
DeepSmile: Anomaly Detection Software for Facial Movement Assessment

 , , , and
, , , and
Abstract
:1. Introduction
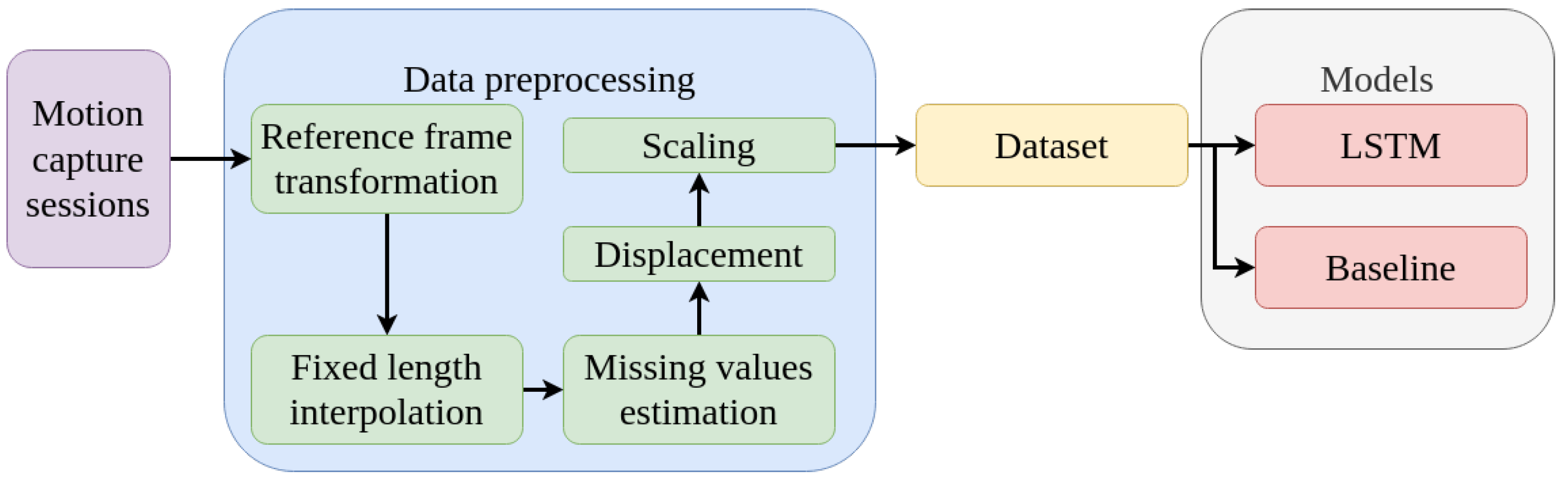
2. Materials and Methods
2.1. Motion Capture Sessions
2.2. Data Preprocessing
2.3. Datasets
2.4. Models
2.4.1. Baseline
2.4.2. Long-Short Term Memory
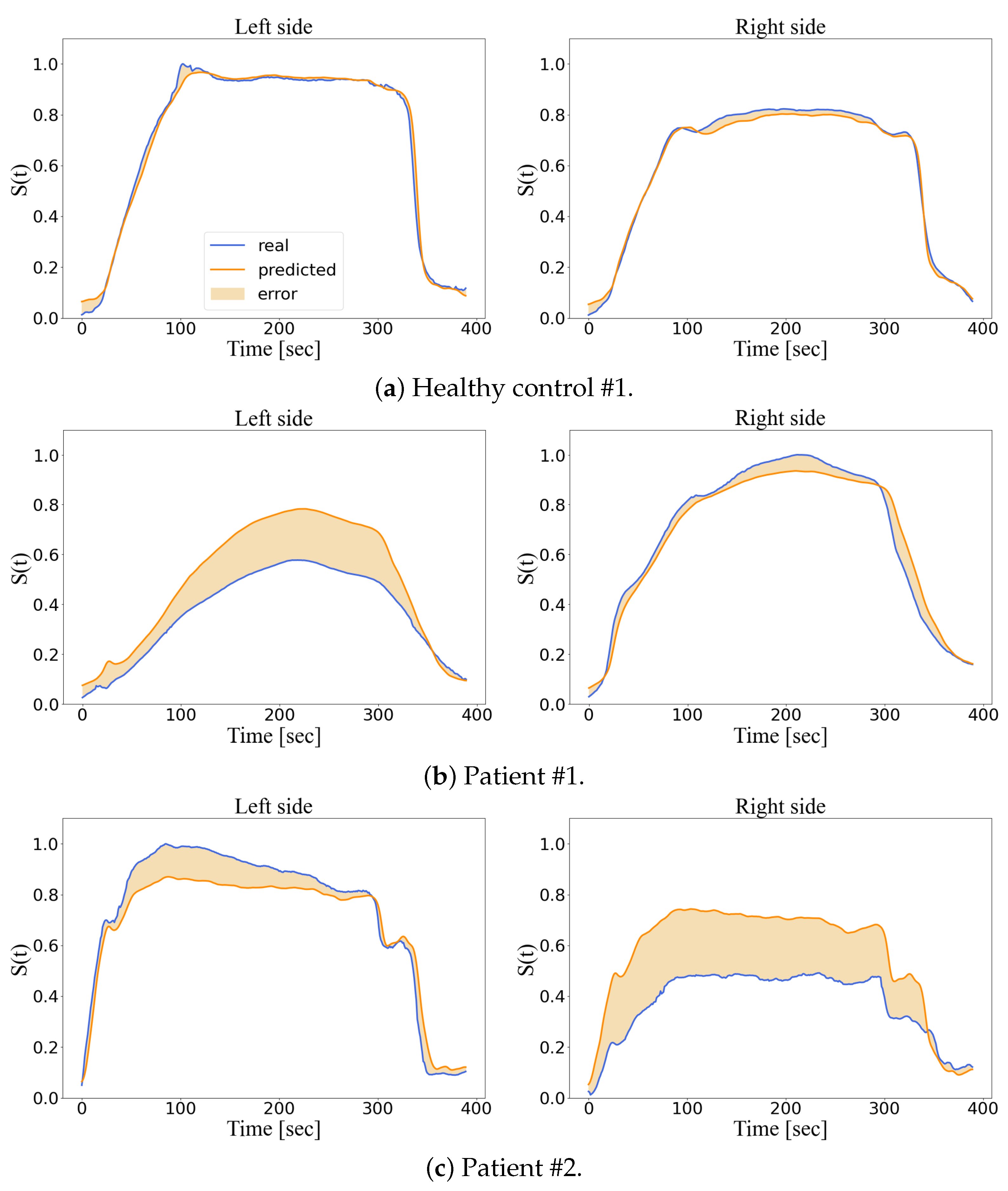
3. Results
4. Discussion
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Jones, A.L.; Schild, C.; Jones, B.C. Facial metrics generated from manually and automatically placed image landmarks are highly correlated. Evol. Hum. Behav. 2021, 42, 186–193. [Google Scholar] [CrossRef]
- Imai, T.; Okami, K. Facial cues to age perception using three-dimensional analysis. PLoS ONE 2019, 14, e0209639. [Google Scholar] [CrossRef] [PubMed]
- Burton, A.M.; Bruce, V.; Dench, N. What’s the difference between men and women? Evidence from facial measurement. Perception 1993, 22, 153–176. [Google Scholar] [CrossRef]
- Bargiela-Chiappini, F.; Haugh, M. Face, communication and social interaction. J. Politeness Res. Lang. Behav. Cult. 2011, 7. [Google Scholar] [CrossRef]
- Edward, L.; Dakpe, S.; Feissel, P.; Devauchelle, B.; Marin, F. Quantification of facial movements by motion capture. Comput. Methods Biomech. Biomed. Eng. 2012, 15, 259–260. [Google Scholar] [CrossRef] [PubMed]
- Steinbacher, J.; Metz, A.A.; Tzou, C.H.J. 3D, 4D, Mobile APP, VR, AR, and MR Systems in Facial Palsy. In Facial Palsy; Springer: rBerlin/Heidelberg, Germany, 2021; pp. 405–425. [Google Scholar]
- Jiang, C.; Wu, J.; Zhong, W.; Wei, M.; Tong, J.; Yu, H.; Wang, L. Automatic facial paralysis assessment via computational image analysis. J. Healthc. Eng. 2020, 2020, 2398542. [Google Scholar] [CrossRef]
- House, J.W. Facial nerve grading systems. Laryngoscope 1983, 93, 1056–1069. [Google Scholar] [CrossRef]
- Hato, N.; Fujiwara, T.; Gyo, K.; Yanagihara, N. Yanagihara facial nerve grading system as a prognostic tool in Bell’s palsy. Otol. Neurotol. 2014, 35, 1669–1672. [Google Scholar] [CrossRef]
- Neely, J.G.; Cherian, N.G.; Dickerson, C.B.; Nedzelski, J.M. Sunnybrook facial grading system: Reliability and criteria for grading. Laryngoscope 2010, 120, 1038–1045. [Google Scholar] [CrossRef]
- Fattah, A.Y.; Gurusinghe, A.D.; Gavilan, J.; Hadlock, T.A.; Marcus, J.R.; Marres, H.; Nduka, C.C.; Slattery, W.H.; Snyder-Warwick, A.K. Facial nerve grading instruments: Systematic review of the literature and suggestion for uniformity. Plast. Reconstr. Surg. 2015, 135, 569–579. [Google Scholar] [CrossRef]
- Revenaugh, P.C.; Smith, R.M.; Plitt, M.A.; Ishii, L.; Boahene, K.; Byrne, P.J. Use of objective metrics in dynamic facial reanimation: A systematic review. JAMA Facial Plast. Surg. 2018, 20, 501–508. [Google Scholar] [CrossRef] [PubMed]
- Popat, H.; Richmond, S.; Benedikt, L.; Marshall, D.; Rosin, P.L. Quantitative analysis of facial movement—A review of three-dimensional imaging techniques. Comput. Med. Imaging Graph. 2009, 33, 377–383. [Google Scholar] [CrossRef] [PubMed]
- Gaudin, R.A.; Robinson, M.; Banks, C.A.; Baiungo, J.; Jowett, N.; Hadlock, T.A. Emerging vs time-tested methods of facial grading among patients with facial paralysis. JAMA Facial Plast. Surg. 2016, 18, 251–257. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Dalla Toffola, E.; Bossi, D.; Buonocore, M.; Montomoli, C.; Petrucci, L.; Alfonsi, E. Usefulness of BFB/EMG in facial palsy rehabilitation. Disabil. Rehabil. 2005, 27, 809–815. [Google Scholar] [CrossRef] [PubMed]
- Kartush, J.M.; Lilly, D.J.; Kemink, J.L. Facial electroneurography: Clinical and experimental investigations. Otolaryngol.—Head Neck Surg. 1985, 93, 516–523. [Google Scholar] [CrossRef]
- Lee, D.H. Clinical efficacy of electroneurography in acute facial paralysis. J. Audiol. Otol. 2016, 20, 8. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Valls-Solé, J.; Montero, J. Movement disorders in patients with peripheral facial palsy. Mov. Disord. Off. J. Mov. Disord. 2003, 18, 1424–1435. [Google Scholar] [CrossRef]
- King, D.E. Dlib-ml: A machine learning toolkit. J. Mach. Learn. Res. 2009, 10, 1755–1758. [Google Scholar]
- Barbosa, J.; Seo, W.K.; Kang, J. paraFaceTest: An ensemble of regression tree-based facial features extraction for efficient facial paralysis classification. BMC Med. Imaging 2019, 19, 1–14. [Google Scholar] [CrossRef] [Green Version]
- Wang, T.; Zhang, S.; Dong, J.; Liu, L.; Yu, H. Automatic evaluation of the degree of facial nerve paralysis. Multimed. Tools Appl. 2016, 75, 11893–11908. [Google Scholar] [CrossRef] [Green Version]
- Miller, M.Q.; Hadlock, T.A.; Fortier, E.; Guarin, D.L. The Auto-eFACE: Machine learning–enhanced program yields automated facial palsy assessment tool. Plast. Reconstr. Surg. 2021, 147, 467–474. [Google Scholar] [CrossRef] [PubMed]
- Guo, Z.; Dan, G.; Xiang, J.; Wang, J.; Yang, W.; Ding, H.; Deussen, O.; Zhou, Y. An unobtrusive computerized assessment framework for unilateral peripheral facial paralysis. IEEE J. Biomed. Health Inform. 2017, 22, 835–841. [Google Scholar] [CrossRef] [PubMed]
- Manohar, V.; Goldgof, D.; Sarkar, S.; Zhang, Y. Facial strain pattern as a soft forensic evidence. In Proceedings of the 2007 IEEE Workshop on Applications of Computer Vision (WACV’07), Austin, TX, USA, 21–22 February 2007; p. 42. [Google Scholar]
- Manohar, V.; Shreve, M.; Goldgof, D.; Sarkar, S. Modeling facial skin motion properties in video and its application to matching faces across expressions. In Proceedings of the 2010 20th International Conference on Pattern Recognition, Istanbul, Turkey, 23–26 August 2010; pp. 2122–2125. [Google Scholar]
- Guo, Z.; Shen, M.; Duan, L.; Zhou, Y.; Xiang, J.; Ding, H.; Chen, S.; Deussen, O.; Dan, G. Deep assessment process: Objective assessment process for unilateral peripheral facial paralysis via deep convolutional neural network. In Proceedings of the 2017 IEEE 14th international symposium on biomedical imaging (ISBI 2017), Melbourne, Australia, 18–21 April 2017; pp. 135–138. [Google Scholar]
- LeCun, Y.; Bottou, L.; Bengio, Y.; Haffner, P. Gradient-based learning applied to document recognition. Proc. IEEE 1998, 86, 2278–2324. [Google Scholar] [CrossRef] [Green Version]
- Song, A.; Wu, Z.; Ding, X.; Hu, Q.; Di, X. Neurologist standard classification of facial nerve paralysis with deep neural networks. Future Internet 2018, 10, 111. [Google Scholar] [CrossRef] [Green Version]
- Adolphs, N.; Haberl, E.J.; Liu, W.; Keeve, E.; Menneking, H.; Hoffmeister, B. Virtual planning for craniomaxillofacial surgery–7 years of experience. J. Cranio-Maxillofac. Surg. 2014, 42, e289–e295. [Google Scholar] [CrossRef]
- Verzé, L.; Bianchi, F.A.; Schellino, E.; Ramieri, G. Soft tissue changes after orthodontic surgical correction of jaws asymmetry evaluated by three-dimensional surface laser scanner. J. Craniofacial Surg. 2012, 23, 1448–1452. [Google Scholar] [CrossRef] [PubMed]
- Bianchi, F.A.; Verze, L.; Ramieri, G. Facial mobility after bimaxillary surgery in class III patients: A three-dimensional study. In Proceedings of the XXI Congress f the European Association for Cranio-Maxillo-Facial Surgery. EACMFS2012, Dubrovnik, Croatia, 11–15 September 2012; p. 304. [Google Scholar]
- Petrides, G.; Clark, J.R.; Low, H.; Lovell, N.; Eviston, T.J. Three-dimensional scanners for soft-tissue facial assessment in clinical practice. J. Plast. Reconstr. Aesthetic Surg. 2021, 74, 605–614. [Google Scholar] [CrossRef]
- Sjögreen, L.; Lohmander, A.; Kiliaridis, S. Exploring quantitative methods for evaluation of lip function. J. Oral Rehabil. 2011, 38, 410–422. [Google Scholar] [CrossRef] [Green Version]
- Ju, X.; Khambay, B.; O’Leary, E.; Al-Anezi, T.; Ayoub, A. Evaluation of the reproducibility of non-verbal facial animations. In Proceedings of the International Conference on Articulated Motion and Deformable Objects, Mallorca, Spain, 11–13 July 2012; Springer: Berlin/Heidelberg, Germany, 2012; pp. 184–193. [Google Scholar]
- Sarhan, F.R.; Mansour, K.; Neiva, C.; Godard, C.; Devauchelle, B.; Marin, F.; Dakpe, S. Apports d’une plateforme d’analyse du mouvement dans l’évaluation et la rééducation des atteintes de la mimique faciale. Kinésithérapie Rev. 2015, 15, 30–31. [Google Scholar] [CrossRef]
- Sarhan, F.R.; Mansour, K.B.; Godard, C.; Neiva, C.; Devauchelle, B.; Marin, F.; Dakpe, S. Validation d’un protocole d’analyse quantifiée des mouvements de la mimique faciale. Neurophysiol. Clin./Clin. Neurophysiol. 2016, 46, 280. [Google Scholar] [CrossRef]
- Sforza, C.; Frigerio, A.; Mapelli, A.; Mandelli, F.; Sidequersky, F.V.; Colombo, V.; Ferrario, V.F.; Biglioli, F. Facial movement before and after masseteric-facial nerves anastomosis: A three-dimensional optoelectronic pilot study. J. Cranio-Maxillofac. Surg. 2012, 40, 473–479. [Google Scholar] [CrossRef] [PubMed]
- Sforza, C.; Frigerio, A.; Mapelli, A.; Tarabbia, F.; Annoni, I.; Colombo, V.; Latiff, M.; Ferreira, C.L.P.; Rabbiosi, D.; Sidequersky, F.V.; et al. Double-powered free gracilis muscle transfer for smile reanimation: A longitudinal optoelectronic study. J. Plast. Reconstr. Aesthetic Surg. 2015, 68, 930–939. [Google Scholar] [CrossRef] [Green Version]
- Trotman, C.A.; Faraway, J.; Hadlock, T.; Banks, C.; Jowett, N.; Jung, H.J. Facial soft-tissue mobility: Baseline dynamics of patients with unilateral facial paralysis. Plast. Reconstr. Surg. Glob. Open 2018, 6, e1955. [Google Scholar] [CrossRef]
- Hochreiter, S.; Schmidhuber, J. Long short-term memory. Neural Comput. 1997, 9, 1735–1780. [Google Scholar] [CrossRef]
- Chalapathy, R.; Menon, A.; Chawla, S. Anomaly Detection using One-Class Neural Networks. arXiv 2018, arXiv:1704.06743v. [Google Scholar]
- Sarhan, F.R. Quantification des mouvements de la mimique faciale par motion capture sur une population de volontaires sains. Ph.D. Thesis, University of Technology of Compiègne, Compiègne, France, 2017. Available online: https://theses.fr/2017COMP2370 (accessed on 6 January 2023).
- Dagnes, N.; Marcolin, F.; Vezzetti, E.; Sarhan, F.R.; Dakpé, S.; Marin, F.; Nonis, F.; Mansour, K.B. Optimal marker set assessment for motion capture of 3D mimic facial movements. J. Biomech. 2019, 93, 86–93. [Google Scholar] [CrossRef] [PubMed]
- Sainani, K.L. Dealing with missing data. PM&R 2015, 7, 990–994. [Google Scholar]
- Sarhan, F.R.; Olivetto, M.; Ben Mansour, K.; Neiva, C.; Colin, E.; Choteau, B.; Marie, J.P.; Testelin, S.; Marin, F.; Dakpé, S. Quantified analysis of facial movement, a reference for clinical applications. J. Clin. Anat. 2023, in press. [Google Scholar]
- Olivetto, M.; Sarhan, F.-R.; Mansour, K.B.; Marie, J.-P.; Marin, F.; Dakpe, S. Quantitative Analysis of Facial Palsy Based on 3D Motion Capture (SiMoVi-FaceMoCap Project). Arch. Phys. Med. Rehabil. 2019, 100, e112. [Google Scholar] [CrossRef]
- Mansour, K.B.; Sarhan, F.; Neiva, C.; Godard, C.; Devauchelle, B.; Marin, F.; Dakpé, S. Analysis of mimic facial movements based on motion capture. Comput. Methods Biomech. Biomed. Engin 2014, 17, 78–79. [Google Scholar] [CrossRef]
- Géron, A. Hands-on Machine Learning with Scikit-Learn, Keras, and TensorFlow: Concepts, Tools, and Techniques to Build Intelligent Systems; O’Reilly Media, Inc.: Sebastopol, CA, USA, 2019. [Google Scholar]
- Rumelhart, D.E.; Hinton, G.E.; Williams, R.J. Learning Internal Representations by Error Propagation; Parallel Distributed Processing: Explorations in the Microstructure of Cognition: Foundations; MIT Press: Cambridge, MA, USA, 1987; pp. 318–362. [Google Scholar]
- Elman, J.L. Finding structure in time. Cogn. Sci. 1990, 14, 179–211. [Google Scholar] [CrossRef]
- Canizo, M.; Triguero, I.; Conde, A.; Onieva, E. Multi-head CNN–RNN for multi-time series anomaly detection: An industrial case study. Neurocomputing 2019, 363, 246–260. [Google Scholar] [CrossRef]
- Lindemann, B.; Maschler, B.; Sahlab, N.; Weyrich, M. A survey on anomaly detection for technical systems using LSTM networks. Comput. Ind. 2021, 131, 103498. [Google Scholar] [CrossRef]
- Yu, Z.; Liu, G.; Liu, Q.; Deng, J. Spatio-temporal convolutional features with nested LSTM for facial expression recognition. Neurocomputing 2018, 317, 50–57. [Google Scholar] [CrossRef]
- Yu, Y.; Si, X.; Hu, C.; Zhang, J. A review of recurrent neural networks: LSTM cells and network architectures. Neural Comput. 2019, 31, 1235–1270. [Google Scholar] [CrossRef] [PubMed]
- Graves, A.; Schmidhuber, J. Framewise phoneme classification with bidirectional LSTM and other neural network architectures. Neural Netw. 2005, 18, 602–610. [Google Scholar] [CrossRef]
- Kingma, D.P.; Ba, J. Adam: A method for stochastic optimization. arXiv 2014, arXiv:1412.6980. [Google Scholar]
- Gaber, A.; Taher, M.F.; Wahed, M.A.; Shalaby, N.M.; Gaber, S. Classification of facial paralysis based on machine learning techniques. BioMed. Eng. Online 2022, 21, 1–20. [Google Scholar] [CrossRef]
- Nguyen, H.; Tran, K.P.; Thomassey, S.; Hamad, M. Forecasting and Anomaly Detection approaches using LSTM and LSTM Autoencoder techniques with the applications in supply chain management. Int. J. Inf. Manag. 2021, 57, 102282. [Google Scholar] [CrossRef]
- Knoedler, L.; Baecher, H.; Kauke-Navarro, M.; Prantl, L.; Machens, H.G.; Scheuermann, P.; Palm, C.; Baumann, R.; Kehrer, A.; Panayi, A.C.; et al. Towards a Reliable and Rapid Automated Grading System in Facial Palsy Patients: Facial Palsy Surgery Meets Computer Science. J. Clin. Med. 2022, 11, 4998. [Google Scholar] [CrossRef]
- Knoedler, L.; Miragall, M.; Kauke-Navarro, M.; Obed, D.; Bauer, M.; Tißler, P.; Prantl, L.; Machens, H.G.; Broer, P.N.; Baecher, H.; et al. A Ready-to-Use Grading Tool for Facial Palsy Examiners—Automated Grading System in Facial Palsy Patients Made Easy. J. Pers. Med. 2022, 12, 1739. [Google Scholar] [CrossRef]
- Parra-Dominguez, G.S.; Sanchez-Yanez, R.E.; Garcia-Capulin, C.H. Facial paralysis detection on images using key point analysis. Appl. Sci. 2021, 11, 2435. [Google Scholar] [CrossRef]
- Jowett, N.; Malka, R.; Hadlock, T.A. Effect of weakening of ipsilateral depressor anguli oris on smile symmetry in postparalysis facial palsy. JAMA Facial Plast. Surg. 2017, 19, 29–33. [Google Scholar] [CrossRef] [PubMed]
- Sahin, S.; Yaman, M.; Mungan, S.O.; Kiziltan, M.E. What happens in the other eye? Blink reflex alterations in contralateral side after facial palsy. J. Clin. Neurophysiol. 2009, 26, 454–457. [Google Scholar] [CrossRef] [PubMed]
- de Sanctis Pecora, C.; Shitara, D. Botulinum toxin type a to improve facial symmetry in facial palsy: A practical guideline and clinical experience. Toxins 2021, 13, 159. [Google Scholar] [CrossRef] [PubMed]
- Wang, Q.; Ma, Y.; Zhao, K.; Tian, Y. A comprehensive survey of loss functions in machine learning. Ann. Data Sci. 2022, 9, 187–212. [Google Scholar] [CrossRef]
- Le-Duc, T.; Nguyen, Q.H.; Lee, J.; Nguyen-Xuan, H. Strengthening Gradient Descent by Sequential Motion Optimization for Deep Neural Networks. IEEE Trans. Evol. Comput. 2022. [Google Scholar] [CrossRef]
- Bengio, Y.; Lamblin, P.; Popovici, D.; Larochelle, H. Greedy layer-wise training of deep networks. In Advances in Neural Information Processing Systems 19: Proceedings of the 2006 Conference; MIT Press: Cambridge, MA, USA, 2006. [Google Scholar]
- Zheng, L.; Li, Z.; Li, J.; Li, Z.; Gao, J. AddGraph: Anomaly Detection in Dynamic Graph Using Attention-based Temporal GCN. In Proceedings of the Twenty-Eighth International Joint Conference on Artificial Intelligence (IJCAI-1-19), Macao, China, 10–16 August 2019; pp. 4419–4425. [Google Scholar]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Hardware or Software | Settings |
|---|---|
| Model | Asus Strix G15 |
| Operative System | Windows home |
| GPU | NVIDIA GeForce RTX 3060 |
| Memory (RAM) | 16 GB |
| Processor | AMD Ryzen 7 5800H with Radeon Graphics 3.2 GHz |
| Memory storage capacity | 512 GB SSD |
| Programming languages | Python 3.10 |
| IDE | Jupyter notebook, Spyder |
| Libraries | Tensorflow, Pandas, Numpy, Tkinter, Scikit learn |
| Smile | H-1 | H-2 | H-3 | H-4 | P-1 | P-2 | P-3 |
|---|---|---|---|---|---|---|---|
| LSTM | |||||||
| Baseline |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Rodríguez Martínez, E.A.; Polezhaeva, O.; Marcellin, F.; Colin, É.; Boyaval, L.; Sarhan, F.-R.; Dakpé, S. DeepSmile: Anomaly Detection Software for Facial Movement Assessment. Diagnostics 2023, 13, 254. https://doi.org/10.3390/diagnostics13020254
Rodríguez Martínez EA, Polezhaeva O, Marcellin F, Colin É, Boyaval L, Sarhan F-R, Dakpé S. DeepSmile: Anomaly Detection Software for Facial Movement Assessment. Diagnostics. 2023; 13(2):254. https://doi.org/10.3390/diagnostics13020254
Chicago/Turabian StyleRodríguez Martínez, Eder A., Olga Polezhaeva, Félix Marcellin, Émilien Colin, Lisa Boyaval, François-Régis Sarhan, and Stéphanie Dakpé. 2023. "DeepSmile: Anomaly Detection Software for Facial Movement Assessment" Diagnostics 13, no. 2: 254. https://doi.org/10.3390/diagnostics13020254