
Super-Resolution of Dental Panoramic Radiographs Using Deep Learning: A Pilot Study
 , , , ,
, , , ,
Abstract
:1. Introduction
2. Materials and Methods
2.1. Study Design
2.2. Dataset and Data Preparation
2.3. Model Architectures
2.3.1. Super-Resolution Convolutional Neural Networks (SRCNN)
2.3.2. Super-Resolution Generative Adversarial Network (SRGAN)
2.3.3. U-Net
2.3.4. Swin for Image Restoration (SwinIR)
2.3.5. Local Texture Estimator (LTE)
2.4. Training Details
2.5. Evaluation
2.5.1. Mean Squared Error (MSE)
2.5.2. Peak Signal-to-Noise Ratio (PSNR)
2.5.3. Structural Similarity Index (SSIM)
2.5.4. Mean Objective Scale (MOS)
2.6. Statistical Analysis
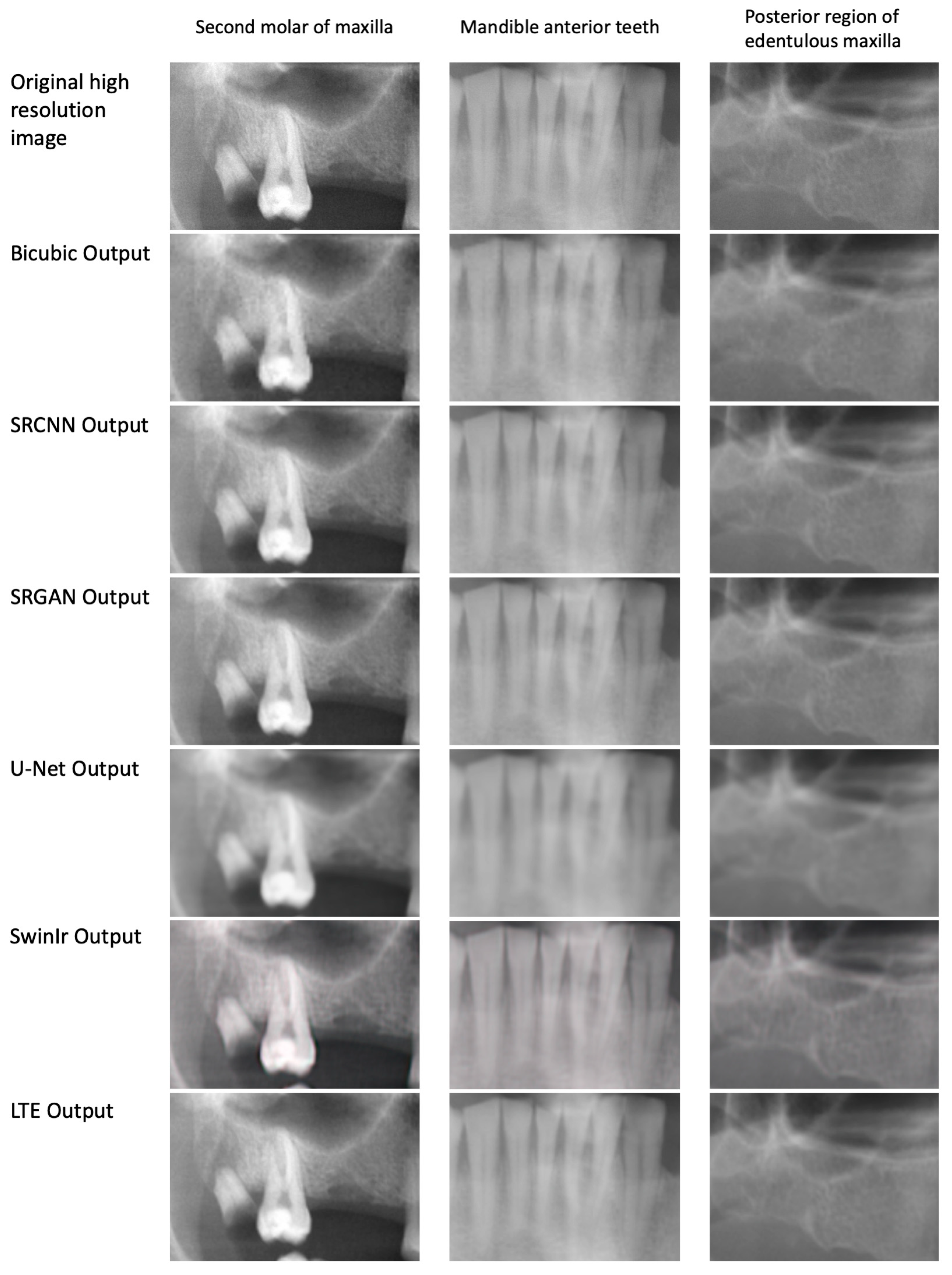
3. Results
4. Discussion
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Data Availability Statement
Conflicts of Interest
References
- Tsiklakis, K.; Mitsea, A.; Tsichlaki, A.; Pandis, N. A systematic review of relative indications and contra-indications for prescribing panoramic radiographs in dental paediatric patients. Eur. Arch. Paediatr. Dent. 2020, 21, 387–406. [Google Scholar] [CrossRef] [PubMed]
- Vesala, T.; Ekholm, M.; Ventä, I. Is dental panoramic tomography appropriate for all young adults because of third molars? Acta Odontol. Scand. 2021, 79, 52–58. [Google Scholar] [CrossRef]
- Yeom, H.-G.; Kim, J.-E.; Huh, K.-H.; Yi, W.-J.; Heo, M.-S.; Lee, S.-S.; Choi, S.-C. Correlation between spatial resolution and ball distortion rate of panoramic radiography. BMC Med. Imaging 2020, 20, 68. [Google Scholar] [CrossRef]
- Yeom, H.-G.; Kim, J.-E.; Huh, K.-H.; Yi, W.-J.; Heo, M.-S.; Lee, S.-S.; Choi, S.-C.; Lee, S.-J. Development of panorama resolution phantom for comprehensive evaluation of the horizontal and vertical resolution of panoramic radiography. Sci. Rep. 2020, 10, 16529. [Google Scholar] [CrossRef] [PubMed]
- Wenzel, A.; Møystad, A. Work flow with digital intraoral radiography: A systematic review. Acta Odontol. Scand. 2010, 68, 106–114. [Google Scholar] [CrossRef] [PubMed]
- Kositbowornchai, S.; Basiw, M.; Promwang, Y.; Moragorn, H.; Sooksuntisakoonchai, N. Accuracy of diagnosing occlusal caries using enhanced digital images. Dentomaxillofac. Radiol. 2004, 33, 236–240. [Google Scholar] [CrossRef]
- Ghaznavi, A.; Ghaznavi, D.; Valizadeh, S.; Vasegh, Z.; Al-Shuhayeb, M. Accuracy of linear measurements made on cone beam computed tomography scans at different magnifications. J. Contemp. Med. Sci. 2019, 5, 274–278. [Google Scholar] [CrossRef]
- Kositbowornchai, S.; Sikram, S.; Nuansakul, R.; Thinkhamrop, B. Root fracture detection on digital images: Effect of the zoom function. Dent. Traumatol. 2003, 19, 154–159. [Google Scholar] [CrossRef]
- Wang, Z.; Chen, J.; Hoi, S.C.H. Deep Learning for Image Super-Resolution: A Survey. IEEE Trans. Pattern Anal. Mach. Intell. 2021, 43, 3365–3387. [Google Scholar] [CrossRef] [Green Version]
- Ahmad, W.; Ali, H.; Shah, Z.; Azmat, S. A new generative adversarial network for medical images super resolution. Sci. Rep. 2022, 12, 9533. [Google Scholar] [CrossRef]
- Moran, M.B.H.; Faria, M.D.B.; Giraldi, G.A.; Bastos, L.F.; Conci, A. Using super-resolution generative adversarial network models and transfer learning to obtain high resolution digital periapical radiographs. Comput. Biol. Med. 2021, 129, 104139. [Google Scholar] [CrossRef] [PubMed]
- Mongan, J.; Moy, L.; Kahn, C.E., Jr. Checklist for Artificial Intelligence in Medical Imaging (CLAIM): A Guide for Authors and Reviewers. Radiol. Artif. Intell. 2020, 2, e200029. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Schwendicke, F.; Singh, T.; Lee, J.H.; Gaudin, R.; Chaurasia, A.; Wiegand, T.; Uribe, S.; Krois, J. Artificial intelligence in dental research: Checklist for authors, reviewers, readers. J. Dent. 2021, 107, 103610. [Google Scholar] [CrossRef] [PubMed]
- Li, Y.; Sixou, B.; Peyrin, F. A Review of the Deep Learning Methods for Medical Images Super Resolution Problems. IRBM 2021, 42, 120–133. [Google Scholar] [CrossRef]
- Dong, C.; Loy, C.C.; He, K.; Tang, X. Image super-resolution using deep convolutional networks. IEEE Trans. Pattern Anal. Mach. Intell. 2015, 38, 295–307. [Google Scholar] [CrossRef] [Green Version]
- Ledig, C.; Theis, L.; Huszár, F.; Caballero, J.; Cunningham, A.; Acosta, A.; Aitken, A.; Tejani, A.; Totz, J.; Wang, Z. Photo-realistic single image super-resolution using a generative adversarial network. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 4681–4690. [Google Scholar]
- Ronneberger, O.; Fischer, P.; Brox, T. U-net: Convolutional networks for biomedical image segmentation. In Proceedings of the International Conference on Medical Image Computing and Computer-Assisted Intervention, Munich, Germany, 5–9 October 2015; pp. 234–241. [Google Scholar]
- Liang, J.; Cao, J.; Sun, G.; Zhang, K.; Van Gool, L.; Timofte, R. SwinIR: Image restoration using swin transformer. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, BC, Canada, 11–17 October 2021; pp. 1833–1844. [Google Scholar]
- Lee, J.; Jin, K.H. Local texture estimator for implicit representation function. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 1929–1938. [Google Scholar]
- Liashchynskyi, P.; Liashchynskyi, P. Grid search, random search, genetic algorithm: A big comparison for NAS. arXiv 2019, arXiv:1912.06059. [Google Scholar]
- Madhyastha, P.; Jain, R. On model stability as a function of random seed. arXiv 2019, arXiv:1909.10447. [Google Scholar]
- Picard, D. Torch. manual_seed (3407) is all you need: On the influence of random seeds in deep learning architectures for computer vision. arXiv 2021, arXiv:2109.08203. [Google Scholar]
- Virtanen, P.; Gommers, R.; Oliphant, T.E.; Haberland, M.; Reddy, T.; Cournapeau, D.; Burovski, E.; Peterson, P.; Weckesser, W.; Bright, J.; et al. SciPy 1.0: Fundamental algorithms for scientific computing in Python. Nat. Methods 2020, 17, 261–272. [Google Scholar] [CrossRef] [Green Version]
- Schober, P.; Boer, C.; Schwarte, L.A. Correlation coefficients: Appropriate use and interpretation. Anesth. Analg. 2018, 126, 1763–1768. [Google Scholar] [CrossRef]
- Umehara, K.; Ota, J.; Ishida, T. Application of super-resolution convolutional neural network for enhancing image resolution in chest CT. J. Digit. Imaging 2018, 31, 441–450. [Google Scholar] [CrossRef] [PubMed]
- Umehara, K.; Ota, J.; Ishimaru, N.; Ohno, S.; Okamoto, K.; Suzuki, T.; Ishida, T. Performance evaluation of super-resolution methods using deep-learning and sparse-coding for improving the image quality of magnified images in chest radiographs. Open J. Med. Imaging 2017, 7, 100–111. [Google Scholar] [CrossRef] [Green Version]
- Umehara, K.; Ota, J.; Ishimaru, N.; Ohno, S.; Okamoto, K.; Suzuki, T.; Shirai, N.; Ishida, T. Super-resolution convolutional neural network for the improvement of the image quality of magnified images in chest radiographs. In Medical Imaging 2017: Image Processing; SPIE: Bellingham, WA, USA, 2017; pp. 488–494. [Google Scholar]
- Moran, M.; Faria, M.; Giraldi, G.; Bastos, L.; Conci, A. Do radiographic assessments of periodontal bone loss improve with deep learning methods for enhanced image resolution? Sensors 2021, 21, 2013. [Google Scholar] [CrossRef] [PubMed]
- Puttaguntaa, M.; Subbanb, R.; Cc, N.K.B. SwinIR Transformer Applied for Medical Image Super-Resolution. Procedia Comput. Sci. 2022, 204, 907–913. [Google Scholar]
- Zang, H.; Zhu, L.; Ding, Z.; Li, X.; Zhan, S. Cascaded Dense-UNet for Image Super-Resolution. J. Circuits Syst. Comput. 2020, 29, 2050121. [Google Scholar] [CrossRef]
- Park, J.; Hwang, D.; Kim, K.Y.; Kang, S.K.; Kim, Y.K.; Lee, J.S. Computed tomography super-resolution using deep convolutional neural network. Phys. Med. Biol. 2018, 63, 145011. [Google Scholar] [CrossRef]
- Qiu, D.; Cheng, Y.; Wang, X. Progressive U-Net residual network for computed tomography images super-resolution in the screening of COVID-19. J. Radiat. Res. Appl. Sci. 2021, 14, 369–379. [Google Scholar] [CrossRef]
- Qiu, D.; Cheng, Y.; Wang, X. Dual U-Net residual networks for cardiac magnetic resonance images super-resolution. Comput. Methods Programs Biomed. 2022, 218, 106707. [Google Scholar] [CrossRef]
- Wang, X.; Yi, J.; Guo, J.; Song, Y.; Lyu, J.; Xu, J.; Yan, W.; Zhao, J.; Cai, Q.; Min, H. A Review of Image Super-Resolution Approaches Based on Deep Learning and Applications in Remote Sensing. Remote Sens. 2022, 14, 5423. [Google Scholar] [CrossRef]
- Martins, L.A.C.; Brasil, D.M.; Forner, L.A.; Viccari, C.; Haiter-Neto, F.; Freitas, D.Q.; Oliveira, M.L. Does dose optimisation in digital panoramic radiography affect diagnostic performance? Clin. Oral Investig. 2021, 25, 637–643. [Google Scholar] [CrossRef]


{kind=link}
| Term | Definition |
|---|---|
| Batch size | The number of image samples in each batch of the dataset used for training model |
| Early stopping | Assessing the performance of the model during training and stopping training at some criterion to reduce overfitting |
| Epoch | One training cycle |
| Hyperparameter | Non-learnable parameters that affect the training |
| Hyperparameter tuning | A strategy to find optimal hyperparameters |
| Learning rate | A hyperparameter that is used to adjust learning speed |
| Optimizer | A hyperparameter that is used to adjust learnable parameters |
| Overfitting | A model overfits when it begins to memorize training data instead of developing generalizable patterns |
| Approach | MSE | PSNR | SSIM |
|---|---|---|---|
| Bicubic | 25.74 | 34.02 | 0.890 |
| SRCNN | 7.48 ± 0.30 | 39.57 ± 0.16 | 0.917 ± 0.004 |
| SRGAN | 22.31 ± 0.37 | 34.43 ± 0.32 | 0.901 ± 0.005 |
| U-Net | 8.55 ± 0.23 | 38.76 ± 0.28 | 0.917 ± 0.003 |
| SwinIR | 17.31 ± 0.21 | 36.53 ± 0.35 | 0.916 ± 0.001 |
| LTE | 7.42 ± 0.44 | 39.74 ± 0.17 | 0.919 ± 0.003 |
| Approach | MSE | PSNR | SSIM | ||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| SRCNN | SRGAN | U-Net | SwinIR | LTE | SRCNN | SRGAN | U-Net | SwinIR | LTE | SRCNN | SRGAN | U-Net | SwinIR | LTE | |
| Bicubic | <0.001 | <0.001 | <0.001 | <0.001 | <0.001 | <0.001 | 0.046 | <0.001 | <0.001 | <0.001 | <0.001 | <0.001 | <0.001 | <0.001 | <0.001 |
| SRCNN | - | <0.001 | <0.001 | <0.001 | 0.801 | - | <0.001 | <0.001 | <0.001 | 0.206 | - | <0.001 | 1 | 0.588 | 0.742 |
| SRGAN | - | - | <0.001 | <0.001 | <0.001 | - | - | <0.001 | <0.001 | <0.001 | - | - | <0.001 | <0.001 | <0.001 |
| U-Net | - | - | - | <0.001 | <0.001 | - | - | - | <0.001 | <0.001 | - | - | - | 0.959 | 0.584 |
| SwinIR | - | - | - | - | <0.001 | - | - | - | - | <0.001 | - | - | - | - | 0.068 |
| Approach | Rater 1 | Rater 2 | Rater 3 | Rater 4 | Total MOS (Mean ± sd) | p Value |
|---|---|---|---|---|---|---|
| SRCNN | 2.87 | 3.81 | 3.27 | 3.84 | 3.45 ± 0.75 | <0.001 |
| SRGAN | 3.03 | 3.39 | 3.19 | 3.45 | 3.27 ± 0.65 | <0.001 |
| U-Net | 2.93 | 3.39 | 2.97 | 3.56 | 3.21 ± 0.86 | 0.002 |
| SwinIR | 2.94 | 3.23 | 2.81 | 3.31 | 3.07 ± 0.77 | 0.017 |
| LTE | 3.43 | 3.73 | 3.43 | 3.77 | 3.59 ± 0.54 | <0.001 |
| HR image | 3.78 | 4.13 | 3.77 | 4.20 | 3.97 ± 0.53 | <0.001 |
| Bicubic | 2.1 | 2.91 | 2.67 | 3.03 | 2.68 ± 0.77 | - |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Mohammad-Rahimi, H.; Vinayahalingam, S.; Mahmoudinia, E.; Soltani, P.; Bergé, S.J.; Krois, J.; Schwendicke, F. Super-Resolution of Dental Panoramic Radiographs Using Deep Learning: A Pilot Study. Diagnostics 2023, 13, 996. https://doi.org/10.3390/diagnostics13050996
Mohammad-Rahimi H, Vinayahalingam S, Mahmoudinia E, Soltani P, Bergé SJ, Krois J, Schwendicke F. Super-Resolution of Dental Panoramic Radiographs Using Deep Learning: A Pilot Study. Diagnostics. 2023; 13(5):996. https://doi.org/10.3390/diagnostics13050996
Chicago/Turabian StyleMohammad-Rahimi, Hossein, Shankeeth Vinayahalingam, Erfan Mahmoudinia, Parisa Soltani, Stefaan J. Bergé, Joachim Krois, and Falk Schwendicke. 2023. "Super-Resolution of Dental Panoramic Radiographs Using Deep Learning: A Pilot Study" Diagnostics 13, no. 5: 996. https://doi.org/10.3390/diagnostics13050996