1. Introduction
Earthquakes are among the most perilous natural disasters, causing loss of life, serious calamities, and destruction of building infrastructures, resulting in both life and economic losses [
1,
2]. In the past two decades, earthquakes and tsunamis have naturally been the fatalist form of disasters, accounting for 58% of overall fatalities regardless of their comparatively low frequency [
3]. In recent decades, a series of strong earthquakes have been responsible for inducing landslides in different global regions [
4]. Flushing excess debris downstream of rivers, leading to bank erosion and floodplain accumulation, and channel eruptions that affect flood frequency, towns, ecosystems, and infrastructure are slower consequences of earthquakes [
5].
Earthquakes also cause wide cracks and fractures on verges and mountain crests, thus increasing the occurrence of landslides that may last for years [
6]. Due to the dreadful consequences of earthquakes, seismologists and geologists have a huge compel to make accurate predictions for earthquakes by considering the time, place, and magnitude [
7,
8,
9,
10]. Therefore, many researchers have adopted different methods for predicting an earthquake by considering the environmental and regional dynamics of different seismically prone areas.
Existing earthquake prediction research can be broadly split into four groups based on the methodologies used: (1) precursor signal investigation, (2) mathematical analysis, (3) Machine Learning (ML)-based algorithms, and (4) Deep Learning (DL)-based algorithms. For the first group, researchers have explored earthquake precursor signals. The researchers have observed different features, such as an increase in temperature [
11,
12], recording the behavior of animals [
13,
14], an emanation of radon gas [
15], lithosphere–atmosphere ionosphere coupling [
16], and variability of Aerosol Optical Depth (AOD) [
17]. The air above the epicentral region of an impending significant earthquake frequently becomes overloaded with positive airborne ions due to the electromagnetic signals from the crustal rocks. These positive airborne ions have been shown to cause changes in stress hormone levels in animals and humans [
13]. The water on the surface is also oxidized to hydrogen peroxide due to these charges, and this, plus oxidation, can cause behavioral changes among aquatic animals [
13,
14]. The concentration of Rn-222 in soil has been observed to be influenced before earthquakes [
15].
Researchers have adopted statistical methods and techniques in the second type to accomplish earthquake prediction. TheFibonacci, Dual, and Lucas (FDL) approach [
18], fuzzy mathematics [
19], likelihood analysis of earthquake catalogs [
20], stochastic models [
21], statistical physics approach [
22], Poisson distribution [
23], etc., are some of the techniques that have been studied for predicting earthquakes.
The third type of research focused on using data-mining or ML methods such as Fuzzy Logic [
24], AdaBoost [
10], Decision Tree [
25,
26], Support Vector Machines (SVM) [
27], K-nearest Neighbors [
28], etc., to predict earthquakes based on previously recorded seismic data in the same region. DL algorithms have been used in the fourth type of work to anticipate the magnitude and timing of significant seismic events. DL is a rapidly expanding field of ML research that detects and classifies data patterns using multi-layered representations and is inspired by ANNs. The term ‘deep’ in this strategy refers to a series of levels, through which data from one level are converted into another level [
29]. A suitable data transformation allows obtaining the most appropriate hierarchical representations of data as the number of layers (i.e., network depth) increases [
30]. To date, various DL architectures (e.g., Recurrent Neural Networks (RNNs), and Convolutional Neural Networks (CNNs)) have been presented [
31,
32,
33], all of which have enhanced the state-of-the-art in ML research.
Although much work has been carried out on earthquake predictions, very few can accurately predict seismic events [
2,
34]. The insufficient earthquake predictions are due to the number of real-time factors that are difficult to analyze and the higher complexities of the prediction processes. Traditional and existing statistical methods cannot accurately predict the complex nonlinear correlations amongst earthquake occurrences [
35]. However, due to their relatively better prediction performance, numerous ML and DL neural networks (NNs) have recently become the center of attention in the prediction of earthquakes for various situations and with different seismic parameters and have performed well [
8,
36,
37,
38,
39,
40]. Some of the most prominently used NN architectures in earthquake-related studies include the Multilayer Perceptron (MLP) [
41], Backward Propagation Neural Network [
42], Deep Neural Network (DNN) [
43], and Feed-Forward Neural Network [
44], RNN [
45], Shallow Neural Network (SNN) [
26], Pattern Recognition Neural Network (PRNN) [
46], etc. Various NN architectures have also been used in other fields for prediction and classification purposes, and their exceptional performances have been documented. Some of the prominent architectures include the Modular Neural Network (MNN) [
47], Long Short-Term Memory [
48], Residual Network [
49], etc.
Furthermore, in previous studies, only history-based time-series data were used to predict earthquakes in a specific area; hence, excellent or accurate results could not be produced [
50]. The study of earthquakes’ spatial and temporal properties is an important branch of seismic science divided into two general forecast categories: long-term forecasting based on months and years and short-term forecasting based on days and hours [
51,
52]. Short-term earthquake prediction is more challenging due to the complexity of earthquake phenomena [
53], crustal blocks-and-faults structure [
54], the intricacies of the Earth’s lithosphere, and the lack of a credible approach for such forecasts [
55]. Moreover, short-term seismic events are directly associated with social infrastructure and human lives [
56].
Some studies [
55,
57] have focused on the variables directly correlated with the expected output variable. However, these studies ignored the less correlated variables when making predictions. Moreover, most existing studies are based on the temporal correlation between independent and dependent variables rather than spatial correlations. Furthermore, it is also considered important to change the parameters of the DL or ML models, which include the neurons, hidden layers, learning rate, epochs, etc., to obtain the best architecture for the model [
58].
This provides the novelty of the present study, where both the spatial and temporal characteristics of a large area and real-time data, along with history-based data, are considered to make earthquake predictions using multiple state-of-the-art NNs. The overall outcomes of the study are the primary contributions of this study. Generally, this study had the following objectives:
To utilize two ML methods, MNN and SNN, and two DL methods, RNN and DNN, and check their applicability and performance for earthquake prediction. The choice of methods was based on the literature review and the application and performance of the techniques in different research areas.
To explore the spatiotemporal viewpoint of earthquake prediction, as the results of prediction models for certain input variables are different, as each method extracts the information from the input variables differently.
To examine the prediction accuracy of the models by introducing and analyzing the role of an additional spatial variable, namely Fault Density (FD), involved in the earthquake-prediction process.
To use accuracy, information gain analysis (IGA), and sensitivity metrics for evaluating the descriptive power of each input variable, including the suggested FD, to evaluate the overall performance of the considered models.
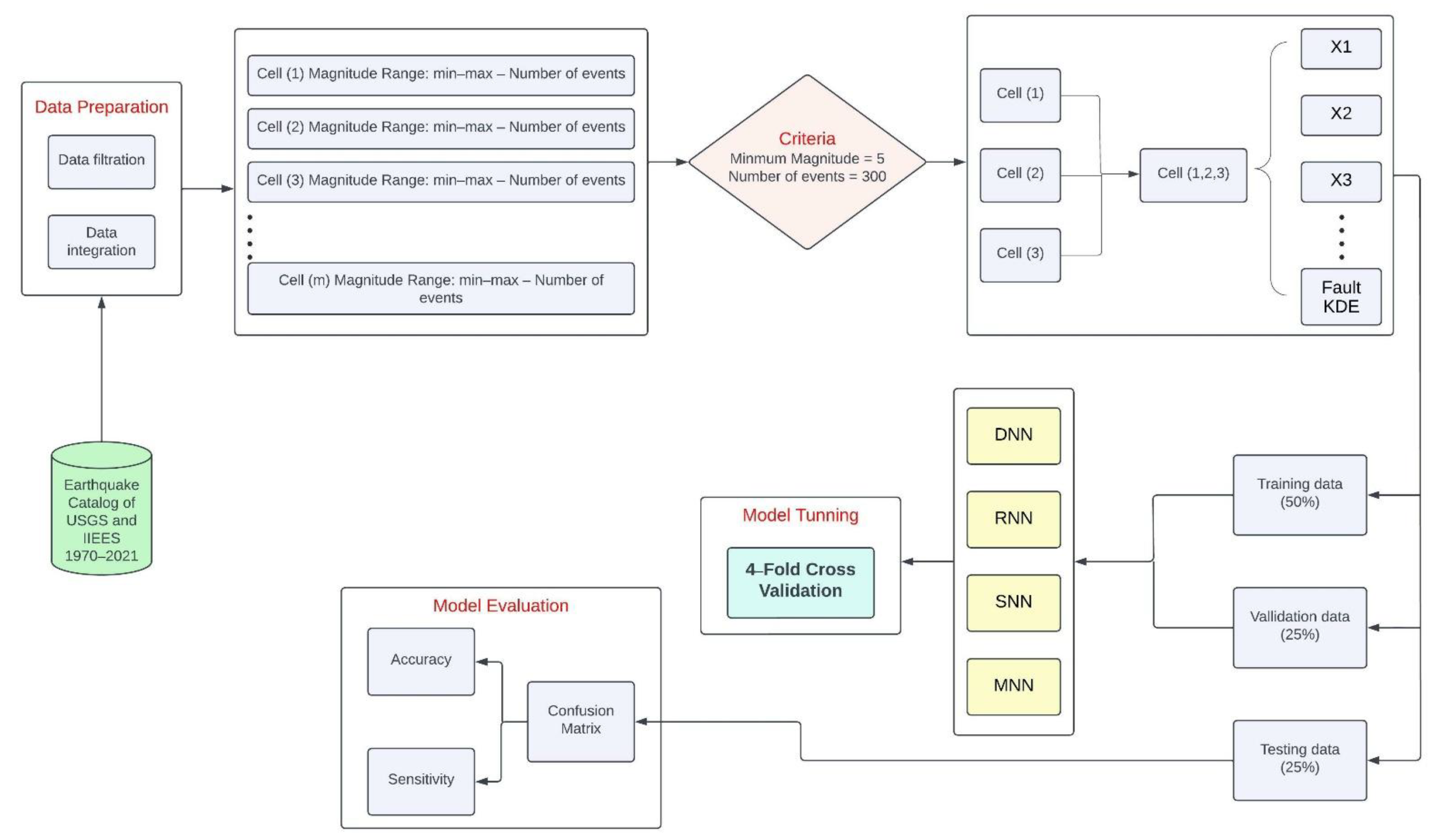
The rest of the study is organized such that the study area is described in
Section 2. Data preparation, the considered seismic variables, and the description of the methods used are given in
Section 3. The obtained results of this study are presented in
Section 4, and the discussion about the general outcomes of the study and their importance are presented in
Section 5. Eventually,
Section 6 is the conclusion, offering a brief description of the outcomes of the present study.
5. Discussion
Earthquake is among the major catastrophes that cause significant casualties and damage to infrastructures [
9,
32,
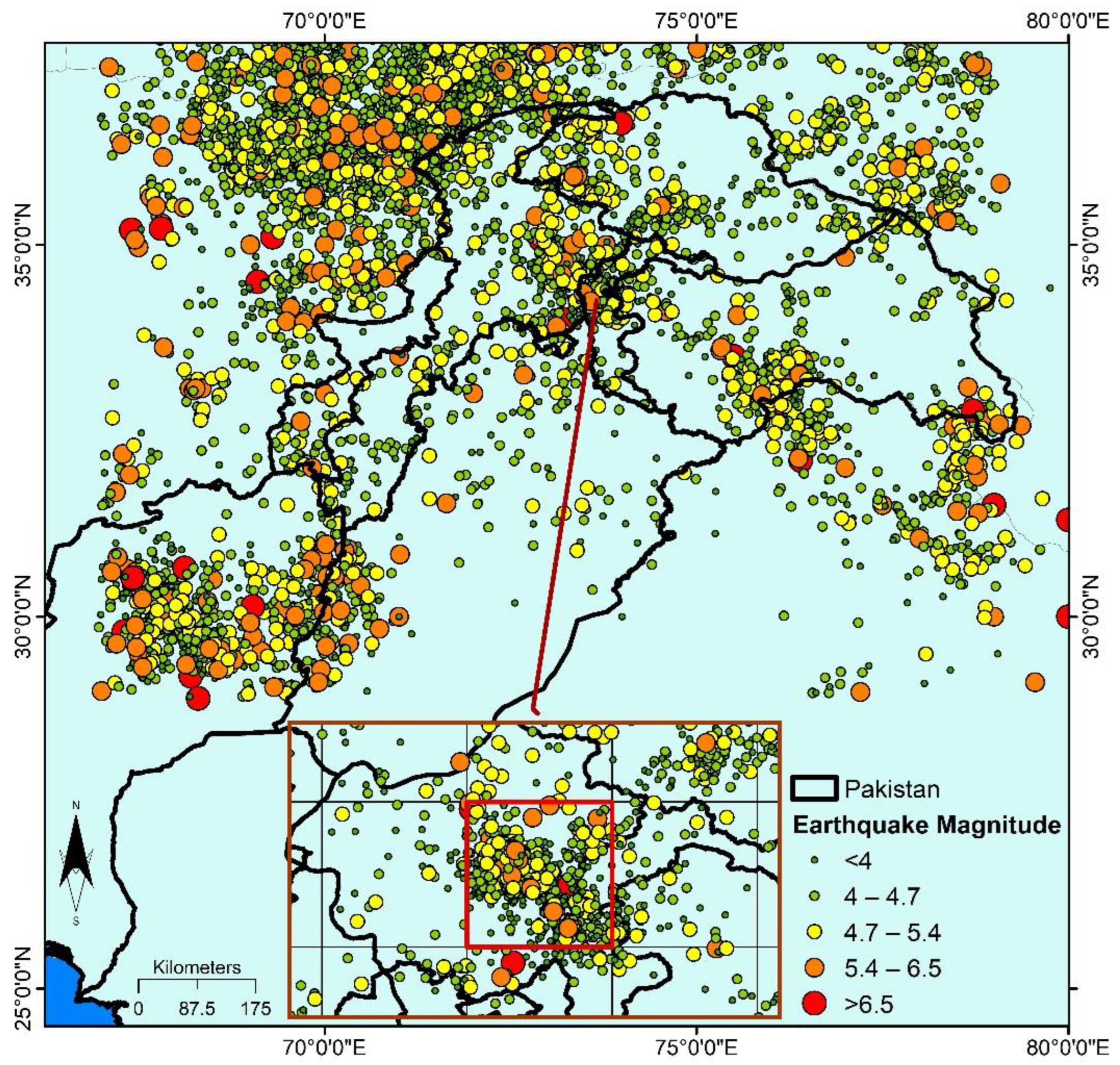
97]. Hindu Kush, Himalayas, and the Karakoram Mountains range in the North of Pakistan are amongst the most seismically lively regions globally. Unfortunately, the North of Pakistan has a record of suffering mild to rigorous and, at times, overwhelming earthquakes, primarily due to its presence at the boundary of the Indian and Eurasian plates [
27,
35]. Although naturally occurring earthquakes cannot be stopped, their prediction and adequate protection measures can prevent the loss of human life and several valuables.
A mechanism suitable for earthquake prediction that can offer positive predictions is a pressing need at present. A system that is competent in earthquake prediction should predict the accurate location, exact magnitude range, a specific incidence timespan, and the likelihood of incidence. However, no such comprehensive earthquake prediction system has existed to date [
8,
27]. Several researchers have tackled this problem individually, and investigations have been conducted to predict some of the aforementioned characteristics. However, a holistic study is missing.
The present study attempts to predict earthquakes of Richter magnitude greater than or equal to 3 in Northern Pakistan using four models (two ML and two DL models): DNN, RNN, SNN, and MNN, combined with 20 seismicity indicators from previously conducted investigations. The arithmetically computed seismicity indicators from the former earthquakes signify the seismic trend of the region. These indicators were used as input to the approaches for earthquake prediction. The seismic indicators were mathematically computed using the records from the earthquake catalog of IIEES and USGS.
Interestingly, some former investigations [
8,
10] suggested that the cutoff magnitude centered on the GR law must be computed in advance. Moreover, following the calculation of the cutoff magnitude, all events below the computed cutoff magnitude must be excluded. The reason for doing this is to safeguard that inadequate and deceptive information is not fed into the model [
10]. Nevertheless, this approach of computing and utilizing the cutoff magnitude results in dropping a big chunk of the data, which is not suitable for operating the models. Therefore, the present research did not apply the cutoff magnitude to the data but excluded all the events with a Richter
Mw less than 3.
The seismic variables used in this study are listed in
Table 3. These include 16 traditionally used variables and the variables of longitude, latitude, and depth, and a new variable FD. The variables of depth and FD were identified by IGA as being spatial variables of intermediate significance. Therefore, to further investigate the role of the FD variable along with depth, the four used algorithms were operated with distinct sequences of input variables presented in
Table 5.
It is important to point out that the variables (X1, X2, X3, X4, and X5) with low IGA values were not removed from the input vector, which is the opposite of the widespread practice of excluding such variables. The reasoning for not excluding these variables stems from the notion that a variable’s effectiveness correspondingly hinges on the capability of the fundamental model. A practical model would benefit from the valuable information coming from less important variables and could offer improved predictions. It is also important to mention that several architectures with distinct hyperparameters were tested to locate the perfect DNN model. The model with the most excellent validation accuracy was chosen as the ideal model. The details of the perfect structure of the DNN model for variable set 3 are listed in
Table 7.
Contemplating the two variables of depth and FD, it appears that MNN and SNN were able to utilize the underlying information held by these variables. However, the DNN and RNN could not successfully exploit these two variables. Meanwhile, MNN was the most successful ML algorithm in terms of utilizing the data stored by the depth and FD variables. The deep neural structure of MNN could be a reason for such efficacy by MNN. Furthermore, this structure can obtain valuable information from minimally associated independent input variables.
To analyze the performance of the used ML and DL models in this study, the accuracy and the sensitivity measures were computed. Accuracy was selected as a generic metric for examining the general implementation of the models. The purpose of using sensitivity was to understand how each model performed for each of the four classes. More specifically, the overall performance of the used models is represented by accuracy, whereas the ability of the models to accurately perceive the earthquakes that occurred is indicated by sensitivity.
Sensitivity values for classes 1 and 4 are higher than those for classes 2 and 3. According to
Table 10, the highest sensitivity values for classes 1 and 4 occurred when the models were using variables set 1. The most straightforward explanation for this is that the magnitudes for these classes are more closely linked to the FD variable. The low sensitivity values for classes 2 and 3 relatives to classes 1 and 4 for all models are most likely due to significant noise in the magnitude data.
Even though MNN performs much better than the other considered models in terms of accuracy, the sensitivity values were not the highest for MNN, as can be seen from
Table 8,
Table 9 and
Table 10. The best models in terms of sensitivity for predicting classes 1, 2, 3, and 4 were SNN on the variables set 1, DNN on the variables set 1, RNN on the variables set 2, and MNN on the variables set 1. A closer look at the listed sensitivity results in
Table 10 reveals that optimal predictions of classes 1, 3, and 4 occurred when the models were exploiting the additional FD variable. This specifies the appropriateness and practicality of the variable, specifically for predicting large-magnitude earthquakes. Classes 3 and 4 can be predicted with the probability of good sensitivity values using the FD variables.
Moreover, the accuracy for both training and testing data for SNN and MNN, which are ML techniques, is surprisingly more than the DL techniques of DNN and RNN, as can be witnessed from
Table 8 and
Table 9. Technically, this is impossible because ML employs fewer layers for analysis, whereas DL uses more layers, which leads to more accurate results [
86,
98]. The constructed ML models demonstrated a markedly higher prediction capability than the DL models. This may mean that the DL models considered the classification problem to be linear while it was nonlinear in its nature. Additionally, the different hyperparameter settings affect the performance of ML and DL models [
99]. Even though the hyperparameters were changed, and optimal models were constructed during the training process, the choice of the hyperparameters used for the models might not be compatible with the data considered for the analysis.
The DNN model outperformed other models regarding the sensitivity values for class 1. In some cases, such as for class 2, other models outperformed DNN. Amongst the used models, DNN had the most extraordinary complexity. Therefore, in certain situations, this lower sensitivity might be due to its greater parametrization, as was previously observed in an investigation conducted by Mignan and Broccardo [
75]. The authors suggested that, due to the structured and tabular nature of catalog data and the insufficient number of calculated features, NN models with shallow structures might compete with DNNs in earthquake prediction. A few other investigations also observed such an adherence regarding the predictive ability of SNNs and deep learning [
100,
101]. However, the involvement of several hidden layers in DNN allows for one to understand features at distinct levels of perception [
98]. This was a key reason for the better performance of the DNN model as compared to other models.
After learning the superiority of the four models, the prediction abilities of the models per class were assessed. The outcomes demonstrated that when the objective was to utilize a general model to predict both high- and low-magnitude earthquakes, RNN or SNN could be a better choice. Nevertheless, as per the sensitivity analysis of classes 1 and 3, MNN or DNN can be a suitable option, as they can better detect and sense low- and moderate-magnitude earthquakes than other models. Regardless of the size of the network and the substantial number of parameters required for the training of the DNN model, the outcomes showed that this complicated model was considerably effective in employing the information from the FD and depth variables. Additionally, the SNN model outperformed other models in predicting high-magnitude earthquakes. This performance of SNN was unexpected, as its structure is comparatively straightforward, and the associations between the input variables and the higher-magnitude earthquakes are quite complicated.
From the viewpoint of a disaster management organization, any model attempting to predict earthquakes should not produce false alarms, as they can cause massive panic and economic loss [
46]. Centered on this notion, specificity,
NPV, and
PPV were computed for all four classes of the DNN model, and the results are shown in
Table 11. The specificity,
PPV, and
NPV values for class 1 are relatively higher than those in other classes. For class 4, the
PPV value of 84.10% for the DNN model is very promising.
The advantages of the proposed methods for earthquake magnitude prediction become clear after a comparison with similar studies published previously in the same region and other parts of the world. Asim, Martínez-Álvarez, Basit and Iqbal [
46] utilized four ML techniques, RNN, PRNN, LPBoost Ensemble, and Random Forest, to predict earthquakes in the Hindukush region of Northern Pakistan using eight seismic indicators. These indicators were centered on the eminent geophysical facts of GR’s inverse law, dissemination of distinctive earthquake magnitudes and seismic quiescence, and mathematically computed from the earthquake catalog of the region. The authors observed that the LPBoost Ensemble (79%) and PRNN (79%) have the highest accuracy for validation data, while the LPBoost Ensemble (65%) and RNN (64%) have the highest accuracy for the testing data. Compared to this previously conducted study, the present study used more seismic variables, and the accuracy of most of the models for validation and testing data was relatively higher. For example, the testing accuracy of SNN for variable set 2 was 89.30%, while the testing accuracy of MNN for variable set 1 was 84.9%. Moreover, the DNN model also outperforms all the used models in the previous study in terms of specificity.
Moreover, Aslam, Zafar, Khalil and Azam [
34] used eight seismic features based on seismological notions, such as the dissemination of typical earthquake extents, the eminent geophysical specifics of Gutenberg–Richter’s inverse law, and seismic quiescence for earthquake prediction in Northern Pakistan. The authors developed a hybrid classification system based on a Support Vector Regressor (SVR) and Hybrid Neural Network (HNN) for earthquakes greater than or equal to 5.5. The accuracy assessment of the SVR-HNN model revealed that the model has a specificity of 86% and a sensitivity of 61%. However, the model attained an accuracy of 79% for the testing data. Compared to the results of the present study, this previously conducted study not only used fewer variables but also attained relatively less accuracy for the developed model compared to the sensitivity results of most of the models of the present study.
Furthermore, Yousefzadeh, Hosseini and Farnaghi [
62] introduced and investigated the impact of spatial parameters on the performance of four ML models, specifically, SNN, DNN, DT, and SVM, for predicting future earthquakes’ magnitude in Iran. The results showed that the SVM and DT model achieved the highest accuracy for training data while DT and DNN achieved the highest accuracy for testing data. The authors also used different variable sets for different models and found that DNN and SVM models better detect intermediate- and high-magnitude earthquakes than other models. As the present study introduced different models than the mentioned study, the outcomes of this study also concluded that the DNN model is better than the other practiced models. This establishes the superiority of DNN compared to other conventional techniques.
Based on the outcomes of the present study, it can be stated that the adopted methods can be assessed for their accuracy in other locations by considering spatial variables. Then, a comparison can be carried out to highlight the limitations or adequacies of the methods for the two cases.
6. Conclusions
In the present study, two ML algorithms of SNN, MNN, and two DL algorithms of RNN, and DNN, were utilized to predict short-term earthquakes in the Northern Part of Pakistan, a seismically active region. An additional seismic variable named FD was used, along with the most frequently utilized seismic variables defined in the earlier research. Three different variable sets containing different variables were separately utilized to check the performance of the individual model in response to different variables. When used in different variable sets, the variables of depth and FD facilitated the accuracy of the used ML and DL earthquake prediction models to a certain extent.
The outcomes demonstrated adequate performances of DNN and SNN in predicting the low-magnitude earthquakes, respectively. The DNN model demonstrated an accuracy of 98% for variables set 2 and class 1, whereas the accuracy was 94% for variables set 1. The SNN model showed an accuracy of 95% for variables set 1 and class 1. However, the performance of both RNN and SNN was more encouraging in dealing with high-magnitude events. The SNN model exhibited an accuracy of 95.80% for variables set 2 and class 4, while the RNN model demonstrated an accuracy of 88.30% for variables set 1 and class 4.
6.1. Limitations
The present study only used historical earthquake records from two open-access sources. For future studies, it is important to acquire data from multiple sources to better represent the documented earthquake events in the area. Moreover, it could also be beneficial to acquire some field data from the relevant authorities in the area. Furthermore, different input variables can also be used along with the variables used in this study to check for their influence on the model performance.
6.2. Implications and Future Research
The model presented in this study can be used to predict earthquakes with low and high magnitudes, as advocated by the accuracy assessment results. Moreover, earthquake prediction systems can be a great deal of help for the concerned authorities. An alert triggered by such a system can allow for controls to activate supplies and halt critical damage-causing systems such as electricity and nuclear power plants to avoid fatalities.
Future research can assess the usability of further DNN architectures, such as CNNs, for earthquake prediction and contrast their functioning with other techniques to establish the most superior model. Additionally, the effect of the FD variable on the performance of other contemporary and conventional methods can also be assessed in the context of other seismic regions.

 ,
, 




{kind=link}
{kind=link}
{kind=link}