
Hybrid Techniques of Facial Feature Image Analysis for Early Detection of Autism Spectrum Disorder Based on Combined CNN Features
 , , , , and
, , , , and
Abstract
:1. Introduction
- Enhancement of facial feature images for ASD through artifact removal, facial region cropping, and data normalization.
- Applying a hybrid technique for ASD detection via using a hybrid of CNN models (VGG16, ResNet101, and MobileNet) with XGBoost and RF algorithms.
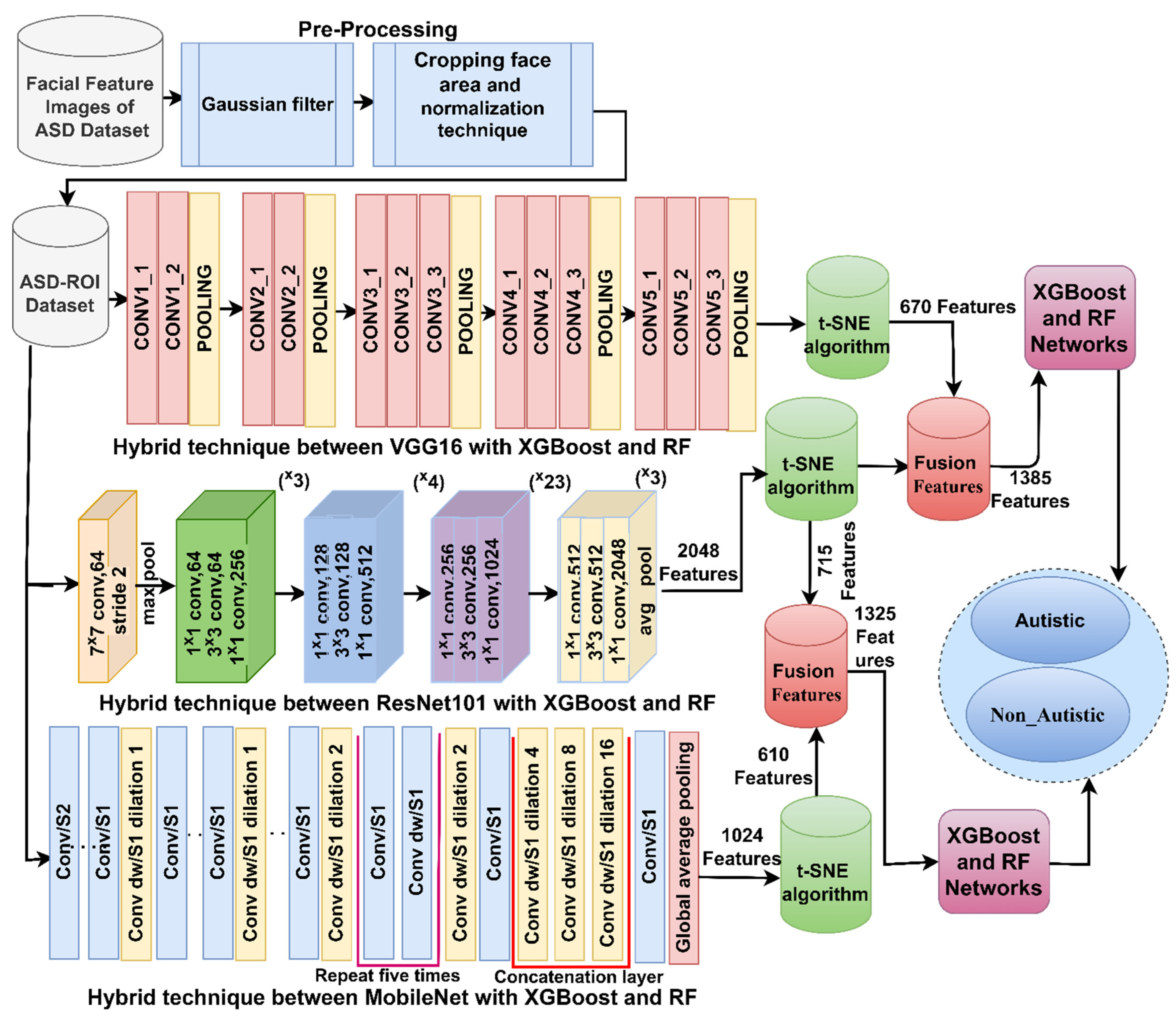
- Applying XGBoost and RF algorithms with features fused from various combinations of CNN models (VGG16-ResNet101, ResNet101-MobileNet, and VGG16-MobileNet) to achieve the early detection of ASD.
- Applying the t-SNE algorithm after the CNN models to reduce high-dimensional features. This process involves selecting the most significant fundamental features while eliminating redundant features.
2. Related Work
3. Materials and Methods
3.1. Description of Facial Features of the Autism Dataset
3.2. Improving Facial Feature Images of the Autism Dataset
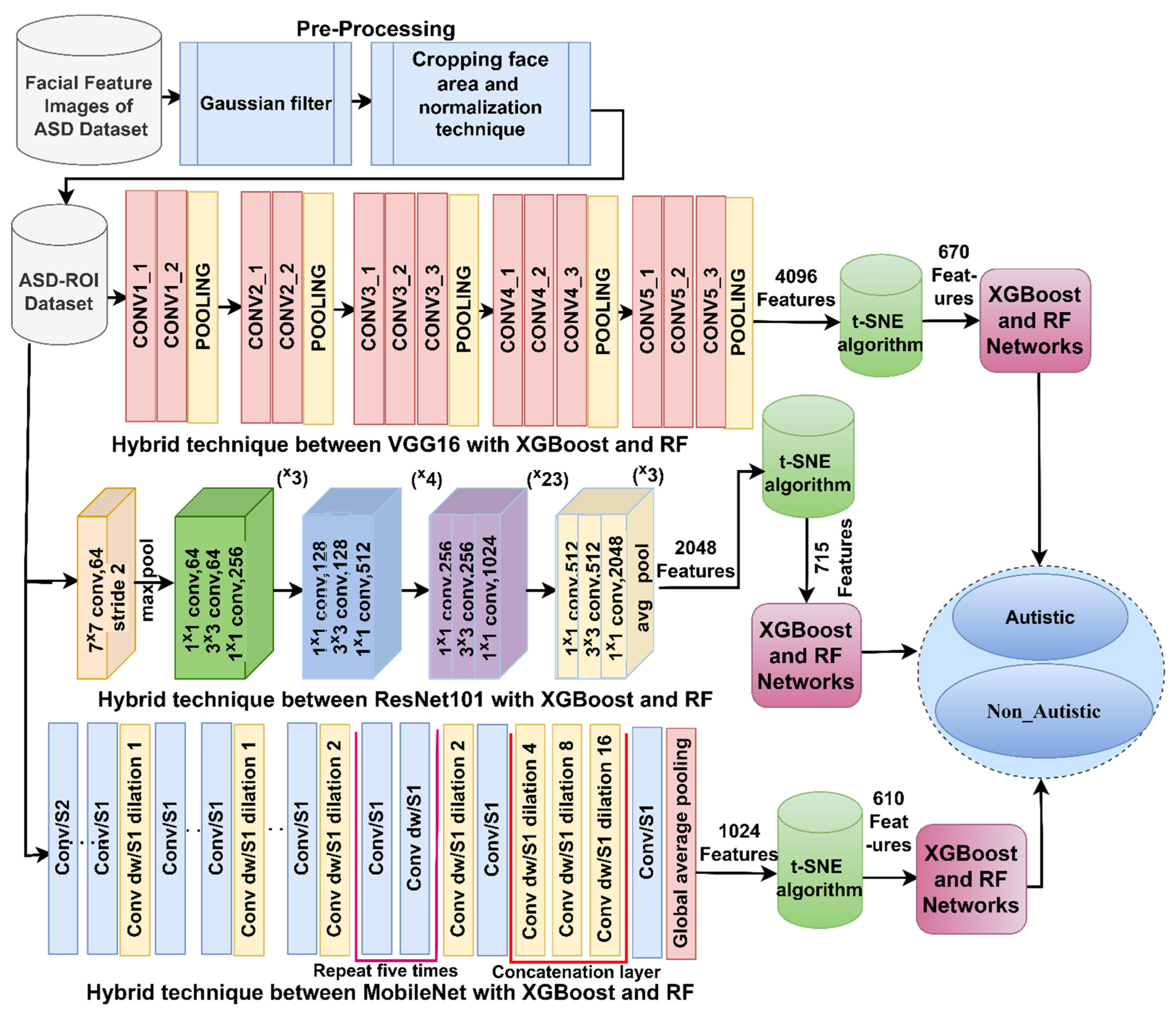
3.3. Training of Hybrid Models with Incorporated CNN Features
3.3.1. Deep Learning Models for Feature Extraction
3.3.2. t-Distributed Stochastic Neighbor Embedding
3.3.3. Classification
Extreme Gradient Boosting
Random Forest
3.4. Proposed Strategies
3.4.1. Training of Pre-Trained Strategies
3.4.2. Training of Hybrid Strategies
3.4.3. Training of Hybrid Strategies Based on Combined Features of CNN Models
4. Results of the Strategy Executions
4.1. Split of the ASD Datasets
4.2. Performance Measures
4.3. Augmentation Data Technique for the ASD Dataset
4.4. Results of the Pre-Trained CNN Models
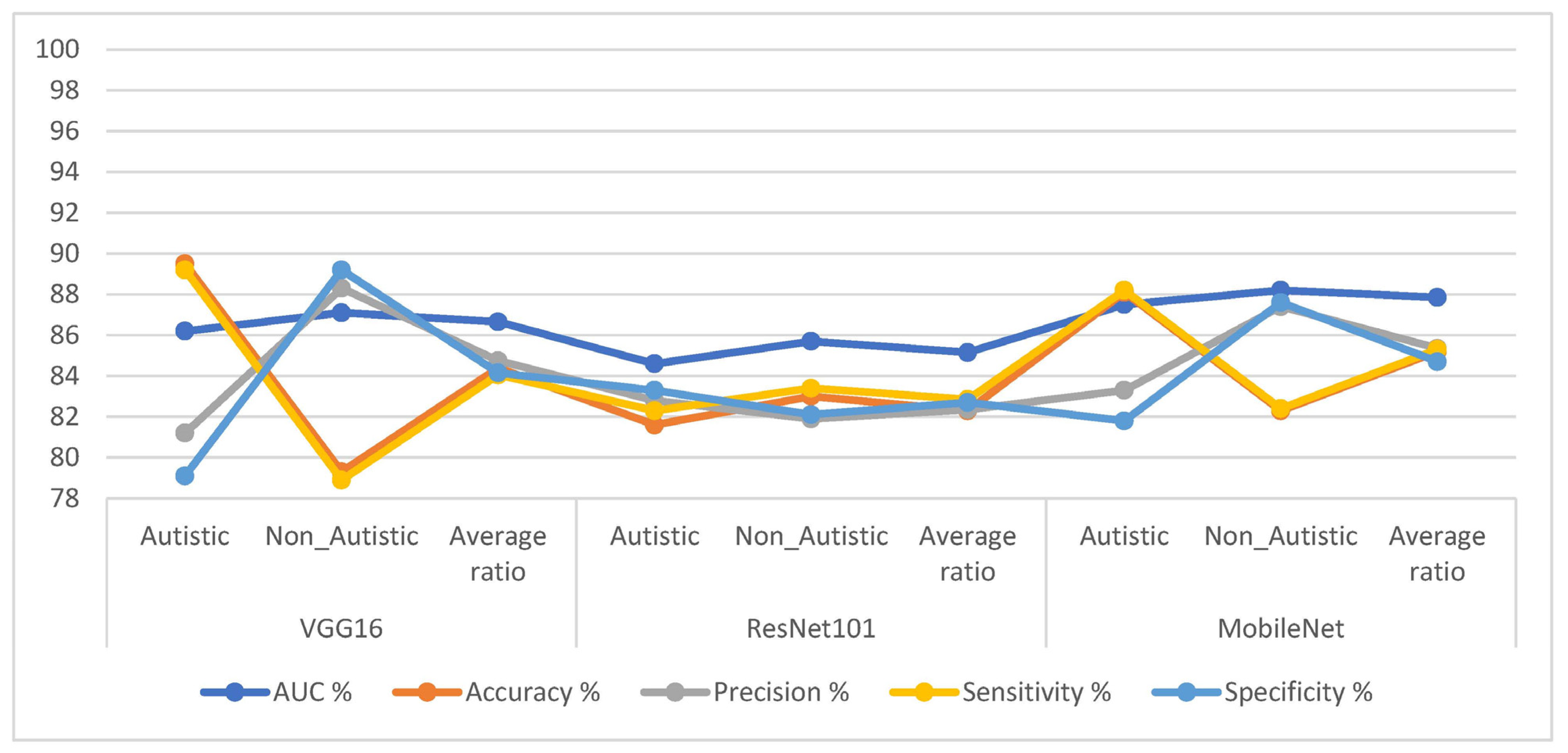
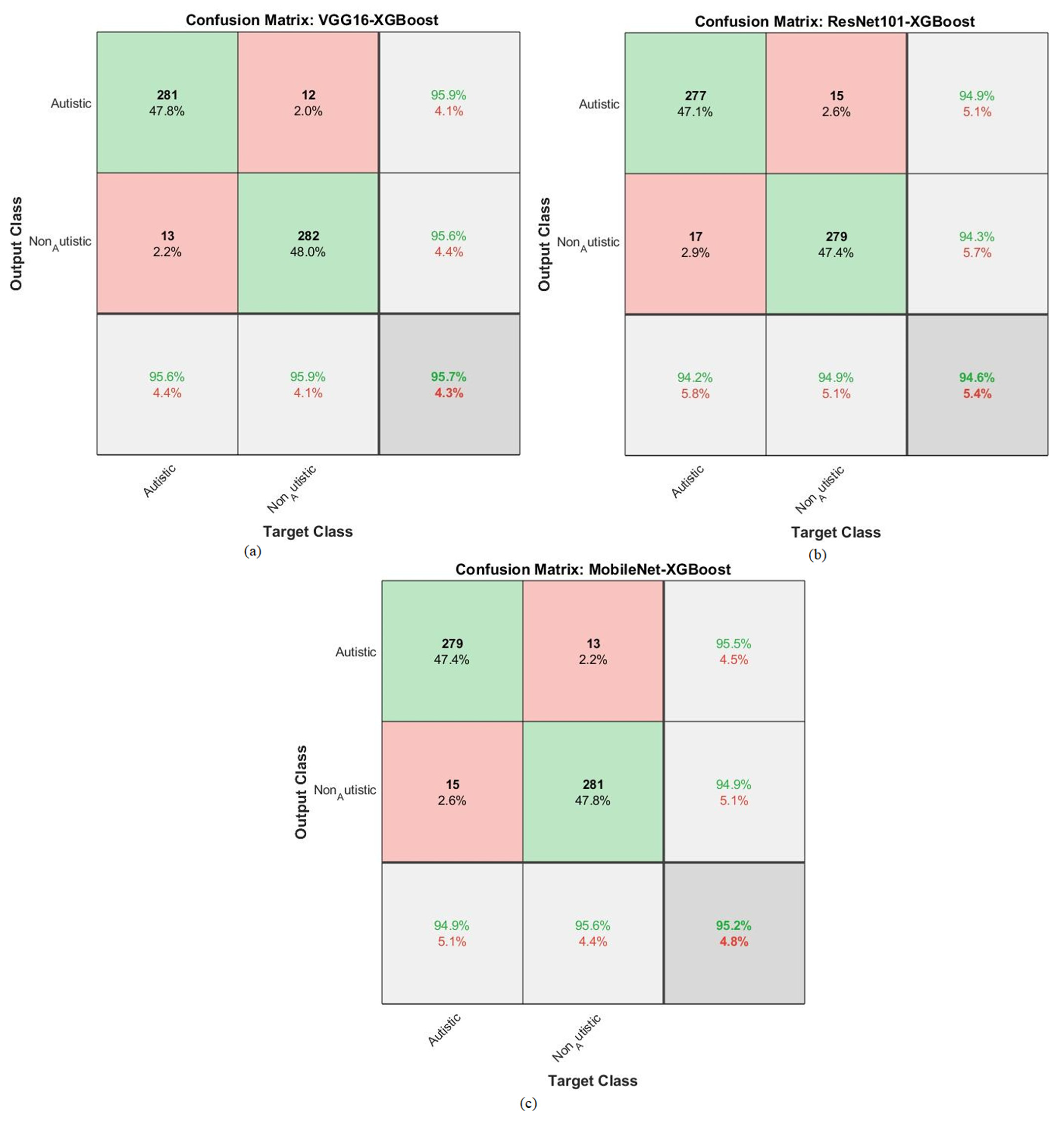
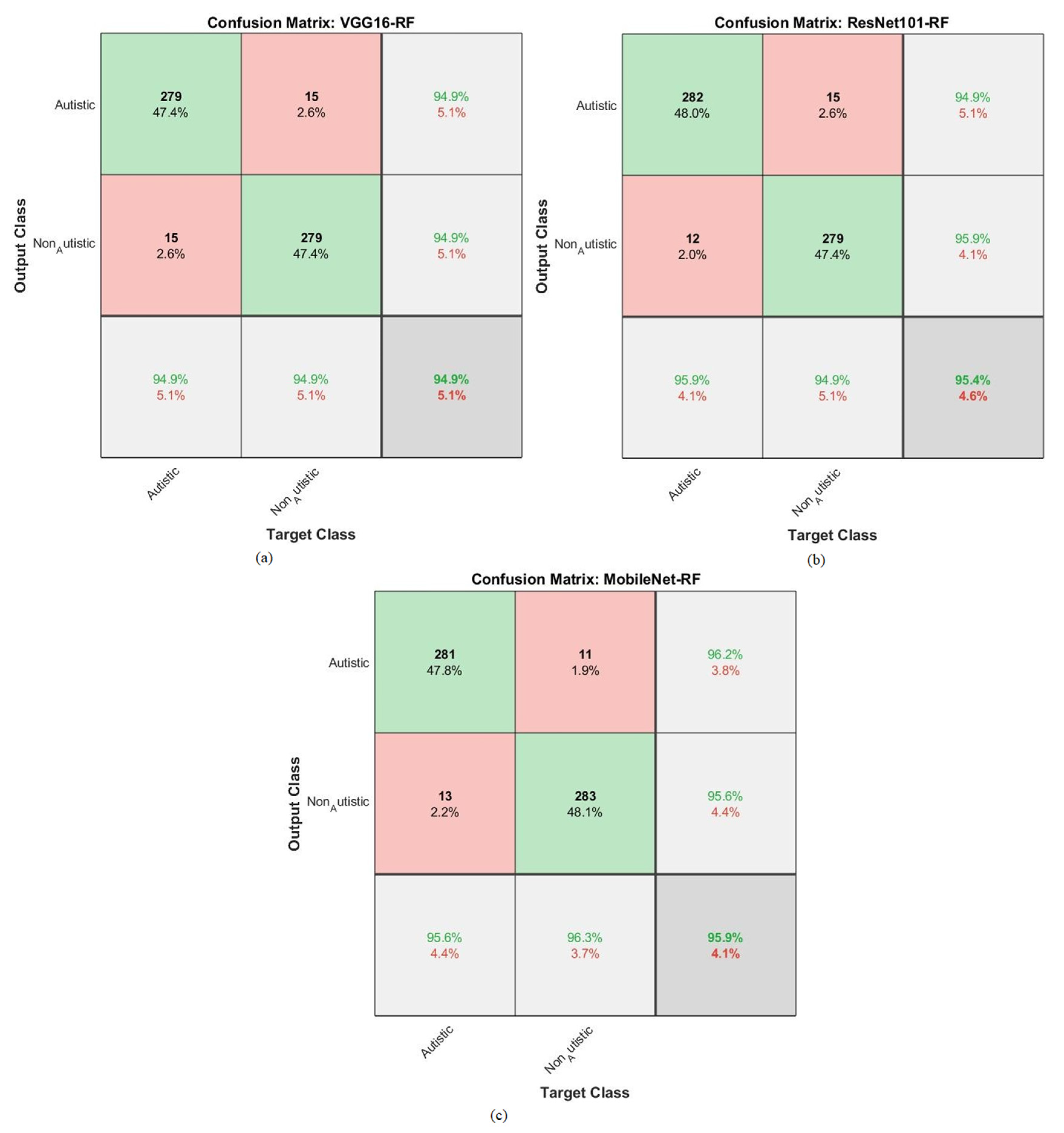
4.5. Results of the Hybrid Models
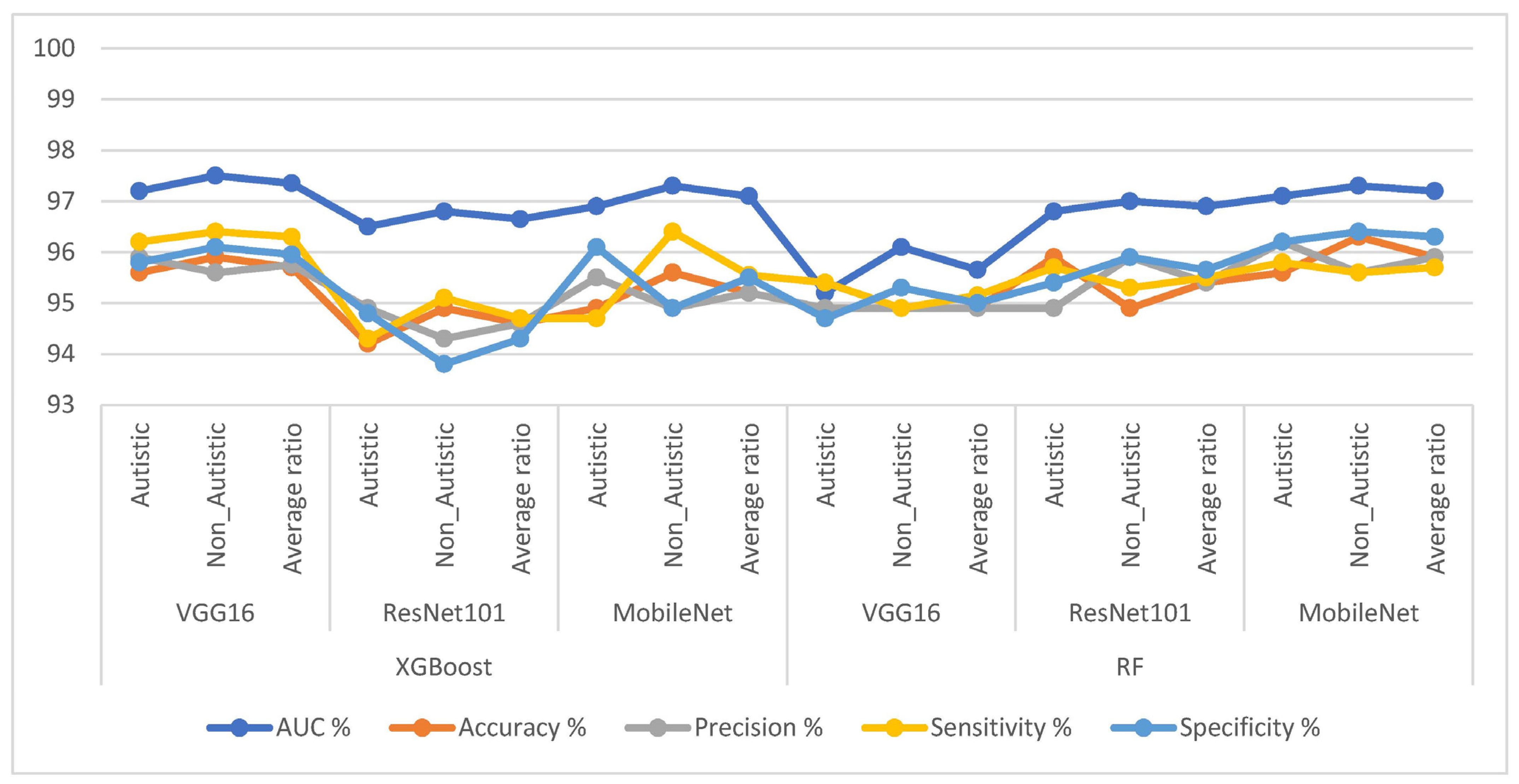
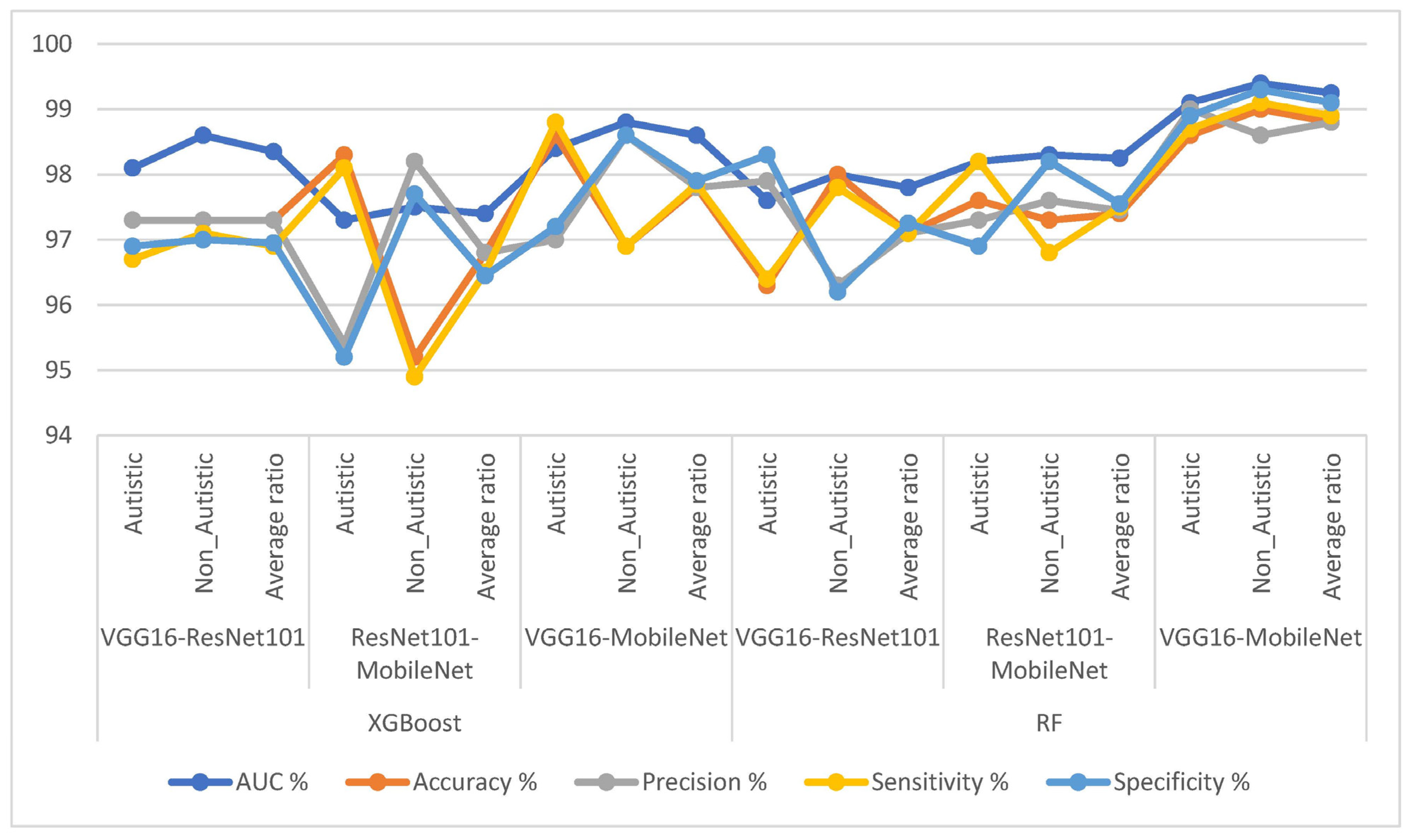
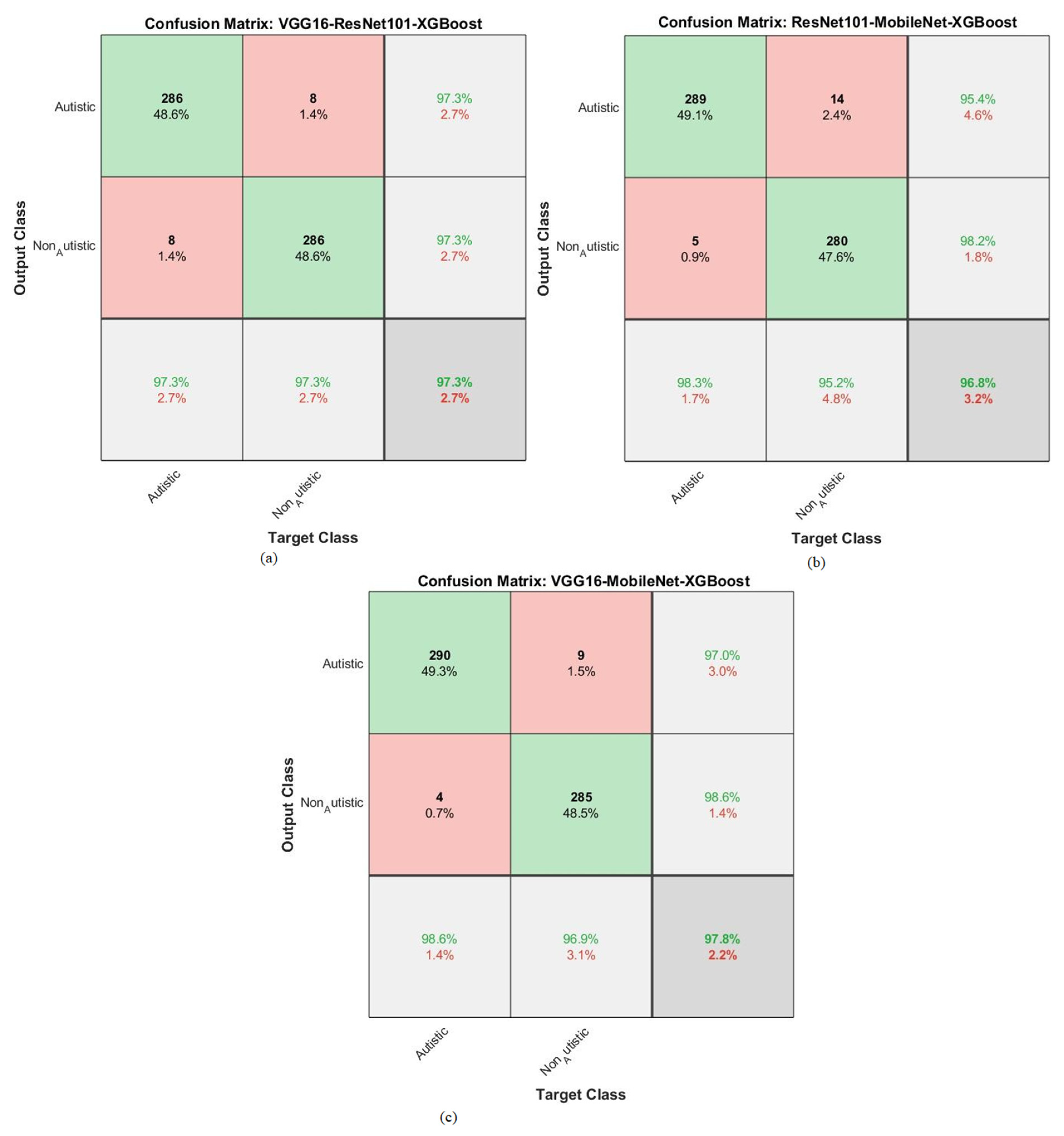
4.6. Results of Hybrid Models Utilizing Fused CNN Features
5. Discussion and Comparison of the Implementation of System Performance
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Tisato, V.; Silva, J.A.; Longo, G.; Gallo, I.; Singh, A.V.; Milani, D.; Gemmati, D. Genetics and Epigenetics of One-Carbon Metabolism Pathway in Autism Spectrum Disorder: A Sex-Specific Brain Epigenome? Genes 2021, 12, 782. [Google Scholar] [CrossRef]
- Ortega, M.A.; Álvarez-Mon, M.A.; García-Montero, C.; Fraile-Martínez, O.; Monserrat, J.; Martinez-Rozas, L.; Rodríguez-Jiménez, R.; Álvarez-Mon, M.; Lahera, G. Microbiota–gut–brain axis mechanisms in the complex network of bipolar disorders: Potential clinical implications and translational opportunities. Mol. Psychiatry 2023, 1–29. [Google Scholar] [CrossRef]
- Chaste, P.; Leboyer, M. Autism risk factors: Genes, environment, and gene-environment interactions. Dialog. Clin. Neurosci. 2012, 14, 281–292. [Google Scholar] [CrossRef] [PubMed]
- Kohn, N.; Szopinska-Tokov, J.; Arenas, A.L.; Beckmann, C.; Arias-Vasquez, A.; Aarts, E. Multivariate associative patterns between the gut microbiota and large-scale brain network connectivity. Gut Microbes 2021, 13, 2006586. [Google Scholar] [CrossRef] [PubMed]
- Ostrovsky, A.; Willa, M.; Cho, T.; Strandberg, M.; Howard, S.; Davitian, C. Data-driven, client-centric applied behavior analysis treatment-dose optimization improves functional outcomes. World J. Pediatr. 2023, 19, 753–760. [Google Scholar] [CrossRef] [PubMed]
- DiCriscio, A.S.; Smith, J.; Troiani, V. Comprehensive Assessment of Visual Perceptual Skills in Autism Spectrum Disorder. Front. Psychol. 2021, 12, 662808. [Google Scholar] [CrossRef]
- Nicpon, M.F.; Assouline, S.G.; Schuler, P.; Amend, E.R. Gifted and talented students on the autism spectrum: Best practices for fostering talent and accommodating concerns. In Special Populations in Gifted Education; Routledge: Oxford, UK, 2021; pp. 227–247. [Google Scholar] [CrossRef]
- Fetta, A.; Carati, E.; Moneti, L.; Pignataro, V.; Angotti, M.; Bardasi, M.C.; Cordelli, D.M.; Franzoni, E.; Parmeggiani, A. Relationship between sensory alterations and repetitive behaviours in children with autism spectrum disorders: A parents’ questionnaire based study. Brain Sci. 2021, 11, 484. [Google Scholar] [CrossRef] [PubMed]
- Tofani, M.; Scarcella, L.; Galeoto, G.; Giovannone, F.; Sogos, C. Behavioral gender differences across Pre-School Children with Autism Spectrum Disorders: A cross-sectional study. J. Autism Dev. Disord. 2023, 53, 3301–3306. [Google Scholar] [CrossRef]
- Briot, K.; Pizano, A.; Bouvard, M.; Amestoy, A. New Technologies as Promising Tools for Assessing Facial Emotion Expressions Impairments in ASD: A Systematic Review. Front. Psychiatry 2021, 12, 634756. [Google Scholar] [CrossRef] [PubMed]
- Solorio, A. Understanding the Experiences and Barriers to Care Affecting Families of Children with Autism Spectrum Disorder (ASD). Ph.D. Thesis, The University of Arizona, Tucson, AZ, USA, 2023. Available online: https://repository.arizona.edu/handle/10150/667971 (accessed on 17 December 2022).
- Dellapiazza, F.; Audras-Torrent, L.; Michelon, C.; Baghdadli, A. Clinical characteristics of children with ASD and comorbid ADHD: Association with social impairment and externalizing and internalizing behaviours. Res. Dev. Disabil. 2021, 113, 103930. [Google Scholar] [CrossRef]
- Washington, P.; Wall, D.P. A Review of and Roadmap for Data Science and Machine Learning for the Neuropsychiatric Phenotype of Autism. Annu. Rev. Biomed. Data Sci. 2023, 6, 211–228. [Google Scholar] [CrossRef]
- Khalaji, E.; Eraslan, S.; Yesilada, Y.; Yaneva, V. Effects of data preprocessing on detecting autism in adults using web-based eye-tracking data. Behav. Inf. Technol. 2022, 1–9. [Google Scholar] [CrossRef]
- Cardoso, T.V.; Michelassi, G.C.; Franco, F.O.; Sumiya, F.M.; Portolese, J.; Brentani, H.; Machado-Lima, A.; Nunes, F.L. Autism Spectrum Disorder diagnosis based on trajectories of eye tracking data. In Proceedings of the 2021 IEEE 34th International Symposium on Computer-Based Medical Systems (CBMS), Aveiro, Portugal, 7–9 June 2021; pp. 50–55. [Google Scholar] [CrossRef]
- Radha, S.; Abinaya, M.N.; Darshini, K.D.; Kamalnath, K.N.; Jayanthi, P. Ensemble of Behavioral Features for Early Detection of Autism Spectrum Disorder. In International Conference on Soft Computing for Security Applications; Springer Nature: Singapore, 2023; pp. 681–694. [Google Scholar] [CrossRef]
- Cilia, F.; Carette, R.; Elbattah, M.; Dequen, G.; Guérin, J.-L.; Bosche, J.; Vandromme, L.; Le Driant, B. Computer-Aided Screening of Autism Spectrum Disorder: Eye-Tracking Study Using Data Visualization and Deep Learning. JMIR Hum. Factors 2021, 8, e27706. [Google Scholar] [CrossRef]
- Gaspar, A.; Oliva, D.; Hinojosa, S.; Aranguren, I.; Zaldivar, D. An optimized Kernel Extreme Learning Machine for the classification of the autism spectrum disorder by using gaze tracking images. Appl. Soft Comput. 2022, 120, 108654. [Google Scholar] [CrossRef]
- Zhao, Z.; Tang, H.; Zhang, X.; Qu, X.; Hu, X.; Lu, J. Classification of Children With Autism and Typical Development Using Eye-Tracking Data from Face-to-Face Conversations: Machine Learning Model Development and Performance Evaluation. J. Med. Internet Res. 2021, 23, e29328. [Google Scholar] [CrossRef]
- Kollias, K.-F.; Syriopoulou-Delli, C.K.; Sarigiannidis, P.; Fragulis, G.F. Autism detection in High-Functioning Adults with the application of Eye-Tracking technology and Machine Learning. In Proceedings of the 2022 11th International Conference on Modern Circuits and Systems Technologies, 2022 (MOCAST), Bremen, Germany, 8–10 June 2022; pp. 1–4. [Google Scholar] [CrossRef]
- Sun, B.; Wang, B.; Wei, Z.; Feng, Z.; Wu, Z.L.; Yassin, W.; Stone, W.S.; Lin, Y.; Kong, X. The Role of EEG Functional Connectivity Coupled with Eye Tracking in Early Diagnosis of Autism Spectrum Disorder. 2023; in press. [Google Scholar] [CrossRef]
- Alsaade, F.W.; Alzahrani, M.S. Classification and Detection of Autism Spectrum Disorder Based on Deep Learning Algorithms. Comput. Intell. Neurosci. 2022, 2022, 8709145. [Google Scholar] [CrossRef]
- Liao, M.; Duan, H.; Wang, G. Application of Machine Learning Techniques to Detect the Children with Autism Spectrum Disorder. J. Health Eng. 2022, 2022, 9340027. [Google Scholar] [CrossRef]
- Alcañiz, M.; Chicchi-Giglioli, I.A.; Carrasco-Ribelles, L.A.; Marín-Morales, J.; Minissi, M.E.; Teruel-García, G.; Sirera, M.; Abad, L. Eye gaze as a biomarker in the recognition of autism spectrum disorder using virtual reality and machine learning: A proof of concept for diagnosis. Autism Res. 2021, 15, 131–145. [Google Scholar] [CrossRef]
- Kanhirakadavath, M.R.; Chandran, M.S.M. Investigation of Eye-Tracking Scan Path as a Biomarker for Autism Screening Using Machine Learning Algorithms. Diagnostics 2022, 12, 518. [Google Scholar] [CrossRef]
- Ahmed, I.A.; Senan, E.M.; Rassem, T.H.; Ali, M.A.H.; Shatnawi, H.S.A.; Alwazer, S.M.; Alshahrani, M. Eye Tracking-Based Diagnosis and Early Detection of Autism Spectrum Disorder Using Machine Learning and Deep Learning Techniques. Electronics 2022, 11, 530. [Google Scholar] [CrossRef]
- Mazumdar, P.; Arru, G.; Battisti, F. Early detection of children with Autism Spectrum Disorder based on visual exploration of images. Signal Process. Image Commun. 2021, 94, 116184. [Google Scholar] [CrossRef]
- Negin, F.; Ozyer, B.; Agahian, S.; Kacdioglu, S.; Ozyer, G.T. Vision-assisted recognition of stereotype behaviors for early diagnosis of Autism Spectrum Disorders. Neurocomputing 2021, 446, 145–155. [Google Scholar] [CrossRef]
- Autism_Image_Data|Kaggle. Available online: https://www.kaggle.com/datasets/cihan063/autism-image-data (accessed on 31 July 2023).
- Alalayah, K.M.; Senan, E.M.; Atlam, H.F.; Ahmed, I.A.; Shatnawi, H.S.A. Effective Early Detection of Epileptic Seizures through EEG Signals Using Classification Algorithms Based on t-Distributed Stochastic Neighbor Embedding and K-Means. Diagnostics 2023, 13, 1957. [Google Scholar] [CrossRef]
- Berto, S.; Treacher, A.H.; Caglayan, E.; Luo, D.; Haney, J.R.; Gandal, M.J.; Geschwind, D.H.; Montillo, A.A.; Konopka, G. Association between resting-state functional brain connectivity and gene expression is altered in autism spectrum disorder. Nat. Commun. 2022, 13, 3328. [Google Scholar] [CrossRef] [PubMed]
- Akter, T.; Ali, M.H.; Khan, M.I.; Satu, M.S.; Uddin, M.J.; Alyami, S.A.; Ali, S.; Azad, A.; Moni, M.A. Improved Transfer-Learning-Based Facial Recognition Framework to Detect Autistic Children at an Early Stage. Brain Sci. 2021, 11, 734. [Google Scholar] [CrossRef]
- Ahmed, I.A.; Senan, E.M.; Shatnawi, H.S.A.; Alkhraisha, Z.M.; Al-Azzam, M.M.A. Multi-Models of Analyzing Dermoscopy Images for Early Detection of Multi-Class Skin Lesions Based on Fused Features. Processes 2023, 11, 910. [Google Scholar] [CrossRef]
- Olayah, F.; Senan, E.M.; Ahmed, I.A.; Awaji, B. AI Techniques of Dermoscopy Image Analysis for the Early Detection of Skin Lesions Based on Combined CNN Features. Diagnostics 2023, 13, 1314. [Google Scholar] [CrossRef]
- Mohammed, B.A.; Senan, E.M.; Al-Mekhlafi, Z.G.; Alazmi, M.; Alayba, A.M.; Alanazi, A.A.; Alreshidi, A.; Alshahrani, M. Hybrid Techniques for Diagnosis with WSIs for Early Detection of Cervical Cancer Based on Fusion Features. Appl. Sci. 2022, 12, 8836. [Google Scholar] [CrossRef]
- Al-Jabbar, M.; Alshahrani, M.; Senan, E.M.; Ahmed, I.A. Histopathological Analysis for Detecting Lung and Colon Cancer Malignancies Using Hybrid Systems with Fused Features. Bioengineering 2023, 10, 383. [Google Scholar] [CrossRef]
- Alam, M.S.; Rashid, M.M.; Roy, R.; Faizabadi, A.R.; Gupta, K.D.; Ahsan, M.M. Empirical Study of Autism Spectrum Disorder Diagnosis Using Facial Images by Improved Transfer Learning Approach. Bioengineering 2022, 9, 710. [Google Scholar] [CrossRef]
- Alalayah, K.M.; Senan, E.M.; Atlam, H.F.; Ahmed, I.A.; Shatnawi, H.S.A. Automatic and Early Detection of Parkinson’s Disease by Analyzing Acoustic Signals Using Classification Algorithms Based on Recursive Feature Elimination Method. Diagnostics 2023, 13, 1924. [Google Scholar] [CrossRef] [PubMed]
- Zhou, G.; Ni, Z.; Zhao, Y.; Luan, J. Identification of Bamboo Species Based on Extreme Gradient Boosting (XGBoost) Using Zhuhai-1 Orbita Hyperspectral Remote Sensing Imagery. Sensors 2022, 22, 5434. [Google Scholar] [CrossRef] [PubMed]
- Uddin, M.J.; Ahamad, M.M.; Sarker, P.K.; Aktar, S.; Alotaibi, N.; Alyami, S.A.; Kabir, M.A.; Moni, M.A. An Integrated Statistical and Clinically Applicable Machine Learning Framework for the Detection of Autism Spectrum Disorder. Computers 2023, 12, 92. [Google Scholar] [CrossRef]
- Deng, L.; Rattadilok, P. A Sensor and Machine Learning-Based Sensory Management Recommendation System for Children with Autism Spectrum Disorders. Sensors 2022, 22, 5803. [Google Scholar] [CrossRef]
- Bala, M.; Ali, M.H.; Satu, M.S.; Hasan, K.F.; Moni, M.A. Efficient Machine Learning Models for Early Stage Detection of Autism Spectrum Disorder. Algorithms 2022, 15, 166. [Google Scholar] [CrossRef]
- Al-Jabbar, M.; Alshahrani, M.; Senan, E.M.; Ahmed, I.A. Analyzing Histological Images Using Hybrid Techniques for Early Detection of Multi-Class Breast Cancer Based on Fusion Features of CNN and Handcrafted. Diagnostics 2023, 13, 1753. [Google Scholar] [CrossRef]
- Eroglu, Y.; Yildirim, M.; Cinar, A. mRMR-based hybrid convolutional neural network model for classification of Alzheimer’s disease on brain magnetic resonance images. Int. J. Imaging Syst. Technol. 2021, 32, 517–527. [Google Scholar] [CrossRef]











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Phase | 80% (80:20) | Testing 20% | |
|---|---|---|---|
| Classes | Training (80%) | Validation (20%) | |
| Autism spectrum disorder | 941 | 235 | 294 |
| Typically developing | 941 | 235 | 294 |
| Models | Classes | AUC % | Accuracy % | Precision % | Sensitivity % | Specificity % |
|---|---|---|---|---|---|---|
| VGG16 | Autistic | 86.2 | 89.5 | 81.2 | 89.2 | 79.1 |
| Non_Autistic | 87.1 | 79.3 | 88.3 | 78.9 | 89.2 | |
| Average ratio | 86.65 | 84.4 | 84.75 | 84.05 | 84.15 | |
| ResNet101 | Autistic | 84.6 | 81.6 | 82.8 | 82.3 | 83.3 |
| Non_Autistic | 85.7 | 83 | 81.9 | 83.4 | 82.1 | |
| Average ratio | 85.15 | 82.3 | 82.35 | 82.85 | 82.7 | |
| MobileNet | Autistic | 87.5 | 88.1 | 83.3 | 88.2 | 81.8 |
| Non_Autistic | 88.2 | 82.3 | 87.4 | 82.4 | 87.6 | |
| Average ratio | 87.85 | 85.2 | 85.35 | 85.3 | 84.7 |
| Classifiers | CNN for Features | Classes | AUC % | Accuracy % | Precision % | Sensitivity % | Specificity % |
|---|---|---|---|---|---|---|---|
| XGBoost | VGG16 | Autistic | 97.2 | 95.6 | 95.9 | 96.2 | 95.8 |
| Non_Autistic | 97.5 | 95.9 | 95.6 | 96.4 | 96.1 | ||
| Average ratio | 97.35 | 95.7 | 95.75 | 96.3 | 95.95 | ||
| ResNet101 | Autistic | 96.5 | 94.2 | 94.9 | 94.3 | 94.8 | |
| Non_Autistic | 96.8 | 94.9 | 94.3 | 95.1 | 93.8 | ||
| Average ratio | 96.65 | 94.6 | 94.6 | 94.7 | 94.3 | ||
| MobileNet | Autistic | 96.9 | 94.9 | 95.5 | 94.7 | 96.1 | |
| Non_Autistic | 97.3 | 95.6 | 94.9 | 96.4 | 94.9 | ||
| Average ratio | 97.1 | 95.2 | 95.2 | 95.55 | 95.5 | ||
| RF | VGG16 | Autistic | 95.2 | 94.9 | 94.9 | 95.4 | 94.7 |
| Non_Autistic | 96.1 | 94.9 | 94.9 | 94.9 | 95.3 | ||
| Average ratio | 95.65 | 94.9 | 94.9 | 95.15 | 95 | ||
| ResNet101 | Autistic | 96.8 | 95.9 | 94.9 | 95.7 | 95.4 | |
| Non_Autistic | 97 | 94.9 | 95.9 | 95.3 | 95.9 | ||
| Average ratio | 96.9 | 95.4 | 95.4 | 95.5 | 95.65 | ||
| MobileNet | Autistic | 97.1 | 95.6 | 96.2 | 95.8 | 96.2 | |
| Non_Autistic | 97.3 | 96.3 | 95.6 | 95.6 | 96.4 | ||
| Average ratio | 97.2 | 95.9 | 95.9 | 95.7 | 96.3 |
| Classifiers | Models for Fusion Features | Classes | AUC % | Accuracy % | Precision % | Sensitivity % | Specificity % |
|---|---|---|---|---|---|---|---|
| XGBoost | VGG16-ResNet101 | Autistic | 98.1 | 97.3 | 97.3 | 96.7 | 96.9 |
| Non_Autistic | 98.6 | 97.3 | 97.3 | 97.1 | 97 | ||
| Average ratio | 98.35 | 97.3 | 97.3 | 96.9 | 96.95 | ||
| ResNet101-MobileNet | Autistic | 97.3 | 98.3 | 95.4 | 98.1 | 95.2 | |
| Non_Autistic | 97.5 | 95.2 | 98.2 | 94.9 | 97.7 | ||
| Average ratio | 97.4 | 96.8 | 96.8 | 96.5 | 96.45 | ||
| VGG16-MobileNet | Autistic | 98.4 | 98.6 | 97 | 98.8 | 97.2 | |
| Non_Autistic | 98.8 | 96.9 | 98.6 | 96.9 | 98.6 | ||
| Average ratio | 98.6 | 97.8 | 97.8 | 97.85 | 97.9 | ||
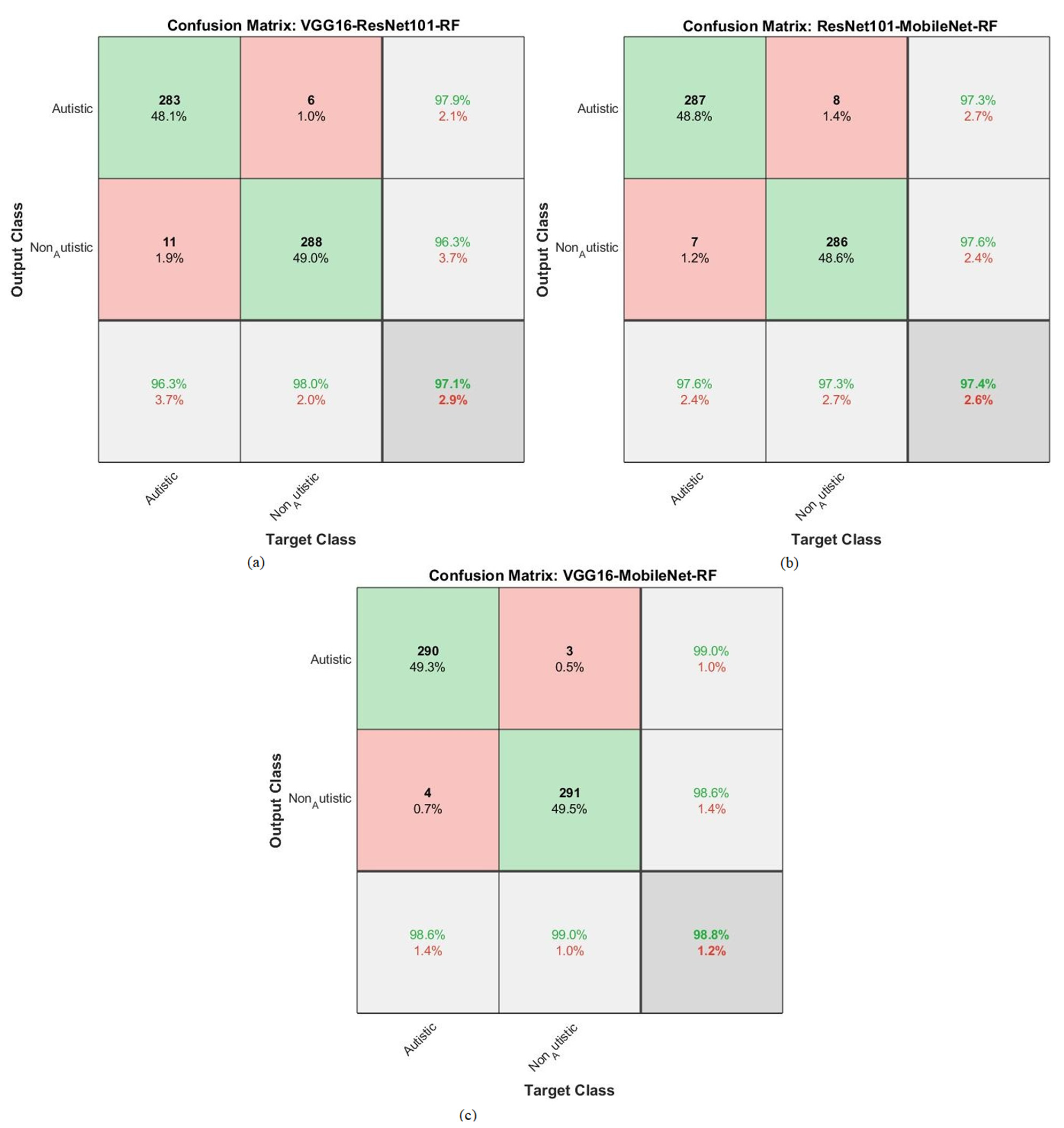
| RF | VGG16-ResNet101 | Autistic | 97.6 | 96.3 | 97.9 | 96.4 | 98.3 |
| Non_Autistic | 98 | 98 | 96.3 | 98.2 | 96.2 | ||
| Average ratio | 97.8 | 97.1 | 97.1 | 97.3 | 97.25 | ||
| ResNet101-MobileNet | Autistic | 98.2 | 97.6 | 97.3 | 98.2 | 96.9 | |
| Non_Autistic | 98.3 | 97.3 | 97.6 | 96.8 | 98.2 | ||
| Average ratio | 98.25 | 97.4 | 97.45 | 97.5 | 97.55 | ||
| VGG16-MobileNet | Autistic | 99.1 | 98.6 | 99 | 98.7 | 98.9 | |
| Non_Autistic | 99.4 | 99 | 98.8 | 99.3 | 99.3 | ||
| Average ratio | 99.25 | 98.8 | 98.9 | 99 | 99.1 |
| Study | Method | Accuracy | Sensitivity | Specificity |
|---|---|---|---|---|
| Khalaji et al. [14] | Data pre-processing + various classifiers | 75 | 82 | - |
| Cardoso et al. [15] | RF classifiers + ET signals | 75 | 82 | - |
| Radha et al. [16] | Sequential neural network + eye movement analysis | 95.7 | 84 | - |
| Cilia et al. [17] | CNN + eye-tracking scan paths | 90 | 83 | 80 |
| Gaspar et al. [18] | KELM + data augmentation + GPC | 95.8 | - | - |
| Zhong et al. [19] | 4 ML classifiers + eye tracking + forward feature selection | 92.31 | - | - |
| Kollias et al. [20] | Transfer learning + DT, logistic regression | 80.5 | - | - |
| Sun et al. [21] | NBS-predict + eye tracking + restricted interest stimuli | 63.4 | 91 | - |
| Alsaa-de et al. [22] | Deep learning + facial features | 91 | - | - |
| Liao et al. [23] | EEG + eye tracking + naive Bayes | 87.5 | - | - |
| Alcañiz et al. [24] | Machine learning + eye tracking + virtual environment | 86 | 91 | - |
| Kanhirakadavath et al. [25] | Deep neural network + image augmentation | 97 | 93.28 | 91.38 |
| Ibrahim et al. [26] | Neural networks, pre-trained CNNs, ResNet-18, and hybrid method | 93.6 | - | - |
| Mazumdar et al. [27] | Machine learning + eye tracking + image content | 59 | 68 | 50 |
| Negin et al. [28] | Local descriptors, MLP, GNB, SVM, articulated pose-based skeleton sequences, LSTM, ConvLSTM, and 3DCNN | 72 | - | - |
| Proposed model | VGG16-MobileNet-RF | 98.8 | 99 | 99.1 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Awaji, B.; Senan, E.M.; Olayah, F.; Alshari, E.A.; Alsulami, M.; Abosaq, H.A.; Alqahtani, J.; Janrao, P. Hybrid Techniques of Facial Feature Image Analysis for Early Detection of Autism Spectrum Disorder Based on Combined CNN Features. Diagnostics 2023, 13, 2948. https://doi.org/10.3390/diagnostics13182948
Awaji B, Senan EM, Olayah F, Alshari EA, Alsulami M, Abosaq HA, Alqahtani J, Janrao P. Hybrid Techniques of Facial Feature Image Analysis for Early Detection of Autism Spectrum Disorder Based on Combined CNN Features. Diagnostics. 2023; 13(18):2948. https://doi.org/10.3390/diagnostics13182948
Chicago/Turabian StyleAwaji, Bakri, Ebrahim Mohammed Senan, Fekry Olayah, Eman A. Alshari, Mohammad Alsulami, Hamad Ali Abosaq, Jarallah Alqahtani, and Prachi Janrao. 2023. "Hybrid Techniques of Facial Feature Image Analysis for Early Detection of Autism Spectrum Disorder Based on Combined CNN Features" Diagnostics 13, no. 18: 2948. https://doi.org/10.3390/diagnostics13182948