
ASCU-Net: Attention Gate, Spatial and Channel Attention U-Net for Skin Lesion Segmentation


Abstract
:1. Introduction
1.1. General Background
- (1)
- A new Attention Gate, Spatial and Channel Attention U-Net (ASCU-Net) model was proposed for the accurate segmentation of skin lesions in dermoscopic images. A convolutional multi-attentive module was used to extract the image features and generate resultant maps of skin lesion segmentation.
- (2)
- The multiple attention learning mechanism of the triple attention decoding block was ingeniously designed. The module embeds AG, spatial, and channel attention modules to further improve the feature representation capability, and the U-Net network built on this module significantly improved the performance of skin lesion segmentation. The effectiveness of the triple attention decoder block was verified by an ablation study.
- (3)
- The performance of the ASCU-Net segmentation method was compared with other algorithms on the ISIC-2016 [19] and ISIC-2017 datasets [20], with significant improvements in six evaluation metrics including accuracy, sensitivity, specificity, precision, dice coefficient, and Jaccard index. In addition, to verify the reliability and applicability of the network, the network trained on the ISIC-2017 dataset was put to test on another publicly available dataset named PH2 [21].
1.2. Related Works
1.2.1. Skin Lesion Segmentation
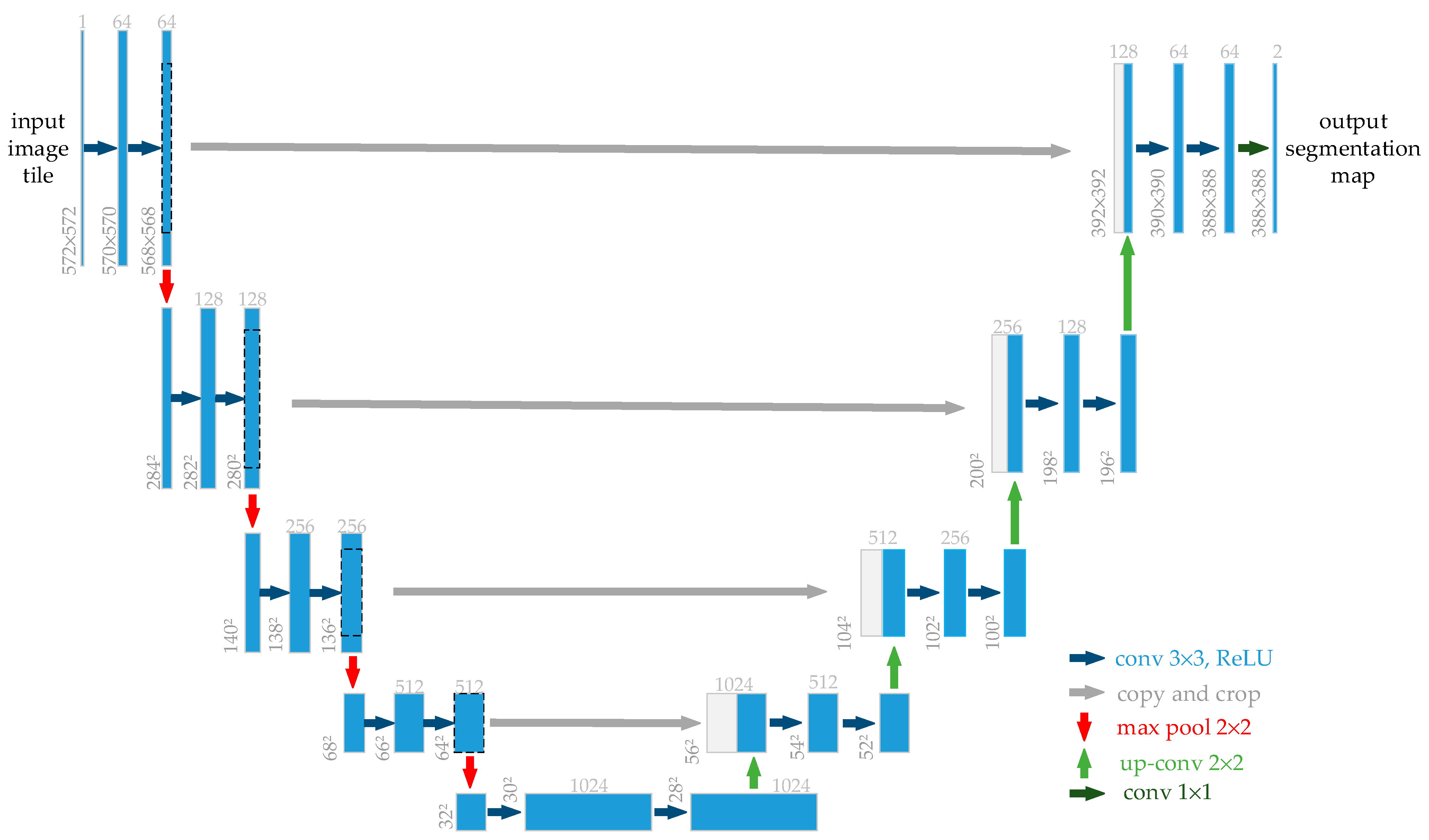
1.2.2. Overview of U-Net Architecture
1.2.3. Attention Mechanism
2. Materials and Methods
2.1. Proposed ASCU-Net Architecture
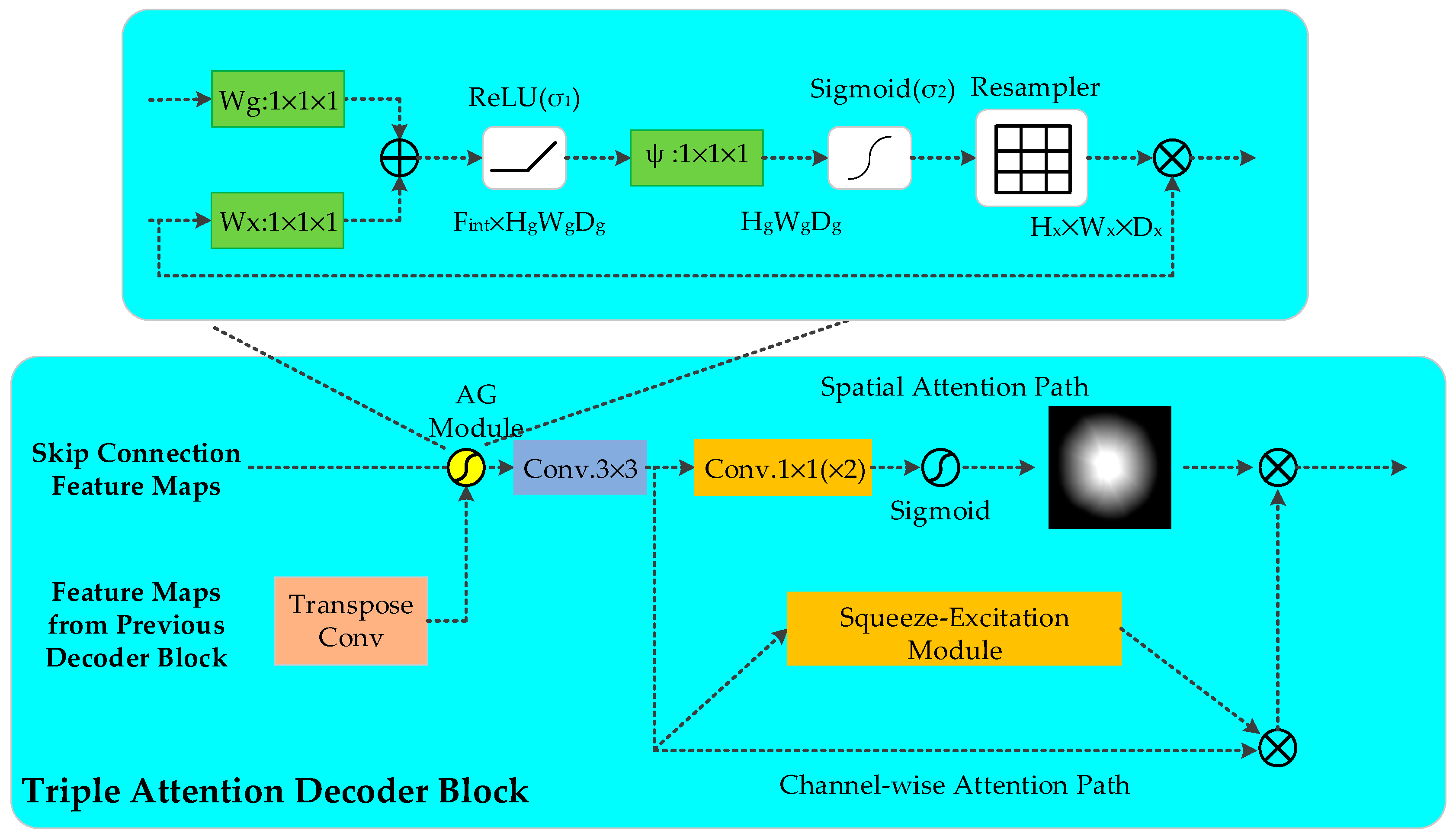
2.2. Triple Attention Decoder Block
2.2.1. Attention Gate
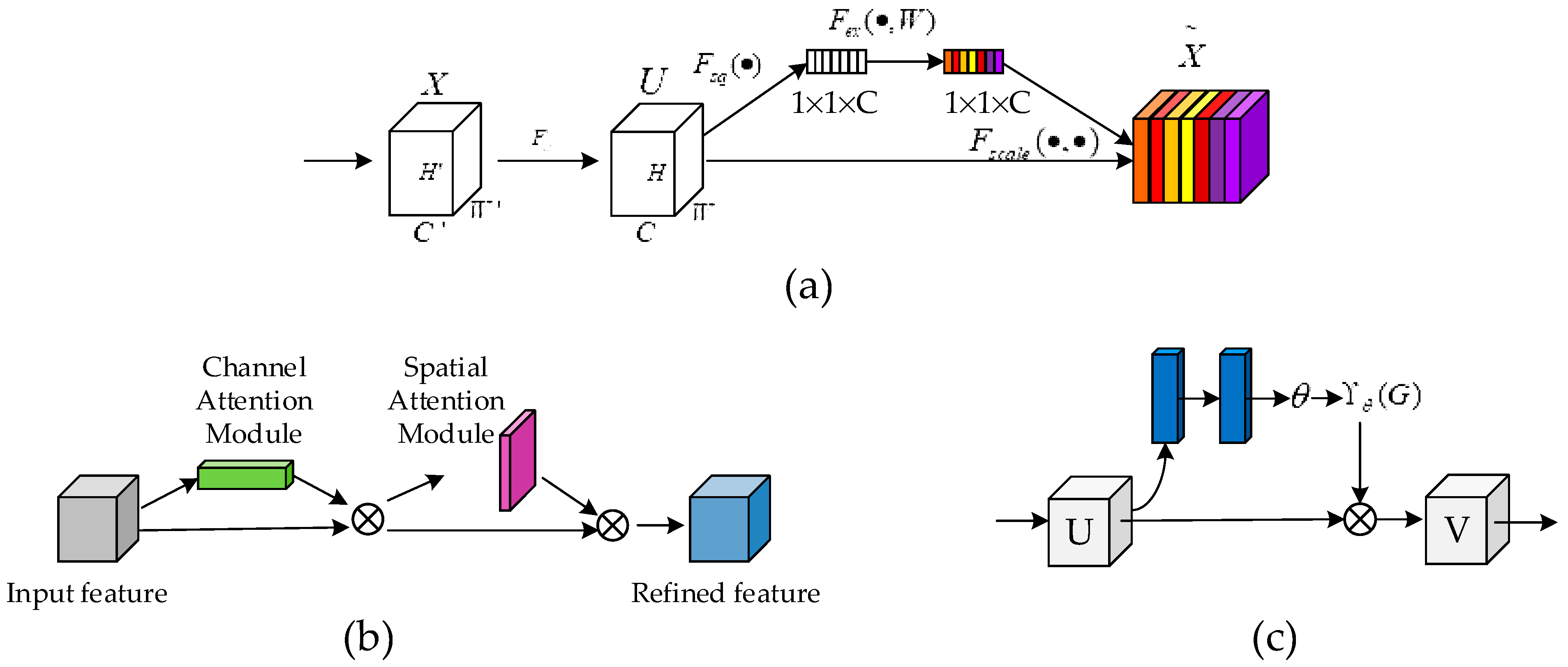
2.2.2. Spatial Attention Module
2.2.3. Channel Attention Module
2.2.4. Channel and Spatial Attention
2.3. Loss Function
3. Experiments and Results
3.1. Performance Evaluation Metrics
3.2. Experimental Setups
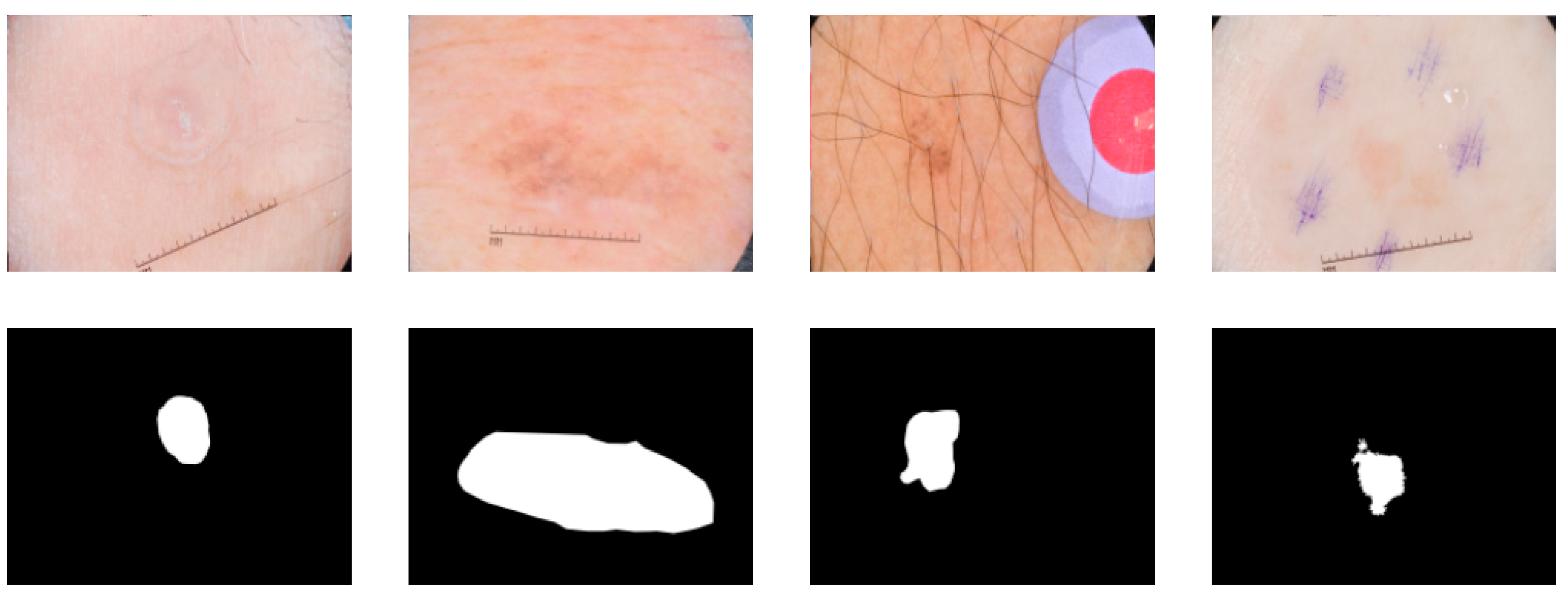
3.2.1. Dataset
3.2.2. Implementation Details
3.3. Comparative Experiment
3.3.1. Comparison on the ISIC-2016 Dataset
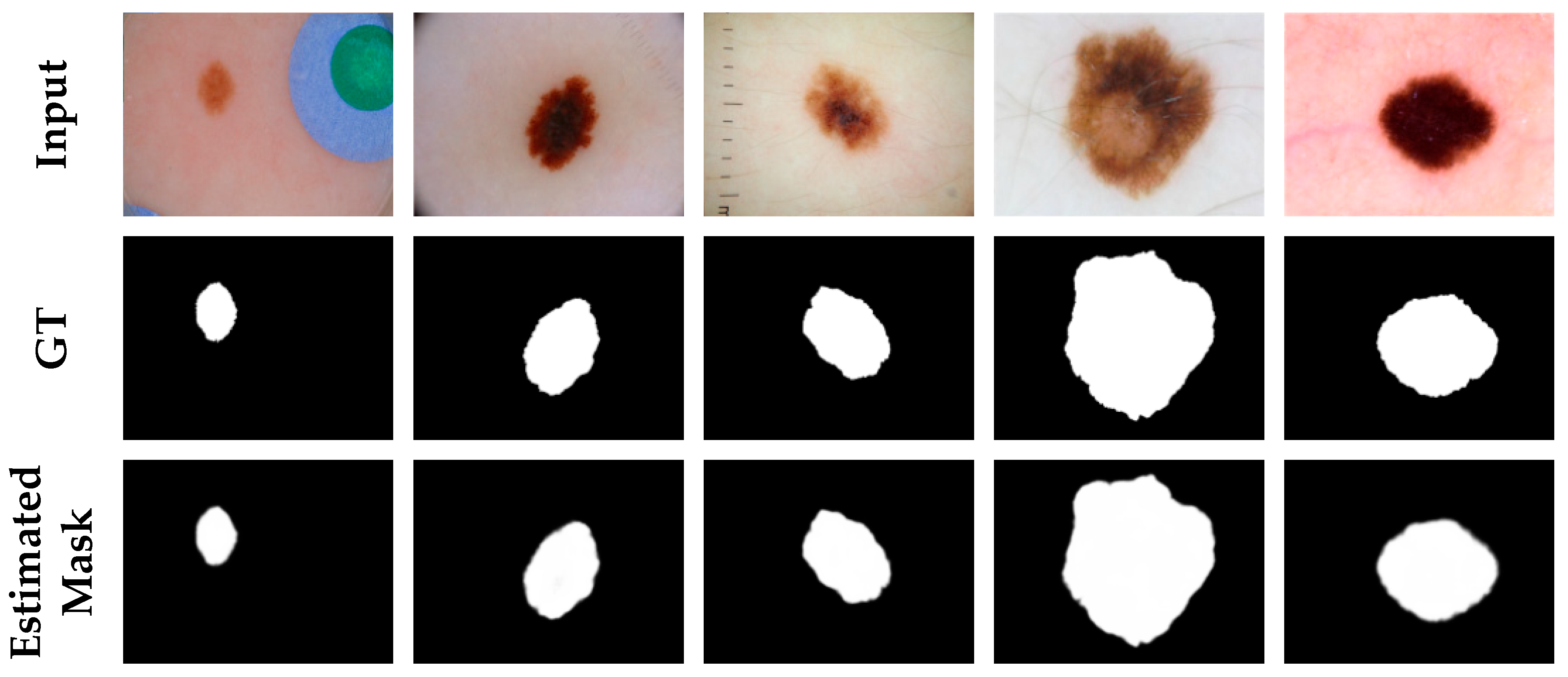
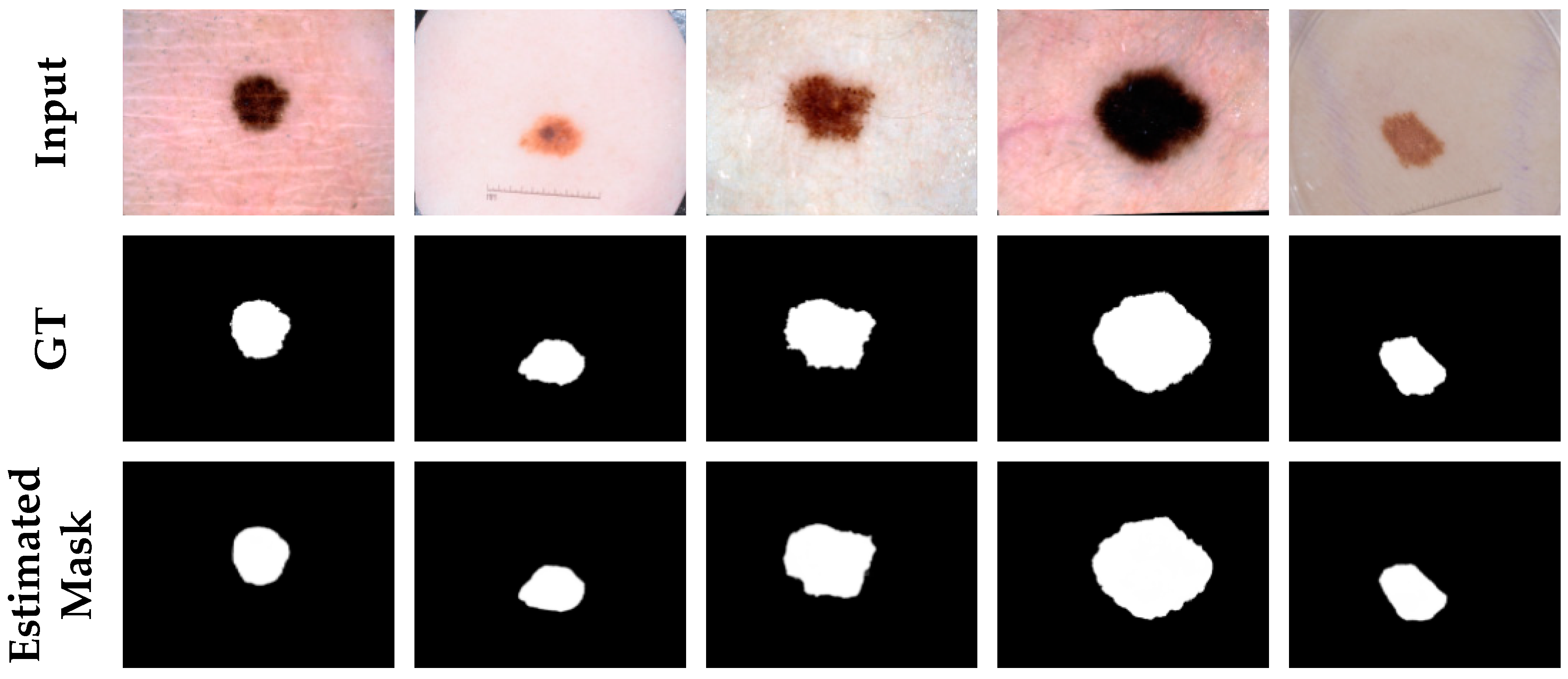
3.3.2. Comparison on the ISIC-2017 Dataset
3.3.3. Comparison on the PH2 Dataset
3.4. Ablation Experiment
4. Discussion
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Siegel, R.; Miller, K.; Jemal, A. Cancer statistics, 2019. CA Cancer J. Clin. 2019, 69, 7–34. [Google Scholar] [CrossRef] [Green Version]
- Radiation: Ultraviolet (UV) Radiation and Skin Cancer. Available online: Who.int/uv/faq/skincancer/en/index1.html (accessed on 1 January 2017).
- Mahbod, A.; Ecker, R.; Ellinger, I. Skin Lesion Classification Using Hybrid Deep Neural Networks. In Proceedings of the ICASSP 2019—2019 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Brighton, UK, 12–17 May 2019; pp. 1229–1233. [Google Scholar]
- Yu, L.; Chen, H.; Dou, Q.; Qin, J.; Heng, P. Automated Melanoma Recognition in Dermoscopy Images via Very Deep Residual Networks. IEEE Trans. Med. Imaging 2017, 36, 994–1004. [Google Scholar] [CrossRef]
- Xie, Y.; Zhang, J.; Xia, Y.; Shen, C. A Mutual Bootstrapping Model for Automated Skin Lesion Segmentation and Classification. IEEE Trans. Med. Imaging 2020, 39, 2482–2493. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Ahn, E.; Kim, J.; Bi, L.; Kumar, A.; Li, C.; Fulham, M.; Feng, D. Saliency-Based Lesion Segmentation Via Background Detection in Dermoscopic Images. IEEE J. Biomed. Health Inform. 2017, 21, 1685–1693. [Google Scholar] [CrossRef] [PubMed]
- Li, H.; He, X.; Zhou, F.; Yu, Z.; Ni, D.; Chen, S.; Wang, T.; Lei, B. Dense Deconvolutional Network for Skin Lesion Segmentation. IEEE J. Biomed. Health Inform. 2019, 23, 527–537. [Google Scholar] [CrossRef] [PubMed]
- Wang, S.; Sun, J.; Mehmood, I.; Pan, C.; Chen, Y.; Zhang, Y. Cerebral micro bleeding identification based on a nin-layer convolutional neural network with stochastic pooling. Concurr. Comput. Pract. Exp. 2020, 32, e5130. [Google Scholar] [CrossRef]
- Ronneberger, O.; Fischer, P.; Brox, T. U-Net: Convolutional Networks for Biomedical Image Segmentation. arXiv 2015, arXiv:1505.04597. [Google Scholar]
- Oktay, O.; Schlemper, J.; Folgoc, L.L.; Lee, M.J.; Heinrich, M.; Misawa, K.; Mori, K.; McDonagh, S.G.; Hammerla, N.; Kainz, B.; et al. Attention U-Net: Learning Where to Look for the Pancreas. arXiv 2018, arXiv:1804.03999. [Google Scholar]
- Guo, Y.; Stein, J.; Wu, G.; Krishnamurthy, A. SAU-Net: A Universal Deep Network for Cell Counting. In Proceedings of the 10th ACM International Conference on Bioinformatics, Computational Biology and Health Informatics (ACM-BCB ’19), Niagara Falls, NY, USA, 7–10 September 2019; p. 8. [Google Scholar]
- Chen, Y.; Wang, K.; Liao, X.; Qian, Y.; Wang, Q.; Yuan, Z.; Heng, P. Channel-Unet: A Spatial Channel-Wise Convolutional Neural Network for Liver and Tumors Segmentation. Front. Genet. 2019, 10, 1110. [Google Scholar] [CrossRef] [Green Version]
- Huang, G.; Liu, Z.; Weinberger, K.Q. Densely Connected Convolutional Networks. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 2261–2269. [Google Scholar]
- Wang, H.; Wang, G.; Sheng, Z.; Zhang, S. Automated Segmentation of Skin Lesion Based on Pyramid Attention Network. In Proceedings of the MLMI 2019, Shenzhen, China, 13 October 2019; pp. 435–443. [Google Scholar]
- Sinha, A.; Dolz, J. Multi-scale guided attention for medical image segmentation. arXiv 2019, arXiv:1906.02849. [Google Scholar] [CrossRef] [Green Version]
- Sun, J.; Darbeha, F.; Zaidi, M.; Wang, B. SAUNet: Shape Attentive U-Net for Interpretable Medical Image Segmentation. arXiv 2020, arXiv:2001.07645. [Google Scholar]
- Xu, K.; Ba, J.; Kiros, R.; Cho, K.; Courville, A.C.; Salakhutdinov, R.; Zemel, R.; Bengio, Y. Show, Attend and Tell: Neural Image Caption Generation with Visual Attention. arXiv 2015, arXiv:1502.03044. [Google Scholar]
- Hu, J.; Shen, L.; Albanie, S.; Sun, G.; Wu, E. Squeeze-and-Excitation Networks. IEEE Trans. Pattern Anal. Mach. Intell. 2020, 42, 2011–2023. [Google Scholar] [CrossRef] [Green Version]
- Gutman, D.C.; Codella, N.C.F.; Celebi, M.E.; Helba, B.; Marchetti, M.; Mishra, N.; Halpern, A. Skin Lesion Analysis toward Melanoma Detection: A Challenge at the International Symposium on Biomedical Imaging (ISBI) 2016, hosted by the International Skin Imaging Collaboration (ISIC). arXiv 2016, arXiv:1605.01397. [Google Scholar]
- Codella, N.; Gutman, D.; Celebi, M.E.; Helba, B.; Marchetti, M.A.; Dusza, S.; Kalloo, A.; Liopyris, K.; Mishra, N.; Kittler, H.; et al. Skin lesion analysis toward melanoma detection: A challenge at the 2017 International symposium on biomedical imaging (ISBI), hosted by the international skin imaging collaboration (ISIC). In Proceedings of the 2018 IEEE 15th International Symposium on Biomedical Imaging (ISBI 2018), Washington, DC, USA, 4–7 April 2018; pp. 168–172. [Google Scholar]
- Mendonça, T.; Ferreira, P.; Marques, J.; Marçal, A.; Rozeira, J. PH2—A dermoscopic image database for research and benchmarking. In Proceedings of the 2013 35th Annual International Conference of the IEEE Engineering in Medicine and Biology Society (EMBC), Osaka, Japan, 3–7 July 2013; pp. 5437–5440. [Google Scholar]
- Korotkov, K.; García, R. Computerized analysis of pigmented skin lesions: A review. Artif. Intell. Med. 2012, 56, 69–90. [Google Scholar] [CrossRef] [PubMed]
- Erkol, B.; Moss, R.; Stanley, R.J.; Stoecker, W.V.; Hvatum, E. Automatic lesion boundary detection in dermoscopy images using gradient vector flow snakes. Ski. Res. Technol. 2005, 11, 17–26. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Ma, Z.; Tavares, J. A Novel Approach to Segment Skin Lesions in Dermoscopic Images Based on a Deformable Model. IEEE J. Biomed. Health Inform. 2016, 20, 615–623. [Google Scholar] [CrossRef] [Green Version]
- Schmid, P. Lesion detection in dermatoscopic images using anisotropic diffusion and morphological flooding. In Proceedings of the 1999 International Conference on Image Processing (Cat. 99CH36348), Kobe, Japan, 24–28 October 1999; Volume 3, pp. 449–453. [Google Scholar]
- Fleming, M.G.; Steger, C.; Zhang, J.; Gao, J.; Cognetta, A.; Pollak, I.; Dyer, C. Techniques for a structural analysis of dermatoscopic imagery. Comput. Med. Imaging Graph 1998, 22, 375–389. [Google Scholar] [CrossRef]
- Celebi, M.E.; Iyatomi, H.; Schaefer, G.; Stoecker, W.V. Lesion border detection in dermoscopy images. Comput. Med. Imaging Graph 2009, 33, 148–153. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Yuan, Y.; Lo, Y. Improving Dermoscopic Image Segmentation with Enhanced Convolutional-Deconvolutional Networks. IEEE J. Biomed. Health Inform. 2019, 23, 519–526. [Google Scholar] [CrossRef] [Green Version]
- Yuan, Y.; Chao, M.; Lo, Y.C. Automatic Skin Lesion Segmentation Using Deep Fully Convolutional Networks With Jaccard Distance. IEEE Trans. Med. Imaging 2017, 36, 1876–1886. [Google Scholar] [CrossRef] [PubMed]
- Yu, Z.; Jiang, X.; Zhou, F.; Qin, J.; Ni, D.; Chen, S.; Lei, B.; Wang, T. Melanoma Recognition in Dermoscopy Images via Aggregated Deep Convolutional Features. IEEE Trans. Biomed. Eng. 2019, 66, 1006–1016. [Google Scholar] [CrossRef] [PubMed]
- Song, L.; Lin, J.; Wang, Z.; Wang, H. Dense-Residual Attention Network for Skin Lesion Segmentation. In Proceedings of the MLMI 2019, Shenzhen, China, 13 October 2019; pp. 319–327. [Google Scholar]
- Vesal, S.; Ravikumar, N.; Maier, A. SkinNet: A Deep Learning Framework for Skin Lesion Segmentation. In Proceedings of the 2018 IEEE Nuclear Science Symposium and Medical Imaging Conference Proceedings (NSS/MIC), Sydney, Australia, 10–17 November 2018; pp. 1–3. [Google Scholar]
- Bi, L.; Feng, D.; Kim, J. Improving Automatic Skin Lesion Segmentation using Adversarial Learning based Data Augmentation. arXiv 2018, arXiv:1807.08392. [Google Scholar]
- Bi, L.; Kim, J.; Ahn, E.; Kumar, A.; Fulham, M.; Feng, D. Dermoscopic Image Segmentation via Multistage Fully Convolutional Networks. IEEE Trans. Biomed. Eng. 2017, 64, 2065–2074. [Google Scholar] [CrossRef] [Green Version]
- Hasan, M.; Dahal, L.; Samarakoon, P.; Tushar, F.I.; Marly, R.M. DSNet: Automatic Dermoscopic Skin Lesion Segmentation. Comput. Biol. Med. 2020, 120, 103738. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Adegun, A.A.; Viriri, S. FCN-Based DenseNet Framework for Automated Detection and Classification of Skin Lesions in Dermoscopy Images. IEEE Access 2020, 8, 150377–150396. [Google Scholar] [CrossRef]
- Long, J.; Shelhamer, E.; Darrell, T. Fully convolutional networks for semantic segmentation. In Proceedings of the 2015 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Boston, MA, USA, 7–12 June 2015; pp. 3431–3440. [Google Scholar]
- Badrinarayanan, V.; Kendall, A.; Cipolla, R. SegNet: A Deep Convolutional Encoder-Decoder Architecture for Image Segmentation. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 2481–2495. [Google Scholar] [CrossRef]
- Drozdzal, M.; Vorontsov, E.; Chartrand, G.; Kadoury, S.; Pal, C. The Importance of Skip Connections in Biomedical Image Segmentation. arXiv 2016, arXiv:1608.04117. [Google Scholar]
- Wei, Z.; Song, H.; Chen, L.; Li, Q.; Han, G. Attention-Based DenseUnet Network With Adversarial Training for Skin Lesion Segmentation. IEEE Access 2019, 7, 136616–136629. [Google Scholar] [CrossRef]
- Ibtehaz, N.; Rahman, M.S. MultiResUNet: Rethinking the U-Net Architecture for Multimodal Biomedical Image Segmentation. Neural Netw. 2020, 121, 74–87. [Google Scholar] [CrossRef] [PubMed]
- Itti, L.; Koch, C.; Niebur, E. A Model of Saliency-Based Visual Attention for Rapid Scene Analysis. IEEE Trans. Pattern Anal. Mach. Intell. 2009, 20, 1254–1259. [Google Scholar] [CrossRef] [Green Version]
- Rensink, R.A. Visual Search for Change: A Probe into the Nature of Attentional Processing. Vis. Cogn. 2000, 7, 345–376. [Google Scholar] [CrossRef] [Green Version]
- Corbetta, M.; Shulman, G. Control of goal-directed and stimulus-driven attention in the brain. Nat. Rev. Neurosci. 2002, 3, 201–215. [Google Scholar] [CrossRef]
- Mnih, V.; Heess, N.; Graves, A.; Kavukcuoglu, K. Recurrent Models of Visual Attention. arXiv 2014, arXiv:1406.6247. [Google Scholar]
- Kaul, C.; Manandhar, S.; Pears, N. Focusnet: An Attention-Based Fully Convolutional Network for Medical Image Segmentation. In Proceedings of the 2019 IEEE 16th International Symposium on Biomedical Imaging (ISBI 2019), Venice, Italy, 8–11 April 2019; pp. 455–458. [Google Scholar]
- Woo, S.; Park, J.; Lee, J.-Y.; Kweon, I.-S. CBAM: Convolutional Block Attention Module. arXiv 2018, arXiv:1807.06521v2. [Google Scholar]
- Jaderberg, M.; Simonyan, K.; Zisserman, A.; Kavukcuoglu, K. Spatial Transformer Networks. arXiv 2015, arXiv:1506.02025. [Google Scholar]
- Kang, C.; Yu, X.; Wang, S.; Guttery, D.; Pandey, H.M.; Tian, Y.; Zhang, Y. A Heuristic Neural Network Structure Relying on Fuzzy Logic for Images Scoring. IEEE Trans. Fuzzy Syst. 2020, 29, 34–45. [Google Scholar] [CrossRef]
- Jetley, S.; Lord, N.; Lee, N.; Torr, P. Learn To Pay Attention. arXiv 2018, arXiv:1804.02391. [Google Scholar]
- Wang, X.; Girshick, R.B.; Gupta, A.; He, K. Non-local Neural Networks. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 7794–7803. [Google Scholar]
- Al-Masni, M.A.; Al-antari, M.A.; Choi, M.-T.; Han, S.-M.; Kim, T.-S. Skin lesion segmentation in dermoscopy images via deep full resolution convolutional networks. Comput. Methods Programs Biomed. 2018, 162, 221–231. [Google Scholar] [CrossRef] [PubMed]
- Goyal, M.; Yap, M.H. Multi-class Semantic Segmentation of Skin Lesions via Fully Convolutional Networks. arXiv 2020, arXiv:1711.10449. [Google Scholar]
- Powers, D. Evaluation: From precision, recall and F-measure to ROC, informedness, markedness and correlation. arXiv 2020, arXiv:2010.16061. [Google Scholar]
- Zhou, Z.; Siddiquee, M.M.R.; Tajbakhsh, N.; Liang, J. UNet++: A Nested U-Net Architecture for Medical Image Segmentation. arXiv 2018, arXiv:1807.10165. [Google Scholar]
- Alom, M.; Hasan, M.; Yakopcic, C.; Taha, T.; Asari, V. Recurrent Residual Convolutional Neural Network based on U-Net (R2U-Net) for Medical Image Segmentation. arXiv 2018, arXiv:1802.06955. [Google Scholar]










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Datasets | ISIC-2016 | ISIC-2017 | PH2 |
|---|---|---|---|
| Obtained from | ISIC | ISIC | Hospital Pedro Hispano, Portugal. |
| Total number | 1279 | 2750 | 200 |
| Train/Test number | 900/379 | 2150/600 | 0/200 |
| Resolution (pixel) | 576 × 768 to 2848 × 4288 | 540 × 722 to 4499 × 6748 | 560 × 768 |
| Augmentation methods | Horizontal-vertical flip | Only for testing | |
| Methods | Performance Evaluation Metrics | |||||
|---|---|---|---|---|---|---|
| AC | SE | SP | PC | F1 | JS | |
| U-Net [9] | 0.943 | 0.907 | 0.962 | 0.895 | 0.887 | 0.812 |
| Attention U-Net [10] | 0.944 | 0.908 | 0.963 | 0.890 | 0.886 | 0.811 |
| U-Net++ [55] | 0.943 | 0.903 | 0.964 | 0.901 | 0.889 | 0.815 |
| Recurrent U-Net [56] | 0.937 | 0.896 | 0.965 | 0.884 | 0.874 | 0.793 |
| Ours | 0.954 | 0.927 | 0.961 | 0.915 | 0.908 | 0.845 |
| Methods | Performance Evaluation Metrics | |||||
|---|---|---|---|---|---|---|
| AC | SE | SP | PC | F1 | JS | |
| U-Net [9] | 0.913 | 0.762 | 0.976 | 0.887 | 0.781 | 0.687 |
| Attention U-Net [10] | 0.913 | 0.765 | 0.976 | 0.889 | 0.783 | 0.692 |
| U-Net++ [55] | 0.912 | 0.749 | 0.979 | 0.900 | 0.777 | 0.685 |
| Recurrent U-Net [56] | 0.905 | 0.816 | 0.953 | 0.782 | 0.754 | 0.643 |
| Ours | 0.926 | 0.825 | 0.965 | 0.897 | 0.830 | 0.742 |
| Methods | Performance Evaluation Metrics | |||||
|---|---|---|---|---|---|---|
| AC | SE | SP | PC | F1 | JS | |
| U-Net [9] | 0.910 | 0.885 | 0.959 | 0.899 | 0.873 | 0.794 |
| Attention U-Net [10] | 0.916 | 0.899 | 0.958 | 0.895 | 0.880 | 0.802 |
| U-Net++ [55] | 0.909 | 0.883 | 0.960 | 0.900 | 0.873 | 0.794 |
| Recurrent U-Net [56] | 0.919 | 0.926 | 0.945 | 0.867 | 0.882 | 0.800 |
| Ours | 0.943 | 0.960 | 0.937 | 0.877 | 0.909 | 0.842 |
| Methods | Attention Mechanism | Performance Evaluation Metrics | |||||||
|---|---|---|---|---|---|---|---|---|---|
| AG | Spatial Attention | Channel Attention | AC | SE | SP | PC | F1 | JS | |
| No-attention | × | × | × | 0.912 | 0.764 | 0.973 | 0.881 | 0.778 | 0.681 |
| single-AG | √ | × | × | 0.923 | 0.795 | 0.976 | 0.910 | 0.816 | 0.726 |
| single-spatial | × | √ | × | 0.911 | 0.757 | 0.976 | 0.889 | 0.775 | 0.681 |
| single-channel | × | × | √ | 0.910 | 0.755 | 0.977 | 0.887 | 0.774 | 0.678 |
| AG + channel | √ | × | √ | 0.925 | 0.819 | 0.973 | 0.897 | 0.825 | 0.737 |
| AG + spatial | √ | √ | × | 0.910 | 0.753 | 0.978 | 0.892 | 0.776 | 0.682 |
| Spatial + channel | × | √ | √ | 0.924 | 0.798 | 0.977 | 0.914 | 0.822 | 0.734 |
| Ours | √ | √ | √ | 0.926 | 0.825 | 0.965 | 0.897 | 0.830 | 0.742 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Tong, X.; Wei, J.; Sun, B.; Su, S.; Zuo, Z.; Wu, P. ASCU-Net: Attention Gate, Spatial and Channel Attention U-Net for Skin Lesion Segmentation. Diagnostics 2021, 11, 501. https://doi.org/10.3390/diagnostics11030501
Tong X, Wei J, Sun B, Su S, Zuo Z, Wu P. ASCU-Net: Attention Gate, Spatial and Channel Attention U-Net for Skin Lesion Segmentation. Diagnostics. 2021; 11(3):501. https://doi.org/10.3390/diagnostics11030501
Chicago/Turabian StyleTong, Xiaozhong, Junyu Wei, Bei Sun, Shaojing Su, Zhen Zuo, and Peng Wu. 2021. "ASCU-Net: Attention Gate, Spatial and Channel Attention U-Net for Skin Lesion Segmentation" Diagnostics 11, no. 3: 501. https://doi.org/10.3390/diagnostics11030501