Artificial Auditory Perception Pattern Recognition System Based on Spatiotemporal Convolutional Neural Network


Abstract
:1. Introduction
2. Related Works and Foundations
3. Proposed Method
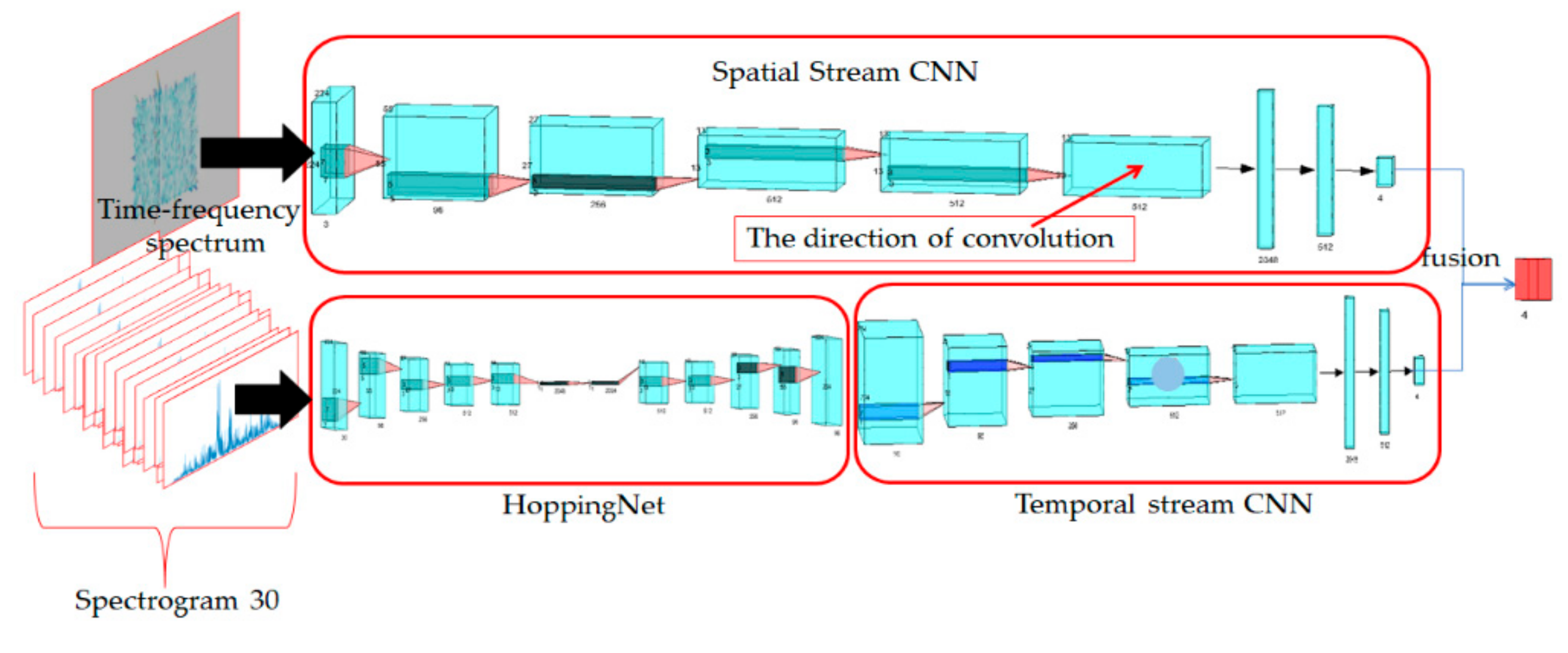
3.1. Branch of Temporal Stream CNN and HoppingNet
3.1.1. HoppingNet
3.1.2. Temporal Stream CNN
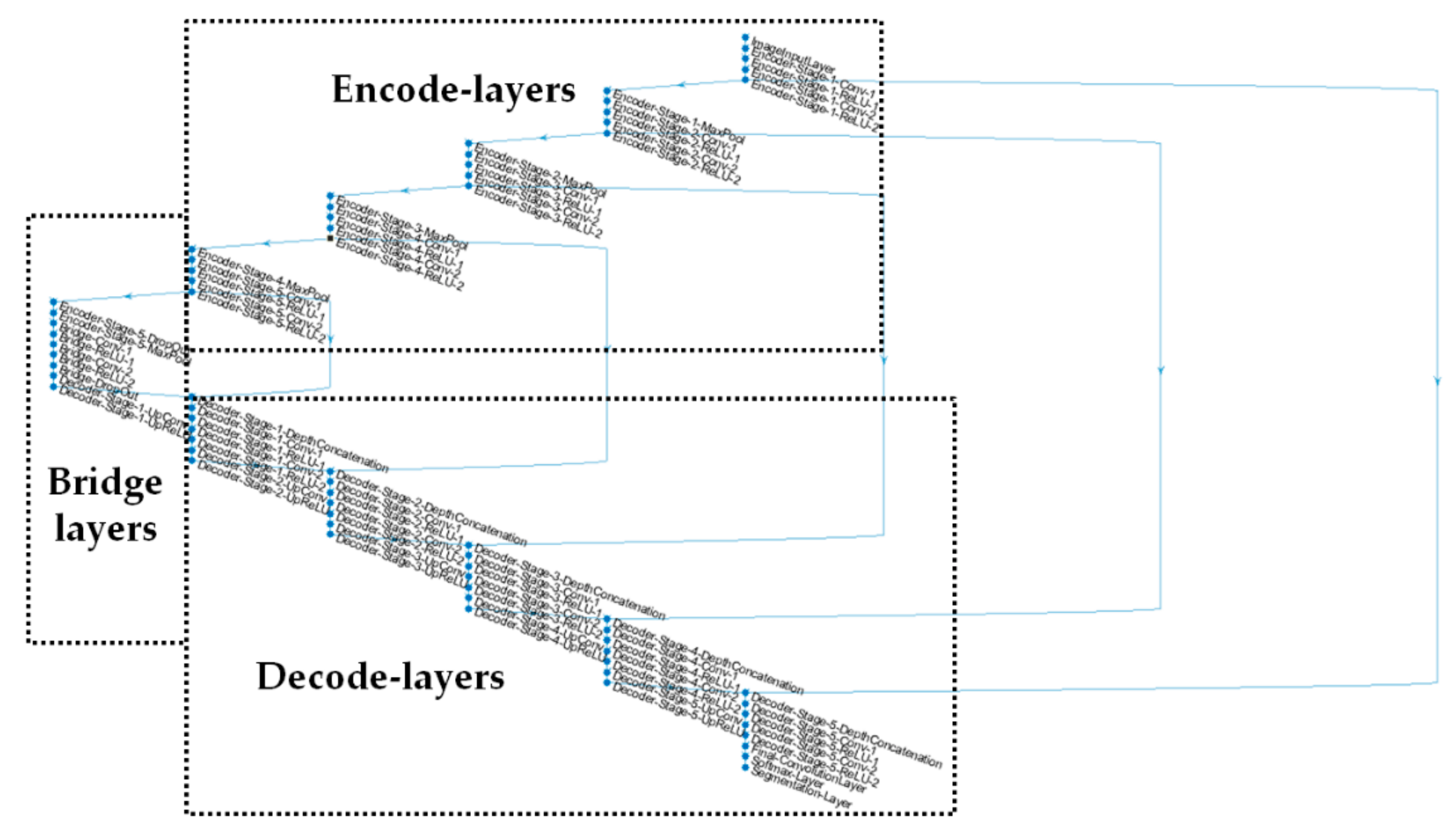
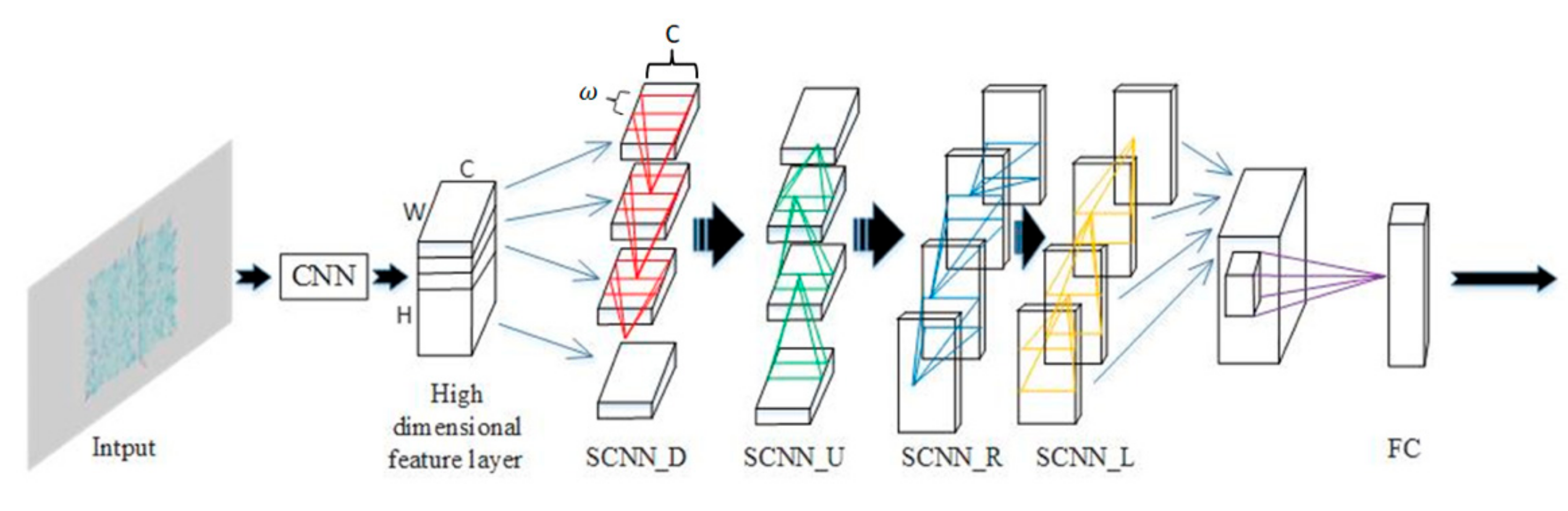
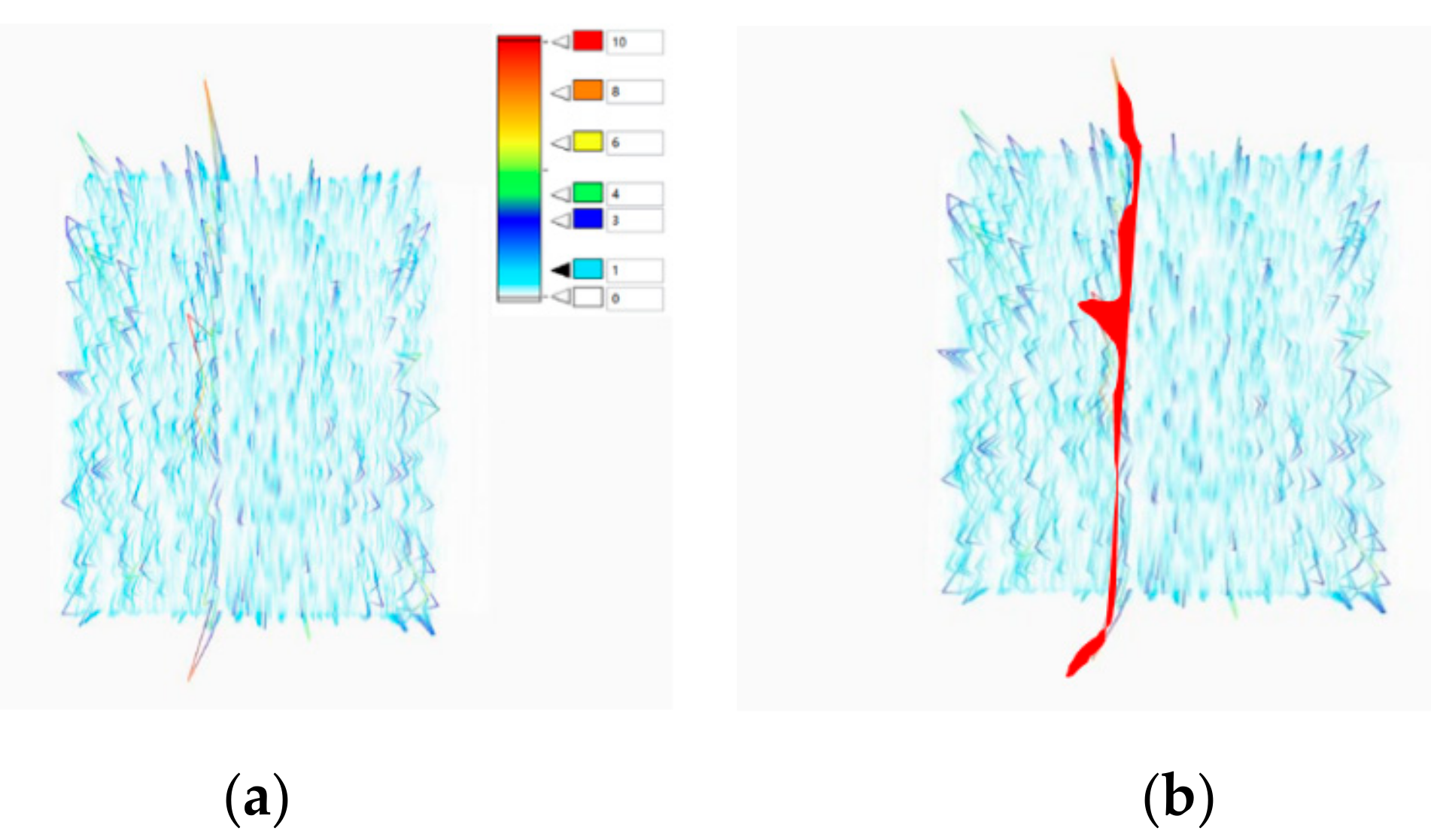
3.2. The Branch of Spatial Stream CNN
3.3. Model Implementation
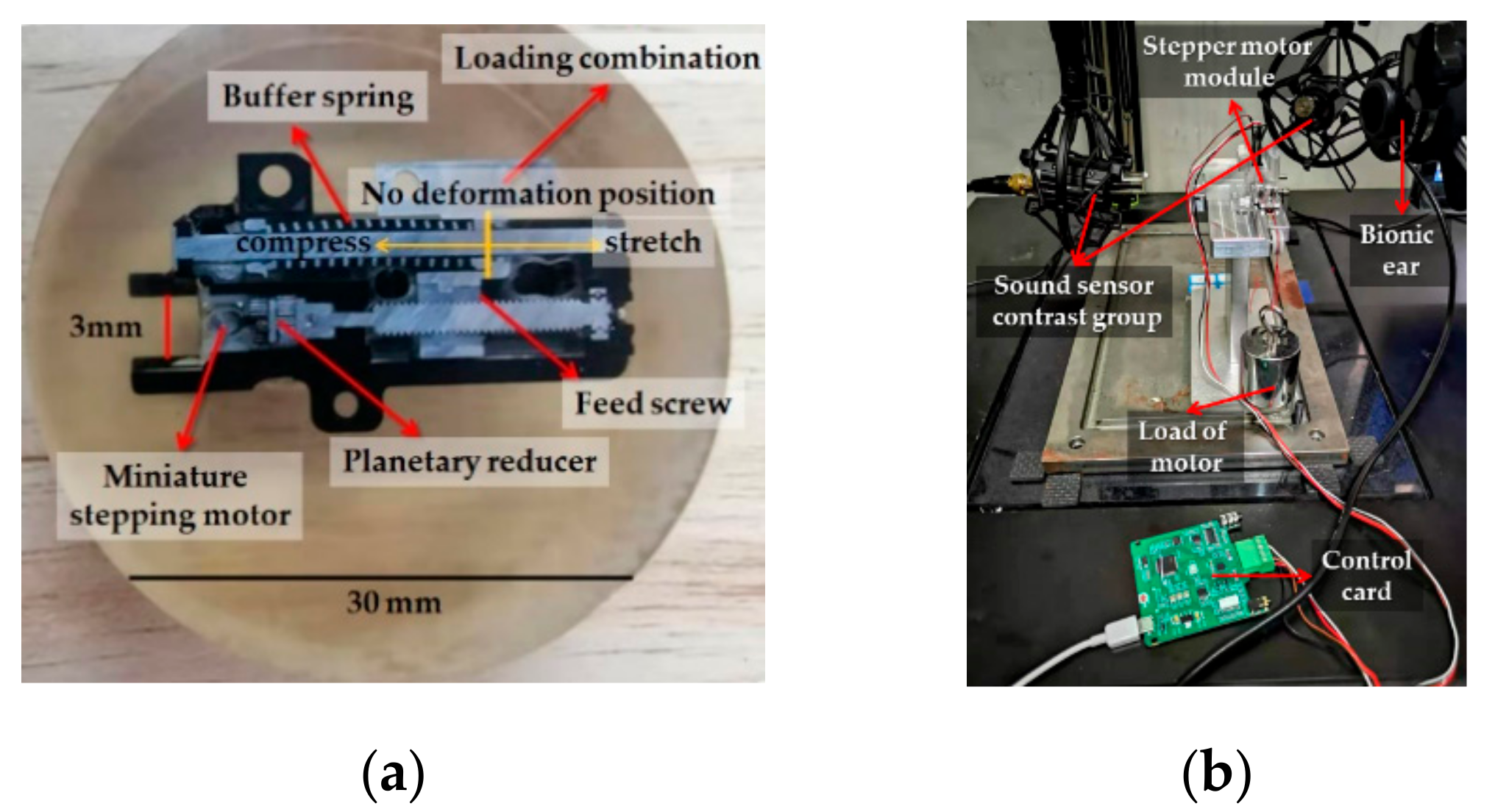
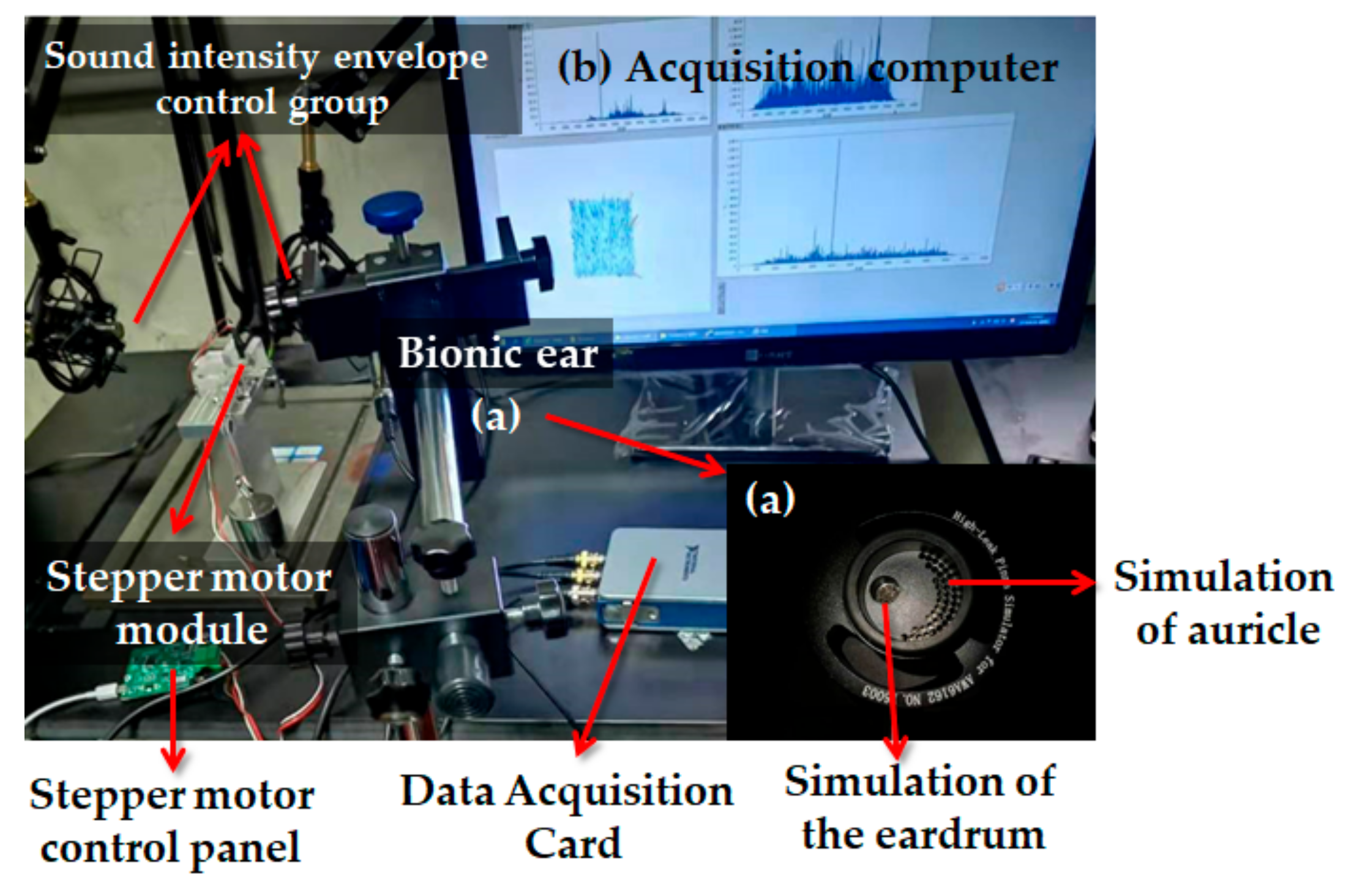
3.4. Experiment Details
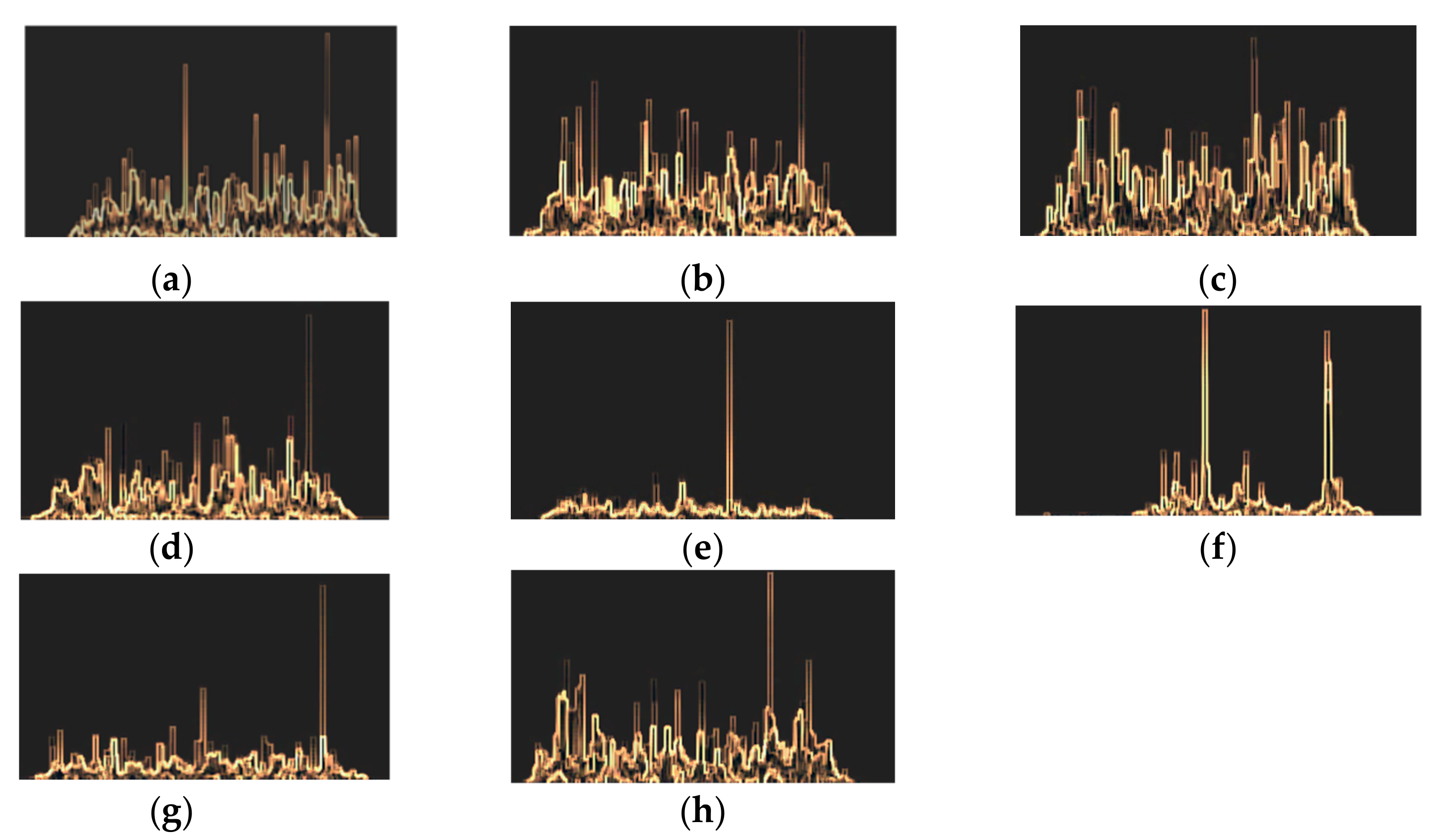
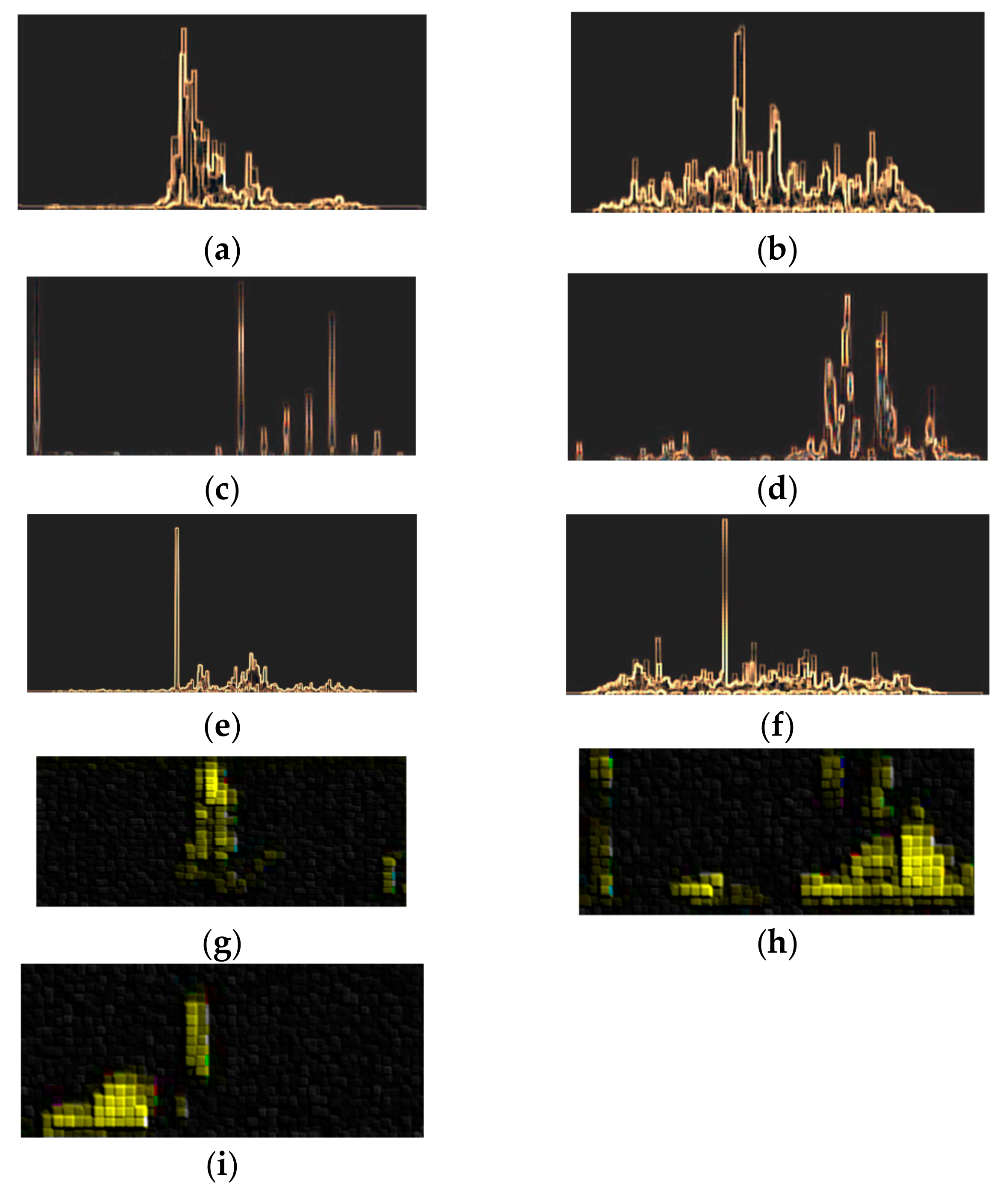
3.4.1. The Dataset
3.4.2. The Implementation Process
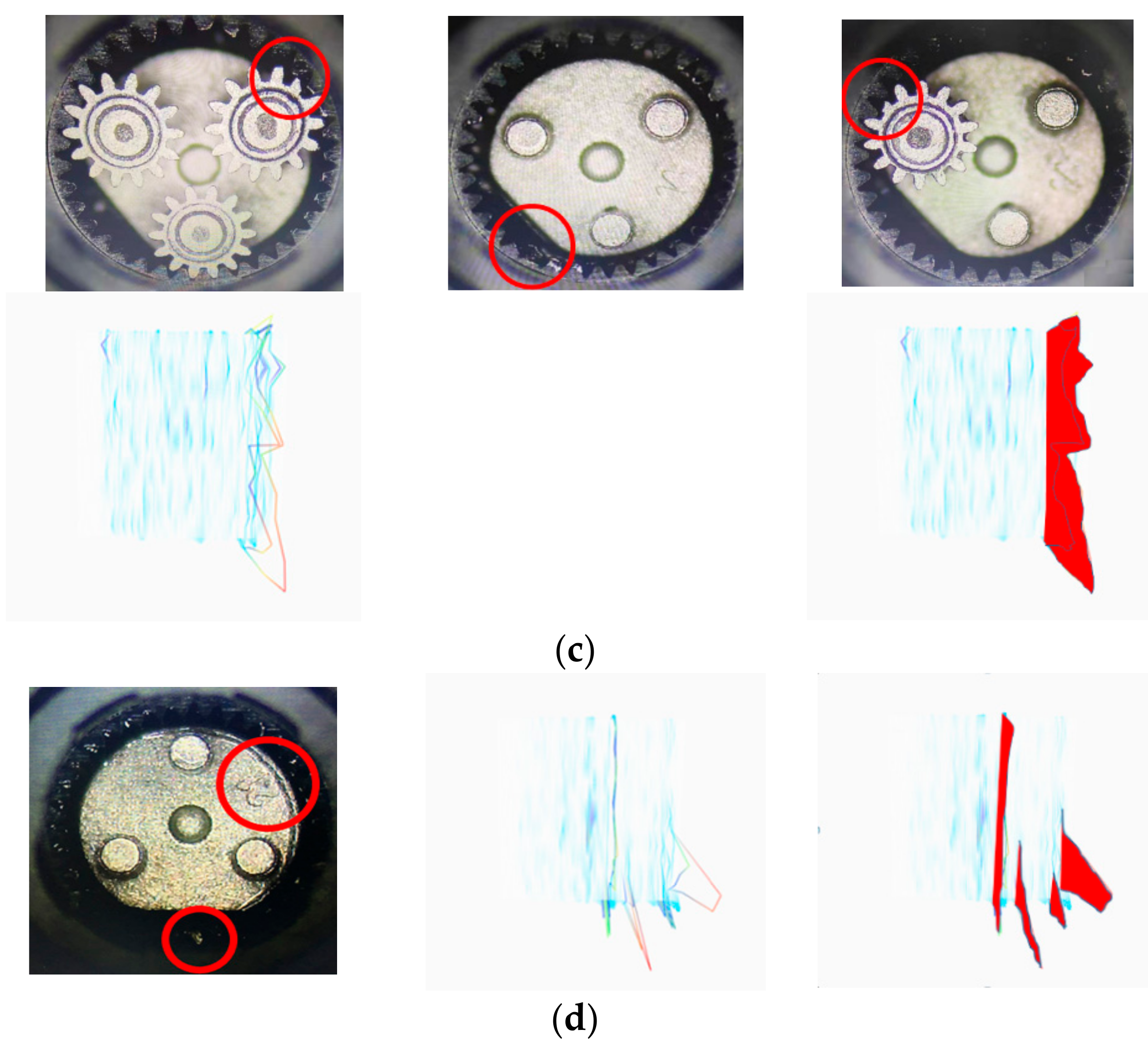
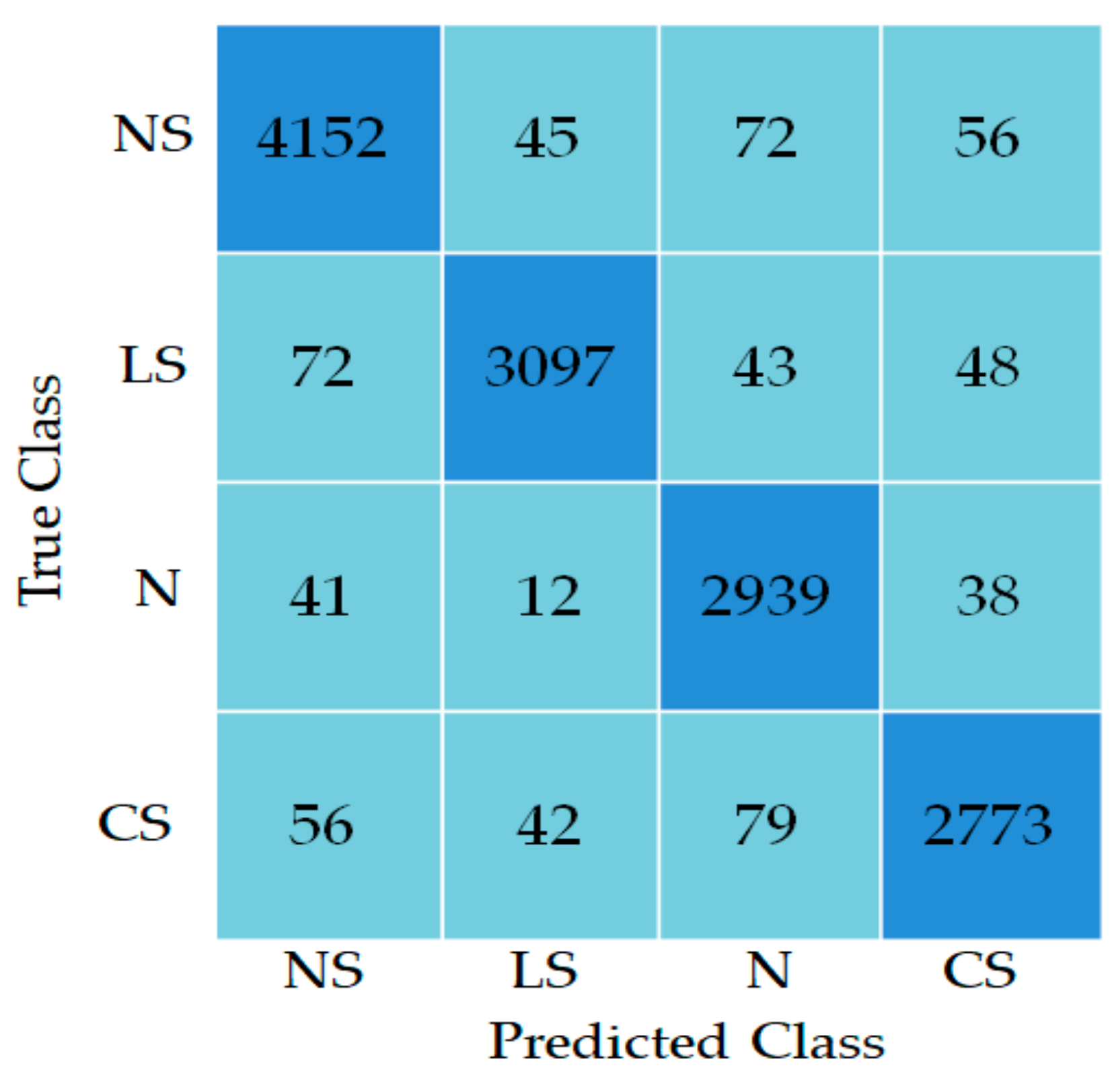
4. Results
5. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Junoh, A.K.; Nopiah, Z.M.; Muhamad, W.Z.W.; Nor, M.J.M.; Fouladi, M.H. An Optimization Model of Noise and Vibration in Passenger Car Cabin. Adv. Mater. Res. Switz. 2012, 383, 6704–6709. [Google Scholar] [CrossRef]
- Albert, B.; Zanni-Merk, C.; de Beuvron, F.D.B.; Maire, J.L.; Pillet, M.; Charrier, J.; Charrier, J.; Knecht, C.A. Smart System for Haptic Quality Control Introducing an Ontological Representation of Sensory Perception Knowledge. In Proceedings of the 8th International Joint Conference on Knowledge Discovery, Knowledge Engineering And Knowledge Management, Porto, Portugal, 9 November 2016; pp. 21–30. [Google Scholar]
- Koch, C.; Georgieva, K.; Kasi eddy, V.; Akinci, B.; Fieguth, P. A review on computer vision based defect detection and condition assessment of concrete and asphalt civil infrastructure. Adv. Eng. Inform. 2015, 29, 196–210. [Google Scholar] [CrossRef] [Green Version]
- Jian, C.X.; Gao, J.; Ao, Y.H. Automatic surface defect detection for mobile phone screen glass based on machine vision. Appl. Soft Comput. 2017, 52, 348–358. [Google Scholar] [CrossRef]
- Park, J.K.; Kwon, B.K.; Park, J.H.; Kang, D.J. Machine Learning-Based Imaging System for Surface Defect Inspection. Int. J. Precis. Eng. Manuf. Green. Technol. 2016, 3, 303–310. [Google Scholar] [CrossRef]
- Shanmugamani, R.; Sadique, M.; Ramamoorthy, B. Detection and classification of surface defects of gun barrels using computer vision and machine learning. Measurement 2015, 60, 222–230. [Google Scholar] [CrossRef]
- Cipollini, F.; Oneto, L.; Coraddu, A.; Savio, S.; Anguita, D. Unintrusive Monitoring of Induction Motors Bearings via Deep Learning on Stator Currents. Procedia Comput. Sci. 2018, 144, 42–51. [Google Scholar] [CrossRef]
- Li, C.; Sanchez, R.V.; Zurita, G.; Cerrada, M.; Cabrera, D. Fault Diagnosis for Rotating Machinery Using Vibration Measurement Deep Statistical Feature Learning. Sensors 2016, 16, 895. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Yao, Y.; Wang, H.L.; Li, S.B.; Liu, Z.H.; Gui, G.; Dan, Y.B.; Hu, J.J. End-To-End Convolutional Neural Network Model for Gear Fault Diagnosis Based on Sound Signals. Appl. Sci. 2018, 8, 1584. [Google Scholar] [CrossRef] [Green Version]
- Wang, J.L.; Yang, Z.L.; Zhang, J.; Zhang, Q.H.; Chien, W.T.K. AdaBalGAN: An Improved Generative Adversarial Network with Imbalanced Learning for Wafer Defective Pattern Recognition. IEEE Trans. Semiconduct. Manuf. 2019, 32, 310–319. [Google Scholar] [CrossRef]
- Wang, L.M.; Qiao, Y.; Tang, X.O. Action Recognition with Trajectory-Pooled Deep-Convolutional Descriptors. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Boston, MA, USA, 8 June 2015; pp. 4305–4314. [Google Scholar]
- Gan, M.; Wang, C.; Zhu, C.A. Construction of hierarchical diagnosis network based on deep learning and its application in the fault pattern recognition of rolling element bearings. Mech. Syst. Signal Process. 2016, 72, 92–104. [Google Scholar] [CrossRef]
- Shang, C.; Yang, F.; Huang, D.X.; Lyu, W.X. Data-driven soft sensor development based on deep learning technique. J. Process Control 2014, 24, 223–233. [Google Scholar] [CrossRef]
- Yao, L.; Ge, Z.Q. Deep Learning of Semisupervised Process Data with Hierarchical Extreme Learning Machine and Soft Sensor Application. IEEE Trans. Ind. Electron. 2018, 65, 1490–1498. [Google Scholar] [CrossRef]
- He, K.M.; Gkioxari, G.; Dollar, P.; Girshick, R. Mask R-CNN. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22 October 2017; pp. 2980–2988. [Google Scholar]
- Le, T.D.; Huynh, D.T.; Pham, H.V. Efficient Human-Robot Interaction using Deep Learning with Mask R-CNN: Detection, Recognition, Tracking and Segmentation. Int. Conf. Control, Autom. Robot. Vis. 2018, 162–167. [Google Scholar]
- Pobar, M.; Ivasic-Kos, M. Mask R-CNN and Optical flow based method for detection and marking of handball actions. In Proceedings of the 2018 11th International Congress on Image and Signal Processing, Biomedical Engineering and Informatics (Cisp-Bmei 2018), Beijing, China, 13–15 October 2018. [Google Scholar]
- Fang, X.; Jie, W.; Feng, T. An Industrial Micro-Defect Diagnosis System via Intelligent Segmentation Region. Sensors 2019, 19, 2636. [Google Scholar] [CrossRef] [Green Version]
- Zhang, J.C.; Zhang, Y.; Ji, D.H.; Liu, M.C. Multi-task and multi-view training for end-to-end relation extraction. Neurocomputing 2019, 364, 245–253. [Google Scholar] [CrossRef]
- Kang, G.Q.; Gao, S.B.; Yu, L.; Zhang, D.K. Deep Architecture for High-Speed Railway Insulator Surface Defect Detection: Denoising Autoencoder With Multitask Learning. IEEE Trans. Instrum. Meas. 2019, 68, 2679–2690. [Google Scholar] [CrossRef]
- Hu, C.; Tang, X.L.; Zou, L.; Yang, K.; Li, Y.N.; Zheng, L. Numerical and Experimental Investigations of Noise and Vibration Characteristics for a Dual-Motor Hybrid Electric Vehicle. IEEE Access 2019, 7, 77052–77062. [Google Scholar] [CrossRef]
- Kwon, Y.H.; Shin, S.B.; Kim, S.D. Electroencephalography Based Fusion Two-Dimensional (2D)-Convolution Neural Networks (CNN) Model for Emotion Recognition System. Sensors 2018, 18, 1383. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Chen, C.L.P.; Liu, Z.L. Broad Learning System: An Effective and Efficient Incremental Learning System without the Need for Deep Architecture. IEEE Trans. Neural Netw. Learn. Syst. 2018, 29, 10–24. [Google Scholar] [CrossRef] [PubMed]
- Salamon, J.; Bello, J.P. Deep Convolutional Neural Networks and Data Augmentation for Environmental Sound Classification. IEEE Signal Process. Lett. 2017, 24, 279–283. [Google Scholar] [CrossRef]
- Mehta, R.K.; Parasuraman, R. Neuroergonomics: A review of applications to physical and cognitive work. Front. Hum. Neurosci. 2013, 7, 889. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Feichtenhofer, C.; Pinz, A.; Zisserman, A. Convolutional Two-Stream Network Fusion for Video Action Recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 26 June 2016; pp. 1933–1941. [Google Scholar]
- Du, Y.; Wang, W.; Wang, H. Hierarchical Recurrent Neural Network for Skeleton Based Action Recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 8 June 2015; pp. 1110–1118. [Google Scholar]
- Chen, Y.H.; Emer, J.; Sze, V. Eyeriss: A Spatial Architecture for Energy-Efficient Dataflow for Convolutional Neural Networks. In ACM SIGARCH Computer Architecture News; IEEE Press: Piscataway, NJ, USA, 2016; pp. 367–379. [Google Scholar]
- Fu, G.; Liu, C.J.; Zhou, R.; Sun, T.; Zhang, Q.J. Classification for High Resolution Remote Sensing Imagery Using a Fully Convolutional Network. Remote Sens. 2017, 9, 498. [Google Scholar] [CrossRef] [Green Version]
- Gong, M.G.; Zhang, M.Y.; Yuan, Y. Unsupervised Band Selection Based on Evolutionary Multiobjective Optimization for Hyperspectral Images. IEEE Trans. Geosci. Remote Sens. 2016, 54, 544–557. [Google Scholar] [CrossRef]
- Chan, T.H.; Jia, K. PCANet: A Simple Deep Learning Baseline for Image Classification. IEEE Trans. Image Process. 2015, 24, 5017–5032. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Wang, F.; Zhang, J.; Xu, X.; Cai, Y.F.; Zhou, Z.G.; Sun, X.Q. New teeth surface and back (TSB) modification method for transient torsional vibration suppression of planetary gear powertrain for an electric vehicle. Mech. Mach. Theory 2019, 140, 520–537. [Google Scholar] [CrossRef]
- Bo, H.; Hualong, H.; Hongtao, L. Convolutional Gated Recurrent Units Fusion for Video Action Recognition. In Proceedings of the 24th International Conference on Neural Information Processing, ICONIP, Guangzhou, China, 14 November 2017. [Google Scholar]
- Mnassri, B.; El Adel, E.; Ouladsine, M. Reconstruction-based contribution approaches for improved fault diagnosis using principal component analysis. J. Process. Control 2015, 33, 60–76. [Google Scholar] [CrossRef]
- Zhang, K.; Zuo, W.M. Beyond a Gaussian Denoiser: Residual Learning of Deep CNN for Image Denoising. IEEE Trans. Image Process. 2017, 7, 3142–3155. [Google Scholar] [CrossRef] [Green Version]
- Tu, Z.G.; Xie, W.; Qin, Q.Q.; Poppe, R.; Veltkamp, R.C.; Li, B.X.; Yuan, J.S. Multi-stream CNN: Learning representations based on human-related regions for action recognition. Pattern Recognit. 2018, 79, 32–43. [Google Scholar] [CrossRef]
- Benisty, H.; Malah, D.; Crammer, K. Grid-based approximation for voice conversion in low resource environments. EURASIP J. Audio Speech Music Process. 2016, 3, 1–14. [Google Scholar] [CrossRef] [Green Version]
- Torija, A.J.; Ruiz, D.P.; Ramos-Ridao, A.F. Use of back-propagation neural networks to predict both level and temporal-spectral composition of sound pressure in urban sound environments. Build. Environ. 2012, 52, 45–56. [Google Scholar] [CrossRef]
- Kulin, M.; Kazaz, T.; Moerman, I.; De Poorter, E. End-to-End Learning From Spectrum Data A Deep Learning Approach for Wireless Signal Identification in Spectrum Monitoring Applications. IEEE Access 2018, 6, 18484–18501. [Google Scholar] [CrossRef]
- Szegedy, C.; Ioffe, S.; Vanhoucke, V.; Alemi, A.A. Inception-v4, Inception-ResNet and the Impact of Residual Connections on Learning. In Proceedings of the Thirty-First Aaai Conference on Artificial Intelligence, San Francisco, CA, USA, 4 February 2017; pp. 4278–4284. [Google Scholar]
- Tajbakhsh, N.; Shin, J.Y.; Gurudu, S.R.; Hurst, R.T. Convolutional Neural Networks for Medical Image Analysis: Full Training or Fine Tuning? IEEE Trans. Med Imaging 2016, 5, 1299–1312. [Google Scholar] [CrossRef] [PubMed] [Green Version]














{kind=link}
{kind=link}
{kind=link}
{kind=link}
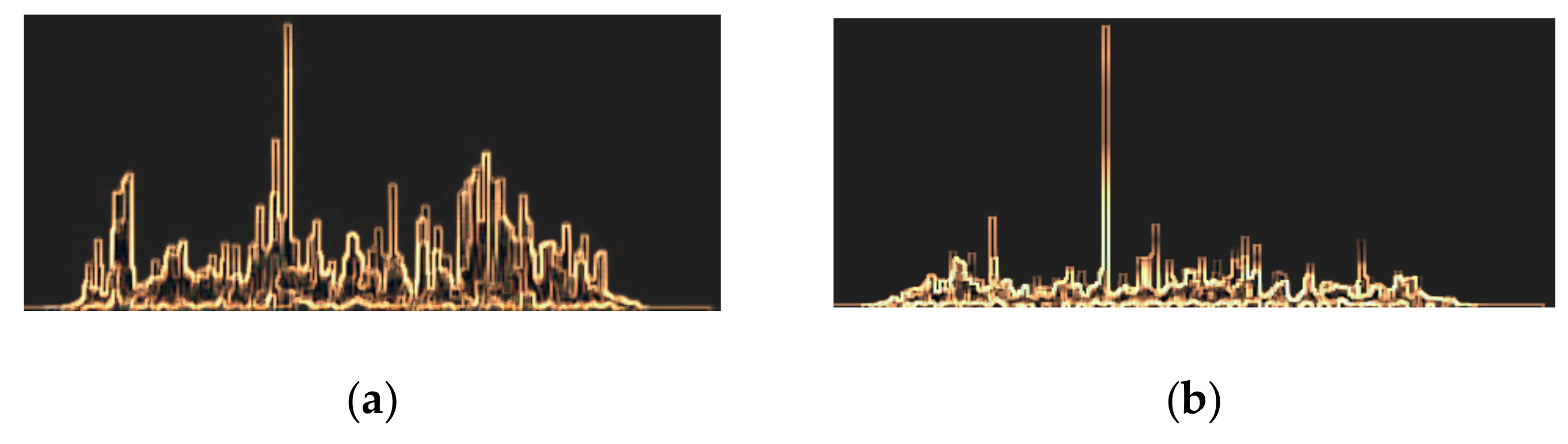{kind=link}
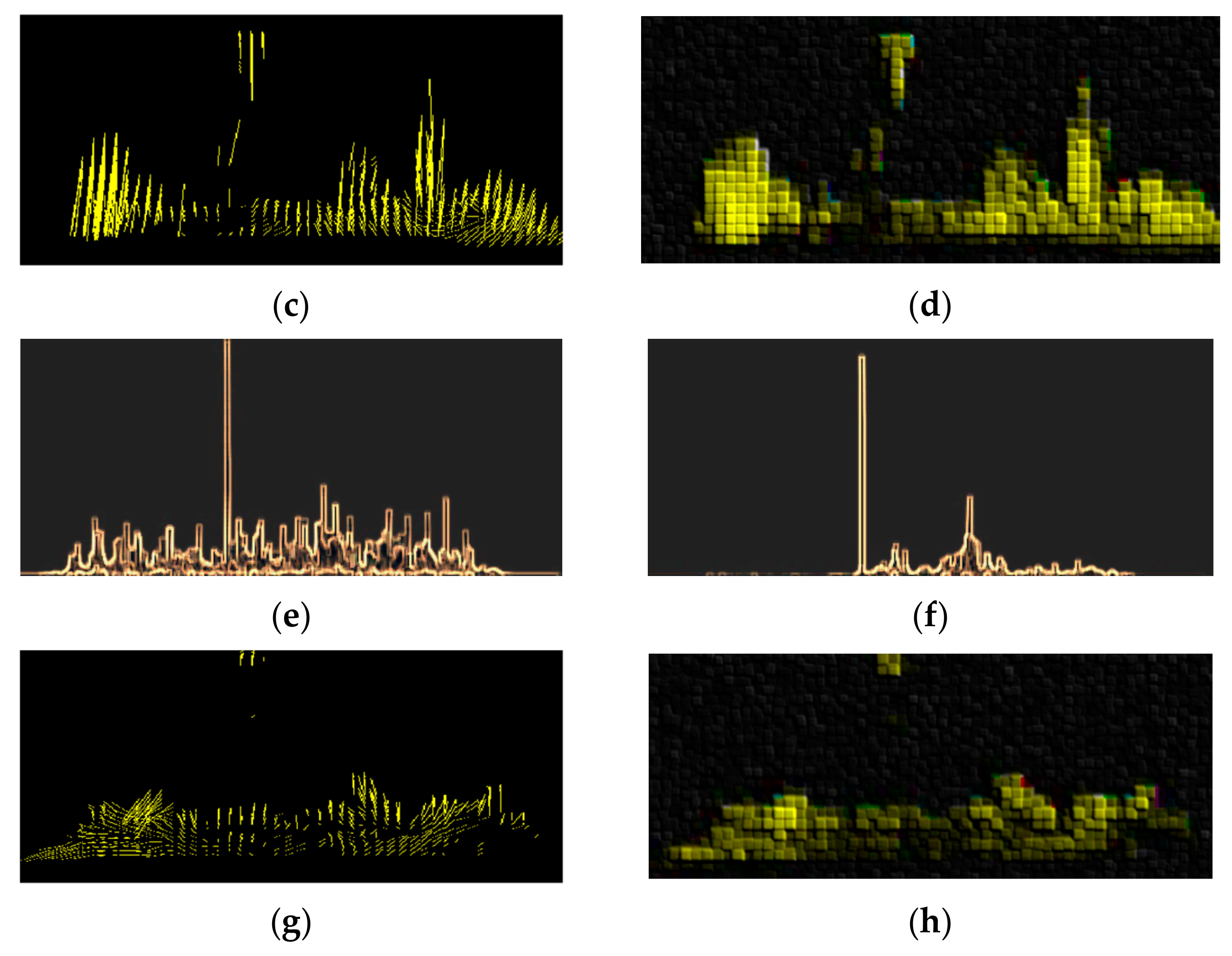{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Layers (Kernel Size, Stride) | Step | Type | Input | Output |
|---|---|---|---|---|
| ImageInputLayer | Encode_Block_1 | 3 | 64 | |
| Conv_ Relu_Encoder_1 (3 × 3,1) | Encode_Block_1 | Pad (same) | 64 | 64 |
| *Conv_ Relu_Encoder_2 (3 × 3,1) | Encode_Block_1 | Pad (same) | 64 | 64 |
| Max_Pooling | Encode_Block_ (2–5) | Pad (0,0,0,0) | 64 | 64 |
| Conv_ Relu_Encoder_1 (3 × 3,1) | Encode_Block_ (2–5) | Pad (same) | 64 | [128,2048] |
| *Conv_ Relu_Encoder_2 (3 × 3,1) | Encode_Block_ (2–5) | Pad (same) | [128,2048] | [128,2048] |
| Drop_Out | Bridge_Block | 50% | [128,2048] | [128,2048] |
| Max_Pooling | Bridge_Block | Pad (0,0,0,0) | 2048 | 4096 |
| Conv_ Relu_Bridge _1 (3 × 3,1) | Bridge_Block | Pad (same) | 4096 | 4096 |
| Conv_ Relu_Bridge _2 (3 × 3,1) | Bridge_Block | Pad (same) | 4096 | 4096 |
| Drop_Out | Bridge_Block | 50% | 4096 | 4096 |
| UpConv_ UpRelu_ Bridge_1 (2 × 2,2) | Bridge_Block | Crop (0,0) | 4096 | 2048 |
| *Depth_ Concatenation_ Decode _1 | Decode_Block_ (1–4) | 4096 | [4096,512] | |
| Conv_ Relu_ Decode _1 (3 × 3,1) | Decode_Block_ (1–4) | Pad (same) | [2048,128] | [2048,64] |
| Conv_ Relu_ Decode _2 (3 × 3,1) | Decode_Block_ (1–4) | Pad (same) | [2048,64] | [2048,64] |
| UpConv_ UpRelu_ Decode_1 (2 × 2,2) | Decode_Block_ (1–4) | Crop (0,0) | [2048,64] | [2048,64] |
| *Depth_ Concatenation_ Decode _1 | Decode_Block_5 | 128 | 128 | |
| Conv_ Relu_ Decode _1 (3 × 3,1) | Decode_Block_5 | Pad (same) | 128 | 64 |
| Conv_ Relu_ Decode _2 (3 × 3,1) | Decode_Block_5 | Pad (same) | 64 | 1 |
| Final_Conv_Seg_Out | Decode_Block_5 | 1 | Pixel-Pr |
| Layers (Kernel Size, Stride) | Type | Input | Output |
|---|---|---|---|
| ImageInputLayer | 15 | 15 | |
| Conv_ Relu_BN_1 (7 × 7,2) | Pad (same) | 15 | 128 |
| Average_Pooling (2 × 2) | Pad (0,0,0,0) | 128 | 128 |
| Conv_ Relu_2 (5 × 5,2) | Pad (same) | 128 | 512 |
| Average_Pooling (2 × 2) | Pad (0,0,0,0) | 512 | 512 |
| Conv_ Relu_ 3 (3 × 3,1) | Pad (same) | 512 | 1024 |
| Conv_ Relu_ 4 (3 × 3,1) | Pad (same) | 512 | 2048 |
| Conv_ Relu_ 5 (3 × 3,1) | Pad (same) | 2048 | 4096 |
| Average_Pooling (2 × 2) | Pad (0,0,0,0) | 4096 | 4096 |
| Fully_Connection_Drop_Out | 50% | 4096 | 2048 |
| Fully_Connection_Drop_Out | 50% | 2048 | 512 |
| Fully_Connection | 512 | 4 |
| Component | Initial Eigenvalues | ||
| Total | % of Variance | Cumulative % | |
| 1 | 9,293 | 66.376 | 66.376 |
| 2 | 2.140 | 15.283 | 81.658 |
| 3 | 0.958 | 6.843 | 88.501 |
| 4 | 0.475 | 3.393 | 91.894 |
| 5 | 0.423 | 3.020 | 94.913 |
| 6 | 0.329 | 2.351 | 97.264 |
| 7 | 0.245 | 1.747 | 99.011 |
| 8 | 0.051 | 0.365 | 99.376 |
| 9 | 0.048 | 0.342 | 99.718 |
| 10 | 0.023 | 0.165 | 99.883 |
| 11 | 0.010 | 0.070 | 99.954 |
| 12 | 0.005 | 0.037 | 99.991 |
| 13 | 0.001 | 0.008 | 99.999 |
| 14 | 0.000 | 0.001 | 100.000 |
| Component | Extraction Sums of Squared Loadings | ||
| Total | % of Variance | Cumulative % | |
| 1 | 9.293 | 66.376 | 66.376 |
| 2 | 2.140 | 15.283 | 81.658 |
| 3 | 0.958 | 6.843 | 88.501 |
| 4 | 0.475 | 3.393 | 91.894 |
| 5 | 0.423 | 3.020 | 94.913 |
| (a) Training Setting | |
| Setting | Accuracy (%) |
| Dropout ratio (0.9) | 91.7 |
| Dropout ratio (0.7) | 93.1 |
| Dropout ratio (0.5) | 93.6 |
| Sum fusion ratio (1:1) | 87.6 |
| Sum fusion ratio (1:2) | 91.6 |
| Sum fusion ratio (1:1.5) | 93.8 |
| Pre-trained | 94.2 |
| Pre-trained + finetuning | 96.1 |
| (b) Input Configuration | |
| Configuration | Accuracy (%) |
| Spectrogram stacking (S = 30) | 87.5 |
| Spectrogram stacking (S = 20) | 88.4 |
| Spectrogram stacking (S = 15) | 91.2 |
| Cropped-jittering | 92.5 |
| Calsse-weight | 94.2 |
| (c) Comparison of Models | |
| Method | Accuracy (%) |
| Improved dense trajectories | 78.2 |
| Temporal CNN | 78.3 |
| Spatial CNN | 81.2 |
| Two-stream (SVM fusion) | 95.8 |
| Two-stream (average fusion) | 93.6 |
| Ours (1:1.5 sum) | 96.1 |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Fang, X.; Fang, H.; Feng, Z.; Wang, J.; Zhou, L. Artificial Auditory Perception Pattern Recognition System Based on Spatiotemporal Convolutional Neural Network. Appl. Sci. 2020, 10, 139. https://doi.org/10.3390/app10010139
Fang X, Fang H, Feng Z, Wang J, Zhou L. Artificial Auditory Perception Pattern Recognition System Based on Spatiotemporal Convolutional Neural Network. Applied Sciences. 2020; 10(1):139. https://doi.org/10.3390/app10010139
Chicago/Turabian StyleFang, Xia, Han Fang, Zhan Feng, Jie Wang, and Libin Zhou. 2020. "Artificial Auditory Perception Pattern Recognition System Based on Spatiotemporal Convolutional Neural Network" Applied Sciences 10, no. 1: 139. https://doi.org/10.3390/app10010139