
CardioNet: Automatic Semantic Segmentation to Calculate the Cardiothoracic Ratio for Cardiomegaly and Other Chest Diseases

 ,
,
Abstract
:1. Introduction
2. Related Works
2.1. Chest Anatomy Segmentation Using Conventional Handmade Features
2.2. Chest Anatomy Segmentation Using Deep Feature (CNN)
3. Methodology
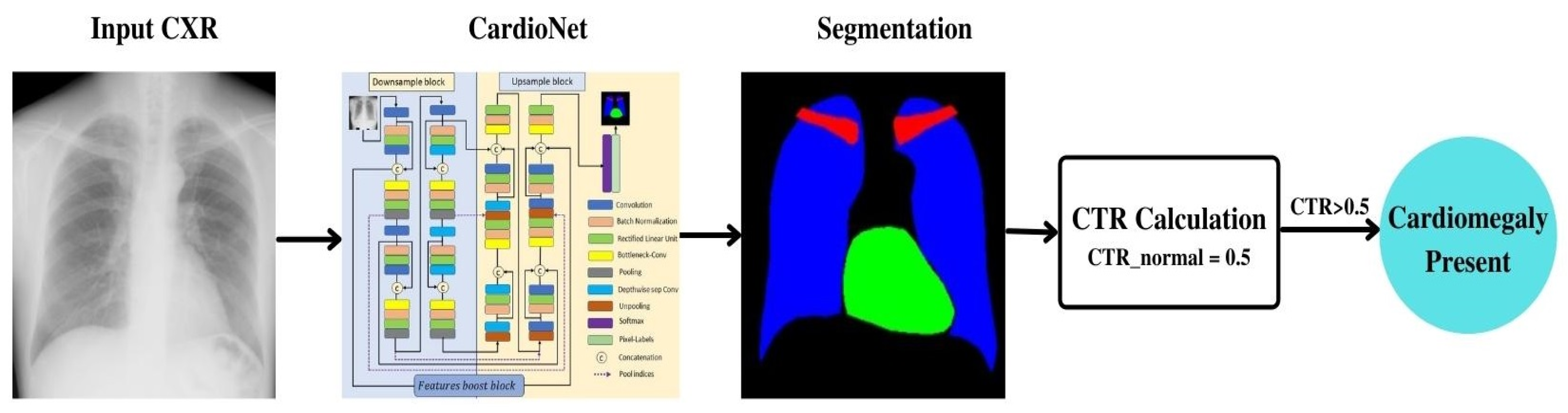
3.1. Proposed CardioNet
3.2. Chest Anatomy Segmentation Using CardioNet Architecture
4. Experiments
4.1. Data Augmentation
4.2. CardioNet Training
4.3. CardioNet Testing
4.3.1. Chest Anatomy Segmentation Testing Using CardioNet
4.3.2. Ablation Study
4.3.3. Comparison of CardioNet with Deep Methods
4.3.4. Lung Segmentation from MC Dataset Using CardioNet
4.3.5. Automated Computation of CTR by the Proposed Method
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Novikov, A.A.; Lenis, D.; Major, D.; Hladůvka, J.; Wimmer, M.; Bühler, K. Fully Convolutional Architectures for Multi-Class Segmentation in Chest Radiographs. IEEE Trans. Med. Imaging 2018, 37, 1865–1876. [Google Scholar] [CrossRef] [Green Version]
- Semsarian, C.; Ingles, J.; Maron, M.S.; Maron, B.J. New Perspectives on the Prevalence of Hypertrophic Cardiomyopathy. J. Am. Coll. Cardiol. 2015, 65, 1249–1254. [Google Scholar] [CrossRef] [Green Version]
- Tavora, F.; Zhang, Y.; Zhang, M.; Li, L.; Ripple, M.; Fowler, D.; Burke, A. Cardiomegaly Is a Common Arrhythmogenic Substrate in Adult Sudden Cardiac Deaths, and Is Associated with Obesity. Pathology 2012, 44, 187–191. [Google Scholar] [CrossRef]
- Candemir, S.; Jaeger, S.; Lin, W.; Xue, Z.; Antani, S.; Thoma, G. Automatic Heart Localization and Radiographic Index Computation in Chest X-rays. In Proceedings of the Medical Imaging, San Diego, CA, USA, 28 February–2 March 2016; p. 978517. [Google Scholar]
- Dimopoulos, K.; Giannakoulas, G.; Bendayan, I.; Liodakis, E.; Petraco, R.; Diller, G.-P.; Piepoli, M.F.; Swan, L.; Mullen, M.; Best, N.; et al. Cardiothoracic Ratio from Postero-Anterior Chest Radiographs: A Simple, Reproducible and Independent Marker of Disease Severity and Outcome in Adults with Congenital Heart Disease. Int. J. Cardiol. 2013, 166, 453–457. [Google Scholar] [CrossRef]
- Hasan, M.A.; Lee, S.-L.; Kim, D.-H.; Lim, M.-K. Automatic Evaluation of Cardiac Hypertrophy Using Cardiothoracic Area Ratio in Chest Radiograph Images. Comput. Methods Programs Biomed. 2012, 105, 95–108. [Google Scholar] [CrossRef]
- Browne, R.F.J.; O’Reilly, G.; McInerney, D. Extraction of the Two-Dimensional Cardiothoracic Ratio from Digital PA Chest Radiographs: Correlation with Cardiac Function and the Traditional Cardiothoracic Ratio. J. Digit. Imaging 2004, 17, 120–123. [Google Scholar] [CrossRef] [Green Version]
- Chen, L.-C.; Papandreou, G.; Kokkinos, I.; Murphy, K.; Yuille, A.L. DeepLab: Semantic Image Segmentation with Deep Convolutional Nets, Atrous Convolution, and Fully Connected CRFs. arXiv 2017, arXiv:1606.00915. [Google Scholar] [CrossRef] [Green Version]
- Moeskops, P.; Viergever, M.A.; Mendrik, A.M.; de Vries, L.S.; Benders, M.J.N.L.; Išgum, I. Automatic Segmentation of MR Brain Images with a Convolutional Neural Network. IEEE Trans. Med. Imaging 2016, 35, 1252–1261. [Google Scholar] [CrossRef] [Green Version]
- Havaei, M.; Davy, A.; Warde-Farley, D.; Biard, A.; Courville, A.; Bengio, Y.; Pal, C.; Jodoin, P.-M.; Larochelle, H. Brain Tumor Segmentation with Deep Neural Networks. Med. Image Anal. 2017, 35, 18–31. [Google Scholar] [CrossRef] [Green Version]
- Hatamizadeh, A.; Terzopoulos, D.; Myronenko, A. Edge-Gated CNNs for Volumetric Semantic Segmentation of Medical Images. arXiv 2020, arXiv:2002.04207. [Google Scholar]
- Hwang, E.J.; Nam, J.G.; Lim, W.H.; Park, S.J.; Jeong, Y.S.; Kang, J.H.; Hong, E.K.; Kim, T.M.; Goo, J.M.; Park, S.; et al. Deep Learning for Chest Radiograph Diagnosis in the Emergency Department. Radiology 2019, 293, 573–580. [Google Scholar] [CrossRef]
- Mittal, A.; Hooda, R.; Sofat, S. LF-SegNet: A Fully Convolutional Encoder-Decoder Network for Segmenting Lung Fields from Chest Radiographs. Wirel. Pers. Commun. 2018, 101, 511–529. [Google Scholar] [CrossRef]
- Peng, T.; Wang, Y.; Xu, T.C.; Chen, X. Segmentation of Lung in Chest Radiographs Using Hull and Closed Polygonal Line Method. IEEE Access 2019, 7, 137794–137810. [Google Scholar] [CrossRef]
- Candemir, S.; Jaeger, S.; Palaniappan, K.; Musco, J.P.; Singh, R.K.; Xue, Z.; Karargyris, A.; Antani, S.; Thoma, G.; McDonald, C.J. Lung Segmentation in Chest Radiographs Using Anatomical Atlases With Nonrigid Registration. IEEE Trans. Med. Imaging 2014, 33, 577–590. [Google Scholar] [CrossRef]
- Jaeger, S.; Karargyris, A.; Antani, S.; Thoma, G. Detecting Tuberculosis in Radiographs Using Combined Lung Masks. In Proceedings of the 2012 Annual International Conference of the IEEE Engineering in Medicine and Biology Society, San Diego, CA, USA, 28 August 2012; pp. 4978–4981. [Google Scholar]
- Jangam, E.; Rao, A.C.S. Segmentation of Lungs from Chest X rays Using Firefly Optimized Fuzzy C-Means and Level Set Algorithm. In Recent Trends in Image Processing and Pattern Recognition; Santosh, K.C., Hegadi, R.S., Eds.; Springer: Singapore, 2019; pp. 303–311. [Google Scholar]
- Vital, D.A.; Sais, B.T.; Moraes, M.C. Robust Pulmonary Segmentation for Chest Radiography, Combining Enhancement, Adaptive Morphology, and Innovative Active Contours. Res. Biomed. Eng. 2018, 34, 234–245. [Google Scholar] [CrossRef]
- Wan Ahmad, W.S.H.M.; Zaki, W.M.D.W.; Ahmad Fauzi, M.F. Lung Segmentation on Standard and Mobile Chest Radiographs Using Oriented Gaussian Derivatives Filter. Biomed. Eng. Online 2015, 14, 20. [Google Scholar] [CrossRef] [Green Version]
- Pattrapisetwong, P.; Chiracharit, W. Automatic Lung Segmentation in Chest Radiographs Using Shadow Filter and Multilevel Thresholding. In Proceedings of the 2016 International Computer Science and Engineering Conference (ICSEC), Chiang Mai, Thailand, 14–17 December 2016; pp. 1–6. [Google Scholar]
- Li, X.; Chen, L.; Chen, J. A Visual Saliency-Based Method for Automatic Lung Regions Extraction in Chest Radiographs. In Proceedings of the 2017 14th International Computer Conference on Wavelet Active Media Technology and Information Processing (ICCWAMTIP), Chengdu, China, 15–17 December 2017; pp. 162–165. [Google Scholar]
- Chen, P.-Y.; Lin, C.-H.; Kan, C.-D.; Pai, N.-S.; Chen, W.-L.; Li, C.-H. Smart Pleural Effusion Drainage Monitoring System Establishment for Rapid Effusion Volume Estimation and Safety Confirmation. IEEE Access 2019, 7, 135192–135203. [Google Scholar] [CrossRef]
- Dawoud, A. Lung Segmentation in Chest Radiographs by Fusing Shape Information in Iterative Thresholding. IET Comput. Vis. 2011, 5, 185–190. [Google Scholar] [CrossRef]
- Saad, M.N.; Muda, Z.; Ashaari, N.S.; Hamid, H.A. Image Segmentation for Lung Region in Chest X-ray Images Using Edge Detection and Morphology. In Proceedings of the 2014 IEEE International Conference on Control System, Computing and Engineering (ICCSCE 2014), Penang, Malaysia, 28–30 November 2014; pp. 46–51. [Google Scholar]
- Chondro, P.; Yao, C.-Y.; Ruan, S.-J.; Chien, L.-C. Low Order Adaptive Region Growing for Lung Segmentation on Plain Chest Radiographs. Neurocomputing 2018, 275, 1002–1011. [Google Scholar] [CrossRef]
- Chung, H.; Ko, H.; Jeon, S.J.; Yoon, K.-H.; Lee, J. Automatic Lung Segmentation with Juxta-Pleural Nodule Identification Using Active Contour Model and Bayesian Approach. IEEE J. Transl. Eng. Health Med. 2018, 6, 1–13. [Google Scholar] [CrossRef]
- Long, J.; Shelhamer, E.; Darrell, T. Fully Convolutional Networks for Semantic Segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition 2015, Boston, MA, USA, 7 June 2015. [Google Scholar]
- Dong, N.; Kampffmeyer, M.; Liang, X.; Wang, Z.; Dai, W.; Xing, E. Unsupervised Domain Adaptation for Automatic Estimation of Cardiothoracic Ratio. In Proceedings of the Medical Image Computing and Computer Assisted Intervention—MICCAI 2018, Granada, Spain, 16–20 September 2018; Frangi, A.F., Schnabel, J.A., Davatzikos, C., Alberola-López, C., Fichtinger, G., Eds.; Springer International Publishing: Cham, Switzerland, 2018; pp. 544–552. [Google Scholar]
- Tang, Y.; Tang, Y.; Xiao, J.; Summers, R.M. XLSor: A Robust and Accurate Lung Segmentor on Chest X-rays Using Criss-Cross Attention and Customized Radiorealistic Abnormalities Generation. In Proceedings of the International Conference on Medical Imaging with Deep Learning, London, UK, 8–10 July 2019; pp. 457–467. [Google Scholar]
- Souza, J.C.; Bandeira Diniz, J.O.; Ferreira, J.L.; França da Silva, G.L.; Corrêa Silva, A.; de Paiva, A.C. An Automatic Method for Lung Segmentation and Reconstruction in Chest X-ray Using Deep Neural Networks. Comput. Methods Programs Biomed. 2019, 177, 285–296. [Google Scholar] [CrossRef]
- Kalinovsky, A.; Kovalev, V. Lung Image Segmentation Using Deep Learning Methods and Convolutional Neural Networks. In Proceedings of the XIII International Conference on Pattern Recognition and Information Processing, PRIP-2016, Minsk, Belarus, 3–5 October 2016. [Google Scholar]
- Liu, H.; Wang, L.; Nan, Y.; Jin, F.; Wang, Q.; Pu, J. SDFN: Segmentation-Based Deep Fusion Network for Thoracic Disease Classification in Chest X-ray Images. Comput. Med. Imaging Graph. 2019, 75, 66–73. [Google Scholar] [CrossRef] [Green Version]
- Venkataramani, R.; Ravishankar, H.; Anamandra, S. Towards Continuous Domain Adaptation for Medical Imaging. In Proceedings of the 2019 IEEE 16th International Symposium on Biomedical Imaging (ISBI 2019), Venice, Italy, 8–11 April 2019; pp. 443–446. [Google Scholar]
- Frid-Adar, M.; Amer, R.; Greenspan, H. Endotracheal Tube Detection and Segmentation in Chest Radiographs Using Synthetic Data. arXiv 2019, arXiv:1908.07170. [Google Scholar]
- Oliveira, H.; dos Santos, J. Deep Transfer Learning for Segmentation of Anatomical Structures in Chest Radiographs. In Proceedings of the 2018 31st SIBGRAPI Conference on Graphics, Patterns and Images (SIBGRAPI), Foz do Iguaçu, Brazil, 29 October 2018; pp. 204–211. [Google Scholar]
- Wang, J.; Li, Z.; Jiang, R.; Xie, Z. Instance Segmentation of Anatomical Structures in Chest Radiographs. In Proceedings of the 2019 IEEE 32nd International Symposium on Computer-Based Medical Systems (CBMS), Cordoba, Spain, 5 June 2019. [Google Scholar]
- Dong, N.; Xu, M.; Liang, X.; Jiang, Y.; Dai, W.; Xing, E. Neural Architecture Search for Adversarial Medical Image Segmentation. In Proceedings of the Medical Image Computing and Computer Assisted Intervention—MICCAI 2019, Shenzhen, China, 13–17 October 2019; Shen, D., Liu, T., Peters, T.M., Staib, L.H., Essert, C., Zhou, S., Yap, P.-T., Khan, A., Eds.; Springer International Publishing: Cham, Switzerland, 2019; pp. 828–836. [Google Scholar]
- Jiang, F.; Grigorev, A.; Rho, S.; Tian, Z.; Fu, Y.; Jifara, W.; Adil, K.; Liu, S. Medical Image Semantic Segmentation Based on Deep Learning. Neural Comput. Appl. 2018, 29, 1257–1265. [Google Scholar] [CrossRef]
- Stollenga, M.F.; Byeon, W.; Liwicki, M.; Schmidhuber, J. Parallel Multi-Dimensional LSTM, with Application to Fast Biomedical Volumetric Image Segmentation. arXiv 2015, arXiv:1506.07452. [Google Scholar]
- Chen, J.; Yang, L.; Zhang, Y.; Alber, M.; Chen, D.Z. Combining Fully Convolutional and Recurrent Neural Networks for 3D Biomedical Image Segmentation. arXiv 2016, arXiv:1609.01006. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27 June 2016; pp. 770–778. [Google Scholar]
- Huang, G.; Liu, Z.; van der Maaten, L.; Weinberger, K.Q. Densely Connected Convolutional Networks. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21 July 2017; pp. 2261–2269. [Google Scholar]
- Badrinarayanan, V.; Kendall, A.; Cipolla, R. SegNet: A Deep Convolutional Encoder-Decoder Architecture for Image Segmentation. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 2481–2495. [Google Scholar] [CrossRef]
- Arsalan, M.; Kim, D.S.; Owais, M.; Park, K. OR-Skip-Net: Outer Residual Skip Network for Skin Segmentation in Non-Ideal Situations. Expert Syst. Appl. 2020, 141, 112922. [Google Scholar] [CrossRef]
- Ronneberger, O.; Fischer, P.; Brox, T. U-Net: Convolutional Networks for Biomedical Image Segmentation. In Proceedings of the Medical Image Computing and Computer-Assisted Intervention, Munich, Germany, 5–9 October 2015; pp. 234–241. [Google Scholar]
- Shiraishi, J.; Katsuragawa, S.; Ikezoe, J.; Matsumoto, T.; Kobayashi, T.; Komatsu, K.; Matsui, M.; Fujita, H.; Kodera, Y.; Doi, K. Development of a Digital Image Database for Chest Radiographs With and Without a Lung Nodule. Am. J. Roentgenol. 2000, 174, 71–74. [Google Scholar] [CrossRef]
- R2019a-Updates to the MATLAB and Simulink Product Families. Available online: https://ch.mathworks.com/products/new_products/latest_features.html (accessed on 4 July 2019).
- GeForce GTX TITAN X Graphics Card. Available online: https://www.nvidia.com/en-us/geforce/graphics-cards/geforce-gtx-titan-x/specifications/ (accessed on 20 April 2022).
- Kingma, D.P.; Ba, J. Adam: A Method for Stochastic Optimization. In Proceedings of the 3rd International Conference on Learning Representations, ICLR 2015, San Diego, CA, USA, 7–9 May 2015; pp. 1–15. [Google Scholar]
- Arsalan, M.; Naqvi, R.A.; Kim, D.S.; Nguyen, P.H.; Owais, M.; Park, K.R. IrisDenseNet: Robust Iris Segmentation Using Densely Connected Fully Convolutional Networks in the Images by Visible Light and Near-Infrared Light Camera Sensors. Sensors 2018, 18, 1501. [Google Scholar] [CrossRef] [Green Version]
- Arsalan, M.; Kim, D.S.; Lee, M.B.; Owais, M.; Park, K. FRED-Net: Fully Residual Encoder-Decoder Network for Accurate Iris Segmentation. Expert Syst. Appl. 2019, 122, 217–241. [Google Scholar] [CrossRef]
- Solovyev, R.; Melekhov, I.; Pesonen, T.; Vaattovaara, E.; Tervonen, O.; Tiulpin, A. Bayesian feature pyramid networks for automatic multi-label segmentation of chest X-rays and assessment of cardiothoracic ratio. In Proceedings of the International Conference on Advanced Concepts for Intelligent Vision Systems, Auckland, New Zealand, 10–14 February 2020; pp. 117–130. [Google Scholar]
- Coppini, G.; Miniati, M.; Monti, S.; Paterni, M.; Favilla, R.; Ferdeghini, E.M. A Computer-Aided Diagnosis Approach for Emphysema Recognition in Chest Radiography. Med. Eng. Phys. 2013, 35, 63–73. [Google Scholar] [CrossRef] [PubMed]
- Van Ginneken, B.; Stegmann, M.B.; Loog, M. Segmentation of Anatomical Structures in Chest Radiographs Using Supervised Methods: A Comparative Study on a Public Database. Med. Image Anal. 2006, 10, 19–40. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Pan, X.; Li, L.; Yang, D.; He, Y.; Liu, Z.; Yang, H. An Accurate Nuclei Segmentation Algorithm in Pathological Image Based on Deep Semantic Network. IEEE Access 2019, 7, 110674–110686. [Google Scholar] [CrossRef]
- Dai, W.; Dong, N.; Wang, Z.; Liang, X.; Zhang, H.; Xing, E.P. SCAN: Structure Correcting Adversarial Network for Organ Segmentation in Chest X-rays. In Deep Learning in Medical Image Analysis and Multimodal Learning for Clinical Decision Support; Stoyanov, D., Taylor, Z., Carneiro, G., Syeda-Mahmood, T., Martel, A., Maier-Hein, L., Tavares, J.M.R.S., Bradley, A., Papa, J.P., Belagiannis, V., et al., Eds.; Lecture Notes in Computer Science; Springer International Publishing: Cham, Switzerland, 2018; Volume 11045, pp. 263–273. [Google Scholar]
- Gaggion, N.; Mansilla, L.; Mosquera, C.; Milone, D.H.; Ferrante, E. Improving Anatomical Plausibility in Medical Image Segmentation via Hybrid Graph Neural Networks: Applications to Chest X-ray Analysis. arXiv 2022, arXiv:2203.10977. [Google Scholar]
- Lyu, Y.; Huo, W.-L.; Tian, X.-L. RU-Net for Heart Segmentation from CXR. J. Phys. Conf. Ser. 2021, 1769, 012015. [Google Scholar] [CrossRef]
- Multi-Path Aggregation U-Net for Lung Segmentation in Chest Radiographs. Available online: https://www.researchsquare.com/article/rs-365278/v1 (accessed on 20 May 2022).
- Jaeger, S.; Candemir, S.; Antani, S.; Wáng, Y.-X.J.; Lu, P.-X.; Thoma, G. Two Public Chest X-ray Datasets for Computer-Aided Screening of Pulmonary Diseases. Quant. Imaging Med. Surg. 2014, 4, 475–477. [Google Scholar]
- Vajda, S.; Karargyris, A.; Jaeger, S.; Santosh, K.C.; Candemir, S.; Xue, Z.; Antani, S.; Thoma, G. Feature Selection for Automatic Tuberculosis Screening in Frontal Chest Radiographs. J. Med. Syst. 2018, 42, 146. [Google Scholar] [CrossRef]
- Santosh, K.C.; Antani, S. Automated Chest X-ray Screening: Can Lung Region Symmetry Help Detect Pulmonary Abnormalities? IEEE Trans. Med. Imaging 2018, 37, 1168–1177. [Google Scholar] [CrossRef]













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Block | Layer Name | Layer Size (Height × Width × Number of Channels), (Stride) | Filters/Groups | Output |
|---|---|---|---|---|
| Downsample block | Conv-1-1 ** | 3 × 3 × 64 (S = 1) | 64 | 350 × 350 × 64 |
| Conv-1-2 | 3 × 3 × 64 (S = 1) | 64 | 350 × 350 × 64 | |
| Concatenation-1 | 350 × 350 × 128 | |||
| Bottleneck-C-1 ** | 1 × 1 (S = 1) | 64 | 350 × 350 × 64 | |
| Pool-1 2 × 2 (S = 2) | 175 × 175 × 64 | |||
| Conv-2-1 ** | 3 × 3 × 64 (S = 1) | 128 | 175 × 175 × 128 | |
| Conv-2-2 | 3 × 3 × 128 (S = 1) | 128 | 175 × 175 × 128 | |
| Concatenation-2 | 175 × 175 × 256 | |||
| Bottleneck-C-2 ** | 1 × 1 (S = 1) | 128 | 175 × 175 × 128 | |
| Pool-2 2 × 2 (S = 2) | 87 × 87 × 128 | |||
| Conv-3-1 ** | 3 × 3 × 128 (S = 1) | 256 | 87 × 87 × 256 | |
| DW-Sep-Conv-3-2 | 3 × 3 × 256 (S = 1) | 256 | 87 × 87 × 256 | |
| Concatenation-3 | 87 × 87 × 512 | |||
| Bottleneck-C-3 ** | 1 × 1 (S = 1) | 128 | 87 × 87 × 256 | |
| Pool-3 2 × 2 (S = 2) | 43 × 43 × 256 | |||
| DW-Sep-Conv-4-1 ** | 3 × 3 × 256 (S = 1) | 256 | 43 × 43 × 256 | |
| DW-Sep-Conv-4-2 | 3 × 3 × 256 (S = 1) | 256 | 43 × 43 × 256 | |
| Concatenation-4 | 43 × 43 × 512 | |||
| Bottleneck-C-4 ** | 1 × 1 (S = 1) | 256 | 43 × 43 × 256 | |
| Pool-4 2 × 2 (S = 2) | 21 × 21 × 256 | |||
| Upsample block | UnPool-4 2 × 2 (S = 2) | 43 × 43 × 256 | ||
| DW-Sep-Conv-4-2 ** | 3 × 3 × 256 (S = 1) | 256 | 43 × 43 × 256 | |
| DW-Sep-Conv-4-1 | 3 × 3 × 256 (S = 1) | 256 | 43 × 43 × 256 | |
| Concatenation-5 | 43 × 43 × 512 | |||
| Bottleneck-C-5 ** | 1 × 1 (S = 1) | 256 | 43 × 43 × 256 | |
| UnPool-3 2 × 2 (S = 2) | 87 × 87 × 256 | |||
| DW-Sep-Conv-3-2 ** | 3 × 3 × 256 (S = 1) | 256 | 87 × 87 × 256 | |
| Conv-3-1 | 3 × 3 × 256 (S = 1) | 128 | 87 × 87 × 128 | |
| Concatenation-6 | 87 × 87 × 640 | |||
| Bottleneck-C-6 ** | 1 × 1 (S = 1) | 128 | 87 × 87 × 128 | |
| UnPool-2 2 × 2 (S = 2) | 175 × 175 × 128 | |||
| Conv-2-2 ** | 3 × 3 × 128 (S = 1) | 128 | 175 × 175 × 128 | |
| Conv-2-1 | 3 × 3 × 128 (S = 1) | 64 | 175 × 175 × 64 | |
| Concatenation-7 | 175 × 175 × 320 | |||
| Bottleneck-C-7 ** | 1 × 1 (S = 1) | 64 | 175 × 175 × 64 | |
| UnPool-1 2 × 2 (S = 2) | 350 × 350 × 64 | |||
| Conv-1-2 ** | 3 × 3 × 64 (S = 1) | 64 | 350 × 350 × 64 | |
| Conv-1-1 | 3 × 3 × 64 (S = 1) | 64 | 350 × 350 × 64 | |
| Concatenation-8 | 350 × 350 × 160 | |||
| Bottleneck-C-8 ** | 1 × 1 (S = 1) | 2 | 350 × 350 × 2 | |
| Method | Other Architectures | CardioNet |
|---|---|---|
| SegNet [43] | 26 convolutional layers (3 × 3) | 16 convolutional layers (3 × 3) |
| No depth-wise separable convolution | 6 depth-wise separable convolutions are involved in reducing the number of trainable parameters | |
| No skip connections are used. | Dense skip paths are used. | |
| Each block has a different number of convolutional layers | Each block has the same number of convolutions (2 convolutions) | |
| No booster block | Booster block. | |
| 5 pooling layers | 4 pooling layers | |
| The number of trainable parameters is 29.46 M. | The number of trainable parameters is 1.72 M. | |
| OR-Skip-Net [44] | There is no internal connectivity between the convolutional layers in the encoder and decoder. | Both internal and external connectivities are used. |
| Residual connectivity is used. | Dense connectivity is used. | |
| 16 convolutional layers (3 × 3) | 16 convolution layers (3 × 3) including 6 layers of booster block (max. depth 32) | |
| No depth-wise separable convolution | 6 depth-wise separable convolution is involved in reducing the number of trainable parameters | |
| Bottleneck layers are not used. | Bottleneck layers are used to reduce the number of channels. | |
| The number of trainable parameters is 09.70 M | The number of trainable parameters is 1.72 M | |
| U-Net [45] | 23 convolutional layers are used | 16 convolutional layers (3 × 3) |
| No depth-wise separable convolution | 6 depth-wise separable convolution is involved in reducing the number of trainable parameters | |
| Up convolutions are used in the expansive part for upsampling | Unpooling layers are used for upsampling | |
| External dense connectivity is used from encoder to decoder. | Both internal and external dense connectivity in downsampling and upsampling block | |
| Cropping is required owing to border pixel loss during convolution | Cropping is not required | |
| The number of trainable parameters is 31.03 M | The number of trainable parameters is 1.72 M |
| Block | Layer Name | Layer Size (Height × Width × Number of channels) | Filters/Groups | Output |
|---|---|---|---|---|
| Features boost block (FBB) | Bottleneck-C ** | 1 × 1 × 8 | 8 | 350 × 350 × 8 |
| Boost-Conv-1-1 ** | 3 × 3 × 8 | 8 | 350 × 350 × 8 | |
| Boost-Conv-1-2 ** | 3 × 3 × 8 | 8 | 350 × 350 × 8 | |
| Boost-Conv-2-1 ** | 3 × 3 × 16 | 16 | 350 × 350 × 16 | |
| Boost-Conv-2-2 ** | 3 × 3 × 16 | 16 | 350 × 350 × 16 | |
| Boost-Conv-3-1 ** | 3 × 3 × 32 | 32 | 350 × 350 × 32 | |
| Boost-Conv-3-2 ** | 3 × 3 × 32 | 32 | 350 × 350 × 32 |
| Methods | Segmentation Regions | Number of Trainable Parameters | Number of 3 × 3 Convolution Layers | Acc | J | D |
|---|---|---|---|---|---|---|
| CardioNet-X | Lungs | 1.57 M | 10 | 98.08 | 93.04 | 96.38 |
| Heart | 98.91 | 88.70 | 93.84 | |||
| Clavicle bone | 97.81 | 85.99 | 91.53 | |||
| CardioNet-B | Lungs | 1.72 M | 16 | 99.24 | 97.28 | 98.61 |
| Heart | 99.08 | 90.42 | 94.76 | |||
| Clavicle bone | 99.76 | 86.74 | 92.74 |
| Type | Method | Lungs | Heart | Clavicle Bone | ||||||
|---|---|---|---|---|---|---|---|---|---|---|
| Acc | J | D | Acc | J | D | Acc | J | D | ||
| Local feature-based methods | Coppini et al. [53] | - | 92.7 | 95.5 | - | - | - | - | - | - |
| Jangam et al. [17] | - | 95.6 | 97.6 | - | - | - | - | - | - | |
| ASM default [54] | - | 90.3 | - | - | 79.3 | - | - | 69.0 | - | |
| Chondro et al. [25] | - | 96.3 | - | - | - | - | - | - | - | |
| Candemir et al. [15] | - | 95.4 | 96.7 | - | - | - | - | - | - | |
| Dawoud [23] | - | 94.0 | - | - | - | - | - | - | - | |
| Peng et al. [55] | 97.0 | 93.6 | 96.7 | - | - | - | - | - | - | |
| Wan Ahmed et al. [19] | 95.77 | - | - | - | - | - | - | - | - | |
| Deep feature-based methods | Dai et al. FCN [56] | - | 94.7 | 97.3 | - | 86.6 | 92.7 | - | - | - |
| Oliveira et al. FCN [35] | 95.05 | 97.45 | 89.25 | 94.24 | 75.52 | 85.90 | ||||
| OR-Skip-Net [44] | 98.92 | 96.14 | 98.02 | 98.94 | 88.8 | 94.01 | 99.70 | 83.79 | 91.07 | |
| ResNet101 [36] | 95.3 | 97.6 | 90.4 | 94.9 | 85.2 | 92.0 | ||||
| ContextNet-2 [33] | - | 96.5 | - | - | - | - | - | |||
| BFPN [52] | - | 87.0 | 93.0 | - | 82.0 | 90.0 | - | - | - | |
| InvertedNet [1] | 94.9 | 97.4 | 88.8 | 94.1 | 83.3 | 91.0 | ||||
| HybridGNet [57] | 97.43 | 93.34 | ||||||||
| RU-Net [58] | 85.57 | |||||||||
| MPDC DDLA U-Net [59] | 95.61 | 97.90 | ||||||||
| CardioNet (Average of Fold 1 and Fold 2) | 99.24 | 97.28 | 98.61 | 99.08 | 90.42 | 94.76 | 99.76 | 86.74 | 92.74 | |
| Type | Method | Accuracy | Jaccard Index | Dice Coefficient |
|---|---|---|---|---|
| Handcrafted feature-based methods | Vajda et al. [61] | 69.0 | - | - |
| Candemir et al. [4] | - | 94.1 | 96.0 | |
| Peng et al. [55] | 97.0 | - | - | |
| Deep feature-based methods | Feature selection and Vote [62] | 83.0 | - | - |
| Feature selection with BN [62] | 77.0 | - | - | |
| Bayesian feature pyramid network [52] | - | 87.0 | 93.0 | |
| Souza et al. [30] | 96.97 | 88.07 | 96.97 | |
| HybridGNet [57] | 95.4 | |||
| MPDC DDLA U-Net [59] | 94.83 | 96.53 | ||
| CardioNet (proposed method) | 98.92 | 95.61 | 97.75 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Jafar, A.; Hameed, M.T.; Akram, N.; Waqas, U.; Kim, H.S.; Naqvi, R.A. CardioNet: Automatic Semantic Segmentation to Calculate the Cardiothoracic Ratio for Cardiomegaly and Other Chest Diseases. J. Pers. Med. 2022, 12, 988. https://doi.org/10.3390/jpm12060988
Jafar A, Hameed MT, Akram N, Waqas U, Kim HS, Naqvi RA. CardioNet: Automatic Semantic Segmentation to Calculate the Cardiothoracic Ratio for Cardiomegaly and Other Chest Diseases. Journal of Personalized Medicine. 2022; 12(6):988. https://doi.org/10.3390/jpm12060988
Chicago/Turabian StyleJafar, Abbas, Muhammad Talha Hameed, Nadeem Akram, Umer Waqas, Hyung Seok Kim, and Rizwan Ali Naqvi. 2022. "CardioNet: Automatic Semantic Segmentation to Calculate the Cardiothoracic Ratio for Cardiomegaly and Other Chest Diseases" Journal of Personalized Medicine 12, no. 6: 988. https://doi.org/10.3390/jpm12060988