
An Outperforming Artificial Intelligence Model to Identify Referable Blepharoptosis for General Practitioners

 , , , , ,
, , , , ,
Abstract
:1. Introduction
2. Materials and Methods
2.1. Image Preparation
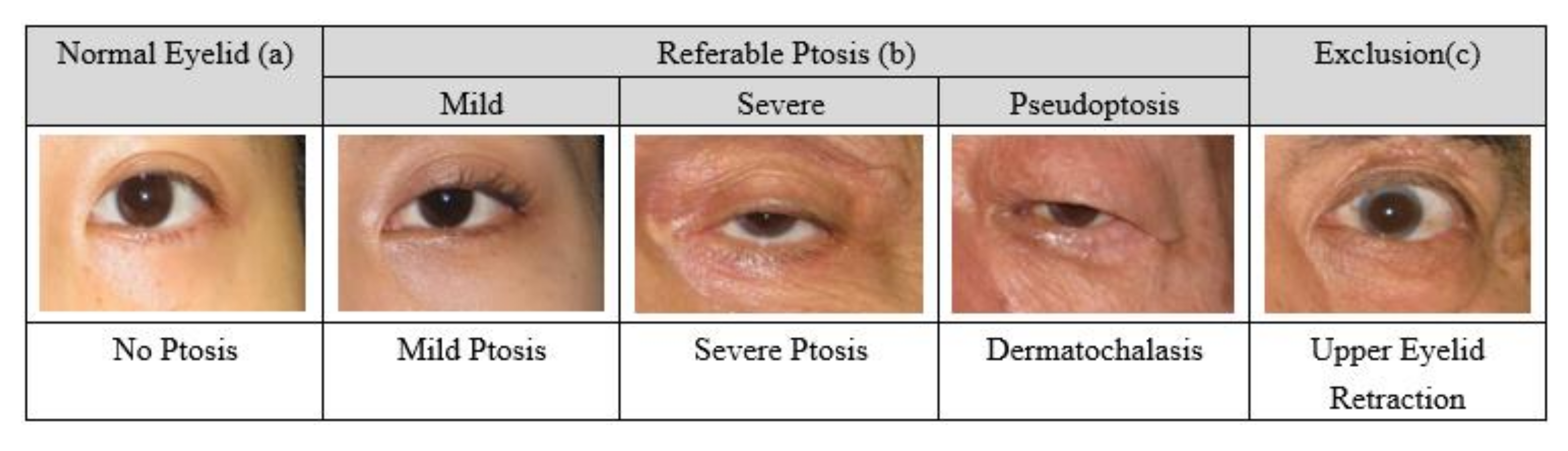
2.2. Inclusion and Exclusion
2.3. Annotations for the Ground Truth
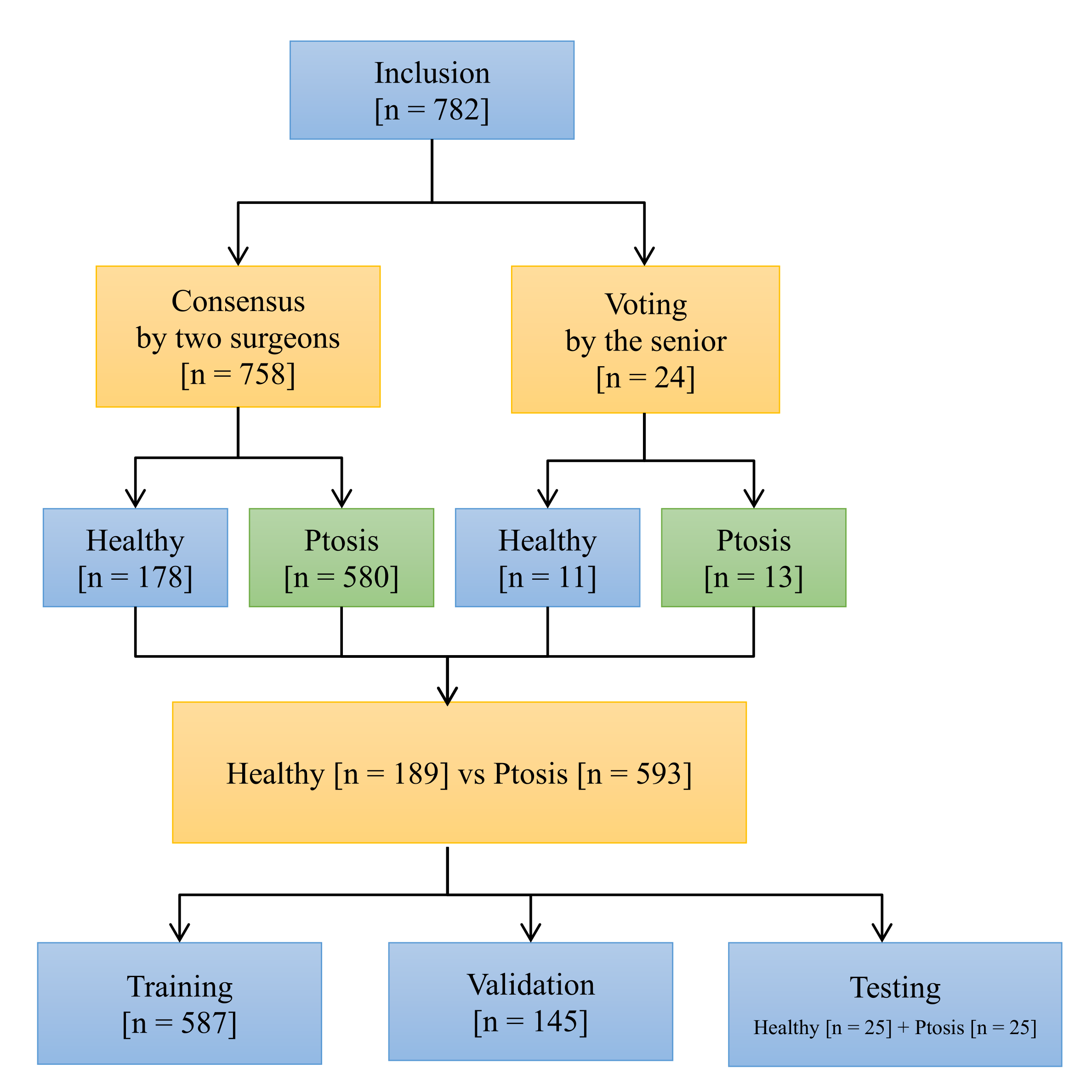
2.4. Data Allocation for Training, Validation, and Testing
2.5. Model Architecture and Training
2.6. Transfer Learning and Data Augmentation
- Images flipped horizontally;
- Random image rotations of up to 15 degrees;
- Random zooms in or out between the range of 90% to 120%;
- Adjusted brightness/contrast by 50%;
- Images shifted horizontally or vertically by 10%.
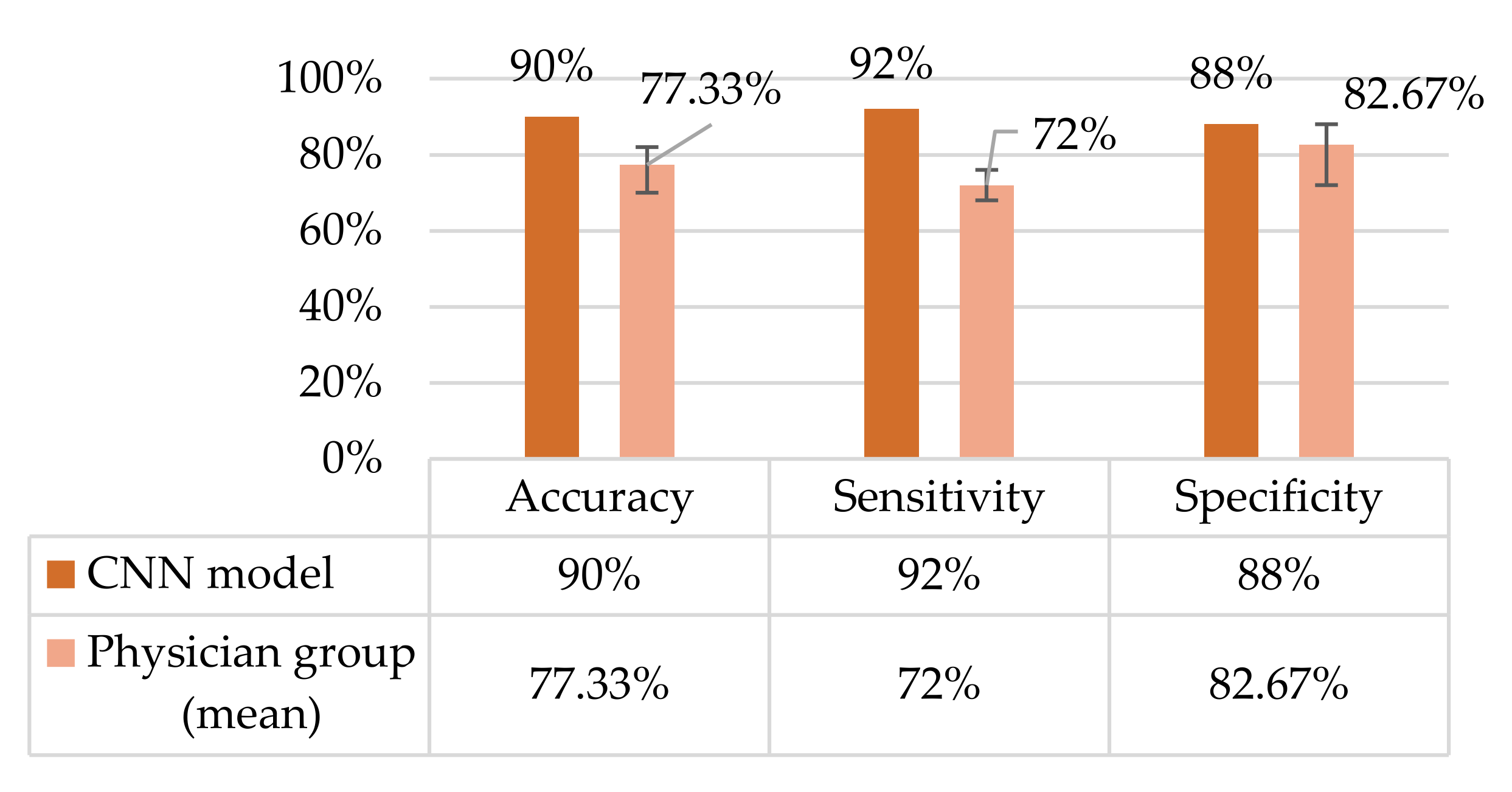
2.7. Testing in Non-Ophthalmic Physician Group
3. Results
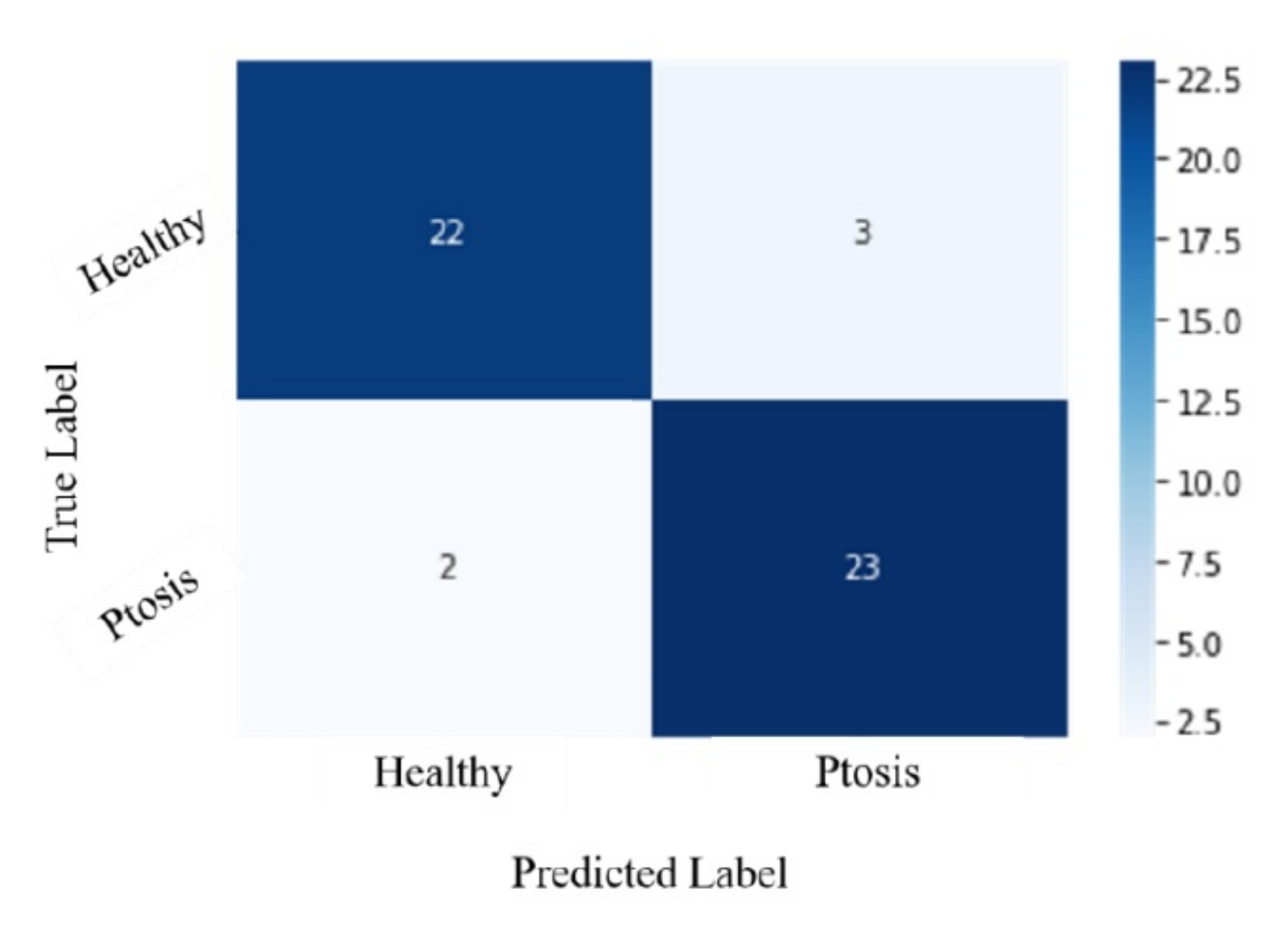
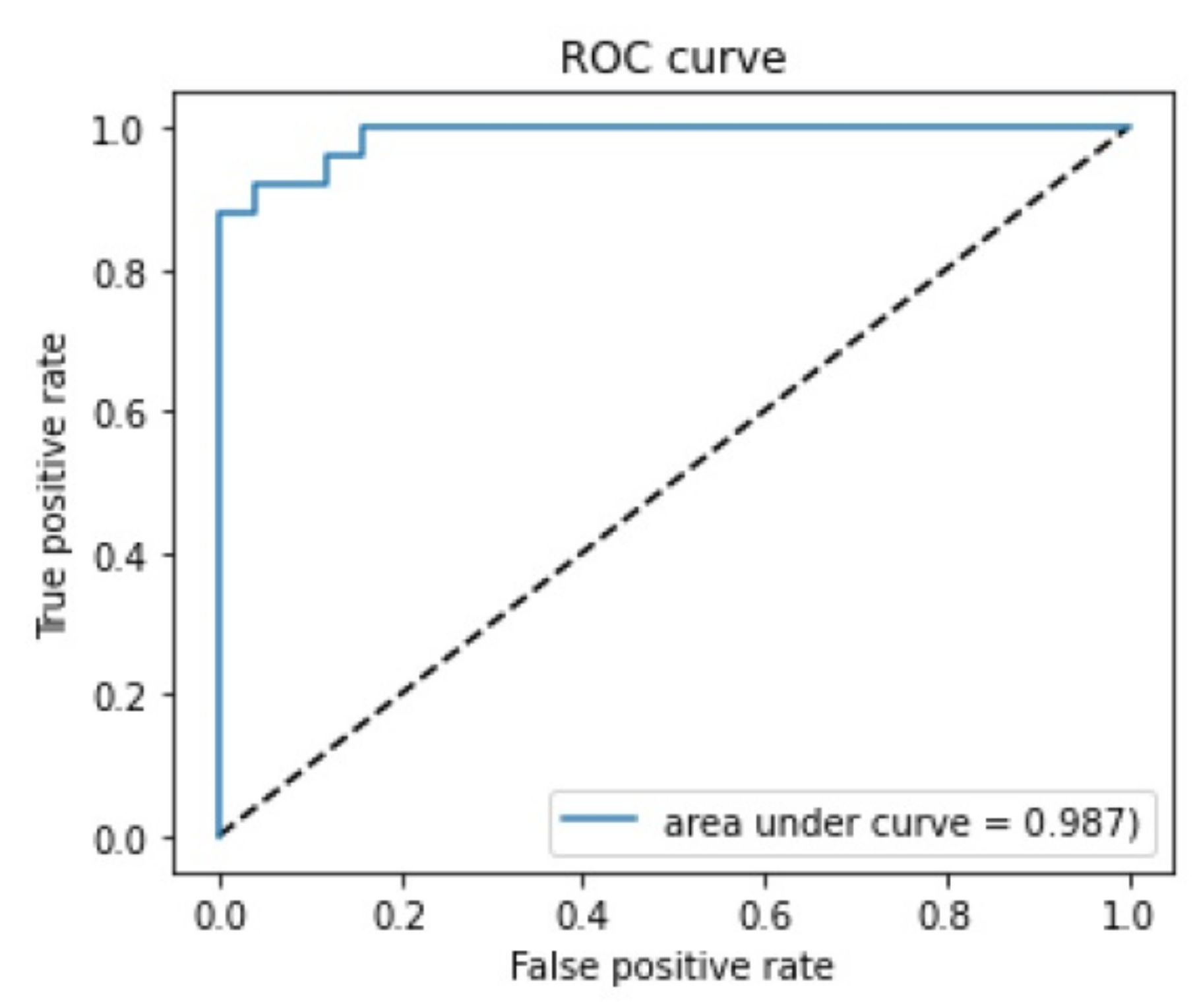
3.1. Confusion Matrix and ROC Curve
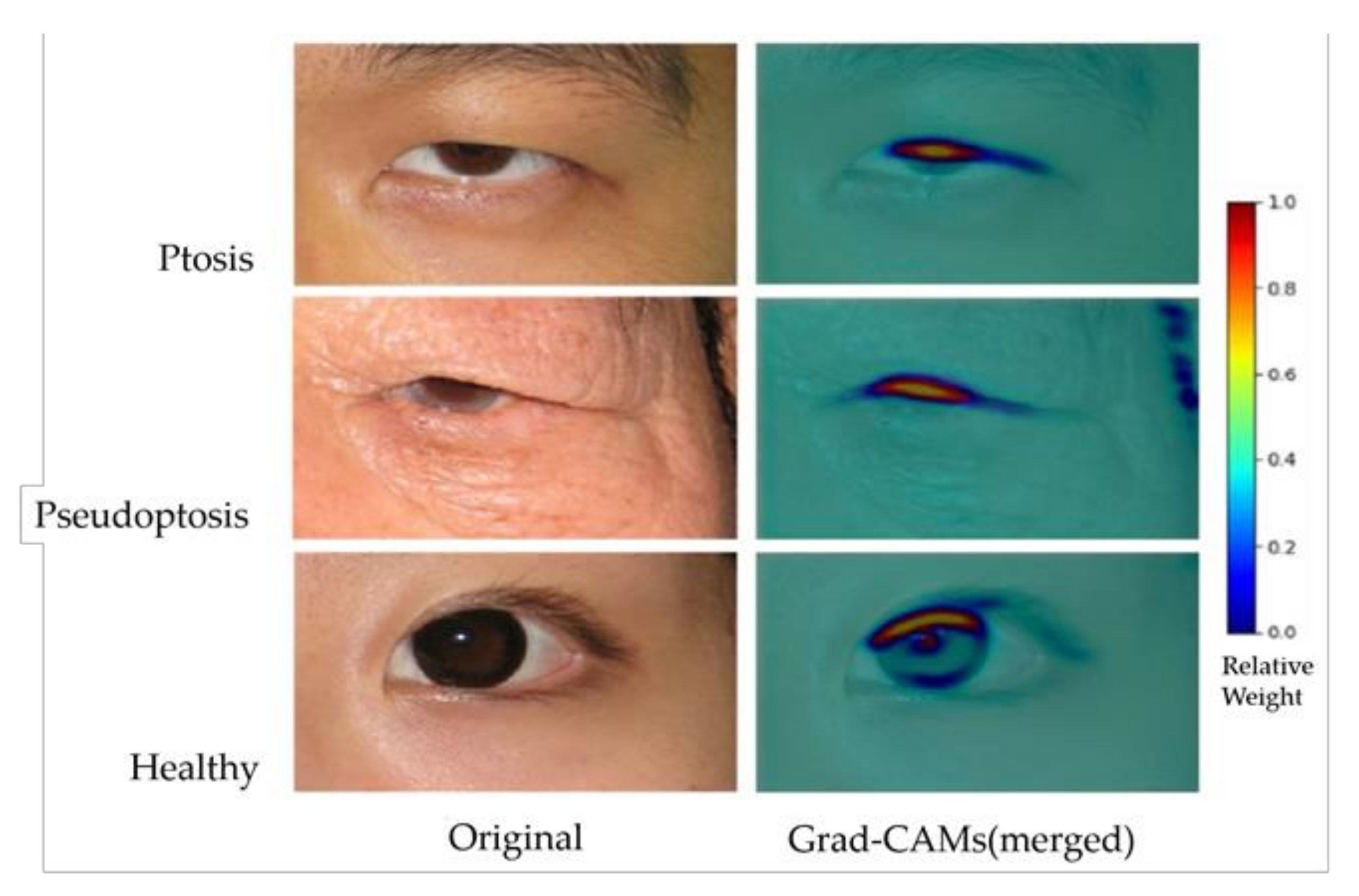
3.2. Grad-CAM Results
4. Discussion
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Al-Haidar, M.; Benatar, M.; Kaminski, H.J. Ocular Myasthenia. Neurol. Clin. 2018, 36, 241–251. [Google Scholar] [CrossRef] [PubMed]
- Bagheri, A.; Borhani, M.; Salehirad, S.; Yazdani, S.; Tavakoli, M. Blepharoptosis Associated With Third Cranial Nerve Palsy. Ophthalmic Plast. Reconstr. Surg. 2015, 31, 357–360. [Google Scholar] [CrossRef] [PubMed]
- Martin, T.J. Horner Syndrome: A Clinical Review. ACS Chem. Neurosci. 2018, 9, 177–186. [Google Scholar] [CrossRef] [PubMed]
- Putterman, A.M. Margin reflex distance (MRD) 1, 2, and 3. Ophthalmic Plast. Reconstr. Surg. 2012, 28, 308–311. [Google Scholar] [CrossRef]
- Boboridis, K.; Assi, A.; Indar, A.; Bunce, C.; Tyers, A. Repeatability and reproducibility of upper eyelid measurements. Br. J. Ophthalmol. 2001, 85, 99–101. [Google Scholar] [CrossRef]
- Nemet, A.Y. Accuracy of marginal reflex distance measurements in eyelid surgery. J. Craniofacial Surg. 2015, 26, e569–e571. [Google Scholar] [CrossRef]
- Gulshan, V.; Peng, L.; Coram, M.; Stumpe, M.C.; Wu, D.; Narayanaswamy, A.; Venugopalan, S.; Widner, K.; Madams, T.; Cuadros, J.; et al. Development and Validation of a Deep Learning Algorithm for Detection of Diabetic Retinopathy in Retinal Fundus Photographs. JAMA 2016, 316, 2402–2410. [Google Scholar] [CrossRef]
- Esteva, A.; Kuprel, B.; Novoa, R.A.; Ko, J.; Swetter, S.M.; Blau, H.M.; Thrun, S. Dermatologist-level classification of skin cancer with deep neural networks. Nature 2017, 542, 115–118. [Google Scholar] [CrossRef]
- Shen, D.; Wu, G.; Suk, H.-I. Deep Learning in Medical Image Analysis. Annu. Rev. Biomed. Eng. 2017, 19, 221–248. [Google Scholar] [CrossRef] [Green Version]
- Wang, F.; Casalino, L.P.; Khullar, D. Deep learning in medicine—promise, progress, and challenges. JAMA internal medicine 2019, 179, 293–294. [Google Scholar] [CrossRef]
- Zeiler, M.D.; Fergus, R. Visualizing and Understanding Convolutional Networks; Springer: Cham, Switzerland, 2014; pp. 818–833. [Google Scholar]
- Hung, J.-Y.; Perera, C.; Chen, K.-W.; Myung, D.; Chiu, H.-K.; Fuh, C.-S.; Hsu, C.-R.; Liao, S.-L.; Kossler, A.L. A deep learning approach to identify blepharoptosis by convolutional neural networks. Int. J. Med. Inform. 2021, 148, 104402. [Google Scholar] [CrossRef] [PubMed]
- Simonyan, K.; Zisserman, A. Very deep convolutional networks for large-scale image recognition. arXiv preprint 2014, arXiv:1409.1556. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the Proceedings of the IEEE conference on computer vision and pattern recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778.
- Huang, G.; Liu, Z.; Van Der Maaten, L.; Weinberger, K.Q. Densely connected convolutional networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 2261–2269. [Google Scholar]
- Amos, B.; Ludwiczuk, B.; Satyanarayanan, M. Openface: A general-purpose face recognition library with mobile applications. CMU Sch. Comput. Sci. 2016, 6. [Google Scholar]
- Bodnar, Z.M.; Neimkin, M.; Holds, J.B. Automated Ptosis Measurements From Facial Photographs. JAMA Ophthalmol. 2016, 134, 146–150. [Google Scholar] [CrossRef] [Green Version]
- Lou, L.; Yang, L.; Ye, X.; Zhu, Y.; Wang, S.; Sun, L.; Qian, D.; Ye, J. A Novel Approach for Automated Eyelid Measurements in Blepharoptosis Using Digital Image Analysis. Curr. Eye Res. 2019, 44, 1075–1079. [Google Scholar] [CrossRef]
- Lai, H.-T.; Weng, S.-F.; Chang, C.-H.; Huang, S.-H.; Lee, S.-S.; Chang, K.-P.; Lai, C.-S. Analysis of Levator Function and Ptosis Severity in Involutional Blepharoptosis. Ann. Plast. Surg. 2017, 78, S58–S60. [Google Scholar] [CrossRef]
- Thomas, P.B.; Gunasekera, C.D.; Kang, S.; Baltrusaitis, T. An Artificial Intelligence Approach to the Assessment of Abnormal Lid Position. Plast. Reconstr. Surg. Glob. Open 2020, 8, e3089. [Google Scholar] [CrossRef]
- Da, K. A method for stochastic optimization. arXiv preprint 2014, arXiv:1412.6980. [Google Scholar]
- Russakovsky, O.; Deng, J.; Su, H.; Krause, J.; Satheesh, S.; Ma, S.; Huang, Z.; Karpathy, A.; Khosla, A.; Bernstein, M. Imagenet large scale visual recognition challenge. Int. J. Comput. Vis. 2015, 115, 211–252. [Google Scholar] [CrossRef] [Green Version]
- Selvaraju, R.R.; Cogswell, M.; Das, A.; Vedantam, R.; Parikh, D.; Batra, D. Grad-cam: Visual explanations from deep networks via gradient-based localization. In Proceedings of the IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017; pp. 618–626. [Google Scholar]
- Cohen, A.J.; Weinberg, D.A. Pseudoptosis. In Evaluation and Management of Blepharoptosis; Springer: New York, NY, USA, 2011. [Google Scholar]
- Huff, J.S.; Austin, E.W. Neuro-Ophthalmology in Emergency Medicine. Emerg. Med. Clin. N. Am. 2016, 34, 967–986. [Google Scholar] [CrossRef]
- Zhang, J.Y.; Zhu, X.W.; Ding, X.; Lin, M.; Li, J. Prevalence of amblyopia in congenital blepharoptosis: A systematic review and Meta-analysis. Int. J. Ophthalmol. 2019, 12, 1187–1193. [Google Scholar] [CrossRef] [PubMed]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Training | Validation (for Training) | Testing | |
|---|---|---|---|
| Referable ptosis group | 455 | 113 | 25 |
| Healthy group | 132 | 32 | 25 |
| Input Size | Layer | Output Size | Number of Feature Maps | Kernel Size | Stride | Activation |
|---|---|---|---|---|---|---|
| - | Image | 200 × 300 × 3 | - | - | - | - |
| 200 × 300 × 3 | Convolution | 200 × 300 × 64 | 64 | 3 × 3 | 1 | ReLU |
| 200 × 300 × 64 | Convolution | 200 × 300 × 64 | 64 | 3 × 3 | 1 | ReLU |
| 200 × 300 × 64 | Max pooling | 100 × 150 × 64 | 64 | - | 2 | - |
| 100 × 150 × 64 | Convolution | 100 × 150 × 128 | 128 | 3 × 3 | 1 | ReLU |
| 100 × 150 × 128 | Convolution | 100 × 150 × 128 | 128 | 3 × 3 | 1 | ReLU |
| 100 × 150 × 128 | Max pooling | 50 × 75 × 128 | 128 | - | 2 | - |
| 50 × 75 × 128 | Convolution | 50 × 75 × 256 | 256 | 3 × 3 | 1 | ReLU |
| 50 × 75 × 256 | Convolution | 50 × 75 × 256 | 256 | 3 × 3 | 1 | ReLU |
| 50 × 75 × 256 | Global max pooling | 1 × 256 | - | - | - | - |
| 1 × 256 | Fully connected | 1 × 512 | - | - | - | ReLU |
| 1 × 512 | Fully connected | 1 | - | - | - | Sigmoid |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Hung, J.-Y.; Chen, K.-W.; Perera, C.; Chiu, H.-K.; Hsu, C.-R.; Myung, D.; Luo, A.-C.; Fuh, C.-S.; Liao, S.-L.; Kossler, A.L. An Outperforming Artificial Intelligence Model to Identify Referable Blepharoptosis for General Practitioners. J. Pers. Med. 2022, 12, 283. https://doi.org/10.3390/jpm12020283
Hung J-Y, Chen K-W, Perera C, Chiu H-K, Hsu C-R, Myung D, Luo A-C, Fuh C-S, Liao S-L, Kossler AL. An Outperforming Artificial Intelligence Model to Identify Referable Blepharoptosis for General Practitioners. Journal of Personalized Medicine. 2022; 12(2):283. https://doi.org/10.3390/jpm12020283
Chicago/Turabian StyleHung, Ju-Yi, Ke-Wei Chen, Chandrashan Perera, Hsu-Kuang Chiu, Cherng-Ru Hsu, David Myung, An-Chun Luo, Chiou-Shann Fuh, Shu-Lang Liao, and Andrea Lora Kossler. 2022. "An Outperforming Artificial Intelligence Model to Identify Referable Blepharoptosis for General Practitioners" Journal of Personalized Medicine 12, no. 2: 283. https://doi.org/10.3390/jpm12020283