Use of Machine Learning to Investigate the Quantitative Checklist for Autism in Toddlers (Q-CHAT) towards Early Autism Screening

 ,
,  ,
,  ,
,  , , , , , and
, , , , , and 
Abstract
:1. Introduction
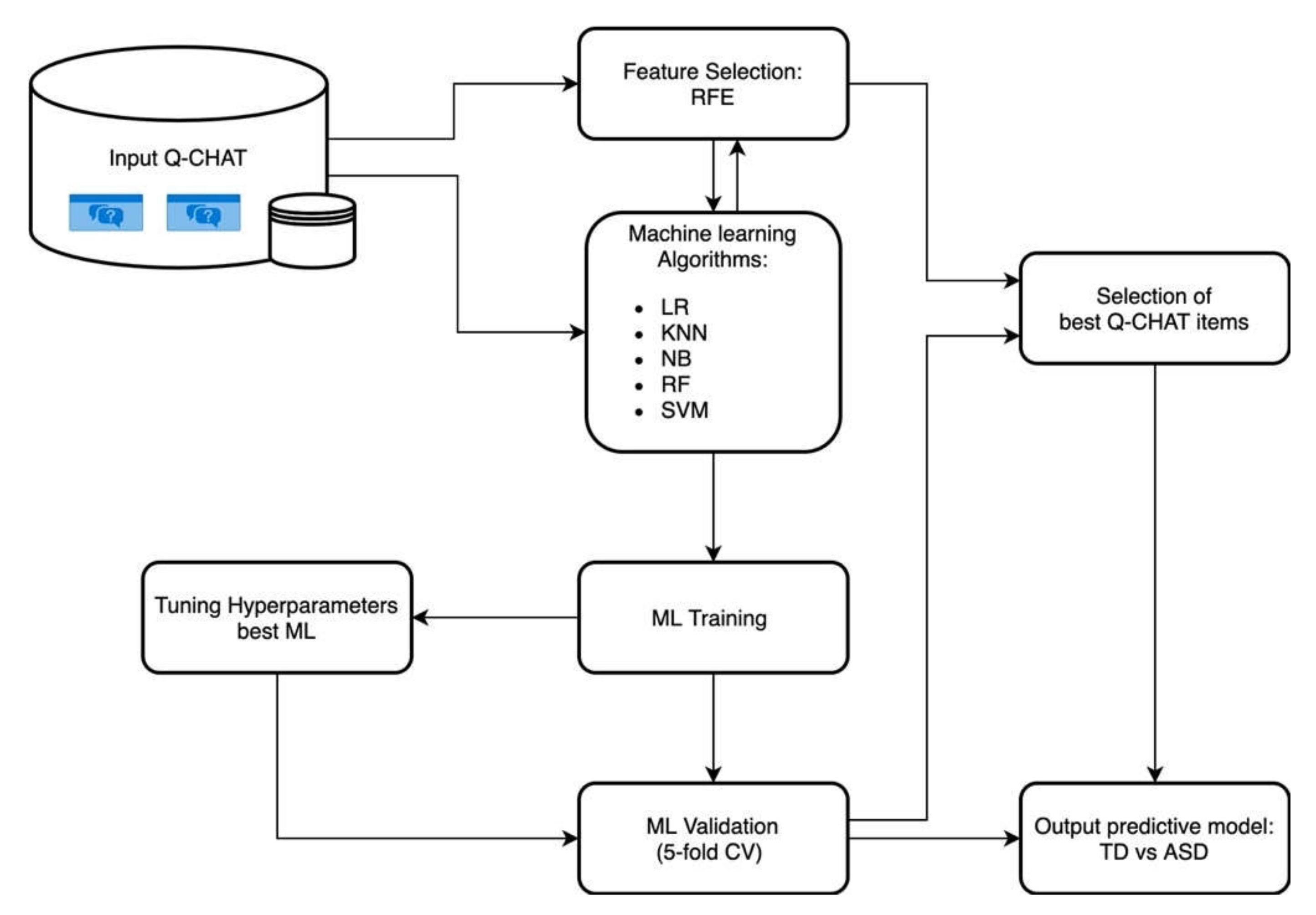
2. Materials and Methods
2.1. Participants
2.2. Data Selection and Machine-Learning Classifier Tuning
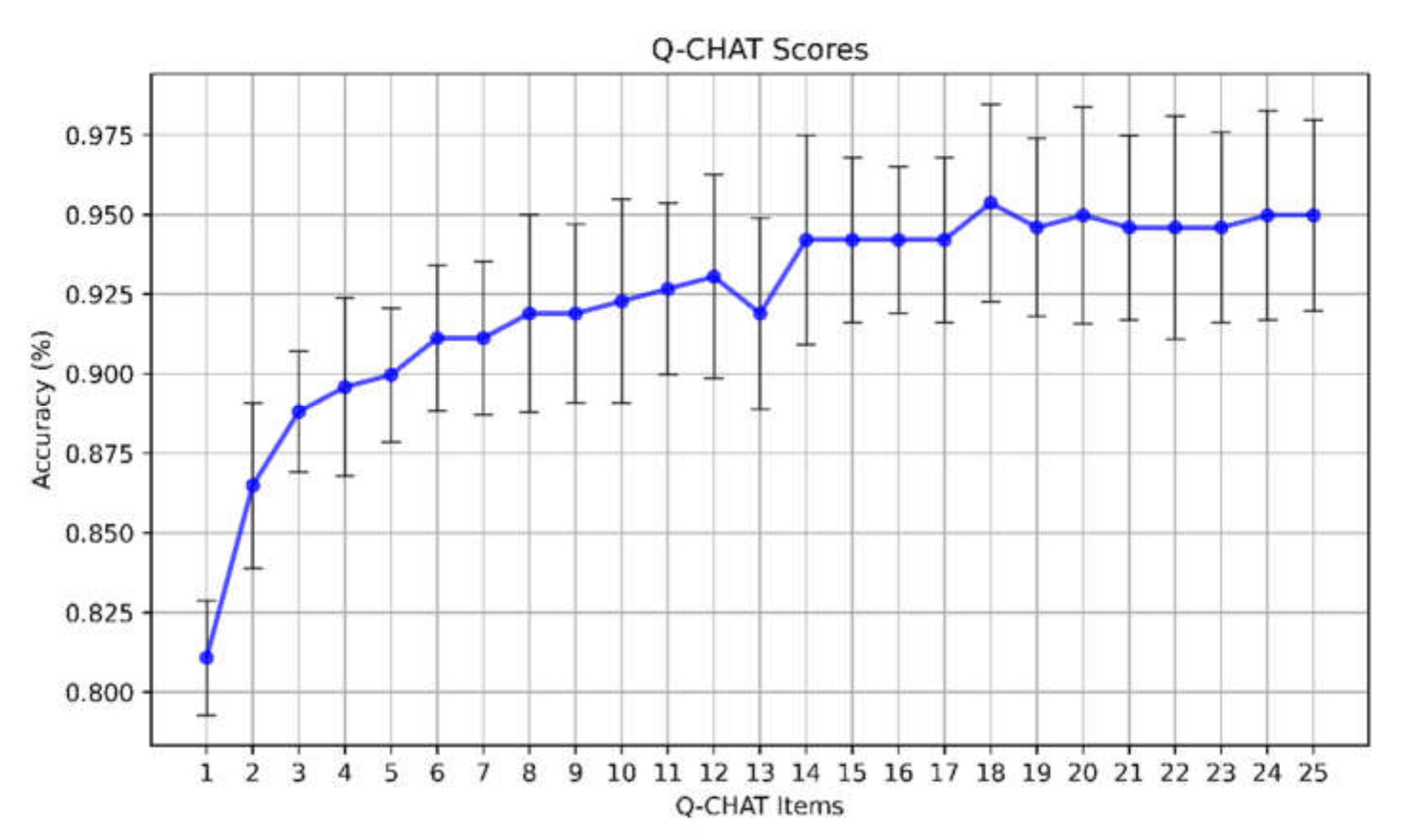
2.3. Feature Selection
2.4. Metric for ML Performance
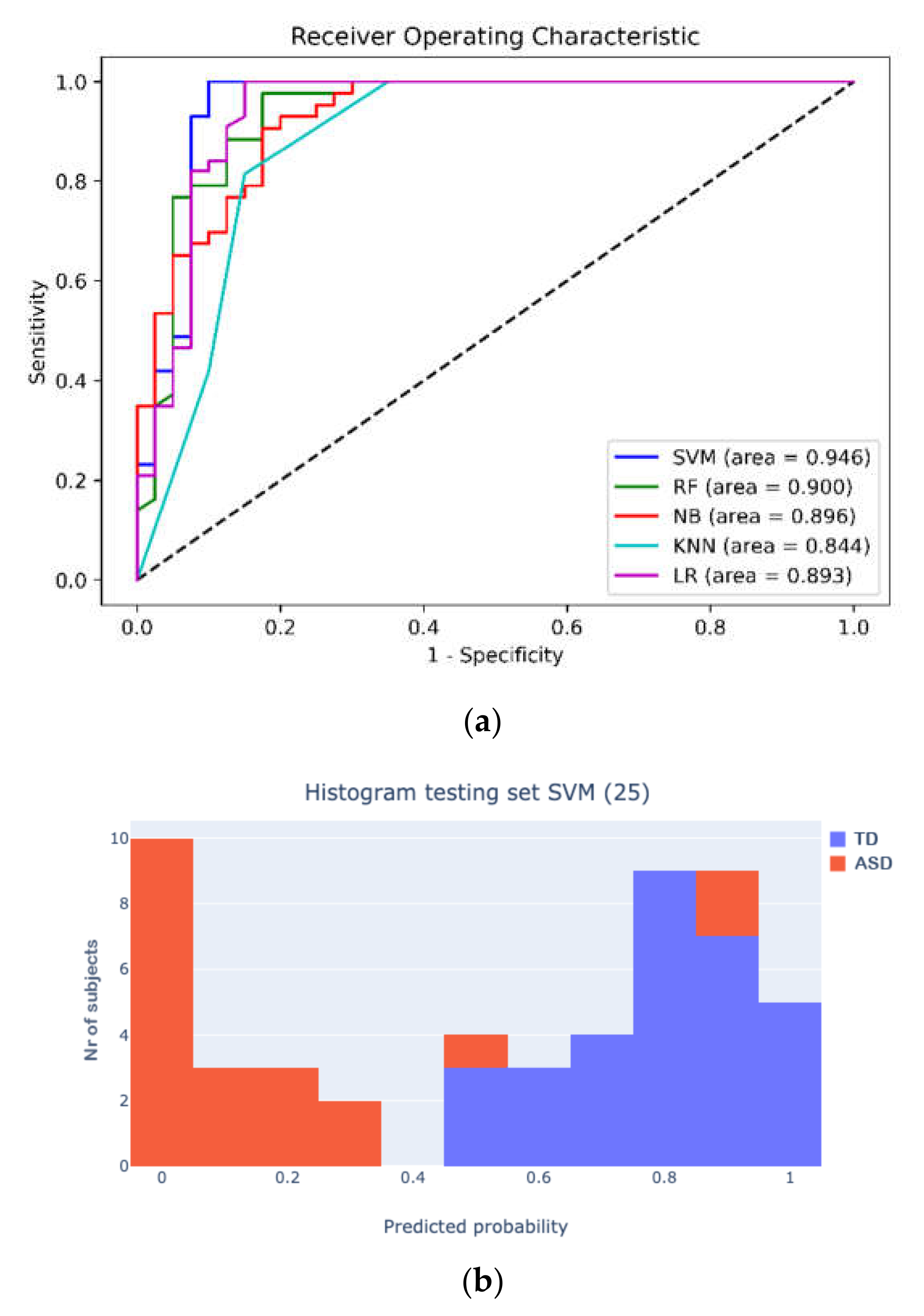
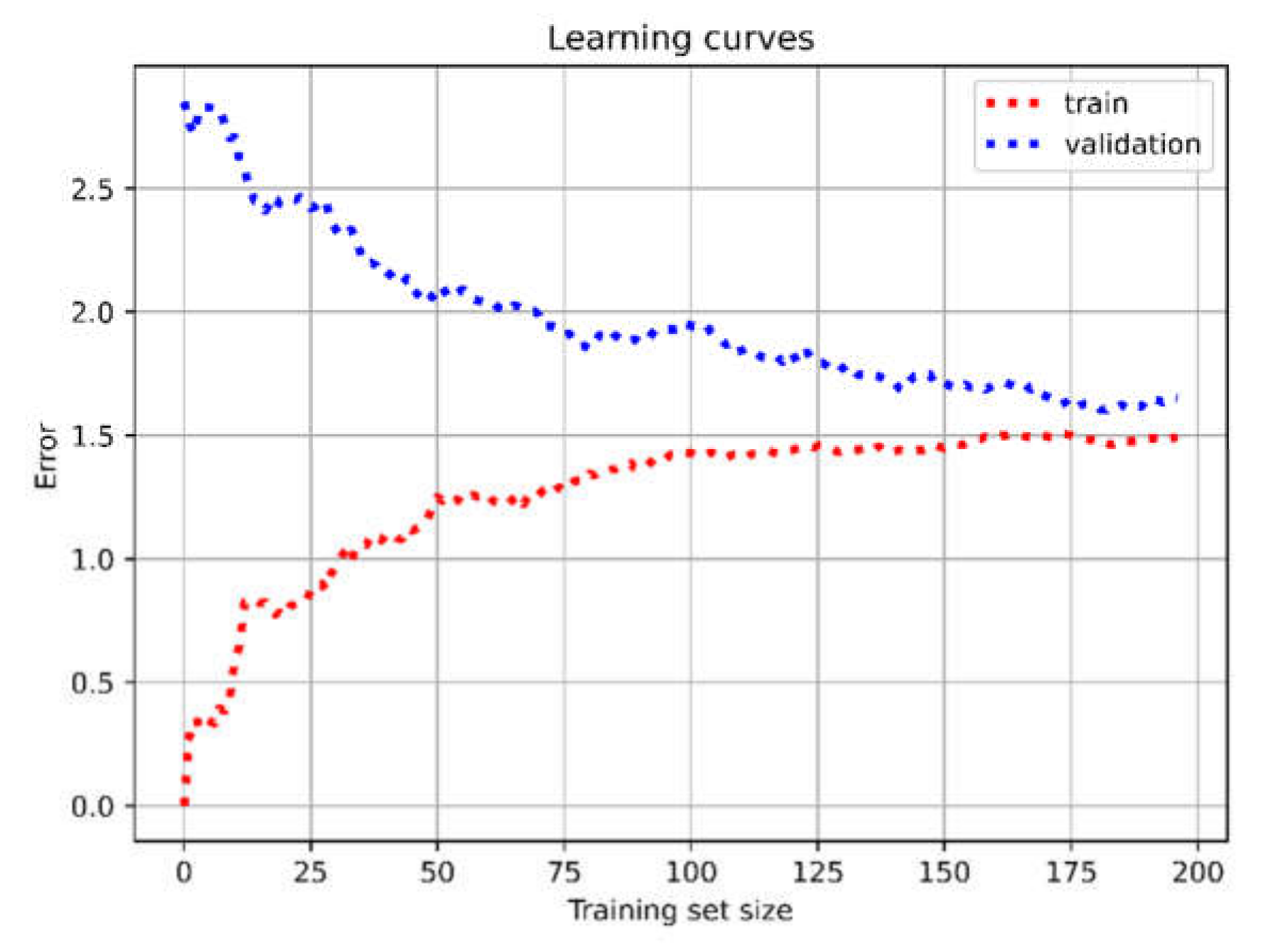
3. Results
4. Discussion
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Diagnostic and Statistical Manual of Mental Disorders: DSM-5, 5th ed.; American Psychiatric Association: Washington, DC, USA, 2013; ISBN 978-0-89042-554-1.
- Elsabbagh, M.; Johnson, M.H. Getting Answers from Babies about Autism. Trends Cogn. Sci. 2010, 14, 81–87. [Google Scholar] [CrossRef]
- Thabtah, F.; Peebles, D. Early Autism Screening: A Comprehensive Review. Int. J. Environ. Res. Public. Health 2019, 16, 3502. [Google Scholar] [CrossRef] [Green Version]
- McPheeters, M.L.; Weitlauf, A.; Vehorn, A.; Taylor, C.; Sathe, N.A.; Krishnaswami, S.; Fonnesbeck, C.; Warren, Z.E. Screening for Autism Spectrum Disorder in Young Children. In U.S. Preventive Services Task Force Evidence Syntheses, Formerly Systematic Evidence Reviews; Agency for Healthcare Research and Quality: Rockville, MD, USA, 2016. [Google Scholar]
- Dereu, M.; Roeyers, H.; Raymaekers, R.; Meirsschaut, M.; Warreyn, P. How Useful Are Screening Instruments for Toddlers to Predict Outcome at Age 4? General Development, Language Skills, and Symptom Severity in Children with a False Positive Screen for Autism Spectrum Disorder. Eur. Child Adolesc. Psychiatry 2012, 21, 541–551. [Google Scholar] [CrossRef]
- Zwaigenbaum, L.; Penner, M. Autism Spectrum Disorder: Advances in Diagnosis and Evaluation. BMJ 2018, 361, k1674. [Google Scholar] [CrossRef] [PubMed]
- Magán-Maganto, M.; Jónsdóttir, S.L.; Sánchez-García, A.B.; García-Primo, P.; Hellendoorn, A.; Charman, T.; Roeyers, H.; Dereu, M.; Moilanen, I.; Muratori, F. Building a Theoretical Framework for Autism Spectrum Disorders Screening Instruments in Europe. Child Adolesc. Ment. Health 2018, 23, 359–367. [Google Scholar] [CrossRef] [Green Version]
- Robins, D.L.; Casagrande, K.; Barton, M.; Chen, C.-M.A.; Dumont-Mathieu, T.; Fein, D. Validation of the Modified Checklist for Autism in Toddlers, Revised with Follow-up (M-CHAT-R/F). Pediatrics 2014, 133, 37–45. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Yuen, T.; Penner, M.; Carter, M.T.; Szatmari, P.; Ungar, W.J. Assessing the Accuracy of the Modified Checklist for Autism in Toddlers: A Systematic Review and Meta-Analysis. Dev. Med. Child Neurol. 2018, 60, 1093–1100. [Google Scholar] [CrossRef] [Green Version]
- Oosterling, I.; Rommelse, N.; De Jonge, M.; Van Der Gaag, R.J.; Swinkels, S.; Roos, S.; Visser, J.; Buitelaar, J. How Useful Is the Social Communication Questionnaire in Toddlers at Risk of Autism Spectrum Disorder? J. Child Psychol. Psychiatry 2010, 51, 1260–1268. [Google Scholar] [CrossRef] [PubMed]
- Stone, W.L.; Coonrod, E.E.; Ousley, O.Y. Brief Report: Screening Tool for Autism in Two-Year-Olds (STAT): Development and Preliminary Data. J. Autism Dev. Disord. 2000, 30, 607. [Google Scholar] [CrossRef] [PubMed]
- Matson, J.L.; Wilkins, J.; Sharp, B.; Knight, C.; Sevin, J.A.; Boisjoli, J.A. Sensitivity and Specificity of the Baby and Infant Screen for Children with AUtIsm Traits (BISCUIT): Validity and Cutoff Scores for Autism and PDD-NOS in Toddlers. Res. Autism Spectr. Disord. 2009, 3, 924–930. [Google Scholar] [CrossRef]
- Allison, C.; Baron-Cohen, S.; Wheelwright, S.; Charman, T.; Richler, J.; Pasco, G.; Brayne, C. The Q-CHAT (Quantitative CHecklist for Autism in Toddlers): A Normally Distributed Quantitative Measure of Autistic Traits at 18–24 Months of Age: Preliminary Report. J. Autism Dev. Disord. 2008, 38, 1414–1425. [Google Scholar] [CrossRef] [PubMed]
- Ruta, L.; Chiarotti, F.; Arduino, G.M.; Apicella, F.; Leonardi, E.; Maggio, R.; Carrozza, C.; Chericoni, N.; Costanzo, V.; Turco, N. Validation of the Quantitative CHecklist for Autism in Toddlers in an Italian Clinical Sample of Young Children with Autism and Other Developmental Disorders. Front. Psychiatry 2019, 10, 488. [Google Scholar] [CrossRef] [Green Version]
- Ruta, L.; Arduino, G.M.; Gagliano, A.; Apicella, F.; Leonardi, E.; Famà, F.I.; Chericoni, N.; Costanzo, V.; Turco, N.; Tartarisco, G. Psychometric Properties, Factor Structure and Cross-Cultural Validity of the Quantitative CHecklist for Autism in Toddlers (Q-CHAT) in an Italian Community Setting. Res. Autism Spectr. Disord. 2019, 64, 39–48. [Google Scholar] [CrossRef]
- Devescovi, R.; Monasta, L.; Bin, M.; Bresciani, G.; Mancini, A.; Carrozzi, M.; Colombi, C. A Two-Stage Screening Approach with I-TC and Q-CHAT to Identify Toddlers at Risk for Autism Spectrum Disorder within the Italian Public Health System. Brain Sci. 2020, 10, 184. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Wong, H.S.; Huertas-Ceballos, A.; Cowan, F.M.; Modi, N.; Medicines for Neonates Investigator Group. Evaluation of Early Childhood Social-Communication Difficulties in Children Born Preterm Using the Quantitative CHecklist for Autism in Toddlers. J. Pediatr. 2014, 164, 26–33. [Google Scholar] [CrossRef] [PubMed]
- Magiati, I.; Goh, D.A.; Lim, S.J.; Gan, D.Z.Q.; Leong, J.C.L.; Allison, C.; Baron-Cohen, S.; Rifkin-Graboi, A.; Broekman, B.P.; Saw, S.M. The Psychometric Properties of the Quantitative-CHecklist for Autism in Toddlers (Q-CHAT) as a Measure of Autistic Traits in a Community Sample of Singaporean Infants and Toddlers. Mol. Autism 2015, 6, 1–14. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Mohammadian, M.; Zarafshan, H.; Mohammadi, M.R.; Karimi, I. Evaluating Reliability and Predictive Validity of the Persian Translation of Quantitative CHecklist for Autism in Toddlers (Q-CHAT). Iran. J. Psychiatry 2015, 10, 64. [Google Scholar] [PubMed]
- Allison, C.; Auyeung, B.; Baron-Cohen, S. Toward Brief “Red Flags” for Autism Screening: The Short Autism Spectrum Quotient and the Short Quantitative CHecklist in 1000 Cases and 3000 Controls. J. Am. Acad. Child Adolesc. Psychiatry 2012, 51, 202–212. [Google Scholar] [CrossRef] [PubMed]
- Wall, D.P.; Kosmicki, J.; Deluca, T.F.; Harstad, E.; Fusaro, V.A. Use of Machine Learning to Shorten Observation-Based Screening and Diagnosis of Autism. Transl. Psychiatry 2012, 2, e100. [Google Scholar] [CrossRef]
- Duda, M.; Kosmicki, J.A.; Wall, D.P. Testing the Accuracy of an Observation-Based Classifier for Rapid Detection of Autism Risk. Transl. Psychiatry 2014, 4, e424. [Google Scholar] [CrossRef]
- Bone, D.; Goodwin, M.S.; Black, M.P.; Lee, C.-C.; Audhkhasi, K.; Narayanan, S. Applying Machine Learning to Facilitate Autism Diagnostics: Pitfalls and Promises. J. Autism Dev. Disord. 2015, 45, 1121–1136. [Google Scholar] [CrossRef] [Green Version]
- Levy, S.; Duda, M.; Haber, N.; Wall, D.P. Sparsifying Machine Learning Models Identify Stable Subsets of Predictive Features for Behavioral Detection of Autism. Mol. Autism 2017, 8, 1–17. [Google Scholar] [CrossRef] [Green Version]
- Kosmicki, J.A.; Sochat, V.; Duda, M.; Wall, D.P. Searching for a Minimal Set of Behaviors for Autism Detection through Feature Selection-Based Machine Learning. Transl. Psychiatry 2015, 5, e514. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Constantino, J.N.; Gruber, C.P. Social Responsiveness Scale: SRS-2; Western Psychological Services: Torrance, CA, USA, 2012. [Google Scholar]
- Duda, M.; Ma, R.; Haber, N.; Wall, D.P. Use of Machine Learning for Behavioral Distinction of Autism and ADHD. Transl. Psychiatry 2016, 6, e732. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Washington, P.; Paskov, K.M.; Kalantarian, H.; Stockham, N.; Voss, C.; Kline, A.; Patnaik, R.; Chrisman, B.; Varma, M.; Tariq, Q.; et al. Feature Selection and Dimension Reduction of Social Autism Data. Pac. Symp. Biocomput. 2020, 25, 707–718. [Google Scholar] [PubMed]
- Bone, D.; Bishop, S.L.; Black, M.P.; Goodwin, M.S.; Lord, C.; Narayanan, S.S. Use of Machine Learning to Improve Autism Screening and Diagnostic Instruments: Effectiveness, Efficiency, and Multi-Instrument Fusion. J. Child Psychol. Psychiatry 2016, 57, 927–937. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Lord, C.; Rutter, M.; DiLavore, P.C.; Risi, S.; Gotham, K.; Bishop, S.L. Autism Diagnostic Observation Schedule, (ADOS-2) Modules 1–4; Western Psychological Services: Los Angeles, CA, USA, 2012. [Google Scholar]
- Abbas, H.; Garberson, F.; Glover, E.; Wall, D.P. Machine Learning Approach for Early Detection of Autism by Combining Questionnaire and Home Video Screening. J. Am. Med. Inform. Assoc. Jamia 2018, 25, 1000–1007. [Google Scholar] [CrossRef] [Green Version]
- Tariq, Q.; Daniels, J.; Schwartz, J.N.; Washington, P.; Kalantarian, H.; Wall, D.P. Mobile Detection of Autism through Machine Learning on Home Video: A Development and Prospective Validation Study. PLoS Med. 2018, 15, e1002705. [Google Scholar] [CrossRef] [Green Version]
- Thabtah, F. ASDTests a Mobile App for ASD, Screening. 2017. Available online: https://www.asdtests.com/ (accessed on 22 March 2021).
- Thabtah, F.; Peebles, D. A New Machine Learning Model Based on Induction of Rules for Autism Detection. Health Inform. J. 2020, 26, 264–286. [Google Scholar] [CrossRef] [Green Version]
- Akter, T.; Satu, M.S.; Khan, M.I.; Ali, M.H.; Uddin, S.; Lio, P.; Quinn, J.M.; Moni, M.A. Machine Learning-Based Models for Early Stage Detection of Autism Spectrum Disorders. IEEE Access 2019, 7, 166509–166527. [Google Scholar] [CrossRef]
- Breiman, L. Random Forests. Mach. Learn. 2001, 45, 5–32. [Google Scholar] [CrossRef] [Green Version]
- Duda, R.O.; Hart, P.E.; Stork, D.G. Pattern Classification; John Wiley & Sons: New York, NY, USA, 2012. [Google Scholar]
- Vapnik, V.N. Statistical Learning Theory; Wiley: New York, NY, USA, 1998; Volume 1, p. 2. [Google Scholar]
- Peterson, L.E. K-Nearest Neighbor. Scholarpedia 2009, 4, 1883. [Google Scholar] [CrossRef]
- Kleinbaum, D.G.; Dietz, K.; Gail, M.; Klein, M.; Klein, M. Logistic Regression; Springer: Berlin, Germany, 2002. [Google Scholar]
- Staelin, C. Parameter Selection for Support Vector Machines; Hewlett-Packard Company: Palo Alto, CA, USA, 2002. [Google Scholar]
- Kohavi, R. A Study of Cross-Validation and Bootstrap for Accuracy Estimation and Model Selection. IJCAI 2001, 14, 1137–1145. [Google Scholar]
- Pedregosa, F.; Varoquaux, G.; Gramfort, A.; Michel, V.; Thirion, B.; Grisel, O.; Blondel, M.; Prettenhofer, P.; Weiss, R.; Dubourg, V.; et al. Scikit-Learn: Machine Learning in Python. J. Mach. Learn. Res. 2011, 12, 2825–2830. [Google Scholar]
- Sanz, H.; Valim, C.; Vegas, E.; Oller, J.M.; Reverter, F. SVM-RFE: Selection and Visualization of the Most Relevant Features through Non-Linear Kernels. BMC Bioinform. 2018, 19, 432. [Google Scholar] [CrossRef] [Green Version]
- Guyon, I.; Weston, J.; Barnhill, S.; Vapnik, V. Gene Selection for Cancer Classification Using Support Vector Machines. Mach. Learn. 2002, 46, 389–422. [Google Scholar] [CrossRef]
- Rivers, K.; Harpstead, E.; Koedinger, K. Learning Curve Analysis for Programming: Which Concepts Do Students Struggle With? In Proceedings of the 2016 ACM Conference on International Computing Education Research, Melbourne, VIC, Australia, 8–12 September 2016; pp. 143–151. [Google Scholar]
- Appendix: Signs and Symptoms of Possible Autism. Autism Spectrum Disorder in under 19s: Recognition, Referral and Diagnosis. Guidance. NICE. Available online: https://www.nice.org.uk/guidance/cg128/chapter/appendix-signs-and-symptoms-of-possible-autism (accessed on 10 February 2021).
- CDC Signs & Symptoms. Autism Spectrum Disorder (ASD). NCBDDD. CDC. Available online: https://www.cdc.gov/ncbddd/autism/signs.html (accessed on 10 February 2021).





{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Model (No. of Selected Features) | Parameters | Kernel | Min | Max | Steps | Scale |
|---|---|---|---|---|---|---|
| First Hyperparameter-Tuning Level | ||||||
| SVM(14) | C | linear, poly, rbf, sigmoid | 1 | 1000 | 10 | logarithmic |
| degree | poly | 2 | 9 | 1 | linear | |
| γ | poly, rbf, sigmoid | 0.001 | 1 | 10 | logarithmic | |
| Second Hyperparameter-Tuning Level | ||||||
| SVM(14) | C | rbf | 0.2 | 4 | 0.2 | linear |
| γ | rbf | 0.02 | 0.3 | 0.02 | linear | |
| Q-CHAT 14 Items (Ordered by Rank SVM–RFE) | Q-CHAT 10 Items (Allison Et Al.; Ordered By PPV) |
|---|---|
| Does your child look at you when you call their name? (1) | Does your child look at you when you call their name? (1) |
| How easy is it for you to have eye contact with your child? (2) | How easy is it for you to have eye contact with your child? (2) |
| Does your child use simple gestures (e.g., wave goodbye)? (19) | Does your child use simple gestures (e.g., wave goodbye)? (19) |
| Can other people easily understand your child’s speech? (4) | Would you describe your child’s first words as typical? (17) |
| Does your child point to indicate that they want something (e.g., a toy that is out of reach) (5) | Does your child point to indicate that they want something (e.g., a toy that is out of reach)? (5) |
| Does your child point to share interest with you (e.g., pointing at an interesting sight)? (6) | Does your child point to share interest with you (e.g., pointing at an interesting sight)? (6) |
| How long can your child’s interest be maintained by a spinning object (e.g., washing machine, electric fan, toy car wheels)? (7) | Does your child follow where you are looking? (10) |
| Does your child pretend (e.g., care for dolls, talk on a toy phone)? (9) | Does your child pretend (e.g., care for dolls, talk on a toy phone)? (9) |
| Does your child do the same thing over and over again (e.g., running the tap, turning the light switch on and off, opening and closing doors)? (16) | Does your child stare at nothing with no apparent purpose? (25) |
| Would you describe your child’s first words as typical? (17) | If you or someone else in the family is visibly upset, does your child show signs of wanting to comfort them? (e.g., stroking their hair, hugging them)? (15) |
| When your child is playing alone, do they line objects up? (3) | |
| Does your child stare at nothing with no apparent purpose? (25) | |
| Does your child echo things they hear (e.g., things that you say, lines from songs or movies, sounds)? (18) | |
| How long can your child’s interest be maintained by just one or two objects? (22) |
| Model (No. of Selected Features) | Accuracy | Classes | PPV | Sensitivity | F1 Score | No. of Subjects for Clinical Validation |
|---|---|---|---|---|---|---|
| SVM (25) | 0.95 (± 0.02) | ASD | 1.00 | 0.90 (±0.04) | 0.95 (±0.03) | 24 |
| TD | 0.91 (±0.04) | 1.00 | 0.96 (±0.03) | 28 | ||
| SVM (14) | 0.91 (± 0.02) | ASD | 0.95 (±0.03) | 0.86 (±0.01) | 0.90 (±0.02) | 24 |
| TD | 0.86 (±0.01) | 0.95 (±0.03) | 0.90 (±0.02) | 28 | ||
| SVM (10; Allison et al.) | 0.87 (± 0.03) | ASD | 0.79 (±0.03) | 0.65 (±0.04) | 0.71 (±0.03) | 24 |
| TD | 0.76 (±0.04) | 0.86 (±0.03) | 0.81 (±0.03) | 28 | ||
| SVM (3) | 0.83 (± 0.05) | ASD | 0.90 (±0.07) | 0.78 (±0.07) | 0.84 (±0.04) | 24 |
| TD | 0.84 (±0.06) | 0.93 (±0.07) | 0.89 (±0.06) | 28 | ||
| RF (25) | 0.90 (± 0.06) | ASD | 0.89 (±0.05) | 0.74 (±0.08) | 0.81 (±0.07) | 24 |
| TD | 0.82 (±0.07) | 0.93 (±0.06) | 0.87 (±0.06) | 28 | ||
| RF (14) | 0.88 (± 0.04) | ASD | 0.86 (±0.04) | 0.83 (±0.06) | 0.84 (±0.05) | 24 |
| TD | 0.87 (±0.05) | 0.90 (±0.04) | 0.88 (±0.04) | 28 | ||
| RF (10; Allison et al.) | 0.84 (± 0.03) | ASD | 0.89 (±0.07) | 0.70 (±0.06) | 0.78 (±0.06) | 24 |
| TD | 0.79 (±0.05) | 0.93 (±0.06) | 0.86 (±0.06) | 28 | ||
| RF (3) | 0.83 (± 0.05) | ASD | 0.83 (±0.06) | 0.83 (±0.05) | 0.83 (±0.06) | 24 |
| TD | 0.86 (±0.05) | 0.86 (±0.06) | 0.86 (±0.06) | 28 | ||
| NB (25) | 0.89 (± 0.04) | ASD | 1.00 | 0.70 (±0.02) | 0.82 (±0.01) | 24 |
| TD | 0.81 (±0.02) | 1.00 | 0.89 (±0.01) | 28 | ||
| NB (14) | 0.88 (± 0.04) | ASD | 1.00 | 0.74 (±0.02) | 0.85 (±0.01) | 24 |
| TD | 0.83 (±0.02) | 1.00 | 0.91 (±0.01) | 28 | ||
| NB (10; Allison et al.) | 0.82 (± 0.03) | ASD | 1.00 | 0.65 (±0.02) | 0.79 (±0.01) | 24 |
| TD | 0.78 (±0.02) | 1.00 | 0.88 (±0.01) | 28 | ||
| NB (3) | 0.84 (± 0.03) | ASD | 0.82 (±0.07) | 0.78 (±0.05) | 0.80 (±0.06) | 24 |
| TD | 0.83 (±0.06) | 0.86 (±0.06) | 0.85 (±0.06) | 28 | ||
| KNN(25) | 0.83 (± 0.03) | ASD | 0.95 (±0.03) | 0.71 (±0.05) | 0.81 (±0.03) | 24 |
| TD | 0.75 (±0.03) | 0.96 (±0.02) | 0.84 (±0.02) | 28 | ||
| KNN(14) | 0.85 (± 0.04) | ASD | 0.98 (±0.02) | 0.73 (±0.08) | 0.84 (±0.05) | 24 |
| TD | 0.77 (±0.05) | 0.98 (±0.02) | 0.86 (±0.03) | 28 | ||
| KNN(10; Allison et al.) | 0.83 (± 0.03) | ASD | 0.90 (±0.05) | 0.76 (±0.04) | 0.83 (±0.03) | 24 |
| TD | 0.77 (±0.04) | 0.91 (±0.05) | 0.83 (±0.03) | 28 | ||
| KNN (3) | 0.66 (± 0.05) | ASD | 0.62 (±0.03) | 0.90 (±0.05) | 0.73 (±0.03) | 24 |
| TD | 0.77 (±0.03) | 0.39 (±0.07) | 0.52 (±0.08) | 28 | ||
| LR(25) | 0.89 (± 0.03) | ASD | 0.92 (±0.05) | 0.87 (±0.05) | 0.89 (±0.03) | 24 |
| TD | 0.87 (±0.05) | 0.91 (±0.06) | 0.88 (±0.03) | 28 | ||
| LR (14) | 0.90 (± 0.02) | ASD | 0.93 (±0.03) | 0.87 (±0.03) | 0.90 (±0.02) | 24 |
| TD | 0.87 (±0.03) | 0.93 (±0.03) | 0.90 (±0.02) | 28 | ||
| LR (10; Allison et al.) | 0.88 (± 0.03) | ASD | 0.92 (±0.04) | 0.84 (±0.06) | 0.88 (±0.03) | 24 |
| TD | 0.84 (±0.05) | 0.91 (±0.05) | 0.87 (±0.03) | 28 | ||
| LR (3) | 0.84 (± 0.05) | ASD | 0.84 (±0.05) | 0.87 (±0.06) | 0.85 (±0.04) | 24 |
| TD | 0.84 (±0.06) | 0.81 (±0.08) | 0.82 (±0.06) | 28 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Tartarisco, G.; Cicceri, G.; Di Pietro, D.; Leonardi, E.; Aiello, S.; Marino, F.; Chiarotti, F.; Gagliano, A.; Arduino, G.M.; Apicella, F.; et al. Use of Machine Learning to Investigate the Quantitative Checklist for Autism in Toddlers (Q-CHAT) towards Early Autism Screening. Diagnostics 2021, 11, 574. https://doi.org/10.3390/diagnostics11030574
Tartarisco G, Cicceri G, Di Pietro D, Leonardi E, Aiello S, Marino F, Chiarotti F, Gagliano A, Arduino GM, Apicella F, et al. Use of Machine Learning to Investigate the Quantitative Checklist for Autism in Toddlers (Q-CHAT) towards Early Autism Screening. Diagnostics. 2021; 11(3):574. https://doi.org/10.3390/diagnostics11030574
Chicago/Turabian StyleTartarisco, Gennaro, Giovanni Cicceri, Davide Di Pietro, Elisa Leonardi, Stefania Aiello, Flavia Marino, Flavia Chiarotti, Antonella Gagliano, Giuseppe Maurizio Arduino, Fabio Apicella, and et al. 2021. "Use of Machine Learning to Investigate the Quantitative Checklist for Autism in Toddlers (Q-CHAT) towards Early Autism Screening" Diagnostics 11, no. 3: 574. https://doi.org/10.3390/diagnostics11030574