
A Semi-Supervised Graph Convolutional Network for Early Prediction of Motor Abnormalities in Very Preterm Infants
 , ,
, ,
Abstract
:1. Introduction
2. Materials and Methods
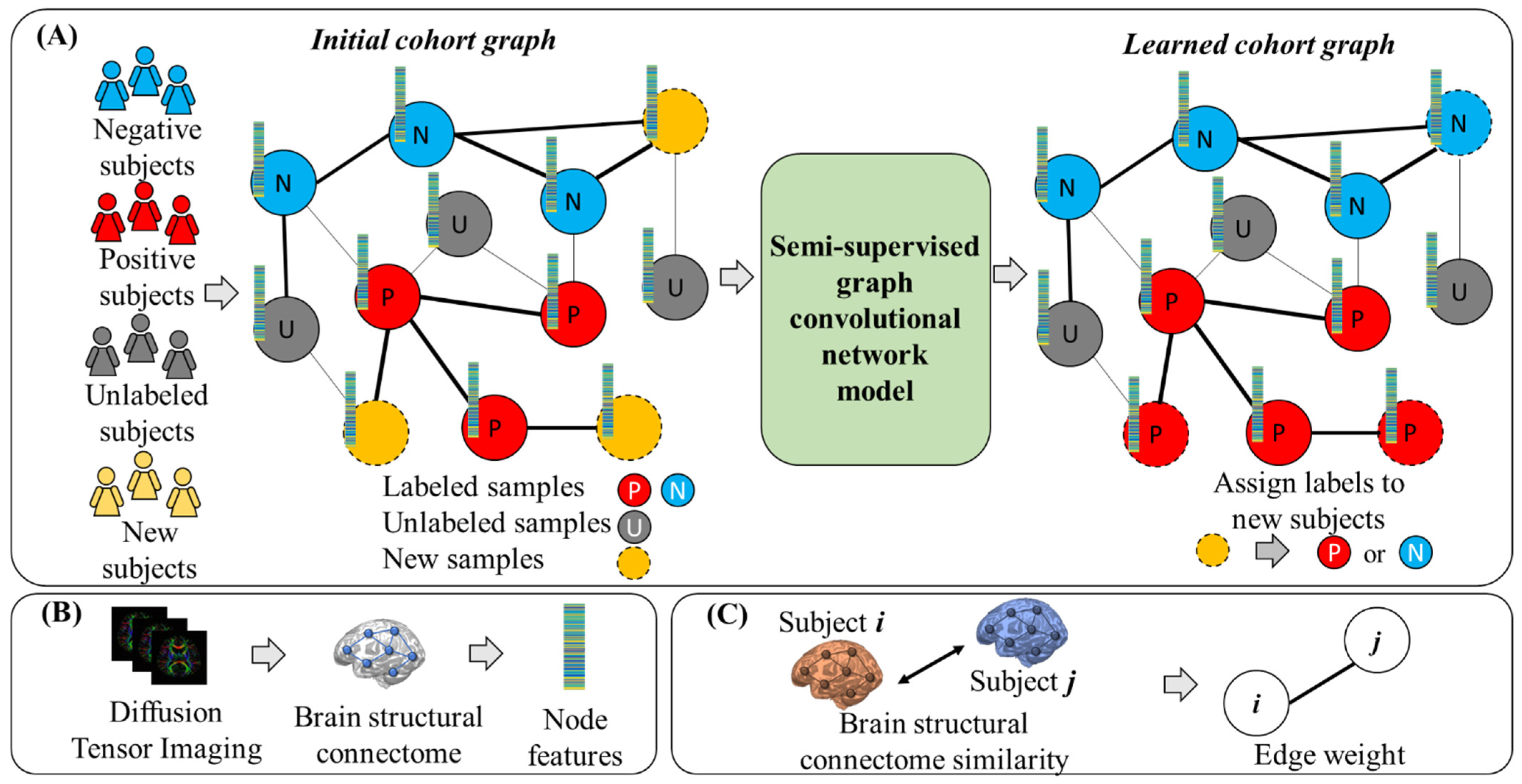
2.1. Overview
2.2. Data Acquisition and Processing
2.2.1. Subjects and MRI Data Acquisition
2.2.2. MRI Data Preprocessing and Feature Extraction
2.2.3. Motor Abnormalities Evaluation at 2 Years Corrected Age
2.3. Semi-Supervised Graph Convolutional Networks
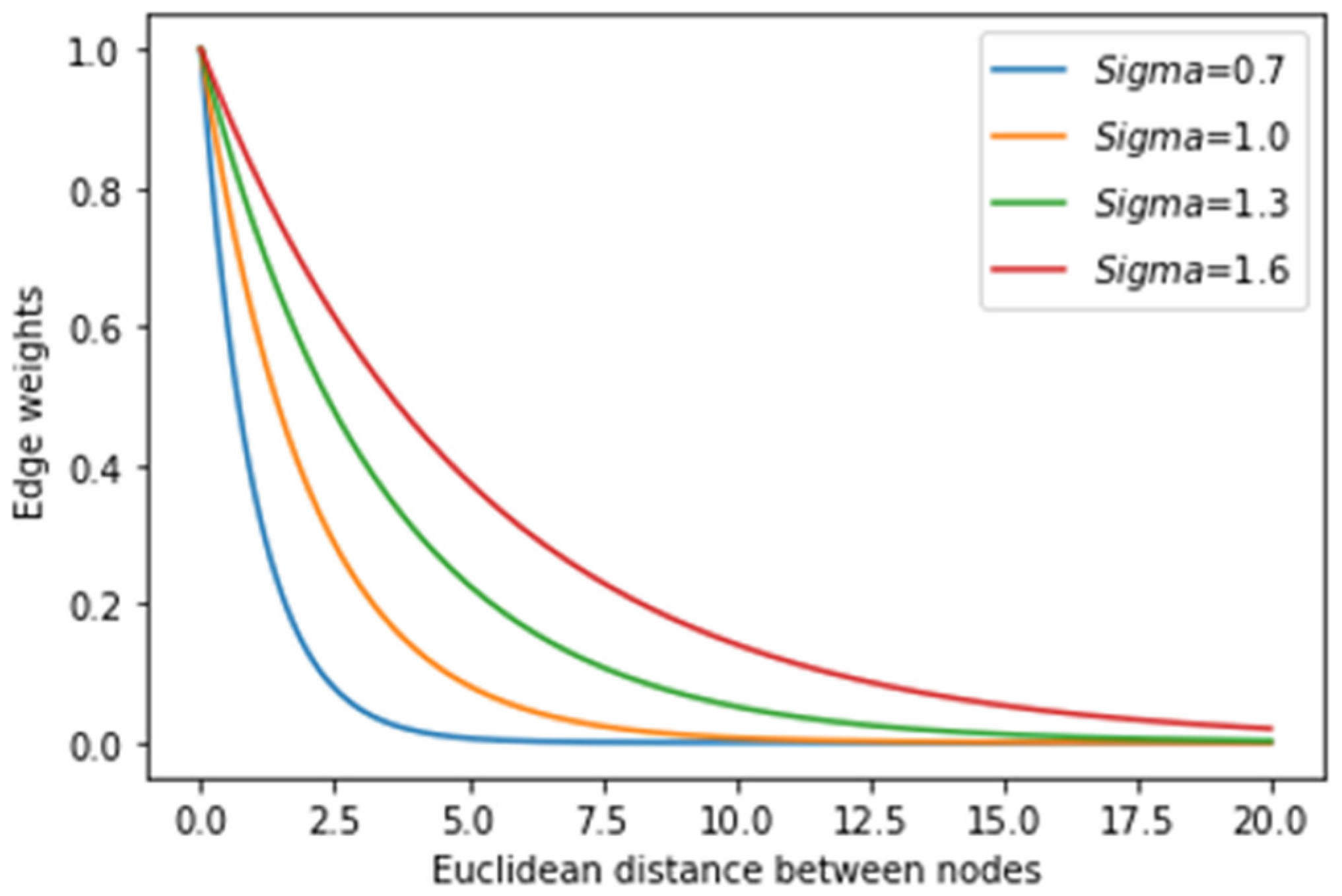
2.3.1. Construction of the Initial Cohort Graph
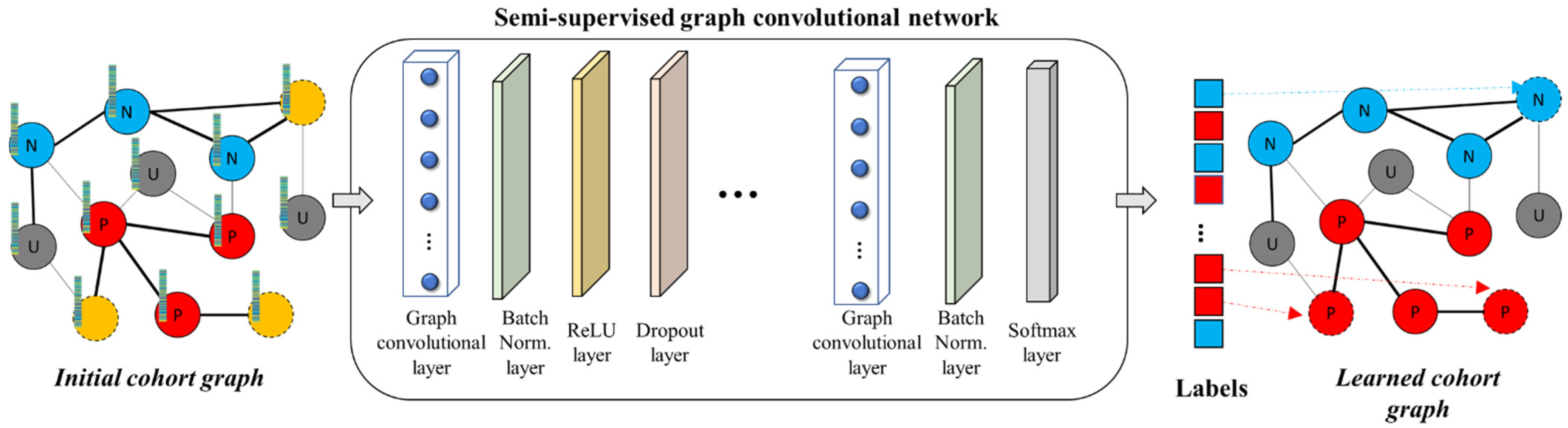
2.3.2. Architecture of the Graph Convolutional Network
2.3.3. Model Training
2.3.4. Model Evaluation
3. Results
3.1. Subjects
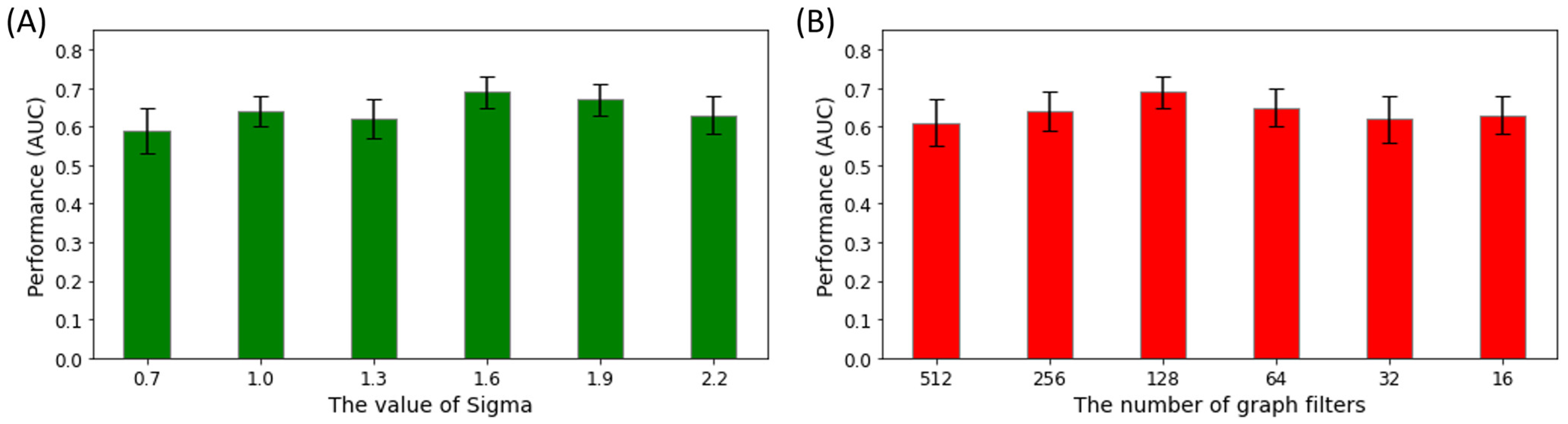
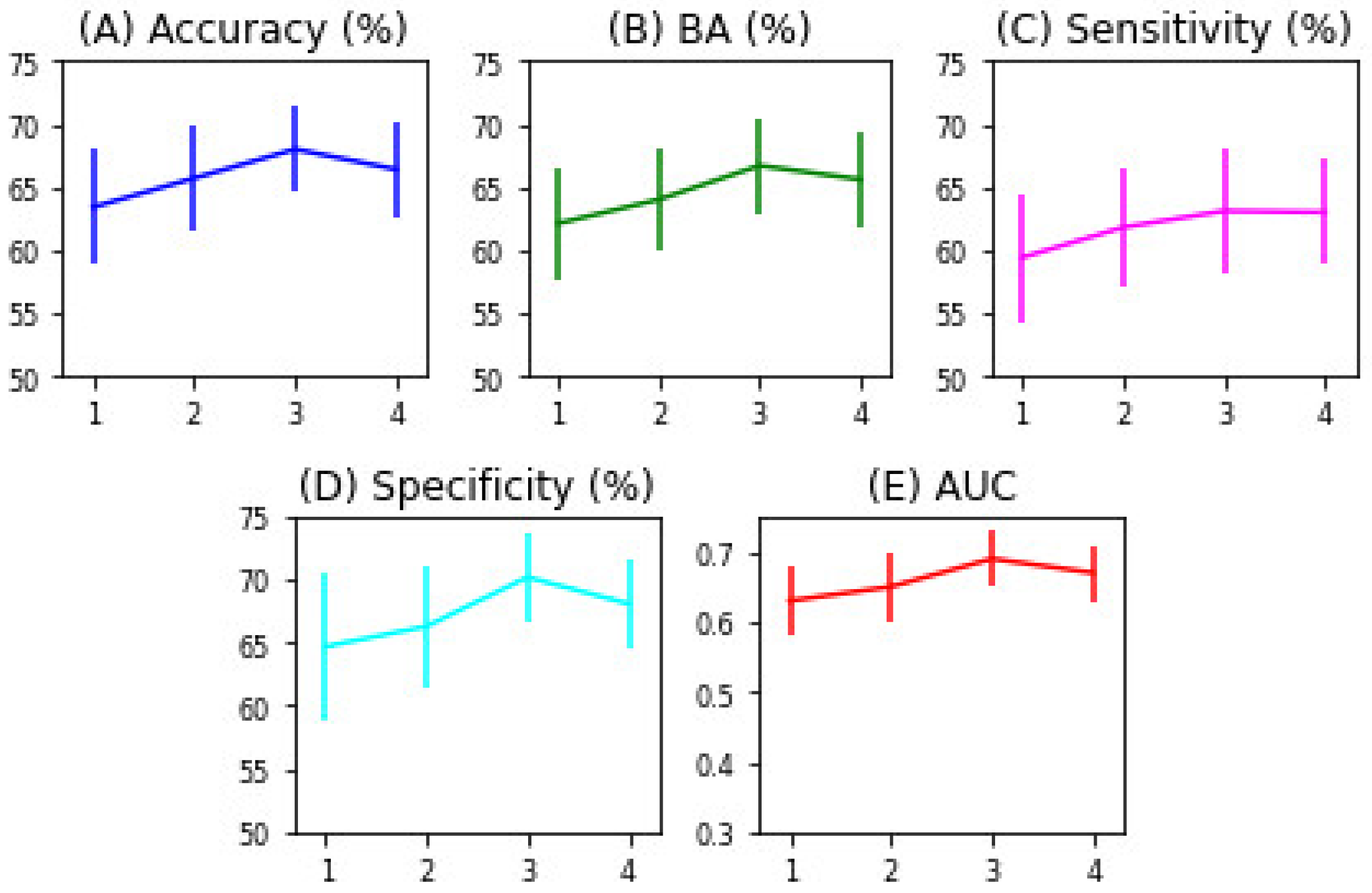
3.2. Semi-Supervised GCN Model Optimization
3.3. Performance Comparison with Other Models
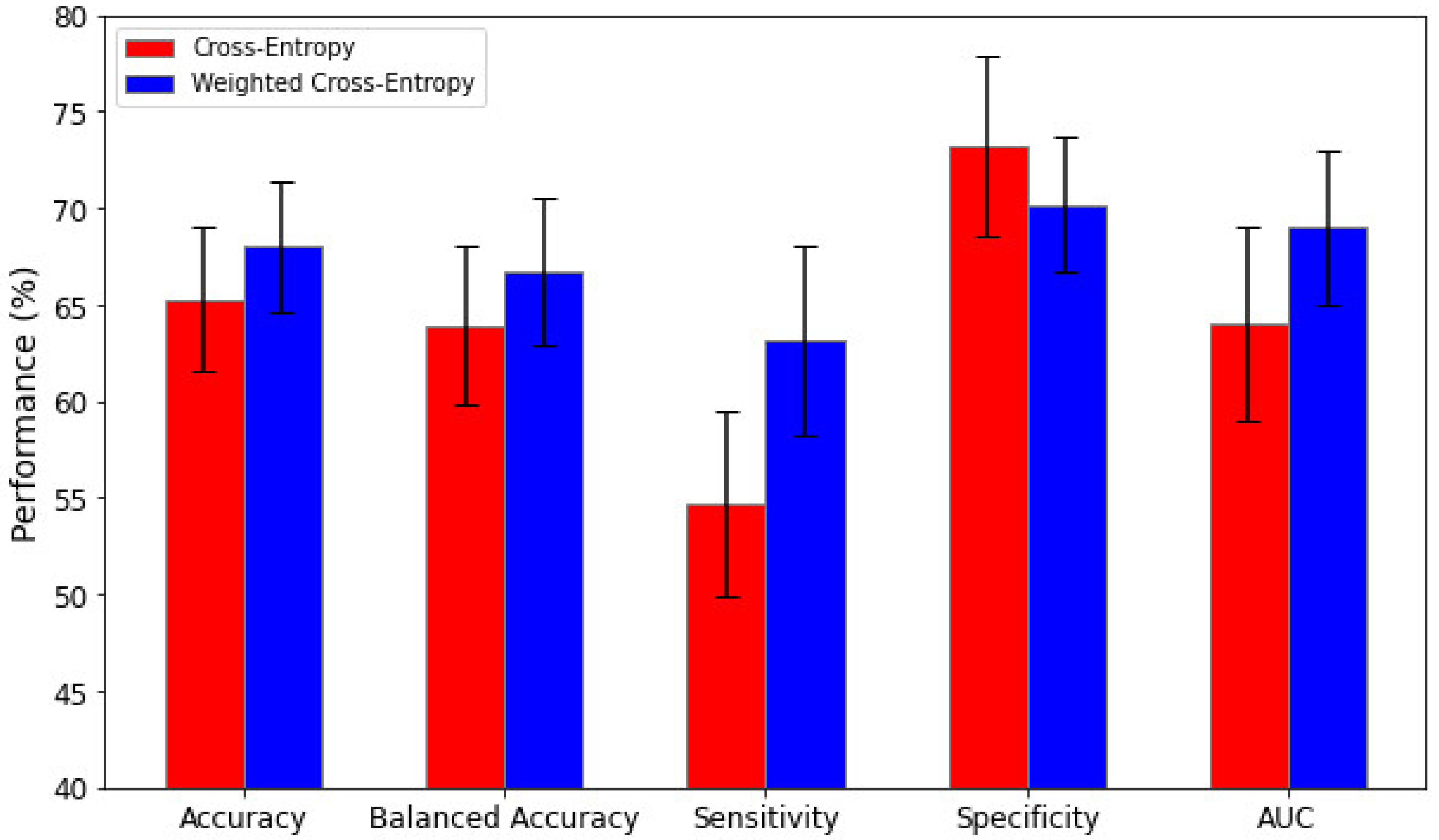
3.4. Impact of Weighted Loss Functions
4. Discussion
4.1. Comparison of the GCN Model with Other Models
4.2. Architecture Optimization of the GCN
4.3. Semi-Supervised Learning Using Unlabeled Datasets
4.4. Weighted Loss Functions for Imbalanced Datasets
4.5. Limitations
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Rogers, E.E.; Hintz, S.R. Early neurodevelopmental outcomes of extremely preterm infants. Semin. Perinatol. 2016, 40, 497–509. [Google Scholar] [CrossRef]
- Hintz, S.R.; Barnes, P.D.; Bulas, D.; Slovis, T.L.; Finer, N.N.; Wrage, L.A.; Das, A.; Tyson, J.E.; Stevenson, D.K.; Carlo, W.A.; et al. Neuroimaging and Neurodevelopmental Outcome in Extremely Preterm Infants. Pediatrics 2015, 135, e32–e42. [Google Scholar] [CrossRef] [PubMed]
- Parikh, N.A. Advanced neuroimaging and its role in predicting neurodevelopmental outcomes in very preterm infants. Semin. Perinatol. 2016, 40, 530–541. [Google Scholar] [CrossRef]
- Williams, J.; Lee, K.J.; Anderson, P.J. Prevalence of motor-skill impairment in preterm children who do not develop cerebral palsy: A systematic review. Dev. Med. Child Neurol. 2010, 52, 232–237. [Google Scholar] [CrossRef]
- Van Hus, J.W.; Potharst, E.S.; Jeukens-Visser, M.; Kok, J.H.; Van Wassenaer-Leemhuis, A.G. Motor impairment in very preterm-born children: Links with other developmental deficits at 5 years of age. Dev. Med. Child Neurol. 2014, 56, 587–594. [Google Scholar] [CrossRef] [PubMed]
- McIntyre, S.; Morgan, C.; Walker, K.; Novak, I. Cerebral Palsy—Don’t Delay. Dev. Disabil. Res. Rev. 2011, 17, 114–129. [Google Scholar] [CrossRef] [PubMed]
- Parikh, N.A.; Harpster, K.; He, L.; Illapani, V.S.P.; Khalid, F.C.; Klebanoff, M.A.; O’shea, T.M.; Altaye, M. Novel diffuse white matter abnormality biomarker at term-equivalent age enhances prediction of long-term motor development in very preterm children. Sci. Rep. 2020, 10, 15920. [Google Scholar] [CrossRef]
- Kline, J.E.; Illapani, V.S.P.; He, L.; Parikh, N.A. Automated brain morphometric biomarkers from MRI at term predict motor development in very preterm infants. NeuroImage Clin. 2020, 28, 102475. [Google Scholar] [CrossRef]
- Chandwani, R.; Kline, J.E.; Harpster, K.; Tkach, J.; Parikh, N.A. The Cincinnati Infant Neurodevelopment Early Prediction Study (CINEPS) Group Early micro- and macrostructure of sensorimotor tracts and development of cerebral palsy in high risk infants. Hum. Brain Mapp. 2021, 42, 4708–4721. [Google Scholar] [CrossRef]
- Alexander, A.L.; Lee, J.E.; Lazar, M.; Field, A.S. Diffusion tensor imaging of the brain. Neurotherapeutics 2007, 4, 316–329. [Google Scholar] [CrossRef] [PubMed]
- O’donnell, L.J.; Westin, C.-F. An Introduction to Diffusion Tensor Image Analysis. Neurosurg. Clin. N. Am. 2011, 22, 185–196. [Google Scholar] [CrossRef] [PubMed]
- Meoded, A.; Huisman, T. Diffusion Tensor Imaging of Brain Malformations: Exploring the Internal Architecture. Neuroimaging Clin. N. Am. 2019, 29, 423–434. [Google Scholar] [CrossRef] [PubMed]
- Kline, J.E.; Dudley, J.; Illapani, V.S.P.; Li, H.; Kline-Fath, B.; Tkach, J.; He, L.; Yuan, W.; Parikh, N.A. Diffuse excessive high signal intensity in the preterm brain on advanced MRI represents widespread neuropathology. Neuroimage 2022, 264, 119727. [Google Scholar] [CrossRef] [PubMed]
- Chau, V.; Synnes, A.; Grunau, R.E.; Poskitt, K.J.; Brant, R.; Miller, S.P. Abnormal brain maturation in preterm neonates associated with adverse developmental outcomes. Neurology 2013, 81, 2082–2089. [Google Scholar] [CrossRef]
- Brown, C.J.; Miller, S.P.; Booth, B.G.; Poskitt, K.J.; Chau, V.; Synnes, A.R.; Zwicker, J.G.; Grunau, R.E.; Hamarneh, G. Prediction of motor function in very preterm infants using connectome features and local synthetic instances. In International Conference on Medical Image Computing and Computer-Assisted Intervention; Springer: Berlin/Heidelberg, Germany, 2015. [Google Scholar]
- Kawahara, J.; Brown, C.J.; Miller, S.P.; Booth, B.G.; Chau, V.; Grunau, R.E.; Zwicker, J.G.; Hamarneh, G. BrainNetCNN: Convolutional neural networks for brain networks; towards predicting neurodevelopment. Neuroimage 2017, 146, 1038–1049. [Google Scholar] [CrossRef]
- He, L.; Li, H.; Chen, M.; Wang, J.; Altaye, M.; Dillman, J.R.; Parikh, N.A. Deep Multimodal Learning From MRI and Clinical Data for Early Prediction of Neurodevelopmental Deficits in Very Preterm Infants. Front. Neurosci. 2021, 15, 753033. [Google Scholar] [CrossRef]
- Parikh, M.; Chen, M.; Braimah, A.; Kline, J.; McNally, K.; Logan, J.; Tamm, L.; Yeates, K.; Yuan, W.; He, L.; et al. Diffusion MRI Microstructural Abnormalities at Term-Equivalent Age Are Associated with Neurodevelopmental Outcomes at 3 Years of Age in Very Preterm Infants. AJNR Am. J. Neuroradiol. 2021, 42, 1535–1542. [Google Scholar] [CrossRef]
- Wasserman, S.; Faust, K. Social Network Analysis: Methods and Applications; Cambridge University Press: Cambridge, UK, 1994. [Google Scholar]
- Zhao, M.; Chan, R.H.M.; Chow, T.W.S.; Tang, P. Compact Graph based Semi-Supervised Learning for Medical Diagnosis in Alzheimer’s Disease. IEEE Signal Process Lett. 2014, 21, 1192–1196. [Google Scholar] [CrossRef]
- Tong, T.; Gray, K.; Gao, Q.; Chen, L.; Rueckert, D. Multi-modal classification of Alzheimer’s disease using nonlinear graph fusion. Pattern Recognit. 2017, 63, 171–181. [Google Scholar] [CrossRef]
- Kipf, T.N.; Welling, M. Semi-supervised classification with graph convolutional networks. arXiv preprint 2016, arXiv:1609.02907. [Google Scholar]
- Defferrard, M.; Bresson, X.; Vandergheynst, P. Convolutional neural networks on graphs with fast localized spectral filtering. Adv. Neural Inf. Process. Syst. 2016, 29. [Google Scholar] [CrossRef]
- Parisot, S.; Ktena, S.I.; Ferrante, E.; Lee, M.; Guerrero, R.; Glocker, B.; Rueckert, D. Disease prediction using graph convolutional networks: Application to Autism Spectrum Disorder and Alzheimer’s disease. Med. Image Anal. 2018, 48, 117–130. [Google Scholar] [CrossRef] [PubMed]
- Jiang, H.; Cao, P.; Xu, M.; Yang, J.; Zaiane, O. Hi-GCN: A hierarchical graph convolution network for graph embedding learning of brain network and brain disorders prediction. Comput. Biol. Med. 2020, 127, 104096. [Google Scholar] [CrossRef]
- Zhu, X.J. Semi-Supervised Learning Literature Survey; University of Wisconsin-Madison, Department of Computer Sciences: Madison, WI, USA, 2005. [Google Scholar]
- Michaeli, T.; Eldar, Y.C.; Sapiro, G. Semi-supervised multi-domain regression with distinct training sets. In Proceedings of the 2012 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Kyoto, Japan, 25–30 March 2012. [Google Scholar]
- Hess, C.P.; Mukherjee, P.; Han, E.T.; Xu, D.; Vigneron, D.B. Q-ball reconstruction of multimodal fiber orientations using the spherical harmonic basis. Magn. Reson. Med. 2006, 56, 104–117. [Google Scholar] [CrossRef] [PubMed]
- Wang, R.; Benner, T.; Sorensen, A.G.; Wedeen, V.J. Diffusion toolkit: A software package for diffusion imaging data processing and tractography. Proc. Intl. Soc. Mag. Reson Med. 2007, 15, 3720. [Google Scholar]
- Shi, F.; Yap, P.-T.; Wu, G.; Jia, H.; Gilmore, J.H.; Lin, W.; Shen, D. Infant Brain Atlases from Neonates to 1- and 2-Year-Olds. PLoS ONE 2011, 6, e18746. [Google Scholar] [CrossRef]
- Bassett, D.S.; Brown, J.A.; Deshpande, V.; Carlson, J.M.; Grafton, S.T. Conserved and variable architecture of human white matter connectivity. Neuroimage 2011, 54, 1262–1279. [Google Scholar] [CrossRef]
- Bayley, N. Bayley-III: Bayley Scales of Infant and Toddler Development; Giunti OS: Florence, Italy, 2009. [Google Scholar]
- Zhang, X.; He, L.; Chen, K.; Luo, Y.; Zhou, J.; Wang, F. Multi-View Graph Convolutional Network and Its Applications on Neuroimage Analysis for Parkinson’s Disease. AMIA Annu. Symp. Proc. 2018, 2018, 1147–1156. [Google Scholar] [PubMed]
- Kingma, D.P.; Ba, J. Adam: A method for stochastic optimization. arXiv 2014, arXiv:1412.6980. [Google Scholar]
- Chen, M.; Li, H.; Wang, J.; Yuan, W.; Altaye, M.; Parikh, N.A.; He, L. Early Prediction of Cognitive Deficit in Very Preterm Infants Using Brain Structural Connectome with Transfer Learning Enhanced Deep Convolutional Neural Networks. Front. Neurosci. 2020, 14, 858. [Google Scholar] [CrossRef]
- He, L.; Li, H.; Wang, J.; Chen, M.; Gozdas, E.; Dillman, J.R.; Parikh, N.A. A multi-task, multi-stage deep transfer learning model for early prediction of neurodevelopment in very preterm infants. Sci. Rep. 2020, 10, 15072. [Google Scholar] [CrossRef] [PubMed]
- He, L.; Li, H.; Holland, S.K.; Yuan, W.; Altaye, M.; Parikh, N.A. Early prediction of cognitive deficits in very preterm infants using functional connectome data in an artificial neural network framework. NeuroImage Clin. 2018, 18, 290–297. [Google Scholar] [CrossRef] [PubMed]
- Li, H.; Parikh, N.A.; He, L. A Novel Transfer Learning Approach to Enhance Deep Neural Network Classification of Brain Functional Connectomes. Front. Neurosci. 2018, 12, 491. [Google Scholar] [CrossRef] [PubMed]
- Ali, R.; Li, H.; Dillman, J.R.; Altaye, M.; Wang, H.; Parikh, N.A.; He, L. A self-training deep neural network for early prediction of cognitive deficits in very preterm infants using brain functional connectome data. Pediatr. Radiol. 2022, 52, 2227–2240. [Google Scholar] [CrossRef] [PubMed]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| High-Risk Group | Low-Risk Group | Unlabeled Group | |
|---|---|---|---|
| Number of subjects | N = 37 | N = 82 | N = 105 |
| Gestational age at birth (weeks) | 28.9 (2.6) | 29.3 (2.4) | 29.5 (2.5) |
| Postmenstrual age at the scan (weeks) | 42.7 (1.1) | 42.0 (1.3) | 43.0 (1.2) |
| Female, N (percentage) | 11 (29.7%) | 43 (52.4%) | 45 (42.8%) |
| Birth weight (gram) | 1244.7 (462.8) | 1276.0 (424.4) | 1353.7 (429.1) |
| Models | Accuracy (%) | BA (%) | Sensitivity (%) | Specificity (%) | AUC |
|---|---|---|---|---|---|
| Logistic Regression | 60.1 ± 4.0 | 58.7 ± 3.9 | 51.6 ± 4.4 | 65.7 ± 4.0 | 0.59 ± 0.03 |
| Ridge Classifier | 63.3 ± 3.7 | 61.2 ± 3.8 | 50.5 ± 4.2 | 71.9 ± 3.5 | 0.62 ± 0.04 |
| SVM (linear kernel) | 65.7 ± 3.4 | 64.5 ± 3.7 | 59.8 ± 5.1 | 69.1 ± 3.2 | 0.64 ± 0.03 |
| SVM (rbf kernel) | 66.2 ± 3.8 | 64.9 ± 4.0 | 61.5 ± 4.3 | 68.2 ± 4.1 | 0.65 ± 0.04 |
| Deep neural network | 65.9 ± 3.2 | 64.6 ± 4.4 | 60.2 ± 4.9 | 68.9 ± 4.3 | 0.64 ± 0.05 |
| GCN (ours) | 66.4 ± 3.3 | 65.4 ± 3.4 | 61.7 ± 4.7 | 69.0 ± 3.9 | 0.67 ± 0.05 |
| GCN w/unlabeled (ours) | 68.0 ± 3.4 | 66.7 ± 3.8 | 63.1 ± 4.9 | 70.2 ± 3.5 | 0.69 ± 0.04 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Li, H.; Li, Z.; Du, K.; Zhu, Y.; Parikh, N.A.; He, L. A Semi-Supervised Graph Convolutional Network for Early Prediction of Motor Abnormalities in Very Preterm Infants. Diagnostics 2023, 13, 1508. https://doi.org/10.3390/diagnostics13081508
Li H, Li Z, Du K, Zhu Y, Parikh NA, He L. A Semi-Supervised Graph Convolutional Network for Early Prediction of Motor Abnormalities in Very Preterm Infants. Diagnostics. 2023; 13(8):1508. https://doi.org/10.3390/diagnostics13081508
Chicago/Turabian StyleLi, Hailong, Zhiyuan Li, Kevin Du, Yu Zhu, Nehal A. Parikh, and Lili He. 2023. "A Semi-Supervised Graph Convolutional Network for Early Prediction of Motor Abnormalities in Very Preterm Infants" Diagnostics 13, no. 8: 1508. https://doi.org/10.3390/diagnostics13081508