nanri, A.; Nakagawa, T.; Kuwahara, K.; Yamamoto, S.; Honda, T.; Okazaki, H.; Uehara, A.; Yamamoto, M.; Miyamoto, T.; Kochi, T.; et al. Development of Risk Score for Predicting 3-Year Incidence of Type 2 Diabetes: Japan Epidemiology Collaboration on Occupational Health Study. PLoS ONE 2015, 10, e0142779. [Google Scholar] [CrossRef]
- Gao, W.G.; Dong, Y.H.; Pang, Z.C.; Nan, H.R.; Wang, S.J.; Ren, J.; Zhang, L.; Tuomilehto, J.; Qiao, Q. A simple Chinese risk score for undiagnosed diabetes. Diabet. Med. 2010, 27, 274–281. [Google Scholar] [CrossRef]
- Baan, C.A.; Ruige, J.B.; Stolk, R.P.; Witteman, J.C.; Dekker, J.M.; Heine, R.J.; Feskens, E.J. Performance of a predictive model to identify undiagnosed diabetes in a health care setting. Diabetes Care 1999, 22, 213–219. [Google Scholar] [CrossRef] [Green Version]
- Hussain, A.; Claussen, B.; Ramachandran, A.; Williams, R. Prevention of type 2 diabetes: A review. Diabetes Res. Clin. Pract. 2007, 76, 317–326. [Google Scholar] [CrossRef] [PubMed]
- Chen, M.; Yang, J.; Zhou, J.; Hao, Y.; Zhang, J.; Youn, C.H. 5G-Smart Diabetes: Toward Personalized Diabetes Diagnosis with Healthcare Big Data Clouds. IEEE Commun. Mag. 2018, 57, 16–23. [Google Scholar] [CrossRef]
- Choi, E.; Schuetz, A.; Stewart, W.F.; Sun, J. Using recurrent neural network models for early detection of heart failure onset. J. Am. Med. Inform. Assoc. 2017, 23, 361–370. [Google Scholar] [CrossRef] [PubMed]
- Anthimopoulos, M.; Christodoulidis, S.; Ebner, L.; Christe, A.; Mougiakakou, S. Lung Pattern Classification for Interstitial Lung Diseases Using a Deep Convolutional Neural Network. IEEE Trans. Med. Imaging 2016, 35, 1207–1216. [Google Scholar] [CrossRef] [PubMed]
- Li, H.; Huang, Z.; Fu, J.; Li, Y.; Zeng, N.; Zhang, J.; Ye, C.; Jin, L. Modified Weights-and-Structure-Determination Neural Network for Pattern Classification of Flatfoot. IEEE Access 2019, 7, 63146–63154. [Google Scholar] [CrossRef]
- Gulshan, V.; Peng, L.; Coram, M.; Stumpe, M.C.; Wu, D.; Narayanaswamy, A.; Venugopalan, S.; Widner, K.; Madams, T.; Cuadros, J.; et al. Development and Validation of a Deep Learning Algorithm for Detection of Diabetic Retinopathy in Retinal Fundus Photographs. JAMA 2016, 316, 2402–2410. [Google Scholar] [CrossRef]
- Esteva, A.; Kuprel, B.; Novoa, R.A.; Ko, J.; Swetter, S.M.; Blau, H.M.; Thrun, S. Dermatologist-level classification of skin cancer with deep neural networks. Nature 2017, 542, 115–118. [Google Scholar] [CrossRef]
- Xiao, J.; Ding, R.; Xu, X.; Guan, H.; Feng, X.; Sun, T.; Zhu, S.; Ye, Z. Comparison and development of machine learning tools in the prediction of chronic kidney disease progression. J. Transl. Med. 2019, 17, 119. [Google Scholar] [CrossRef] [Green Version]
- LeCun, Y.; Bengio, Y.; Hinton, G. Deep learning. Nature 2015, 521, 436–444. [Google Scholar] [CrossRef]
- Mercaldo, F.; Nardone, V.; Santone, A. Diabetes mellitus affected patients classification and diagnosis through machine learning techniques. Procedia Comput. Sci. 2017, 112, 2519–2528. [Google Scholar] [CrossRef]
- Alcalá-Rmz, V.; Zanella-Calzada, L.A.; Galván-Tejada, C.E.; García-Hernández, A.; Cruz, M.; Valladares-Salgado, A.; Galván-Tejada, J.I. Identification of Diabetic Patients through Clinical and Para-Clinical Features in Mexico: An Approach Using Deep Neural Networks. Int. J. Environ. Res. Public Health 2019, 16, 381. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Soltani, Z.; Jafarian, A. A New Artificial Neural Networks Approach for Diagnosing Diabetes Disease Type II. Int. J. Adv. Comput. Sci. Appl. 2016, 7, 89–94. [Google Scholar] [CrossRef] [Green Version]
- Kweon, S.; Kim, Y.; Jang, M.J.; Kim, Y.; Kim, K.; Choi, S.; Chun, C. Data resource profile: The Korea National Health and Nutrition Examination Survey (KNHANES). Int. J. Epidemiol. 2014, 43, 69–77. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Ryu, K.S.; Bae, J.W.; Jeong, M.H.; Cho, M.C.; Ryu, K.H. Risk Scoring System for Prognosis Estimation of Multivessel Disease Among Patients with ST-Segment Elevation Myocardial Infarction. Int. Heart J. 2019, 60, 708–714. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Cox, D.R. The Regression Analysis of Binary Sequences. J. R. Stat. Soc. Ser. B 1958, 20, 215–232. [Google Scholar] [CrossRef]
- Munkhdalai, L.; Munkhdalai, T.; Namsrai, O.E.; Lee, J.Y.; Ryu, K.H. An Empirical Comparison of Machine-Learning Methods on Back Client Credit Assessments. Sustainability 2018, 11, 699. [Google Scholar] [CrossRef] [Green Version]
- Dreiseitl, S.; Ohno-Machado, L. Logistic regression and artificial neural network classification models: A methodology review. J. Biomed. Inform. 2002, 35, 352–359. [Google Scholar] [CrossRef] [Green Version]
- Altman, N.S. An Introduction to Kernel and Nearest-Neighbor Nonparametric Regression. Am. Stat. 1992, 46, 175–185. [Google Scholar]
- Tan, P.N.; Steinbach, M.; Kumar, V.; Karpatne, A. Introduction to Data Mining, 2nd ed.; Pearson Education: London, UK, 2018; pp. 262–295. [Google Scholar]
- Viola, P.; JONES, M.J. Robust Real-Time Face Detection. Int. J. Comput. Vis. 2004, 57, 137–154. [Google Scholar] [CrossRef]
- Liaw, A.; Wiener, M. Classification and regression by randomForest. R News 2002, 2, 18–22. [Google Scholar]
- Griffis, J.C.; Allendorfer, J.B.; Szaflarski, J.P. Voxel-based Gaussian naïve Bayes classification of ischemic stroke lesions in individual T1-weighted MRI scans. J. Neurosci. Methods 2016, 257, 97–108. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Kingma, D.P.; Ba, J.L. ADAM: A Method for Stochastic Optimization. arXiv 2014, arXiv:1412.6980. [Google Scholar]
- Ruder, S. An Overview of Gradient Descent Optimization Algorithms. arXiv 2016, arXiv:1609.04747. [Google Scholar]
- Bradley, A.P. The use of the area under the ROC curve in the evaluation of machine learning algorithms. Pattern Recognit. 1997, 30, 1145–1159. [Google Scholar] [CrossRef] [Green Version]
- Pei, D.; Gong, H.; Zhang, C.; Guo, Q. Accurate and rapid screening model for potential diabetes mellitus. BMC Med Inform. Decis. Mak. 2019, 19, 41. [Google Scholar] [CrossRef] [Green Version]
- Makrilakis, K.; Liatis, S.; Grammatikou, S.; Perrea, D.; Stathi, C.; Tsiligros, P.; Katsilambros, N. Validation of the Finnish diabetes risk score (FINDRISC) questionnaire for screening for undiagnosed type 2 diabetes, dysglycaemia and the metabolic syndrome in Greece. Diabetes Metab. 2011, 37, 144–151. [Google Scholar] [CrossRef]
- Lindström, J.; Tuomilehto, J. The diabetes risk score: A practical tool to predict type 2 diabetes risk. Diabetes Care 2003, 26, 725–731. [Google Scholar] [CrossRef] [Green Version]
- Rathmann, W.; Martin, S.; Haastert, B.; Icks, A.; Holle, R.; Löwel, H.; Giani, G.; KORA Study Group. Performance of screening questionnaires and risk scores for undiagnosed diabetes: The KORA Survey 2000. Arch. Intern. Med. 2005, 165, 436–441. [Google Scholar] [CrossRef] [Green Version]
- Bang, H.; Edwards, A.M.; Bomback, A.S.; Ballantyne, C.M.; Brillon, D.; Callahan, M.A.; Teutsch, S.M.; Mushlin, A.I.; Kern, L.M. Development and validation of a patient self-assessment score for diabetes risk. Ann. Intern. Med. 2009, 151, 775–783. [Google Scholar] [CrossRef]
- Al-Lawati, J.A.; Tuomilehto, J. Diabetes risk score in Oman: A tool to identify prevalent type 2 diabetes among Arabs of the Middle East. Diabetes Res. Clin. Pract. 2007, 77, 438–444. [Google Scholar] [CrossRef]
- Witte, D.R.; Shipley, M.J.; Marmot, M.G.; Brunner, E.J. Performance of existing risk scores in screening for undiagnosed diabetes: An external validation study. Diabet. Med. 2010, 27, 46–53. [Google Scholar] [CrossRef] [PubMed]
- Leiter, L.A.; Barr, A.; Bélanger, A.; Lubin, S.; Ross, S.A.; Tildesley, H.D.; Fontaine, N. Diabetes Screening in Canada (DIASCAN) Study: Prevalence of undiagnosed diabetes and glucose intolerance in family physician offices. Diabetes Care 2001, 24, 1038–1043. [Google Scholar] [CrossRef] [PubMed] [Green Version]






{kind=link}
{kind=link}
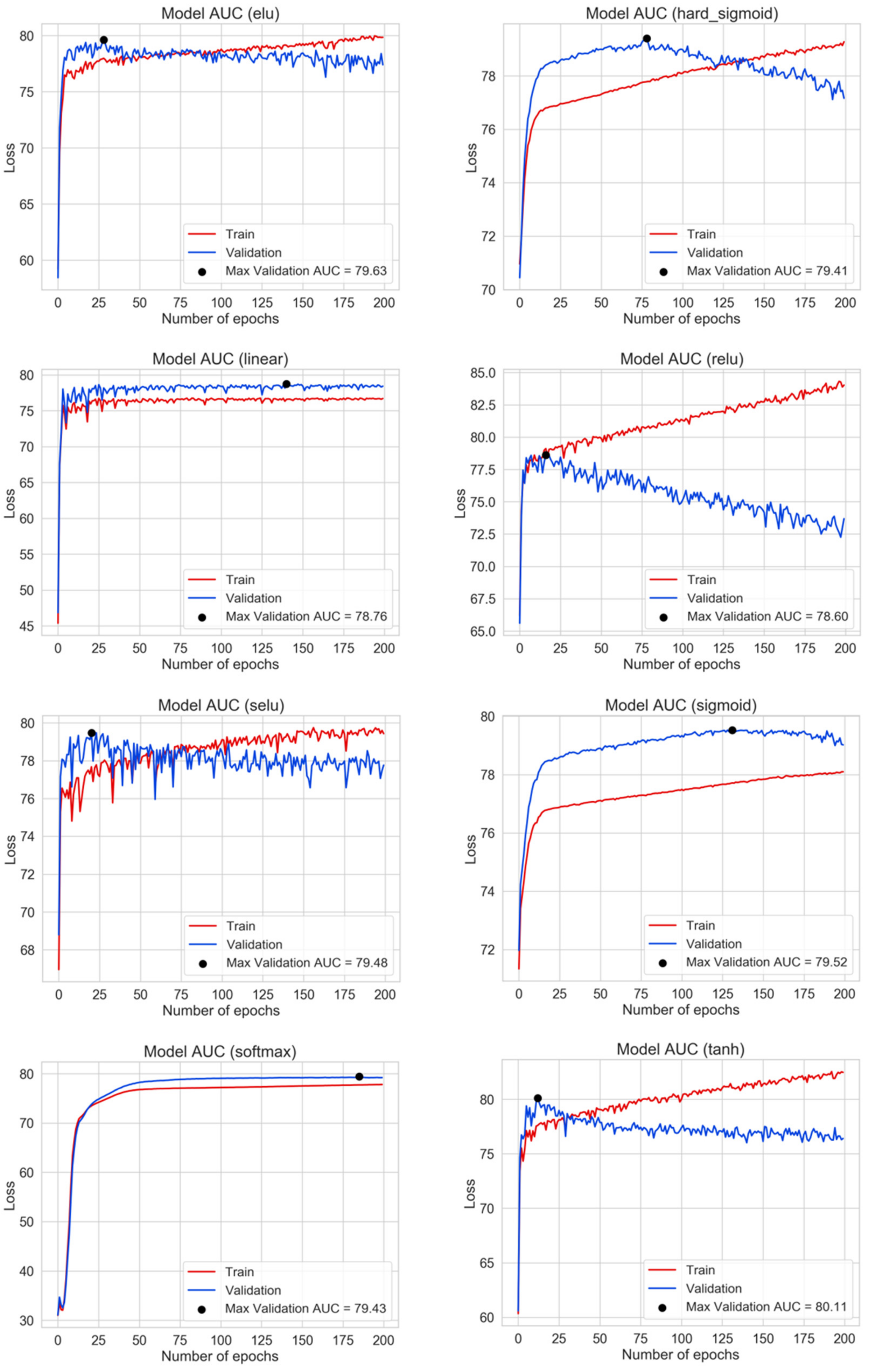{kind=link}
{kind=link}
{kind=link}
| Variables | Development Dataset n = 11456 | Validation Dataset n = 4444 | ||||
|---|---|---|---|---|---|---|
| NG n = 8311 | IFG b = 2781 | UDG n = 364 | NG n = 3115 | IFG b = 1182 | UDG n = 147 | |
| Age (year) | 45.6 ± 15.5 | 54.0 ± 13.3 | 55.6 ± 12.4 | 45.7 ± 15.8 | 53.9 ± 14.2 | 55.5 ± 13.5 |
| Male (%) | 37.7 | 52.8 | 55.2 | 37.5 | 52.7 | 55.8 |
| Height (cm) | 162.9 ± 9.0 | 163.6 ± 9.2 | 163.3 ± 9.7 | 163.2 ± 9.1 | 163.8 ± 9.3 | 163.5 ± 9.1 |
| Weight (kg) | 61.6 ± 11.4 | 66.9 ± 12.2 | 69.4 ± 13.5 | 62.1 ± 11.7 | 67.5 ± 12.7 | 71.5 ± 14.1 |
| SBP (mmHg) | 114.3 ± 15.8 | 122.2 ± 16.2 | 124.3 ± 15.6 | 114.9 ± 15.2 | 123.0 ± 16.0 | 128.0 ± 17.8 |
| DBP (mmHg) | 74.1 ± 9.9 | 77.7 ± 10.5 | 78.8 ± 10.6 | 74.5 ± 9.4 | 78.3 ± 10.3 | 79.7 ± 11.9 |
| Hypertension (%) | 12.2 | 26.3 | 34.1 | 13.9 | 28.0 | 39.5 |
| BMI (kg/m2) | 23.1 ± 3.2 | 24.9 ± 3.4 | 25.9 ± 3.9 | 23.2 ± 3.3 | 25.0 ± 3.4 | 26.6 ± 4.1 |
| WC (cm) | 78.9 ± 9.4 | 85.1 ± 9.2 | 88.2 ± 9.7 | 80.2 ± 9.6 | 86.0 ± 9.3 | 90.5 ± 9.6 |
| FHD (%) | 18.3 | 22.4 | 33.0 | 21.5 | 26.1 | 36.1 |
| Father (%) | 8.1 | 7.7 | 11.8 | 10.6 | 10.9 | 11.6 |
| Mother (%) | 8.8 | 10.8 | 16.8 | 9.7 | 12.6 | 15.7 |
| Sibling (%) | 3.9 | 7.6 | 12.4 | 4.6 | 7.6 | 13.6 |
| Smoker (%) | 35.0 | 46.5 | 51.9 | 34.1 | 48.2 | 47.6 |
| FPG (mg/dL) | 89.9 ± 5.8 | 107.0 ± 6.3 | 153.3 ± 37.0 | 90.0 ± 5.9 | 107.1 ± 6.4 | 156.8 ± 43.4 |
| TC (mg/dL) | 187.7 ± 34.0 | 195.4 ± 34.8 | 206.6 ± 37.8 | 193.1 ± 34.6 | 200.4 ± 37.9 | 208.2 ± 24.3 |
| TG (mg/dL) | 118.0 ± 89.2 | 159.1 ± 121.0 | 216.8 ± 103.8 | 120.7± 97.3 | 166.7 ± 150.1 | 204.4 ± 140.0 |
| HDL (mg/dL) | 53.0 ± 12.2 | 48.8 ± 11.4 | 46.7 ± 11.2 | 53.4 ± 13.3 | 49.1±12.2 | 46.5 ± 11.0 |
| Variables | B | Odd ration (95% CI) | P value |
|---|---|---|---|
| Age | 0.34 | 1.03 (1.03~1.04) | <0.01 |
| Male gender | 0.55 | 1.74 (1.41~2.15) | <0.01 |
| Hypertension | 1.02 | 2.77 (2.22~3.47) | <0.01 |
| BMI | 0.17 | 1.18 (1.15~1.22) | <0.01 |
| WC | 0.07 | 1.08 (1.07~1.09) | <0.01 |
| FHD | 0.72 | 2.05 (1.64~2.57) | <0.01 |
| Smoke | 0.57 | 1.77 (1.44~2.19) | <0.01 |
| Model | NIVs (non-invasive variables) | AUC |
|---|---|---|
| Undiagnosed screening | ||
| Our DLM | Gender, age, hypertension, family history of diabetes, smoking status, BMI, waist circumference | 80.11 |
| Lee et al. [3] | Age, family history of diabetes, hypertension, waist circumference, smoking status, alcohol intake (drinks/day) | 74.12 |
| Baan et al. [12] | Age, male, anti-hypertension medication, BMI | 67.50 |
| Gao et al. [11] | Age, waist circumference, diabetes in parents and or sibling | 74.11 |
| Onset of type 2 diabetes | ||
| Nanri et al. [10] | Male, age, BMI, waist circumference, smoking status, hypertension | 74.69 |
| Zhou et al. [8] | Male, age, family history of diabetes, waist circumference, dyslipidemia, diastolic blood pressure, BMI | 75.56 |
| Aekplakorn et al. [9] | Age, sex, BMI, waist circumference, hypertension, history of diabetes in parent or sibling | 75.33 |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ryu, K.S.; Lee, S.W.; Batbaatar, E.; Lee, J.W.; Choi, K.S.; Cha, H.S. A Deep Learning Model for Estimation of Patients with Undiagnosed Diabetes. Appl. Sci. 2020, 10, 421. https://doi.org/10.3390/app10010421
Ryu KS, Lee SW, Batbaatar E, Lee JW, Choi KS, Cha HS. A Deep Learning Model for Estimation of Patients with Undiagnosed Diabetes. Applied Sciences. 2020; 10(1):421. https://doi.org/10.3390/app10010421
Chicago/Turabian StyleRyu, Kwang Sun, Sang Won Lee, Erdenebileg Batbaatar, Jae Wook Lee, Kui Son Choi, and Hyo Soung Cha. 2020. "A Deep Learning Model for Estimation of Patients with Undiagnosed Diabetes" Applied Sciences 10, no. 1: 421. https://doi.org/10.3390/app10010421