
Detection of Diabetes through Microarray Genes with Enhancement of Classifiers Performance



Abstract
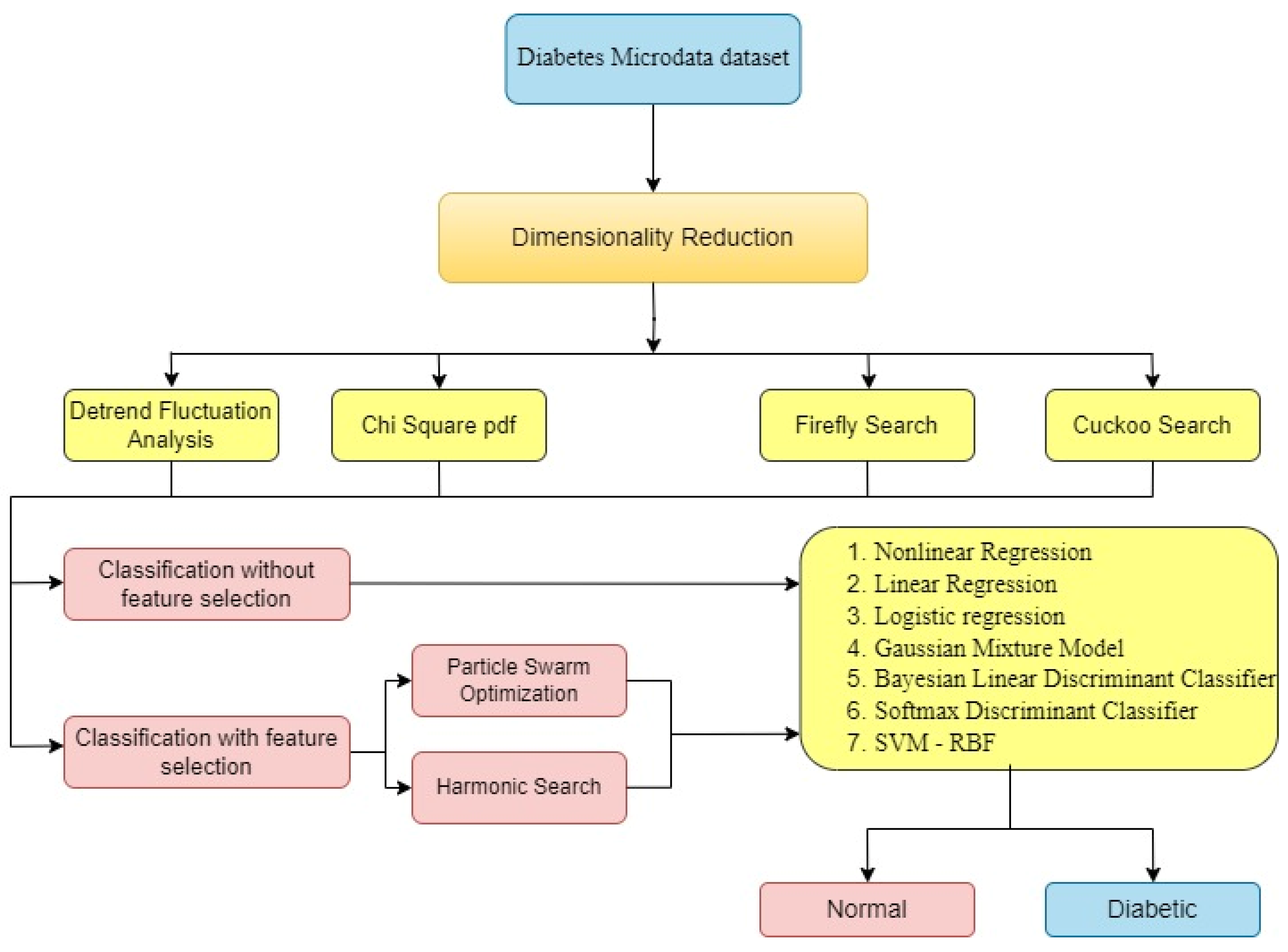
:1. Introduction
2. Literature Review
3. Material and Methods
Data Set
4. Dimensionality Reduction
- A.
- Detrend Fluctuation Analysis (DFA)
- B.
- Chi Square Probability Density Function
- C.
- Firefly algorithm As Dimensionality Reduction
- An attraction is made to another fly regardless of the sex because every fly is considered as unisex;
- “Opposite poles attract,” the attractiveness one of the fireflies is higher to another one which is slightly less bright. If none of the flies are getting brighter, it moves randomly on the surface;
- If the distance increases, the brightness or light intensity of a firefly may decrease because the medium of air absorbs light and, thus, the brightness of a firefly k which is seem by another firefly is given by:
- D.
- Cuckoo Search Algorithm as Dimensionality Reduction
- Cuckoo’s lay an egg at a time, and are kept inside an arbitrarily selected shell;
- To create a consecutive generation, the best host shell with a good quality egg is selected to transfer its own.
- A fixed no. of host nests is accessible. Indeed, cuckoo’s place an egg in a nest with a probability of ; where is Cuckoo egg probability. To construct a new nest in an additional location, the host can demolish the cuckoo eggs, or remove the nest
Statistical Analysis
5. Feature Selection
5.1. Particle Swarm Optimization (PSO)
- Step 1: Initialization of the process;
- Step 2: For each particle, the dimension of a space is denoted as h;
- Step 3: Initialization of the particle position as and velocity as ;
- Step 4: Evaluate the fitness function;
- Step 5: Initialize the with a copy of ;
- Step 6: Initialize the with a copy of with the best fitness function;
- Step 7: Repeat the steps until the stopping criteria are satisfied.
5.2. Harmonic Search (HS)
- Step 1: Initialization
- Step 2: Memory Initialization
- Step 3: New Harmony Development
- Memory consideration;
- Pitch adjustment;
- Random selection.
- Step 4: Harmony memory updation
- Step 5: Stopping criteria
- (i)
- Formulate the null hypothesis;
- (ii)
- Compute the p-value t-test;
- (iii)
- Check for the significance of p-value < 0.01, then the null hypothesis is accepted or otherwise rejected.
6. Classification Techniques
- Non-Linear regression
- Parameter initialization;
- Curves value produced by the initial values;
- To minimize the MSE value, calculate the parameters iteratively and modify the same to get the curve to be close to the nearer value;
- If the MSE value has not changed when compared to the previous value, the process must stop.
- 2.
- Linear regression
- The features selection parameters based on the DFA, Chi2Pdf, Firefly, and Cuckoo search algorithms is input to the classifiers;
- Fit a line that splits the data in a linear method;
- To minimize the observed data for prediction and to define the cost function for computes, the total squared error value is obtained;
- Find the solutions by equating to zero for computing the derivate for ;
- Repeat the steps 2, 3, and 4 to get the coefficients that give the minimum squared error.
- 3.
- Logistic Regression
- 4.
- Gaussian Mixture Model (GMM)
- 5.
- Bayesian Linear Discriminant Classifier (BLDC)
- 6.
- Softmax Discriminant Classifier (SDC)
- 7.
- Support Vector Machine– Radial Basis Function (SVM–RBF)
- Steps for the SVM is to identify
7. Training and Testing of Classifiers
Selection of Target
8. Results and Discussion
8.1. Performance Metrics
- Accuracy
- 2.
- Recall
- 3.
- Precision
- 4.
- F1 Score
- 5.
- Matthews Correlation Coefficient (MCC)
- 6.
- Error Rate
- 7.
- Jaccard Metric:
- 8.
- Kappa
8.2. Computational Complexity
8.3. Comparison of Previous Works
9. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Kumar, D.; Ashok, R. Govindasamy. Performance and evaluation of classification data mining techniques in diabetes. Int. J. Comput. Sci. Inf. Technol. 2015, 6, 1312–1319. [Google Scholar]
- Lam, A.A.; Lepe, A.; Wild, S.H.; Jackson, C. Diabetes comorbidities in low-and middle-income countries: An umbrella review. J. Glob. Health 2021, 11, 04040. [Google Scholar] [CrossRef]
- Mohsen, F.; Safieh, H.; Shibani, M.; Ismail, H.; Alzabibi, M.A.; Armashi, H.; Sawaf, B. Assessing diabetes mellitus knowledge among Syrian medical students: A cross-sectional study. Heliyon 2021, 7, e08079. [Google Scholar] [CrossRef]
- Nakrani, M.N.; Wineland, R.H.; Anjum, F. Physiology, Glucose Metabolism. In StatPearls; StatPearls Publishing: Treasure Island, FL, USA, 2023. Available online: https://www.ncbi.nlm.nih.gov/books/NBK560599/ (accessed on 20 August 2021).
- WHO. Diabetes—India; World Health Organization: Geneve, Switzerland; Available online: https://www.who.int/india/health-topics/mobile-technology-for-preventing-ncds (accessed on 13 November 2021).
- Krishnamoorthy, Y.; Rajaa, S.; Murali, S.; Rehman, T.; Sahoo, J.; Kar, S.S. Prevalence of metabolic syndrome among adult population in India: A systematic review and meta-analysis. PLoS ONE 2020, 15, e0240971. [Google Scholar] [CrossRef]
- Sahu, G.; Gohain, S.; Brahma, A. Drug utilization pattern of antidiabetic drugs among indoor diabetic patients in a tertiary care teaching hospital, Jorhat. Biomedicine 2020, 40, 512–515. [Google Scholar] [CrossRef]
- NCD Risk Factor Collaboration. Worldwide trends in diabetes since 1980: A pooled analysis of 751 population-based studies with 4·4 million participants. Lancet 2016, 387, 1513–1530. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Available online: https://www.niddk.nih.gov/health-information/diabetes/overview/what-is-diabetes/type-2-diabetes (accessed on 20 August 2021).
- Deshpande, A.D.; Harris-Hayes, M.; Schootman, M. Epidemiology of diabetes and diabetes-related complications. Phys. Ther. 2008, 88, 1254–1264. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Tonyan, Z.N.; Nasykhova, Y.A.; Danilova, M.M.; Barbitoff, Y.A.; Changalidi, A.I.; Mikhailova, A.A.; Glotov, A.S. Overview of Transcriptomic Research on Type 2 Diabetes: Challenges and Perspectives. Genes 2022, 13, 1176. [Google Scholar] [CrossRef]
- Kavakiotis, I.; Tsave, O.; Salifoglou, A.; Maglaveras, N.; Vlahavas, I.; Chouvarda, I. Machine learning and data mining methods in diabetes research. Comput. Struct. Biotechnol. J. 2017, 15, 104–116. [Google Scholar] [CrossRef] [PubMed]
- Davidson, K.W.; Barry, M.J.; Mangione, C.M.; Cabana, M.; Caughey, A.B.; Davis, E.M.; Donahue, K.E.; Doubeni, C.A.; Krist, A.H.; Kubik, M.; et al. Screening for prediabetes and type 2 diabetes: US Preventive Services Task Force recommendation statement. Jama 2021, 326, 736–743. [Google Scholar] [PubMed]
- Shaw, J.E.; Sicree, R.A.; Zimmet, P.Z. Global estimates of the prevalence of diabetes for 2010 and 2030. Diabetes Res. Clin. Pract. 2010, 87, 4–14. [Google Scholar] [CrossRef] [PubMed]
- Mohan, V.; Pradeepa, R. Epidemiology of type 2 diabetes in India. Indian J. Ophthalmol. 2021, 69, 2932. [Google Scholar] [CrossRef] [PubMed]
- Abdulkareem, S.A.; Radhi, H.Y.; Fadil, Y.A.; Mahdi, H. Soft computing techniques for early diabetes prediction. Indones. J. Electr. Eng. Comput. Sci. 2022, 25, 1167–1176. [Google Scholar] [CrossRef]
- Mujumdar, A.; Vaidehi, V. Diabetes prediction using machine learning algorithms. Procedia Comput. Sci. 2019, 165, 292–299. [Google Scholar] [CrossRef]
- Bhaskaran, K.; Unnikrishnan, R.; Deepa, S. Prediction of diabetes using machine learning techniques. Int. J. Eng. Res. Technol. 2017, 6, 232–237. [Google Scholar]
- Llaha, O.; Rista, A. Prediction and Detection of Diabetes using Machine Learning. In Proceedings of the 20th International Conference on Real-Time Applications in Computer Science and Information Technology (RTA-CSIT), Tirana, Albania, 21–22 May 2021; pp. 94–102. [Google Scholar]
- Ahamed, B.S.; Arya, M.S.; Sangeetha, S.K.B.; Osvin, N.V.A. Diabetes Mellitus Disease Prediction and Type Classification Involving Predictive Modeling Using Machine Learning Techniques and Classifiers. Appl. Comput. Intell. Soft Comput. 2022, 2022, 7899364. [Google Scholar] [CrossRef]
- Tigga, N.P.; Garg, S. Prediction of type 2 diabetes using machine learning classification methods. Procedia Comput. Sci. 2020, 167, 706–716. [Google Scholar] [CrossRef]
- Maniruzzaman; Kumar, N.; Abedin, M.; Islam, S.; Suri, H.S.; El-Baz, A.S.; Suri, J.S. Comparative approaches for classification of diabetes mellitus data: Machine learning paradigm. Comput. Methods Programs Biomed. 2017, 152, 23–34. [Google Scholar] [CrossRef]
- Gupta, S.K.; Singh, Z.; Purty, A.J.; Kar, M.; Vedapriya, D.R.; Mahajan, P.; Cherian, J. Diabetes prevalence and its risk factors in rural area of Tamil Nadu. Indian J. Community Med. Off. Publ. Indian Assoc. Prev. Soc. Med. 2010, 35, 396. [Google Scholar] [CrossRef]
- Howlader, K.C.; Satu, S.; Awal, A.; Islam, R.; Islam, S.M.S.; Quinn, J.M.W.; Moni, M.A. Machine learning models for classification and identification of significant attributes to detect type 2 diabetes. Health Inf. Sci. Syst. 2022, 10, 2. [Google Scholar] [CrossRef]
- Sisodia, D.; Sisodia, D.S. Prediction of diabetes using classification algorithms. Procedia Comput. Sci. 2018, 132, 1578–1585. [Google Scholar] [CrossRef]
- Mathur, P.; Leburu, S.; Kulothungan, V. Prevalence, awareness, treatment and control of diabetes in India from the countrywide National NCD Monitoring Survey. Front. Public Health 2022, 10, 205. [Google Scholar] [CrossRef] [PubMed]
- Kazerouni, F.; Bayani, A.; Asadi, F.; Saeidi, L.; Parvizi, N.; Mansoori, Z. Type2 diabetes mellitus prediction using data mining algorithms based on the long-noncoding RNAs expression: A comparison of four data mining approaches. BMC Bioinform. 2020, 21, 372. [Google Scholar] [CrossRef]
- Lawi, A.; Syarif, S. Performance evaluation of naive Bayes and support vector machine in type 2 diabetes Mellitus gene expression microarray data. J. Phys. Conf. Ser. 2019, 1341, 042018. [Google Scholar]
- Berthouze, L.; Farmer, S.F. Adaptive time-varying detrended fluctuation analysis. J. Neurosci. Methods 2012, 209, 178–188. [Google Scholar] [CrossRef]
- Alifah; Siswantining, T.; Sarwinda, D.; Bustamam, A. RFE and Chi-Square Based Feature Selection Approach for Detection of Diabetic Retinopathy. In Proceedings of the International Joint Conference on Science and Engineering (IJCSE 2020), Surabaya, Indonesia, 3 October 2020; Atlantis Press: Amsterdam, The Netherland, 2020. [Google Scholar]
- Yang, X.-S. Firefly algorithm, Levy flights and global optimization. In Research and Development in Intelligent Systems XXVI: Incorporating Applications and Innovations in Intelligent Systems XVII.; Springer: London, UK, 2010. [Google Scholar]
- Yang, X.S.; He, X. Firefly algorithm: Recent advances and applications. arXiv 2013, arXiv:1308.3898. [Google Scholar] [CrossRef] [Green Version]
- Yang, X.S.; Deb, S. Cuckoo search via Lévy flights. In Proceedings of the 2009 World Congress on Nature & Biologically Inspired Computing (NaBIC), Coimbatore, India, 9–11 December 2009; pp. 210–214. [Google Scholar]
- Gandomi, A.H.; Yang, X.S.; Alavi, A.H. Cuckoo search algorithm: A metaheuristic approach to solve structural optimization problems. Eng. Comput. 2013, 29, 17–35. [Google Scholar] [CrossRef]
- Rajaguru, H.; Prabhakar, S.K.; Manjusha, M. Performance Analysis of Original Particle Swarm Optimization and Modified PSO Technique for Robust Classification of Epilepsy Risk level from EEG Signals. Int. J. Pharm. Technol. 2016, 8, 18273–18283. [Google Scholar]
- Bharanidharan, N.; Rajaguru, H. Classification of dementia using harmony search optimization technique. In Proceedings of the 2018 IEEE Region 10 Humanitarian Technology Conference (R10-HTC), Malambe, Sri Lanka, 6–8 December 2018. [Google Scholar]
- Zhang, G.; Allaire, D.; Cagan, J. Reducing the Search Space for Global Minimum: A Focused Regions Identification Method for Least Squares Parameter Estimation in Nonlinear Models. J. Comput. Inf. Sci. Eng. 2023, 23, 021006. [Google Scholar] [CrossRef]
- Draper, N.R.; Smith, H. Applied Regression Analysis; John Wiley & Sons: Hoboken, NJ, USA, 1998; Volume 326. [Google Scholar]
- Hamid, I.Y. Prediction of Type 2 Diabetes through Risk Factors using Binary Logistic Regression. J. Al-Qadisiyah Comput. Sci. Math. 2020, 12, 1. [Google Scholar]
- Adiwijaya, K.; Wisesty, U.N.; Lisnawati, E.; Aditsania, A.; Kusumo, D.S. Dimensionality reduction using principal component analysis for cancer detection based on microarray data classification. J. Comput. Sci. 2018, 14, 1521–1530. [Google Scholar] [CrossRef] [Green Version]
- Prabhakar, S.K.; Rajaguru, H.; Lee, S.-W. A comprehensive analysis of alcoholic EEG signals with detrend fluctuation analysis and post classifiers. In Proceedings of the 2019 7th International Winter Conference on Brain-Computer Interface (BCI), Gangwon, Republic of Korea, 18–20 February 2019. [Google Scholar]
- Zhou, W.; Liu, Y.; Yuan, Q.; Li, X. Epileptic seizure detection using lacunarity and Bayesian linear discriminant analysis in intracranial EEG. IEEE Trans. Biomed. Eng. 2013, 60, 3375–3381. [Google Scholar] [CrossRef] [PubMed]
- Zang, F.; Zhang, J.S. Softmax Discriminant Classifier. In Proceedings of the 3rd International Conference on Multimedia Information Networking and Security, Shanghai, China, 4–6 November 2011; pp. 16–20. [Google Scholar]
- Yao, X.; Panaye, A.; Doucet, J.; Chen, H.; Zhang, R.; Fan, B.; Liu, M.; Hu, Z. Comparative classification study of toxicity mechanisms using support vector machines and radial basis function neural networks. Anal. Chim. Acta 2005, 535, 259–273. [Google Scholar] [CrossRef]
- Fushiki, T. Estimation of prediction error by using K-fold cross-validation. Stat. Comput. 2011, 21, 137–146. [Google Scholar] [CrossRef]
- Fawcett, T. An introduction to ROC analysis. Pattern Recognit. Lett. 2006, 27, 861–874. [Google Scholar] [CrossRef]
- Saito, M.; Yamanaka, S. Performance evaluation of least-squares probabilistic classifier for corporate credit rating classification problem. JSIAM Lett. 2021, 13, 9–12. [Google Scholar] [CrossRef]
- Chicco, D.; Jurman, G. An invitation to greater use of Matthews correlation coefficient (MCC) in robotics and artificial intelligence. Front. Robot. AI 2022, 78, 876814. [Google Scholar] [CrossRef]
- Hart, P.E.; Stork, D.G.; Duda, R.O. Pattern Classification; John Wiley & Sons: Hoboken, NJ, USA, 2006. [Google Scholar]
- Tharwat, A. Classification assessment methods. Appl. Comput. Inform. 2020, 17, 168–192. [Google Scholar] [CrossRef]
- Kvålseth, T.O. Note on Cohen’s kappa. Psychol. Rep. 1989, 65, 223–226. [Google Scholar] [CrossRef]
- Kumar, P.S.; Pranavi, S. Performance analysis of machine learning algorithms on diabetes dataset using big data analytics. In Proceedings of the 2017 International Conference on Infocom Technologies and Unmanned Systems (Trends and Future directions) (ICTUS), Venue, Amity, 18–20 December 2017. [Google Scholar] [CrossRef]
- Olivera, A.R.; Roesler, V.; Iochpe, C.; Schmidt, M.I.; Vigo, A.; Barreto, S.M.; Duncan, B.B. Comparison of machine-learning algorithms to build a predictive model for detecting undiagnosed diabetes-ELSA-Brasil: Accuracy study. Sao Paulo Med. J. 2017, 135, 234–246. [Google Scholar] [CrossRef] [Green Version]
- Alghamdi, M.; Al-Mallah, M.; Keteyian, S.; Brawner, C.; Ehrman, J.; Sakr, S. Predicting diabetes mellitus using smote and ensemble machine learning approach: The henry ford exercise testing (ft) project. PLoS ONE 2017, 12, e0179805. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Xie, J.; Liu, Y.; Zeng, X.; Zhang, W.; Mei, Z. A Bayesian network model for predicting type 2 diabetes risk based on electronic health records. Mod. Phys Lett B. 2017, 31, 1740055. [Google Scholar] [CrossRef] [Green Version]
- Sarwar, M.A.; Kamal, N.; Hamid, W.; Shah, M.A. Prediction of diabetes using machine learning algorithms in healthcare. In Proceedings of the 2018 24th International Conference on Automation and Computing (ICAC), Tyne, UK, 6–7 September 2018. [Google Scholar] [CrossRef]
- Zou, Q.; Qu, K.; Luo, Y.; Yin, D.; Ju, Y.; Tang, H. Predicting diabetes mellitus with machine learning techniques. Front. Genet. 2018, 9, 515. [Google Scholar] [CrossRef]
- Perveen, S.; Shahbaz, M.; Keshavjee, K.; Guergachi, A. Metabolic syndrome and development of diabetes mellitus: Predictive modeling based on machine learning techniques. IEEE Access 2019, 7, 1365–1375. [Google Scholar] [CrossRef]
- Yuvaraj, N.; Sripreethaa, K.R. Diabetes prediction in healthcare systems using machine learning algorithms on Hadoop cluster. Clust. Comput. 2017, 22, 1365–1375. [Google Scholar] [CrossRef]
- Jakka, A.; Jakka, V.R. Performance evaluation of machine learning models for diabetes prediction. Int. J. Innov. Technol. Explor. Eng Regul. Issue 2019, 8, 1976–1980. [Google Scholar] [CrossRef]
- Radja, M.; Emanuel, A.W.R. Performance evaluation of supervised machine learning algorithms using different data set sizes for diabetes prediction. In Proceedings of the 2019 5th International Conference on Science in Information Technology (ICSITech), Jogjakarta, Indonesia, 23–24 October 2019. [Google Scholar] [CrossRef]
- Xiong, X.-L.; Zhang, R.-X.; Bi, Y.; Zhou, W.-H.; Yu, Y.; Zhu, D.-L. Machine learning models in type 2 diabetes risk prediction: Results from a cross-sectional retrospective study in Chinese adults. Curr. Med. Sci. 2019, 39, 582–588. [Google Scholar] [CrossRef]
- Dinh, A.; Miertschin, S.; Young, A.; Mohanty, S.D. A data-driven approach to predicting diabetes and cardiovascular disease with machine learning. BMC Med. Inform. Decis. Mak. 2019, 19, 211. [Google Scholar] [CrossRef] [Green Version]
- Yang, T.; Zhang, L.; Yi, L.; Feng, H.; Li, S.; Chen, H.; Zhu, J.; Zhao, J.; Zeng, Y.; Liu, H. Ensemble learning models based on noninvasive features for type 2 diabetes screening: Model development and validation. JMIR Med. Inform. 2020, 8, e15431. [Google Scholar] [CrossRef]
- Muhammad, L.J.; Algehyne, E.A.; Usman, S.S. Predictive supervised machine learning models for diabetes mellitus. SN Comput. Sci. 2020, 1, 240. [Google Scholar] [CrossRef]
- Lam, B.; Catt, M.; Cassidy, S.; Bacardit, J.; Darke, P.; Butterfeld, S.; Alshabrawy, O.; Trenell, M.; Missier, P. Using wearable activity trackers to predict type 2 diabetes: Machine learning-based cross-sectional study of the UK biobank accelerometer cohort. JMIR Diabetes 2021, 6, 23364. [Google Scholar] [CrossRef]
- De Silva, K.; Lim, S.; Mousa, A.; Teede, H.; Forbes, A.; Demmer, R.T.; Jonsson, D.; Enticott, J. Nutritional markers of undiagnosed type 2 diabetes in adults: Findings of a machine learning analysis with external validation and benchmarking. PLoS ONE 2021, 16, e0250832. [Google Scholar] [CrossRef]
- Kim, H.; Lim, D.H.; Kim, Y. Classification and prediction on the effects of nutritional intake on overweight/obesity, dyslipidemia, hypertension and type 2 diabetes mellitus using deep learning model: 4–7th Korea national health and nutrition examination survey. Int. J. Environ. Res. Public Health 2021, 18, 5597. [Google Scholar] [CrossRef]
- Ramesh, J.; Aburukba, R.; Sagahyroon, A. A remote healthcare monitoring framework for diabetes prediction using machine learning. Healthc. Technol. Lett. 2021, 8, 45–57. [Google Scholar] [CrossRef]
- Phongying, M.; Hiriote, S. Diabetes Classification Using Machine Learning Techniques. Computation 2023, 11, 96. [Google Scholar] [CrossRef]
- Changpetch, P.; Pitpeng, A.; Hiriote, S.; Yuangyai, C. Integrating Data Mining Techniques for Naïve Bayes Classification: Applications to Medical Datasets. Computation 2021, 9, 99. [Google Scholar] [CrossRef]
- Kumari, S.; Kumar, D.; Mittal, M. An ensemble approach for classification and prediction of diabetes mellitus using soft voting classifier. Int. J. Cogn. Comput. Eng. 2021, 2, 40–46. [Google Scholar] [CrossRef]
- Yang, H.; Luo, Y.; Ren, X.; Wu, M.; He, X.; Peng, B.; Deng, K.; Yan, D.; Tang, H.; Lin, H. Risk prediction of diabetes: Big data mining with fusion of multifarious physical examination indicators. Inf. Fusion 2021, 75, 140–149. [Google Scholar] [CrossRef]
- Haq, A.U.; Li, J.P.; Khan, J.; Memon, M.H.; Nazir, S.; Ahmad, S.; Khan, G.A.; Ali, A. Intelligent machine learning approach for effective recognition of diabetes in E-healthcare using clinical data. Sensors 2020, 20, 2649. [Google Scholar] [CrossRef] [PubMed]













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Data Set | No of Genes | Class 1 Diabetes | Class 2 Non-Diabetic | Total |
|---|---|---|---|---|
| Pancreas | 28735 | 20 | 50 | 70 |
| Statistical Parameters | DFA | Chi2pdf | Firefly Algorithm | Cuckoo Search | ||||
|---|---|---|---|---|---|---|---|---|
| DP | NDP | DP | NDP | DP | NDP | DP | NDP | |
| Mean | 1.6302 | 1.6301 | 0.0690 | 0.0691 | 1.0278 | 0.1260 | 8.7158 | 12.6033 |
| Variance | 0.1614 | 0.1665 | 0.0007 | 0.0008 | 0.0004 | 1.45 × 10−9 | 48.4751 | 71.7672 |
| Skewness | 0.2319 | 0.2758 | −0.2771 | −0.3228 | 1.6527 | 4.0298 | 0.6087 | 0.2692 |
| Kurtosis | 0.2706 | 0.1600 | 0.0301 | 0.0096 | 3.1033 | 78.3911 | −1.1233 | −1.3759 |
| Pearson CC | 0.9516 | 0.9598 | 0.9781 | 0.9814 | 0.8803 | 0.5006 | 0.7048 | 0.6859 |
| CCA | 0.05914 | 0.06411 | 0.04785 | 0.05107 | ||||
| Feature Selection | DR Techniques | DFA | Chi Square pdf | Firefly Algorithm | Cuckoo Search | ||||
|---|---|---|---|---|---|---|---|---|---|
| Class | DP | NDP | DP | NDP | DP | NDP | DP | NDP | |
| PSO | p value < 0.05 | 0.415 | 0.1906 | 0.3877 | 0.16074 | 0.38059 | 0.2435 | 0.4740 | 0.48824 |
| Harmonic Search | p value < 0.05 | 0.0004 | 0.4290 | 0.3836 | 0.43655 | 0.00031 | 0.469 | 0.3488 | 0.3979 |
| Truth of Clinical Situation | Predicted Values | ||
|---|---|---|---|
| Diabetic | Non-Diabetic | ||
| Actual Values | Diabetic | TP | FN |
| Non-Diabetic | FP | TN | |
| Classifiers | With DFA DR Method | With Chi2 pdf DR Method | With Firefly Algorithm DR Method | With Cuckoo Search DR Method | ||||
|---|---|---|---|---|---|---|---|---|
| Training MSE | Testing MSE | Training MSE | Testing MSE | Training MSE | Testing MSE | Training MSE | Testing MSE | |
| NLR | 7.92 × 10−5 | 1.633 × 10−4 | 9.8 × 10−5 | 5.439 × 10−5 | 6.56 × 10−5 | 2.9 × 10−4 | 2.81 × 10−5 | 1.45 × 10−4 |
| Linear Reg | 4.62 × 10−5 | 8.936 × 10−5 | 6.08 × 10−5 | 1.945 × 10−4 | 5.48 × 10−5 | 3.566 × 10−4 | 9.22 × 10−5 | 1.35 × 10−4 |
| Logistic Regression | 2.6 × 10−5 | 1.325 × 10−4 | 2.21 × 10−5 | 1.565 × 10−4 | 8.84 × 10−5 | 4.625 × 10−4 | 9.8 × 10−5 | 1.685 × 10−4 |
| GMM | 1.52 × 10−5 | 1.21 × 10−4 | 7.06 × 10−5 | 1.662 × 10−4 | 7.92 × 10−5 | 2.442 × 10−4 | 3.42 × 10−5 | 1.103 × 10−4 |
| BDLC | 1.82 × 10−6 | 6.978 × 10−5 | 8.46 × 10−5 | 2.492 × 10−4 | 4.49 × 10−5 | 2.136 × 10−4 | 1.44 × 10−5 | 7.161 × 10−5 |
| SDC | 2.72 × 10−5 | 1.567 × 10−4 | 1.21 × 10−5 | 1.095 × 10−4 | 4.22 × 10−5 | 3.081 × 10−4 | 1.21 × 10−5 | 1.04 × 10−4 |
| SVM (RBF) | 1.96 × 10−5 | 1.656 × 10−4 | 4.62 × 10−5 | 1.454 × 10−4 | 3.48 × 10−5 | 1.924 × 10−4 | 1.26 × 10−8 | 5.141 × 10−6 |
| Classifiers | With DFA DR Method | With Chi2 pdf DR Method | With Firefly Algorithm DR Method | With Cuckoo Search DR Method | ||||
|---|---|---|---|---|---|---|---|---|
| Training MSE | Testing MSE | Training MSE | Testing MSE | Training MSE | Testing MSE | Training MSE | Testing MSE | |
| NLR | 3.61 × 10−6 | 9.01 × 10−6 | 5.29 × 10−6 | 4.062 × 10−5 | 3.36 × 10−6 | 1.568 × 10−4 | 3.84 × 10−7 | 3.737 × 10−5 |
| Linear Reg | 9.61 × 10−6 | 1.603 × 10−5 | 1.22 × 10−7 | 4.825 × 10−6 | 8.28 × 10−6 | 1.464 × 10−5 | 4.62 × 10−6 | 5.042 × 10−5 |
| Logistic Regression | 1.44 × 10−5 | 1.422 × 10−6 | 2.6 × 10−8 | 6.806 × 10−6 | 6.89 × 10−5 | 1.486 × 10−4 | 7.4 × 10−7 | 2.906 × 10−5 |
| GMM | 6.24 × 10−5 | 8.021 × 10−5 | 1.36 × 10−7 | 1.168 × 10−5 | 4.62 × 10−6 | 1.394 × 10−5 | 2.7 × 10−7 | 1.511 × 10−4 |
| BDLC | 1.76 × 10−5 | 4.063 × 10−5 | 7.29 × 10−6 | 5.653 × 10−5 | 1.52 × 10−6 | 1.192 × 10−4 | 5.33 × 10−7 | 2.92 × 10−5 |
| SDC | 9 × 10−6 | 2.003 × 10−5 | 2.89 × 10−6 | 2.493 × 10−5 | 1.02 × 10−5 | 1.243 × 10−4 | 8.65 × 10−8 | 5.525 × 10−5 |
| SVM (RBF) | 2.12 × 10−7 | 8.5 × 10−6 | 1.94 × 10−9 | 1.885 × 10−6 | 2.56 × 10−6 | 1.889 × 10−5 | 7.22 × 10−7 | 1.022 × 10−5 |
| Classifiers | With DFA DR Method | With Chi2 pdf DR Method | With Firefly Algorithm DR Method | With Cuckoo Search DR Method | ||||
|---|---|---|---|---|---|---|---|---|
| Training MSE | Testing MSE | Training MSE | Testing MSE | Training MSE | Testing MSE | Training MSE | Testing MSE | |
| NLR | 7.06 × 10−5 | 1.68 × 10−5 | 3.25 × 10−5 | 5.46 × 10−5 | 5.04 × 10−5 | 9.7 × 10−5 | 9.61 × 10−6 | 5.07 × 10−5 |
| Linear Reg | 9.22 × 10−5 | 2.44 × 10−4 | 1.44 × 10−5 | 2.22 × 10−5 | 1.68 × 10−5 | 1.21 × 10−4 | 8.28 × 10−7 | 2.86 × 10−5 |
| Logistic Regression | 5.93 × 10−8 | 1.68 × 10−5 | 6.25 × 10−6 | 3.03 × 10−5 | 2.81 × 10−7 | 2.86 × 10−5 | 3.25 × 10−5 | 3.14 × 10−5 |
| GMM | 1.09 × 10−5 | 2.21 × 10−4 | 1.76 × 10−5 | 5.66 × 10−5 | 3.02 × 10−5 | 7.57 × 10−5 | 3.84 × 10−5 | 1.23 × 10−5 |
| BDLC | 2.92 × 10−8 | 5.04 × 10−5 | 1.82 × 10−4 | 4.22 × 10−5 | 3.25 × 10−5 | 2.58 × 10−5 | 1.85 × 10−5 | 7.42 × 10−5 |
| SDC | 6.56 × 10−8 | 1.72 × 10−5 | 1.69 × 10−4 | 2.5 × 10−5 | 5.76 × 10−6 | 2.25 × 10−4 | 1.52 × 10−5 | 3.72 × 10−5 |
| SVM (RBF) | 4.36 × 10−5 | 4.88 × 10−6 | 7.4 × 10−5 | 8.13 × 10−6 | 6.56 × 10−5 | 1.02 × 10−5 | 1.86 × 10−7 | 1.7 × 10−6 |
| Classifiers | Description |
|---|---|
| NLR | Set distribution as N(o,σ2), g < 0.2, H < 0.014 with τ = 1, Convergence Criteria: MSE |
| LR | < 0.6, β = 0.01 and Convergence Criteria: MSE |
| LoR | Threshold H θ(x) = 0.5. Criterion: MSE |
| GMM | Mean, covariance of the input samples and tuning parameter as like in Expectation Maximum in test point likelihood probability 0.15, cluster probability of 0.6, with a convergence rate of 0.6. Criterion: MSE |
| BLDC | Prior probability P(x): 0.5, class mean µx = 0.8 and µy = 0.1. Criterion: MSE |
| SDC | C: 0.5, Coefficient of the kernel function (gamma): 10, Class weights: 0.5, Convergence Criteria: MSE |
| SVM–RBF | C: 1, Coefficient of the kernel function (gamma): 100, Class weights: 0.86, Convergence Criteria: MSE |
| Dimensionality Reduction | Classifiers | Parameters | |||||||
|---|---|---|---|---|---|---|---|---|---|
| Accuracy (%) | Recall | Precision | F1Score (%) | MCC | Error Rate (%) | Jaccard Metric (%) | Kappa | ||
| Detrend Fluctuation Analysis (DFA) | NLR | 55.7142 | 60 | 34.2857 | 43.6363 | 0.1264 | 44.2857 | 27.9069 | 0.1142 |
| Linear Reg | 55.7142 | 55 | 33.3333 | 41.5094 | 0.0995 | 44.2857 | 26.1904 | 0.0920 | |
| Logistic Regression | 55.7142 | 60 | 34.2857 | 43.6363 | 0.1264 | 44.2857 | 27.9069 | 0.1142 | |
| GMM | 55.7142 | 55 | 33.3333 | 41.5094 | 0.0995 | 44.2857 | 26.1904 | 0.0920 | |
| BDLC | 58.5714 | 60 | 36.3636 | 45.2830 | 0.1628 | 41.4285 | 29.2682 | 0.1506 | |
| SDC | 54.2857 | 55 | 32.3529 | 40.7407 | 0.0813 | 45.7142 | 25.5813 | 0.0743 | |
| SVM (RBF) | 57.1428 | 70 | 36.8421 | 48.2758 | 0.1995 | 42.8571 | 31.8181 | 0.1732 | |
| Chi2pdf | NLR | 61.4285 | 70 | 40 | 50.909 | 0.2529 | 38.5714 | 34.1463 | 0.2285 |
| Linear Reg | 57.1428 | 70 | 36.8421 | 48.2758 | 0.1995 | 42.8571 | 31.8181 | 0.1732 | |
| Logistic Regression | 54.2857 | 55 | 32.3529 | 40.7407 | 0.0813 | 45.7142 | 25.5813 | 0.0743 | |
| GMM | 54.2857 | 55 | 32.3529 | 40.7407 | 0.0813 | 45.7142 | 25.5813 | 0.0743 | |
| BDLC | 52.8571 | 50 | 30.3030 | 37.7358 | 0.0361 | 47.1428 | 23.2558 | 0.0334 | |
| SDC | 55.7142 | 55 | 33.3333 | 41.5094 | 0.0995 | 44.2857 | 26.1904 | 0.0920 | |
| SVM (RBF) | 65.7142 | 55 | 42.3076 | 47.826 | 0.2337 | 34.2857 | 31.4285 | 0.2293 | |
| Firefly Algorithm | NLR | 52.8571 | 50 | 30.3030 | 37.7358 | 0.0361 | 47.1428 | 23.2558 | 0.0334 |
| Linear Reg | 52.8571 | 55 | 31.4285 | 40 | 0.0632 | 47.1428 | 25 | 0.0571 | |
| Logistic Regression | 51.4285 | 50 | 29.4117 | 37.037 | 0.0180 | 48.5714 | 22.7272 | 0.0165 | |
| GMM | 54.2857 | 55 | 32.3529 | 40.7407 | 0.0813 | 45.7142 | 25.5813 | 0.0743 | |
| BDLC | 52.8571 | 55 | 31.4285 | 40 | 0.0632 | 47.1428 | 25 | 0.0571 | |
| SDC | 52.8571 | 50 | 30.3030 | 37.7358 | 0.0361 | 47.1428 | 23.2558 | 0.0334 | |
| SVM (RBF) | 54.2857 | 60 | 33.3333 | 42.8571 | 0.1084 | 45.7142 | 27.2727 | 0.0967 | |
| Cuckoo Search | NLR | 54.2857 | 50 | 31.25 | 38.4615 | 0.0544 | 45.7142 | 23.8095 | 0.0508 |
| Linear Reg | 57.1428 | 55 | 34.375 | 42.3076 | 0.1178 | 42.8571 | 26.8292 | 0.1101 | |
| Logistic Regression | 57.1428 | 55 | 34.375 | 42.3076 | 0.1178 | 42.8571 | 26.8292 | 0.1101 | |
| GMM | 55.7142 | 55 | 33.3333 | 41.5094 | 0.0995 | 44.2857 | 26.1904 | 0.0920 | |
| BDLC | 58.5714 | 60 | 36.3636 | 45.2830 | 0.1628 | 41.4285 | 29.2682 | 0.1506 | |
| SDC | 57.1428 | 55 | 34.375 | 42.3076 | 0.1178 | 42.8571 | 26.8292 | 0.1101 | |
| SVM (RBF) | 65.7142 | 60 | 42.8571 | 50 | 0.2581 | 34.2857 | 33.3333 | 0.25 | |
| Dimensionality Reduction | Classifiers | Parameters | |||||||
|---|---|---|---|---|---|---|---|---|---|
| Accuracy (%) | Recall | Precision | F1 Score (%) | MCC | Error Rate (%) | Jaccard Metric (%) | Kappa | ||
| Detrend Fluctuation Analysis (DFA) | NLR | 84.2857 | 85 | 68 | 75.5555 | 0.6505 | 15.7142 | 60.7142 | 0.6418 |
| Linear Reg | 60 | 80 | 40 | 53.3333 | 0.2921 | 40 | 36.3636 | 0.2461 | |
| Logistic Regression | 81.4285 | 75 | 65.2173 | 69.7674 | 0.5674 | 18.5714 | 53.5714 | 0.5645 | |
| GMM | 57.1428 | 60 | 35.2941 | 44.4444 | 0.1446 | 42.8571 | 28.5714 | 0.1322 | |
| BDLC | 65.7142 | 85 | 44.7368 | 58.6206 | 0.3899 | 34.2857 | 41.4634 | 0.3385 | |
| SDC | 74.2857 | 85 | 53.125 | 65.3846 | 0.4987 | 25.7142 | 48.5714 | 0.4661 | |
| SVM (RBF) | 82.8571 | 90 | 64.2857 | 75 | 0.6454 | 17.1428 | 60 | 0.625 | |
| Chi2pdf | NLR | 65.7142 | 85 | 44.73684 | 58.6206 | 0.3899 | 34.2857 | 41.4634 | 0.3385 |
| Linear Reg | 87.1428 | 90 | 72 | 80 | 0.7165 | 12.8571 | 66.6666 | 0.7069 | |
| Logistic Regression | 60 | 60 | 37.5 | 46.1538 | 0.1813 | 40 | 30 | 0.1694 | |
| GMM | 84.2857 | 75 | 71.4285 | 73.1707 | 0.6210 | 15.7142 | 57.6923 | 0.6206 | |
| BDLC | 65.7142 | 55 | 42.3076 | 47.8260 | 0.2337 | 34.2857 | 31.4285 | 0.2293 | |
| SDC | 81.4285 | 65 | 68.4210 | 66.6666 | 0.5384 | 18.5714 | 50 | 0.5380 | |
| SVM (RBF) | 91.4285 | 90 | 81.8181 | 85.7142 | 0.7979 | 8.57142 | 75 | 0.7961 | |
| Firefly Algorithm | NLR | 62.8571 | 85 | 42.5 | 56.6666 | 0.3560 | 37.1428 | 39.5348 | 0.3 |
| Linear Reg | 77.1428 | 90 | 56.25 | 69.2307 | 0.5622 | 22.8571 | 52.9411 | 0.5254 | |
| Logistic Regression | 55.7142 | 60 | 34.2857 | 43.6363 | 0.1264 | 44.2857 | 27.9069 | 0.1142 | |
| GMM | 75.7142 | 85 | 54.8387 | 66.6666 | 0.5183 | 24.2857 | 50 | 0.4892 | |
| BDLC | 58.5714 | 70 | 37.8378 | 49.1228 | 0.2171 | 41.4285 | 32.5581 | 0.1912 | |
| SDC | 62.8571 | 50 | 38.4615 | 43.4782 | 0.1682 | 37.1428 | 27.7777 | 0.1651 | |
| SVM (RBF) | 75.7142 | 85 | 54.8387 | 66.6666 | 0.5183 | 24.2857 | 50 | 0.4892 | |
| Cuckoo Search | NLR | 72.8571 | 60 | 52.17391 | 55.8139 | 0.3654 | 27.1428 | 38.7096 | 0.3636 |
| Linear Reg | 62.8571 | 70 | 41.17647 | 51.8518 | 0.2711 | 37.1428 | 35 | 0.2479 | |
| Logistic Regression | 80 | 65 | 65 | 65 | 0.51 | 20 | 48.1481 | 0.51 | |
| GMM | 57.1428 | 65 | 36.1111 | 46.4285 | 0.1717 | 42.8571 | 30.2325 | 0.1532 | |
| BDLC | 70 | 70 | 48.2758 | 57.1428 | 0.3668 | 30 | 40 | 0.3524 | |
| SDC | 68.5714 | 55 | 45.8333 | 50 | 0.2760 | 31.4285 | 33.3333 | 0.2735 | |
| SVM (RBF) | 81.4285 | 85 | 62.9629 | 72.3404 | 0.6032 | 18.5714 | 56.6666 | 0.5882 | |
| Dimensionality Reduction | Classifiers | Parameters | |||||||
|---|---|---|---|---|---|---|---|---|---|
| Accuracy (%) | Recall | Precision | F1 Score (%) | MCC | Error Rate (%) | Jaccard Metric (%) | Kappa | ||
| Detrend Fluctuation Analysis (DFA) | NLR | 78.5714 | 80 | 59.2592 | 68.0851 | 0.5382 | 21.4285 | 51.6129 | 0.5248 |
| Linear Reg | 52.8571 | 50 | 30.3030 | 37.7358 | 0.0361 | 47.1428 | 23.2558 | 0.0334 | |
| Logistic Regression | 78.5714 | 80 | 59.2592 | 68.0851 | 0.5382 | 21.4285 | 51.6129 | 0.5248 | |
| GMM | 54.2857 | 55 | 32.3529 | 40.7407 | 0.0813 | 45.7142 | 25.5814 | 0.0743 | |
| BDLC | 64.2857 | 65 | 41.9354 | 50.9803 | 0.2637 | 35.7142 | 34.2105 | 0.2489 | |
| SDC | 75.7142 | 85 | 54.8387 | 66.6667 | 0.5183 | 24.2857 | 50 | 0.4892 | |
| SVM (RBF) | 85.7142 | 85 | 70.8333 | 77.2727 | 0.6757 | 14.2857 | 62.9629 | 0.6698 | |
| Chi2pdf | NLR | 61.4285 | 65 | 39.3939 | 49.0566 | 0.2262 | 38.5714 | 32.5 | 0.2092 |
| Linear Reg | 72.8571 | 75 | 51.7241 | 61.2244 | 0.4310 | 27.1428 | 44.1176 | 0.4140 | |
| Logistic Regression | 70 | 80 | 48.4848 | 60.3773 | 0.4162 | 30 | 43.2432 | 0.3849 | |
| GMM | 64.2857 | 60 | 41.3793 | 48.9795 | 0.2384 | 35.7142 | 32.4324 | 0.2290 | |
| BDLC | 67.1428 | 65 | 44.8275 | 53.0612 | 0.3026 | 32.8571 | 36.1111 | 0.2907 | |
| SDC | 71.4285 | 70 | 50 | 58.3333 | 0.3872 | 28.5714 | 41.1764 | 0.375 | |
| SVM (RBF) | 84.2857 | 85 | 68 | 75.5556 | 0.6505 | 15.7142 | 60.7142 | 0.6418 | |
| Firefly Algorithm | NLR | 55.7142 | 55 | 33.3333 | 41.5094 | 0.0995 | 44.2857 | 26.1904 | 0.0920 |
| Linear Reg | 55.7142 | 55 | 33.3333 | 41.5094 | 0.0995 | 44.2857 | 26.1904 | 0.0920 | |
| Logistic Regression | 71.4285 | 85 | 50 | 62.9629 | 0.4609 | 28.5714 | 45.9459 | 0.4214 | |
| GMM | 58.5714 | 60 | 36.3636 | 45.2830 | 0.1628 | 41.4285 | 29.2682 | 0.1506 | |
| BDLC | 75.7142 | 70 | 56 | 62.2222 | 0.4525 | 24.2857 | 45.1612 | 0.4465 | |
| SDC | 54.2857 | 50 | 31.25 | 38.4615 | 0.0544 | 45.7142 | 23.8095 | 0.0508 | |
| SVM (RBF) | 85.7142 | 80 | 72.7272 | 76.1904 | 0.6617 | 14.2857 | 61.5384 | 0.6601 | |
| Cuckoo Search | NLR | 62.8571 | 65 | 40.625 | 50 | 0.2448 | 37.1428 | 33.3333 | 0.2288 |
| Linear Reg | 71.4285 | 70 | 50 | 58.3333 | 0.3872 | 28.5714 | 41.1764 | 0.375 | |
| Logistic Regression | 71.4285 | 70 | 50 | 58.3333 | 0.3872 | 28.5714 | 41.1764 | 0.375 | |
| GMM | 80 | 80 | 61.5384 | 69.5652 | 0.5609 | 20 | 53.3333 | 0.5504 | |
| BDLC | 58.5714 | 60 | 36.3636 | 45.2830 | 0.1628 | 41.4285 | 29.2682 | 0.1506 | |
| SDC | 68.5714 | 70 | 46.6666 | 56 | 0.3468 | 31.4285 | 38.8889 | 0.3304 | |
| SVM (RBF) | 90 | 90 | 78.2608 | 83.7209 | 0.7694 | 10 | 72 | 0.7655 | |
| Classifiers | With DFA DR Method | With Chi2 pdf DR Method | With Firefly Algorithm DR Method | With Cuckoo Search DR Method |
|---|---|---|---|---|
| NLR | O(2n2log2n) | O(2n2log2n) | O(2n4log2n) | O(2n4log2n) |
| Linear Reg | O(2nlog2n) | O(2n2log2n) | O(2n3log2n) | O(2n3log2n) |
| Logistic Regression | O(2n2log2n) | O(2n2log2n) | O(2n3log2n) | O(2n3log2n) |
| GMM | O(2n3log2n) | O(2n3log2n) | O(2n4log2n) | O(2n4log2n) |
| BDLC | O(2n3 log2n) | O(2n3log2n) | O(2n4log2n) | O(2n4 log2n) |
| SDC | O(2n2log2n) | O(2n2log2n) | O(2n4log2n) | O(2n4log2n) |
| SVM (RBF) | O(2n2log4n) | O(2n2log4n) | O(2n4log4n) | O(2n3log4n) |
| Classifiers | With DFA DR Method | With Chi2 pdf DR Method | With Firefly Algorithm DR Method | With Cuckoo Search DR Method |
|---|---|---|---|---|
| NLR | O(2n4log2n) | O(2n4log2n) | O(2n6log2n) | O(2n6log2n) |
| Linear Reg | O(2n3log2n) | O(2n4log2n) | O(2n5log2n) | O(2n5log2n) |
| Logistic Regression | O(2n4log2n) | O(2n4log2n) | O(2n4log2n) | O(2n5log2n) |
| GMM | O(2n5log2n) | O(2n5log2n) | O(2n6log2n) | O(2n6log2n) |
| BDLC | O(2n5log2n) | O(2n5log2n) | O(2n6log2n) | O(2n6log2n) |
| SDC | O(2n4log2n) | O(2n4log2n) | O(2n4log2n) | O(2n4log2n) |
| SVM (RBF) | O(2n4log2n) | O(2n4log4n) | O(2n6log4n) | O(2n5log4n) |
| Classifiers | With DFA DR Method | With Chi2 pdf DR Method | With Firefly Algorithm DR Method | With Cuckoo Search DR Method |
|---|---|---|---|---|
| NLR | O(2n3log2n) | O (2n3log2n) | O(2n4log2n) | O(2n4log2n) |
| Linear Reg | O(2n2log2n) | O(2n3log2n) | O(2n5log2n) | O(2n5log2n) |
| Logistic Regression | O(2n3log2n) | O(2n3log2n) | O(2n4log2n) | O(2n4log2n) |
| GMM | O(2n4log2n) | O(2n5log2n) | O(2n5log2n) | O(2n5log2n) |
| BDLC | O(2n4log2n) | O(2n4log2n) | O(2n5log2n) | O(2n5log2n) |
| SDC | O(2n3log2n) | O(2n3log2n) | O(2n3log2n) | O(2n4log2n) |
| SVM (RBF) | O(2n4log2n) | O(2n4log2n) | O(2n4log2n) | O (2n4log2n) |
| S. No | Author (With Year) | Description of the Population | Data Sampling | Machine Learning Parameter | Accuracy (%) |
|---|---|---|---|---|---|
| 1 | Kumar et al. (2017) [52] | Diagnosis lab, Warangal—IN. Diabetes: 650 | N-fold (N = 10) cross validation | Support Vector Machine, Naive Bayes, K-nearest neighbor C4.5 Decision tree | Accuracy: 69, 67, 70, 74 |
| 2 | Olivera et al. (2017) [53] | Diabetes: 12,447 unknown: 1359 age: 35–74 | Training set (70%) test set (30%) tenfold cross-validation | Logistic Regression Artificial Neural Network K-nearest neighbor Naïve Bayes | Balanced Accuracy: 69.3, 69.47, 68.74, 68.95 |
| 3 | Alghamdi et al. (2017) [54] | Total: 32,555 diabetes: 5099 imbalanced | N-fold cross validation | Naïve Bayes tree, random forest, and logistic model tree, j48 decision tree | Accuracy: 83.9, 84.1, 79.9, 84.3, 84.1 |
| 4 | Xie et al. (2017) [55] | Total: 21,285 diabetes: 1124 age: 35–65 | Training set (75%) test set (25%) | K2 structure-learning algorithm | Accuracy = 82.48 |
| 5 | Sarwar et al. (2018) [56] | Pima Indians Diabetes Dataset = 768 | Training set (70%) test set (30%) tenfold cross-validation | K nearest neighbors, Naïve Bayes, support vector machine, decision tree, Logistic Regression, random forest | Accuracy: 77, 74, 77, 71, 74, 71 |
| 6 | Zou et al. (2018) [57] | Physical Examination data in Luzhou, China. Total data: 164431 | Fivefold cross-validation | Random forest J48 decision tree Deep Neural Network | Accuracy: 81, 79, 78 |
| 7 | Perveen et al. (2019) [58] | Total: 667, 907 age: 22–74 diabetes: 8.13% imbalance | K-medoids under sampling | J48 decision tree, Naïve Bayes | Accuracy: 88.3, 87.3, 83.6, 82.6 |
| 8 | Yuvaraj et al. (2019) [59] | Total: 75,664 | Training set (70%) test set (30%) | Decision tree Naïve Bayes random forest | Accuracy: 88 |
| 9 | Jakka et al. (2019) [60] | Pima Indians Diabetes dataset | None | K nearest neighbor, decision tree, Naive Bayes, support vector machine, Logistic Regression, random forest | Accuracy: 73, 70, 75, 66, 78, 74 |
| 10 | Radja et al. (2019) [61] | Total: 768 diabetes: 500 control: 268 | Tenfold cross-validation | Naive Bayes, support vector machine, decision table, J48 decision tree | Accuracy: 80, 79, 76, 79 |
| 11 | Xiong et al. (2019) [62] | Total: 11845 diabetes: 845 age: 20–100 | Training set (60%) test set (20%) tenfold cross-validation set (20%) | Multilayer perceptron, Ada-Boost, Random Forest, Support Vector Machine, Gradient boosting | Accuracy: 87, 86, 86, 86, 86 |
| 12 | Dinh et al. (2019) [63] | Case 1: 21,131 diabetes: 5532 case 2: 16,426 prediabetes: 6482 | Training set (80%) test set (20%) tenfold cross-validation | Support vector machine, random forest, gradient boosting, Logistic Regression | Accuracy: 89, 84, 86, 72 |
| 13 | Yang et al. (2020) [64] | Total =8057 age: 20–89 imbalanced Non-Diabetic = 6721 Diabetic = 1336 | Training set: (80%, 2011–2014), test set: (20%, 2011–2014) and validation set: (2015–2016) fivefold cross-validation | Linear discriminant analysis, support vector machine random forest | Accuracy: 75, 74, 74 |
| 14 | Muhammad et al. (2020) [65] | Total: 383 age: 1–150 diabetes: 51.9% | Tenfold cross-validation | Logistic Regression Support vector machine K-nearest neighbor Random forest Naive Bayes Gradient boosting | Accuracy: 81, 85, 82, 89, 77, 86 |
| 15 | Lam et al. (2021) [66] | Control: 19,852 diabetes: 3103 age: 40–69 | Tenfold cross-validation | Random forest Logistic Regression extreme gradient boosting GBT | Accuracy: 86 |
| 16 | De Silva et al. (2021) [67] | Total: 16,429 diabetes: 5.6% age: >20 | Training set (30%) validation (30%) test set (40%) | Logistic Regression | Accuracy: 62 |
| 17 | Kim et al. (2021) [68] | Total: 3889 diabetes: 746 age: 40–69 | Fivefold cross-validation | Deep neural network, Logistic Regression, decision tree | Accuracy: 80, 80, 71 |
| 18 | Ramesh et al. (2021) [69] | Pima Indians | Tenfold cross-validation | Support vector machine | Accuracy: 83 |
| 19 | This article | Nordic islet transplantation programme | 10-fold cross-validation | LR, NLR, LoR, GMM, BLDC, SDC, SVM (RBF) | Accuracy: 91 |
| S. No. | Authors | Data Set Used | Machine Learning Models/Classifiers | Accuracy (%) |
|---|---|---|---|---|
| 1 | Methaporn et al. (2023) [70] | Department of Medical Services, Bangkok, Thailand, from 2019–2021 | Support Vector Machine (SVM) | 81.1 |
| Decision Tree (DT) | 81.3 | |||
| k-Nearest neighbour (kNN) | 81.7 | |||
| Random forest | 88.2 | |||
| 2 | Pannapa C et al. (2021) [71] | National Institute of Diabetes and Digestive and Kidney Diseases—PIMA | Random Forest | 76.30 |
| SVM (L) | 77.08 | |||
| SVM (P) | 74.74 | |||
| SVM (RBF) | 75.78 | |||
| kNN | 74.87 | |||
| Thyroid—University of California Irvine (UCI) | Random Forest | 96.74 | ||
| SVM (L) | 96.27 | |||
| SVM (P) | 91.16 | |||
| SVM (RBF) | 95.81 | |||
| kNN | 96.28 | |||
| 3 | Kumari D et al. (2021) [72] | PIMA Indian Data set—May 2008 | Logistic Regression | 74.89 |
| Support vector | 74.08 | |||
| k-Nearest | 71.92 | |||
| Navie Bayes | 74.12 | |||
| Decision tree | 71.42 | |||
| Random forest | 77.48 | |||
| Ada boost | 75.32 | |||
| XG Boost | 75.75 | |||
| Gradient Boost | 75.32 | |||
| CatBoost | 75.32 | |||
| 4 | Hui Yang et al. (2021) [73] | Physical examination data from the EMR of Luzhou Municipal Health Commission in China from 2011 to 2017 | Linear regression | 80 |
| XG Boost | 72 | |||
| Random Forest | 80 | |||
| 5 | Amin Ul Haq et al. (2020) [74] | Dataset of diabetes, taken from the hospital Frankfurt, Germany | ID3 | 99 |
| Ada Boost | 98.5 | |||
| Random Forest | 98.3 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Chellappan, D.; Rajaguru, H. Detection of Diabetes through Microarray Genes with Enhancement of Classifiers Performance. Diagnostics 2023, 13, 2654. https://doi.org/10.3390/diagnostics13162654
Chellappan D, Rajaguru H. Detection of Diabetes through Microarray Genes with Enhancement of Classifiers Performance. Diagnostics. 2023; 13(16):2654. https://doi.org/10.3390/diagnostics13162654
Chicago/Turabian StyleChellappan, Dinesh, and Harikumar Rajaguru. 2023. "Detection of Diabetes through Microarray Genes with Enhancement of Classifiers Performance" Diagnostics 13, no. 16: 2654. https://doi.org/10.3390/diagnostics13162654