
Anti-Aliasing Attention U-net Model for Skin Lesion Segmentation


 ,
,  and
and
Abstract
:1. Introduction
- Illumination: the skin color is affected by the level of illumination (shadows, nonwhite lights, and whether the image was captured indoors or outdoors).
- Camera equipment: the sensor quality of the camera directly impacts the color image.
- Ethnicity: people across different regions, as well as ethnic groups, have different skin colors.
- Individual characteristics: age and working environment also influence skin color.
- Other factors: background, makeup, or glasses also affect skin color.
- We proposed combining some augmentation techniques to robustly increase the quantity, as well as the quality, of the data. This suggestion overcame the noisy information in the input images, reduced the over-fitting problem, and increased the available images.
- We proposed a model with a multipath structure for robust skin segmentation that exploits both the context’s global and spatial features.
- The proposed model with an attention block can capture image highlights. It enhanced efficiency in training and testing and improved the accuracy of skin segmentation
- Results on the benchmark dataset showed the improvement of the proposed model, whereby our model with fewer parameters performed better than existing recognition methods.
2. Related Work
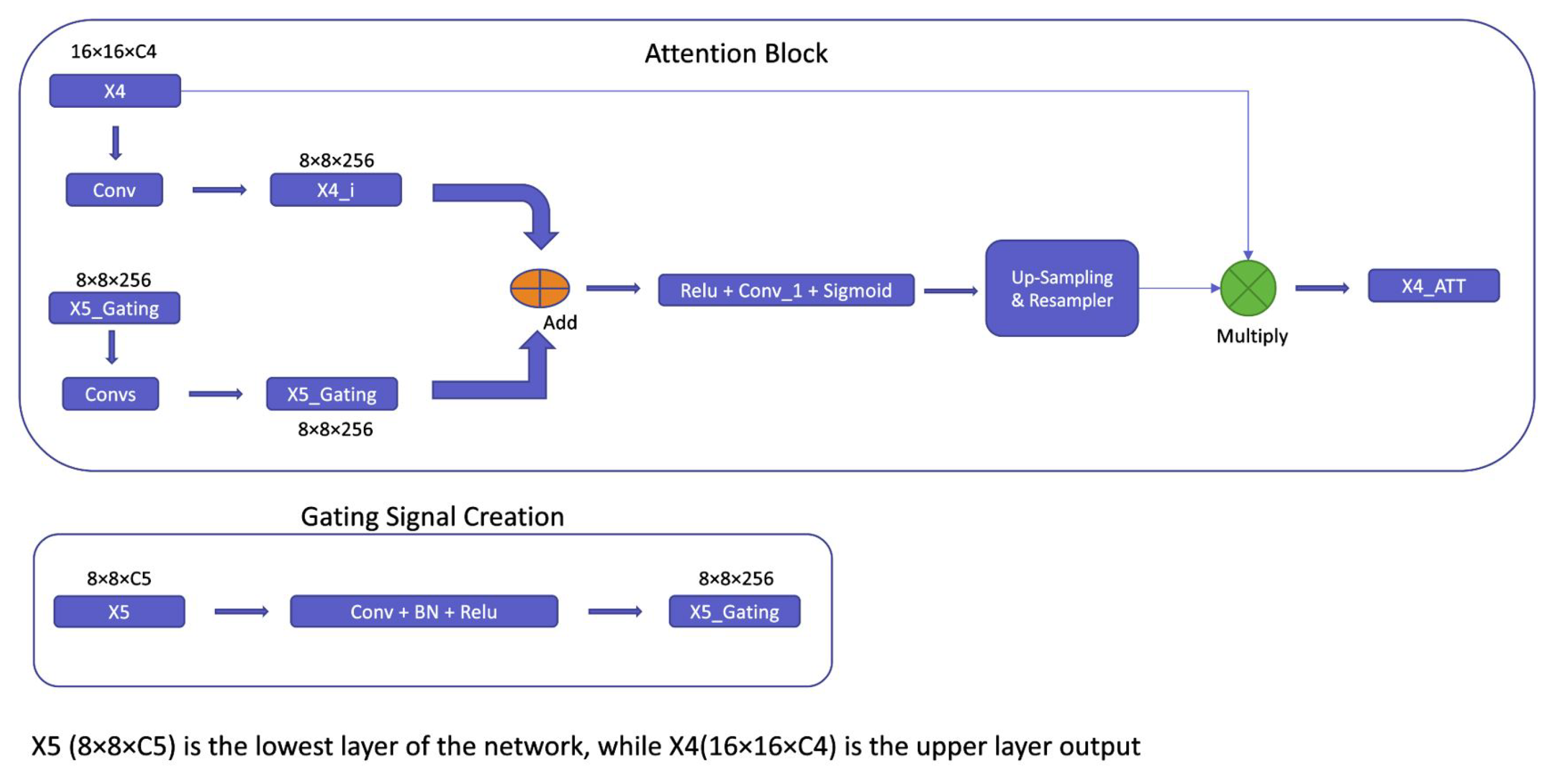
3. Proposed Method
4. Experiments
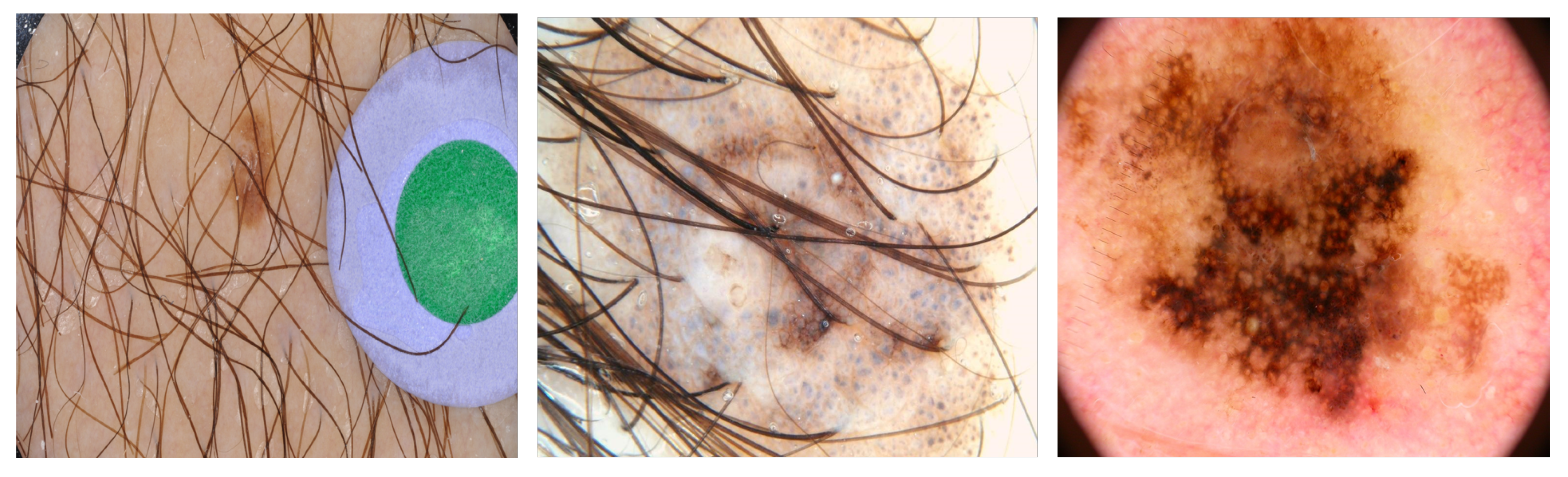
4.1. Dataset
4.1.1. Dataset Modalities
- One fold was used as the testing dataset.
- The remaining folds were used as the training dataset.
- The model was fitted on the training dataset and evaluated on the testing dataset.
- An average of five tests was used to obtain the final result.
4.1.2. The Preprocessing Dataset
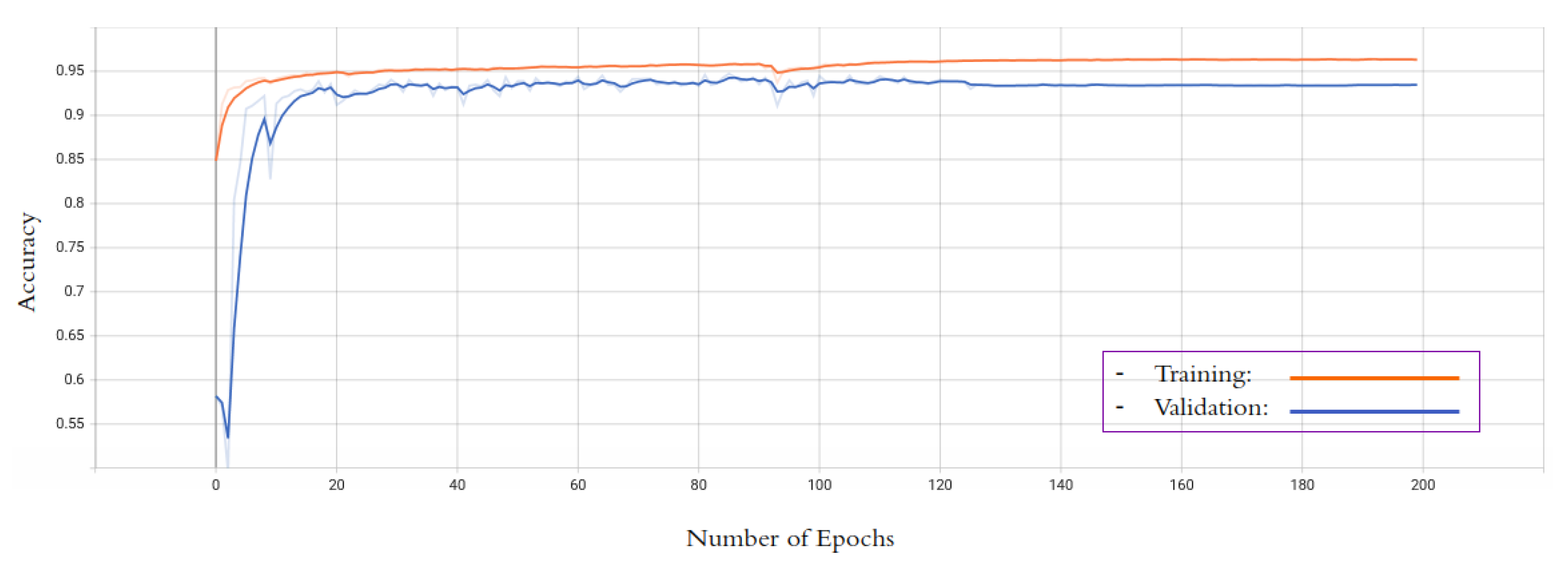
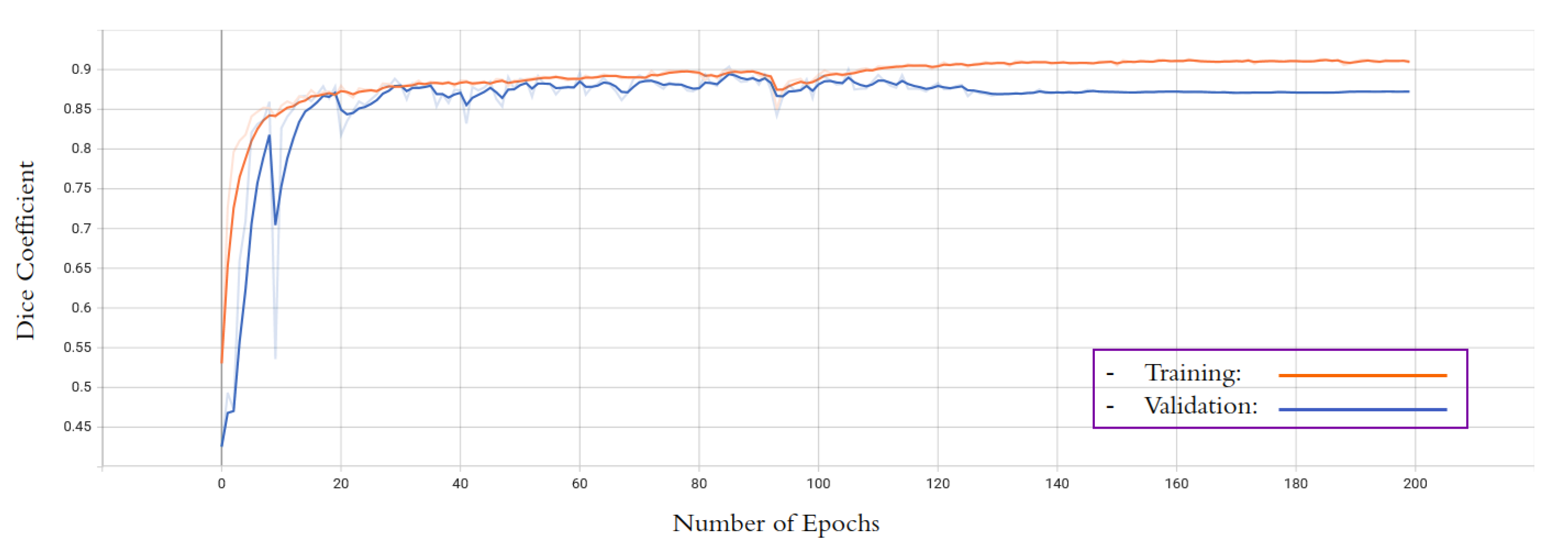
4.2. Experimental Setups
4.3. The Evaluation Protocol
5. Results
5.1. Quantitive Results
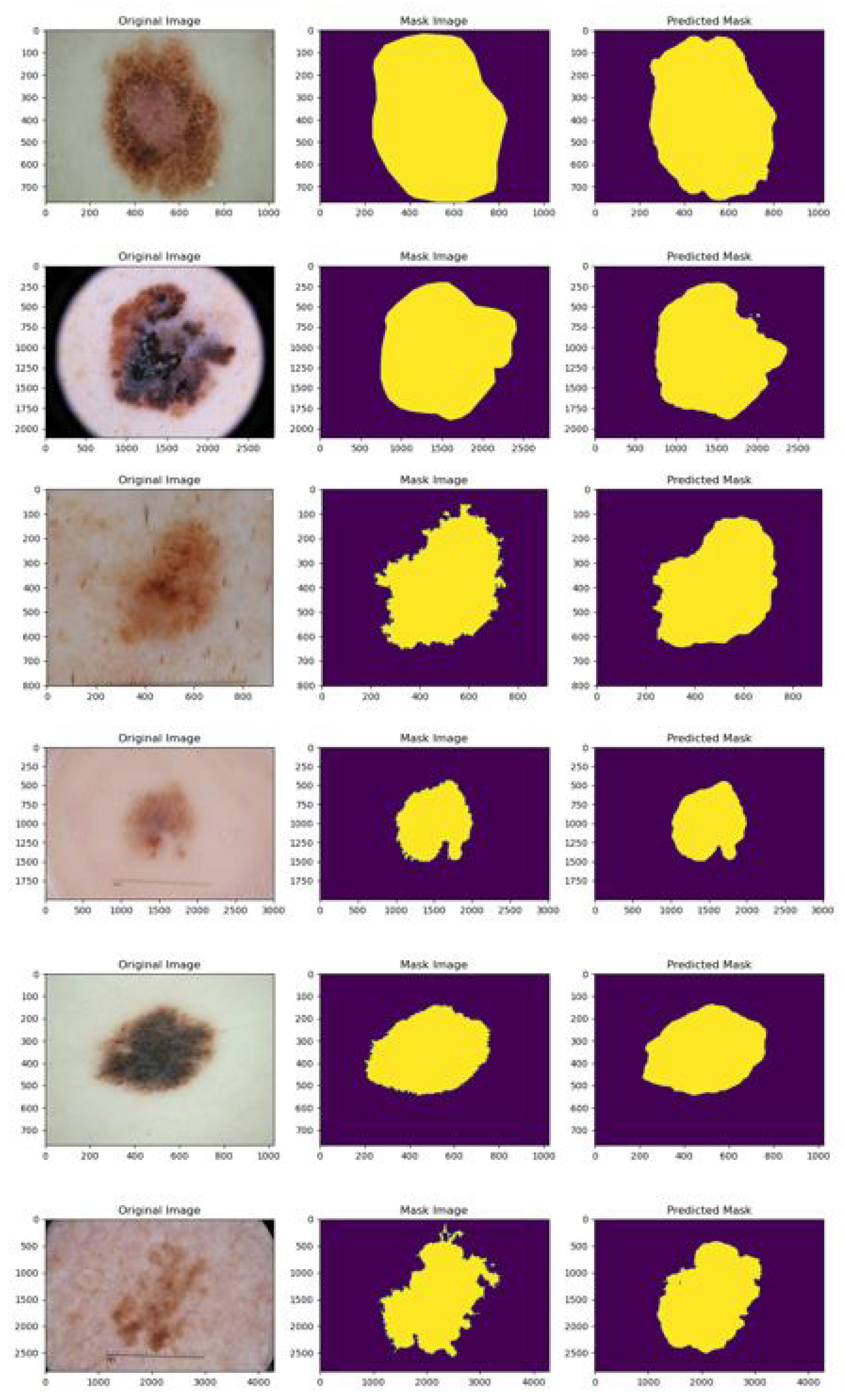
5.2. Qualitative Results
6. Conclusions and Future Directions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Zhou, M.; Liang, L.; Sun, J.; Wang, Y. AAM based face tracking with temporal matching and face segmentation. In Proceedings of the 2010 IEEE Computer Society Conference on Computer Vision and Pattern Recognition, San Francisco, CA, USA, 13–18 June 2010; IEEE: Piscataway, NJ, USA, 2010; pp. 701–708. [Google Scholar]
- Viola, P.; Jones, M.J. Robust real-time face detection. Int. J. Comput. Vis. 2004, 57, 137–154. [Google Scholar] [CrossRef]
- Mitra, S.; Acharya, T. Gesture recognition: A survey. IEEE Trans. Syst. Man Cybern. Part C Appl. Rev. 2007, 37, 311–324. [Google Scholar] [CrossRef]
- Tagare, H.D.; Jaffe, C.C.; Duncan, J. Medical image databases: A content-based retrieval approach. J. Am. Med. Inform. Assoc. 1997, 4, 184–198. [Google Scholar] [CrossRef]
- Garcia, E.; Jimenez, M.A.; De Santos, P.G.; Armada, M. The evolution of robotics research. IEEE Robot. Autom. Mag. 2007, 14, 90–103. [Google Scholar] [CrossRef]
- Burdea, G.C.; Coiffet, P. Virtual Reality Technology; John Wiley Sons: Hoboken, NJ, USA, 2003. [Google Scholar]
- Zhao, W.; Chellappa, R.; Phillips, P.J.; Rosenfeld, A. Face recognition: A literature survey. ACM Comput. Surv. 2003, 35, 399–458. [Google Scholar] [CrossRef]
- Mitsunaga, N.; Miyashita, T.; Ishiguro, H.; Kogure, K.; Hagita, N. Robovie-IV: A communication robot interacting with people daily in an office. In Proceedings of the 2006 IEEE/RSJ International Conference on Intelligent Robots and Systems, Beijing, China, 9–15 October 2006; IEEE: Piscataway, NJ, USA, 2006; pp. 5066–5072. [Google Scholar]
- Masood, A.; Al-Jumaily, A. Computer aided diagnostic support system for skin cancer: A review of techniques and algorithms. Int. J. Biomed. Imaging 2013, 2013, 323268. [Google Scholar] [CrossRef] [PubMed]
- Kakumanu, P.; Makrogiannis, S.; Bourbakis, N. A survey of skin-color modeling and detection methods. Pattern Recognit. 2007, 40, 1106–1122. [Google Scholar] [CrossRef]
- Kohler, R. A segmentation system based on thresholding. Comput. Graph. Image Process. 1981, 15, 319–338. [Google Scholar] [CrossRef]
- Tayal, Y.; Lamba, R.; Padhee, S. Automatic face detection using color based segmentation. Int. J. Sci. Res. Publ. 2012, 2, 1–7. [Google Scholar]
- Joshi, G.D.; Sivaswamy, J.; Krishnadas, S.R. Depth discontinuity-based cup segmentation from multiview color retinal images. IEEE Trans. Biomed. Eng. 2012, 59, 1523–1531. [Google Scholar] [CrossRef]
- Gould, S.; Gao, T.; Koller, D. Region-based segmentation and object detection. Adv. Neural Inf. Process. Syst. 2009, 22, 655–663. [Google Scholar]
- Guth, F.; de Campos, T.E. Skin lesion segmentation using U-Net and good training strategies. arXiv 2018, arXiv:1811.11314. [Google Scholar]
- Chen, L.C.; Papandreou, G.; Schroff, F.; Adam, H. Rethinking atrous convolution for semantic image segmentation. arXiv 2017, arXiv:1706.05587. [Google Scholar]
- Lin, T.Y.; Dollár, P.; Girshick, R.; He, K.; Hariharan, B.; Belongie, S. Feature pyramid networks for object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 2117–2125. [Google Scholar]
- Paszke, A.; Chaurasia, A.; Kim, S.; Culurciello, E. Enet: A deep neural network architecture for real-time semantic segmentation. arXiv 2016, arXiv:1606.02147. [Google Scholar]
- Vuola, A.O.; Akram, S.U.; Kannala, J. Mask-RCNN and U-net ensembled for nuclei segmentation. In Proceedings of the 2019 IEEE 16th International Symposium on Biomedical Imaging (ISBI 2019), Venice, Italy, 8–11 April 2019; IEEE: Piscataway, NJ, USA, 2019; pp. 208–212. [Google Scholar]
- Ma, Z.; Tavares, J.M.R. Effective features to classify skin lesions in dermoscopic images. Expert Syst. Appl. 2017, 84, 92–101. [Google Scholar] [CrossRef]
- Jaisakthi, S.M.; Mirunalini, P.; Aravindan, C. Automated skin lesion segmentation of dermoscopic images using GrabCut and k-means algorithms. IET Comput. Vis. 2018, 12, 1088–1095. [Google Scholar] [CrossRef]
- Adjed, F.; Safdar Gardezi, S.J.; Ababsa, F.; Faye, I.; Chandra Dass, S. Fusion of structural and textural features for melanoma recognition. IET Comput. Vis. 2018, 12, 185–195. [Google Scholar] [CrossRef]
- Garcia-Arroyo, J.L.; Garcia-Zapirain, B. Segmentation of skin lesions in dermoscopy images using fuzzy classification of pixels and histogram thresholding. Comput. Methods Programs Biomed. 2019, 168, 11–19. [Google Scholar] [CrossRef]
- Do, T.T.; Hoang, T.; Pomponiu, V.; Zhou, Y.; Chen, Z.; Cheung, N.M.; Koh, D.; Tan, A.; Tan, S.H. Accessible melanoma detection using smartphones and mobile image analysis. IEEE Trans. Multimed. 2018, 20, 2849–2864. [Google Scholar] [CrossRef]
- Alfed, N.; Khelifi, F. Bagged textural and color features for melanoma skin cancer detection in dermoscopic and standard images. Expert Syst. Appl. 2017, 90, 101–110. [Google Scholar] [CrossRef]
- Zhou, H.; Li, X.; Schaefer, G.; Celebi, M.E.; Miller, P. Mean shift based gradient vector flow for image segmentation. Comput. Vis. Image Underst. 2013, 117, 1004–1016. [Google Scholar] [CrossRef]
- Li, X.; Chen, H.; Qi, X.; Dou, Q.; Fu, C.W.; Heng, P.A. H-DenseUNet: Hybrid densely connected UNet for liver and tumor segmentation from CT volumes. IEEE Trans. Med. Imaging 2018, 37, 2663–2674. [Google Scholar] [CrossRef] [PubMed]
- Huang, H.; Lin, L.; Tong, R.; Hu, H.; Zhang, Q.; Iwamoto, Y.; Han, X.; Chen, Y.W.; Wu, J. Unet 3+: A full-scale connected unet for medical image segmentation. In Proceedings of the ICASSP 2020—2020 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Barcelona, Spain, 4–8 May 2020; IEEE: Piscataway, NJ, USA, 2020; pp. 1055–1059. [Google Scholar]
- Jha, D.; Smedsrud, P.H.; Riegler, M.A.; Johansen, D.; De Lange, T.; Halvorsen, P.; Johansen, H.D. Resunet++: An advanced architecture for medical image segmentation. In Proceedings of the 2019 IEEE International Symposium on Multimedia (ISM), San Diego, CA, USA, 9–11 December 2019; IEEE: Piscataway, NJ, USA, 2019; pp. 225–2255. [Google Scholar]
- Sun, Y.; Bi, F.; Gao, Y.; Chen, L.; Feng, S. A multi-attention UNet for semantic segmentation in remote sensing images. Symmetry 2022, 14, 906. [Google Scholar] [CrossRef]
- Venkatesh, G.M.; Naresh, Y.G.; Little, S.; O’Connor, N.E. A deep residual architecture for skin lesion segmentation. In OR 2.0 Context-Aware Operating Theaters, Computer Assisted Robotic Endoscopy, Clinical Image-Based Procedures, and Skin Image Analysis: First International Workshop, OR 2.0 2018, 5th International Workshop, CARE 2018, 7th International Workshop, CLIP 2018, Third International Workshop, ISIC 2018, Held in Conjunction with MICCAI 2018, Granada, Spain, 16–20 September 2018, Proceedings 5; Springer International Publishing: Berlin/Heidelberg, Germany, 2018; pp. 277–284. [Google Scholar]
- Badrinarayanan, V.; Kendall, A.; Cipolla, R. Segnet: A deep convolutional encoder-decoder architecture for image segmentation. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 2481–2495. [Google Scholar] [CrossRef]
- Geng, L.; Zhang, S.; Tong, J.; Xiao, Z. Lung segmentation method with dilated convolution based on VGG-16 network. Computer Assisted Surgery. Comput. Assist. Surg. 2019, 24 (Suppl. S2), 27–33. [Google Scholar] [CrossRef]
- Zhuang, J. LadderNet: Multi-path networks based on U-Net for medical image segmentation. arXiv 2018, arXiv:1810.07810. [Google Scholar]
- Punn, N.S.; Agarwal, S. Inception u-net architecture for semantic segmentation to identify nuclei in microscopy cell images. ACM Trans. Multimed. Comput. Commun. Appl. 2020, 16, 1–15. [Google Scholar] [CrossRef]
- Le, P.T.; Chang, C.C.; Li, Y.H.; Hsu, Y.C.; Wang, J.C. Antialiasing Attention Spatial Convolution Model for Skin Lesion Segmentation with Applications in the Medical IoT. Wirel. Commun. Mob. Comput. 2022, 2022, 1278515. [Google Scholar] [CrossRef]
- Wang, J.; Wei, L.; Wang, L.; Zhou, Q.; Zhu, L.; Qin, J. Boundary-aware transformers for skin lesion segmentation. In Proceedings of the International Conference on Medical Image Computing and Computer-Assisted Intervention, Strasbourg, France, 27 September–1 October 2021; Springer: Cham, Switzerland, 2021; pp. 206–216. [Google Scholar]
- Piccolo, D.; Ferrari, A.; Peris, K.E.T.T.Y.; Daidone, R.; Ruggeri, B.; Chimenti, S. Dermoscopic diagnosis by a trained clinician vs. a clinician with minimal dermoscopy training vs. computer-aided diagnosis of 341 pigmented skin lesions: A comparative study. Br. J. Dermatol. 2002, 147, 481–486. [Google Scholar] [CrossRef]
- Zhang, R. Making convolutional networks shift-invariant again. In International Conference on Machine Learning; PMLR: London, UK, 2019; pp. 7324–7334. [Google Scholar]
- Jha, D.; Riegler, M.A.; Johansen, D.; Halvorsen, P.; Johansen, H.D. Doubleu-net: A deep convolutional neural network for medical image segmentation. In Proceedings of the 2020 IEEE 33rd International Symposium on Computer-Based Medical Systems (CBMS), Rochester, MN, USA, 28–30 July 2020; pp. 558–564. [Google Scholar]
- Li, Y.; Shen, L. Skin lesion analysis towards melanoma detection using deep learning network. Sensors 2018, 18, 556. [Google Scholar] [CrossRef]
- Zafar, K.; Gilani, S.O.; Waris, A.; Ahmed, A.; Jamil, M.; Khan, M.N.; Kashif, A.S. Skin lesion segmentation from dermoscopic images using convolutional neural network. Sensors 2020, 20, 1601. [Google Scholar] [CrossRef]
- Setiawan, A.W. Image segmentation metrics in skin lesion: Accuracy, sensitivity, specificity, dice coefficient, Jaccard index, and Matthews correlation coefficient. In Proceedings of the 2020 International Conference on Computer Engineering, Network, and Intelligent Multimedia (CENIM), Surabaya, Indonesia, 17–18 November 2020; IEEE: Piscataway, NJ, USA, 2020; pp. 97–102. [Google Scholar]










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Metrics | Dice | Jacc | Precision | Recall | F1-Score | Accuracy |
|---|---|---|---|---|---|---|
| ISIC 2018 | 0.881 | 0.809 | 0.909 | 0.893 | 0.900 | 0.955 |
| Method | Dice | Jaccard |
|---|---|---|
| U-net [40] | - | 0.764 |
| Unet++ [40] | 0.879 | 0.805 |
| DoubleU-net [40] | 0.896 | 0.821 |
| MultiResUnet [40] | - | 0.803 |
| TransUNET [40] | 0.894 | 0.822 |
| DeeplabV3 [40] | 0.884 | 0.806 |
| Our proposal | 0.881 | 0.809 |
| Method | Jaccard |
|---|---|
| U_NET [42] | 0.762 |
| FCN [42] | 0.760 |
| ResNet [42] | 0.758 |
| VGG16 [42] | 0.754 |
| Res-Unet [42] | 0.772 |
| Our proposal | 0.845 |
| Model | Parameters (Million) |
|---|---|
| U-net | 7.7 |
| Unet++ | 9.0 |
| DoubleU-net | 29.3 |
| MultiResUnet | 7.3 |
| TransUNET | 105.3 |
| DeeplabV3 | 81.3 |
| Our proposal | 4.2 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Le, P.T.; Pham, B.-T.; Chang, C.-C.; Hsu, Y.-C.; Tai, T.-C.; Li, Y.-H.; Wang, J.-C. Anti-Aliasing Attention U-net Model for Skin Lesion Segmentation. Diagnostics 2023, 13, 1460. https://doi.org/10.3390/diagnostics13081460
Le PT, Pham B-T, Chang C-C, Hsu Y-C, Tai T-C, Li Y-H, Wang J-C. Anti-Aliasing Attention U-net Model for Skin Lesion Segmentation. Diagnostics. 2023; 13(8):1460. https://doi.org/10.3390/diagnostics13081460
Chicago/Turabian StyleLe, Phuong Thi, Bach-Tung Pham, Ching-Chun Chang, Yi-Chiung Hsu, Tzu-Chiang Tai, Yung-Hui Li, and Jia-Ching Wang. 2023. "Anti-Aliasing Attention U-net Model for Skin Lesion Segmentation" Diagnostics 13, no. 8: 1460. https://doi.org/10.3390/diagnostics13081460