
Does COVID-19 Clinical Status Associate with Outcome Severity? An Unsupervised Machine Learning Approach for Knowledge Extraction

 ,
,  ,
,  ,
, 
Abstract
:
1. Introduction
2. Materials and Methods
2.1. Data Processing
2.2. Factor Analysis of Mixed Data (FAMD)
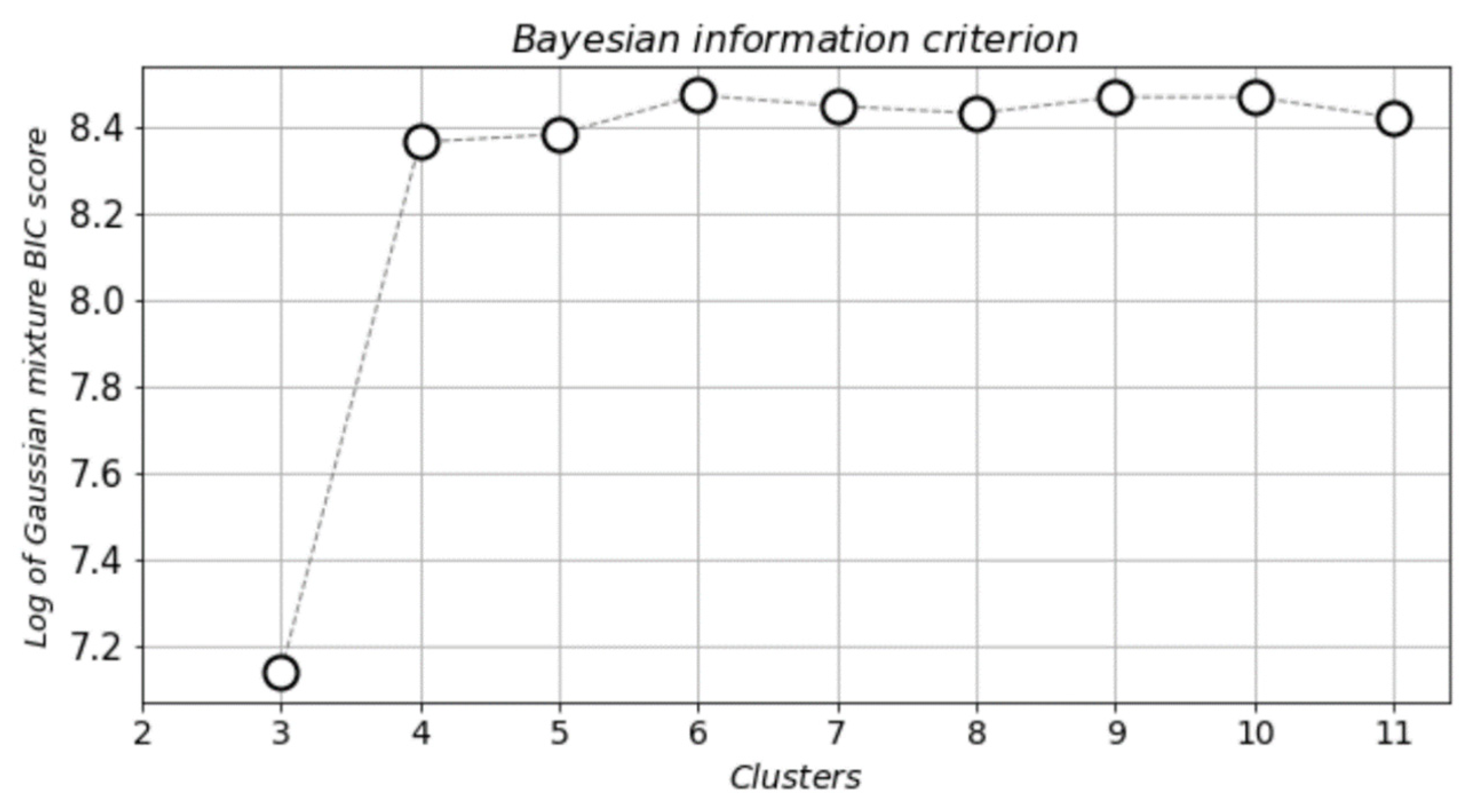
2.3. Bayesian Information Criterion (BIC)
2.4. Gaussian Mixture Models (GMM)
2.5. Cluster Analysis
2.6. Use Case—Patients’ Information
3. Results
4. Discussion
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Conflicts of Interest
References
- Li, Q.; Guan, X.; Wu, P.; Wang, X.; Zhou, L.; Tong, Y.; Ren, R.; Leung, K.S.M.; Lau, E.H.Y.; Wong, J.Y.; et al. Early transmission dynamics in Wuhan, China, of novel coronavirus–infected pneumonia. N. Engl. J. Med. 2020, 382, 1199–1207. [Google Scholar] [CrossRef] [PubMed]
- WHO. WHO Director-General’s Opening Remarks at the Media Briefing on COVID-19; World Health Organization: Geneva, Switzerland, 11 March 2020. [Google Scholar]
- Lalmuanawma, S.; Hussain, J.; Chhakchhuak, L. Applications of machine learning and artificial intelligence for COVID-19 (SARS-CoV-2) pandemic: A review. Chaos Solitons Fractals 2020, 139, 110059. [Google Scholar] [CrossRef]
- Lai, C.C.; Shih, T.P.; Ko, W.C.; Tang, H.J.; Hsueh, P.R. Severe acute respiratory syndrome coronavirus 2 (SARS-CoV-2) and coronavirus disease-2019 (COVID-19): The epidemic and the challenges. Int. J. Antimicrob. Agents 2020, 55, 105924. [Google Scholar] [CrossRef]
- Oran, D.P.; Topol, E.J. Prevalence of asymptomatic SARS-CoV-2 infection: A narrative review. Ann. Intern. Med. 2020, 173, 362–367. [Google Scholar] [CrossRef]
- Grasselli, G.; Pesenti, A.; Cecconi, M. Critical care utilization for the COVID-19 outbreak in Lombardy, Italy: Early experience and forecast during an emergency response. JAMA J. Am. Med. Assoc. 2020, 323, 1545–1546. [Google Scholar] [CrossRef] [Green Version]
- Phua, J.; Weng, L.; Ling, L.; Egi, M.; Lim, C.-M.; Divatia, J.V.; Shrestha, B.R.; Arabi, Y.M.; Ng, J.; Gomersall, C.D.; et al. Intensive care management of coronavirus disease 2019 (COVID-19): Challenges and recommendations. Lancet Respir. Med. 2020, 8, 506–517. [Google Scholar] [CrossRef]
- De Fátima Cobre, A.; Stremel, D.P.; Noleto, G.R.; Fachi, M.M.; Surek, M.; Wiens, A.; Tonina, F.S.; Pontarolod, R. Diagnosis and prediction of COVID-19 severity: Can biochemical tests and machine learning be used as prognostic indicators? Comput. Biol. Med. 2021, 134, 104531. [Google Scholar] [CrossRef] [PubMed]
- Weiss, P.; Murdoch, D.R. Clinical course and mortality risk of severe COVID-19. Lancet 2020, 395, 1014–1015. [Google Scholar] [CrossRef]
- Wu, P.; Ye, H.; Cai, X.; Li, C.; Li, S.; Chen, M.; Wang, M.; Heidari, A.A.; Chen, M.; Li, J.; et al. An effective machine learning approach for identifying non-severe and severe Coronavirus disease 2019 patients in a rural Chinese population: The Wenzhou retrospective study. IEEE Access 2021, 9, 45486–45503. [Google Scholar] [CrossRef]
- Schöning, V.; Liakoni, E.; Baumgartner, C.; Exadaktylos, A.K.; Hautz, W.E.; Atkinson, A.; Hammann, F. Development and validation of a prognostic COVID-19 severity assessment (COSA) score and machine learning models for patient triage at a tertiary hospital. J. Transl. Med. 2021, 19, 1–11. [Google Scholar] [CrossRef] [PubMed]
- Chowdhury, M.E.; Rahman, T.; Khandakar, A.; Mazhar, R.; Kadir, M.A.; Mahbub, Z.B.; Islam, K.R.; Khan, M.S.; Iqbal, A.; Al Emadi, N.; et al. Can AI help in screening viral and COVID-19 pneumonia? IEEE Access 2020, 8, 132665–132676. [Google Scholar] [CrossRef]
- Zame, W.R.; Bica, I.; Shen, C.; Curth, A.; Lee, H.-S.; Bailey, S.; Weatherall, J.; Wright, D.; Bretz, F.; Van Der Schaar, M. Machine learning for clinical trials in the era of COVID-19. Stat. Biopharm. Res. 2020, 12, 506–517. [Google Scholar] [CrossRef] [PubMed]
- Shahid, O.; Nasajpour, M.; Pouriyeh, S.; Parizi, R.M.; Han, M.; Valero, M.; Li, F.; Aledhari, M.; Sheng, Q.Z. Machine learning research towards combating COVID-19: Virus detection, spread prevention, and medical assistance. J. Biomed. Inform. 2021, 117, 103751. [Google Scholar] [CrossRef] [PubMed]
- Qayyum, A.; Qadir, J.; Bilal, M.; Al-Fuqaha, A. Secure and robust machine learning for healthcare: A survey. IEEE Rev. Biomed. Eng. 2020, 14, 156–180. [Google Scholar] [CrossRef]
- Davenport, T.; Kalakota, R. The potential for artificial intelligence in healthcare. Futur. Health J. 2019, 6, 94–98. [Google Scholar] [CrossRef] [Green Version]
- Yilmaz, L.; Tolk, A. Intelligent decision making: An AI-based approach. In Intelligent Decision Making: An AI-Based Approach; Springer: Berlin/Heidelberg, Germany, 2008; pp. 193–226. [Google Scholar]
- Pourhomayoun, M.; Shakibi, M. Predicting mortality risk in patients with COVID-19 using machine learning to help medical decision-making. Smart Health 2021, 20, 100178. [Google Scholar] [CrossRef]
- Papandrianos, N.; Papageorgiou, E.; Anagnostis, A.; Papageorgiou, K. Bone metastasis classification using whole body images from prostate cancer patients based on convolutional neural networks application. PLoS ONE 2020, 15, e0237213. [Google Scholar] [CrossRef]
- Papandrianos, N.; Papageorgiou, E.; Anagnostis, A.; Feleki, A. A deep-learning approach for diagnosis of metastatic breast cancer in bones from whole-body scans. Appl. Sci. 2020, 10, 997. [Google Scholar] [CrossRef] [Green Version]
- Papandrianos, N.; Papageorgiou, E.; Anagnostis, A.; Papageorgiou, K. Efficient bone metastasis diagnosis in bone scintigraphy using a fast convolutional neural network architecture. Diagnostics 2020, 10, 532. [Google Scholar] [CrossRef]
- Kalatzis, A.; Mortazavi, B.; Pourhomayoun, M. Interactive dimensionality reduction for improving patient adherence in remote health monitoring. In Proceedings of the 2018 International Conference on Computational Science and Computational Intelligence, CSCI, Las Vegas, NV, USA, 12–14 December 2018. [Google Scholar]
- Das, S.; Dey, A.; Pal, A.; Roy, N. Applications of artificial intelligence in machine learning: Review and prospect. Int. J. Comput. Appl. 2015, 115, 31–41. [Google Scholar] [CrossRef]
- Saleem, T.J.; Chishti, M.A. Exploring the applications of machine learning in healthcare. Int. J. Sens. Wirel. Commun. Control 2020, 10, 458–472. [Google Scholar] [CrossRef]
- Li, H.; Zhang, Z. EEG Signal Processing and Feature Extraction; Springer: Berlin/Heidelberg, Germany, 2019. [Google Scholar]
- Bolourani, S.; Brenner, M.; Wang, P.; McGinn, T.; Hirsch, J.S.; Barnaby, D.; Zanos, T.P.; Northwell COVID-19 Research Consortium. A machine learning prediction model of respiratory failure within 48 hours of patient admission for COVID-19: Model development and validation. J. Med. Internet Res. 2021, 23, e24246. [Google Scholar] [CrossRef] [PubMed]
- Liang, W.; Liang, H.; Ou, L.; Chen, B.; Chen, A.; Li, C.; Li, Y.; Guan, W.; Sang, L.; Lu, J.; et al. Development and validation of a clinical risk score to predict the occurrence of critical illness in hospitalized patients with COVID-19. JAMA Intern. Med. 2020, 180, 1081–1089. [Google Scholar] [CrossRef]
- Guan, X.; Zhang, B.; Fu, M.; Li, M.; Yuan, X.; Zhu, Y.; Peng, J.; Guo, H.; Lu, Y. Clinical and inflammatory features based machine learning model for fatal risk prediction of hospitalized COVID-19 patients: Results from a retrospective cohort study. Ann. Med. 2021, 53, 257–266. [Google Scholar] [CrossRef]
- Banerjee, A.; Ray, S.; Vorselaars, B.; Kitson, J.; Mamalakis, M.; Weeks, S.; Bakerg, M.; Mackenzie, L.S. Use of machine learning and artificial intelligence to predict SARS-CoV-2 infection from full blood counts in a population. Int. Immunopharmacol. 2020, 86, 106705. [Google Scholar] [CrossRef]
- Zhou, X.; Wang, Z.; Li, S.; Liu, T.; Wang, X.; Xia, J.; Zhao, Y. Machine learning-based decision model to distinguish between COVID-19 and influenza: A retrospective, two-centered, diagnostic study. Health Policy/Politi de Sante 2021, 14, 595–604. [Google Scholar] [CrossRef] [PubMed]
- Heffernan, A.J.; Denny, K.J. Host diagnostic biomarkers of infection in the ICU: Where are we and where are we going? Curr. Infect. Dis. Reports. 2021, 23, 1–11. [Google Scholar] [CrossRef]
- Bertsimas, D.; Lukin, G.; Mingardi, L.; Nohadani, O.; Orfanoudaki, A.; Stellato, B.; Wiberg, H.; Gonzalez-Garcia, S.; Parra-Calderón, C.L.; Robinson, K.; et al. COVID-19 mortality risk assessment: An international multi-center study. PLoS ONE 2020, 15, e0243262. [Google Scholar] [CrossRef] [PubMed]
- Wu, G.; Yang, P.; Xie, Y.; Woodruff, H.C.; Rao, X.; Guiot, J.; Frix, A.-N.; Louis, R.; Moutschen, M.; Li, J. Development of a clinical decision support system for severity risk prediction and triage of COVID-19 patients at hospital admission: An international multicentre study. Eur. Respir. J. 2020, 56, 2. [Google Scholar] [CrossRef] [PubMed]
- Chamola, V.; Hassija, V.; Gupta, S.; Goyal, A.; Guizani, M.; Sikdar, B. Disaster and pandemic management using machine learning: A survey. IEEE Internet Things J. 2020, 8, 16047–16071. [Google Scholar] [CrossRef]
- Pathak, Y.; Shukla, P.; Tiwari, A.; Stalin, S.; Singh, S. Deep transfer learning based classification model for COVID-19 disease. IRBM 2020. [Google Scholar] [CrossRef] [PubMed]
- Sprung, C.L.; Joynt, G.M.; Christian, M.D.; Truog, R.D.; Rello, J.; Nates, J.L. Adult ICU triage during the coronavirus disease 2019 pandemic: Who will live and who will die? Recommendations to improve survival. Crit. Care Med. 2020, 48, 1196–1202. [Google Scholar] [CrossRef] [PubMed]
- Killgore, W.D.S.; Cloonan, S.A.; Taylor, E.C.; Dailey, N.S. Mental health during the first weeks of the COVID-19 pandemic in the United States. Front. Psychiatry 2021, 12, 561898. [Google Scholar] [CrossRef]
- Grace, S.L.; Hershenfield, K.; Robertson, E.; Stewart, D.E. The occupational and psychosocial impact of SARS on academic physicians in three affected hospitals. J. Psychosom. Res. 2005, 46, 385–391. [Google Scholar] [CrossRef] [PubMed]
- Galbraith, N.; Boyda, D.; McFeeters, D.; Hassan, T. The mental health of doctors during the COVID-19 pandemic. BJPsych Bull. 2020, 45, 93–97. [Google Scholar] [CrossRef]
- Maben, J.; Bridges, J. COVID-19: Supporting nurses’ psychological and mental health. J. Clin. Nurs. 2020, 29, 2742–2750. [Google Scholar] [CrossRef] [Green Version]
- Baskin, R.G.; Bartlett, R. Healthcare worker resilience during the COVID-19 pandemic: An integrative review. J. Nurs. Manag. 2021, 29, 2329–2342. [Google Scholar] [CrossRef] [PubMed]
- Mangory, K.Y.; Ali, L.Y.; Rø, K.I.; Tyssen, R. Effect of burnout among physicians on observed adverse patient outcomes: A literature review. BMC Health Serv. Res. 2021, 21, 369. [Google Scholar] [CrossRef]
- Fink, G. Stress: Concepts, cognition, emotion, and behavior: Handbook in stress series. In Stress: Concepts, Cognition, Emotion, and Behavior: Handbook in Stress Series; Academic Press: Cambridge, MA, USA, 2016; Volume 1. [Google Scholar]
- National Academies of Sciences, Engineering, and Medicine; National Academy of Medicine; Committee on Systems Approaches to Improve Patient Care by Supporting Clinician Well-Being. Taking Action against Clinician Burnout: A Systems Approach to Professional Well-Being; National Academies Press: Washington, DC, USA, 2019. [Google Scholar]
- Anagnostis, A.; Papageorgiou, E.; Bochtis, D. Application of artificial neural networks for natural gas consumption forecasting. Sustainability 2020, 12, 6409. [Google Scholar] [CrossRef]
- Saracco, J.; Chavent, M.; Garcia-Audin, L.; Lespinet-Najib, V.; Ron-Langevin, R. Classification de variables et analyse multivariée de données mixtes issues d’une étude BCI. Ingénierie Cogn. 2018. [Google Scholar] [CrossRef]
- Neath, A.A.; Cavanaugh, J.E. The Bayesian information criterion: Background, derivation, and applications. Wiley Interdiscip. Rev. Comput. Stat. 2011, 4, 199–203. [Google Scholar] [CrossRef]
- Reynolds, D. Gaussian mixture models. Encycl. Biom. 2009, 741, 659–663. [Google Scholar]
- Waring, J.; Lindvall, C.; Umeton, R. Automated machine learning: Review of the state-of-the-art and opportunities for healthcare. Artif. Intell. Med. 2020, 104, 101822. [Google Scholar] [CrossRef]
- Ji, D.; Zhang, D.; Xu, J.; Chen, Z.; Yang, T.; Zhao, P.; Chen, G.; Cheng, G.; Wang, Y.; Bi, J.; et al. Prediction for Progression Risk in Patients With COVID-19 Pneumonia: The CALL Score. Clin. Infect. Dis. 2020, 71, 1393–1399. [Google Scholar] [CrossRef] [Green Version]
- Wynants, L.; Van Calster, B.; Collins, G.S.; Riley, R.D.; Heinze, G.; Schuit, E.; Bonten, M.M.; Dahly, D.L.; Damen, J.A.; Debray, T.P.; et al. Prediction models for diagnosis and prognosis of COVID-19 infection: Systematic review and critical appraisal WhAt is AlreAdy knoWn on this topic. BMJ 2020, 369, m1328. [Google Scholar] [CrossRef] [Green Version]
- Khodeir, M.M.; Shabana, H.A.; Alkhamiss, A.S.; Rasheed, Z.; Alsoghair, M.; Alsagaby, S.A.; Khan, M.I.; Fernández, N.; Al Abdulmonem, W. Early prediction keys for COVID-19 cases progression: A meta-analysis. J. Infect. Public Health 2021, 14, 561–569. [Google Scholar] [CrossRef] [PubMed]
- Drent, M.; Cobben, N.A.M.; Henderson, R.F.; Wouters, E.F.M.; Van Dieijen-Visser, M. Usefulness of lactate dehydrogenase and its isoenzymes as indicators of lung damage or inflammation. Eur. Respir. J. 1996, 9, 1736–1742. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Mehta, P.; McAuley, D.F.; Brown, M.; Sanchez, E.; Tattersall, R.S.; Manson, J.J. COVID-19: Consider cytokine storm syndromes and immunosuppression. Lancet 2020, 395, 1033–1034. [Google Scholar] [CrossRef]
- Vargas-vargas, M.; Cortés-rojo, C. Letter to the editor Ferritin levels and COVID-19. Ther. Adv. Vaccines. 2020, 44, e72. [Google Scholar]
- Abbaspour, N.; Hurrell, R.; Kelishadi, R. Review on iron and its importance for human health. J. Res. Med. Sci. 2014, 19, 164–174. [Google Scholar] [PubMed]
- Gallo Marin, B.; Aghagoli, G.; Lavine, K.; Yang, L.; Siff, E.J.; Chiang, S.S.; Salazar-Mather, T.P.; Dumenco, L.; Savaria, M.C.; Aung, S.N.; et al. Predictors of COVID-19 severity: A literature review. Rev. Med. Virol. 2021, 31, 1–10. [Google Scholar] [CrossRef] [PubMed]
- Poggiali, E.; Zaino, D.; Immovilli, P.; Rovero, L.; Losi, G.; Dacrema, A.; Nuccetelli, M.; Vadacca, G.B.; Guidetti, D.; Vercelli, A.; et al. Lactate dehydrogenase and C-reactive protein as predictors of respiratory failure in COVID-19 patients. Clin. Chim. Acta 2020, 509, 135–138. [Google Scholar] [CrossRef] [PubMed]
- Oh, B.; Hwangbo, S.; Jung, T.; Min, K.; Lee, C.; Apio, C.; Lee, H.; Lee, S.; Moon, M.K.; Kim, S.-W.; et al. Prediction models for the clinical severity of patients with COVID-19 in Korea: Retrospective multicenter cohort study. J. Med. Internet Res. 2021, 23, e25852. [Google Scholar] [CrossRef] [PubMed]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Type | Variable |
|---|---|
| General (mixed) | sex, age |
| Comorbidities (categorical) | Cardiovascular_disease, chronic_kidney_disease, chronic_obstructive_pulmonary_disease, asthma, diabetes mellitus, arterial_hypertension, immunosuppression, cancer |
| Symptoms (categorical) | cough, fever, weakness, headache, dizziness, abdominal_pain, nausea, diarrhea, vomit, anosmia, tastelessness, throat_pain |
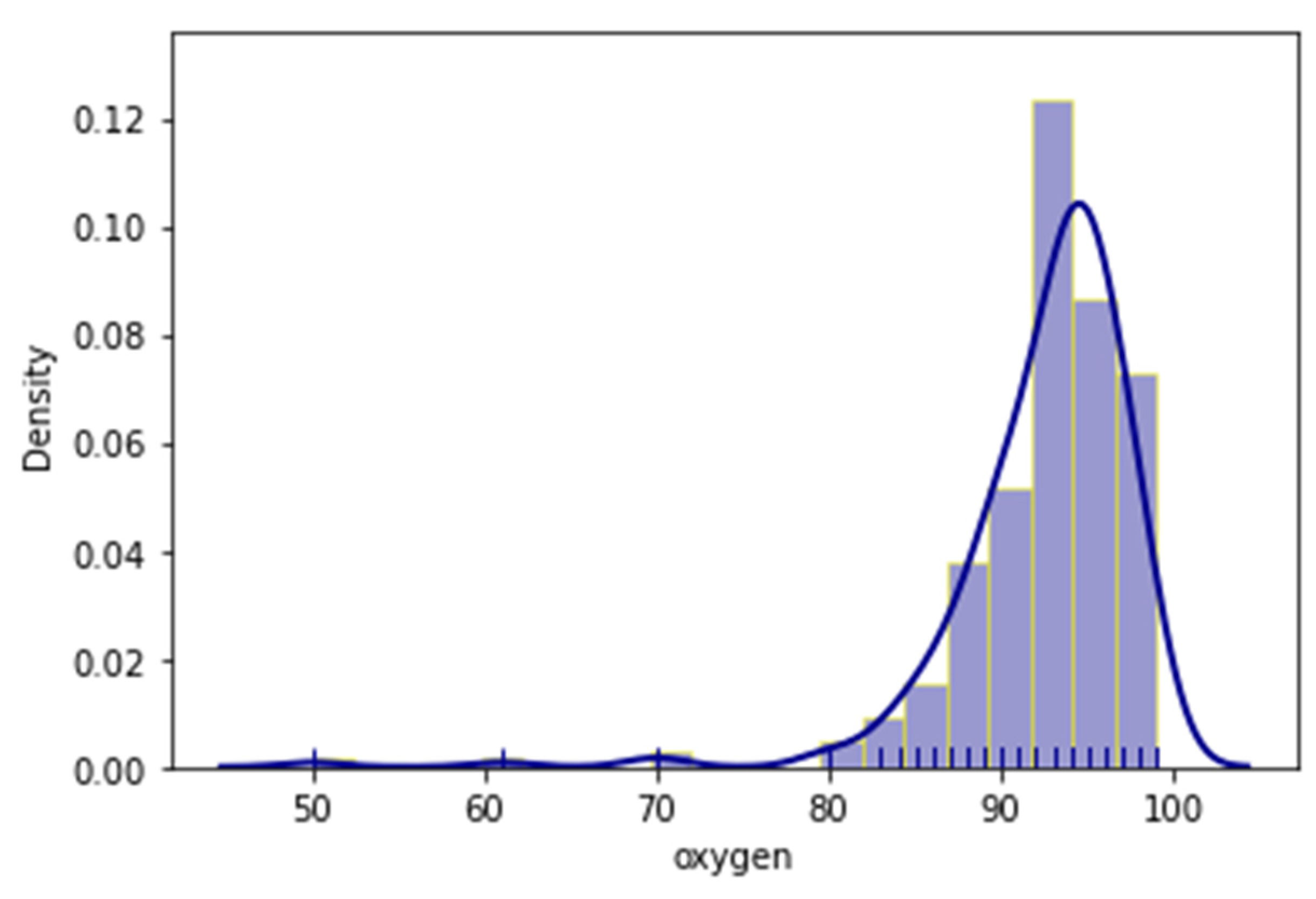
| Measurable (numerical) | oxygen, temperature, d-dimmers, WBC, Ht, eosinophils, basophils, PLT, ferritin, AST, ALT, LDH, albumin, CRP, IL6, lymphocytes |
| Reference (mixed) | Hospitalization_ICU, death |
| Comorbidities | Counts (n) | Percentages (%) |
|---|---|---|
| Cardiovascular Disease | 68 | 25.37 |
| Chronic Kidney Disease | 8 | 2.98 |
| Chronic obstructive pulmonary disease | 10 | 3.73 |
| Asthma | 5 | 1.87 |
| Diabetes mellitus | 48 | 17.91 |
| Arterial Hypertension | 98 | 36.57 |
| Immunosuppresion | 9 | 3.36 |
| Cancer | 15 | 5.60 |
| Cluster # | 1 | 2 | 3 | 4 |
|---|---|---|---|---|
| total patients | 110 | 21 | 58 | 79 |
| sex (male/female) | 29/81 | 13/8 | 41/17 | 53/26 |
| age | 61.3 ± 15.0 | 65.4 ± 13.9 | 64.5 ± 13.9 | 65.2 ± 13.9 |
| oxygen | 94.2 ± 3.3 | 87.5 ± 11.4 | 90.6 ± 6.1 | 92.9 ± 3.1 |
| temperature | 37.1 ± 0.7 | 37.5 ± 0.8 | 37.3 ± 0.8 | 37.5 ± 0.7 |
| d-dimers | 451.2 ± 697.2 | 1833.7 ± 3845.4 | 1020.7 ± 1233.4 | 483.4 ± 539.9 |
| WBC | 6.2 ± 2.8 | 11.3 ± 5.8 | 10.4 ± 8.3 | 6.5 ± 2.8 |
| Ht | 36.3 ± 10.9 | 29.2 ± 16.9 | 32.9 ± 15.9 | 31.1 ± 17.0 |
| eosinophils | 0.08 ± 0.4 | 0.008 ± 0.01 | 0.04 ± 0.1 | 0.1 ± 0.7 |
| basophils | 0.04 ± 0.1 | 0.02 ± 0.02 | 0.02 ± 0.04 | 0.03 ± 0.07 |
| PLT | 217.2 ± 92.2 | 291.3 ± 136.3 | 240.9 ± 134.5 | 194.4 ± 80.7 |
| ferritin | 291.2 ± 217.7 | 2084.4 ± 2353.3 | 811.7 ± 720.8 | 421.4 ± 280.4 |
| AST | 29.7 ± 14.3 | 146.3 ± 103.8 | 58.5 ± 33.2 | 30.6 ± 13.6 |
| ALT | 25.4 ± 15.5 | 112.3 ± 91.2 | 47.1 ± 38.7 | 23.1 ± 12.9 |
| LDH | 266.8 ± 83.0 | 646.9 ± 250.8 | 473.6 ± 38.7 | 306.7 ± 89.6 |
| albumin | 3.6 ± 0.4 | 3.3 ± 0.4 | 9.7 ± 48.4 | 8.3 ± 41.9 |
| CRP | 4.0 ± 4.0 | 179.6 ± 747.2 | 9.4 ± 9.2 | 11.9 ± 47.3 |
| IL6 | 28.2 ± 32.6 | 160.9 ± 246.6 | 94.9 ± 144.7 | 31.4 ± 23.6 |
| lymphocytes | 2.39 ± 8.6 | 1.3 ± 0.8 | 18.1 ± 129.3 | 1.2 ± 0.6 |
| Cluster # | 1 | 2 | 3 | 4 |
|---|---|---|---|---|
| total patients | 110 | 21 | 58 | 79 |
| sex (male/female) | 29/81 | 13/8 | 41/17 | 53/26 |
| cardiovascular disease (%) | 21 (19.1%) | 7 (33.3%) | 12 (20.7%) | 28 (35.4%) |
| chronic kidney disease (%) | 1 (0.9%) | 1 (4.8%) | 3 (5.2%) | 3 (3.8%) |
| chronic obstructive pulmonary disease (%) | 3 (2.7%) | 1 (4.8%) | 3 (5.2%) | 3 (3.8%) |
| asthma (%) | 3 (2.7%) | 1 (4.8%) | 1 (1.7%) | 0 (0%) |
| diabetes (%) | 13 (11.8%) | 3 (14.3%) | 8 (13.8%) | 24 (30.4%) |
| arterial hypertension (%) | 28 (25.5%) | 4 (19.0%) | 25 (43.1%) | 41 (51.9%) |
| immunosuppression (%) | 3 (2.7%) | 0 (0%) | 1 (1.7%) | 5 (6.3%) |
| cancer (%) | 6 (5.5%) | 2 (9.5%) | 2 (3.4%) | 5 (6.3%) |
| cough (%) | 19 (17.3%) | 7 (33.3%) | 19 (32.8%) | 28 (35.4%) |
| fever (%) | 63 (57.3%) | 4 (19.0%) | 49 (84.5%) | 77 (97.5%) |
| weakness (%) | 23 (20.9%) | 2 (9.5%) | 20 (34.5%) | 38 (48.1%) |
| headache (%) | 1 (0.9%) | 0 (0%) | 1 (1.7%) | 3 (3.8%) |
| dizziness (%) | 6 (5.5%) | 0 (0%) | 2 (3.4%) | 3 (3.8%) |
| abdominal ache (%) | 2 (1.8%) | 0 (0%) | 1 (1.7%) | 1 (1.3%) |
| nausea (%) | 2 (1.8%) | 0 (0%) | 0 (0%) | 4 (5.1%) |
| diarrhea (%) | 7 (6.4%) | 0 (0%) | 4 (6.9%) | 6 (7.6%) |
| vomit (%) | 4 (3.6%) | 0 (0%) | 3 (5.2%) | 3 (3.8%) |
| anosmia (%) | 2 (1.8%) | 0 (0%) | 0 (0%) | 1 (1.3%) |
| tastelessness (%) | 1 (0.9%) | 0 (0%) | 0 (0%) | 1 (1.3%) |
| throat ache (%) | 4 (3.6%) | 0 (0%) | 0 (0%) | 1 (1.3%) |
| hospitalization ICU (%) | 2 (1.8%) | 5 (23.8%) | 8 (13.8%) | 6 (7.6%) |
| death (%) | 1 (0.9%) | 5 (23.8%) | 5 (8.6%) | 6 (7.6%) |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Karlafti, E.; Anagnostis, A.; Kotzakioulafi, E.; Vittoraki, M.C.; Eufraimidou, A.; Kasarjyan, K.; Eufraimidou, K.; Dimitriadou, G.; Kakanis, C.; Anthopoulos, M.; et al. Does COVID-19 Clinical Status Associate with Outcome Severity? An Unsupervised Machine Learning Approach for Knowledge Extraction. J. Pers. Med. 2021, 11, 1380. https://doi.org/10.3390/jpm11121380
Karlafti E, Anagnostis A, Kotzakioulafi E, Vittoraki MC, Eufraimidou A, Kasarjyan K, Eufraimidou K, Dimitriadou G, Kakanis C, Anthopoulos M, et al. Does COVID-19 Clinical Status Associate with Outcome Severity? An Unsupervised Machine Learning Approach for Knowledge Extraction. Journal of Personalized Medicine. 2021; 11(12):1380. https://doi.org/10.3390/jpm11121380
Chicago/Turabian StyleKarlafti, Eleni, Athanasios Anagnostis, Evangelia Kotzakioulafi, Michaela Chrysanthi Vittoraki, Ariadni Eufraimidou, Kristine Kasarjyan, Katerina Eufraimidou, Georgia Dimitriadou, Chrisovalantis Kakanis, Michail Anthopoulos, and et al. 2021. "Does COVID-19 Clinical Status Associate with Outcome Severity? An Unsupervised Machine Learning Approach for Knowledge Extraction" Journal of Personalized Medicine 11, no. 12: 1380. https://doi.org/10.3390/jpm11121380