Topic Modeling and Characterization of Hate Speech against Immigrants on Twitter around the Emergence of a Far-Right Party in Spain




Abstract
:1. Introduction
2. Theoretical Framework
2.1. Defining Hate Speech
RQ1: What are the features of hate speech toward immigrants around the emergence of a far-right party, such as Vox?
RQ2: What are the underlying topics of hate speech toward immigrants around the emergence of a far-right party, such as Vox?
3. Method
3.1. Sample and Procedure
3.2. Measures
3.2.1. Hate Speech towards Immigrants
3.2.2. Types of Hate Speech against Immigrants
3.2.3. Frequency Distribution
3.2.4. Topic Modeling (Latent Dirichlet Allocation—LDA)
4. Results
4.1. Distribution of the Sample and Sub-Sample
4.2. Features of Hate Speech
- -
- Foul language: Dishonest or obscene words are used. As previously mentioned, the presence of this type of language in a message does not necessarily mean that there is hate against immigrants, and it is the co-occurrence—the proximity between the two terms—that determines the presence of hate. For example, when the obscene word is applied to the collective of immigrants, the presence of hate speech is more common, as in: “Putos inmigrantes. La gente que quieren que se mueran de hambre. esos merecen la pena. Viva VOX.”2
- -
- Incitement to violence: This type of message invites others to conduct violent acts against a specific person or collective. This dimension is linked to physical and psychological threats (see next point), but it is based on an abstract call rather than a direct threat. In the next example, we can see how the emitter calls for the expulsion of immigrants in a violent way using despising terms in a threatening way: “A día de hoy solo Vox, pide acabar con la inmigración ilegal. Españoles hay que votarlos para limpiar España de estos salvajes. Y los que no los voteis, disfrutar de lo votado.”3
- -
- Physical or psychological threat: These messages go against the physical and psychological integrity of the victims (Miró 2016), and, unlike the previous group, the threat is more immediate and leads more directly to the completion of the violent act. It must be highlighted that violence might not be the end but rather a means, as in the following example: “A ver si sale vox y echamos a todas estas putas ratas de el pais.”4
- -
- Humiliation and contempt: Underestimation of a person or collective and rejection of them based on their inherent condition. For Schmidt and Wiegand (2017), this dimension is sometimes given by the context, and so it might be hard to detect. See, for example: “Pues a mí me han convencido los de #vox, por fin gente como #shakira, #Messi, #Griezmann, #benzema … Dejarán de quitarle el trabajo a nuestros hijos españoles! A su casa!! #VOXalNatural #Politica #EleccionesYa.”5
- -
- Distasteful expressions: Eschatological, vulgar, or disgusting expressions are used. This type of expressions can vary depending the geographical location of the emitter and the addition of a negative charge to the message. In the next example, it can be seen how these expressions highlight the hate against a specific group of immigrants: “Fuera los Moros!, … tomar por culo su religion! a si de claro!, … que se vaya la coño norte de Africa!”6
- -
- Irony: This is the hardest to detect as the hate is expressed in a subtler way. In the next example, we can see how sarcasm is used to criticize and to say the opposite to the literal meaning of the words: “Pero los crucifijos fuera de las escuelas… y @vox_es son muy malos. Los siguientes hombres de paz van a ser los del ISIS… no?”7
- -
- False or doubtful information: These messages include unconfirmed generalizations, stereotypes, or false affirmations regarding a collective. In the context of hate speech content, it is common that these messages attempt to create social alarm regarding something that attacks the internal culture or beliefs with external impositions. For example: “Exacto. Sin embargo, nos están destruyendo nuestras creencias, nuestras tradiciones e imponiéndonos islamismo radical y “culturas” ajenas a nosotros y que faltan el respeto.”8
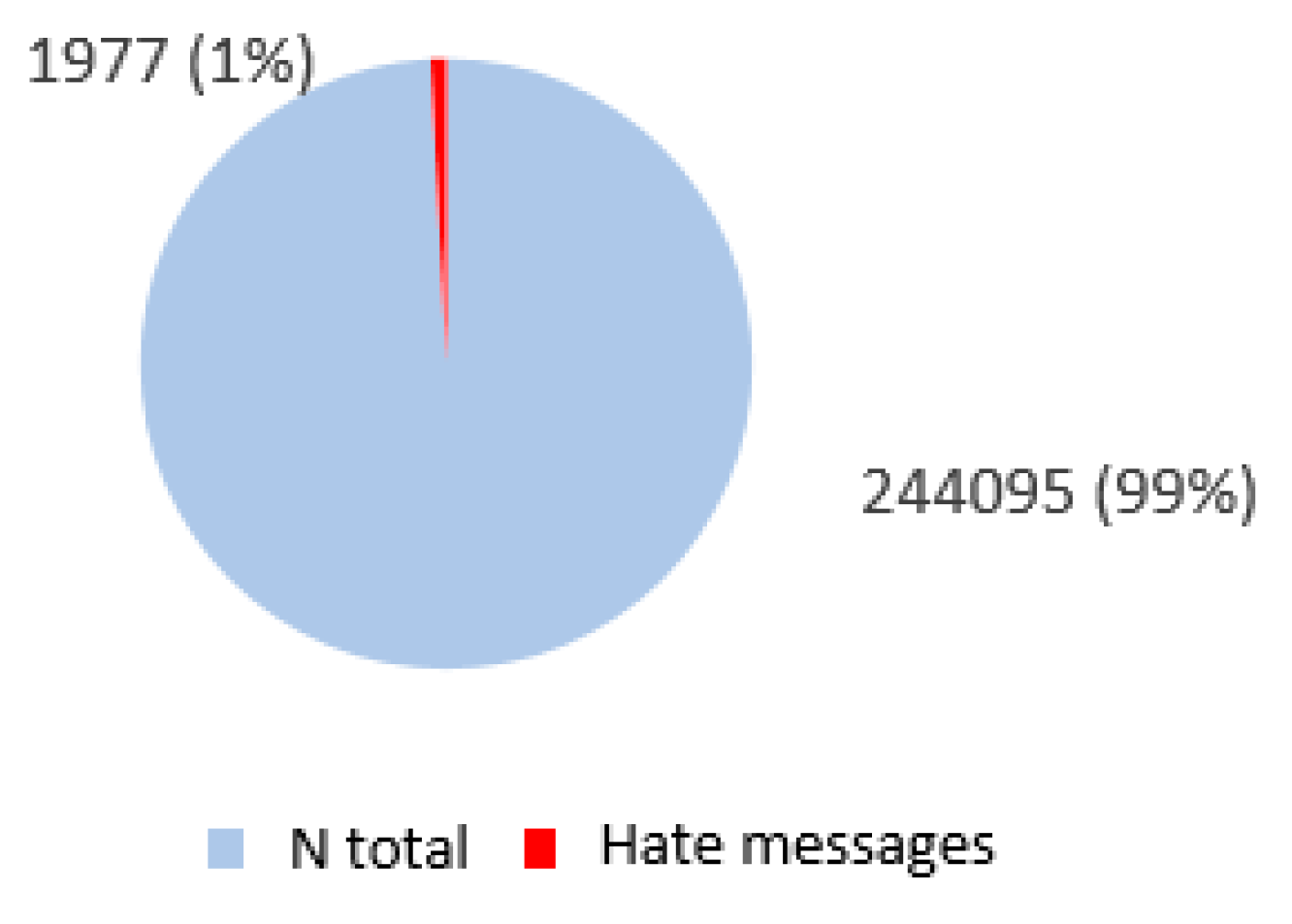
4.3. Frequency Distribution
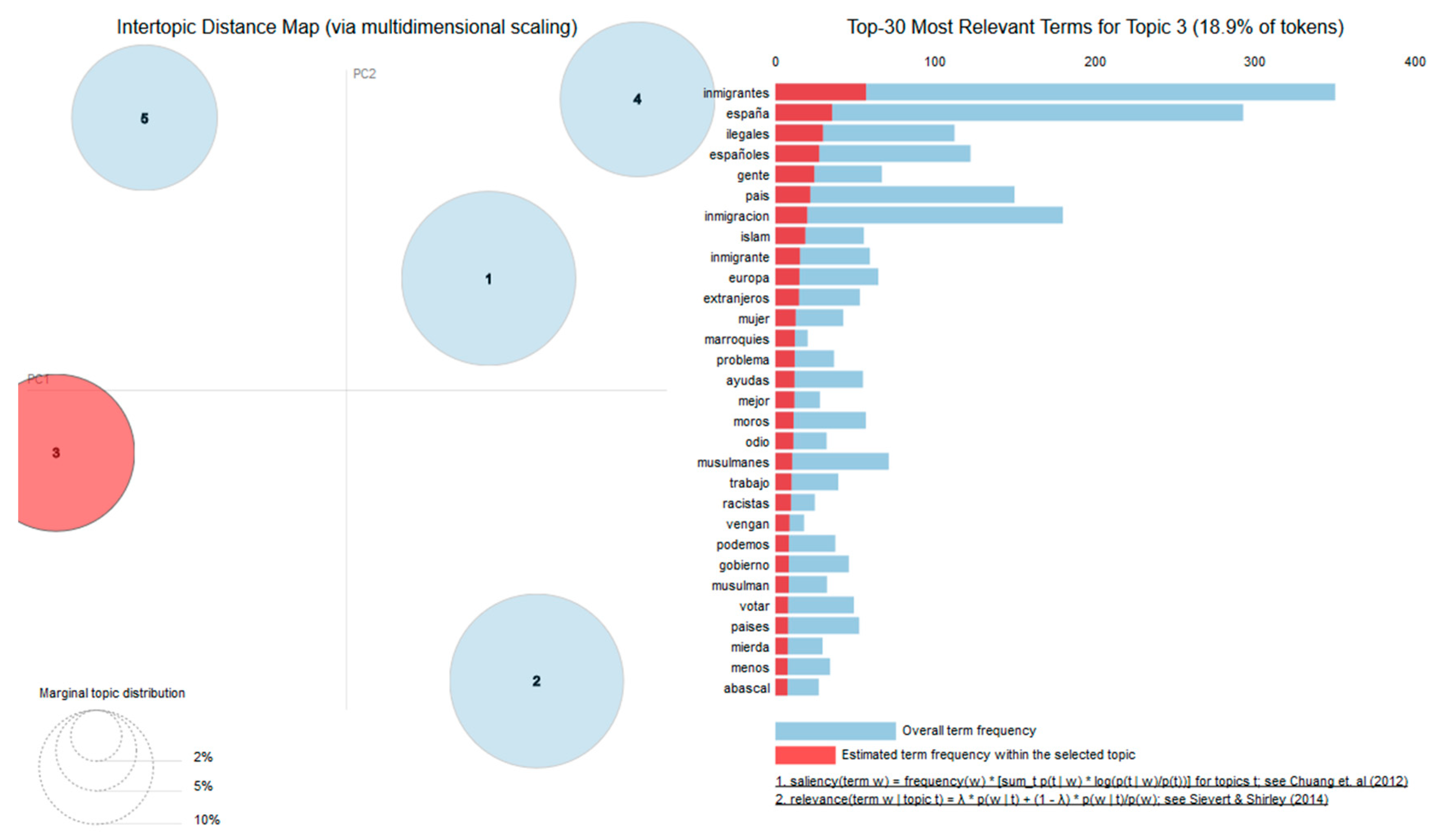
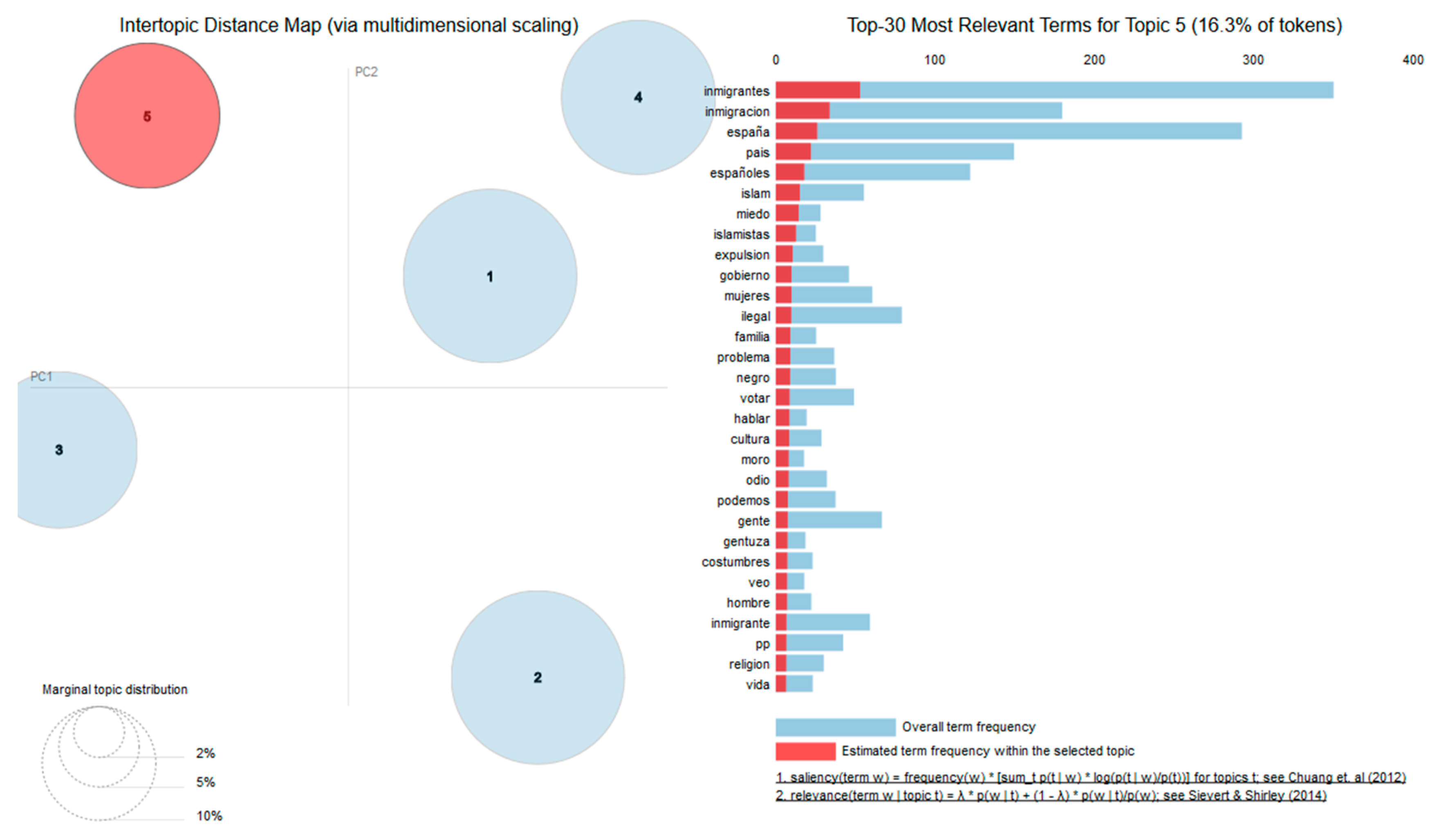
4.4. Topic Modeling
5. Discussion of Results and Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Alcácer, Rafael. 2015. Víctimas y disidentes. El “discurso del odio” en EE.UU. y Europa. Revista Española De Derecho Constitucional 35: 45–86. [Google Scholar]
- Alonso, Sonia, and Cristóbal Rovira Kaltwasser. 2015. Spain: No country for the populist radical right? South European Society and Politics 20: 21–45. [Google Scholar] [CrossRef]
- Arango, Joaquín Ramón Mahía, David Moya, and Elena Sánchez-Montijano. 2019. Inmigración, Elecciones Y Comportamiento Político. Anuario CIDOB De La Inmigración. Edited by En Joaquín Arango, Ramón Mahía, David Moya and Elena Sánchez-Montijano. Barcelona: CIDOB, pp. 16–30. [Google Scholar] [CrossRef]
- Arcila-Calderón, Carlos, David Blanco-Herrero, and María Belén Valdez-Apolo. 2020. Rechazo y discurso de odio en Twitter: Análisis de contenido de los tuits sobre migrantes y refugiados en español. Revista Española de Investigaciones Sociológicas (REIS) 172: 21–40. [Google Scholar] [CrossRef]
- Awan, Imran. 2014. Islamophobia on Twitter: A Typology of Online Hate against Muslims on Social Media. Policy & Internet 6: 133–50. [Google Scholar] [CrossRef]
- Awan, Imran, and Irene Zempi. 2015. The affinity between online and offline anti-Muslim hate crime: Dynamics and impacts. Aggression and Violent Behaviour 27: 1–8. [Google Scholar] [CrossRef] [Green Version]
- Bartlett, Jamie, Jeremy Reffin, Noelle Rumball, and Sarah Williamson. 2014. Anti-Social Media. London: DEMOS. [Google Scholar]
- Ben-David, Anat, and Ariadna Matamoros-Fernandez. 2016. Hate speech and covert discrimination on social media: Monitoring the Facebook pages of extreme-right political parties in Spain. International Journal of Communication 10: 1167–93. [Google Scholar]
- Benesch, Susan. 2014. Countering Dangerous Speech: New Ideas for Genocide Prevention. Working Paper. Washington, DC, USA: US Holocaust Memorial Museum. [Google Scholar]
- Bird, Steven, Ewan Klein, and Edward Loper. 2009. Natural Language Processing with Python: Analyzing Text with the Natural Language Toolkit. Sebastopol: O’Reilly Media. [Google Scholar]
- Blei, David M., Andrew Y. Ng, and Michael I. Jordan. 2003. Latent Dirichlet Allocation. Journal of Machine Learning Research 3: 993–1022. [Google Scholar]
- Burnap, Pete, and Matthew L. Williams. 2015. Cyber hate speech on twitter: An application of machine classification and statistical modeling for policy and decision making. Policy & Internet 7: 223–42. [Google Scholar] [CrossRef] [Green Version]
- Canini, Kevin, Lei Shi, and Thomas Griffiths. 2009. Online Inference of Topics with Latent Dirichlet Allocation. In Proceedings of the Artificial Intelligence and Statistics. Clearwater Beach: JMLR, pp. 65–72. [Google Scholar]
- Casals, Xavier. 2000. La ultraderecha española: una presencia ausente (1975–1999). Historia y política: Ideas, procesos y movimientos sociales 3: 147–74. [Google Scholar]
- Castromil, Antón R., Raquel Rodríguez-Díaz, and Paula Garrigós. 2020. La agenda política en las elecciones de abril de 2019 en España: programas electorales, visibilidad en Twitter y debates electorales. El Profesional de la Información 29: e290217. [Google Scholar] [CrossRef]
- Collobert, Ronan, Jason Weston, Léon Bottou, Michael Karlen, Koray Kavukcuoglu, and Pavel Kuksa. 2011. Natural language processing (almost) from scratch. Journal of Machine Learning Research 12: 2493–537. [Google Scholar]
- Cueva, Ricardo. 2012. El «discurso del odio» y su prohibición; hate speech and its ban; hate speech and its ban. DOXA. Cuadernos de Filosofía del Derecho 35: 437–55. [Google Scholar] [CrossRef] [Green Version]
- Davidson, Thomas, Dana Warmsley, Michael Macy, and Ingmar Weber. 2017. Automated hate speech detection and the problem of offensive language. In Proceedings of the Eleventh International AAAI Conference on Web and Social Media. Palo Alto: AAAI, pp. 512–15. [Google Scholar]
- D’heer, Evelien, and Verdegem Pieter. 2014. Conversations about the elections on Twitter: Towards a structural understanding of Twitter’s relation with the political and the media field. European Journal of Communication 29: 720–34. [Google Scholar] [CrossRef]
- European Commission against Racism and Intolerance. 2016. ECRI General Policy Recommendation N°. 15 on Combating Hate Speech. Strasbourg: European Council. [Google Scholar]
- European Council. 2008. Framework Decision 2008/913/JHA of 28 November 2008 on Combating Certain Forms and Expressions of Racism and Xenophobia by Means of Criminal law. Available online: https://eur-lex.europa.eu/legal-content/EN/TXT/?uri=celex%3A32008F0913 (accessed on 21 October 2020).
- Evolvi, Giulia. 2018. Hate in a tweet: Exploring Internet-Based Islamophobic Discourses. Religions 9: 307. [Google Scholar] [CrossRef] [Green Version]
- Ferreira, Carles. 2019. Vox como representante de la derecha radical en España: un estudio sobre su ideología. Revista Española de Ciencia Política 51: 73–98. [Google Scholar] [CrossRef]
- Gallego, Mar, Estrella Gualda, and Carolina Rebollo. 2017. Women and Refugees in Twitter: Rhetorics on Abuse, Vulnerability and Violence from a Gender Perspective. Journal of Mediterranean Knowledge 2: 37–58. [Google Scholar]
- Gobierno de España. 2015. Ley Orgánica 1/2015, de 30 de marzo, por la que se modifica el Código Penal. Boletín Oficial del Estado 77: 27061–176. [Google Scholar]
- Gould, Robert. 2019. Vox España and Alternative für Deutschland: Propagating the Crisis of National Identity. Genealogy 3: 64. [Google Scholar] [CrossRef] [Green Version]
- Grimmer, Justin, and Brandon M. Stewart. 2013. Text as data: The promise and pitfalls of automatic content analysis methods for political texts. Political Analysis 21: 267–97. [Google Scholar] [CrossRef]
- Gualda, Estrella, and Carolina Rebollo. 2016. The Refugee Crisis on Twitter: A Diversity of Discourses At A European Crossroads. Journal of Spatial and Organizational Dynamics 4: 199–212. [Google Scholar]
- Hayes, Andrew F., and Klaus Krippendorff. 2007. Answering the call for a standard reliability measure for coding data. Communication Methods and Measures 1: 77–89. [Google Scholar] [CrossRef]
- Hernández Conde, Macarena, and Manuel Fernández García. 2019. Partidos emergentes de la ultraderecha: ¿fake news, fake outsiders? Vox y la web Caso Aislado en las elecciones andaluzas de 2018. Teknokultura 16: 33–53. [Google Scholar] [CrossRef]
- Jacobi, Carina, Wouter van Atteveldt, and Kasper Welbers. 2015. Quantitative analysis of large amounts of journalistic texts using topic modelling. Digital Journalism 4: 89–106. [Google Scholar] [CrossRef]
- Keller, Tobias R., Valerie Hase, Jagadish Thaker, Daniela Mahl, and Mike S. Schäfer. 2020. News Media Coverage of Climate Change in India 1997–2016: Using Automated Content Analysis to Assess Themes and Topics. Environmental Communication 14: 219–235. [Google Scholar] [CrossRef]
- Kreis, Ramona. 2017. #refugeesnotwelcome: Anti-refugee discourse on Twitter. Discourse & Communication 11: 498–514. [Google Scholar] [CrossRef]
- Lubbers, Marcel, and Marcel Coenders. 2017. Nationalistic attitudes and voting for the radical right in Europe. European Union Politics 18: 98–118. [Google Scholar] [CrossRef]
- McCombs, Maxwell E., and Donald L. Shawn. 1972. The agenda-setting function of the mass media. Public Opinion Quarterly 36: 176–87. [Google Scholar] [CrossRef]
- Miró, Fernando. 2016. Taxonomía de la comunicación violenta y el discurso del odio en internet. IDP: Revista De Internet, Derecho Y Política 22: 82–107. [Google Scholar]
- Mondal, Mainack, Leandro Araújo Silva, and Fabrício Benevenuto. 2017. A Measurement Study of Hate Speech in Social Media. In Proceedings of the 28th ACM Conference on Hypertext and Social Media. New York: ACM, pp. 85–94. [Google Scholar]
- Morales, Laura, Sergi Pardos-Prado, and Virginia Ros. 2015. Issue emergence and the dynamics of electoral competition around immigration in Spain. Acta Politica 50: 461–85. [Google Scholar] [CrossRef] [Green Version]
- Moyá, Miguel, and Susana Herrera. 2015. Cómo puede contribuir twitter a una comunicación política más avanzada. Arbor 191: a257. [Google Scholar] [CrossRef] [Green Version]
- Müller, Karsten, and Carlo Schwarz. 2018. Fanning the Flames of Hate: Social Media and Hate Crime. Available online: https://papers.ssrn.com/sol3/papers.cfm?abstract_id=3082972 (accessed on 10 October 2020).
- Murray, Kate E., and David A. Marx. 2013. Attitudes toward unauthorized immigrants, authorized immigrants, and refugees. Cultural Diversity and Ethnic Minority Psychology 19: 332–41. [Google Scholar] [CrossRef] [Green Version]
- Neuendorf, Kimberly A. 2002. The Content Analysis Guidebook. Thousand Oaks: Sage. [Google Scholar]
- Ong, Shyue Ping, Shreyas Cholia, Anubhav Jain, Miriam Brafman, Dand Gunter, Gerbrand Ceder, and Kristin A. Persson. 2015. The materials application programming interface (API): A simple, flexible and efficient API for materials data based on Representational state transfer (REST) principles. Computational Materials Science 97: 209–15. [Google Scholar] [CrossRef] [Green Version]
- Olteanu, Alexandra, Carlos Castillo, Jeremy Boy, and Kush R. Varshney. 2018. The effect of extremist violence on hateful speech online. In Proceedings of the Twelfth International AAAI Conference on Web and Social Media. Palo Alto: AAAI, pp. 221–30. [Google Scholar]
- Peherson, Samuel, Rupert Brown, and Hanna Zagefka. 2011. When does national identification lead to the rejection of immigrants? Crosssectional and longitudinal evidence for the role of essentialist in-group definitions. British Journal of Social Psychology 48: 61–76. [Google Scholar] [CrossRef] [Green Version]
- Ramage, Daniel, David Hall, Ramesh Nallapati, and Christopher D. Manning. 2009. Labeled LDA: A supervised topic model for credit attribution in multi-labeled corpora. In Proceedings of the 2009 Conference on Empirical Methods in Natural Language Processing: Volume 1. Stroudsburg: ACL, pp. 248–56. [Google Scholar]
- Schmidt, Anna, and Michael Wiegand. 2017. A survey on hate speech detection using natural language processing. In Proceedings of the Fifth International Workshop on Natural Language Processing for Social Media. New York: ACM, pp. 1–10. [Google Scholar]
- Stevens, Keith, Philip Kegelmeyer, David Andrzejewski, and David Buttler. 2012. Exploring topic coherence over many models and many topics. In Proceedings of the 2012 Joint Conference on Empirical Methods in Natural Language Processing and Computational Natural Language Learning. Stroudsburg: ACL, pp. 952–61. [Google Scholar]
- Teruel, Germán M. 2017. El discurso del odio como límite a la libertad de expresión en el marco del convenio europeo. Revista De Derecho Constitucional Europeo 27: 81–108. [Google Scholar]
- Turnbull-Dugarte, Stuart J. 2019. Explaining the end of Spanish exceptionalism and electoral support for Vox. Research & Politics 6. [Google Scholar] [CrossRef] [Green Version]
- Turnbull-Dugarte, Stuart J., José Rama, and Andrés Santana. 2020. The Baskerville’s dog suddenly started barking: Voting for VOX in the 2019 Spanish general elections. Political Research Exchange 2. [Google Scholar] [CrossRef]
- Valdez-Apolo, María Belén, Carlos Arcila-Calderón, and Javier J. Amores. 2019. El discurso del odio hacia migrantes y refugiados a través del tono y los marcos de los mensajes en Twitter. RAEIC, Revista de la Asociación Española de Investigación de la Comunicación 6: 361–84. [Google Scholar] [CrossRef]
- Verkuyten, Maykel, Kieran Mepham, and Mathijs Kros. 2018. Public attitudes towards support for migrants: the importance of perceived voluntary and involuntary migration. Ethnic and Racial Studies 41: 901–18. [Google Scholar] [CrossRef] [Green Version]
- Warner, William, and Julia Hirschberg. 2012. Detecting hate speech on the world wide web. In Proceedings of the Second Workshop on Language in Social Media. Stroudsburg: ACL, pp. 19–26. [Google Scholar]
- Waseem, Zeerak, and Dirk Hovy. 2016. Hateful symbols or hateful people? predictive features for hate speech detection on twitter. In Proceedings of the NAACL Student Research Workshop. Stroudsburg: ACL, pp. 88–93. [Google Scholar]
- Webster, Jonathan J., and Chunyu Kit. 1992. Tokenization as the initial phase in NLP. In COLING 1992: The 15th International Conference on Computational Linguistics. Nantes: ACL, pp. 1106–10. [Google Scholar]
- Zou, Chen. 2018. Analyzing research trends on drug safety using topic modeling. Expert Opinion on Drug Safety 17: 629–36. [Google Scholar] [CrossRef]
| 1 | Other approaches such as TFIDF or N-gram for text representation were not considered in this study. |
| 2 | Published 30 November 2018 at 19:22. In English: “Fucking immigrants. People want them to starve to death. They deserve the punishment. Long live VOX.” |
| 3 | Published 25 November 2018 at 21:45. In English: “To this day only VOX demands to end illegal immigration. Spaniards, we have to vote to clean Spain from these savages. And those who do not vote for them, enjoy your vote.” |
| 4 | Published 15 December 2018 at 23:29. In English: “Let’s hope Vox wins and we remove all these fucking rats from the country.” |
| 5 | Published 12 December 2018 at 22:27. In English: “I have been convinced by Vox, finally people like #shakira, #Messi, #Griezmann, #benzema… will stop taking the jobs from our Spanish children! To their house! #Voxasitis #Politics #ElectionsNow.” |
| 6 | Published 11 December 2018 at 21:08. In English: “Out with the moors! Fuck off with their religion! Clear as day! Fuck off to the fucking North of Africa!” |
| 7 | Published 13 December 2018 at 23:08. In English: “But the crucifixes out of the schools… and @vox_es are very bad. The next men of peace will be the ones of ISIS, right?” |
| 8 | Published 25 November 2018 at 21:05. In English: “Exactly. However, they are destroying our beliefs, our traditions and forcing us into a radical Islamism and “cultures” that are alien to us and that are disrespectful.” |
| 9 | Even when some terms might be not special or meaningful for the analysis, we did not include in the Stop Word list reference terms such as “Inmigrantes” (immigrants) or “España” (Spain). We consider that far from being redundant they might offer better results in the co-occurrence analysis. |
| 10 | In English: “immigrants, spain, country, illegals, immigration, spanish [masculine plural], women, muslims, Europe, party, moors, islam, benefits, foreigners, vote, government, pp [People’s Party of Spain], expel, work, black.” |
| 11 | In English: “immigrants, spain, immigration, illegals, country, spanish [masculine plural], party, pp, muslims, government, andalusia, women, black, europe, expel, foreigners, vote, islam, program, melilla.” |
| 12 | In English: “immigrants, spain, country, spanish [masculine plural], illegals, women, muslims, benefits, moors, europe, immigration, islam, religion, foreigners, muslim, shit, law, rights, culture, male chauvinists.” |
| 13 | In English: “spain, country, immigrants, fucking [masculine plural], shit, ass, moors, cunt, muslims, fucking [masculine singular], whore/fucking [feminine singular], girls, sons, garbage, rapists, immigration, spanish [masculine plural], clean, offenders, riffraff.” |
| 14 | In English: “immigrants, spain, immigration, muslims, country, women, spanish [masculine plural], party, illegals, europe, countries, immigrant, psoe [Spanish Socialist Party], pp, illegal.” |
| 15 | In English: “Spain, country, immigrants, immigration, spanish [masculine plural], illegal, moors, benefits, millions, woman, illegals, muslim [feminine singular], expel, immigrant, countries.” |
| 16 | In English: “immigrants, spain, illegals, spanish [masculine plural], people, country, immigration, islam, immigrant, Europe, foreigners, woman, Moroccan [masculine plural], problem, benefits.” |
| 17 | In English: “immigrants, spain, illegals, immigration, party, country, people, left, illegal, melilla, borders, Europe, Spanish [masculine singular], spanish [masculine plural], invasion.” |
| 18 | In English: “immigrants, immigration, spain, country, spanish [masculine plural], islam, fear, islamists, expel, government, women, illegal, family, problem, black.” |
| 19 | In English: “voice.” |









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Spain | Immigration | Government | Islam | Insults |
|---|---|---|---|---|
| España | inmigrantes | programa | religión | mierda |
| españoles | inmigrante | ayudas | cultura | putos |
| español | Ilegales | trabajo | musulmana | puto |
| país | Ilegal | votar | musulmán | negro |
| Andalucía | extranjeros | problema | musulmanes | basura |
| Melilla | expulsar | ley | moros | gentuza |
| países | Europa | mujeres | violadores | |
| derechos | mujer | delincuentes | ||
| partido | coño | |||
| pp | culo | |||
| psoe | machistas |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Calderón, C.A.; de la Vega, G.; Herrero, D.B. Topic Modeling and Characterization of Hate Speech against Immigrants on Twitter around the Emergence of a Far-Right Party in Spain. Soc. Sci. 2020, 9, 188. https://doi.org/10.3390/socsci9110188
Calderón CA, de la Vega G, Herrero DB. Topic Modeling and Characterization of Hate Speech against Immigrants on Twitter around the Emergence of a Far-Right Party in Spain. Social Sciences. 2020; 9(11):188. https://doi.org/10.3390/socsci9110188
Chicago/Turabian StyleCalderón, Carlos Arcila, Gonzalo de la Vega, and David Blanco Herrero. 2020. "Topic Modeling and Characterization of Hate Speech against Immigrants on Twitter around the Emergence of a Far-Right Party in Spain" Social Sciences 9, no. 11: 188. https://doi.org/10.3390/socsci9110188