Production of high-quality steel using the basic oxygen furnace (BOF) requires a deep understanding of numerous complex chemical reactions and accurate end-point control [
1]. In BOF, oxygen is blown into the liquid metal, which leads to a conversion of molten pig iron and scraps into liquid steel. Pig iron contains different types of impurities such as carbon, sulfur, manganese, and phosphorous. A high content of phosphorous in the final product leads to poor mechanical properties such as low ductility and increased brittleness, thus, increasing the probability of cracking during deformation and welding [
2]. The process of removing phosphorous from pig iron to obtain high-quality steel in BOF is known as dephosphorization. In recent years, the phosphorous content in iron ores has increased significantly, making the dephosphorization process more critical [
3]. Research has shown that for a given basicity and carbon content, the presence of iron oxide has a greater effect on dephosphorization compared to dissolved oxygen in steel [
4]. The partition ratio between slag and steel quantifies the ability of phosphorous holding onto the slag, given by,
, which indicates the extent of phosphorous removal in the finished steel. Therefore, the extent of dephosphorization can be measured by
.
Over the years, industries have tried to develop analytical tools to control phosphorous to maintain the quality of products, and many thermodynamics-based mathematical models were developed. In 1974, Balajiva and Vajragupta studied the influences of different chemical compositions of slag on phosphorous removal [
5]. The temperature of BOF was kept constant while %CaO, %FeO, and %P2O5 were considered as the controlling factors. Their results showed that an increase in CaO and FeO contents increased the extent of dephosphorization. Suito and Inoue discovered that the phosphorous content in slag is reduced when MnO is added to the slag [
6]. Later in 2006, Suito and Inoue conducted experiments to study the behavior of phosphorous transfer from CaO-Fe
tO-P
2O
5(-SiO
2) slags to CaO particles. Based on the results, they developed an equation for the phosphorous partition at the metal-slag interface, given by
, where
T represents the
equilibrium temperature [
7]. Assis and Tayeb used 100% direct reduced iron (DRI) in an electric arc furnace (EAF) to investigate the phosphorous equilibrium in different slags [
8]. The study has shown that the presence of alumina in slag significantly reduces the phosphorous partition coefficients due to the inactivity of iron oxide. In addition, an equation was developed by Tayeb et al. to describe the relation between phosphorous partition coefficients, slag temperature, and composition, given by,
. Although simulation of the dynamic reactions is important and effective in many cases of end-point predictions, there are still many uncertainties in the BOF process that are not being captured in even
state-of-the-art thermodynamic models owing to the overwhelming numbers of chemical reactions taking place in the process. Therefore, data-driven models are more likely to capture the true non-linear, complex, and stochastic nature of the relationships that exist among the relevant variables in a BOF process.
There are many advantages of using data-driven models over thermodynamic models, and the former one unites and simplifies many complex interactions between factors. A data-driven model learns from large data and evaluates the affecting factors while using none or limited domain knowledge. This factor becomes increasingly handy when the underlying reactions operate at conditions far away from equilibrium. In addition, validation of results is also crucial in building a reliable model used for prediction, and a machine learning (ML) model is a great choice for the situation. ML includes all algorithms that allow the computer to learn from often large data sets and then makes intellectual decisions based on the feedback. The algorithms are built upon the data themselves as it updates and learns from the training data. Recently, multiple linear regression (MLR) model was used to analyze dephosphorization data from the BOF of two steelmakers with different slag basicity and temperatures [
9]. Results showed that by reducing the tapping temperature, the phosphorous distribution can be better controlled during steel making. Similarly, Drain et al. developed partition relations between minor slag constituents and dephosphorization of steel and validated those by fitting against a large industrial data set [
3]. Their investigation highlighted several important factors; for example, Al
2O
3 was found to have a positive relation with a phosphorous partition at high oxygen potentials and vice versa. Bae et al. explored a range of ML models such as artificial neural network (ANN) and support vector regression (SVR) for the end-point prediction of phosphorous content using a three-year span production data [
10]. The 10-fold validation results showed that ANN and SVR perform much better in providing accurate predictions than other algorithms such as extreme gradient boosting (XGBoost) and K-nearest neighbor (KNN). Wang et al. discussed about a multi-level recursive regression model to predict end-point phosphorus [
11]. He and Zhang employed principal component analysis combined with a back-propagation neural network on data obtained from a BOF process [
12]. Further, Gao et al. introduced an ensemble algorithm combining k-nearest neighbor-based weighted twin support vector regression and Lévy flight whale optimization algorithm [
13]. Duo and Zhang implemented a novel multiclass classifier decision tree twin support vector machine based on kernel clustering algorithm [
14]. More recently, Phull et al. studied a decision tree-based twin support vector machine to assess the performance of a dephosphorization process using end-point phosphorus content in two BOF steelmaking plants [
15]. Indeed, these works imply significant and successful applications of machine learning models for the end-point predictions in BOF. However, either most of these models project and explore dephosphorization as a regression problem [
10,
11], or not many machine learning models are applied specifically to the dephosphorization process, but rather used to study other measurable components of a BOF process [
13,
14]. As a result, a detailed investigation is required to further explore the potential of machine learning classifiers (rather than regressors), e.g., support vector machines (SVMs) or other variants of SVM to study the non-linear complex relationships among variables in a BOF process, specifically for dephosphorization.
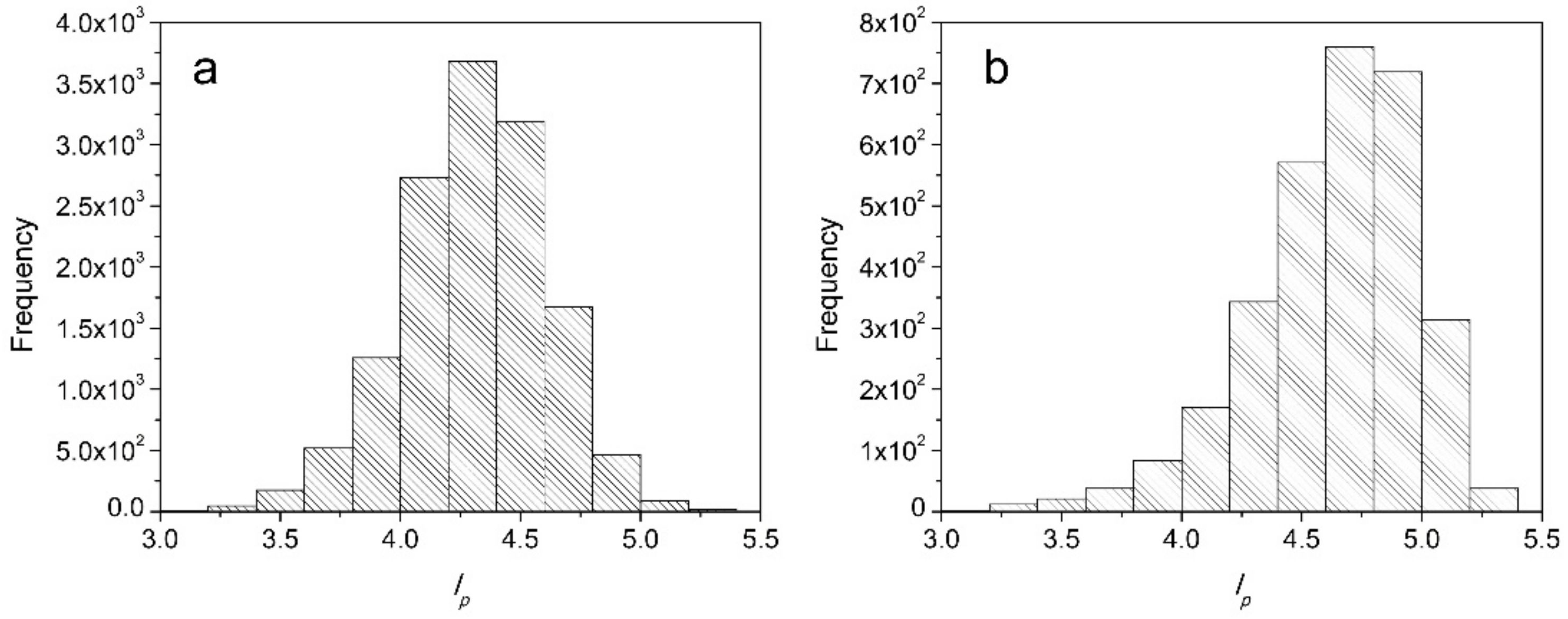
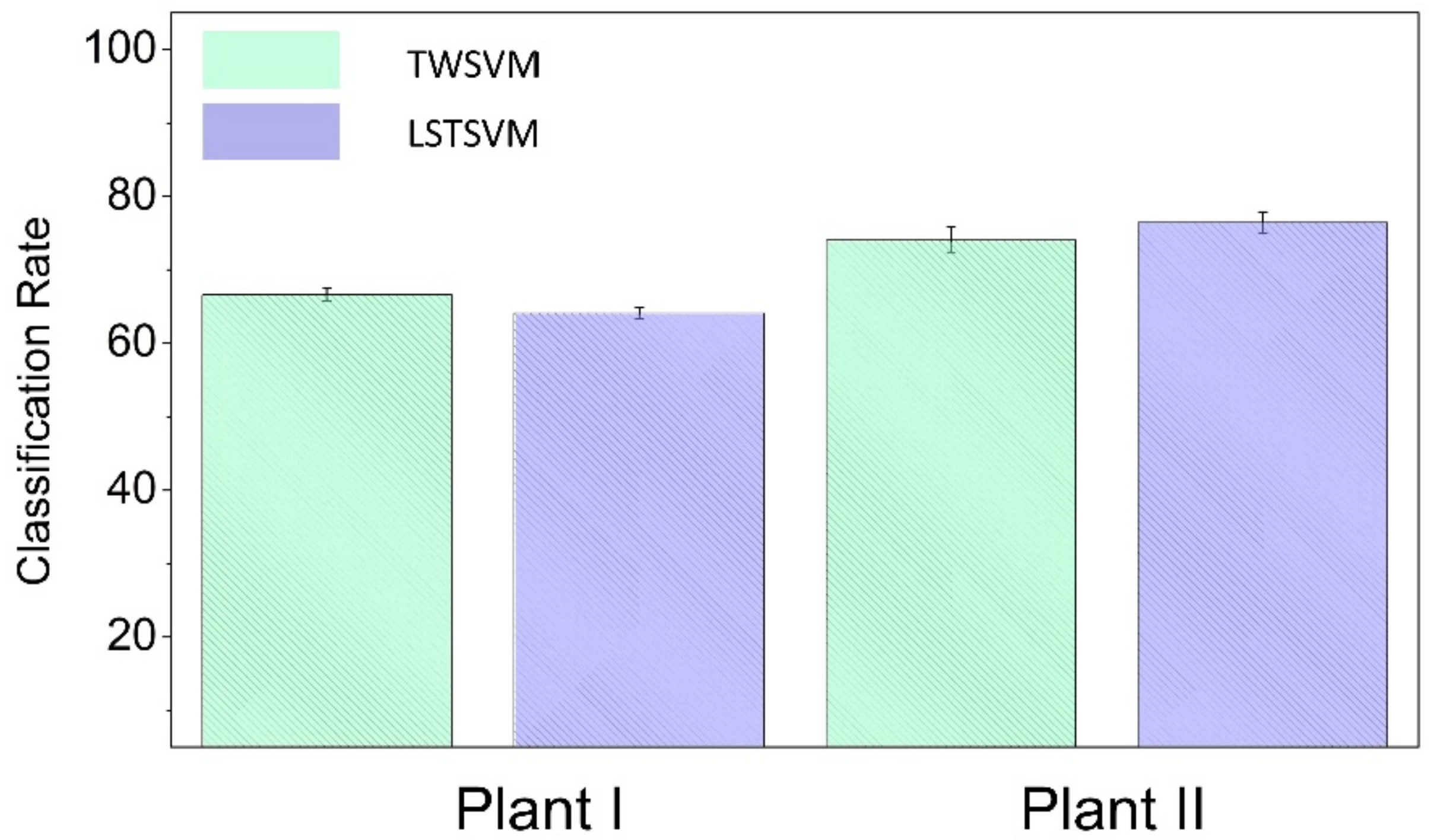
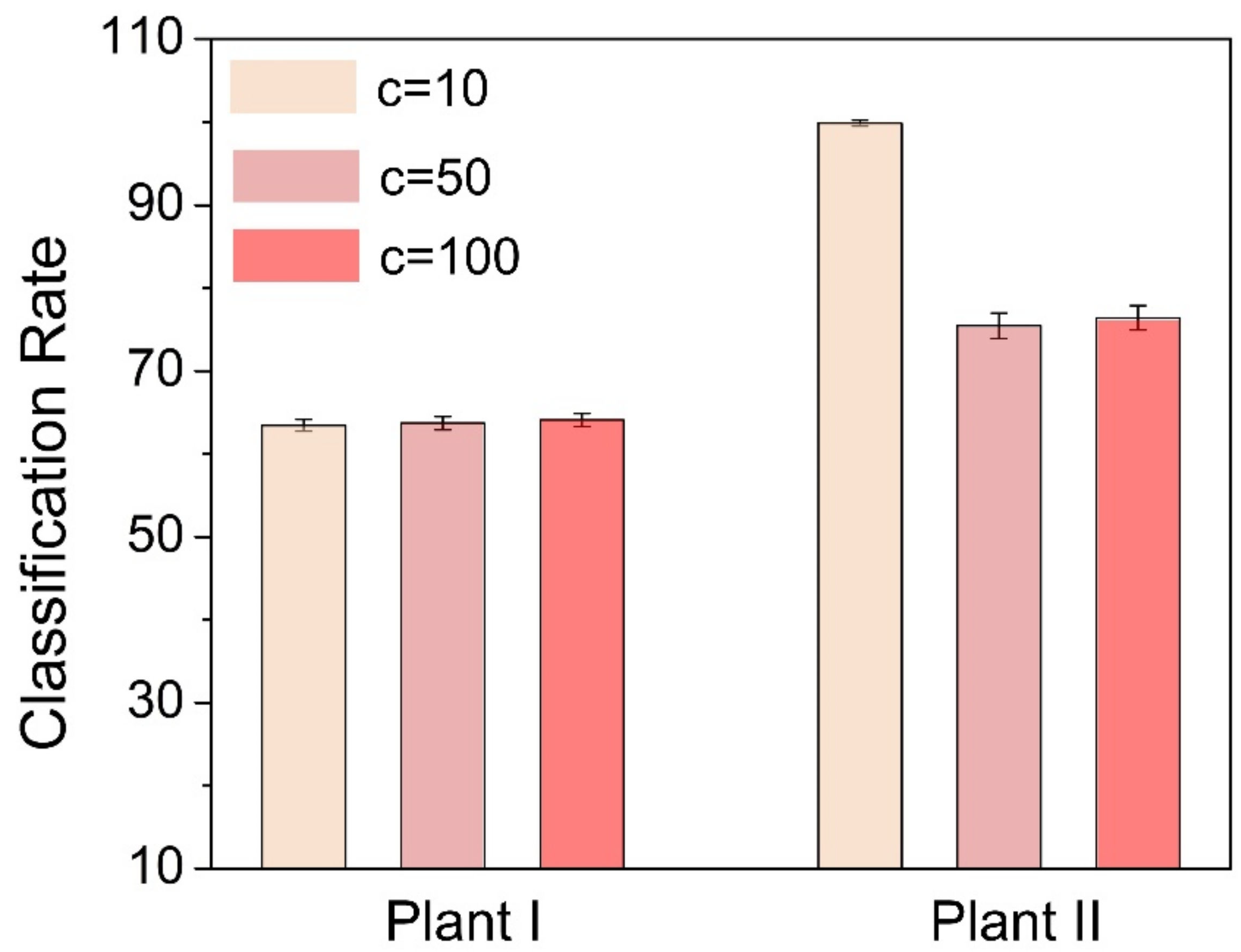
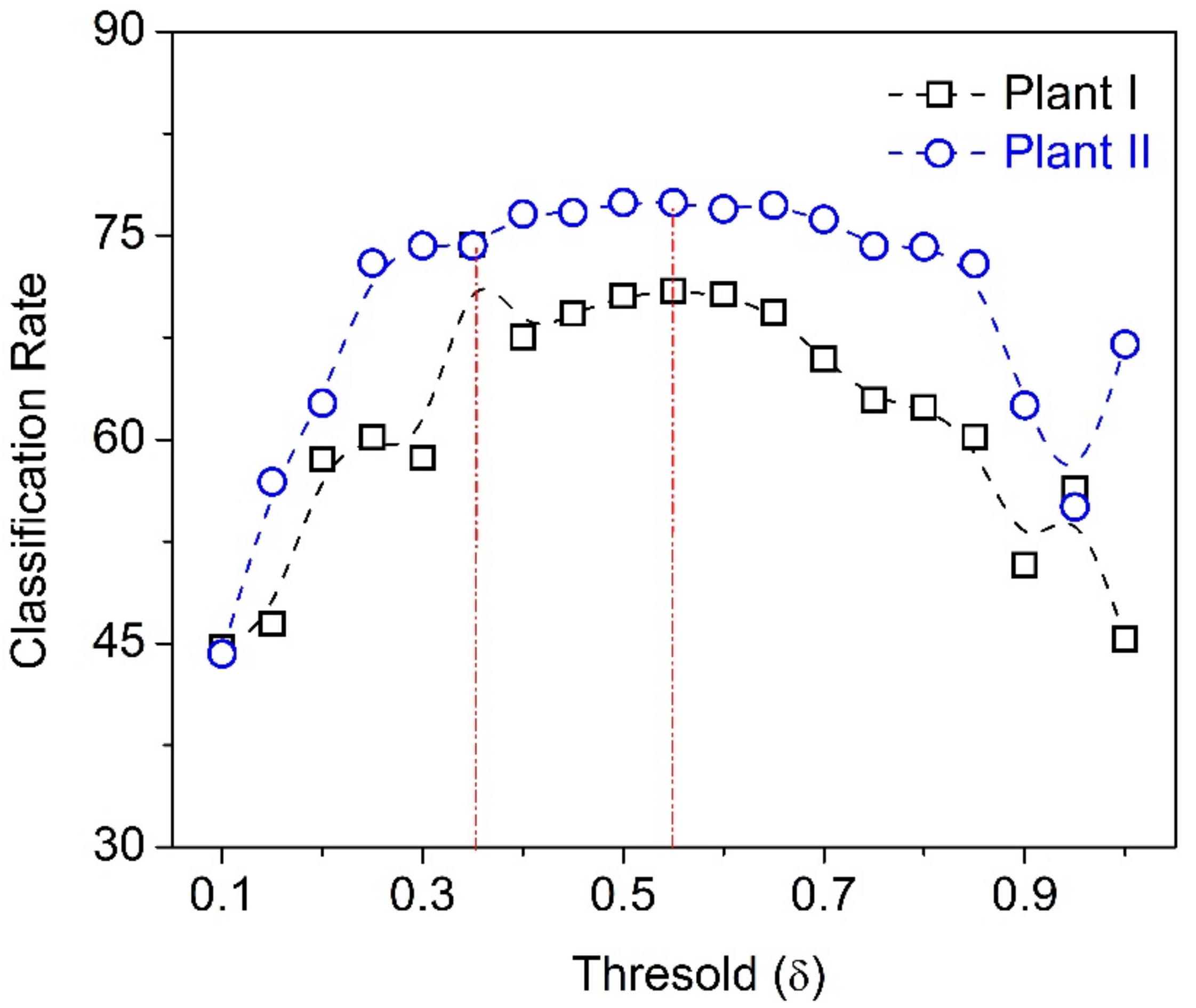
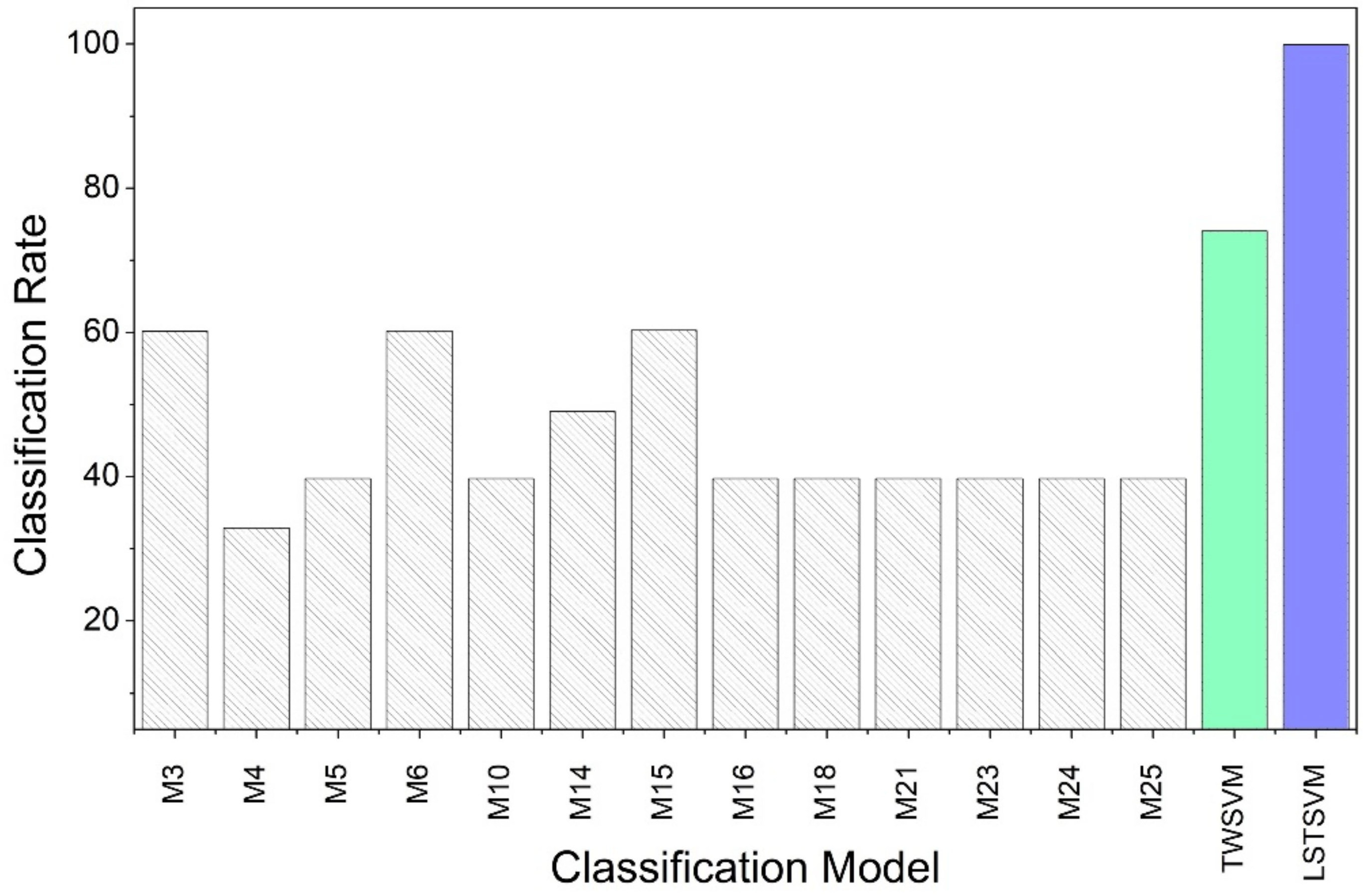
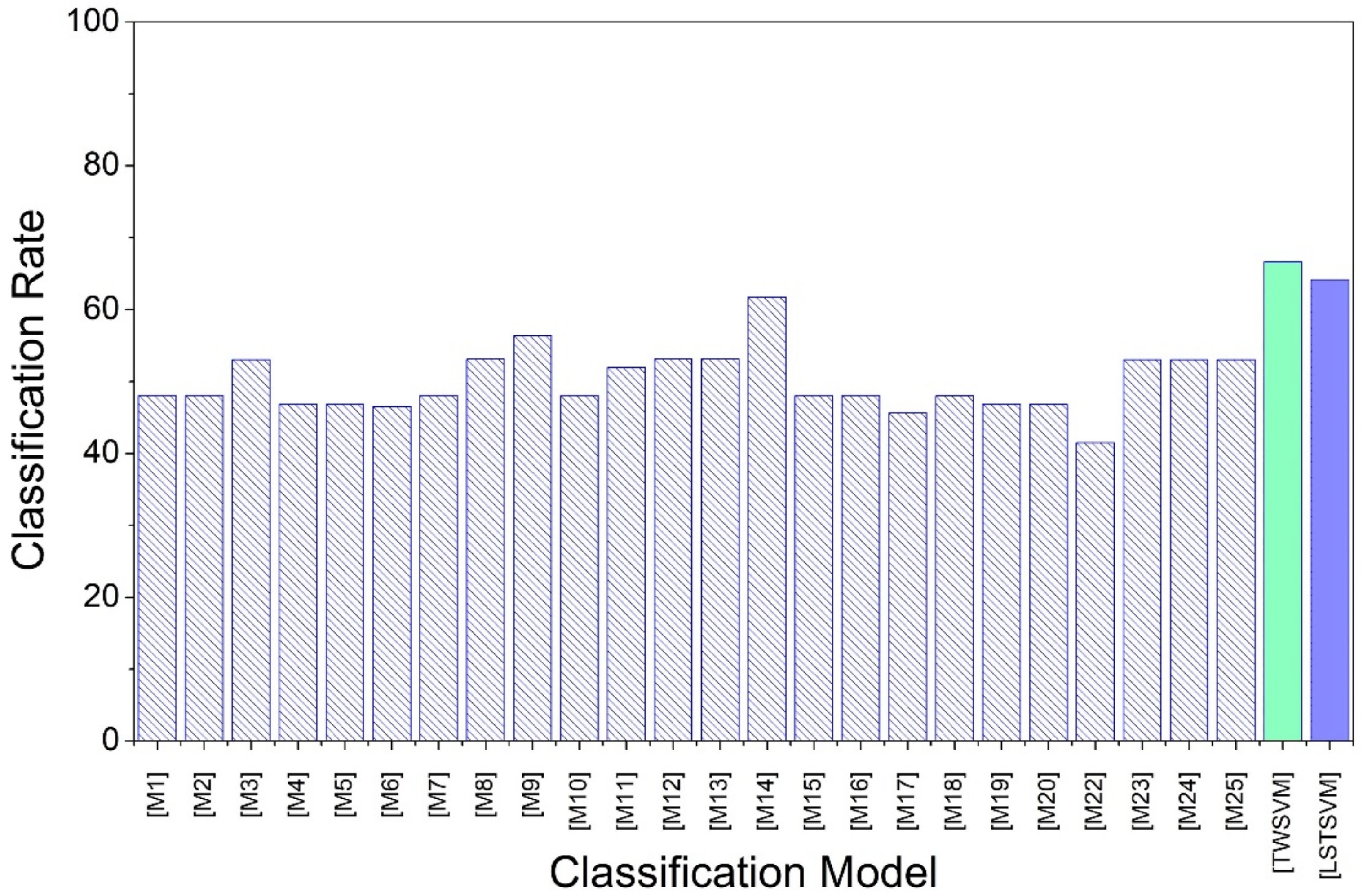
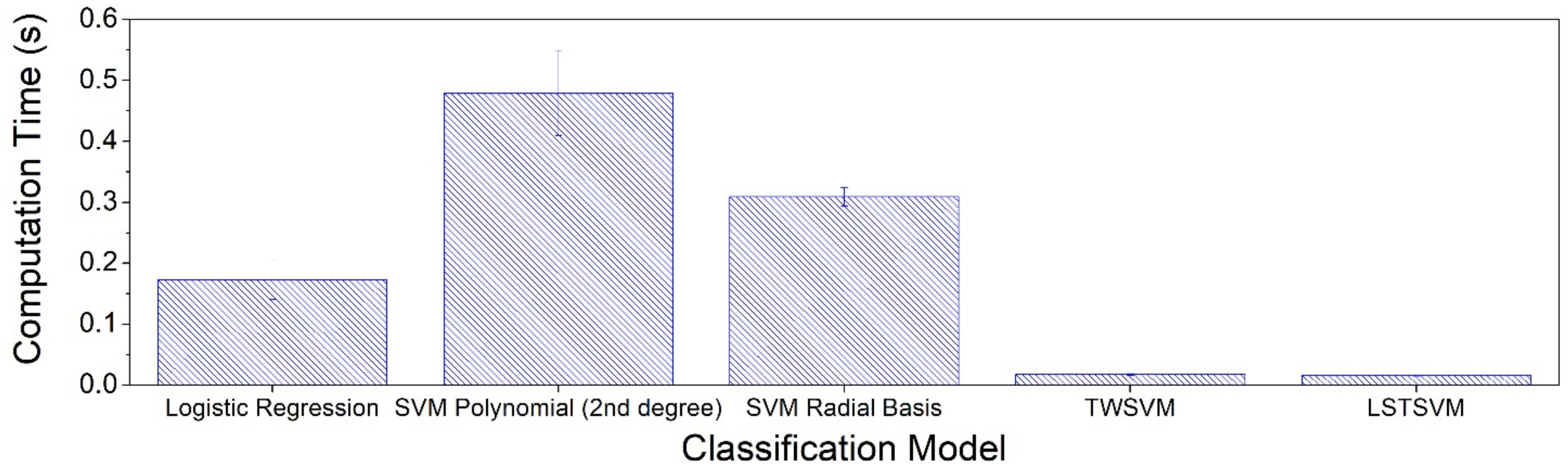
In this article, following the work of Phull et al., ML models are developed using twin support vector machine (TWSVM) and least square twin support vector machine (LSTSVM) for the end-point phosphorous prediction [
15]. These models are applied to BOF plant data of two steelmakers in North America. Phosphorous partition is quantified, and the measure is used to classify steel samples based on the chemical composition of slag. The partition values are labeled as Classes 1 and 2 by implementing the K-means clustering algorithm [
16,
17]. The degree of phosphorous removal is represented through the partition labels. The goal is to implement ML algorithms to predict the partition labeling based on the chemical composition of slag as well as the tapping temperature. TWSVM and LSTSVM are the two ML methods incorporated in the training and testing process. In general, the SVM algorithm determines the best hyperplane as the decision boundary, separating the data into classes. Unlike SVM, TWSVM determines two non-parallel hyperplanes, each fitting one class of data [
18,
19]. In addition, the computation cost is much less than that of SVM because TWSVM solves a pair of much simplified quadratic programming problems (QPPs). Therefore, for a complex situation such as the phosphorous end-point prediction, TWSVM is preferred over general SVM. LSTSVM is a more appropriate algorithm than TWSVM for data sets with unbalanced classes, as it chooses a different parameter for each class [
20,
21]. LSTSVM and TWSVM are also preferred over regular SVM when it comes to the large scale and high complexity of QPPs. Consequently, using the mentioned classification algorithms, gradation of the extent of phosphorus removal can be obtained, which can be used to classify a final batch of BOF output to have superior or inferior quality of steel.














{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}