
Validation of a Deep Learning Chest X-ray Interpretation Model: Integrating Large-Scale AI and Large Language Models for Comparative Analysis with ChatGPT


Abstract
:1. Introduction
2. Materials and Methods
2.1. Dataset
2.2. Input Data
2.3. Analyzing Readings by LLMs
2.4. Statistical Analytics
3. Results
4. Discussion
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Sezgin, E. Artificial intelligence in healthcare: Complementing, not replacing, doctors and healthcare providers. Digit. Health 2023, 9, 20552076231186520. [Google Scholar] [CrossRef] [PubMed]
- Meskó, B.; Topol, E.J. The imperative for regulatory oversight of large language models (or generative AI) in healthcare. Npj Digit. Med. 2023, 6, 120. [Google Scholar] [CrossRef] [PubMed]
- Yang, H.; Li, J.; Liu, S.; Du, L.; Liu, X.; Huang, Y.; Shi, Q.; Liu, J. Exploring the Potential of Large Language Models in Personalized Diabetes Treatment Strategies. medRxiv 2023. [Google Scholar] [CrossRef]
- Omiye, J.A.; Lester, J.; Spichak, S.; Rotemberg, V.; Daneshjou, R. Beyond the hype: Large language models propagate race-based medicine. medRxiv 2023. [Google Scholar] [CrossRef]
- Tustumi, F.; Andreollo, N.A.; Aguilar-Nascimento, J.E.D. Future of the language models in healthcare: The role of chatbot. Arq. Bras. De Cir. Dig. 2023, 36, e1727. [Google Scholar] [CrossRef] [PubMed]
- Zhu, L.; Mou, W.; Chen, R. Can the ChatGPT and other Large Language Models with internet-connected database solve the questions and concerns of patient with prostate cancer? J. Transl. Med. 2023, 21, 269. [Google Scholar] [CrossRef] [PubMed]
- Beaulieu-Jones, B.R.; Shah, S.; Berrigan, M.T.; Marwaha, J.S.; Lai, S.L.; Brat, G.A. Evaluating Capabilities of Large Language Models: Performance of GPT4 on American Board of Surgery Qualifying Exam Question Banks. medRxiv 2023. [Google Scholar] [CrossRef]
- OpenAI. Usage Policies. 2023. Available online: https://openai.com/policies/usage-policies (accessed on 28 December 2023).
- Vedantham, S.; Shazeeb, M.S.; Chiang, A.; Vijayaraghavan, G.R. Artificial Intelligence in Breast X-ray Imaging. Semin. Ultrasound CT MRI 2022, 44, 2–7. [Google Scholar] [CrossRef]
- Shin, H.J.; Lee, S.; Kim, S.; Son, N.H.; Kim, E.K. Hospital-wide survey of clinical experience with artificial intelligence applied to daily chest radiographs. PLoS ONE 2023, 18, e0282123. [Google Scholar] [CrossRef]
- Tembhare, N.P.; Tembhare, P.U.; Chauhan, C.U. Chest X-ray Analysis using Deep Learning. Int. J. Sci. Technol. Eng. 2023, 11, 1441–1447. [Google Scholar] [CrossRef]
- Govindarajan, A.; Govindarajan, A.; Tanamala, S.; Chattoraj, S.; Reddy, B.; Agrawal, R.; Iyer, D.; Srivastava, A.; Kumar, P.; Putha, P. Role of an Automated Deep Learning Algorithm for Reliable Screening of Abnormality in Chest Radiographs: A Prospective Multicenter Quality Improvement Study. Diagnostics 2022, 12, 2724. [Google Scholar] [CrossRef] [PubMed]
- Ridder, K.; Preuhs, A.; Mertins, A.; Joerger, C. Routine Usage of AI-based Chest X-ray Reading Support in a Multi-site Medical Supply Center. arXiv 2022, arXiv:2210.10779. [Google Scholar]
- Vasilev, Y.; Vladzymyrskyy, A.; Omelyanskaya, O.; Blokhin, I.; Kirpichev, Y.; Arzamasov, K. AI-Based C.X.R. First Reading: Current Limitations to Ensure Practical Value. Diagnostics 2023, 13, 1430. [Google Scholar] [CrossRef] [PubMed]
- Kim, D.; Chung, J.; Choi, J.; Succi, M.D.; Conklin, J.; Longo, M.G.F.; Ackman, J.B.; Little, B.P.; Petranovic, M.; Kalra, M.K.; et al. Accurate auto-labeling of chest X-ray images based on quantitative similarity to an explainable AI model. Nat. Commun. 2022, 13, 1867. [Google Scholar] [CrossRef] [PubMed]
- Qin, C.; Yao, D.; Shi, Y.; Song, Z. Computer-aided detection in chest radiography based on artificial intelligence: A survey. Biomed. Eng. Online 2018, 17, 113. [Google Scholar] [CrossRef]
- Radford, A.; Kim, J.W.; Hallacy, C.; Ramesh, A.; Goh, G.; Agarwal, S.; Sastry, G.; Askell, A.; Mishkin, P.; Clark, J.; et al. Learning transferable visual models from natural language supervision. arXiv 2021, arXiv:2103.00020. [Google Scholar]
- Jia, C.; Yang, Y.; Xia, Y.; Chen, Y.; Parekh, Z.; Pham, H.; Le, Q.V.; Sung, Y.; Li, Z.; Duerig, T. Scaling up visual and vision-language representation learning with noisy text supervision. arXiv 2021, arXiv:2102.05918. [Google Scholar]
- Srivastav, S.; Chandrakar, R.; Gupta, S.; Babhulkar, V.; Agrawal, S.; Jaiswal, A.; Prasad, R.; Wanjari, M.B.; Agarwal, S.; Wanjari, M. ChatGPT in Radiology: The Advantages and Limitations of Artificial Intelligence for Medical Imaging Diagnosis. Cureus 2023, 15, e41435. [Google Scholar] [CrossRef]
- Hu, M.; Pan, S.; Li, Y.; Yang, X. Advancing Medical Imaging with Language Models: A Journey from N-grams to ChatGPT. arXiv 2023, arXiv:2304.04920. [Google Scholar]
- Biswas, S.; Logan, N.S.; Davies, L.N.; Sheppard, A.L.; Wolffsohn, J.S. Assessing the utility of ChatGPT as an artificial intelligence-based large language model for information to answer questions on myopia. Ophthalmic Physiol. Opt. 2023, 43, 1562–1570. [Google Scholar] [CrossRef]
- Zhang, J.; Sun, K.; Jagadeesh, A.; Ghahfarokhi, M.; Gupta, D.; Gupta, A.; Gupta, V.; Guo, Y. The Potential and Pitfalls of using a Large Language Model such as ChatGPT or GPT-4 as a Clinical Assistant. arXiv 2023, arXiv:2307.08152. [Google Scholar]
- DeGrave, A.J.; Cai, Z.R.; Janizek, J.D.; Daneshjou, R.; Lee, S.I. Dissection of medical AI reasoning processes via physician and generative-AI collaboration. medRxiv 2023. [Google Scholar] [CrossRef]
- Jha, D.; Rauniyar, A.; Srivastava, A.; Hagos, D.H.; Tomar, N.K.; Sharma, V.; Keles, E.; Zhang, Z.; Demir, U.; Topcu, A.; et al. Ensuring Trustworthy Medical Artificial Intelligence through Ethical and Philosophical Principles. arXiv 2023, arXiv:2304.11530. [Google Scholar]
- Polat Erdeniz, S.; Kramer, D.; Schrempf, M.; Rainer, P.P.; Felfernig, A.; Tran, T.N.; Burgstaller, T.; Lubos, S. Machine Learning Based Risk Prediction for Major Adverse Cardiovascular Events for ELGA-Authorized Clinics1. In dHealth; Studies in health technology and informatics; IOS Press: Amsterdam, The Netherlands, 2023. [Google Scholar] [CrossRef]
- Chaddad, A.; Lu, Q.; Li, J.; Katib, Y.; Kateb, R.; Tanougast, C.; Bouridane, A.; Abdulkadir, A. Explainable, Domain-Adaptive, and Federated Artificial Intelligence in Medicine. IEEE/CAA J. Autom. Sin. 2022, 10, 859–876. [Google Scholar] [CrossRef]
- Lal, A.; Dang, J.; Nabzdyk, C.; Gajic, O.; Herasevich, V. Regulatory oversight and ethical concerns surrounding software as medical device (SaMD) and digital twin technology in healthcare. Ann. Transl. Med. 2022, 10, 950. [Google Scholar] [CrossRef]
- Hewitt, A.W. Dr AI will see you now. Clin. Exp. Ophthalmol. 2023, 51, 409–410. [Google Scholar] [CrossRef]
- Fowler, G.E.; Blencowe, N.S.; Hardacre, C.; Callaway, M.P.; Smart, N.J.; Macefield, R. Artificial intelligence as a diagnostic aid in cross-sectional radiological imaging of surgical pathology in the abdominopelvic cavity: A systematic review. BMJ Open 2023, 13, e064739. [Google Scholar] [CrossRef]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Assessment | Description | |
|---|---|---|
| Accuracy | Acceptable | The reading is accurate and clinically useful. |
| Questionable | There are errors in the reading, but it retains some clinical usability. | |
| Unacceptable | There are significant errors in the reading, rendering it clinically useless. | |
| False Findings | None | There are no false findings. |
| False Positive (FP) | The reading includes a false positive. | |
| False Negative (FN) | The reading includes a false negative. | |
| Both | The reading has both false positives and false negatives. | |
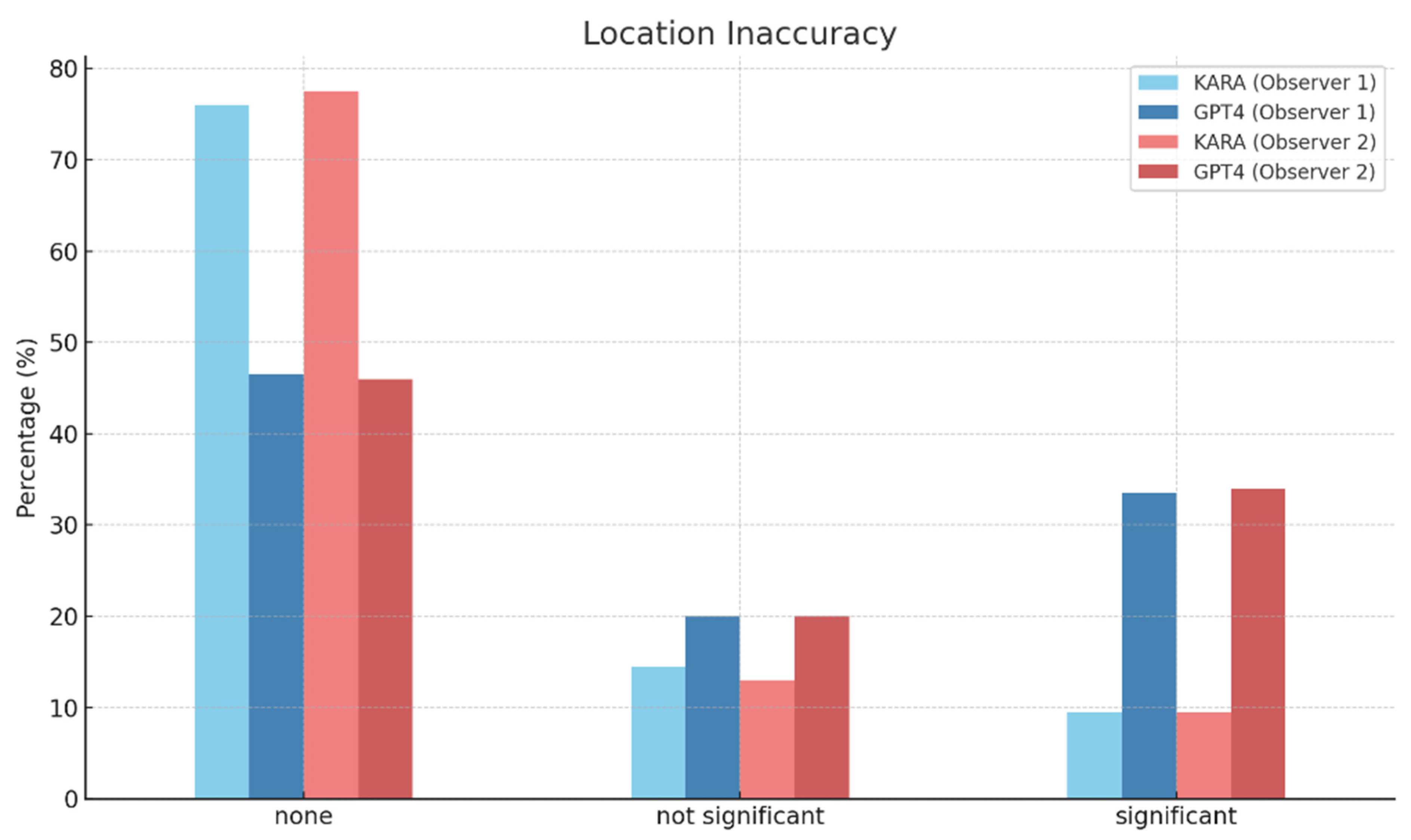
| Location Inaccuracy | None | There is no location inaccuracy. |
| Not significant | The location of lesions is inaccurately identified, but it does not significantly affect clinical judgment. | |
| Significant | The location of lesions is inaccurately identified, and it severely affects clinical judgment. | |
| Count Inaccuracy | None | There is no count inaccuracy. |
| Single | The count of lesions is inaccurate, but single error is noted. | |
| Multiple | The count of lesions is incorrect and multiple count errors of lesion are seen. | |
| Hallucination | None | There are no hallucinations in the reading. |
| Not significant | Hallucinations are present but do not significantly affect clinical judgment. | |
| Significant | Hallucinations are present and significantly affect clinical judgment. | |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Lee, K.H.; Lee, R.W.; Kwon, Y.E. Validation of a Deep Learning Chest X-ray Interpretation Model: Integrating Large-Scale AI and Large Language Models for Comparative Analysis with ChatGPT. Diagnostics 2024, 14, 90. https://doi.org/10.3390/diagnostics14010090
Lee KH, Lee RW, Kwon YE. Validation of a Deep Learning Chest X-ray Interpretation Model: Integrating Large-Scale AI and Large Language Models for Comparative Analysis with ChatGPT. Diagnostics. 2024; 14(1):90. https://doi.org/10.3390/diagnostics14010090
Chicago/Turabian StyleLee, Kyu Hong, Ro Woon Lee, and Ye Eun Kwon. 2024. "Validation of a Deep Learning Chest X-ray Interpretation Model: Integrating Large-Scale AI and Large Language Models for Comparative Analysis with ChatGPT" Diagnostics 14, no. 1: 90. https://doi.org/10.3390/diagnostics14010090