
Development of Data-Driven Machine Learning Models for the Prediction of Casting Surface Defects


Abstract
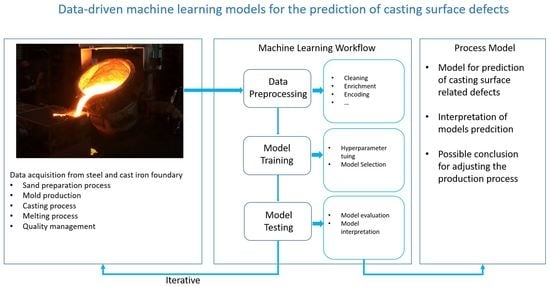
:
1. Introduction
Casting Surface Defects
2. Machine Learning
2.1. Machine Learning Workflow
- Data acquisition;
- Data pre-processing;
- Training the model;
- Model evaluation.
2.1.1. Data Acquisition
2.1.2. Data Pre-Processing
2.1.3. Training the Model
- Training set: used to initially train the algorithm and teach it how to process information;
- Testing set: used to access the accuracy and performance of the model.
- Mean absolute error (MAE): is a loss metric corresponding to the expected value of the absolute error loss. If is the predicted value of the i-th sample, and is the corresponding true value, n is the number of samples, the MAE estimated over n is defined as:
- Mean squared error (MSE): is a loss metric corresponding to the expected value of the squared error. MSE estimated over n is defined as:
- Root mean square error (RMSE): is the square root of value obtained from MSE:
- score: represents the proportion of variance of y that has been explained by the independent variables in the model. It provides an indication of fitting goodness and, therefore, a measure of how well unseen samples are likely to be predicted by the model:
- Root mean squared logarithmic error (RMSLE): computes a risk metric corresponding to the expected value of the root squared logarithmic error:
2.1.4. Model Evaluation
2.2. Machine Learning Algorithm
2.2.1. Ridge Regression
2.2.2. Random Forest Regression
2.2.3. Extremely Randomized Trees Regression
2.2.4. XGBoost
2.2.5. CatBoost
2.2.6. Gradient Boosting Regression
2.3. Model Interpretation
- The first one is global interpretability—the collective SHAP framework can show how much each predictor contributes, either positively or negatively, to the target variable. The features with positive sign contribute to the final prediction activity, whereas features with negative sign contribute to the prediction inactivity. In particular, the importance of a feature i is defined by the SHAP as follow:Here, is the output of the ML model to be interpreted using a set of S of features, and N is the complete set of all features. The contribution of feature is determined as the average of its contribution among all possible permutations of a feature set. Furthermore, this equation considers the order of feature, which influence the observed changes in a model’s output in the presence of correlated features [30].
- The second benefit is local interpretability—each observation obtains its own set of SHAP framework. This greatly increases its transparency. We can explain why a case receives its prediction and the contributions of the predictors. Traditional variable importance algorithms only show the results across the entire population but not for each individual case. The local interpretability enables us to pinpoint and contrast the impact of the factors.
- Third, SHAP framework suggests a model-agnostic approximation for SHAP framework, which can be calculated for any ML model, while other methods use linear regression or logistic regression models as the surrogate models.
3. Experiments and Results
3.1. Introduction to Dataset
3.2. Experiments Settings
3.3. Experiments Results
3.4. Global Model Interpretation Using SHAP
4. Discussion and Conclusions
Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Kommission, E. Mitteilung der Kommission an das Europäische Parlament, den Europäischen Rat, den Rat, den Europäischen wirtschafts- und Sozialausschuss und den Ausschuss der Regionen: Der Europäische Grüne Deal 2019. Available online: https://eur-lex.europa.eu/legal-content/DE/TXT/?uri/ (accessed on 1 October 2021).
- Thiede, S.; Juraschek, M.; Herrmann, C. Implementing cyber-physical production systems in learning factories. Procedia Cirp 2016, 54, 7–12. [Google Scholar] [CrossRef] [Green Version]
- Lee, J.; Noh, S.D.; Kim, H.J.; Kang, Y.S. Implementation of cyber-physical production systems for quality prediction and operation control in metal casting. Sensors 2018, 18, 1428. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Ferguson, M.; Ak, R.; Lee, Y.T.T.; Law, K.H. Automatic localization of casting defects with convolutional neural networks. In Proceedings of the 2017 IEEE International Conference on Big Data (Big Data), Boston, MA, USA, 11–14 December 2017; pp. 1726–1735. [Google Scholar]
- Fernández, J.M.M.; Cabal, V.Á.; Montequin, V.R.; Balsera, J.V. Online estimation of electric arc furnace tap temperature by using fuzzy neural networks. Eng. Appl. Artif. Intell. 2008, 21, 1001–1012. [Google Scholar] [CrossRef]
- Tsoukalas, V. An adaptive neuro-fuzzy inference system (ANFIS) model for high pressure die casting. Proc. Inst. Mech. Eng. Part B J. Eng. Manuf. 2011, 225, 2276–2286. [Google Scholar] [CrossRef]
- Dučić, N.; Jovičić, A.; Manasijević, S.; Radiša, R.; Ćojbašić, Ž.; Savković, B. Application of Machine Learning in the Control of Metal Melting Production Process. Appl. Sci. 2020, 10, 6048. [Google Scholar] [CrossRef]
- Bouhouche, S.; Lahreche, M.; Boucherit, M.; Bast, J. Modeling of ladle metallurgical treatment using neural networks. Arab. J. Sci. Eng. 2004, 29, 65–84. [Google Scholar]
- Hasse, S. Guß-und Gefügefehler: Erkennung, Deutung und Vermeidung von Guß-und Gefügefehlern bei der Erzeugung von Gegossenen Komponenten; Fachverlag Schiele & Schoen: Berlin, Germany, 2003. [Google Scholar]
- Parsons, S. Introduction to machine learning by Ethem Alpaydin, MIT Press, 0-262-01211-1, 400 pp. Knowl. Eng. Rev. 2005, 20, 432–433. [Google Scholar] [CrossRef]
- Mueller, J.P.; Massaron, L. Machine Learning for Dummies; John Wiley & Sons: Hoboken, NJ, USA, 2021. [Google Scholar]
- Bishop, C.M. Pattern recognition. Mach. Learn. 2006, 128, 89–93. [Google Scholar]
- Ioffe, S.; Szegedy, C. Batch normalization: Accelerating deep network training by reducing internal covariate shift. In Proceedings of the 32nd International Conference on Machine Learning, Lille, France, 6–11 July 2021; Bach, F., Blei, D., Eds.; PMLR: Lille, France, 2015; Volume 37, pp. 448–456. [Google Scholar]
- Breiman, L. Random forests. Mach. Learn. 2001, 45, 5–32. [Google Scholar] [CrossRef] [Green Version]
- Breiman, L.; Friedman, J.H.; Olshen, R.A.; Stone, C.J. Classification and regression trees. Belmont, CA: Wadsworth. Int. Group 1984, 432, 151–166. [Google Scholar]
- Breiman, L. Bagging predictors. Mach. Learn. 1996, 24, 123–140. [Google Scholar] [CrossRef] [Green Version]
- Freund, Y.; Schapire, R.E. A decision-theoretic generalization of on-line learning and an application to boosting. J. Comput. Syst. Sci. 1997, 55, 119–139. [Google Scholar] [CrossRef] [Green Version]
- Geurts, P.; Ernst, D.; Wehenkel, L. Extremely randomized trees. Mach. Learn. 2006, 63, 3–42. [Google Scholar] [CrossRef] [Green Version]
- Chen, T.; Guestrin, C. Xgboost: A scalable tree boosting system. In Proceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining; ACM: New York, NY, USA, 2016; pp. 785–794. [Google Scholar]
- Prokhorenkova, L.; Gusev, G.; Vorobev, A.; Dorogush, A.V.; Gulin, A. CatBoost: Unbiased boosting with categorical features. arXiv 2017, arXiv:1706.09516. [Google Scholar]
- Ribeiro, M.T.; Singh, S.; Guestrin, C. “Why should i trust you?”. Explaining the predictions of any classifier. In Proceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining; ACM: New York, NY, USA, 2016; pp. 1135–1144. [Google Scholar]
- Shrikumar, A.; Greenside, P.; Kundaje, A. Learning important features through propagating activation differences. In Proceedings of the 34th International Conference on Machine Learning, Sydney, Australia, 6–11 August 2017; Precup, D., Teh, Y.W., Eds.; PMLR: Lille, France, 2017; Volume 70, pp. 3145–3153. [Google Scholar]
- Antwarg, L.; Miller, R.M.; Shapira, B.; Rokach, L. Explaining Anomalies Detected by Autoencoders Using SHAP. arXiv 2019, arXiv:1903.02407. [Google Scholar]
- Lundberg, S.; Lee, S.I. A unified approach to interpreting model predictions. arXiv 2017, arXiv:1705.07874. [Google Scholar]
- Štrumbelj, E.; Kononenko, I. Explaining prediction models and individual predictions with feature contributions. Knowl. Inf. Syst. 2014, 41, 647–665. [Google Scholar] [CrossRef]
- Datta, A.; Sen, S.; Zick, Y. Algorithmic transparency via quantitative input influence: Theory and experiments with learning systems. In Proceedings of the 2016 IEEE Symposium on Security and Privacy (SP), San Jose, CA, USA, 22–26 May 2016; pp. 598–617. [Google Scholar]
- Bach, S.; Binder, A.; Montavon, G.; Klauschen, F.; Müller, K.R.; Samek, W. On pixel-wise explanations for non-linear classifier decisions by layer-wise relevance propagation. PLoS ONE 2015, 10, e0130140. [Google Scholar] [CrossRef] [Green Version]
- Lipovetsky, S.; Conklin, M. Analysis of regression in game theory approach. Appl. Stoch. Model. Bus. Ind. 2001, 17, 319–330. [Google Scholar] [CrossRef]
- Shapley, L.S. A value for n-person games. Contrib. Theory Games 1953, 2, 307–317. [Google Scholar]
- Rodríguez-Pérez, R.; Bajorath, J. Interpretation of machine learning models using shapley values: Application to compound potency and multi-target activity predictions. J. Comput.-Aided Mol. Des. 2020, 34, 1013–1026. [Google Scholar] [CrossRef]
- Beganovic, T. Gießerei 4.0—Wege für das Brownfield. 3. Symposium Gießerei 4.0. 2018. Available online: https://s3-eu-west-1.amazonaws.com/editor.production.pressmatrix.com/emags/139787/pdfs/original/cc65a080-6f72-4d1e-90b1-8361995504d0.pdf (accessed on 1 October 2021).







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Mean | Std | |
|---|---|---|
| C (wt%) | 1.68 | 1.24 |
| Si (wt%) | 1.12 | 0.55 |
| Mn (wt%) | 0.53 | 0.23 |
| P (wt%) | 0.02 | 0.01 |
| S (wt%) | 0.01 | 0.01 |
| Cr (wt%) | 20.83 | 6.16 |
| Ni (wt%) | 15.25 | 20.89 |
| Mo (wt%) | 0.59 | 1.47 |
| Cu (wt%) | 0.07 | 0.07 |
| Al (wt%) | 0.13 | 0.46 |
| Ti (wt%) | 0.02 | 0.04 |
| B (wt%) | 0.00 | 0.00 |
| Nb (wt%) | 0.39 | 0.57 |
| V (wt%) | 0.30 | 0.58 |
| W (wt%) | 0.79 | 1.94 |
| Co (wt%) | 0.54 | 1.39 |
| melt duration (min) | 112.54 | 157.44 |
| holding time (min) | 94.68 | 48.40 |
| melt energy (kWh) | 622.48 | 126.80 |
| liquid heel (kg) | 90.31 | 200.39 |
| charged material (kg) | 911.67 | 237.19 |
| scrap (kg) | 25.21 | 35.44 |
| […] | […] | […] |
| Model | MAE | MSE | RMSE | R2 | RMSLE |
|---|---|---|---|---|---|
| GB | 10.7366 | 323.9538 | 17.8981 | 0.7372 | 0.7264 |
| CatBoost | 10.8500 | 317.1721 | 17.6428 | 0.7442 | 0.7434 |
| ET | 10.0091 | 302.2621 | 17.0227 | 0.8561 | 0.7091 |
| XGBoost | 10.8536 | 341.6021 | 18.3330 | 0.7231 | 0.7193 |
| Random forest | 10.7280 | 343.3068 | 18.3815 | 0.7244 | 0.7079 |
| Ridge | 12.7954 | 387.4913 | 19.5019 | 0.6897 | 0.8859 |
| Model | Hyperparameters | ||
|---|---|---|---|
| GB | |||
| CatBoost | |||
| ET | |||
| XGBoost | |||
| Random forest | |||
| Ridge | |||
| Model | MAE | MSE | RMSE | R2 | RMSLE |
|---|---|---|---|---|---|
| GB | 10.8295 | 336.6787 | 18.3488 | 0.7187 | 0.7481 |
| CatBoost | 10.6095 | 340.0453 | 18.4403 | 0.7159 | 0.7088 |
| ET | 9.2742 | 288.6199 | 16.9888 | 0.7452 | 0.6585 |
| XGBoost | 10.1959 | 310.3118 | 17.6157 | 0.7408 | 0.7003 |
| Random forest | 10.3164 | 349.7810 | 18.7024 | 0.7078 | 0.6978 |
| Ridge | 13.3635 | 439.6418 | 20.9676 | 0.6327 | 0.9129 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Chen, S.; Kaufmann, T. Development of Data-Driven Machine Learning Models for the Prediction of Casting Surface Defects. Metals 2022, 12, 1. https://doi.org/10.3390/met12010001
Chen S, Kaufmann T. Development of Data-Driven Machine Learning Models for the Prediction of Casting Surface Defects. Metals. 2022; 12(1):1. https://doi.org/10.3390/met12010001
Chicago/Turabian StyleChen, Shikun, and Tim Kaufmann. 2022. "Development of Data-Driven Machine Learning Models for the Prediction of Casting Surface Defects" Metals 12, no. 1: 1. https://doi.org/10.3390/met12010001