

Hybrid Feature-Learning-Based PSO-PCA Feature Engineering Approach for Blood Cancer Classification


Abstract
:1. Introduction
- Introduction of a new hybrid feature engineering approach based on feature learning extraction and the integration of features generated by PCA and bio-inspired PSO feature selection algorithms for the multi-class classification of ALL in peripheral blood smear images;
- Incorporation of both feature optimization and Bayesian-based hyperparameter optimization in the introduced approach to boast the classification performance of ALL;
- Generation of several individually extracted feature sets by pre-trained CNN, PCA, PSO, and integrated PCA-PSO feature set;
- Comparison of the classification performance of optimized SVM and EL classifiers trained by the individual feature sets and the proposed hybrid feature set.
2. Dataset and Methods
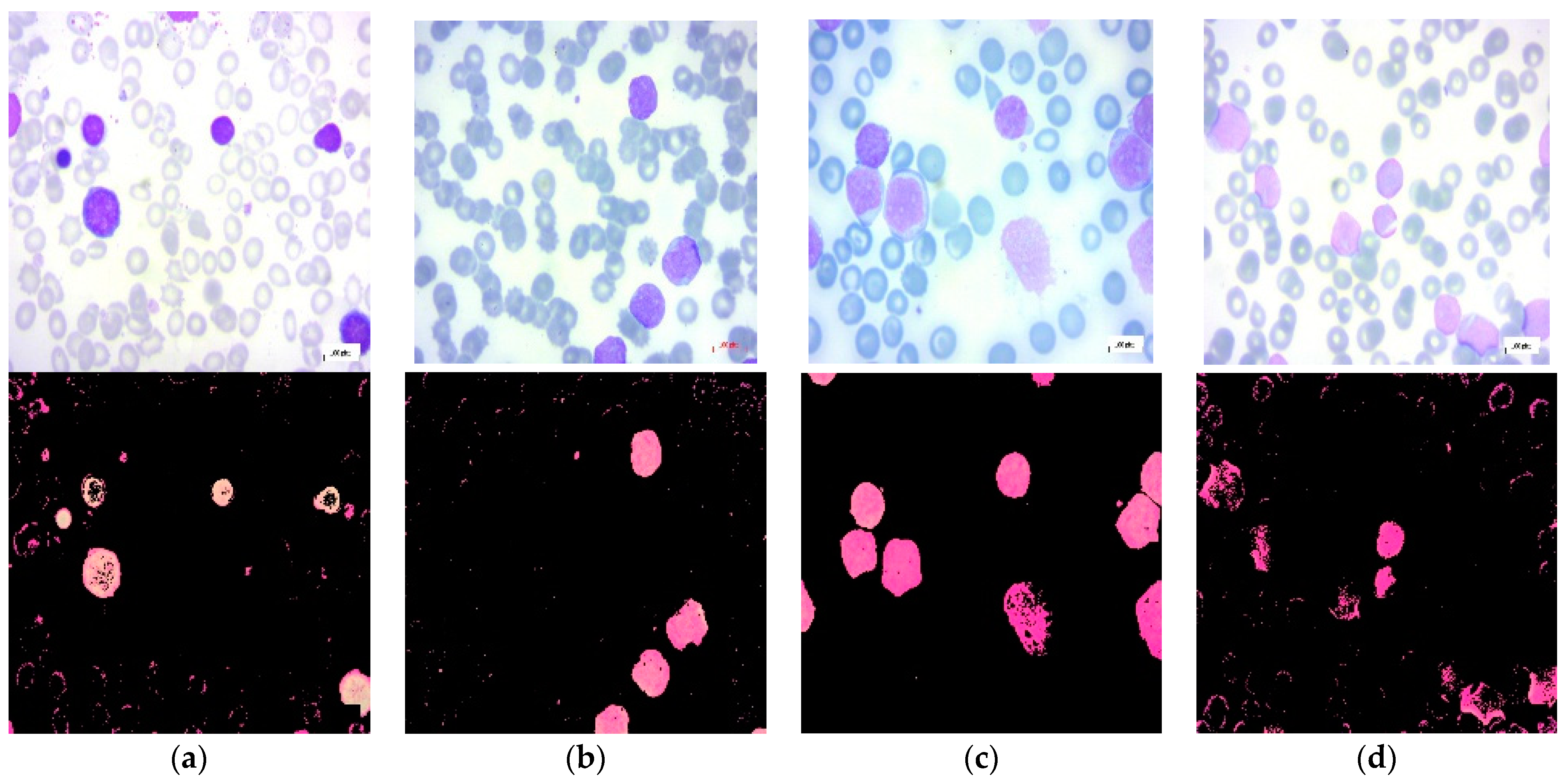
2.1. Dataset
2.2. Methods
2.2.1. Framework
2.2.2. Feature-Transfer-Based Extraction by GoogleNet
2.2.3. Principal Component Analysis
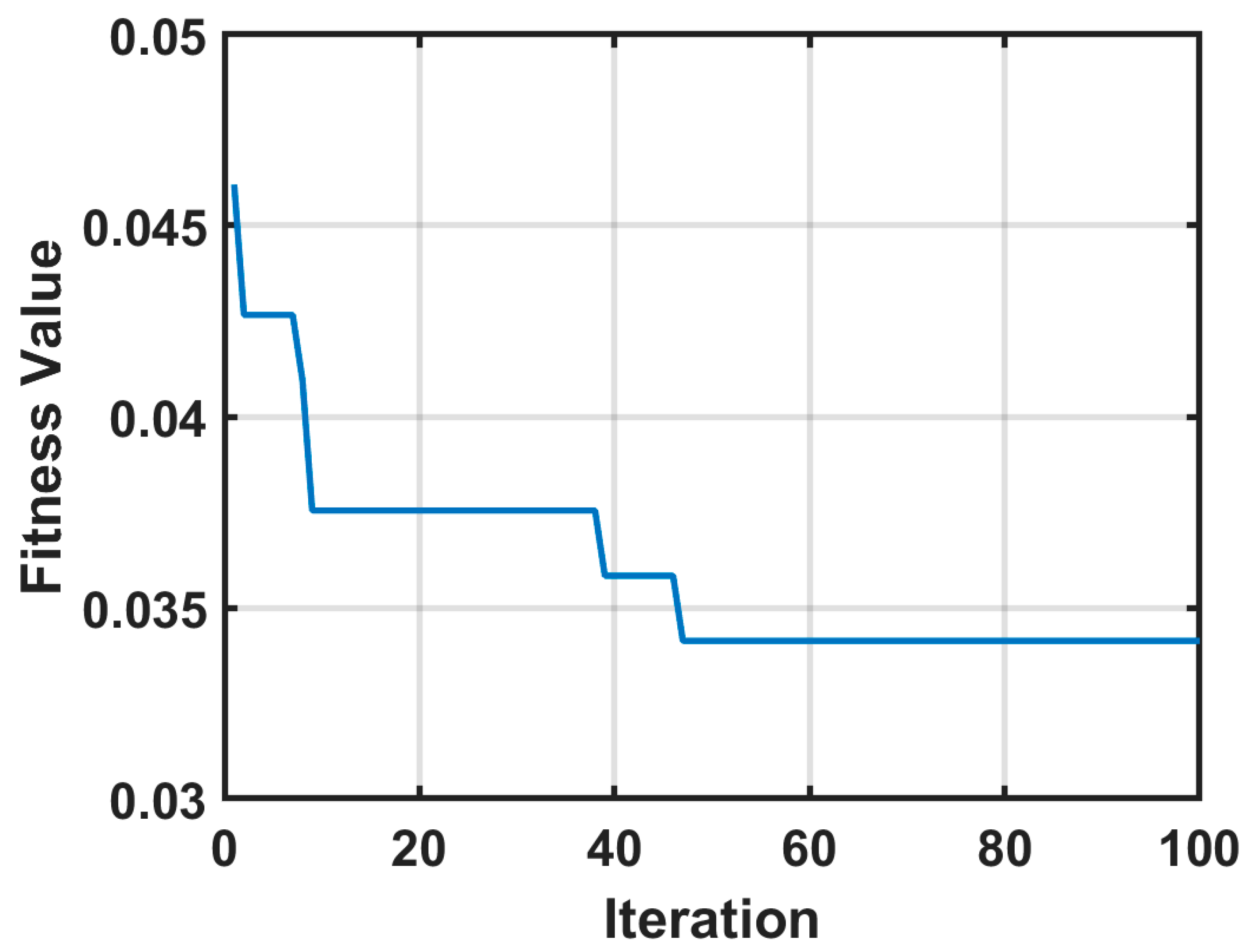
2.2.4. Particle Swarm Optimization for Feature Selection
2.2.5. Support Vector Machine (SVM)
2.2.6. Subspace Discriminant Ensemble-Learning Classification
2.2.7. Performance Metrics
3. Results and Discussion
4. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Sallam, N.M.; Saleh, A.I.; Arafat Ali, H.; Abdelsalam, M.M. An efficient EGWO algorithm as feature selection for B-ALL diagnoses and its subtypes classification using peripheral blood smear images. Alexandria Eng. J. 2023, 68, 39–66. [Google Scholar] [CrossRef]
- Rezayi, S.; Mohammadzadeh, N.; Bouraghi, H.; Saeedi, S.; Mohammadpour, A. Timely Diagnosis of Acute Lymphoblastic Leukemia Using Artificial Intelligence-Oriented Deep Learning Methods. Comput. Intell. Neurosci. 2021, 2021, 5478157. [Google Scholar] [CrossRef]
- Möckl, L.; Roy, A.R.; Moerner, W.E. Deep learning in single-molecule microscopy: Fundamentals, caveats, and recent developments [Invited]. Biomed. Opt. Express 2020, 11, 1633–1661. [Google Scholar] [CrossRef]
- Almadhor, A.; Sattar, U.; Al Hejaili, A.; Ghulam Mohammad, U.; Tariq, U.; Ben Chikha, H. An efficient computer vision-based approach for acute lymphoblastic leukemia prediction. Front. Comput. Neurosci. 2022, 16, 1083649. [Google Scholar] [CrossRef]
- Mustaqim, T.; Fatichah, C.; Suciati, N. Deep Learning for the Detection of Acute Lymphoblastic Leukemia Subtypes on Microscopic Images: A Systematic Literature Review. IEEE Access 2023, 11, 16108–16127. [Google Scholar] [CrossRef]
- Atteia, G.E. Latent Space Representational Learning of Deep Features for Acute Lymphoblastic Leukemia Diagnosis. Comput. Syst. Sci. Eng. 2022, 45, 361–376. [Google Scholar] [CrossRef]
- Abbas, N.; Mohamad, D.; Abdullah, A.H.; Saba, T.; Al-Rodhaan, M.; Al-Dhelaan, A. Report: Nuclei segmentation of leukocytes in blood smear digital images. Pak. J. Pharm. Sci. 2015, 28, 1801–1806. [Google Scholar]
- Rehman, A.; Abbas, N.; Saba, T.; Rahman, S.I.u.; Mehmood, Z.; Kolivand, H. Classification of acute lymphoblastic leukemia using deep learning. Microsc. Res. Tech. 2018, 81, 1310–1317. [Google Scholar] [CrossRef]
- Begum, A.R.J.; Razak, D.T.A. A Proposed Novel Method for Detection and Classification of Leukemia using Blood Microscopic Images. Int. J. Adv. Res. Comput. Sci. 2017, 8, 147–151. [Google Scholar]
- Mahmood, N.; Shahid, S.; Bakhshi, T.; Riaz, S.; Ghufran, H.; Yaqoob, M. Identification of significant risks in pediatric acute lymphoblastic leukemia (ALL) through machine learning (ML) approach. Med. Biol. Eng. Comput. 2020, 58, 2631–2640. [Google Scholar] [CrossRef]
- Bodzas, A.; Kodytek, P.; Zidek, J. Automated Detection of Acute Lymphoblastic Leukemia From Microscopic Images Based on Human Visual Perception. Front. Bioeng. Biotechnol. 2020, 8, 539332. [Google Scholar] [CrossRef]
- Sampathila, N.; Chadaga, K.; Goswami, N.; Chadaga, R.P.; Pandya, M.; Prabhu, S.; Bairy, M.G.; Katta, S.S.; Bhat, D.; Upadya, S.P. Customized Deep Learning Classifier for Detection of Acute Lymphoblastic Leukemia Using Blood Smear Images. Healthcare 2022, 10, 1812. [Google Scholar] [CrossRef]
- Ansari, S.; Navin, A.H.; Sangar, A.B.; Gharamaleki, J.V.; Danishvar, S. A Customized Efficient Deep Learning Model for the Diagnosis of Acute Leukemia Cells Based on Lymphocyte and Monocyte Images. Electronics 2023, 12, 322. [Google Scholar] [CrossRef]
- Saeed, A.; Shoukat, S.; Shehzad, K.; Ahmad, I.; Eshmawi, A.A.; Amin, A.H.; Tag-Eldin, E. A Deep Learning-Based Approach for the Diagnosis of Acute Lymphoblastic Leukemia. Electronics 2022, 11, 3168. [Google Scholar] [CrossRef]
- Mondal, C.; Hasan, M.K.; Ahmad, M.; Awal, M.A.; Jawad, M.T.; Dutta, A.; Islam, M.R.; Moni, M.A. Ensemble of Convolutional Neural Networks to diagnose Acute Lymphoblastic Leukemia from microscopic images. Inform. Med. Unlocked 2021, 27, 100794. [Google Scholar] [CrossRef]
- Rodrigues, L.F.; Backes, A.R.; Travençolo, B.A.N.; de Oliveira, G.M.B. Optimizing a Deep Residual Neural Network with Genetic Algorithm for Acute Lymphoblastic Leukemia Classification. J. Digit. Imaging 2022, 35, 623–637. [Google Scholar] [CrossRef]
- Ahmad, R.; Awais, M.; Kausar, N.; Akram, T. White Blood Cells Classification Using Entropy-Controlled Deep Features Optimization. Diagnostics 2023, 13, 352. [Google Scholar] [CrossRef]
- Agustin, R.I.; Arif, A.; Sukorini, U. Classification of immature white blood cells in acute lymphoblastic leukemia L1 using neural networks particle swarm optimization. Neural Comput. Appl. 2021, 33, 10869–10880. [Google Scholar] [CrossRef]
- Sahlol, A.T.; Abdeldaim, A.M.; Hassanien, A.E. Automatic acute lymphoblastic leukemia classification model using social spider optimization algorithm. Soft Comput. 2019, 23, 6345–6360. [Google Scholar] [CrossRef]
- Ghaderzadeh, M.; Aria, M.; Hosseini, A.; Asadi, F.; Bashash, D.; Abolghasemi, H. A fast and efficient CNN model for B-ALL diagnosis and its subtypes classification using peripheral blood smear images. Int. J. Intell. Syst. 2022, 37, 5113–5133. [Google Scholar] [CrossRef]
- Kaggle. Acute Lymphoblastic Leukemia (ALL) Image Dataset. Available online: https://www.kaggle.com/datasets/mehradaria/leukemia (accessed on 22 June 2023).
- Szegedy, C.; Liu, W.; Jia, Y.; Sermanet, P.; Reed, S.; Anguelov, D.; Erhan, D.; Vanhoucke, V.; Rabinovich, A.; Liu, W.; et al. Going deeper with convolutions. In Proceedings of the 2015 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Boston, MA, USA, 7–12 June 2015; pp. 1–9. [Google Scholar]
- Jolliffe, I.T.; Cadima, J. Principal component analysis: A review and recent developments. Philos. Trans. R. Soc. A Math. Phys. Eng. Sci. 2016, 374, 20150202. [Google Scholar] [CrossRef]
- Eberhart, R.; Kennedy, J. A new optimizer using particle swarm theory. In Proceedings of the Sixth International Symposium on Micro Machine and Human Science, Nagoya, Japan, 4–6 October 1995; pp. 39–43. [Google Scholar] [CrossRef]
- Xue, B.; Zhang, M.; Browne, W.N. Particle swarm optimisation for feature selection in classification: Novel initialisation and updating mechanisms. Appl. Soft Comput. 2014, 18, 261–276. [Google Scholar] [CrossRef]
- Xue, B.; Zhang, M.; Browne, W.N.; Yao, X. A Survey on Evolutionary Computation Approaches to Feature Selection. IEEE Trans. Evol. Comput. 2016, 20, 606–626. [Google Scholar] [CrossRef]
- Zhang, Y.; Wang, S.; Ji, G. A Comprehensive Survey on Particle Swarm Optimization Algorithm and Its Applications. Math. Probl. Eng. 2015, 2015, 931256. [Google Scholar] [CrossRef]
- Goodfellow, I.; Bengio, Y.; Courville, A. Deep Learning; Adaptive Computation and Machine Learning Series; The MIT Press: Cambridge, MA, USA, 2016; ISBN 0262035618. [Google Scholar]
- Atteia, G.; Alhussan, A.A.; Samee, N.A. BO-ALLCNN: Bayesian-Based Optimized CNN for Acute Lymphoblastic Leukemia Detection in Microscopic Blood Smear Images. Sensors 2022, 22, 5520. [Google Scholar] [CrossRef]
- Ho, T.K. The Random Subspace Method for Constructing Decision Forests. IEEE Trans. Pattern Anal. Mach. Intell. 1998, 20, 832–844. [Google Scholar] [CrossRef]
- Taner, A.; Mengstu, M.T.; Selvi, K.Ç.; Duran, H.; Kabaş, Ö.; Gür, İ.; Karaköse, T.; Gheorghiță, N.-E. Multiclass Apple Varieties Classification Using Machine Learning with Histogram of Oriented Gradient and Color Moments. Appl. Sci. 2023, 13, 7682. [Google Scholar] [CrossRef]
- Vakharia, V.; Shah, M.; Suthar, V.; Patel, V.K.; Solanki, A. Hybrid perovskites thin films morphology identification by adapting multiscale-SinGAN architecture, heat transfer search optimized feature selection and machine learning algorithms. Phys. Scr. 2023, 98, 025203. [Google Scholar] [CrossRef]
- Abdeldaim, A.M.; Sahlol, A.T.; Elhoseny, M.; Hassanien, A.E. Computer-Aided Acute Lymphoblastic Leukemia Diagnosis System Based on Image Analysis. Stud. Comput. Intell. 2018, 730, 131–147. [Google Scholar] [CrossRef]
- Praveena, S.; Singh, S.P. Sparse-FCM and Deep Convolutional Neural Network for the segmentation and classification of acute lymphoblastic leukaemia. Biomed. Tech. 2020, 65, 759–773. [Google Scholar] [CrossRef]
- Hamza, M.A.; Albraikan, A.A.; Alzahrani, J.S.; Dhahbi, S.; Al-Turaiki, I.; Al Duhayyim, M.; Yaseen, I.; Eldesouki, M.I. Optimal Deep Transfer Learning-Based Human-Centric Biomedical Diagnosis for Acute Lymphoblastic Leukemia Detection. Comput. Intell. Neurosci. 2022, 2022, 7954111. [Google Scholar] [CrossRef] [PubMed]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Experiment | Feature Engineering Approach | Kernel Scale | Kernel Function | Box Constrain | Classification Error |
|---|---|---|---|---|---|
| Experiment 1 | Feature Transfer (GoogleNet) | 1 | Quadratic | 0.2856 | 0.0296 |
| Experiment 2 | PCA | 1 | Quadratic | 977.59 | 0.031 |
| Experiment 3 | PSO | 1 | Quadratic | 0.001017 | 0.033 |
| Experiment 4 | Integration of PCA and PSO Features | 1 | Quadratic | 981.0134 | 0.0289 |
| Experiment | Feature Engineering Approach | Feature Set Name | # Features | SVM AC% | SDEL AC% |
|---|---|---|---|---|---|
| Experiment 1 | Feature Transfer (GoogleNet) | FTF | 1024 | 97 | 96.5 |
| Experiment 2 | PCA | HPCF | 94 | 96.9 | 95.4 |
| Experiment 3 | PSO | PSOF | 524 | 96.7 | 96.5 |
| Experiment 4 | Integration of PCA and PSO Features | HFS | 618 | 97.4 | 96.8 |
| Class | SVM | SDEL | ||
|---|---|---|---|---|
| S% | SP% | S% | SP% | |
| Benign | 94.1 | 98.9 | 94.1 | 98.9 |
| Early | 97.4 | 98.8 | 96.7 | 98.6 |
| Pre-B | 97.7 | 98.6 | 96.8 | 98.6 |
| Pro-B | 99.0 | 99.8 | 98.8 | 99.6 |
| Feature Engineering Approach | Classifier | Optimization | AC% | Publication |
|---|---|---|---|---|
| Feature extraction: VGGNet. Features selection: salp swarm optimization. | KNN, SVM, decision tree, naive Bayes | Salp Swarm Optimization | 96.1 | [33] |
| Feature extraction: Hand-crafted features from input images. Features selection: social spider optimization. | Ensemble of classical ML classifiers | Social Spider Optimization | 95.2 | [19] |
| Feature extraction: customized CNN. Features selection: grey-wolf-based Jaya optimization. | Customized CNN | Grey-wolf-based Jaya Optimization | 93.5 | [34] |
| Feature extraction: pre-trained CNNs. Features selection: competitive swarm optimization. | ABiLSTM | Competitive Swarm Optimization | 96 | [35] |
| Feature extraction: GoogleNet. Features selection: hybrid PSO-PCA approach. | Bayesian-optimized SVM | Hybrid PSO-PCA approach | 97.4 | Proposed study |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Atteia, G.; Alnashwan, R.; Hassan, M. Hybrid Feature-Learning-Based PSO-PCA Feature Engineering Approach for Blood Cancer Classification. Diagnostics 2023, 13, 2672. https://doi.org/10.3390/diagnostics13162672
Atteia G, Alnashwan R, Hassan M. Hybrid Feature-Learning-Based PSO-PCA Feature Engineering Approach for Blood Cancer Classification. Diagnostics. 2023; 13(16):2672. https://doi.org/10.3390/diagnostics13162672
Chicago/Turabian StyleAtteia, Ghada, Rana Alnashwan, and Malak Hassan. 2023. "Hybrid Feature-Learning-Based PSO-PCA Feature Engineering Approach for Blood Cancer Classification" Diagnostics 13, no. 16: 2672. https://doi.org/10.3390/diagnostics13162672