
A Review of Cooling and Heating Loads Predictions of Residential Buildings Using Data-Driven Techniques

Abstract
:1. Introduction
- (a)
- Experimental data-based publications (simulated—synthetic/real);
- (b)
- Publications that use a machine learning approach or more;
- (c)
- Publications with a scope limited to heating and cooling load predictions.
2. Background on Energy Efficiency in Buildings
- Designing buildings to maximise natural lighting, reduce energy consumption for heating and cooling, and using energy-efficient building materials;
- Optimising HVAC systems to reduce energy consumption by using sensors to control temperature, optimising system controls, and using energy-efficient components;
- Optimising lighting systems by using energy-efficient lighting technology, such as LED lights, and installing sensors to automatically turn lights off when not in use;
- Integrating renewable energy systems, such as solar panels or wind turbines, to reduce reliance on fossil fuels;
- Using computerised energy management systems to monitor energy consumption and optimise energy usage in buildings and infrastructure;
- Conducting life cycle analyses of buildings and infrastructure to identify areas where energy waste could be reduced throughout the building’s lifespan.
- Insulation: Proper insulation can reduce heat loss and gain, and therefore the amount of energy needed to maintain a comfortable indoor temperature. Adding insulation to an under-insulated attic can result in savings of up to 20% on heating and cooling costs [23]. Additionally, insulation in walls, floors, and ceilings can reduce energy consumption by up to 30%;
- Energy-efficient windows: Designed to reduce the amount of heat transfer between the interior and exterior of a building. Energy-efficient windows can reduce energy consumption by 12–33% in heating-dominated climates, and 18–38% in cooling-dominated climates [24];
- Efficient Lighting: The use of LED lights, for example, can reduce energy consumption by up to 75% compared to traditional incandescent bulbs [25]. Energy Star certified appliances, which meet energy efficiency guidelines set by the U.S. Environmental Protection Agency, can save up to 50% more energy than standard models;
- Building Design: A building’s design can also contribute to energy efficiency. Orienting a building to take advantage of natural sunlight and ventilation can reduce the need for lighting and air conditioning. A well-designed ventilation system can also help regulate indoor temperature and reduce the need for heating and cooling [26].
- Roof Area: Home heating and cooling loads depend on the roof area with the heat gain or loss being greater from a larger roof area and the difference in temperature between the indoors and the outdoors. Insulating and employing reflecting roofing materials reduce heat transmission [29];
- Glazing Area: A home’s total window, skylight, and glass door areas are called the glazing area and can contribute significantly to the heating or cooling of a room with the rate of heat transfer increasing with glazing area, affecting a home’s heating, and cooling demands. Energy-efficient windows with low-emissivity (low-E) coatings, insulated glass, and double-glazing reduce the rate heat transfer [30] ;
- Surface Area: The area of external walls and the roof affect the heating and cooling load, with the rate of heat transfer increasing with surface area, affecting home heating and cooling [9];
- Relative Compactness (Shape of Building): A compact building with a reduced surface area-to-volume ratio reduces the heating and cooling demands. Energy-efficient buildings have a reduced exposed surface area [31];
- Wall Area: Walls transmit heat in the case of a thermal gradient between the indoors and the outdoors. Depending on the weather, larger wall areas result in greater heat intake or loss. Insulation, thermal barriers, and energy-efficient building materials can help to minimise the rate of heat transfer through walls.
3. Machine Learning Techniques for Energy Efficiency Prediction
3.1. Ensemble Learning
3.2. Support Vector Machine and Artificial Neural Networks Learners
3.3. Statistical and Probabilistic Learners
- P(Y|X) is the posterior probability: the probability of the class given the test data X input variable values;
- P(X|Y) is the probability of X variable values given the class value;
- P(Y) is the prior probability of the class;
- P(X) is the probability of X input variable values.
3.4. Other Machine Learning Algorithms
4. Discussion
4.1. Data and Simulation Tools
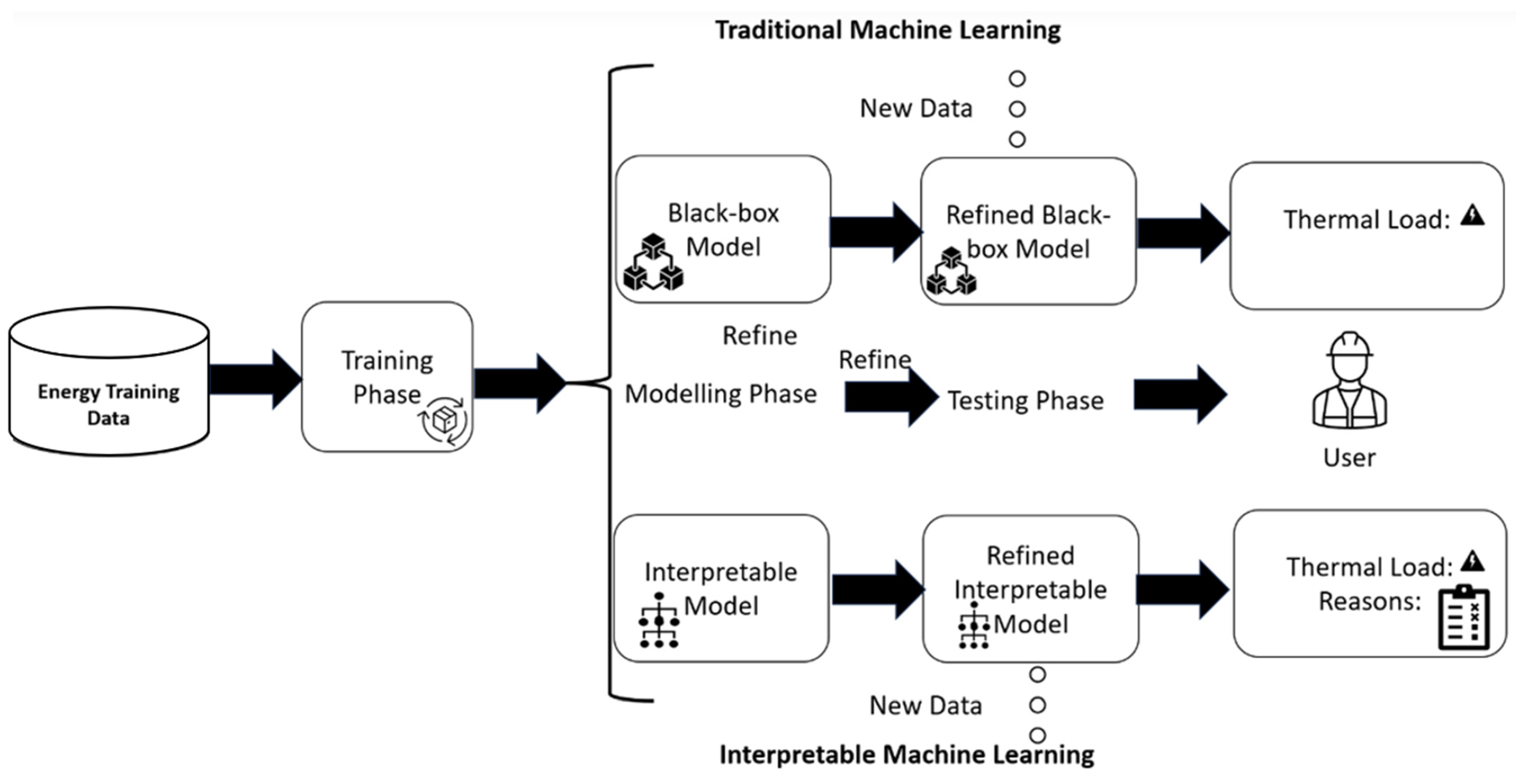
4.2. Models Interpretability for Stakeholders
- 5.
- What are the influential building features that impact energy loads in an energy efficient system?
- 6.
- Why are certain features influential?
- 7.
- Under which values can we optimise the energy efficiency of a building, and how do we reach these values?
- 8.
- What energy consumption patterns can be found? And to which features do they belong?
- 9.
- How do we obtain an efficient HVAC system in terms of energy consumption?
- 10.
- How do we determine early designs of a building with energy conservation in mind?
4.3. Platforms and Algorithms’ Hyperparameters
5. Conclusions, Limitations and Future Works
Author Contributions
Funding
Conflicts of Interest
Abbreviations
| AI | Artificial intelligence |
| AMT | Alternating model tree |
| ANN | Artificial neural networks |
| BEMS | Building Energy Management Systems |
| CMA-ES | Covariance matrix adaptive evolution strategy |
| DH | District heating |
| DSOS | Discrete symbiotic organisms search |
| EPB | Energy performance of buildings |
| ERT | Extra random tree |
| FIMT-DD | Fast Incremental Model Trees with Drift Detection |
| GPR | Gaussian process regression algorithm |
| GSVR | Group support vector regression |
| HEMS | Home Energy Management System |
| HVAC | Heating, ventilation, and air conditioning |
| LCA | League championship algorithm |
| LLWL | Lazy locally weighted learning |
| MAE | Mean absolute error |
| MAPE | Mean absolute percentage error |
| ML | Machine learning |
| MLPr | Multi-layer Perceptron Regressor |
| MOA | Massive Online Analysis |
| MOBO | Multi-objective building optimisation tool |
| MRMR | Maximum relevance minimum redundancy |
| PLS | Partial least square |
| PSO | Particle swarm optimisation |
| RBFr | Radial basis function regression |
| RMSD | Root mean squared deviation |
| SRTE | SFLA-optimised regression tree ensemble |
| SVM | Support vector machines |
| UCI | University of California Irvine |
| WEKA | Waikato Environment for Knowledge Analysis |
References
- Sekisov, A. Problems of achieving energy efficiency in residential low-rise housing construction within the framework of the resource-saving technologies use. In Proceedings of the E3S Web of Conferences, Prague, Czech Republic, 12–17 September 2021; EDP Sciences: Paris, France, 2021; Volume 281, p. 06004. [Google Scholar]
- Energy.gov. Available online: https://www.energy.gov/eere/energy-efficiency#:~:text=Energy%20efficiency%20is%20the%20use,less%20energy%20to%20produce%20goods (accessed on 20 March 2023).
- Almughram, O.; Zafar, B.; Ben Slama, S. Home Energy Management Machine Learning Prediction Algorithms: A Review. In Proceedings of the 2nd International Conference on Industry 4.0 and Artificial Intelligence (ICIAI 2021), Hammamet, Tunisia, 28–30 November 2021; Atlantis Press: Paris, France, 2022; pp. 40–47. [Google Scholar]
- Wheeler, G. Performance of Energy Management Systems; Oregon State University: Corvallis, OR, USA, 2009. [Google Scholar]
- Zhang, J. Design and Technical Analysis of HVAC Ventilation System in Green Building. In Proceedings of the E3S Web of Conferences, Prague, Czech Republic, 12–17 September 2021; EDP Sciences: Paris, France, 2021; Volume 261, p. 03039. [Google Scholar]
- Lu, C.; Li, S.; Penaka, S.R.; Olofsson, T. Automated machine learning-based framework of heating and cooling load prediction for quick residential building design. Energy 2023, 274, 127334. [Google Scholar] [CrossRef]
- Guo, J.; Yun, S.; Meng, Y.; He, N.; Ye, D.; Zhao, Z.; Jia, L.; Yang, L. Prediction of heating and cooling loads based on light gradient boosting machine algorithms. J. Affect. Disord. 2023, 236, 110252. [Google Scholar] [CrossRef]
- Tsanas, A.; Xifara, A. Accurate quantitative estimation of energy performance of residential buildings using statistical machine learning tools. Energy Build. 2012, 49, 560–567. [Google Scholar] [CrossRef]
- Heat Load in Buildings. Heat Load in Buildings—Designing Buildings. 2022. Available online: https://www.designingbuildings.co.uk/wiki/Heat_load_in_buildings (accessed on 31 May 2023).
- Rinaldi. 3 Types of Heating and Cooling Loads: Learn the Fundamentals; Rinaldi’s Air Conditioning & Heating: Orlando, FL, USA, 2021; Available online: https://rinaldis.com/heating-and-cooling-loads/ (accessed on 31 May 2021).
- Sun, Y.; Haghighat, F.; Fung, B.C.M. A review of the-state-of-the-art in data-driven approaches for building energy prediction. Energy Build. 2020, 221, 110022. [Google Scholar] [CrossRef]
- Chen, Z.; Xiao, F.; Guo, F.; Yan, J. Interpretable machine learning for building energy management: A state-of-the-art review. Adv. Appl. Energy 2023, 9, 100123. [Google Scholar] [CrossRef]
- International Energy Agency (IEA). Energy Efficient Buildings. 2021. Available online: https://www.iea.org/topics/energy-efficient-buildings (accessed on 3 February 2024).
- U.S. Green Building Council (USGBC). LEED. 2021. Available online: https://www.usgbc.org/leed (accessed on 25 March 2023).
- U.S. Green Building Council. What Is A Green Building? 2021. Available online: https://www.usgbc.org/articles/what-green-building (accessed on 24 March 2023).
- National Renewable Energy Laboratory. Renewable Energy Integration. 2021. Available online: https://www.nrel.gov/research/renewable-energy-integration.html (accessed on 2 June 2023).
- ISO 14040; International Organization for Standardization (IOS). Environmental Management—Life Cycle Assessment. 2019. Available online: https://www.iso.org/standard/68383.html\ (accessed on 3 February 2024).
- ASHRAE. 2020. Available online: https://www.ashrae.org/file%20library/about/position%20documents/pd_energyefficiencyinbuildings_ra2023.pdf (accessed on 12 May 2023).
- U.S. Department of Energy. Building Energy Efficiency. 2021. Available online: https://www.energy.gov/eere/buildings/building-energy-efficiency (accessed on 1 April 2023).
- Energy Star. About Energy Star. Available online: https://www.energystar.gov/about (accessed on 20 March 2023).
- National Renewable Energy Laboratory (NREL)-Home and Building Energy Management Systems. NREL.Gov. Available online: https://www.nrel.gov/grid/energy-management.html (accessed on 30 March 2023).
- U.S. Department of Energy (USDE). Zero Energy Buildings. 2021. Available online: https://www.energy.gov/eere/buildings/zero-energy-buildings (accessed on 28 March 2023).
- U.S. Department of Energy (USDE). Insulation. Available online: https://www.energy.gov/energysaver/weatherize/insulation (accessed on 19 April 2023).
- National Renewable Energy Laboratory (NREL). Energy-Efficient Windows. Available online: https://www.nrel.gov/docs/fy20osti/76883.pdf (accessed on 15 May 2023).
- U.S. Department of Energy. Lighting. 2021. Available online: https://www.energy.gov/energysaver/lighting (accessed on 22 March 2023).
- U.S. Department of Energy. Designing and Orienting Buildings for Optimum Energy Performance. Available online: https://www.energy.gov/energysaver/designing-and-orienting-buildings-optimum-energy-performance (accessed on 3 February 2024).
- Ghasemkhani, B.; Yilmaz, R.; Birant, D.; Kut, R.A. Machine Learning Models for the Prediction of Energy Consumption Based on Cooling and Heating Loads in Internet-of-Things-Based Smart Buildings. Symmetry 2022, 14, 1553. [Google Scholar] [CrossRef]
- Basic HVAC System Diagram with Important Parts and Components. ETechnoG (n.d.). Available online: https://www.etechnog.com/2020/11/what-is-hvac-system-its-need-important.html (accessed on 20 May 2023).
- Lubis, I.H.; Koerniawan, M.D. Reducing heat gains and cooling loads through roof structure. IOP Conf. Ser. Earth Environ. Sci. 2018, 152, 012008. [Google Scholar] [CrossRef]
- Hamlin, S.; Glass is essential to a building’s energy efficiency. Building Enclosure RSS. Available online: https://www.buildingenclosureonline.com/articles/89628-glass-is-essential-to-a-buildings-energy-efficiency (accessed on 24 May 2023).
- Geletka, V.; Sedlakova, A. Shape of Buildings and Energy Consumption—suw.biblos.pk.edu.pl. Available online: https://suw.biblos.pk.edu.pl/resources/i1/i4/i4/i8/i8/r14488/GeletkaV_ShapeBuildings.pdf (accessed on 29 May 2023).
- Breiman, L. Random Forests. Mach. Learn. 2001, 45, 5–32. [Google Scholar] [CrossRef]
- Zhou, Z.H. Ensemble Learning. In Encyclopedia of Biometrics; Li, S.Z., Jain, A., Eds.; Springer: Boston, MA, USA, 2009. [Google Scholar] [CrossRef]
- Breiman, L. Bagging predictors. Mach. Learn. 1996, 24, 123–140. [Google Scholar] [CrossRef]
- Analyticsvidhya, Jan 2023. Available online: https://www.analyticsvidhya.com/blog/2023/01/ensemble-learning-methods-bagging-boosting-and-stacking/ (accessed on 7 May 2023).
- Chaganti, R.; Rustam, F.; Daghriri, T.; Díez, I.d.l.T.; Mazón, J.L.V.; Rodríguez, C.L.; Ashraf, I. Building Heating and Cooling Load Prediction Using Ensemble Machine Learning Model. Sensors 2022, 22, 7692. [Google Scholar] [CrossRef]
- Pachauri, N.; Ahn, C.W. Regression tree ensemble learning-based prediction of the heating and cooling loads of residential buildings. Build. Simul. 2022, 15, 2003–2017. [Google Scholar] [CrossRef]
- Provatas, R. An Online Machine Learning Algorithm for Heat Load Forecasting in District Heating Systems. Master’s Thesis, Blekinge Institute of Technology, Karlskrona, Sweden, 2014. [Google Scholar]
- Liu, J.; Zeng, K.; Wang, H.; Du, B.; Tang, Y. Generalized Prediction of Commercial Buildings Cooling and Heating Load Based on Machine Learning Technology. In IOP Conference Series: Earth and Environmental Science, Proceedings of the 4th International Conference on Environmental, Industrial and Energy Engineering (EI2E 2020), Guiyang, China, 15–17 October 2020; IOP Publishing: Bristol, UK, 2020; Volume 610. [Google Scholar] [CrossRef]
- Moradzadeh, A.; Mohammadi-Ivatloo, B.; Abapour, M.; Anvari-Moghaddam, A.; Roy, S.S. Heating and Cooling Loads Forecasting for Residential Buildings Based on Hybrid Machine Learning Applications: A Comprehensive Review and Comparative Analysis; IEEE Access: Piscataway, NJ, USA, 2021; Volume 10, pp. 2196–2215. [Google Scholar] [CrossRef]
- Abdou, N.; El Mghouchi, Y.; Jraida, K.; Hamdaoui, S.; Hajou, A.; Mouqallid, M. Prediction and optimization of heating and cooling loads for low energy buildings in Morocco: An application of hybrid machine learning methods. J. Build. Eng. 2022, 61, 105332. [Google Scholar] [CrossRef]
- Tyralis, H.; Papacharalampous, G. A Review of Probabilistic Forecasting and Prediction with Machine Learning. 2022. Available online: https://arxiv.org/pdf/2209.08307 (accessed on 3 February 2024).
- Webb, G.I. Naïve Bayes. In Encyclopedia of Machine Learning; Sammut, C., Webb, G.I., Eds.; Springer: Boston, MA, USA, 2011. [Google Scholar] [CrossRef]
- Li, X.; Yao, R. A machine-learning-based approach to predict residential annual space heating and cooling loads considering occupant behaviour. Energy 2020, 212, 118676. [Google Scholar] [CrossRef]
- Huang, S.; Zuo, W.; Sohn, M. A Bayesian Network Model for Predicting Cooling Load of Commercial Buildings. Build. Simul. 2018, 11, 87–101. [Google Scholar] [CrossRef]
- Prasetiyo, B.; Alamsyah; Muslim, M.A. Analysis of building energy efficiency dataset using naive bayes classification classifier. In Proceedings of the CMSE2018: 5. International Conference on Mathematics, Science and Education 2018, Kuta, Indonesia, 8–9 October 2018; International Atomic Energy Agency (IAEA): Vienna, Austria, 2018. [Google Scholar] [CrossRef]
- Dalipi, F.; Yayilgan, S.Y.; Gebremedhin, A. Data-Driven Machine-Learning Model in District Heating System for Heat Load Prediction: A Comparison Study. Appl. Comput. Intell. Soft Comput. 2016, 2016, 3403150. [Google Scholar] [CrossRef]
- Kurek, T.; Bielecki, A.; Świrski, K.; Wojdan, K.; Guzek, M.; Białek, J.; Brzozowski, R.; Serafin, R. Heat demand forecasting algorithm for a Warsaw district heating network. Energy 2021, 217, 119347. [Google Scholar] [CrossRef]
- Moayedi, H.; Bui, D.T.; Dounis, A.; Lyu, Z.; Foong, L.K. Predicting Heating Load in Energy-Efficient Buildings through Machine Learning Techniques. Appl. Sci. 2019, 9, 4338. [Google Scholar] [CrossRef]
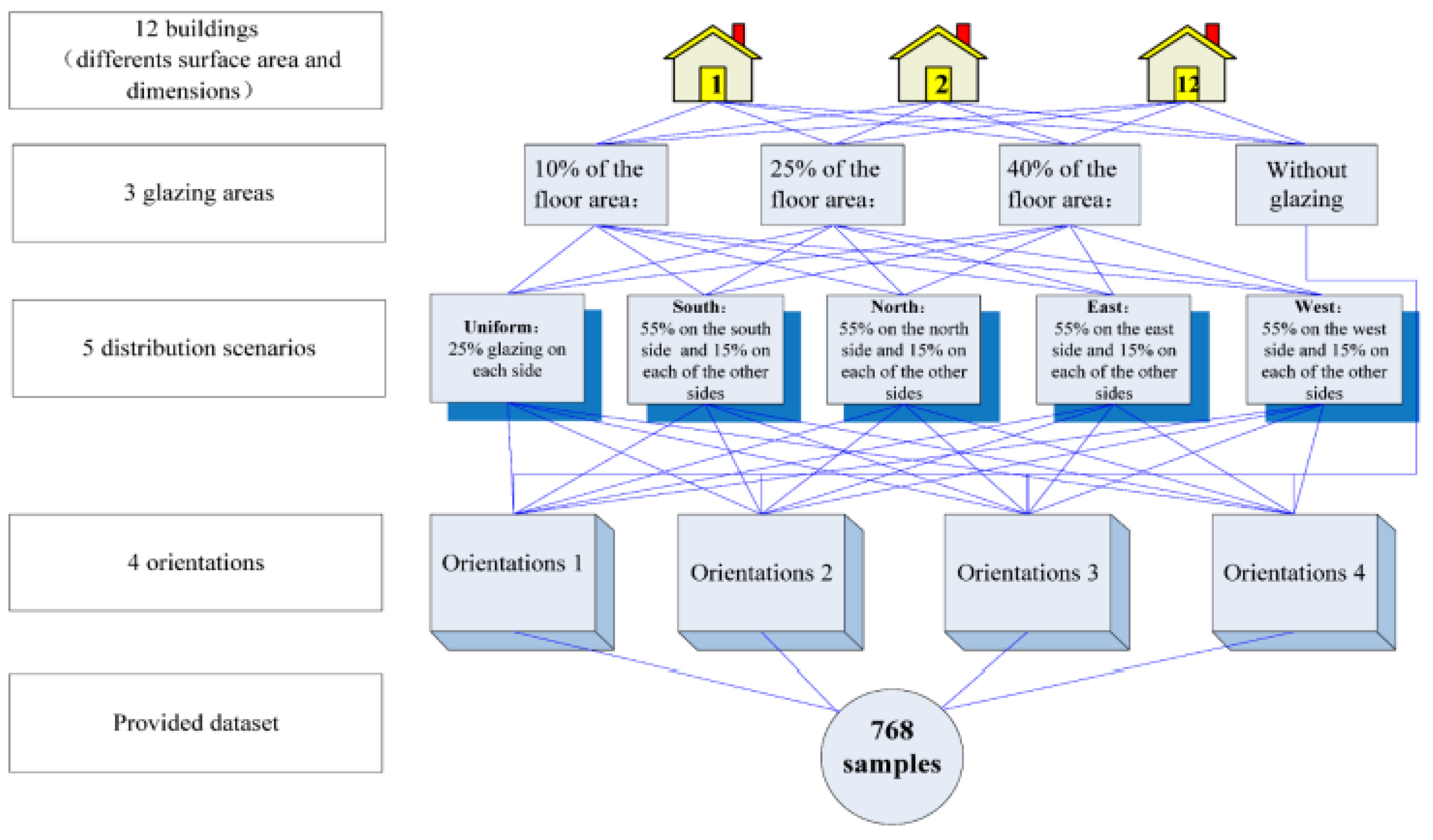
- UCI. Available online: https://archive.ics.uci.edu/ml/datasets/energy+efficiency (accessed on 20 March 2023).
- Seyedzadeh, S.; Rahimian, F.P.; Rastogi, P.; Oliver, S.; Glesk, I.; Kumar, B. Multi-objective optimisation for tuning building heating and cooling loads forecasting models. In Proceedings of the 36th CIB W78 2019 Conference, Northumbria University, Newcastle upon Tyne, UK, 18–20 September 2019. [Google Scholar]
- An, W.; Zhu, X.; Yang, K.; Kim, M.K.; Liu, J. Hourly Heat Load Prediction for Residential Buildings Based on Multiple Combination Models: A Comparative Study. Buildings 2023, 13, 2340. [Google Scholar]
- Crawley, D.B.; Lawrie, L.K.; Winkelmann, F.C.; Buhl, W.; Huang, Y.; Pedersen, C.O.; Strand, R.K.; Liesen, R.J.; Fisher, D.E.; Witte, M.J.; et al. EnergyPlus: Creating a new-generation building energy simulation program. Energy Build. 2001, 33, 319–331. [Google Scholar] [CrossRef]
- Birdsall, B.; Buhl, W.F.; Ellington, K.L.; Erdem, A.E.; Winkelmann, F.C. Overview of the DOE-2 Building Energy Analysis Program, Version 2.1D; Technical Report LBL-19735-Rev.1; Lawrence Berkeley National Laboratory: Berkeley, CA, USA, 1990. [Google Scholar]
- Chen, F.; Deng, Y.; Xue, Z.; Wu, R. Toolpack for building environment simulation DeST. Heat. Vent. Air Cond. 1999, 29, 58–63. (In Chinese) [Google Scholar]
- Klein, S.A.; Duffie, J.A.; Beckman, W.A. TRNSYS—A transient simulation program. ASHRAE Trans. 1976, 82, 623–633. [Google Scholar]
- Beatriz, A.; Rodríguez-Ubiñas, E.; Bedoya-Frutos, C.; Vega-Sánchez, S. Evaluation of Three Solar and Daylighting Control System Based on Calumen II, Ecotect, and Radiance Simulation Programmes to Obtain an Energy Efficient and Healthy Interior in the Experimental Building Prototype SD10. Energy Build. 2014, 83, 225–236. [Google Scholar]
- Amani, N.; Sabamehr, A.; Palmero Iglesias, L.M. Review on Energy Efficiency using the Ecotect Simulation Software for Residential Building Sector. Iran. J. Energy Environ. 2022, 13, 284–294. [Google Scholar] [CrossRef]
- Naser, M.Z. An engineer’s guide to eXplainable Artificial Intelligence and Interpretable Machine Learning: Navigating causality, forced goodness, and the false perception of inference. Autom. Constr. 2021, 129, 103821. [Google Scholar] [CrossRef]
- Gao, Y.; Ruan, Y. Interpretable deep learning model for building energy consumption prediction based on attention mechanism. Energy Build. 2021, 252, 111379. [Google Scholar] [CrossRef]
- Eusuff, M.; Lansey, K.; Pasha, F. Shuffled frog-leaping algorithm: A memetic meta-heuristic for discrete optimization. Eng. Optim. 2006, 38, 129–154. [Google Scholar] [CrossRef]



{kind=link}
{kind=link}
| Year | Problem | ML Methods | Feature Selection/Optimisation | Performance Measure | Dataset Source | # of Features excl. class | Platform | Interpretable Models | Reference |
|---|---|---|---|---|---|---|---|---|---|
| 2023 | Heating and cooling loads prediction | LR, naive Bayes, three versions of decision trees, SVM, and XGBoost, DNN | Variance threshold and recursive feature elimination | R2, RMSE | Residential buildings in the Hohhot area of Mongolia | 8 | TPOT Python | No | [6] |
| 2023 | Heating and cooling loads prediction | Random-LightGBM, CMA-ES-LightGBM, TPE-LightGBM, and Grid-LightGBM, RF, SVM | RF-filter | R2, RMSE, MAE, MAPE | Residential buildings in the Hohhot area in Mongolia | 8 | Not known | No | [7] |
| 2022 | Heating and cooling loads prediction | Ensemble Learner with decision tree, RF, MLP, KNN, LR, 3RF, LR-GAM | No feature selection | R2 | [8] | 8 | Python-scikit-learn | No | [36] |
| 2022 | Heating and cooling loads prediction | Ensemble Learner with decision trees and the least square-boosting, different Gaussian process regression algorithm (GPR) versions | Shuffled Frog Leaping Optimisation | MSE, RMSE, R | [8] | 8 | Not known | No | [37] |
| 2022 | Heating and cooling loads prediction | ANN, SVM, LR, bagging, boosting and various tree-based algorithms | Maximum relevance minimum redundancy, F-test, regression Relief version-F | RMSE, MSE, and MAE | [8] | 8 | Tensorflow, H2O, Caffe, PyTorch, Microsoft Cognitive Toolkit | No | [27] |
| 2022 | Heating and cooling loads prediction | League championship algorithm (LCA), discrete symbiotic organisms search (DSOS) algorithm, particle swarm optimisation (PSO), SVM, ANN | Wrapper method | Optimisation with objective function and R2 | Synthetic building energy data of 1000 points | 11 | TRNSYS software coupled with multi-objective building optimisation tool (MOBO) | No | [41] |
| 2021 | Heating load prediction in a district heating system | Fuzzy logic, mixture of ANN and regression techniques | Forward feature selection | R2, MAE | Warsaw District Heating Network | Variety of measurements, geographical descriptions, weather, and billing data | [48] | ||
| 2020 | Heating and cooling loads prediction | KNN, CART, Lasso Regression, ElasticNet, RF, bagging, LIR, RIDGE, extra random tree (ERT), SVM | Recursive Feature Elimination with ERT algorithm, Pearson correlation | Accuracy | [8] | 8 | Not known | No | [39] |
| 2020 | Heating and cooling loads prediction | SVM, MLP | No feature selection | Accuracy, R, MSE, RMSE, MAE | [8] | 8 | Not known | No | [40] |
| 2020 | Heating and cooling loads prediction | Linear kernel support vector regression, polynomial kernel support vector regression, Gaussian radial basis function kernel support vector regression, LR, ANN | Spearman correlation | MSE, MAE | Residential building based on synthetic data in China generated by EnergyPlus tool | 5 | R tool | No | [44] |
| 2019 | Heating and cooling loads prediction | RF | Optimisation method to tune the algorithm’s hyperparameter | RMSE | US Department of Energy commercial building reference database, residential houses in Geneva, Switzerland and north of Germany | 12—climate, building and others | Python | No | [51] |
| 2019 | Heating load prediction | Multi-layer Perceptron Regressor (MLPr), lazy locally weighted learning (LLWL), alternatingmodel tree (AMT), RF ElasticNet, and radial basis function regression (RBFr) | No feature selection | R2, MAE, RMSE, RAE, and RRSE | [8] | 8 | Ecotect, WEKA | No | [49] |
| 2019 | Heating and cooling loads prediction | Naive Bayes | No feature selection | Precision, recall, MAE | [8] | 8 | Rapid Miner | No | [46] |
| 2018 | Cooling load | Bayesian network, ANN, SVM | No feature selection | R2, RMSE | University campus in Annapolis, Maryland, USA | Variety of features in 14 datasets | Python | No | [45] |
| 2016 | Heating load prediction in a district heating system | SVM, RF, Partial Least Square (PLS) | No feature selection | R, MAE | Waste incineration plants in Hamar, Norway | 5 | Unknown | No | [47] |
| 2014 | Heating load prediction | Bagging with Fast Incremental Model Trees with Drift Detection (FIMT-DD) | No feature selection | Mean absolute percentage error (MAPE) | Multiple district heating (DH)–datasets in Sweden | Variety of features | Massive Online Analysis (MOA) and WEKA | No | [38] |
| 2023 | Heating load prediction | Back propagation (BP) and ELMAN neural networks | Principal component analysis (PCA), | MSE, RMSE, MAE, MAPE, Accuracy | Meteorological data of a community in Weifang | Variety of features | MATLAB | No | [52] |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Abdel-Jaber, F.; Dirks, K.N. A Review of Cooling and Heating Loads Predictions of Residential Buildings Using Data-Driven Techniques. Buildings 2024, 14, 752. https://doi.org/10.3390/buildings14030752
Abdel-Jaber F, Dirks KN. A Review of Cooling and Heating Loads Predictions of Residential Buildings Using Data-Driven Techniques. Buildings. 2024; 14(3):752. https://doi.org/10.3390/buildings14030752
Chicago/Turabian StyleAbdel-Jaber, Fayez, and Kim N. Dirks. 2024. "A Review of Cooling and Heating Loads Predictions of Residential Buildings Using Data-Driven Techniques" Buildings 14, no. 3: 752. https://doi.org/10.3390/buildings14030752