1. Introduction
Farm intelligence has become an inevitable choice with the development of livestock farming in the direction of large-scale farming and precise management. This requires precise detection of individual livestock in the breeding process. Identifying and managing single individual poultry is crucial for many subsequent breeding and conservation tasks, such as tracking growth stages, detecting body condition score (BCS) [
1,
2], and adjusting breeding programs. The lack of monitoring of individual growth stages can lead to poor healthcare, misjudgment of heat detection, and delayed reproduction, resulting in lower production, reduced health, and even animal loss. In this study, we research the face detection of chickens.
The growth stages of a chicken can be classified by its day-old age [
3];
Table 1 exhibits the details.
Particular characters of chicken are typically used as the metrics for determining the living stages. Specifically, the following: (1) Beak. The beak of a chick is sharp and thin, as is the beak angle. Adult chickens forage outdoors for a long time; after eight months, their beaks are thick and short, the end becomes hard and smooth, and the two corners of the mouth are wide and rough. (2) Nasal tumor. The nasal tumors of chicks are light red, and those of two-year-old or older chickens are light pink, large, soft, and moist. The nasal tumors of four- or five-year-old chickens are pink and rough. When judging empirically, the characteristics of the toes and feathers are also referred to. (3) Toes. Chicks have soft, tiny scales on their feet, which are bright red. The feet of adult chickens are stout and dark red, with thick, hard scales. Their toenails are hard and curved. (4) Feathers. Chicken wings can indicate the child chickens’ month-age [
4]. Nevertheless, these visual methods can merely classify chickens roughly, instead of accurately determining their exact age and growth stages.
At present, traditional farms generally rely on manual records and judgments for the differentiation of chick growth stages, which can cause a large amount of labor input. Moreover, the workforce is, to some extent, based on personal practical experience, which is also generally inefficient and error-prone. In addition, some farms will use tags, spraying, and other invasive physical methods to mark the chick, so as to facilitate the subsequent record and identification management. This kind of invasive marking method will likely cause the chick to be sick, pecking tags, infected with diseases, and showing stereotyped behavior. This is not in line with animal protectionism. Noninvasive biometric methods have significant advantages over traditional methods, both in terms of cost and security. In the field of livestock individual identification and growth stage detection, increasingly more researchers are using deep learning methods. Deep-learning-based individual detection techniques have higher accuracy and robustness than traditional individual detection techniques. Moreover, detection by capturing the images of livestock does not cause harm to them. Therefore, this paper adopted a noninvasive biometric detection method and studied deep-learning-based chick face detection.
The performance of deep-learning-based methods has been optimized and improved in recent years, enhancing the implementation ability of noninvasive livestock detection management. This has been confirmed by several researchers’ projects and research results. Liang Han et al. [
5] introduced a livestock detection dataset in aerial images and presented a detection algorithm to count the amount of livestock on the grassland. They first adopted a modified U-net to segment aerial images, and then obtained regions of interest (ROIs). Afterward, a Google Inception-v4 net was used to classify each ROI so as to detect objects precisely. Liyao Yao et al. [
6] presented a cow face detection framework incorporating Faster R-CNN (region-based convolutional neural network) and PANSNet-5 models for detecting and recognizing cow faces. This combination successfully enhanced the recognition capability, reaching 98.3% detection accuracy and 94.1% recognition accuracy. The experiment was based on their released large-scale cow detection–recognition dataset. To track the birds’ migration movement, an automated bird-counting model [
7] was built to count the number of birds in captured digital images. The RPN (Region Proposal Network) was used to select anchors with the highest likelihood of containing regions of interest. Then, the highest ones would be fed into the subsequent Fast R-CNN. The Fast R-CNN detector ultimately returns the binary label for birds’ existence and their bounding box coordinates.
Although these years have witnessed the boom of computer vision implementations in livestock detection, the applications in the field of this paper’s research are still limited—the computer-vision-based detection and artificial intelligence management for chickens are rarely seen, and concerning technologies and research data are comparatively not up to date, though chickens are one of the most common and traditional poultry. Among few pieces of research about the classification of the growth stages of chicks, one outstanding achievement is that Yufei Ren et al. [
3] presented an attention encoder to find chicken face features. They implemented this structure in different mainstream CNN (convolution neural networks) to search for the most excellent network for this task. The ResNet-50 based on the attention encoder achieved 95.2% accuracy as the best. Nonetheless, the chicken face images in their dataset are with simple and ideal white background, and the chicken day ages are merely from 1 to 32 days. The situations of the subsequent days are unknown. Another excellent design is from Hung-Wei Liu and Hao-Ting Lin et al. [
8], who designed a dead chicken removal system that could detect the dead chicken and sweep it with the robotic arm. They adopted a YOLOv4 deep learning algorithm to implement the detection, with the Precision reaching 95.24%, accuracy achieving 97.5%, and Recall reaching 100%. Moreover, current detection models are not ideal for individual recognition and day-old age detection, because chicken face detection tasks contain multiple objects under complicated scenarios and objects’ occlusion. Chicken faces are smaller than other livestock, and day-old age individuals have inconspicuous differences. These traits require the detection model to be capable of processing high-density objects with complex backgrounds, and the accuracy of detecting tiny features must be advanced. Some detection methods even require external devices to capture information about the livestock.
Hence, given the research contributions of the previous scientists and the lack of extant methods, this paper proposes an advanced chicken face detection network based on GAN (generative adversarial network) and MAE (masked autoencoder) modules, for detecting chicken faces from diverse growth stages.
The contributions of this paper are the following:
Using GAN and MAE models to augment the small volume of data in the dataset.
We used multiple data enhancement methods to balance the dataset.
We added feature map outcomes to three feature map results, changing the downsampling of the feature map outputs to fourfold, which provides more minor object features for subsequent feature fusion.
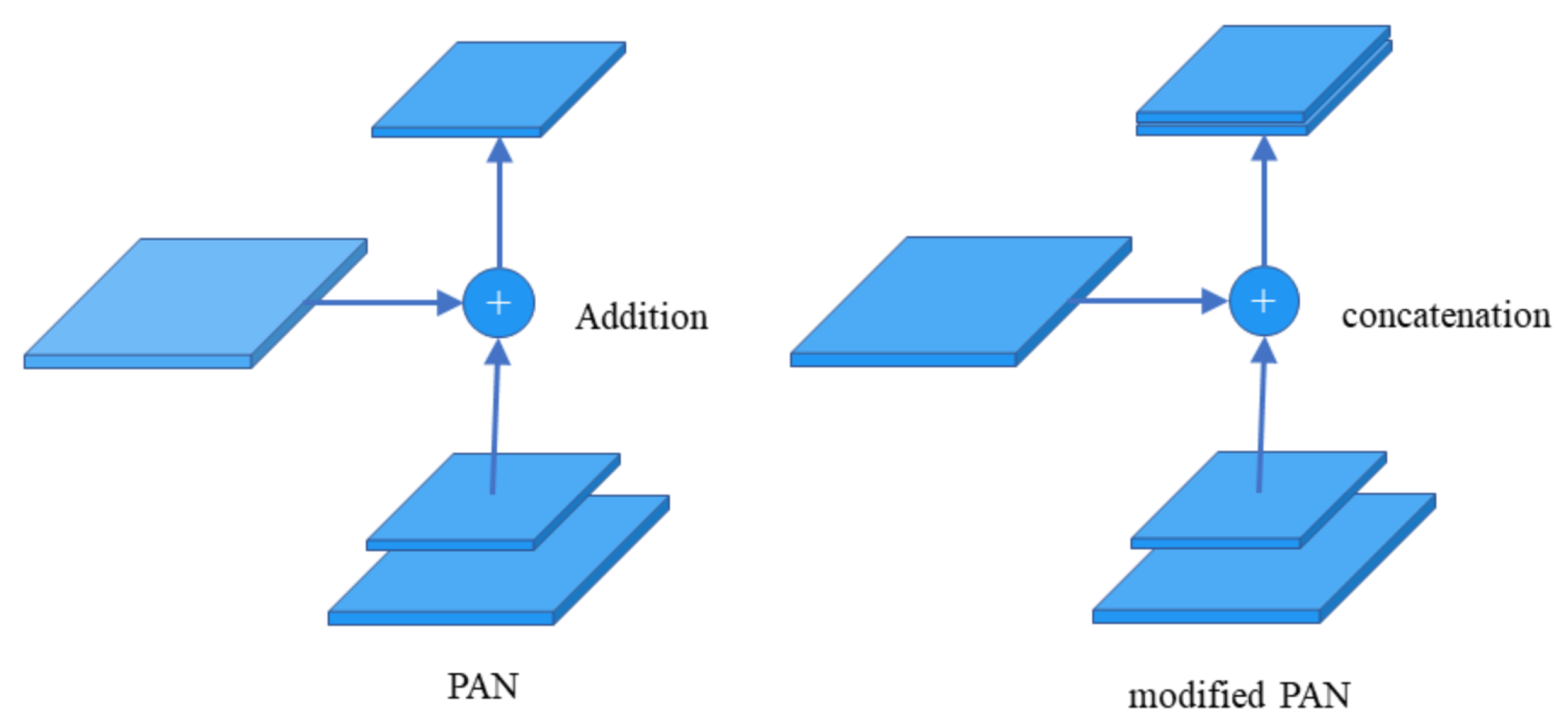
We opted for the idea of dense connectivity, improving the feature fusion module to reuse features. The YOLO head classifier responsible for object detection can combine features from different levels of feature layers to obtain better object detection and classification results.
We applied our model equipped with cameras and edge servers for a specific chicken coop.
Using growth stage detection technology in livestock farms can improve the accuracy and efficiency of supervision, increasing productivity and profitability. At the same time, it reduces farming costs while following a humane and ethical approach to animal protection.
The subsequent sections of this paper are as follows:
Section 2 introduces the development of object detection.
Section 3 demonstrates the dataset that we used and the preprocessing methods and illustrates all the methods that we employed.
Section 4 provides the validation results by conducting ablation experiments and introduces how to apply this method in practical production.
Section 5 summarizes the whole work.
2. Related Work
The core problem of machine vision is to parse information from images that computers can understand [
9,
10,
11]. Due to data volume accumulation, computational power advances, and their powerful representation capabilities [
12], deep learning models have become a popular research field in machine vision.
Image analysis has three primary categories [
13,
14,
15], depending on the requirements of subsequent tasks:
Classification.
The classification task structures an image into a certain category of information, describing the image with a predefined category or instance identification code. This task is the most straightforward and primary image understanding task, and is the first one where deep learning models have broken out and achieved large-scale applications. Among all the excellent classification methods, ImageNet [
16,
17] is the most authoritative set of reviews. The annual ImageNet Large-Scale Visual Recognition Challenge (ILSVRC) has spawned many excellent deep network structures [
18,
19], which provide the foundation for other tasks. In the application domain, face recognition [
20,
21], scenes, etc., can be classified as classification tasks.
Object detection [
22,
23].
The classification task focuses on the overall image and describes the whole picture’s content. Detection [
24,
25,
26], however, focuses on a particular target and requires both class and location information for this target [
27]. In contrast to classification, object detection provides an understanding of the image’s foreground and background. We need to divide the object of interest from the background and determine the object’s description (category and location). Object detection is a fundamental task in computer vision. Image segmentation, object tracking, and keypoint detection rely on object detection.
Image segmentation [
28,
29].
Image segmentation includes semantic segmentation, instance segmentation, and panoptic segmentation [
30,
31]. Semantic segmentation [
32,
33] segments all objects in an image (including the background), but cannot distinguish between different individuals for the same category. Instance segmentation [
34] is an extension of the detection task, which needs to describe the object’s contour (more detailed than the detection frame). Panoptic segmentation [
35] is based on instance segmentation and can segment the background objects. Segmentation is a pixel-level description of an image that gives significance to each pixel class (instance) and is suitable for scenarios that require a high level of understanding, such as the segmentation of roads and non-roads for unmanned vehicles.
This paper researched chick face detection, which belongs to the mid-level processing of image analysis problems. Zhengxia Zou et al. reviewed the evolution of object detection over a 20-year period [
36], including milestone detectors, datasets, metrics, and the development of significant techniques. They divided the 20-year development process of object detection into two phases, bounded by 2014: the traditional object detection period and the deep-learning-based object detection period.
Traditional object detection has high false positives for template matching, poor algorithm adaptability, practical problems that can be solved, and colossal development and maintenance costs. Its development is limited by two factors: no practical method of image representation and limited computational resources. Therefore, most of the traditional object detection algorithms are based on handcrafted features, and various acceleration techniques must be designed to reduce the dependence on computational resources. The main milestones in this cold weapon era are the following: (1) Object detection based on sliding windows [
37]. This local image evaluation method detects a specific object in an image, such as birds. However, this method involves classifying and discriminating thousands of windows of different positions and sizes one by one, which consumes a lot of computational resources and makes it tricky to achieve real-time detection. (2) VJ Detector (Viola–Jones) in 2001 [
38]. This is the first real-time image-based face detector based on sliding windows. This detector represents the image as integral and can quickly compute Haar-like features. (3) HOG (histogram of oriented gradients) detector in 2005 [
39]. The gradient features of the whole image are extracted, and the HOG features are formed by extracting and dividing the detection window and splicing the histogram features to finally achieve human detection. (4) DPM (deformable part model) [
40] is a component-based detection feature and algorithm derived from HOG, which extracts more discriminative features on the basis of HOG features.
After 2014, called the “era of the beauty of GPU (graphics processing unit)”, deep-learning-based detectors are divided into CNN-based two-stage detectors (R-CNN, SPP-NET, Fast R-CNN, Faster R-CNN) and CNN-based one-stage detectors (YOLO, SSD). Until today, researchers have designed network structures, optimized methods, and loss functions to improve the effectiveness of model detection. The year 2014 saw the introduction of R-CNN [
41], the pioneer of deep learning in object detection, proposing classification and localization based on candidate frames. However, R-CNN severely affects the quality of CNN extracted features when unifying the region proposal size, and also spends a lot of computation time and storage space when extracting the region proposal features. Therefore, the SPP-NET (spatial pyramid pooling network) was introduced to extract the features of the whole image at one time, which can handle region proposals of arbitrary size, improving the quality of the features extracted by CNN and enhancing the robustness. In 2015, Ross et al. proposed Fast R-CNN [
42], which optimized the loss function and changed the pooling strategy to accelerate CNN’s training and prediction significantly. However, its extraction of region proposals took a longer time. In the same year, Faster R-CNN [
43] was introduced, which used RPN (Region Proposal Network) [
43] to replace the selective search region proposal extraction method (which had been used in the previous R-CNN family of networks) and greatly improved the detection speed. In 2016, the “cost-effective choice” YOLO (You Only Look Once) [
44] was proposed, and SSD (single-shot multiBox detector) was introduced. In 2017, FPNs (feature pyramid networks) [
45] and Mask R-CNN [
46] were proposed. In 2018, IoU-Net [
47] was proposed, and in 2019, GIoU-Net [
48] was proposed. So far, object detection methods have been refined, improved, and broken through.
Although object detection and deep learning methods are changing rapidly, it does not mean that the age-old methods are not relevant today. The most typical example is AlexNet [
18], which emerged in 2012. Alex used two GPUs for parallel computing, and proposed many preprocessing methods for image data augmentation. He also introduced the first ReLu nonlinear activation function, Dropout, and LRN (local response normalization) techniques, which significantly improved the training rate of the network and reduced the error rate, opening the way for later generations to explore object detection methods. The foundation of the method and ideas was laid.
5. Conclusions
Refined and intelligent management of livestock farming is becoming increasingly important in agricultural production. The facial recognition of individual poultry according to day age is the basis for carrying out downstream production tasks. Considering the requirement and traditional difficulties in poultry detection, we proposed a deep network model that can accurately detect chicken faces with the following innovations:
We augmented the limited-scale dataset by employing the GAN and MAE models. Compared with the baseline method without data augmentation, our GAN-MAE augmentation method increased the F1 and mAP from 0.87 and 0.75 to 0.91 and 0.84, respectively.
We solved the imbalance between different classes of the dataset using multiple data enhancement methods.
We added feature map outputs to three feature map outputs of this algorithm, thus changing the eightfold downsampling of the feature map outputs to fourfold downsampling, which provides more small object features for subsequent feature fusion.
The feature fusion module was improved based on the idea of dense connectivity to achieve feature reuse. The YOLO head classifier responsible for object detection can combine features from different levels of feature layers to obtain better object detection and classification results.
Our model achieved the most exceptional performance in the contrast experiments, with 0.91 F1, 0.84 mAP, and 37 FPS, which are well over those of the two-stage models and EfficientDet.
We deployed our camera and edge server for a specific chicken coop, and applied our model.
Although our research obtained the aforementioned breakthroughs and achievements, there are still some limitations. The day-old age interval of our dataset is 30 days, which is not refined enough. We just identified the face of chickens from different growth stages, but the specific day-age, behavior, and health condition cannot be classified. Our model gained the most promising F1 and mAP outcomes; however, the inference speed is inferior to YOLOv3 and YOLOv5. These interesting research areas are worthwhile to be further explored, and they will also be the future work of the authors in this paper.


 ,
, 












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}