2.1. Study Area and Data
Lagos was the former administrative capital of Nigeria, and it remains the hub of economic activities within the country. The population of the city keeps increasing, and it is projected that it is approaching ‘megacity’ status [
20]. High population density, economic activities, and transportation generate large volumes of air pollutants, such as PM
2.5 [
21]. For instance, due to the shortfall in power supply, business owners spend a huge chunk of their operating costs on the running of fossil-fuel-powered generators that generate noise and air pollution [
22]. Moreover, Zeng et al. [
23] showed that the concentration of PM
2.5 is Lagos is higher than those recorded in Hong Kong. In the study presented in this paper, PM
2.5 data collected over 15-min intervals over a 6-month period at a location at the University of Lagos were used to assess the effectiveness of using contemporary techniques for modelling and forecasting the concentration of PM
2.5.
The concentration of PM2.5 was measured using the EarthSense Zephyr air quality sensor; meteorological variables (temperature and relative humidity) were also quantified. These data (PM2.5 concentration and the meteorological variables) were used to train the univariate and multivariate models developed in this study. Subsequently, the trained models were used to generate forecasts of PM2.5 concentration.
2.2. Modeling Techniques
As stated previously, seven methods were used to predict the PM
2.5 concentration. A regression-based method—i.e., autoregressive integrated moving average (ARIMA)—was applied in this study because it has been extensively applied in previous research on air pollution forecasting [
24]. However, the ARIMA model does not have the capacity to capture nonlinear relationships. Therefore, the predictive performance of machine learning methods (such as support-vector machines, neural networks, and random forests, among others) was compared with the ARIMA model. The nonlinear relationships between the variables included in machine learning models are difficult to interpret. However, these models can be interpreted through the use of sensitivity analysis (i.e., the improvement in predictive accuracy through the inclusion or removal of certain variables).
ARIMA: ARIMA is a time-series modelling approach used for forecasting. The ARIMA model has three elements, i.e., an autoregression model, a moving average model, and differencing [
25]. ARIMA models strive to capture information present in the autocorrelation of the data and use it for modelling and forecasting purposes. The ARIMA model can be mathematically expressed as:
where
represents the differenced time-series data for PM
2.5 concentration,
is the constant, and
is the error term. The order of differencing of the time-series data is ‘d’. The ‘predictors’ on the right-hand side of Equation (1) include the lagged values of PM
2.5 concentration and lagged errors. The
p,
d, and
q elements of the ARIMA model are automatically determined using a variant of the Hyndman–Khandakar algorithm [
26].
Exponential smoothing: This method was introduced in the late 1950s [
27,
28,
29], and has been applied to forecasting problems in several fields; it is an extension of the simple moving average system in which past observations are weighted equally based on the averages of a number of subsets of the full dataset; for the exponential smoothing method, the weighting assigned to past events exponentially decreases over time. The formula for the exponential smoothing can be expressed as:
where
is the forecast of PM
2.5 concentration at the next time period,
is the forecast of PM
2.5 concentration at time (
t),
is the actual value of PM
2.5 concentration at time (
t), and
α is a weight called the exponential smoothing constant (0 ≤
≤ 1).
Exponential smoothing has been used for modelling and forecasting of several problems, e.g., emergency department visits [
30] and electricity consumption [
31], among others. However, the weights attached to these previous values decay exponentially with respect to time [
26]. Thus, the weights attached to recent observations (such as
yt−1) are higher than those of the older observations (such as
yt−6).
Prophet model: This is one of the modelling techniques applied in the current study. According to Hyndman and Athanasopoulos [
25], the Prophet model is a nonlinear regression model that was introduced by Facebook [
32]. The Prophet model can be expressed in mathematical form as shown in Equation (3). This method works best with data that have ‘strong seasonality’. For example, this technique has been used for the forecasting of groundwater levels [
33] and variations in oil production [
34].
where
describes a piecewise linear trend,
s(
t) describes the various seasonal patterns,
h(
t) captures the holiday effects, and
is a white noise error term.
Neural network (NN): Neural networks are a modelling technique that is inspired by nature. The neural network model mimics the human brain, and captures complex nonlinear relationships between dependent and independent variables. Two types of neural network models were used in this study: (1) neural network autoregression (NNAR), and (2) a neural network model based on multiple variables. The NNAR model is similar to the ARIMA model in terms of the variables included in the model. The NNAR model is a neural network model with 3 layers, i.e., 1 input, 1 hidden, and 1 output. For instance, an NNAR (9, 4) model is a neural network model that predicts
using
as inputs and 4 nodes in the hidden layer. The number of lags and number of nodes to be included are determined automatically as described in [
25].
Several variables, including meteorological factors (see
Table 1) and the PM
2.5 concentration, are included in the second neural network model. The second type of neural network model uses the information contained in previous values of the PM
2.5 concentration and independent variables to predict future values of the PM
2.5 concentration.
Random forest (RF): Random forest is an ensemble learning method that generates a large number of decision trees during the training process. The bootstrapping of the training dataset ensures that each decision tree that forms part of the random forest is unique. The prediction generated by the random forest model is an average of the output of each of the decision trees (see Equation (4)). Random forests prevent overfitting of the model to the training data. Reduced likelihood of overfitting is achieved through the integration of trees of various sizes and the averaging of the results.
where
is the random forest prediction, and
N is the number of runs over the trees in the random forest.
The forecast generated by the random forest model is the average of the outputs of each decision tree.
Support-vector machine (SVM): The SVM was initially developed by Vladimir Vapnik and his colleagues [
35]. The main goal of the SVM algorithm is to identify an optimal hyperplane (the formula for the hyperplane is presented in Equation (5)) that linearly separates the collected data into two groups.
where
w is the weight vector,
x is the input vector, and
b is the bias.
The SVM algorithm was initially used for solving classification problems; however, it was extended with the adoption of the ε-insensitive loss function, and it can be applied to regression tasks (i.e., prediction of numbers) [
36]. The SVM model uses nonlinear mapping to project input vectors in a higher dimensional space. The SVM model is able to always converge to optimal weights, and this gives SVM an advantage over the neural network model. In this study, the radial basis function (RBF) kernel was utilised, and the tuned hyperparameters of the SVM model are
and C.
Extreme gradient boosting (XGBoost): XGBoost is a relatively new machine learning algorithm that is an ensemble of decision trees that utilise the gradient boosting framework. The method was developed by Chen and Guestrin in 2016 [
37]. The main intuition behind the XGBoost model is that the ensemble combines the output of a large number of decision trees to produce better predictions. XGBoost is an ensemble of gradient boosted decision trees. Moreover, the gradient boosting technique, which is a method introduced by Friedman [
38], builds an ensemble of models through an interactive process aimed at improving accuracy—it initializes with a single model; subsequently, new models, which learn from the errors of the previous model, are added to the ensemble to improve the accuracy of the forecast. The predictions from the XGBoost model are computed using an additive strategy:
where
is the test sample,
is the number of samples,
is the
nth tree model, and
n is the number of all trees in the model.
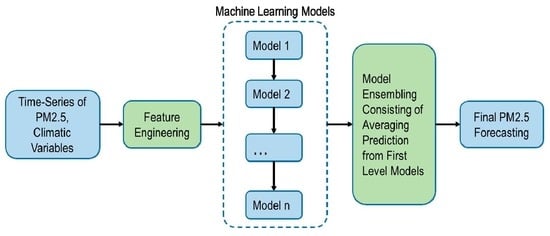
2.3. Modeling Process
The proposed models were used to generate predictions of the average hourly concentrations of PM
2.5. The data used to estimate the models were collected using the air pollution sensor described in the previous section. To evaluate the relevance of the metrological variables, two groups of models (i.e., with and without metrological variables) were developed. The ARIMA model was used as the baseline model. The decision to apply the ARIMA model was informed by its extensive application in previous studies on air pollution forecasting [
39]. The forecasting performances of the other modelling techniques were compared with those of the ARIMA model. The modelling process was carried out in 4 stages: (1) data cleaning and preparation, (2) fitting the data to the models, (3) using the estimated model for forecasting, and (4) forecast evaluation. All of the models were implemented using the R programming software [
40] and several packages, including
modeltime,
modeltime.ensemble,
timetk,
tidyverse [
41,
42], and
tidymodels [
43], among others. This software and these packages provide a platform for the application of statistical and machine learning models.
Data cleaning and preparation: The air pollution measuring device collected the PM
2.5 concentration and meteorological data at 15-min intervals. These data were aggregated and converted into hourly time-series data on PM
2.5 concentration, temperature, and relative humidity. As shown in previous research, the data cleaning process can have an impact on the accuracy of forecasting [
44]; thus, the linear interpolation approach was used to replace the outliers that existed in the collected data. The time-series data on PM
2.5 concentration are presented in
Figure 1. The descriptive statistics for the PM
2.5 concentration and metrological data are presented in
Table 1.
The size of the dataset has a significant impact on the reliability of forecasts generated from models. To improve the accuracy of forecasting, the use of feature extraction methods (such as principal component analysis), dummy variables, Fourier series, and featuring engineering has been suggested in previous research [
25,
45,
46]. Similarly, the outcome of forecasting competitions has shown that the use of feature engineering (e.g., extracting additional features out of the time data) improves the accuracy of forecasts. Therefore, in the present study, the ‘
modeltime’ package in the R programming software was used to create calendar-related features that were added to the multivariate models (i.e., models that contain predictor and outcome variables). The variables incorporated into the multivariate models, along with their justifications, are described and explained in the Results section of this paper.
2.4. Forecast Accuracy
PM2.5 concentration, relative humidity, and ambient temperature data covering the period between 1 December 2020 and 28 May 2021 (4283 data points) were collected and utilised for this study. The data were divided into two groups: training (4259 data points) and test (24 data points). The models were estimated using the training dataset. Subsequently, the trained models were used to generate forecasts for the previous 24 h, i.e., model validation. Adequate care was taken to ensure that there was no data leakage. To evaluate the accuracy of the forecasts generated by the models, the actual test data were compared with the forecast data.
Several metrics are usually used for evaluating the quality of the predictive accuracy of forecast models; they are usually classified into scale-dependent, percentage-based, relative-error-based, and relative measures. Hyndman and Koehler [
47] identified the limitations of these four groups of metrics. For instance, it was stated that the mean absolute percentage error (MAPE) treats positive and negative errors in a different way [
47]. Based on these limitations, the mean absolute scaled error (MASE) was identified as a suitable method for the evaluation of forecast accuracy. In the present study, MAE (mean absolute error), MASE, and root-mean-square Error (RMSE) were adopted. The use of RMSE is attributed to the extent of its usage in similar previous studies [
48,
49]. RMSE can be calculated as:
where
is the forecast error at time
t,
represents the actual value of PM
2.5 concentration at time
t, and
denotes the forecast of
.
where
n is the total number of values.
MASE can be computed as follows [
47]:
where:
and
MAEnaive is the MAR for the naïve model.
In forecasting research, it is expected that complex/advanced modelling techniques will generate better forecasts when compared with simple models, such as the naïve model. If a complex model produces a poor forecast when compared to a simple model, then it should be discarded [
25]. If the value of MASE is greater than 1, this means that the model produces a forecast that is worse than that of the naïve model. A lower value (i.e., a value close to 0) of MASE indicates that the predictive accuracy of the model is better when compared with the naïve model.


 ,
, 







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}