2.1. Ambient Assisted Living Systems
Several surveys in the literature describe recent trends in smart homes aimed at assisted living systems [
6,
7,
8,
9]. These monitoring systems can use exclusively ambient sensors (i.e., RGB and/or infrared cameras) to limit user discomfort as much as possible [
10,
11,
12], can use wearable sensors if health parameters need to be monitored [
13], or can exploit different modalities at the same time [
6,
7,
8].
The following systems make a pervasive use of ambient and wearable sensors. Necesity [
14] is an ambient assisted living system, which monitors the states of the elderly (out, active, inactive, resting, sleeping and inactive anomalous), through different ambient sensors (pressure, door and activity) scattered into the environment. Both [
15,
16] present an elderly healthcare system aimed at monitoring different activities using body sensors. A significant issue for systems based on body sensors is the need to apply them onto the subject, for better accuracy or to detect more actions or activities. This can be considered a critical aspect because wearable sensors can lead to physical discomfort for the user. A different kind of sensor, less invasive and more discreet, is used in the system presented by [
17], which can both track and detect the fall of elderly people using smart tiles.
Regarding video-based systems, ref. [
18] propose a method for human posture-based and movements-based monitoring, limited however to only 5 postures (standing, bending, sitting, lying and lying toward) and 4 movements (running, jump, inactive, active). IFADS (Image-based FAll Detection System) [
19] focuses on falls that might happen while sitting down and standing up from a chair, a situation of potential danger for elderly people.
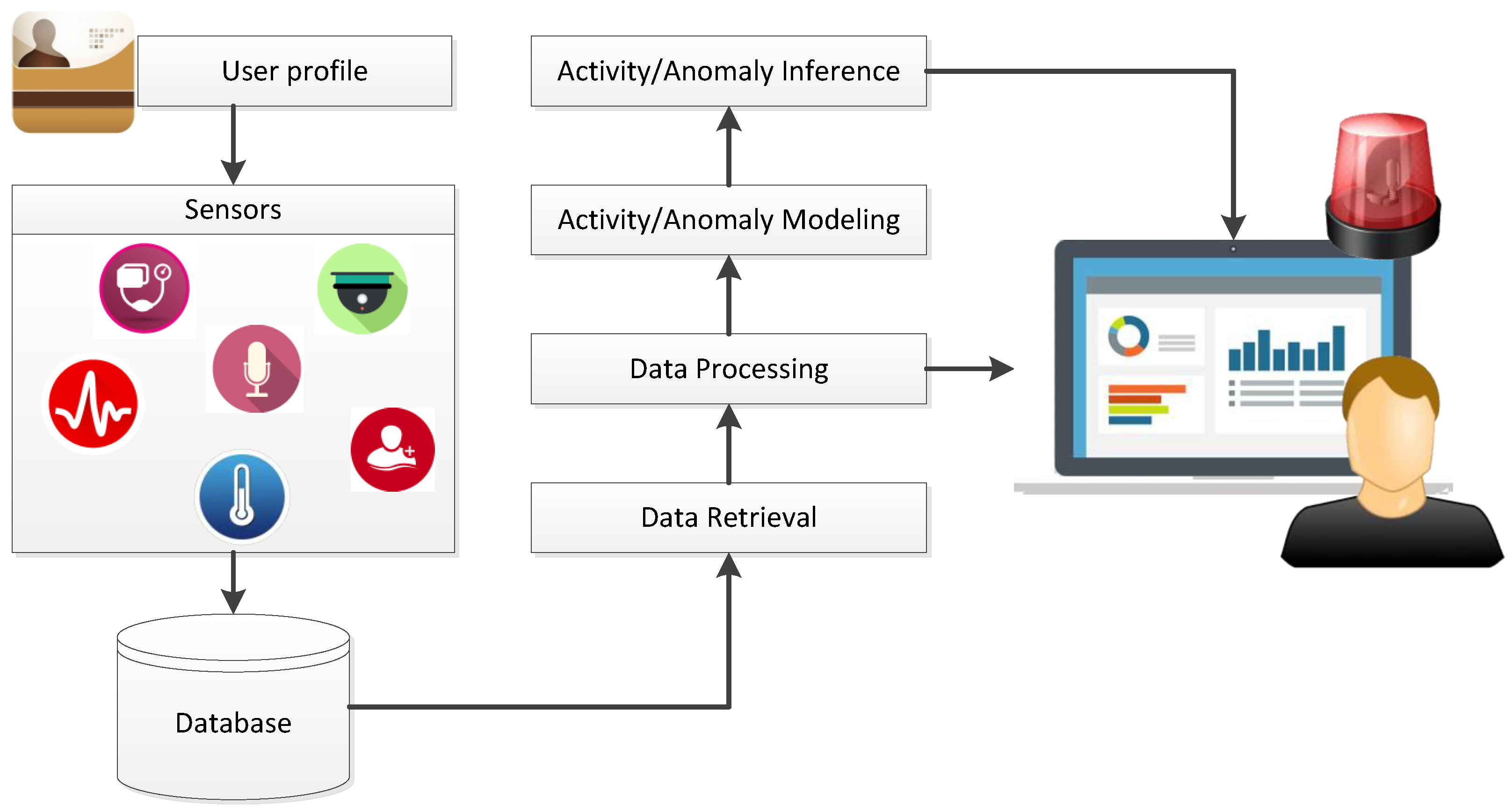
In this work we design a monitoring system which exploits visual data. This type of information is easily acquired using RGB cameras that can be placed in the environment with minimum effort. As an indication of the pervasiveness and affordability of this kind of sensors, the survey [
8] reports more than 60 works on activity monitoring systems exploiting visual data, and about 20 works for wearable sensors. Moreover, different from existing solutions in the literature, our system is carefully designed to support the recognition and monitoring of a wider variety of actions, including status, different alerting situations as well as daily life activities. These actions have been specifically selected for monitoring elderly people at home.
2.2. Action Recognition Methods
In recent years, deep learning received considerable attention in computer vision applications. Many deep learning-based approaches have been proposed to tackle the problem of human action recognition. In the following we present some works on action recognition mostly based on RGB inputs and exploiting different deep learning strategies.
Table 1 summarizes the performance of some of the relevant methods in the state-of-the-art. Results are reported for the most common datasets. The works in the literature are mainly based on one of the following three deep learning strategies: fusing different pieces of information about the video stream (i.e., two-stream networks [
20]); including spatio-temporal structure (i.e., 3D convolutional networks [
21]); including temporal analysis of video contents (i.e., long short-term memory networks [
22]).
In two-stream networks, the spatial RGB information, is usually combined with temporal information in the form of motion vectors or optical flows. The two sources of information are used for training two separate networks and the outputs are fused in late layers. In [
20], a spatial network is trained on single RGB frames while the temporal network is trained on a stack of optical flow frames. The two networks perform classification and the fusion is applied to the class scores using a Support Vector Machine (SVM). In [
38], computed optical flows are substituted with motion vectors that are readily available in video streams, thus improving the efficiency of the two-stream networks making the approach usable in real-time applications. In [
29], instead of performing late fusion, the two streams are fused in middle layers using convolution and pooling layers. Long-range temporal structure modeling and warped flows are exploited in [
30] in a temporal segment network (TSN) improving the original two-stream network results. Fusing multiple information is also exploited in [
42] where a multitask deep architecture is used to perform 2D and 3D pose estimation jointly with action recognition. The model first predicts location of body joints and then, using this information, it predicts the action performed in the video. The joint pose/action learning and recognition is shown to be more robust than using the information separately.
Temporal information can be also incorporated into the network architectures by considering stack of frames and 3D convolutions. The work introducing this rationale is [
21]. It is shown that an architecture with small
convolution kernels in all layers can improve recognition performance. The new architecture (3D ConvNet) is able to produce robust features (C3D) that can be effectively used in a simple linear classifier for action recognition. Carreira et al. [
33] extend a two-stream network architecture, based on inception-V1, with 3D convolutions creating a two-stream inflated 3D ConvNet (I3D). The temporal 3D ConvNet [
34] extends a DenseNet architecture by introducing a new temporal layer that models variable temporal convolution kernel depths with 3D filters and 3D pooling kernels. An approach to learn video representations using neural networks with long-term temporal convolutions (LTC) is presented in [
32]. Different low-level frame representations are considered, and high-quality optical flows are found to be the most relevant for robust action recognition. Standard Convolutional Neural Networks (CNN) analyze information at local neighborhood. Wang et al. [
40] introduced non-local operations as a generic family of building blocks for capturing long-range dependencies in action recognition videos. Experiments are performed on the Inflated 3D ConvNet showing improvements to the Kinetics dataset. Tran et al. [
39] demonstrated the advantages of 3D CNNs over 2D CNNs within the framework of residual learning. The 3D convolutional filters are factorized into separate spatial and temporal components. The devised R(2+1)D convolutional block (2+1-dimensional ResNet) can achieve comparable or superior results to the state-of-the-art methods.
Training networks for action recognition usually requires a large amount of annotated data. In [
43] a study is conducted on how to improve action recognition classification using large-scale weakly supervised pre-training. The reference model used in the experimentation is the R(2+1)D-d [
39]. Results shows that notwithstanding data noise, the models significantly improve the state-of-the-art performance. Most 3DCNN models are built upon RGB and optical flow streams and lack information about human pose. Yan et al. [
44] proposed a novel model that encodes multiple pose modalities within a unified 3D framework. The model, Pose-Action 3D Machine (PA3D), exploits a novel temporal pose convolution to aggregate spatial poses over frames. Building deep 3DCNN results in expensive computational cost and memory demand. Qiu et al. [
35] proposed a new family of Pseudo-3D (P3D) blocks to replace 2D Residual Units in ResNet achieving spatio-temporal encoding for videos.
3DCNN-based approaches incorporate temporal information extending filter and pooling layer to work with group of frames. Approaches based on Long-Short-Term Memory networks (LSTM) process a video as an ordered sequence of frames. Each frame is fed to the network that retains information about previous frames in internal memory states. Ng et al. [
28] proposed a recurrent neural network that uses LSTM cells connected to the output of the underlying CNN. Donahue et al. [
22] developed a novel recurrent convolutional architecture suitable for large-scale visual learning. The tested RNN models are directly connected to ConvNet models, and are trained to output variable length video descriptions of actions. In [
31] a spatio-temporal LSTM for 3D human action recognition is proposed. The standard LSTM learning approach is extended to incorporate both spatial and temporal domains to analyze the hidden sources of action-related information within the input data over both domains concurrently. In standard LSTM approaches it is implicitly assumed that motions in videos are stationary across different spatial locations. To overcome this limitation, Lattice-LSTM [
36] extends LSTM by learning independent hidden state transitions of memory cells for individual spatial locations. In [
37] a network based on the recurrent neural networks with long short-term memory units is built. The model uses a spatial attention module to assign different levels of importance to different joints in a 3D skeleton. Moreover, a temporal attention module allocates different levels of attention to each frame within a sequence. Attention-LSTMs (ALSTMs) take into account spatial locality in the form of attention. To be applied for video sequence, VideoLSTM [
41] enhances an ALSTM architecture by introducing Convolutional ALSTM modules to exploit the spatial correlation in frames, and a Motion-based Attention module to guide the network towards the relevant spatio-temporal locations.
2.3. Action Recognition Datasets
In the literature there exist many datasets that provide a list of different actions depending on the recognition task for which they have been designed.
Table 2 shows a list of the most used datasets for human action recognition based on RGB data. For each dataset we report a brief description, the total number of action samples and the number of classes.
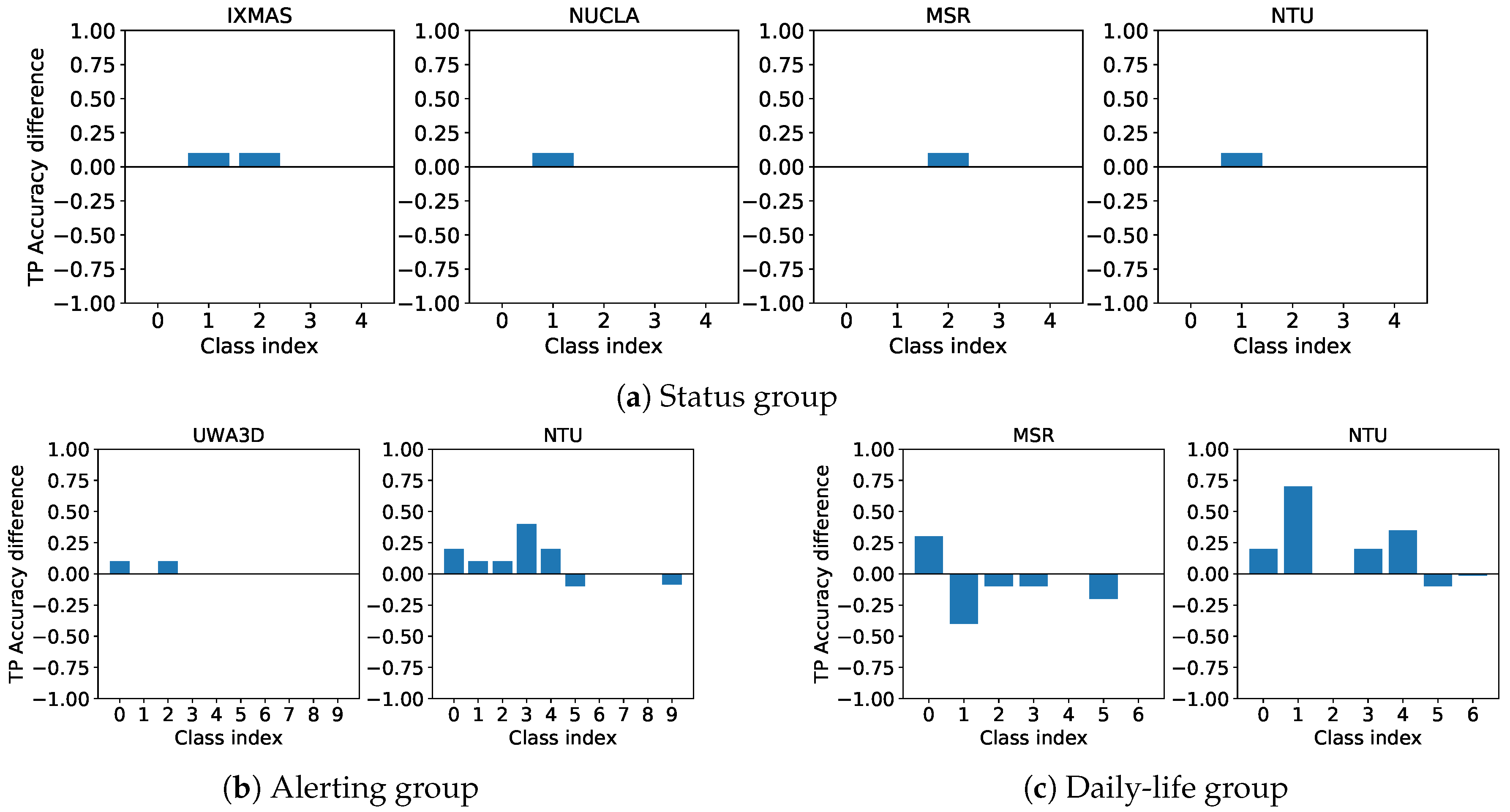
IXMAS [
45]: the dataset contains 15 actions captured from different viewpoints. A total of 11 people perform the following actions: nothing, check watch, cross arms, scratch head, sit down, get up, turn around, walk, wave, punch, kick, point, pick up, throw (over head), throw (from bottom up). The acquisition device is a low-resolution 23fps RGB camera. Its position is fixed, just as background, illumination and environment where actions are performed.
UCF Sport [
46]: the dataset is a collection of sport videos acquired from a wide range of video sources. It contains 150 video sequences belonging to 10 actions: diving, golf swing, kicking, lifting, riding horse, running, skateboarding, swing-bench, swing-side, and walking.
Hollywood 2 [
47]: twelve frequent actions in movies are considered in this dataset: answer phone, drive car, eat, fight person, get out car, hand shake, hug person, kiss, run, sit down, sit up, stand up. These actions have been labelled from 69 movie scripts and the corresponding sequence included in the dataset for a total of 600,000 frames and 7 h of video. The dataset also contains scene labelling.
HMDB-51 [
23]: the dataset contains 51 action categories for a total of about 7000 manually annotated clips extracted from a variety of sources ranging from digitized movies to YouTube videos. Each action category contains at least 101 clips. The actions comprise: facial actions (e.g., smile), facial actions involving objects (e.g., smoking), body movements (e.g., clap hands), body movements involving objects (e.g., draw sword), human interaction (e.g., fencing).
MSR Daily Activity 3D [
48]: contains 16 different activities acquired with a Kinect device: drink, eat, read book, call cellphone, write on a paper, use laptop, use vacuum cleaner, cheer up, sit still, toss paper, play game, lay down on sofa, walk, play guitar, stand up, sit down. If possible, the subject performs each activity in two different position sitting and standing. The acquisition environment is the same for all the sequences using a fixed camera position.
UCF-50 [
49]: the dataset contains a set of 50 actions whose videos are taken from the web. The videos are characterized by random camera motion, poor lighting conditions, clutter, as well as changes in scale, appearance, and viewpoints. The actions in the dataset are very heterogeneous and some examples are tai chi, rowing, play piano, tossing balls, and biking.
UCF-101 [
24]: it is an extension of the UCF-50 dataset. 51 new actions are added bringing the total action classes to 101 and the total 13,320 video clips. Each class has an average of 125 clips.
N-UCLA [
50]: the dataset includes 10 actions captured from different viewpoints (usually 3) using multiple Kinect devices, 10 actors perform following actions: pick up with one hand, pick up with two hands, drop trash, walk around, sit down, stand up, donning, doffing, throw, carry.
Sports 1M [
51]: this is the largest available dataset of human actions. It contains 1 million YouTube videos belonging to 487 classes. On average, 1000–3000 videos comprise each class. The video classes belong to the following macro-category: aquatic sports, team sports, winter sports, ball sports, combat sports, sports with animals.
UWA3D II [
52]: contains 30 actions, mainly captured from 4 different viewpoints (front, left, right and top view) with a Kinect device in the same environments. A total of 10 subjects perform the following actions: one hand waving, one hand punching, two hand waving, two hand punching, sitting down, standing up, vibrating, falling down, holding chest, holding head, holding back, walking, irregular walking, lying down, turning around, drinking, phone answering, bending, jumping jack, running, picking up, putting down, kicking, jumping, dancing, mopping floor, sneezing, sitting down (chair), squatting, coughing.
Kinetics [
25]: the dataset contains 400 human action classes, with at least 400 video clips for each action. Each clip lasts around 10 s and is taken from a different YouTube video. The videos are annotated using Amazon’s Mechanical Turk. The actions cover a wide range of situations including human-object interactions such as playing instruments, as well as human-human interactions such as shaking hands.
DALY [
53]: the Daily Action Localization in YouTube contains high-quality temporal and spatial annotations for 3.6k instances of 10 actions in 31 h of videos (3.3 million frames). The actions belong to 10 categories: applying makeup on lips, brushing teeth, cleaning floor, cleaning, drinking, folding textile, ironing, phoning, playing harmonica, taking photos/videos.
Charades [
26]: the dataset has been created by hundreds of people recording videos in their own homes, acting out casual everyday activities. The dataset is composed of 9848 annotated videos with an average length of 30 s, showing activities of 267 people from three continents. In total, Charades provides 27,847 video descriptions, 66,500 temporally localized intervals for 157 action classes and 41,104 labels for 46 object classes.
NTU [
27]: the dataset includes 60 actions for a total of 56,880 videos acquired with a Kinect v2 device. Video sequences are recorded in different environments and captured from different viewpoints. Actions are gathered under the following categories: daily actions, medical conditions and mutual actions.
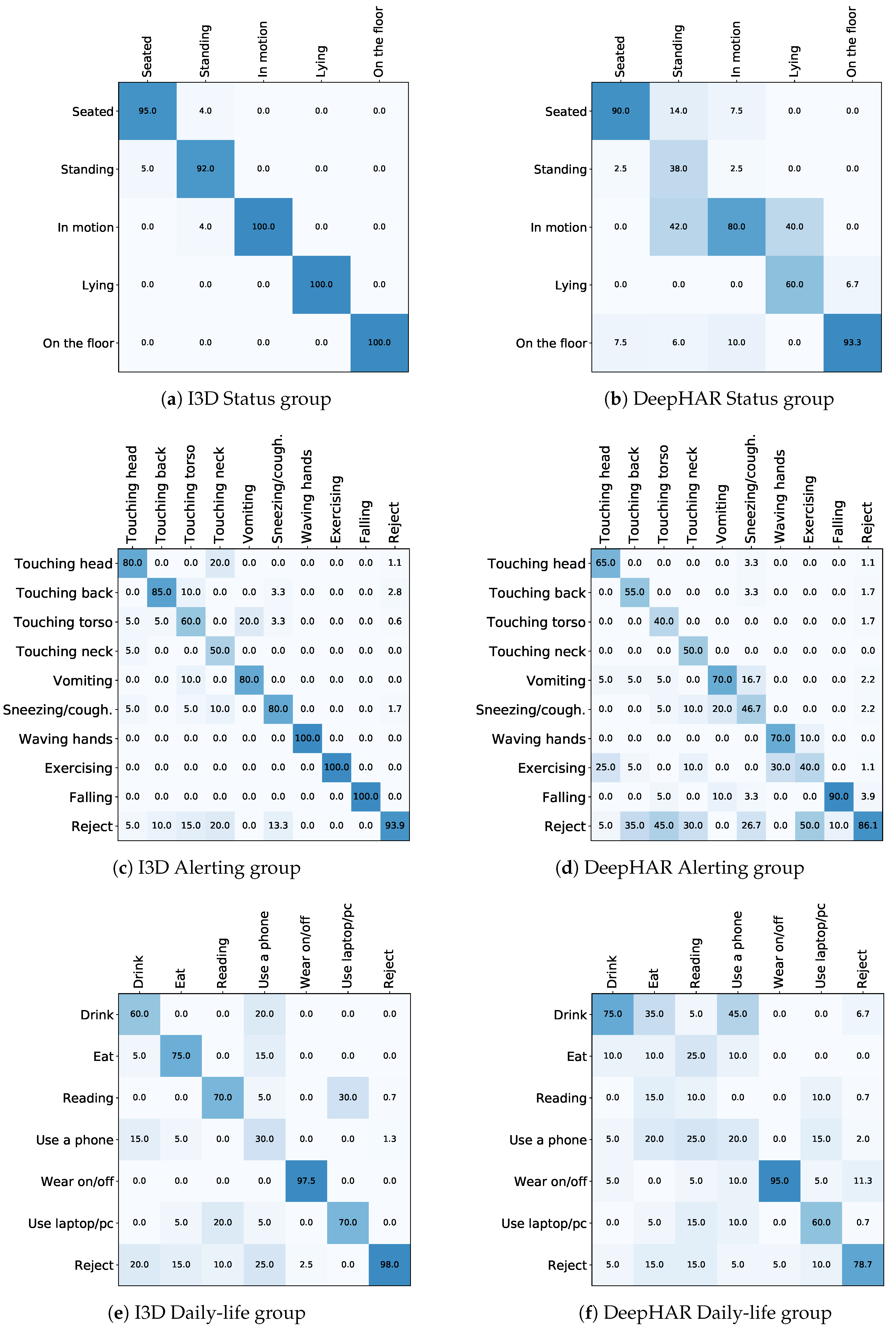
As it can be seen, the datasets in the literature are different and designed with different aims in mind. There are datasets specific for a given scenario, and others which are very heterogeneous; datasets containing high-quality videos, and datasets with homemade videos; datasets with a static background and others with a dynamic background; etc. For a robust and reliable action recognition system, selecting the right dataset is crucial if we do not want to introduce any bias towards any specific acquisition condition or set of actions. Moreover, most of the datasets in the literature are not suitable for monitoring the actions of elderly people in an indoor scenario, while others contain a small selection of possible actions of interest. However, to the best of our knowledge, no public dataset contains actions specifically performed by elderly people, depicting instead either adult or young actors. This can represent a bias for elderly monitoring, as older subjects move with a different speed compared to younger people, and could perform actions in a different way. These motivations lead us to the creation of a merged dataset selecting samples from different datasets, with the purpose of better generalizing the variability of actions movements, and partially mitigating the observed representation gap. The resulting dataset is presented in the following section.














{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}