Machine-Learning-Based Laboratory Developed Test for the Diagnosis of Sepsis in High-Risk Patients


Abstract
:1. Introduction
2. Materials and Methods
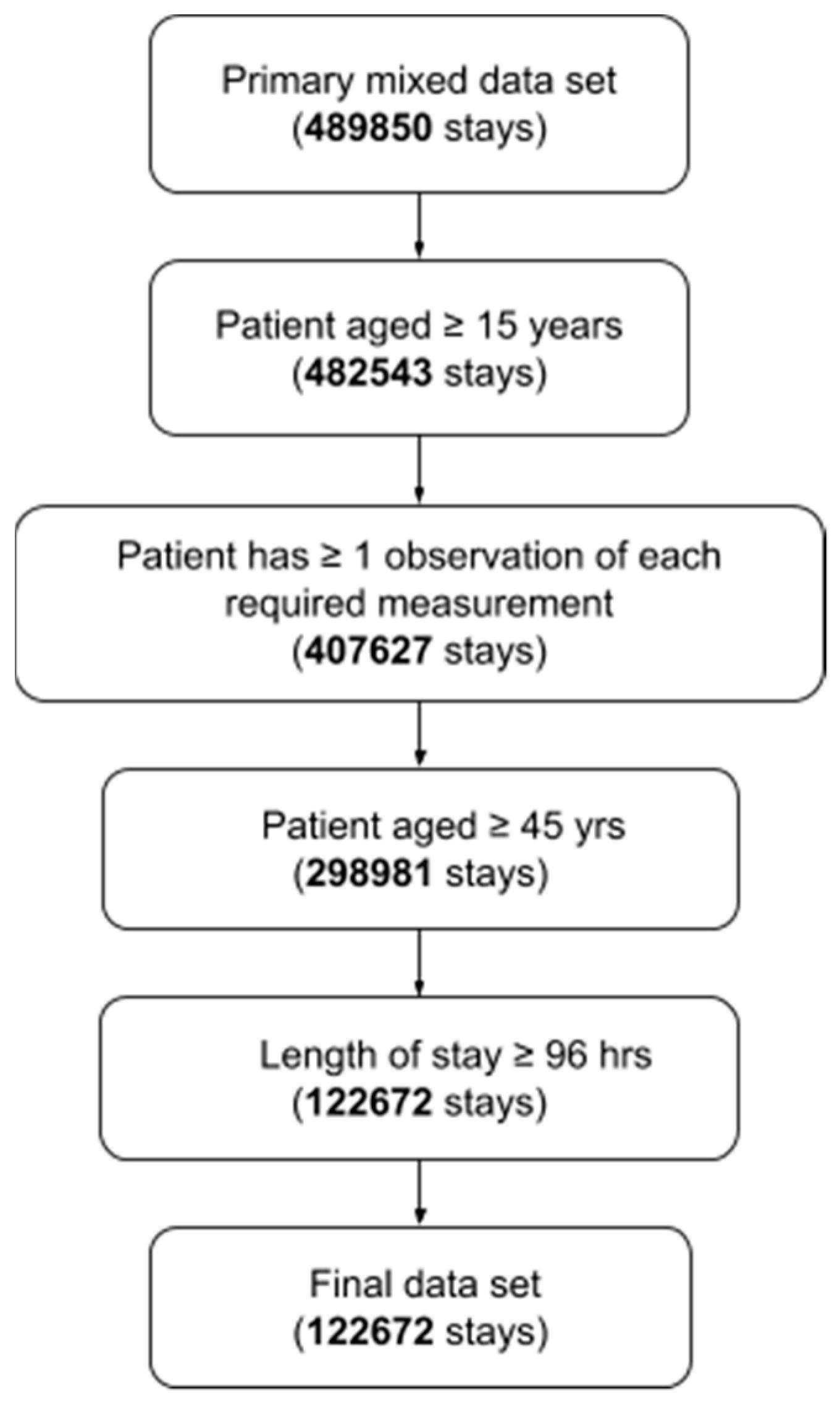
2.1. Datasets for Training and Testing
2.2. Inclusion Criteria
2.3. Definition of Sepsis Onset Time
2.4. Model Diagnostic Problem and Machine Learning Methods
2.5. Comparators
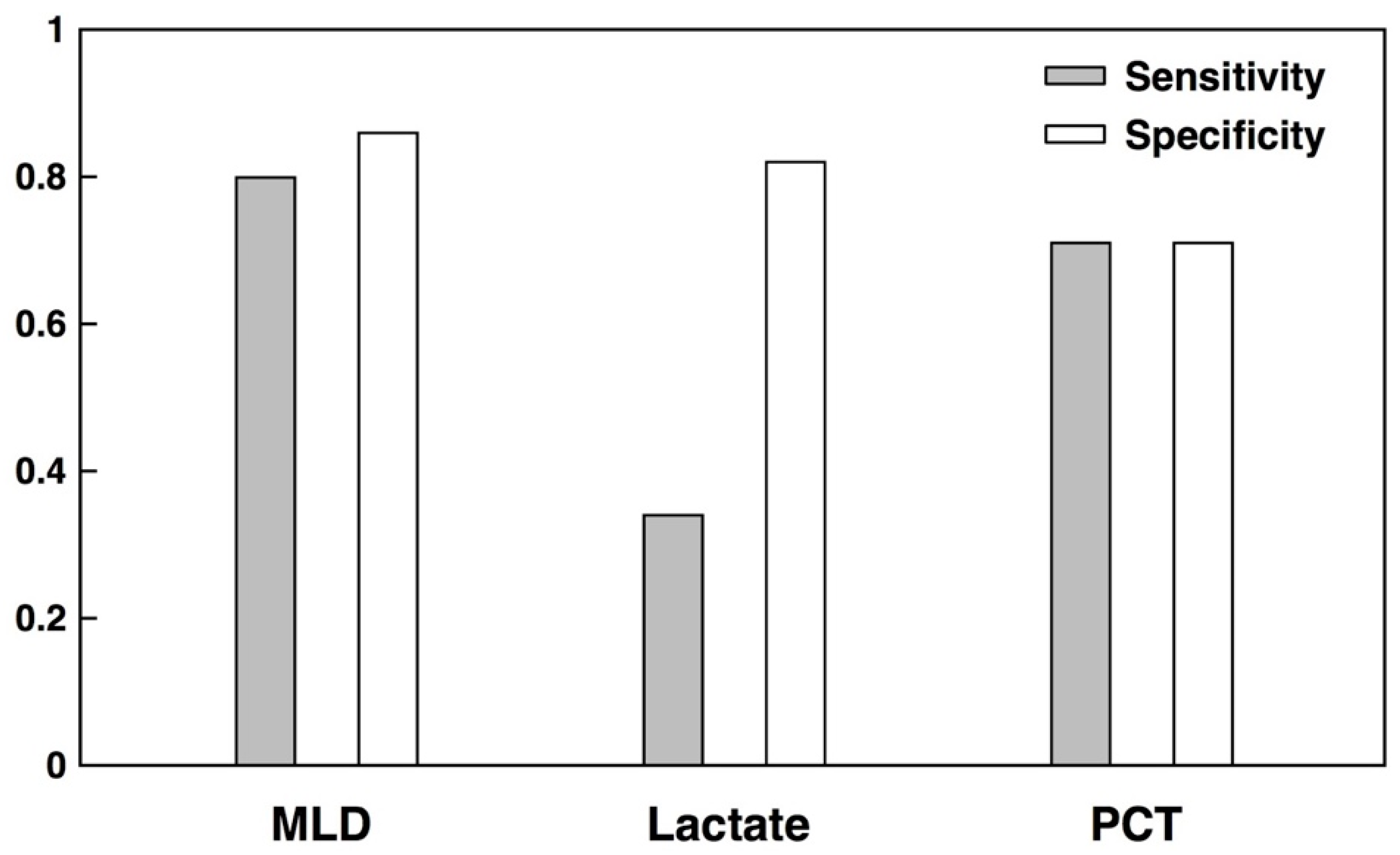
3. Results
4. Discussion
Author Contributions
Funding
Conflicts of Interest
References
- Lever, A.; Mackenzie, I. Sepsis: Definition, epidemiology, and diagnosis. BMJ 2007, 335, 879–883. [Google Scholar] [CrossRef] [PubMed]
- Angus, D.C.; Linde-Zwirble, W.T.; Lidicker, J.; Clermont, G.; Carcillo, J.; Pinsky, M.R. Epidemiology of severe sepsis in the United States: Analysis of incidence, outcome, and associated costs of care. Crit. Care Med. 2001, 29, 1303–1310. [Google Scholar] [CrossRef] [PubMed]
- McCoy, A.; Das, R. Reducing patient mortality, length of stay and readmissions through machine learning based sepsis prediction in the emergency department, intensive care unit and hospital floor units. BMJ Open Qual. 2017, 6, e000158. [Google Scholar] [CrossRef] [PubMed]
- Chalupka, A.N.; Talmor, D. The economics of sepsis. Crit. Care Clin. 2012, 28, 57–76. [Google Scholar] [CrossRef] [PubMed]
- Stevenson, E.K.; Rubenstein, A.R.; Radin, G.T.; Wiener, R.S.; Walkey, A.J. Two decades of mortality trends among patients with severe sepsis: A comparative meta-analysis. Crit. Care Med. 2014, 42, 625. [Google Scholar] [CrossRef] [PubMed]
- Gaieski, D.F.; Edwards, J.M.; Kallan, M.J.; Carr, B.G. Benchmarking the incidence and mortality of severe sepsis in the United States. Crit. Care Med. 2013, 41, 1167–1174. [Google Scholar] [CrossRef] [PubMed]
- Dellinger, R.P.; Levy, M.M.; Rhodes, A.; Annane, D.; Gerlach, H.; Opal, S.M.; Sevransky, J.E.; Sprung, C.L.; Douglas, I.S.; Jaeschke, R.; et al. Surviving Sepsis Campaign Guidelines Committee including The Pediatric Subgroup. Surviving Sepsis Campaign: International guidelines for management of severe sepsis and septic shock, 2012. Intens. Care Med. 2013, 32, 165–228. [Google Scholar] [CrossRef] [PubMed]
- Dellinger, R.P.; Levy, MM.; Carlet, J.M.; Bion, J.; Parker, M.M.; Jaeschke, R.; Calandra, T. Surviving Sepsis Campaign: International guidelines for management of severe sepsis and septic shock. Intens. Care Med. 2008, 34, 17–60. [Google Scholar] [CrossRef] [PubMed]
- Singer, A.J.; Taylor, M.; Domingo, A.; Ghazipura, S.; Khorasonchi, A.; Thode, H.C., Jr.; Shapiro, N.I. Diagnostic characteristics of a clinical screening tool in combination with measuring bedside lactate level in emergency department patients with suspected sepsis. Acad. Emerg. Med. 2014, 21, 853–857. [Google Scholar] [CrossRef]
- Taneja, I.; Reddy, B.; Damhorst, G.; Zhao, S.D.; Hassan, U.; Price, Z.; Winter, J. Combining biomarkers with EMR data to identify patients in different phases of sepsis. Sci. Rep. 2017, 7, 10800. [Google Scholar] [CrossRef] [PubMed]
- Haydar, S.; Spanier, M.; Weems, P.; Wood, S.; Strout, T. Comparison of QSOFA score and SIRS criteria as screening mechanisms for emergency department sepsis. Am. J. Emerg. Med. 2017, 35, 1730–1733. [Google Scholar] [CrossRef] [PubMed]
- Churpek, M.M.; Zadravecz, F.J.; Winslow, C.; Howell, M.D.; Edelson, D.P. Incidence and prognostic value of the systemic inflammatory response syndrome and organ dysfunctions in ward patients. Am. J. Respir. Crit. Care Med. 2015, 192, 958–964. [Google Scholar] [CrossRef] [PubMed]
- Vincent, J.; de Mendonça, A.; Cantraine, F.; Monero, R.; Takala, J.; Suter, P.M.; Sprung, C.L.; Colardyn, F.; Blecher, S. Use of the SOFA score to assess the incidence of organ dysfunction/failure in intensive care units: Results of a multicenter, prospective study. Crit. Care Med. 1998, 26, 1793–1800. [Google Scholar] [CrossRef] [PubMed]
- Saeed, M.; Villarroel, M.; Reisner, A.T.; Clifford, G.; Lehman, L.W.; Moody, G.; Mark, R.G. Multiparameter Intelligent Monitoring in Intensive Care II (MIMIC-II): A public-access intensive care unit database. Crit. Care Med. 2011, 39, 952. [Google Scholar] [CrossRef] [PubMed]
- Johnson, A.E.; Pollard, T.J.; Shen, L.; Li-Wei, H.L.; Feng, M.; Ghassemi, M.; Moody, B.; Szolovits, P.; Celi, L.A.; Mark, R.G. MIMIC-III, a freely accessible critical care database. Sci. Data 2016, 3, 160035. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Lipton, Z.C.; Kale, D.C.; Elkan, C.; Wetzel, R. Learning to diagnose with LSTM recurrent neural networks. arXiv, 2015; arXiv:1511.03677. [Google Scholar]
- Nachimuthu, S.K.; Huag, P.J. Early Detection of Sepsis in the Emergency Department using Dynamic Bayesian Networks. In Proceedings of the 2012 AMIA Annual Symposium, Chicago, IL, USA, 3–7 November 2012; pp. 653–662. [Google Scholar]
- Henry, K.E.; Hager, D.N.; Pronovost, P.J.; Saria, S. A targeted real-time early warning score (TREWScore) for septic shock. Sci. Transl. Med. 2015, 7, 299ra122. [Google Scholar] [CrossRef] [PubMed]
- Nemati, S.; Holder, A.; Razmi, F.; Stanley, M.D.; Clifford, G.D.; Buchman, T.G. An Interpretable Machine Learning Model for Accurate Prediction of Sepsis in the ICU. Crit. Care Med. 2018, 46, 547–553. [Google Scholar] [CrossRef] [PubMed]
- Mao, Q.; Jay, M.; Hoffman, J.; Calvert, J.; Barton, C.; Shimabukuro, D.; Shieh, L.; Chettipally, U.; Fletcher, G.; Kerem, Y.; et al. Multicentre validation of a sepsis prediction algorithm using only vital sign data in the emergency department, general ward and ICU. BMJ Open 2018, 8, 1–11. [Google Scholar] [CrossRef]
- Calvert, J.S.; Price, D.A.; Chettipally, U.K.; Barton, C.W.; Feldman, M.D.; Hoffman, J.L.; Jay, M.; Das, R. A computational approach to early sepsis detection. Comput. Biol. Med. 2016, 74, 69–73. [Google Scholar] [CrossRef] [Green Version]
- Calvert, J.; Desautels, T.; Chettipally, U.; Barton, C.; Hoffman, J.; Jay, M.; Mao, Q.; Mohamadlou, H.; Das, R. High-performance detection and early prediction of septic shock for alcohol-use disorder patients. Ann. Med. Surg. 2016, 8, 50–55. [Google Scholar] [CrossRef]
- Desautels, T.; Calvert, J.; Hoffman, J.; Jay, M.; Kerem, Y.; Shieh, L.; Shimabukuro, D.; Chettipally, U.; Feldman, M.D.; Barton, C.; et al. Prediction of sepsis in the intensive care unit with minimal electronic health record data: A machine learning approach. JMIR Med. Inform. 2016, 4, e28. [Google Scholar] [CrossRef] [PubMed]
- Chen, T.; Guestrin, C. Xgboost: A scalable tree boosting system. In Proceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, San Francisco, CA, USA, 13–17 August 2016; pp. 785–794. [Google Scholar]
- Gardner-Thorpe, J.; Love, N.; Wrightson, J.; Walsh, S.; Keeling, N. The value of Modified Early Warning Score (MEWS) in surgical in-patients: A prospective observational study. Ann. R. Coll. Surg. Engl. 2006, 88, 571–575. [Google Scholar] [CrossRef] [PubMed]
- Singer, M.; Deutschman, C.S.; Seymour, C.W.; Shankar-Hari, M.; Annane, D.; Bauer, M.; Bellomo, R.; Bernard, G.R.; Chiche, J.; Coopersmith, C.M.; et al. The Third International Consensus Definitions for Sepsis and Septic Shock (Sepsis-3). Jama 2016, 315, 801–810. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Fullerton, J.N.; Price, C.L.; Silvey, N.E.; Brace, S.J.; Perkins, G.D. Is the Modified Early Warning Score (MEWS) superior to clinician judgement in detecting critical illness in the pre-hospital environment? Resuscitation 2012, 83, 557–562. [Google Scholar] [CrossRef] [PubMed]
- Nguyen, H.B.; Rivers, E.P.; Knoblich, B.P.; Jacobsen, G.; Muzzin, A.; Ressler, J.A.; Tomlanovich, M.C. Early lactate clearance is associated with improved outcome in severe sepsis and septic shock. Crit. Care Med. 2004, 32, 1637–1642. [Google Scholar] [CrossRef] [PubMed]
- Tang, B.M.; Eslick, G.D.; Craig, J.C.; McLean, A.S. Accuracy of procalcitonin for sepsis diagnosis in critically ill patients: Systematic review and meta-analysis. Lancet Infect. Dis. 2007, 7, 210–217. [Google Scholar] [CrossRef]
- Calvert, J.; Hoffman, J.; Barton, C.; Shimabukuro, D.; Ries, M.; Chettipally, U.; Kerem, Y.; Jay, M.; Mataraso, S.; Das, R. Cost and mortality impact of an algorithm-driven sepsis prediction system. J. Med. Econ. 2017, 20, 646–651. [Google Scholar] [CrossRef]
- Simpson, S.Q. New sepsis criteria: A change we should not make. Chest 2016, 149, 1117–1118. [Google Scholar] [CrossRef]
- Abraham, E. New definitions for sepsis and septic shock: Continuing evolution but with much still to be done. Jama 2016, 315, 757–759. [Google Scholar] [CrossRef]



{kind=link}
{kind=link}
| Metric | MLD | SIRS | MEWS | qSOFA |
|---|---|---|---|---|
| AUROC | 0.917 | 0.468 | 0.639 | 0.653 |
| Sensitivity | 0.799 | 0.835 | 0.774 | 0.663 |
| Specificity | 0.860 | 0.036 | 0.317 | 0.531 |
| PPV | 0.566 | 0.166 | 0.206 | 0.244 |
| NPV | 0.949 | 0.489 | 0.860 | 0.873 |
| DOR | 24.4 | 0.190 | 1.59 | 2.23 |
| Accuracy | 0.848 | 0.185 | 0.402 | 0.556 |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Calvert, J.; Saber, N.; Hoffman, J.; Das, R. Machine-Learning-Based Laboratory Developed Test for the Diagnosis of Sepsis in High-Risk Patients. Diagnostics 2019, 9, 20. https://doi.org/10.3390/diagnostics9010020
Calvert J, Saber N, Hoffman J, Das R. Machine-Learning-Based Laboratory Developed Test for the Diagnosis of Sepsis in High-Risk Patients. Diagnostics. 2019; 9(1):20. https://doi.org/10.3390/diagnostics9010020
Chicago/Turabian StyleCalvert, Jacob, Nicholas Saber, Jana Hoffman, and Ritankar Das. 2019. "Machine-Learning-Based Laboratory Developed Test for the Diagnosis of Sepsis in High-Risk Patients" Diagnostics 9, no. 1: 20. https://doi.org/10.3390/diagnostics9010020