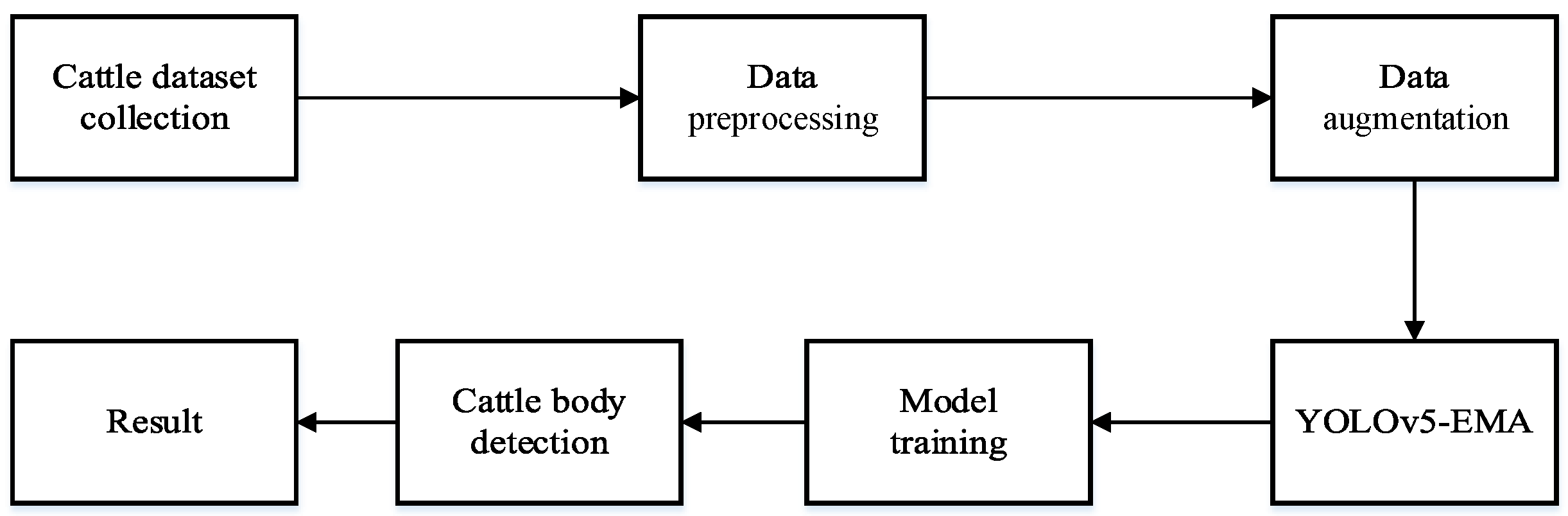
In this section, we will provide a comprehensive presentation of the experimental results and engage in corresponding discussions. The experiments are organized into several parts, encompassing a holistic comparison of different models, individual and specific key body part comparisons across various models, assessments of distinct attention modules, and an evaluation of the EMA attention module’s performance at different positions. In summary, the objective of these evaluations is to ascertain the superiority of YOLOv5-EMA.
Throughout this study, the term “cattle” refers to individual cattle, “head” denotes the head part, and “leg” indicates the leg part.
3.2. Comparison of Different Models on Individual Cattle and Specific Key Body Parts
To assess the effectiveness of the YOLOv5-EMA model across different critical aspects of cattle anatomy, we will analyze its performance on individual cattle, as well as on their legs and heads. The results of these performance analyses for various models can be found in
Table 4.
Table 4 illustrates that the YOLOv5-EMA model exhibits good performance in the target detection of individuals and key body parts in most evaluation indicators. Specifically, YOLOv5-EMA achieved an mAP@0.5 of 94.8% in individual cattle detection, an mAP@0.5 of 94.9% in leg object detection, and an mAP@0.5 of 95.5% in head object detection.
Table 4 indicates that the YOLOv5-EMA model outperforms all other models on the mAP@0.5 metric across various body parts. This result validates the effectiveness of the YOLOv5-EMA model in detecting key cattle body parts.
Additionally, the qualitative comparison results of various models, such as Faster R-CNN, SSD, YOLOv2, YOLOv3, YOLOv4, YOLOv5, and YOLOv5-EMA, are illustrated in
Figure 8. For clarity, we have labeled the eight cattle from left to right in the
Figure 8 as Sample 1 to Sample 8. The detailed description of the visualization of the detection results for each sample is as follows.
Sample1: For Sample1, in terms of individual cattle detection, Faster-RCNN and YOLOv2 failed to detect the target. Although SSD, YOLOv4, YOLOv3, and YOLOv5 detected the target, there were errors in the detection bounding boxes. The best detection performance was achieved by YOLOv5-EMA. Regarding head detection, Faster-RCNN, YOLOv2, YOLOv3, and YOLOv5 did not detect the target. While SSD detected the target, the right ear part was missed within the detection bounding box. YOLOv4 and the YOLOv5-EMA model exhibited the best detection results. For leg detection, due to the cow’s standing angle, one leg was completely obscured, and only three legs were visible in reality. SSD, YOLOv2, YOLOv3, and YOLOv4 failed to detect the target. Faster-RCNN detected two legs, and YOLOv5 detected four legs (with false positives). However, both of these models had errors in their detection bounding boxes. The best leg detection performance was achieved by YOLOv5-EMA.
Sample2: Concerning Sample2, in terms of individual cattle detection, SSD, Faster-RCNN, YOLOv2, YOLOv3, YOLOv4, and YOLOv5 all detected the target; however, there were errors in the detection bounding boxes, particularly with the right side of the body extending beyond the bounding box. The most outstanding detection performance was achieved by YOLOv5-EMA. In head detection, YOLOv2, YOLOv3, and YOLOv4 failed to detect the target. Although Faster-RCNN and YOLOv5 detected the target, the former incorrectly identified a portion of the body as the head, and the latter had the left ear detected outside the bounding box. SSD and the YOLOv5-EMA model exhibited the best head detection performance. For leg detection, Faster-RCNN and YOLOv2 only detected one leg, while SSD, YOLOv3, and YOLOv4 detected two legs. However, all of these models had errors in their detection bounding boxes relative to the true target. YOLOv5 and YOLOv5-EMA demonstrated the most promising leg detection performance.
Sample3: Regarding Sample3, concerning the individual cattle detection, SSD, Faster-RCNN, YOLOv2, YOLOv3, YOLOv4, YOLOv5, and YOLOv5-EMA were all able to detect the target. However, there were slight inaccuracies in their detection bounding boxes. Notably, YOLOv5-EMA exhibited the smallest errors. In head detection, although YOLOv2 and YOLOv4 also detected the target, they mistakenly included environmental elements within the detection boxes. Conversely, the SSD, Faster-RCNN, YOLOv3, YOLOv5, and YOLOv5-EMA models performed well in head detection. As for leg detection, SSD and YOLOv2 failed to detect the target, YOLOv3 detected two legs, YOLOv4 detected three legs, and Faster-RCNN, YOLOv5, and YOLOv5-EMA all detected four legs. Among these, YOLOv5 and YOLOv5-EMA achieved the best leg detection performance, while other models had some errors in their detection bounding boxes compared to the ground truth target.
Sample4: For sample4, regarding the individual cattle detection, YOLOv2 and YOLOv4 failed to detect the target. Although other models successfully detected the target, there were some inaccuracies in their detection bounding boxes. Only YOLOv5-EMA achieved the smallest error in this regard. Regarding head detection, Faster-RCNN, YOLOv2, YOLOv3, and YOLOv4 failed to detect the target. While SSD and YOLOv5 detected the target, their detection boxes did not fully encompass the left cattle horn. Only the YOLOv5-EMA model demonstrated the best head detection performance. As for leg detection, YOLOv2 failed to detect the target, SSD and YOLOv3 detected one leg, YOLOv4 detected two legs, and Faster-RCNN detected three legs. Although YOLOv5 and YOLOv5-EMA successfully detected all four legs, YOLOv5-EMA performed better in detecting the right hind leg.
Sample5: For sample5, in terms of individual cattle detection, SSD failed to detect the target. Although other models successfully identified the target, their detection boxes exhibited some inaccuracies, particularly around the tail and mouth of the cattle. Only YOLOv5-EMA managed to precisely encompass the entire cattle within the detection box. Regarding head detection, all models successfully recognized the target, but Faster-RCNN, YOLOv2, YOLOv3, and YOLOv4 showed some disparities in their detection boxes compared to the actual objects. In terms of leg detection, YOLOv2 detected only one leg, while the other models detected all four legs. However, the targets were not entirely enclosed within the detection boxes for the latter models. Conversely, YOLOv5-EMA accurately enclosed the entire target within the detection box.
Sample6: For cattle labeled as sample6, regarding individual detection, all models succeeded in detecting the cattle; however, disparities in their detection boxes arose, especially around the right hind leg and the cattle’s head. Precisely encompassing the entire target within their detection frames was achieved exclusively by SSD and YOLOv5-EMA. Concerning head detection, given the cattle’s standing angle, none of the models successfully detected the target. Regarding leg detection, YOLOv2 failed to detect any legs, SSD identified one leg, whereas Faster-RCNN, YOLOv3, and YOLOv4 detected three legs. The YOLOv5 and YOLOv5-EMA models were the only ones to accurately enclose the entire target within their detection frames.
Sample7: In the case of cattle labeled as sample7, all models successfully detected the individual target. Nevertheless, there were disparities in their detection boxes compared to the actual target, particularly in the vicinity of the cattle’s mouth. Notably, only the YOLOv5-EMA model demonstrated the least error in this aspect. When it came to head detection, solely the YOLOv5-EMA model achieved a successful target detection. As for leg detection, YOLOv2 identified one leg, whereas SSD, Faster-RCNN, YOLOv2, and YOLOv4 detected three legs. Although the YOLOv3, YOLOv5, and YOLOv5-EMA models recognized four legs, only the YOLOv5 and YOLOv5-EMA models accurately enclosed the entire target within their detection frames. Other models exhibited inaccuracies in their detection boxes relative to the true target.
Sample8: For sample8, Faster-RCNN encountered difficulties in successfully detecting the target, whereas other models managed to identify the target. However, these models exhibited certain inaccuracies in their detection boxes, particularly around the tail and ears of the cattle. Only the YOLOv5-EMA model succeeded in fully encompassing the target within its detection box. In the realm of head detection, Faster-RCNN, YOLOv2, and YOLOv3 struggled to detect the target effectively, whereas YOLOv4 and YOLOv5, while detecting the target, also displayed inaccuracies in their detection boxes, particularly around the ears. It was only SSD and the YOLOv5-EMA model that could accurately enclose the target within their detection boxes. Concerning leg detection, due to the angle at which the cattle were positioned, one leg remained entirely obscured, leaving only three legs visible in reality. Among these scenarios, SSD, Faster-RCNN, and YOLOv2 identified one leg, while YOLOv3 and YOLOv4 identified two legs. Although YOLOv3 detected three legs, it was plagued by inaccuracies in its detection boxes. In contrast, YOLOv5 and the YOLOv5-EMA model successfully identified all three legs with the highest level of precision.
Above all,
Figure 8 illustrates that YOLOv5-EMA surpasses other models by generating more precise predicted bounding boxes, particularly in scenarios involving occlusion and other demanding situations.
In the YOLOv5-EMA model, the EMA attention module first leverages the large receptive fields of parallel sub-networks to gather multi-scale spatial information. It subsequently establishes mutual dependencies between various spatial positions, facilitating cross-space learning. This empowers the YOLOv5-EMA model to consolidate more comprehensive feature information when detecting individual cattle and specific key areas such as the head and legs. As a result, it significantly enhances the model’s feature extraction capabilities. The experimental results confirm that the YOLOv5-EMA model performs well in tasks related to individual detection and the identification of specific key areas, thus validating its good performance compared to other models.
3.3. Evaluating the Effectiveness of the EMA Unit
To assess the effectiveness of the EMA attention module, we compare two models with and without EMA modules, namely YOLOv3 and YOLOv3-EMA; YOLOv5 and YOLOv5-EMA. YOLOv5-EMA is formed by incorporating the EMA attention module into the YOLOv5 backbone. The comparison results are shown in
Table 5 and
Table 6.
Table 5 demonstrates that models incorporating the EMA attention module based on YOLOv3 and YOLOv5 exhibit good performance across all evaluation metrics. Specifically, with YOLOv3-EMA, we achieved a precision of 94.5%, a recall of 88.8%,
F1 score of 91.8%, and an mAP@0.5 of 93.9%. Similarly, YOLOv5-EMA achieved outstanding results.
Table 6 illustrates that models incorporating the EMA attention module based on YOLOv3 and YOLOv5 demonstrate good performance improvements in various key parts across all evaluation metrics. To be more specific, YOLOv3-EMA achieved an mAP@0.5 of 94.2% in individual cattle detection, an mAP@0.5 of 93.3% in leg object detection, and an mAP@0.5 of 94.3% in head object detection. Comparatively, YOLOv5-EMA attained an mAP@0.5 of 94.8% in cattle object detection, which aligns with the performance of YOLOv5 models. YOLOv5-EMA achieved an mAP@0.5 of 94.9% in leg object detection, and an mAP@0.5 of 95.5% in head object detection. There was a significant improvement in the detection mAP for the data related to the legs and head.
Additionally, to provide readers with a more intuitive understanding,
Figure 9 illustrates the qualitative comparison results and the Grad-CAM heatmap of the different models with or without EMA.
Figure 9a shows the predictive results of different models. We have observed the following phenomenon. Individual cattle detection: For individual cattle detection, YOLOv3 faced the following issues, with instances outside the detection boxes. Alternatively, for the YOLOv3-EMA model, two cattle were detected entirely within the detection boxes, and the error in the detection box for the middle cow was significantly reduced. Furthermore, for the YOLOv5 model, there were similar issues in the individual cattle detection, particularly for the middle and rightmost cows, where real targets were sometimes detected outside the detection boxes. In contrast, concerning YOLOv5-EMA model, the rightmost cow was consistently detected entirely within the detection box, and the error for the middle cow was significantly reduced. Cattle head detection: Regarding cattle head detection, YOLOv3 failed to detect any targets initially. Alternatively, for the YOLOv3-EMA model, two cattle heads were successfully detected, leading to a noticeable improvement in detection performance. Similarly, YOLOv5 detected two cattle heads, but the rightmost cattle’s ear part was detected outside the detection box. For the YOLOv5-EMA model, not only were the right two cattle heads detected, but the rightmost cattle head was completely contained within the detection box. Cattle leg detection: In the case of cattle leg detection, YOLOv3 encountered the following issues, include missing one leg on the leftmost cattle, occasionally detecting the legs of the middle and rightmost cows outside the detection boxes, respectively. On the other hand, for YOLOv3-EMA, all the legs of the leftmost cattle were successfully detected, and although one leg of the middle cow was still occasionally missed, the detected legs were accurately positioned within the detection box. In both YOLOv5 and YOLOv5-EMA, all cattle legs were successfully detected; YOLOv5-EMA exhibited more precise detection of the right hind leg of the leftmost cattle.
Further,
Figure 9b–d present the Grad-CAM heatmaps of different models. Individual cattle detection: Concerning the individual cattle detection, YOLOv3 exhibits a poor performance on the rightmost cattle. On the contrary, YOLOv3-EMA brings about a notable shift in detection focus, transitioning from the surroundings to the abdominal region of the cattle for improved accuracy. In addition, while YOLOv5 primarily emphasizes the cattle’s abdomen, YOLOv5-EMA goes a step further by incorporating environmental awareness alongside its focus on the abdomen. Cattle head detection: For cattle head detection, the attention of YOLOv3 appears to be scattered across the head, abdomen, and tail regions. Yet, for YOLOv3-EMA, the detection focus sharply narrows down to the cow’s head region. YOLOv5 exhibits a diminished emphasis on the head of the leftmost cattle, whereas YOLOv5-EMA enhances this attention. Cattle leg detection: When it comes to cattle leg detection, YOLOv3 and YOLOv5 primarily focus their attention on the knee area of the cattle’s legs. However, in contrast, YOLOv3-EMA and YOLOv5-EMA shift their focus towards the entire cattle’s legs.
By incorporating the EMA attention module into the Backbone of YOLO series detection models, we have successfully improved the detection performance of smaller targets such as heads and legs. This enhancement is attributed to the design of the EMA attention module, which establishes a multiscale parallel subnetwork to capture long and short dependencies. Without reducing the number of channels, each parallel subnetwork constructs localized cross-channel interactions. Through this method, the model is able to fuse the feature maps from parallel subnetworks, thereby enhancing the diversity and quality of feature fusion. Upon comprehensive analysis, incorporating the EMA attention module into the backbone can notably enhance the detection performance of the YOLOv3 and YOLOv5 models.
3.5. Comparison of Models with EMA Integrated at Different Positions
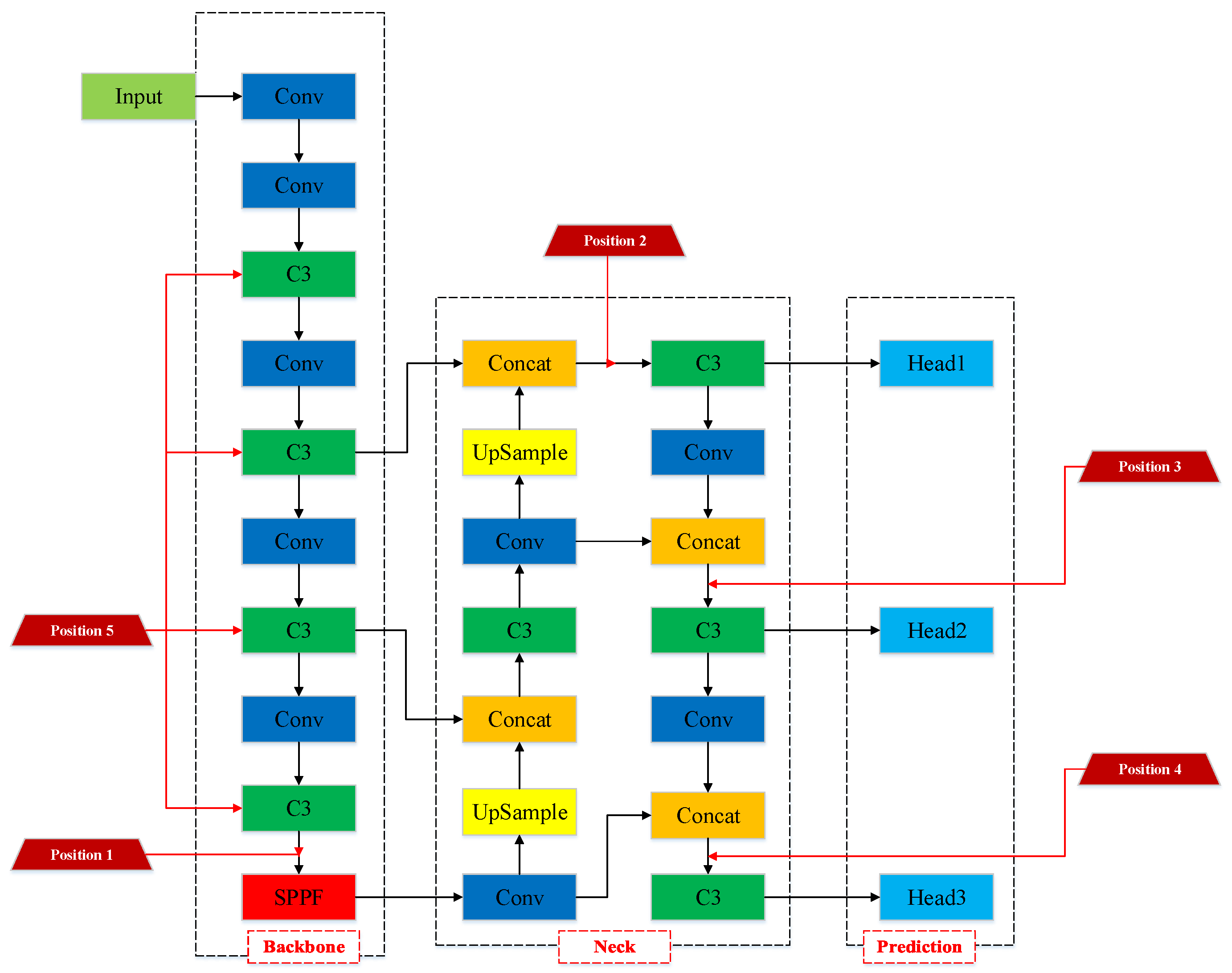
In order to determine the optimal location for integrating the EMA attention module within the Backbone, we conducted a comparative analysis using variant models where attention was positioned at five distinct locations. These positions can be described as follows: Position 1: between the last C3 module and the SPPF module in the backbone; Position2: between the C3 module in the Neck, connected to Head1 detection layer and the concat module; Position 3: between the C3 module in the Neck, connected to Head2 detection layer and the concat module; Position 4: between the C3 module in the Neck, connected to Head3 detection layer and the concat module; and Position 5: inside the C3 module within the Backbone. All of these positions are closely related to the feature extraction locations crucial for object detection. The specific placement of the EMA attention module is visually depicted in
Figure 11. The experimental results involve a comparison of detection performance for individual and local key points, assessed using the mAP@0.5 metric, as presented in
Table 8.
According to
Table 8, it is evident that the model with the EMA attention component added at position 5 (the C3 module of the Backbone) achieves the highest mAP@0.5 values for individual, head, and leg object detection. Furthermore, it exhibits the most significant improvement in leg and head detection performance. While adding the EMA attention mechanism at other positions also substantially enhances individual object detection, it falls short in improving leg and head detection compared to the model with EMA attention at position 5. Specifically, the model that adds the EMA module at position 5 achieved an mAP@0.5 of 95.1% in overall object detection, an mAP@0.5 of 94.9% in leg object detection, and an mAP@0.5 of 95.5% in head object detection. These results confirm that Position 5 is the optimal location for integrating the EMA module.
Furthermore, to provide readers with a clearer and more intuitive understanding,
Figure 12 presents the qualitative detection results and Grad-CAM heatmaps for models with the EMA attention component integrated at different positions.
In
Figure 12a, it becomes clear that models incorporating the EMA attention mechanism from Position 1 to Position 5 can proficiently detect all three cattle during individual detection. However, when narrowing our focus to head detection, only the model with EMA integrated at Position 5 successfully identifies the head of the middle cattle. Similarly, in leg detection, only the model with EMA integrated at Position 5 accurately discerns the left hind leg of the middle cattle.
From
Figure 12b–d, it is evident that, in individual cattle detection, models incorporating EMA at Positions 1, 2, 3, and 4 exhibit reduced attention towards the middle and rightmost cattle. Only the model with EMA at position 5 effectively concentrates its detection focus on the abdominal region of all three cattle. In terms of cattle leg detection, models with EMA at Positions 1, 2, and 3 primarily focus on the knee area. In contrast, models with EMA at positions 4 and 5 expand their attention area to cover the entire leg of the cattle. Concerning cattle head detection, models with EMA at positions 1, 2, 3, and 4 exhibit weaker attention towards the head of the middle cattle. Only the model with EMA at Position 5 achieves the best attention focus on the head of the middle cattle.
In summary, integrating the EMA attention mechanism at position 5 yields the most optimal detection performance. This provides compelling evidence for the effectiveness of incorporating EMA attention into the C3 module of the YOLOv5 Backbone. The primary function of the C3 module in the Backbone is to increase the network depth and receptive field, thereby enhancing feature extraction capabilities. In the experiment, we achieved improved robustness by incorporating the EMA attention mechanism within the C3 module. This allowed for cross-spatial information aggregation along different spatial dimensions, further enhancing feature representational capacity. This approach notably improved the detection performance, particularly in cases involving small targets and occlusions.

















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}