

Health Status Classification for Cows Using Machine Learning and Data Management on AWS Cloud

Abstract
:Simple Summary
Abstract
1. Introduction
- Data variability—Cow health data can be highly variable due to factors such as age, breed, environment, and disease history [7,19]. The resistance threshold of each cow varies depending on the phase of its life cycle. This makes it difficult to establish clear and consistent patterns that accurately reflect the health status of the animal. It is crucial to consider the individual cow’s traits.
- Complex interactions between health factors—The health of livestock is influenced by a variety of interconnected factors [4,6,7], such as genetics, feeding type and frequency, environmental conditions, and local infestations. This makes it challenging to isolate the impact of individual factors on overall health status.
- Subjectivity in observations—Assessment of animal health is often based on subjective observations made by farmers or veterinarians, which often leads to biases and inconsistencies in the data.
- Lack of data—Automated data collection equipment may not always be readily available on farms, which is why some farmers still record their data in notebooks.
- Reliable and secure equipment—Building trust in automated systems takes time and requires consistent proof of their reliability. In order to reduce human intervention in animal husbandry and support monitoring processes, it is crucial to rely on existing equipment and ensure that data are transmitted securely and in a timely manner.
2. Materials and Methods
2.1. Data Collection
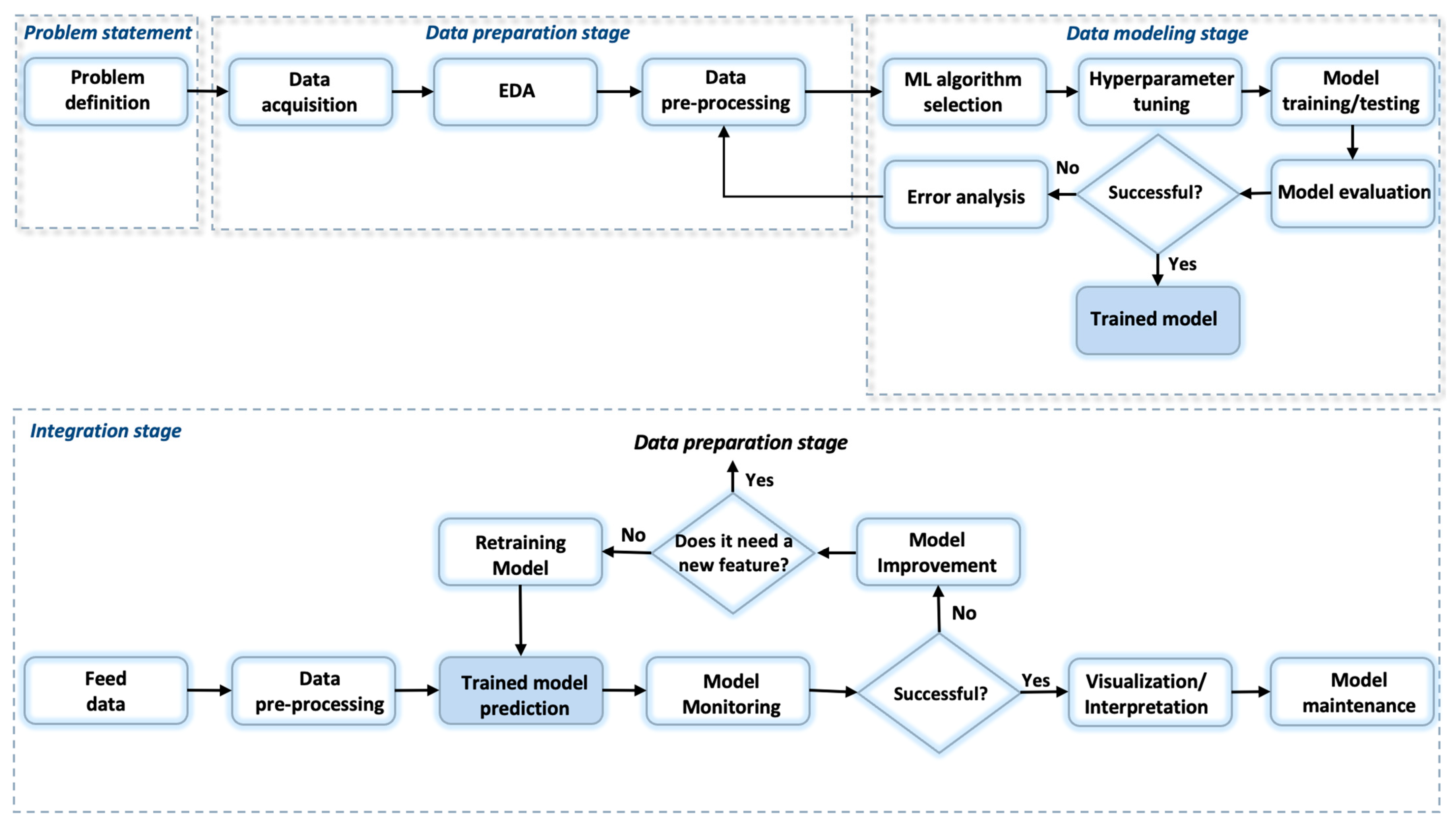
2.2. Workflow
- 1.
- First stage: Problem statement
- Problem definition/hypothesis statement.
- 2.
- Second stage: Data preparation
- Data acquisition.
- Exploratory data analysis (EDA).
- Data pre-processing.
- 3.
- Third stage: Data modeling
- Selection of proper machine learning algorithm.
- Hyperparameter tuning.
- Model training and testing.
- Model evaluation.
- 4.
- Fourth stage: Integration layer
- Feed data.
- Data pre-processing.
- Prediction results.
- Model monitoring.
- Model validation.
- Data visualization and interpretation.
- Model maintenance.
2.2.1. Problem Statement
2.2.2. Data Preparation
Data Acquisition
Exploratory Data Analysis
Data Pre-Processing
- Cast objects to a specified data type. This is the process of converting the variables (values in one column) into the most appropriate data type. Performing this operation allows grouping the categorical values and checking the distribution, as well as deriving statistical measures from the numerical values.
- Process missing values. In the context of IoT data, null, Na, Nan, and NaT values are particularly problematic because they indicate a sensor outage, loss of data in communication, or equipment problem. Null values are removed from this study because they are strongly suspected to be problematic rather than natural. This ensures that the resulting models are built on complete and accurate data, thereby improving the overall quality of the analysis.
- Process outliers. Outliers are observations that lie at an abnormal distance from other values in a random sample from a population. Both missing values and outliers in IoT data need to be further investigated to determine whether they are a random phenomenon or if there is any cyclicality of their occurrence. For this study, the interquartile range (IQR) is calculated, and the handled outliers were treated by the clipping function [20] instead of being deleted because the data contain important information that could show clear signs of the presence of diseases, which directly affect the classification of the animal’s health status.
- Bucketizing (binning). Bucketization of continuous features is a technique used after the data analysis is performed or after ML error analysis. Simplifying complex data by reducing the number of unique values makes the data easier to understand. It also improves the performance of models such as decision trees and random forests.
- Balancing data. Data are unbalanced when there is a significant difference in the number of instances between categorical classes of data. This can cause ML models to prefer the majority class and incorrectly classify instances from the minority class. In this study, there are three equally important classes that need to be correctly classified. To address the imbalance, the synthetic minority over-sampling technique (SMOTE) [21] was utilized in the minority class. This technique synthesizes new examples to balance the number of instances across all classes.
- Categorical encoding. Label encoding is a technique used to convert categorical data into numerical. The label-encoding technique used in this study is one-hot encoding. It involves converting categorical variables into a set of binary columns, where each column represents a unique category in the original variable. The column for a particular category is set to 1 if that category is present in the observation and 0 if it is not present.
- Data standardization. IoT devices gather various sensor data with varying measurement types and scales. Data standardization scales each input variable separately by subtracting the mean and dividing by the standard deviation to shift the distribution to have a mean of zero and a standard deviation of one. The type of standardization used in this study is standard scaler because it preserves the variance of the data.
2.2.3. Modeling
Selection of Proper Machine Learning Algorithm
Hyperparameter Tuning
Model Evaluation
Error Analysis
Data and Model Integration
- AWS Glue—Serverless data integration service. It consists of crawlers, jobs, triggers, and a data catalogue. It is responsible for data extraction from multiple sources, data preparation, and loading them into the data lake [25].
- Data lake—A data lake is an architectural approach that allows storing data in a centralized repository. It consists of simple storage service (S3) buckets. S3 is a petabyte-scale object store which provides virtually unlimited scalability to store any type of data [26].
3. Results
3.1. Univariate and Bivariate Exploratory Data Analysis
3.1.1. Univariate Analysis—Numerical Features
3.1.2. Univariate Analysis—Category Features
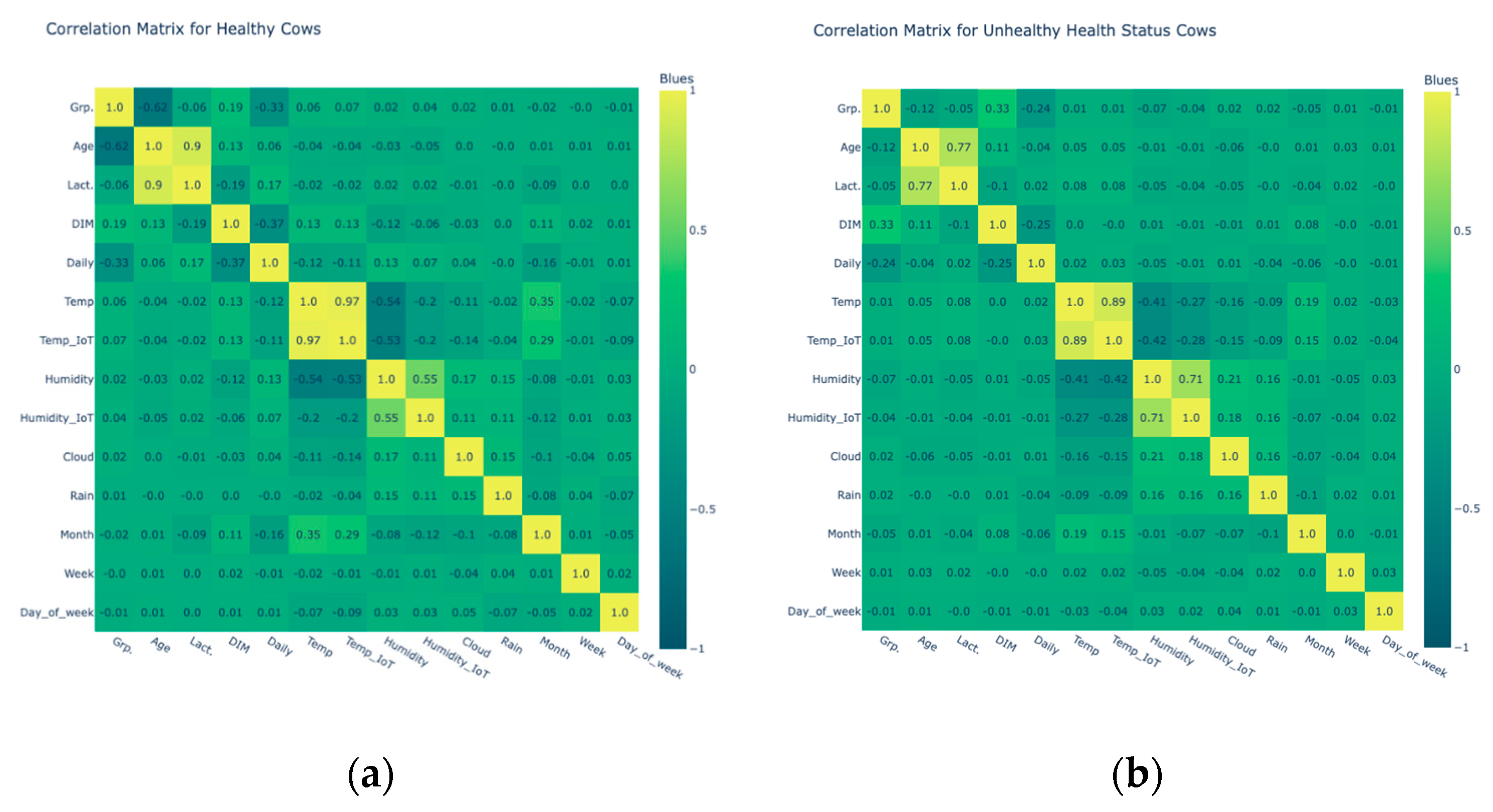
3.1.3. Bivariate Analysis
- The variables “Temp.” and “Temp_IoT” have a strong positive correlation with r = 0.97.
- The variables “Age” and “Lact.”, “Month” and “Temp.”, “Humidity” and “Humidity_IoT”, “Temp_IoT” and “Month” have a positive correlation with values of, respectively, r = 0.54, 0.34, 0.56, and 0.28.
- The variables “DIM” and “Daily Milk”, “Temp.” and “Humidity”, “Temp.” and “Cloud”, and “Temp_IoT” and “Humidity_IoT” have a negative correlation with values of, respectively, r = −0.41, −0.57, −0.18, and −0.27.
3.2. Data Pre-Processing
Balancing
3.3. Data Modeling
3.4. Data and Model Integration
4. Discussion
- S3 buckets are available only for chosen AWS regions. There is no max bucket size or limit to the number of objects in it. The allowed operations in the bucket are “get”, “put”, and “list”.
- Glue: the total number of jobs, crawlers, and triggers within a workflow is up to 100.
- Step functions place quotas on the sizes of certain state machine parameters, such as the number of API actions during a certain time or the number of state machines that one can define (max request size limit of 256 KB).
- SageMaker. For an endpoint, the maximum size of the input data per invocation is limited to 6 MB. This value cannot be adjusted. For batch transform, the maximum size of the input data per invocation is 100 MB. This value cannot be adjusted.
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Appendix A

Appendix B
- The variables “Lact.”, “DIM”, “Daily Milk”, and “Month” show highly statistically significant correlations with “Age”. These correlations have low p-values, indicating strong evidence against the null hypothesis of no correlation. These variables are likely to have a meaningful relationship with “Age” and further investigation into these relationships may provide valuable insights.
- The variables “Age”, “Lact.”, “DIM”, “Temp.”, “Humidity”, “Temp_IoT”, “Humidity_IoT”, and “Month” show highly statistically significant correlations with “Daily Milk”.
- The variables “Age”, “DIM”, “Daily Milk”, “Humidity”, “Humidity_IoT”, “Temp.”, and “Month” show highly statistically significant correlations with “Temp_IoT”.
- The variables “Temp.”, “Temp_IoT”, “Rain”, “Humidity”, “Daily Milk”, and “Month” show highly statistically significant correlations with “Humidity_IoT”.
- The variables “Age”, “Lact.”, “Daily Milk”, and “Month” show highly significant correlations with “DIM”. This indicates strong evidence against the null hypothesis.
- Not statistically significant (p > 0.05):
- The variables “Week” and “Rain” do not show statistically significant relationships with “Daily Milk”. Their p-values (0.6642 and 0.6388, respectively) are above the conventional threshold of 0.05. These variables may not have a strong relationship.
- The variables “Temp.”, “Temp_IoT”, “Humidity”, “Humidity_IoT”, “Cloud”, “Week”, and “Rain” do not show statistically significant relationships with “Lact.”. Their p-values (0.9443, 0.6513, 0.8474, 0.7173, 0.3028, 0.1861, and 0.7448, respectively) are above the conventional threshold of 0.05. These variables may not have a strong relationship.
- The variables “Age”, “Lact.”, “Daily Milk”, and “Week” do not show statistically significant relationships with “Rain”. Their p-values (0.0565, 0.7448, 0.6388, and 0.3620, respectively) are above the conventional threshold of 0.05. These variables may not have a strong relationship.
Appendix C

- -
- “Age” and “Lact.”. There is a high positive correlation of 0.899804. This indicates that older cows tend to have higher number of lactations.
- -
- “DIM” has a weak positive correlation with “Grp.” and “Age”, but a negative correlation was noted with “Lact.” and “Daily Milk” (−0.187216 and −0.369011).
- -
- “Temp.” has a very high positive correlation with “Temp_IoT” at 0.969074. This suggests that these two temperature measurements are highly dependent on each other.
- -
- “Temp.” and “Temp_IoT” have strong negative correlations with humidity, which is expected since temperature and humidity are often inversely related.
- -
- “Humidity” and “Humidity_IoT” are positively correlated at 0.546932, suggesting that they move in the same direction, but perhaps not as consistently as temperature measurements. Also, “Humidity” is positively correlated with cloudiness and rain, suggesting that higher humidity values are associated with more cloudiness and precipitation.
- -
- For time items (month, week, day_of_week), correlations appear weak, suggesting that month, week, or day of the week may not have a strong linear relationship with other variables in this dataset.
- -
- “Grp.” and “Age” have a correlation of −0.619031. As the “Grp.” value increases, “Age” tends to decrease. This may mean that in certain groups the cows tend to be younger.
- -
- “Age” and “Lact.” have a strong positive correlation of 0.773718. Older cows have a higher number of lactations.
- -
- “Temp.” and “Temp_IoT” are also positively correlated at 0.891846. However, the strength of the correlation was slightly lower than that in healthy cows.
- -
- “Grp.” and “DIM” have a positive correlation of 0.327591. In unhealthy cows, as the group increases, so do the days in milk. This relationship is different from that observed in healthy cows.
- -
- “DIM” and “Daily Milk” show a weak negative correlation (−0.245074). Similar to healthy cows, cows with more days in milk may produce less daily milk.
- -
- “Humidity” and “Temp.” have a negative correlation (−0.406108). As seen in healthy cows, there is a similar trend where humidity decreases as temperature increases, but the strength of this relationship is weaker in unhealthy cows.
References
- Farm to Fork Strategy. Available online: https://food.ec.europa.eu/horizontal-topics/farm-fork-strategy_en (accessed on 10 March 2023).
- Animal Welfare. Available online: https://www.efsa.europa.eu/en/topics/topic/animal-welfare (accessed on 10 March 2023).
- Nayeri, S.; Sargolzaei, M.; Tulpan, D. A review of traditional and machine learning methods applied to animal breeding. Anim. Health Res. Rev. 2019, 20, 31–46. [Google Scholar] [CrossRef] [PubMed]
- Li, Y.; Shu, H.; Bindelle, J.; Xu, B.; Zhang, W.; Jin, Z.; Guo, L.; Wang, W. Classification and Analysis of Multiple Cattle Unitary Behaviors and Movements Based on Machine Learning Methods. Animals 2022, 12, 1060. [Google Scholar] [CrossRef] [PubMed]
- Shinde, V.; Jha, S.; Taral, A.; Salgaonkar, K.; Salgaonkar, S. IoT Based Cattle Health Monitoring System. ICIATE 2017, 5, 1–4. [Google Scholar]
- Unold, O.; Nikodem, M.; Piasecki, M.; Szyc, K.; Maciejewski, H.; Bawiec, M.; Dobrowolski, P.; Zdunek, M. IoT-Based Cow Health Monitoring System. Comput. Sci. ICCS 2020, 12141, 344–356. [Google Scholar] [CrossRef]
- Dittrich, I.; Gertz, M.; Krieter, J. Alterations in sick dairy cows’ daily behavioural patterns. Heliyon 2019, 5, e02902. [Google Scholar] [CrossRef]
- Cappai, M.G.; Picciau, M.; Nieddu, G.; Bitti, M.P.L.; Pinna, W. Long term performance of RFID technology in the large scale identification of small ruminants through electronic ceramic boluses: Implications for animal welfare and regulation compliance. Small Rumin. Res. 2014, 117, 169–175. [Google Scholar] [CrossRef]
- Shine, P.; Murphy, M.D. Over 20 Years of Machine Learning Applications on Dairy Farms: A Comprehensive Mapping Study. Sensors 2022, 22, 52. [Google Scholar] [CrossRef]
- Shaik Mazhar, S.A.; Akila, D. Machine Learning and Sensor Roles for Improving Livestock Farming Using Big Data. In Cyber Technologies and Emerging Sciences; Maurya, S., Peddoju, S.K., Ahmad, B., Chihi, I., Eds.; Lecture Notes in Networks and Systems; Springer: Singapore, 2023; Volume 467. [Google Scholar] [CrossRef]
- Becker, C.A.; Aghalari, A.; Marufuzzaman, M.; Stone, A.E. Predicting dairy cattle heat stress using machine learning techniques. J. Dairy Sci. 2021, 104, 501–524. [Google Scholar] [CrossRef]
- Bovo, M.; Agrusti, M.; Benni, S.; Torreggiani, D.; Tassinari, P. Random Forest Modelling of Milk Yield of Dairy Cows under Heat Stress Conditions. Animals 2021, 11, 1305. [Google Scholar] [CrossRef]
- Chen, G.; Li, C.; Guo, Y.; Shu, H.; Cao, Z.; Xu, B. Recognition of Cattle’s Feeding Behaviors Using Noseband Pressure Sensor with Machine Learning. Front. Vet. Sci. 2022, 9, 822621. [Google Scholar] [CrossRef]
- Bao, J.; Xie, Q. Artificial intelligence in animal farming: A systematic literature review. J. Clean. Prod. 2022, 331, 129956. [Google Scholar] [CrossRef]
- Leliveld, L.M.C.; Provolo, G. A Review of Welfare Indicators of Indoor-Housed Dairy Cow as a Basis for Integrated Automatic Welfare Assessment Systems. Animals 2020, 10, 1430. [Google Scholar] [CrossRef] [PubMed]
- Li, Q.F.; Li, J.W.; Ma, W.H.; Gao, R.H.; Yu, L.G.; Ding, L.Y.; Yu, Q.Y. Research Progress of Intelligent Sensing Technology for Diagnosis of Livestock and Poultry Diseases. Sci. Agric. Sin. 2021, 54, 2445–2463. [Google Scholar]
- Sun, D.; Webb, L.; van der Tol, P.P.J.; van Reenen, K. A Systematic Review of Automatic Health Monitoring in Calves: Glimpsing the Future from Current Practice. Front. Vet. Sci. 2021, 8, 761468. [Google Scholar] [CrossRef] [PubMed]
- Fuentes, S.; Viejo, C.G.; Tongson, E.; Dunshea, F.R.; Dac, H.H.; Lipovetzky, N. Animal biometric assessment using non-invasive computer vision and machine learning are good predictors of dairy cows age and welfare: The future of automated veterinary support systems. J. Agric. Food Res. 2022, 10, 100388. [Google Scholar] [CrossRef]
- Fuentes, S.; Gonzalez Viejo, C.; Tongson, E.; Lipovetzky, N.; Dunshea, F.R. Biometric Physiological Responses from Dairy Cows Measured by Visible Remote Sensing Are Good Predictors of Milk Productivity and Quality through Artificial Intelligence. Sensors 2021, 21, 6844. [Google Scholar] [CrossRef]
- For Outliers’ Treatment: Clipping, Winsorizing or Removing? Available online: https://datascience.stackexchange.com/questions/65802/for-outliers-treatment-clipping-winsorizing-or-removing (accessed on 8 February 2023).
- Chawla, N.; Bowyer, K.; Hall, L.; Kegelmeyer, W. SMOTE: Synthetic Minority Over-sampling Technique. J. Artif. Intell. Res. 2002, 16, 321–357. [Google Scholar] [CrossRef]
- Batta, M. Machine learning algorithms—A Review. Int. J. Sci. Res. 2020, 9, 381–386. [Google Scholar] [CrossRef]
- Logunova, I. K-Nearest Neighbors Algorithm for ML. Available online: https://serokell.io/blog/knn-algorithm-in-ml (accessed on 8 February 2023).
- Dineva, K.; Atanasova, T. Design of Scalable IoT Architecture Based on AWS for Smart Livestock. Animals 2021, 11, 2697. [Google Scholar] [CrossRef]
- AWS Glue: Developer Guide, AWS Whitepaper. 2023. Available online: https://docs.aws.amazon.com/pdfs/glue/latest/dg/glue-dg.pdf#trigger-job (accessed on 10 March 2023).
- Strong Best Practices for Data and Analytics Applications: AWS Whitepaper. 2021. Available online: https://docs.aws.amazon.com/pdfs/whitepapers/latest/building-data-lakes/building-data-lakes.pdf#amazon-s3-data-lake-storage-platform (accessed on 10 March 2023).
- AWS Step Functions: Developer Guide, AWS Whitepaper. 2023. Available online: https://docs.aws.amazon.com/pdfs/step-functions/latest/dg/step-functions-dg.pdf#welcome (accessed on 10 March 2023).
- AWS Advanced User Guide. AMS Advanced Concepts and Procedures, AWS Whitepaper. 2023. Available online: https://docs.aws.amazon.com/pdfs/managedservices/latest/userguide/ams-ug.pdf#sagemaker, (accessed on 23 March 2023).
- King, A.; Eckersley, R. Chapter 2—Descriptive Statistics II: Bivariate and Multivariate Statistics. In Statistics for Biomedical Engineers and Scientists, How to Visualize and Analyze Data; Academic Press: Cambridge, MA, USA; Elsevier Ltd.: Amsterdam, The Netherlands, 2019; pp. 23–56. [Google Scholar] [CrossRef]
- Uenishi, S.; Oishi, K.; Kojima, T.; Kitajima, K.; Yasunaka, Y.; Sakai, K.; Sonoda, Y.; Kumagai, H.; Hirooka, H. A novel accel-erometry approach combining information on classified behaviors and quantified physical activity for assessing health status of cattle: A preliminary study. Appl. Anim. Behav. Sci. 2021, 235, 105220. [Google Scholar] [CrossRef]
- Yang, G.; Xu, X.; Song, L.; Zhang, Q.; Duan, Y.; Song, H. Automated measurement of dairy cows body size via 3D point cloud data analysis. Comput. Electron. Agric. 2022, 200, 107218. [Google Scholar] [CrossRef]
- Nielsen, P.; Fontana, I.; Sloth, K.H.; Guarino, M.; Blokhuis, H. Validation and comparison of 2 commercially available activity loggers. J. Dairy Sci. 2018, 101, 5449–5453. [Google Scholar] [CrossRef] [PubMed]
- Rutten, C.J.; Velthuis, A.; Steeneveld, W.; Hogeveen, H. Invited review: Sensors to support health management on dairy farms. J. Dairy Sci. 2013, 96, 1928–1952. [Google Scholar] [CrossRef] [PubMed]
- Adersh, S.; Shyam, S.; Sreehari, S.; Akhil, A.G. Health Monitoring System for Dairy Cows. J. Emerg. Technol. Innov. Res. 2021, 8, 95–99. Available online: https://www.jetir.org/papers/JETIRET06019.pdf (accessed on 8 February 2023).
- Awasthi, A.; Awasthi, A.; Riordan, D.; Walsh, J. Non-Invasive Sensor Technology for the Development of a Dairy Cattle Health Monitoring System. Computers 2016, 5, 23. [Google Scholar] [CrossRef]
- Dittrich, I.; Gertz, M.; Maassen-Francke, B.; Krudewig, K.-H.; Junge, W.; Krieter, J. Estimating risk probabilities for sickness from behavioural patterns to identify health challenges in dairy cows with multivariate cumulative sum control charts. Animal 2022, 16, 100601. [Google Scholar] [CrossRef]
- Kleanthous, N.; Hussain, A.; Mason, A.; Sneddon, J.; Shaw, A.; Fergus, P.; Chalmers, C.; Al-Jumeily, D. Machine Learning Techniques for Classification of Livestock Behavior. In Neural Information Processing, Proceedings of the 25th International Conference, ICONIP, Siem Reap, Cambodia, 13–16 December 2018; Cheng, L., Leung, A., Ozawa, S., Eds.; Lecture Notes in Computer Science; Springer: Cham, Switzerland, 2018; Volume 11304. [Google Scholar] [CrossRef]
- Herbut, P.; Angrecka, S.; Godyń, D.; Hoffmann, G. The physiological and productivity effects of heat stress in cattle—A review. Ann. Anim. Sci. 2019, 19, 579–593. [Google Scholar] [CrossRef]
- Cox, B.; Gasparrini, A.; Catry, B.; Delcloo, A.; Bijnens, E.; Vangronsveld, J.; Nawrot, T. Mortality related to cold and heat. What do we learn from dairy cattle? Environ. Res. 2016, 149, 231–238. [Google Scholar] [CrossRef]
- Dac, H.H.; Gonzalez Viejo, C.; Lipovetzky, N.; Tongson, E.; Dunshea, F.R.; Fuentes, S. Livestock Identification Using Deep Learning for Traceability. Sensors 2022, 22, 8256. [Google Scholar] [CrossRef]
- LokeshBabu, D.S.; Jeyakumar, S.; Vasant, P.V.; Sathiyabarathi, M.; Manimaran, A.; Kumaresan, A.; Pushpadass, H.A.; Sivaram, M.; Ramesha, K.P.; Kataktalware, M.A. Monitoring foot surface temperature using infrared thermal imaging for assessment of hoof health status in cattle: A review. J. Therm. Biol. 2018, 78, 10–21. [Google Scholar] [CrossRef]
- Congdon, J.V.; Hosseini, M.; Gading, E.F.; Masousi, M.; Franke, M.; MacDonald, S.E. The Future of Artificial Intelligence in Monitoring Animal Identification, Health, and Behaviour. Animals 2022, 12, 1711. [Google Scholar] [CrossRef] [PubMed]
- Hogan, M.C.; Norton, J.N.; Reynolds, R.P. Environmental Factors: Macroenvironment Versus Microenvironment. In Management of Animal Care and Use Programs in Research, Education, and Testing, 2nd ed.; Weichbrod, R.H., Thompson, G.A.H., Norton, J.N., Eds.; CRC Press: Boca Raton, FL, USA; Taylor & Francis: Boca Raton, FL, USA, 2018; Chapter 20. Available online: https://www.ncbi.nlm.nih.gov/books/NBK500431/ (accessed on 10 March 2023).
- Ji, B.; Banhazi, T.; Phillips, C.J.C.; Wang, C.; Li, B. A machine learning framework to predict the next month’s daily milk yield, milk composition and milking frequency for cows in a robotic dairy farm. Biosyst. Eng. 2022, 216, 186–197. [Google Scholar] [CrossRef]
- Imrich, I.; Toman, R.; Pšenková, M.; Mlyneková, E.; Kanka, T.; Mlynek, J.; Pontešová, B. Effect of temperature and relative humidity on the milk production of dairy cows. Sci. Technol. Innov. 2021, 13, 22–27. [Google Scholar] [CrossRef]
- Bohmanova, J.; Misztal, I.; Cole, J.B. Temperature-Humidity Indices as Indicators of Milk Production Losses due to Heat Stress. J. Dairy Sci. 2007, 90, 1947–1956. [Google Scholar] [CrossRef] [PubMed]
- Toghdory, A.; Ghoorchi, T.; Asadi, M.; Bokharaeian, M.; Najafi, M.; Ghassemi Nejad, J. Effects of Environmental Temperature and Humidity on Milk Composition, Microbial Load, and Somatic Cells in Milk of Holstein Dairy Cows in the Northeast Regions of Iran. Animals 2022, 12, 2484. [Google Scholar] [CrossRef] [PubMed]
- Hot and Bothered Cows Get £1.24 Million Study, 27 April 2023. Available online: https://www.reading.ac.uk/news/2023/Research-News/Hot-and-bothered-cows-get-million-pound-study (accessed on 30 May 2023).
- Habeeb, A.A.; Gad, A.E.; Atta, M.A. Temperature-Humidity Indices as Indicators to Heat Stress of Climatic Conditions with Relation to Production and Reproduction of Farm Animals. Int. J. Biotechnol. Recent. Adv. 2018, 1, 35–50. [Google Scholar] [CrossRef]
- Ouellet, V.; Toledo, I.M.; Dado-Senn, B.; Dahl, G.E.; Laporta, J. Critical Temperature-Humidity Index Thresholds for Dry Cows in a Subtropical Climate. Front. Anim. Sci. 2021, 2, 706636. [Google Scholar] [CrossRef]
- Wang, J.; Li, J.; Wang, F.; Xiao, J.; Wang, Y.; Yang, H.; Li, S.; Cao, Z. Heat stress on calves and heifers: A review. J. Anim. Sci. Biotechnol. 2020, 11, 79. [Google Scholar] [CrossRef]
- Neves, S.F.; Silva, M.C.F.; Miranda, J.M.; Stilwell, G.; Cortez, P.P. Predictive Models of Dairy Cow Thermal State: A Review from a Technological Perspective. Vet. Sci. 2022, 9, 416. [Google Scholar] [CrossRef]
- Singh, D.; Singh, R.; Gehlot, A.; Akram, S.V.; Priyadarshi, N.; Twala, B. An Imperative Role of Digitalization in Monitoring Cattle Health for Sustainability. Electronics 2022, 11, 2702. [Google Scholar] [CrossRef]
- Shabani, I.; Biba, T.; Çiço, B. Design of a Cattle-Health-Monitoring System Using Microservices and IoT Devices. Computers 2022, 11, 79. [Google Scholar] [CrossRef]
- Artificial Intelligence in the Agri-Food Sector, Applications, Risks and Impacts, March 2023. Available online: https://www.europarl.europa.eu/RegData/etudes/STUD/2023/734711/EPRS_STU(2023)734711_EN.pdf (accessed on 12 May 2023).
- Bobbo, T.; Biffani, S.; Taccioli, C.; Penasa, M.; Cassandro, M. Comparison of machine learning methods to predict udder health status based on somatic cell counts in dairy cows. Sci. Rep. 2021, 11, 13642. [Google Scholar] [CrossRef]
- Vázquez Diosdado, J.A.; Barker, Z.E.; Hodges, H.R.; Amory, J.R.; Croft, D.P.; Bell, N.J.; Edward, A. Classification of behaviour in housed dđairy cows using an accelerometer-based activity monitoring system. Anim. Biotelemetry 2015, 3, 15. [Google Scholar] [CrossRef]
- Bacci di Capaci, R.; Scali, C. A Cloud-Based Monitoring System for Performance Assessment of Industrial Plants. Ind. Eng. Chem. Res. 2020, 59, 2341–2352. [Google Scholar] [CrossRef]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Feature | Feature Description |
|---|---|
| Cow | Registration number of the cow (ID) |
| Age | Age of the cow in days |
| Gender | Gender of the cow |
| Lact. | Lactation—breastfeeding period |
| DIM | The number of days the average milking cow in the herd is milking from calving day |
| Daily Milk | Average daily amount of milk |
| Grp. | The group in which the cow is located |
| Temp. | Temperature of cow’s microclimate |
| Humidity Temp_IoT Humidity_IoT | Humidity of cow’s microclimate Temperature of cow’s macroclimate Humidity of cow’s macroclimate |
| Wind_dir | Wind direction outside |
| Cloud | Degree of cloudiness outside |
| Rain | Amount of precipitation (liters per square meter) |
| Data_time | Timestamp of measurements |
| Healthy | The health status of the animal data |
| ML Algorithm | Algorithm Description |
|---|---|
| K-nearest neighbors (KNN) | It is a non-parametric algorithm. The rationale of the K-nearest neighbors’ algorithm is that each sample can be represented by K-nearest neighbors. The distance between the test and training samples can calculate the classification for the samples. This distance usually uses “Euclidean distance” or “Manhattan distance” [23]. According to the distance order, the test sample is classified as the closest class to it. To measure the sampling distance on the same scale, all features are normalized and then the K-value selection is obtained by cross-validation. |
| Gaussian naïve Bayes (GNB) | This is a probabilistic algorithm based on the Bayes theorem, where one of the hypotheses is the assumption of strong independence between features. It supports continuous-valued features and models each one as conforming to a Gaussian distribution. |
| Decision tree classifier (DTC) | It is a non-parametric algorithm where the data are continuously divided into smaller parts until it reaches a class or is truncated by a hyperparameter such as max_depth. It has a hierarchical tree structure, which consists of a root node (represents a feature), decision nodes which represent the logic statements used to split or divide the data into two parts, and leaf nodes (represent the outcome). |
| XGBoost (XGB) | It is a boosting ensemble algorithm that implements the gradient-boosting decision tree algorithm. It trains individual decision trees sequentially, with each tree trying to classify the errors of the previous tree. The model combines the classifications of all the individual trees to make a final classification. |
| Random forest classifier (RFC) | This ensemble algorithm is a combination of multiple decision trees. Each tree is built independently using bootstrap resampling with replacement replicates of the features and samples, which creates independence in each dataset used to create the next tree in the forest allowing the random forest model to give a robust classification. The classification is made by taking the majority vote on the classifications made by each decision tree. This improves classification accuracy and generalizability while avoiding overfitting of the model... |
| Statistical Measures | Grp. | Age | Lact. | DIM | Daily Milk | Temp. | Temp_IoT | Humidity | Humidity_IoT | Cloudiness | Rain |
|---|---|---|---|---|---|---|---|---|---|---|---|
| Number of records | 53,155 | 53,155 | 40,859 | 40,859 | 37,408 | 53,155 | 53,057 | 53,155 | 53,057 | 53,155 | 53,155 |
| Mean | 6.266 | 1315.875 | 2.38 | 163.27 | 33.11 | 11.05 | 15.84 | 79.42 | 75.90 | 5.911 | 1.953 |
| std | 6.903 | 641.805 | 1.236 | 145.57 | 13.11 | 9.48 | 7.41 | 11.24 | 12.44 | 4.293 | 5.49 |
| Min | 1 | 0 | 1 | 0 | 0.2 | −12 | 2 | 45 | 40 | 0 | 0 |
| 25% | 1 | 792 | 1 | 61 | 24.6 | 4.2 | 9 | 74 | 68 | 1 | 0 |
| 50% | 3 | 1353 | 2 | 123 | 33.7 | 10.8 | 15.8 | 83 | 80 | 8 | 0 |
| 75% | 12 | 1641 | 3 | 239 | 42.4 | 17.8 | 22 | 88 | 86 | 10 | 0.30 |
| Max | 21 | 3293 | 7 | 1013 | 77.4 | 42.0 | 35.2 | 94 | 90 | 10 | 43 |
| Machine Learning Algorithm | Hyperparameters | Recall | Precision | Accuracy |
|---|---|---|---|---|
| K-nearest neighbor classifier (KNN) | k-neighbors = 11 weights = uniform | |||
| p = 2 | 0.726 | 0.719 | 0.816 | |
| n_jobs = −1 | ||||
| Gaussian naïve Bayes (GNB) | var_smoothing = 0.035111 | 0.528 | 0.532 | 0.620 |
| Decision tree classifier (DTC) | max_features = 10 | 0.632 | 0.740 | 0.828 |
| min_samples_leaf = 10 | ||||
| min_samples_split = 3 | ||||
| criterion = gini | ||||
| n_jobs = −1 | ||||
| XGBoost (XGB) | colsample_bytree = 0.75 | 0.609 | 0.70 | 0.784 |
| early_stopping_rounds = 10 | ||||
| learning_rate = 0.1 | ||||
| max_depth = 2 | ||||
| min_child_weight = 1 | ||||
| subsample = 0.75 | ||||
| n_estimators = 100 | ||||
| n_jobs = −1 | ||||
| Random forest classifier (RFC) | bootstrap = False | 0.954 | 0.97 | 0.954 |
| criterion = entropy | ||||
| max_features = 3 | ||||
| min_samples_leaf = 10 | ||||
| n_estimators = 300 | ||||
| verbose = 1 |
| Class | Precision | Recall | F1-Score |
|---|---|---|---|
| 0 | 0.98 | 0.95 | 0.96 |
| 1 | 0.95 | 0.99 | 0.97 |
| 2 | 0.96 | 0.95 | 0.95 |
| Accuracy | Test set 0.9598 Training set 0.9620 | ||
| Number of records | 56,382 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Dineva, K.; Atanasova, T. Health Status Classification for Cows Using Machine Learning and Data Management on AWS Cloud. Animals 2023, 13, 3254. https://doi.org/10.3390/ani13203254
Dineva K, Atanasova T. Health Status Classification for Cows Using Machine Learning and Data Management on AWS Cloud. Animals. 2023; 13(20):3254. https://doi.org/10.3390/ani13203254
Chicago/Turabian StyleDineva, Kristina, and Tatiana Atanasova. 2023. "Health Status Classification for Cows Using Machine Learning and Data Management on AWS Cloud" Animals 13, no. 20: 3254. https://doi.org/10.3390/ani13203254