
Building Energy Consumption Prediction Using a Deep-Forest-Based DQN Method

 ,
,
Abstract
:1. Introduction
1.1. Related Work
1.1.1. Energy Consumption Prediction

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Method | Merits | Demerits | |
|---|---|---|---|
| Engineering [10,11] | Relationships between input and output variables are very clear | Detailed building information is required | |
| Statistical [13,14] | Straightforward and fast | Not flexible | |
| Artificial intelligence | Traditional machine learning [18,19,20] | Learn from historical data | Adopt shallow structures for modeling |
| Deep learning [21,22,29] | Extract more abstract features from raw inputs | May not always reflect the physical behaviors | |
1.1.2. Predictive Control
1.2. The Purpose and Organization of This Paper
2. Related Theories
2.1. Deep Reinforcement Learning
2.1.1. Reinforcement Learning
2.1.2. Deep Q-Network
2.2. Deep Forest
3. DF–DQN Method for Energy Consumption Prediction
3.1. Overall Framework
3.2. Data Pre-Processing
3.3. MDP Modeling
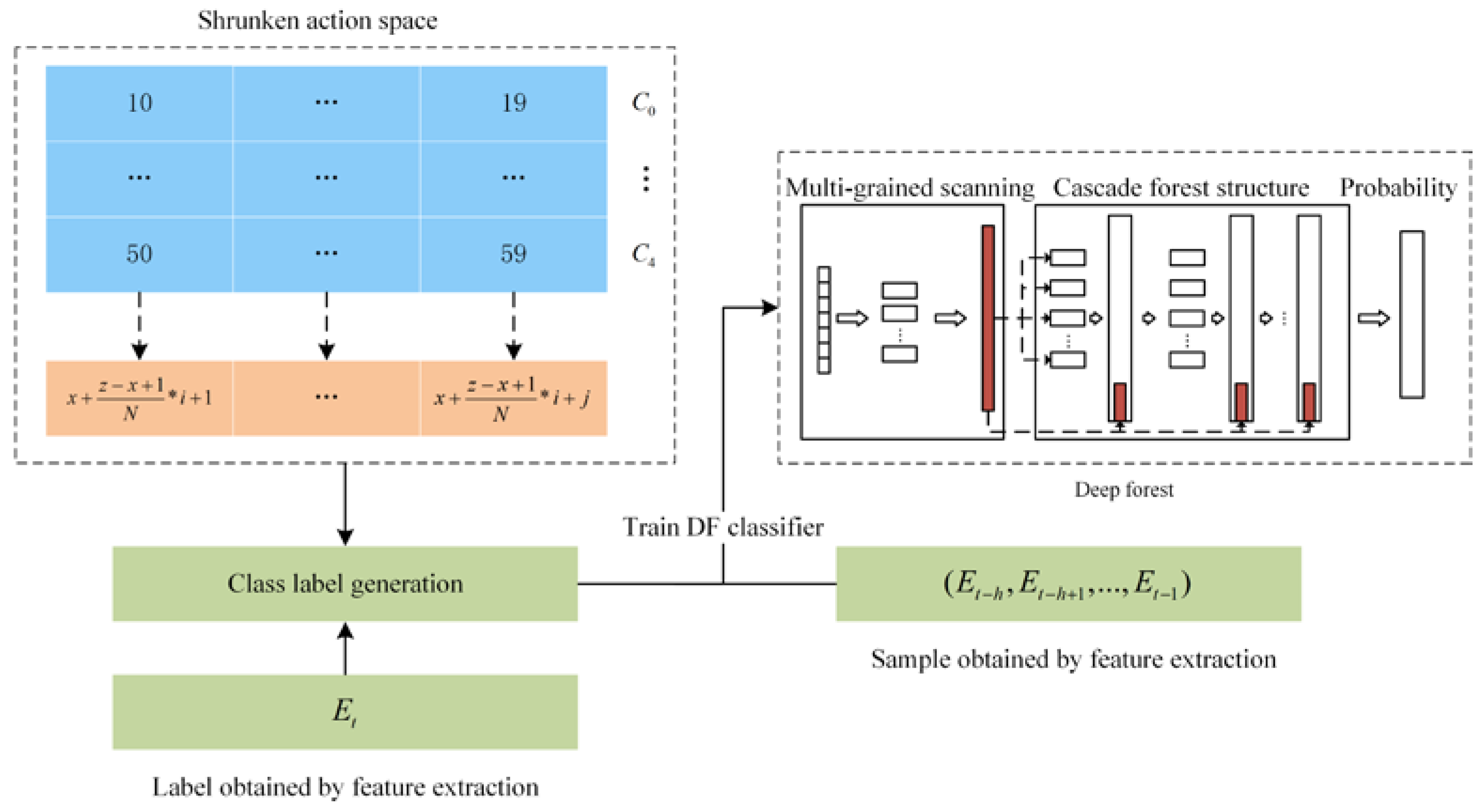
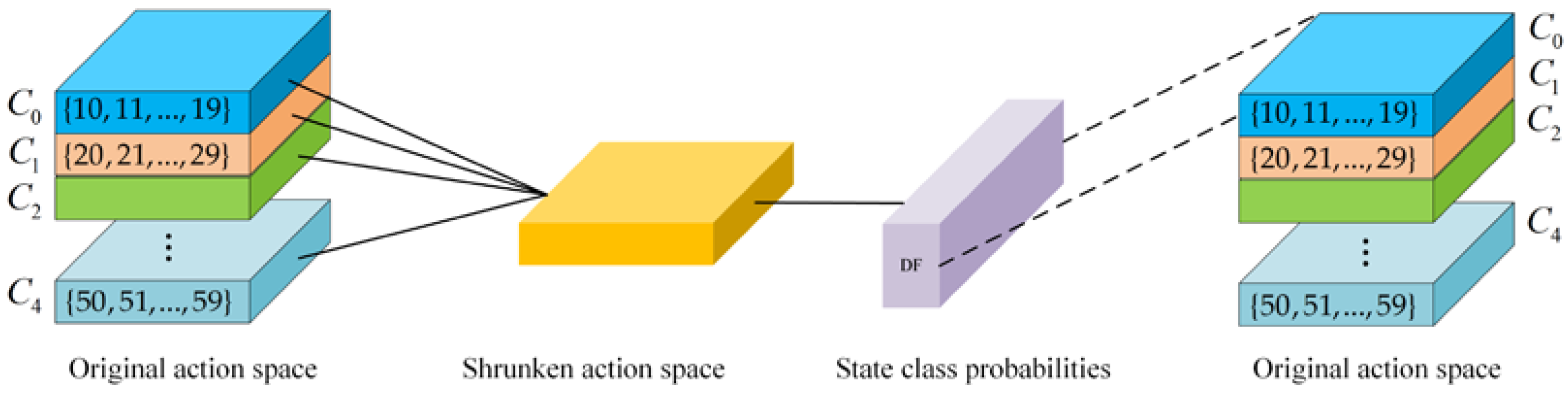
3.3.1. Shrunken Action Space
3.3.2. DF Classifier
3.4. DF–DQN Method
| Algorithm 1 DF–DQN method for energy consumption prediction |
| (1) Initialize state classes |
| (2) Initialize replay memory |
| (3) Initialize action-value function with random weights |
| (4) Initialize target action-value function with weights |
| (5) Split the data set |
| (6) Detect and replace outliers in the training set |
| (7) Extract features to construct samples and labels |
| (8) Train the deep forest classifier |
| (9) Repeat (for each episode) |
| (10) Randomly select a sample |
| (11) Use DF classifier to obtain the possibility of each class |
| (12) Construct initial state (denoted as ) |
| (13) Repeat (for each step) |
| (14) Select a random action with probability |
| (15) otherwise choose |
| (16) Execute action and receive immediate reward |
| (17) Construct state |
| (18) Store transition in |
| (19) Sample a mini-batch from |
| (20) Set |
| (21) Update function using |
| (22) Every steps reset |
| (23) |
| (24) Until terminal state or maximum number of steps is reached |
| (25) Until maximum number of episodes is reached |
4. Case Study
4.1. Experimental Settings
4.2. Evaluation Metrics
4.3. Results and Analyses
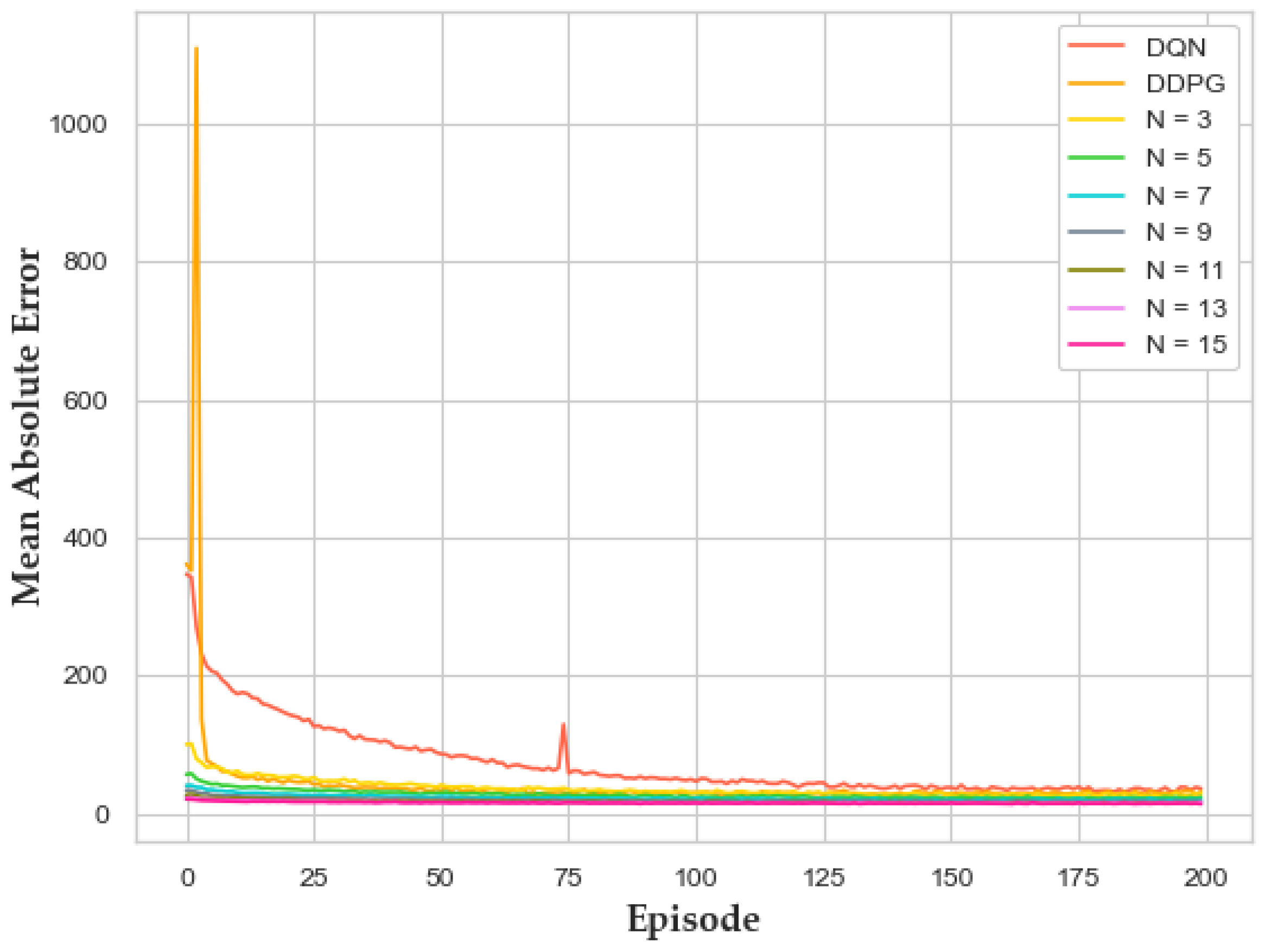
4.3.1. Prediction Accuracy
4.3.2. Convergence Rate and Computation Time
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Conti, J.; Holtberg, P.; Diefenderfer, J.; LaRose, A.; Turnure, J.T.; Westfall, L. International Energy Outlook 2016 with Projections to 2040; USDOE Energy Information Administration (EIA): Washington, DC, USA; Office of Energy Analysis: Washington, DC, USA, 2016.
- China Building Energy Consumption Annual Report 2020. Build. Energy Effic. 2021, 49, 1–6.
- Becerik-Gerber, B.; Siddiqui, M.K.; Brilakis, I.; El-Anwar, O.; El-Gohary, N.; Mahfouz, T.; Jog, G.M.; Li, S.; Kandil, A.A. Civil Engineering Grand Challenges: Opportunities for Data Sensing, Information Analysis, and Knowledge Discovery. J. Comput. Civ. Eng. 2014, 28, 04014013. [Google Scholar] [CrossRef]
- Dawood, N. Short-term prediction of energy consumption in demand response for blocks of buildings: DR-BoB approach. Buildings 2019, 9, 221. [Google Scholar] [CrossRef] [Green Version]
- Moghadam, S.T.; Delmastro, C.; Corgnati, S.P.; Lombardi, P. Urban energy planning procedure for sustainable development in the built environment: A review of available spatial approaches. J. Clean. Prod. 2017, 165, 811–827. [Google Scholar] [CrossRef]
- Kim, J.; Frank, S.; Braun, J.E.; Goldwasser, D. Representing Small Commercial Building Faults in EnergyPlus, Part I: Model Development. Buildings 2019, 9, 233. [Google Scholar] [CrossRef] [Green Version]
- Du, Y.; Zandi, H.; Kotevska, O.; Kurte, K.; Munk, J.; Amasyali, K.; Mckee, E.; Li, F. Intelligent multi-zone residential HVAC control strategy based on deep reinforcement learning. Appl. Energy 2021, 281, 116117. [Google Scholar] [CrossRef]
- Min, Y.; Chen, Y.; Yang, H. A statistical modeling approach on the performance prediction of indirect evaporative cooling energy recovery systems. Appl. Energy 2019, 255, 113832. [Google Scholar] [CrossRef]
- Zhao, H.-X.; Magoulès, F. A review on the prediction of building energy consumption. Renew. Sustain. Energy Rev. 2012, 16, 3586–3592. [Google Scholar] [CrossRef]
- Yao, R.; Steemers, K. A method of formulating energy load profile for domestic buildings in the UK. Energy Build. 2005, 37, 663–671. [Google Scholar] [CrossRef]
- Wang, S.; Xu, X. Simplified building model for transient thermal performance estimation using GA-based parameter identification. Int. J. Therm. Sci. 2006, 45, 419–432. [Google Scholar] [CrossRef]
- Wei, Y.; Zhang, X.; Shi, Y.; Xia, L.; Pan, S.; Wu, J.; Han, M.; Zhao, X. A review of data-driven approaches for prediction and classification of building energy consumption. Renew. Sustain. Energy Rev. 2018, 82, 1027–1047. [Google Scholar] [CrossRef]
- Ma, Y.; Yu, J.; Yang, C.; Wang, L. Study on power energy consumption model for large-scale public building. In Proceedings of the 2010 2nd International Workshop on Intelligent Systems and Applications, Wuhan, China, 22–23 May 2010; pp. 1–4. [Google Scholar]
- Lam, J.C.; Wan, K.K.; Wong, S.; Lam, T.N. Principal component analysis and long-term building energy simulation correlation. Energy Convers. Manag. 2010, 51, 135–139. [Google Scholar] [CrossRef]
- Ahmad, A.S.; Hassan, M.Y.; Abdullah, M.P.; Rahman, H.A.; Hussin, F.; Abdullah, H.; Saidur, R. A review on applications of ANN and SVM for building electrical energy consumption forecasting. Renew. Sustain. Energy Rev. 2014, 33, 102–109. [Google Scholar] [CrossRef]
- Amasyali, K.; El-Gohary, N.M. A review of data-driven building energy consumption prediction studies. Renew. Sustain. Energy Rev. 2018, 81, 1192–1205. [Google Scholar] [CrossRef]
- Tian, C.; Li, C.; Zhang, G.; Lv, Y. Data driven parallel prediction of building energy consumption using generative adversarial nets. Energy Build. 2019, 186, 230–243. [Google Scholar] [CrossRef]
- Azadeh, A.; Ghaderi, S.; Sohrabkhani, S. Annual electricity consumption forecasting by neural network in high energy consuming industrial sectors. Energy Convers. Manag. 2008, 49, 2272–2278. [Google Scholar] [CrossRef]
- Hou, Z.; Lian, Z. An application of support vector machines in cooling load prediction. In Proceedings of the 2009 International Workshop on Intelligent Systems and Applications, Wuhan, China, 23–24 May 2009; pp. 1–4. [Google Scholar]
- Tso, G.K.; Yau, K.K. Predicting electricity energy consumption: A comparison of regression analysis, decision tree and neural networks. Energy 2007, 32, 1761–1768. [Google Scholar] [CrossRef]
- Ozcan, A.; Catal, C.; Donmez, E.; Senturk, B. A hybrid DNN-LSTM model for detecting phishing URLs. Neural Comput. Appl. 2021, 33, 1–17. [Google Scholar] [CrossRef]
- Cai, M.; Pipattanasomporn, M.; Rahman, S. Day-ahead building-level load forecasts using deep learning vs. traditional time-series techniques. Appl. Energy 2019, 236, 1078–1088. [Google Scholar] [CrossRef]
- Ozcan, A.; Catal, C.; Kasif, A. Energy Load Forecasting Using a Dual-Stage Attention-Based Recurrent Neural Network. Sensors 2021, 21, 7115. [Google Scholar] [CrossRef]
- Mnih, V.; Kavukcuoglu, K.; Silver, D.; Rusu, A.A.; Veness, J.; Bellemare, M.G.; Graves, A.; Riedmiller, M.; Fidjeland, A.K.; Ostrovski, G. Human-level control through deep reinforcement learning. Nature 2015, 518, 529–533. [Google Scholar] [CrossRef] [PubMed]
- Levine, S.; Finn, C.; Darrell, T.; Abbeel, P. End-to-end training of deep visuomotor policies. J. Mach. Learn. Res. 2016, 17, 1334–1373. [Google Scholar]
- Sallab, A.E.; Abdou, M.; Perot, E.; Yogamani, S. Deep reinforcement learning framework for autonomous driving. Electron. Imaging 2017, 2017, 70–76. [Google Scholar] [CrossRef] [Green Version]
- Huang, Z.; Chen, J.; Fu, Q.; Wu, H.; Lu, Y.; Gao, Z. HVAC Optimal Control with the Multistep-Actor Critic Algorithm in Large Action Spaces. Math. Probl. Eng. 2020, 2020, 1386418. [Google Scholar] [CrossRef]
- Wei, T.; Wang, Y.; Zhu, Q. Deep reinforcement learning for building HVAC control. In Proceedings of the 54th Annual Design Automation Conference 2017, Austin, TX, USA, 18–22 June 2017; pp. 1–6. [Google Scholar]
- Liu, T.; Tan, Z.; Xu, C.; Chen, H.; Li, Z. Study on deep reinforcement learning techniques for building energy consumption forecasting. Energy Build. 2020, 208, 109675. [Google Scholar] [CrossRef]
- Xue, J.; Kong, X.; Dong, B.; Xu, M. Multi-Agent Path Planning based on MPC and DDPG. arXiv 2021, arXiv:2102.13283. [Google Scholar]
- Shan, K.; Wang, S.; Gao, D.; Xiao, F. Development and validation of an effective and robust chiller sequence control strategy using data-driven models. Autom. Constr. 2016, 65, 78–85. [Google Scholar] [CrossRef]
- Gholamibozanjani, G.; Tarragona, J.; De Gracia, A.; Fernandez, C.; Cabeza, L.F.; Farid, M.M. Model predictive control strategy applied to different types of building for space heating. Appl. Energy 2018, 231, 959–971. [Google Scholar] [CrossRef]
- Imran; Iqbal, N.; Kim, D.H. IoT Task Management Mechanism Based on Predictive Optimization for Efficient Energy Consumption in Smart Residential Buildings. Energy Build. 2021, 257, 111762. [Google Scholar] [CrossRef]
- Qin, H.; Wang, X. A multi-discipline predictive intelligent control method for maintaining the thermal comfort on indoor environment. Appl. Soft Comput. 2021, 166, 108299. [Google Scholar] [CrossRef]
- Fu, C.; Zhang, Y. Research and Application of Predictive Control Method Based on Deep Reinforcement Learning for HVAC Systems. IEEE Access 2021, 9, 130845–130852. [Google Scholar] [CrossRef]
- Liu, T.; Xu, C.; Guo, Y.; Chen, H. A novel deep reinforcement learning based methodology for short-term HVAC system energy consumption prediction. Int. J. Refrig. 2019, 107, 39–51. [Google Scholar] [CrossRef]
- Sutton, R.S.; Barto, A.G. Reinforcement Learning: An Introduction; MIT Press: Cambridge, MA, USA, 2018. [Google Scholar]
- Watkins, C.J.; Dayan, P. Q-learning. Mach. Learn. 1992, 8, 279–292. [Google Scholar] [CrossRef]
- Rummery, G.A.; Niranjan, M. On-Line Q-Learning Using Connectionist Systems; Citeseer: State College, PA, USA, 1994; Volume 37. [Google Scholar]
- Tsitsiklis, J.N.; Van Roy, B. An analysis of temporal-difference learning with function approximation. IEEE Trans. Autom. Control 1997, 42, 674–690. [Google Scholar] [CrossRef] [Green Version]
- Zhou, Z.-H.; Feng, J. Deep forest. Natl. Sci. Rev. 2019, 6, 74–86. [Google Scholar] [CrossRef]
- Breunig, M.M.; Kriegel, H.-P.; Ng, R.T.; Sander, J. LOF: Identifying density-based local outliers. In Proceedings of the 2000 ACM SIGMOD International Conference on Management of Data, Dallas, TX, USA, 15–18 May 2000; pp. 93–104. [Google Scholar]










| Hardware Platform | Configuration |
|---|---|
| Operating system | Windows 10 |
| RAM | 8 GB |
| CPU | Intel Core i5-9500 |
| Programing language | Python |
| Programing software | PyCharm |
| Package | Version |
|---|---|
| TensorFlow | 2.2.0 |
| TensorLayer | 2.2.3 |
| NumPy | 1.19.4 |
| pandas | 1.1.5 |
| DeepForest | 0.1.4 |
| Method | Parameters | Results |
|---|---|---|
| MLR | / | / |
| SVR | Kernel function | Linear |
| DT | Evaluation function | Mean squared error |
| Maximum depth of the tree | 16 | |
| DQN | Neurons | 24,32,32,935 |
| Activation function | ReLu | |
| Learning rate | 0.01 | |
| DF–DQN | Neurons | 24+N,32,32,935/N |
| Activation function | ReLu | |
| Learning rate | 0.01 | |
| DDPG | Neurons (actor) | 24,32,32,1 |
| Activation function (actor) | ReLu | |
| Learning rate (actor) | 0.001 | |
| Neurons (critic) | 24,32,32,1 | |
| Activation function (critic) | ReLu | |
| Learning rate (critic) | 0.001 |
| N | Number of Actions | Accuracy of Classification | MAE | MAPE | RMSE | |
|---|---|---|---|---|---|---|
| 2 | 468 | 99.392% | 23.333 | 7.960% | 36.774 | 0.978 |
| 3 | 312 | 94.706% | 29.630 | 9.664% | 48.750 | 0.961 |
| 4 | 234 | 96.168% | 22.950 | 7.828% | 39.141 | 0.974 |
| 5 | 187 | 95.178% | 23.357 | 7.866% | 38.686 | 0.976 |
| 6 | 156 | 92.739% | 27.439 | 9.476% | 44.295 | 0.968 |
| 7 | 134 | 89.583% | 27.512 | 9.655% | 41.153 | 0.971 |
| 8 | 117 | 89.098% | 23.810 | 8.074% | 39.536 | 0.974 |
| 9 | 104 | 88.327% | 23.152 | 7.886% | 40.831 | 0.973 |
| 10 | 94 | 84.139% | 24.456 | 8.370% | 42.201 | 0.970 |
| 11 | 85 | 83.907% | 23.643 | 8.246% | 40.044 | 0.974 |
| 12 | 78 | 83.586% | 22.254 | 7.845% | 37.480 | 0.976 |
| 13 | 72 | 80.307% | 21.921 | 7.379% | 36.248 | 0.978 |
| 14 | 67 | 77.548% | 20.912 | 7.231% | 34.936 | 0.980 |
| 15 | 63 | 76.462% | 20.432 | 7.021% | 34.057 | 0.981 |
| 16 | 59 | 73.005% | 20.975 | 7.390% | 34.331 | 0.980 |
| 17 | 55 | 71.633% | 20.971 | 7.545% | 35.410 | 0.980 |
| 18 | 52 | 69.037% | 20.590 | 7.315% | 35.442 | 0.979 |
| 19 | 50 | 66.714% | 20.596 | 7.367% | 34.408 | 0.980 |
| 20 | 47 | 64.740% | 20.623 | 7.272% | 35.198 | 0.980 |
| Method | MAE | MAPE | RMSE | R2 |
|---|---|---|---|---|
| MLR | 41.069 | 12.869% | 56.577 | 0.946 |
| SVR | 37.041 | 11.192% | 63.150 | 0.930 |
| DT | 26.349 | 8.868% | 50.470 | 0.959 |
| DQN | 27.942 | 9.362% | 39.869 | 0.973 |
| DDPG | 21.619 | 7.573% | 36.417 | 0.978 |
| DF–DQN (N = 15) | 20.432 | 7.021% | 34.057 | 0.981 |
| Method | Computation Time |
|---|---|
| MLR | 0.07 |
| SVR | 7.734 |
| DT | 0.362 |
| DQN | 833.714 |
| DDPG | 1329.007 |
| DF–DQN (N = 15) | 699.529 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Fu, Q.; Li, K.; Chen, J.; Wang, J.; Lu, Y.; Wang, Y. Building Energy Consumption Prediction Using a Deep-Forest-Based DQN Method. Buildings 2022, 12, 131. https://doi.org/10.3390/buildings12020131
Fu Q, Li K, Chen J, Wang J, Lu Y, Wang Y. Building Energy Consumption Prediction Using a Deep-Forest-Based DQN Method. Buildings. 2022; 12(2):131. https://doi.org/10.3390/buildings12020131
Chicago/Turabian StyleFu, Qiming, Ke Li, Jianping Chen, Junqi Wang, You Lu, and Yunzhe Wang. 2022. "Building Energy Consumption Prediction Using a Deep-Forest-Based DQN Method" Buildings 12, no. 2: 131. https://doi.org/10.3390/buildings12020131