Statistical Physics for Medical Diagnostics: Learning, Inference, and Optimization Algorithms


Abstract
:1. Introduction
2. Disease Definition and Classification
3. The Need for Deeper Probabilistic Models
4. Search for an Optimal Diagnostic Strategy
5. Future Perspectives
5.1. Diagnosis through Simulation of Disease Evolution
5.2. Quantum Algorithms
6. Conclusions and Challenges
Author Contributions
Funding
Conflicts of Interest
References
- Lynch, C.J.; Liston, C. New machine-learning technologies for computer-aided diagnosis. Nat. Med. 2018, 24, 13041305. [Google Scholar] [CrossRef] [PubMed]
- Wainberg, M.; Merico, D.; Delong, A.; Frey, B.J. Deep learning in biomedicine. Nat. Biotechnol. 2018, 36, 829838. [Google Scholar] [CrossRef] [PubMed]
- Yu, K.H.; Beam, A.L.; Kohane, I.S. Artificial intelligence in healthcare. Nat. Biomed. Eng. 2018, 2, 719731. [Google Scholar] [CrossRef] [PubMed]
- Topol, E.J. High-performance medicine: the convergence of human and artificial intelligence. Nat. Med. 2019, 25, 4456. [Google Scholar] [CrossRef] [PubMed]
- Kelly, C.J.; Karthikesalingam, A.; Suleyman, M.; Corrado, G.; King, D. Key challenges for delivering clinical impact with artificial intelligence. BMC Med. 2019, 17, 195. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Ledley, R.S.; Lusted, L.B. Reasoning foundations of medical diagnosis. Science 1959, 130, 9–21. [Google Scholar] [CrossRef]
- Miller, R.A.; Geissbuhler, A. Clinical diagnostic decision support systems—An overview. In Clinical Decision Support Systems; Springer: New York, NY, USA, 1999; pp. 3–34. [Google Scholar]
- Greenes, R. Clinical Decision Support, The Road to Broad Adoption, 2nd ed.; Academic Press: Cambridge, MA, USA, 2014. [Google Scholar]
- Papadakis, M.; McPhee, S.J.; Rabow, M.W. Current Medical Diagnosis and Treatment, 55th ed.; LANGE CURRENT Series; McGraw-Hill Education: New York, NY, USA, 2016; 1920p, ISBN 0071845097. [Google Scholar]
- Bhalla, U.S.; Iyengar, R. Emergent properties of networks of biological signaling pathways. Science 1999, 283, 381–387. [Google Scholar] [CrossRef] [Green Version]
- Kremling, A.; Jahreis, K.; Lengeler, J.W.; Gilles, E.D. The organization of metabolic reaction networks: A signal-oriented approach to cellular models. Metab. Eng. 2000, 2, 190–200. [Google Scholar] [CrossRef]
- Tyson, J.J.; Novák, B. Functional motifs in biochemical reaction networks. Annu. Rev. Phys. Chem. 2010, 61, 219–240. [Google Scholar] [CrossRef] [Green Version]
- Garey, M.R.; Johnson, D.S. Computers and Intractability: A Guide to the Theory of NP-Completeness; W. H. Freeman: Dallas, TX, USA, 1979. [Google Scholar]
- Cooper, G.F. The computational complexity of probabilistic inference using Bayesian belief networks. Artif. Intell. 1990, 42, 393–405. [Google Scholar] [CrossRef]
- Gillespie, D.T. Stochastic simulation of chemical kinetics. Annu. Rev. Phys. Chem. 2007, 58, 35–55. [Google Scholar] [CrossRef] [PubMed]
- Goutsias, J.; Jenkinson, G. Markovian dynamics on complex reaction networks. Phys. Rep. 2013, 529, 199–264. [Google Scholar] [CrossRef] [Green Version]
- Wolpert, D.H.; Macready, W.G. No free lunch theorems for optimization. IEEE Trans. Evol. Comput. 1997, 1, 67–82. [Google Scholar] [CrossRef] [Green Version]
- Soloveichik, D.; Cook, M.; Winfree, E.; Bruck, J. Computation with finite stochastic chemical reaction networks. Nat. Comput. 2008, 7, 615–633. [Google Scholar] [CrossRef] [Green Version]
- Tenne, Y.; Goh, C.K. (Eds.) Computational Intelligence in Expensive Optimization Problems; Springer Science & Business Media: Berlin, Germany, 2010. [Google Scholar]
- Spielgelharter, D.J. Probabilistic expert systems in medicine. Stat. Sci. 1987, 2, 344. [Google Scholar]
- Shwe, M.A.; Middleton, B.; Heckerman, D.E.; Henrion, M.; Horvitz, E.J.; Lehmann, H.P.; Cooper, G.F. Probabilistic diagnosis using a reformulation of the INTERNIST-1/QMR knowledge base. Methods Inf. Med. 1991, 30, 241–255. [Google Scholar] [CrossRef] [Green Version]
- Heckerman, D.E.; Shortliffe, E.H. From certainty factors to belief networks. Artif. Intell. Med. 1992, 4, 35–52. [Google Scholar] [CrossRef]
- Heckerman, D.; Mamdani, A.; Wellman, M.P. Real-world applications of Bayesian networks. Commun. ACM 1995, 38, 24–26. [Google Scholar] [CrossRef]
- Kappen, H.J.; Rodriguez, F.B. Efficient learning in Boltzmann machines using linear response theory. Neural Comput. 1998, 10, 1137–1156. [Google Scholar] [CrossRef]
- Tanaka, T. Mean-field theory of Boltzmann machine learning. Phys. Rev. E 1998, 58, 2302. [Google Scholar] [CrossRef]
- Nguyen, H.C.; Zecchina, R.; Berg, J. Inverse statistical problems: from the inverse Ising problem to data science. Adv. Phys. 2017, 66, 197–261. [Google Scholar] [CrossRef]
- Schneidman, E.; Berry, M.J.; Segev, R.; Bialek, W. Weak pairwise correlations imply strongly correlated network states in a neural population. Nature 2006, 440, 1007–1012. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Cocco, S.; Leibler, S.; Monasson, R. Neuronal couplings between retinal ganglion cells inferred by efficient inverse statistical physics methods. Proc. Natl. Acad. Sci. USA 2009, 106, 14058–14062. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Mezard, M.; Montanari, A. Information, Physics, and Computation; Oxford University Press: Oxford, UK, 2009. [Google Scholar]
- Krzakala, F.; Mézard, M.; Sausset, F.; Sun, Y.F.; Zdeborová, L. Statistical-physics-based reconstruction in compressed sensing. Phys. Rev. X 2012, 2, 021005. [Google Scholar] [CrossRef] [Green Version]
- Barabasi, A.L.; Oltvai, Z.N. Network biology: Understanding the cell’s functional organization. Nat. Rev. Genet. 2004, 5, 101–113. [Google Scholar] [CrossRef]
- Goh, K.I.; Cusick, M.E.; Valle, D.; Childs, B.; Vidal, M.; Barabási, A.L. The human disease network. Proc. Natl. Acad. Sci. USA 2007, 104, 8685–8690. [Google Scholar] [CrossRef] [Green Version]
- Barabási, A.L.; Gulbahce, N.; Loscalzo, J. Network medicine: A network-based approach to human disease. Nat. Rev. Genet. 2011, 12, 56–68. [Google Scholar] [CrossRef] [Green Version]
- Gustafsson, M.; Nestor, C.E.; Zhang, H.; Barabási, A.L.; Baranzini, S.; Brunak, S.; Chung, K.F.; Federoff, H.J.; Gavin, A.C.; Meehan, R.R.; et al. Modules, networks and systems medicine for understanding disease and aiding diagnosis. Genome Med. 2014, 6, 82. [Google Scholar] [CrossRef] [Green Version]
- Yedidia, J.S.; Freeman, W.T.; Weiss, Y. Understanding belief propagation and its generalizations. Explor. Artif. Intell. New Millennium 2003, 8, 236–239. [Google Scholar]
- Wainwright, M.J.; Jordan, M.I. Graphical models, exponential families, and variational inference. In Foundations and Trends® in Machine Learning; NOW Publishers: Hanover, MA, USA, 2008; Volume 1, pp. 1–305. [Google Scholar]
- Murphy, K.P. Machine Learning: A Probabilistic Perspective; MIT Press: Cambridge, MA, USA, 2012. [Google Scholar]
- Pearl, J. Probabilistic Reasoning in Intelligent Systems: Networks of Plausible Inference; Morgan Kaufmann: Burlington, MA, USA, 2014. [Google Scholar]
- Khan, J.; Wei, J.S.; Ringner, M.; Saal, L.H.; Ladanyi, M.; Westermann, F.; Berthold, F.; Schwab, M.; Antonescu, C.R.; Peterson, C.; et al. Classification and diagnostic prediction of cancers using gene expression profiling and artificial neural networks. Nat. Med. 2001, 7, 673–679. [Google Scholar] [CrossRef]
- Baxt, W.G. Use of an artificial neural network for data analysis in clinical decision-making: The diagnosis of acute coronary occlusion. Neural Comput. 1990, 2, 480–489. [Google Scholar] [CrossRef]
- Penedo, M.G.; Carreira, M.J.; Mosquera, A.; Cabello, D. Computer-aided diagnosis: A neural-network-based approach to lung nodule detection. IEEE Trans. Med. Imaging 1998, 17, 872–880. [Google Scholar] [CrossRef] [PubMed]
- Gardner, E. The space of interactions in neural network models. J. Phys. A Math. Gen. 1988, 21, 257. [Google Scholar] [CrossRef]
- Saad, D.; Solla, S.A. Exact solution for on-line learning in multilayer neural networks. Phys. Rev. Lett. 1995, 74, 4337. [Google Scholar] [CrossRef]
- Krotov, D.; Hopfield, J.J. Dense associative memory for pattern recognition. In Advances in Neural Information Processing Systems; MIT Press: Cambridge, MA, USA, 2016; pp. 1172–1180. [Google Scholar]
- Baldassi, C.; Borgs, C.; Chayes, J.T.; Ingrosso, A.; Lucibello, C.; Saglietti, L.; Zecchina, R. Unreasonable effectiveness of learning neural networks: From accessible states and robust ensembles to basic algorithmic schemes. Proc. Natl. Acad. Sci. USA 2016, 113, E7655–E7662. [Google Scholar] [CrossRef] [Green Version]
- Zdeborová, L.; Krzakala, F. Statistical physics of inference: Thresholds and algorithms. Adv. Phys. 2016, 65, 453–552. [Google Scholar] [CrossRef]
- Barra, A.; Genovese, G.; Sollich, P.; Tantari, D. Phase diagram of restricted Boltzmann machines and generalized Hopfield networks with arbitrary priors. Phys. Rev. E 2018, 97, 022310. [Google Scholar] [CrossRef] [Green Version]
- Balian, R. From Microphysics to Macrophysics: Methods and Applications of Statistical Physics; Springer Science & Business Media: Berlin, Germany, 2007. [Google Scholar]
- Van Kampen, N.G. Stochastic Processes in Physics and Chemistry; Elsevier: Amsterdam, The Netherlands, 1992; Volume 1. [Google Scholar]
- Jaynes, E.T. Probability Theory: The Logic of Science; Cambridge University Press: Cambridge, UK, 2003. [Google Scholar]
- Krzakała, F.; Montanari, A.; Ricci-Tersenghi, F.; Semerjian, G.; Zdeborová, L. Gibbs states and the set of solutions of random constraint satisfaction problems. Proc. Natl. Acad. Sci. USA 2007, 104, 10318–10323. [Google Scholar] [CrossRef] [Green Version]
- Mézard, M.; Parisi, G.; Virasoro, M. Spin Glass Theory and Beyond: An Introduction to the Replica Method and Its Applications; World Scientific Publishing Company: Singapore, 1987. [Google Scholar]
- Ramezanpour, A.; Mashaghi, A. Disease evolution in reaction networks: Implications for a diagnostic problem. PLoS Comput. Biol. 2020, 16, e1007889. [Google Scholar] [CrossRef]
- Cramer, A.O.; van Borkulo, C.D.; Giltay, E.J.; van der Maas, H.L.; Kendler, K.S.; Scheffer, M.; Borsboom, D. Major depression as a complex dynamic system. PLOS ONE 2016, 11, e0167490. [Google Scholar] [CrossRef]
- Goldenfeld, N. Lectures on Phase Transitions and the Renormalization Group; CRC Press: Boca Raton, FL, USA, 2018. [Google Scholar]
- Carleo, G.; Cirac, I.; Cranmer, K.; Daudet, L.; Schuld, M.; Tishby, N.; Vogt-Maranto, L.; Zdeborová, L. Machine learning and the physical sciences. Rev. Modern Phys. 2019, 91, 045002. [Google Scholar] [CrossRef] [Green Version]
- Carrasquilla, J.; Melko, R.G. Machine learning phases of matter. Nat. Phys. 2017, 13, 431–434. [Google Scholar] [CrossRef] [Green Version]
- Deng, D.L.; Li, X.; Sarma, S.D. Machine learning topological states. Phys. Rev. B 2017, 96, 195145. [Google Scholar] [CrossRef] [Green Version]
- Rotmensch, M.; Halpern, Y.; Tlimat, A.; Horng, S.; Sontag, D. Learning a health knowledge graph from electronic medical records. Sci. Rep. 2017, 7, 1. [Google Scholar] [CrossRef]
- Zhang, Y.; Cai, T.; Yu, S.; Cho, K.; Hong, C.; Sun, J.; Huang, J.; Ho, Y.L.; Ananthakrishnan, A.N.; Xia, Z.; et al. High-throughput phenotyping with electronic medical record data using a common semi-supervised approach (PheCAP). Nat. Protoc. 2019, 14, 3426–3444. [Google Scholar] [CrossRef]
- Shortliffe, E.H.; Buchanan, B.G. A model of inexact reasoning in medicine. Math. Biosci. 1975, 23, 351–379. [Google Scholar] [CrossRef]
- Sun, K.; Gonçalves, J.P.; Larminie, C.; Pržulj, N. Predicting disease associations via biological network analysis. BMC Bioinform. 2014, 15, 304. [Google Scholar] [CrossRef] [Green Version]
- Liu, W.; Wu, A.; Pellegrini, M.; Wang, X. Integrative analysis of human protein, function and disease networks. Sci. Rep. 2015, 5, 14344. [Google Scholar] [CrossRef] [Green Version]
- Suratanee, A.; Plaimas, K. DDA: A novel network-based scoring method to identify disease-disease associations. Bioinform. Biol. Insights 2015, 9, BBI–S35237. [Google Scholar] [CrossRef] [Green Version]
- Menche, J.; Sharma, A.; Kitsak, M.; Ghiassian, S.D.; Vidal, M.; Loscalzo, J.; Barabási, A.L. Uncovering disease-disease relationships through the incomplete interactome. Science 2015, 347, 1257601. [Google Scholar] [CrossRef] [Green Version]
- Halu, A.; De Domenico, M.; Arenas, A.; Sharma, A. The multiplex network of human diseases. NPJ Syst. Biol. Appl. 2019, 5, 1–2. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Heckerman, D. A tractable inference algorithm for diagnosing multiple diseases. In Machine Intelligence and Pattern Recognition; North-Holland: Amsterdam, The Netherlands, 1990; Volume 10, pp. 163–171. [Google Scholar]
- Nikovski, D. Constructing Bayesian networks for medical diagnosis from incomplete and partially correct statistics. IEEE Trans. Knowl. Data Eng. 2000, 12, 509–516. [Google Scholar] [CrossRef] [Green Version]
- Henrion, M. Towards efficient inference in multiply connected belief networks. In Influence Diagrams, Belief Nets and Decision Analysis; Wiley: New York, NY, USA, 1990; pp. 385–407. [Google Scholar]
- Andreassen, S.; Jensen, F.V.; Olesen, K.G. Medical expert systems based on causal probabilistic networks. Int. J. Bio-Med. Comput. 1991, 28, 1–30. [Google Scholar] [CrossRef]
- Heckerman, D.; Geiger, D.; Chickering, D.M. Learning Bayesian networks: The combination of knowledge and statistical data. Mach. Learn. 1995, 20, 197–243. [Google Scholar] [CrossRef] [Green Version]
- Chickering, D.M. Learning Bayesian networks is NP-complete. In Learning from Data; Springer: New York, NY, USA, 1996; pp. 121–130. [Google Scholar]
- Ramezanpour, A.; Mashaghi, A. Toward First Principle Medical Diagnostics: On the Importance of Disease-Disease and Sign-Sign Interactions. Front. Phys. 2017, 5, 32. [Google Scholar] [CrossRef] [Green Version]
- Wolfram, D.A. An appraisal of INTERNIST-I. Artif. Intell. Med. 1995, 7, 93–116. [Google Scholar] [CrossRef]
- Lee, H.; Grosse, R.; Ranganath, R.; Ng, A.Y. Convolutional deep belief networks for scalable unsupervised learning of hierarchical representations. In Proceedings of the 26th Annual International Conference on Machine Learning, Montreal, QC, Canada, 14–18 June 2009; pp. 609–616. [Google Scholar]
- Abdel-Zaher, A.M.; Eldeib, A.M. Breast cancer classification using deep belief networks. Expert Syst. Appl. 2016, 46, 139–144. [Google Scholar] [CrossRef]
- Goodfellow, I.; Yoshua, B.; Aaron, C. Deep Learning; MIT Press: Cambridge, MA, USA, 2016. [Google Scholar]
- Hinton, G. Deep learning—A technology with the potential to transform health care. JAMA 2018, 320, 1101–1102. [Google Scholar] [CrossRef]
- Naylor, C.D. On the prospects for a (deep) learning health care system. JAMA 2018, 320, 1099–1100. [Google Scholar] [CrossRef]
- Ramoni, M.; Stefanelli, M.; Magnani, L.; Barosi, G. An epistemological framework for medical knowledge-based systems. IEEE Trans. Syst. Man Cybern. 1992, 22, 1361–1375. [Google Scholar] [CrossRef]
- Stausberg, J.; Person, M. A process model of diagnostic reasoning in medicine. Int. J. Med. Inform. 1999, 54, 9–23. [Google Scholar] [CrossRef]
- Card, W.I. The diagnostic process. J. R. Coll. Phys. Lond. 1970, 4, 183. [Google Scholar]
- Wiener, F. Computer simulation of the diagnostic process in medicine. Comput. Biomed. Res. 1975, 8, 129–142. [Google Scholar] [CrossRef]
- Ramezanpour, A.; Mashaghi, A. Uncovering hidden disease patterns by simulating clinical diagnostic processes. Sci. Rep. 2018, 8, 1–3. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Mashaghi, A.; Ramezanpour, A. Statistical physics of medical diagnostics: Study of a probabilistic model. Phys. Rev. E. 2018, 97, 032118. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Mézard, M.; Montanari, A. Reconstruction on trees and spin glass transition. J. Stat. Phys. 2006, 124, 1317–1350. [Google Scholar] [CrossRef] [Green Version]
- Cammarota, C.; Biroli, G. Random pinning glass transition: Hallmarks, mean-field theory and renormalization group analysis. J. Chem. Phys. 2013, 138, 12A547. [Google Scholar] [CrossRef]
- Birge, J.R.; Louveaux, F. Introduction to Stochastic Programming; Springer Science & Business Media: Berlin, Germany, 2011. [Google Scholar]
- Altarelli, F.; Braunstein, A.; Ramezanpour, A.; Zecchina, R. Stochastic matching problem. Phys. Rev. Lett. 2011, 106, 190601. [Google Scholar] [CrossRef] [Green Version]
- Altarelli, F.; Braunstein, A.; Ramezanpour, A.; Zecchina, R. Stochastic optimization by message passing. J. Stat. Mech. Theory Exp. 2011, 2011, P11009. [Google Scholar] [CrossRef]
- Gruber, K. Is the future of medical diagnosis in computer algorithms? Lancet Dig. Health 2019, 1, e15–e16. [Google Scholar] [CrossRef] [Green Version]
- Lim, C.T. Future of health diagnostics. View 2020, 1, e3. [Google Scholar] [CrossRef]
- Cook, S.F.; Bies, R.R. Disease progression modeling: key concepts and recent developments. Curr. Pharmacol. Rep. 2016, 2, 221–230. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- DeWeerdt, S. Disease progression: Divergent paths. Nature 2017, 551, 7681. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Eulenberg, P.; Köhler, N.; Blasi, T.; Filby, A.; Carpenter, A.E.; Rees, P.; Theis, F.J.; Wolf, F.A. Reconstructing cell cycle and disease progression using deep learning. Nat. Commun. 2017, 8, 1–6. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Klughammer, J.; Kiesel, B.; Roetzer, T.; Fortelny, N.; Nemc, A.; Nenning, K.H.; Furtner, J.; Sheffield, N.C.; Datlinger, P.; Peter, N.; et al. The DNA methylation landscape of glioblastoma disease progression shows extensive heterogeneity in time and space. Nat. Med. 2018, 24, 1611–1624. [Google Scholar] [CrossRef]
- Mitchell, M.G. Molecular Pathology and the Dynamics of Disease; Academic Press: Cambridge, MA, USA, 2018. [Google Scholar]
- Smith, V.H.; Holt, R.D. Resource competition and within-host disease dynamics. Trends Ecol. Evol. 1996, 11, 386–389. [Google Scholar] [CrossRef]
- Asachenkov, A.; Marchuk, G.; Mohler, R.; Zuev, S. Disease Dynamics; Springer Science & Business Media: Berlin, Germany, 1993. [Google Scholar]
- Shaw, C.A. Neural Dynamics of Neurological Disease; John Wiley & Sons: Hoboken, NJ, USA, 2017. [Google Scholar]
- Goldstein, B.; McNames, J.; McDonald, B.A.; Ellenby, M.; Lai, S.; Sun, Z.; Krieger, D.; Sclabassi, R.J. Physiologic data acquisition system and database for the study of disease dynamics in the intensive care unit. Crit. Care Med. 2003, 31, 433–441. [Google Scholar] [CrossRef]
- Sjölinder, H.; Jonsson, A.B. Imaging of disease dynamics during meningococcal sepsis. PLoS ONE 2007, 2, e241. [Google Scholar] [CrossRef] [Green Version]
- Kirkpatrick, S.; Gelatt, C.D.; Vecchi, M.P. Optimization by simulated annealing. Science 1983, 220, 671–680. [Google Scholar] [CrossRef]
- Didelot, X.; Everitt, R.G.; Johansen, A.M.; Lawson, D.J. Likelihood-free estimation of model evidence. Bayesian Anal. 2011, 6, 49–76. [Google Scholar] [CrossRef] [Green Version]
- Ratmann, O.; Jørgensen, O.; Hinkley, T.; Stumpf, M.; Richardson, S.; Wiuf, C. Using likelihood-free inference to compare evolutionary dynamics of the protein networks of, H. pylori and, P. falciparum. PLoS Comput. Biol. 2007, 3, e230. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Grelaud, A.; Robert, C.P.; Marin, J.M.; Rodolphe, F.; Taly, J.F. ABC likelihood-free methods for model choice in Gibbs random fields. Bayesian Anal. 2009, 4, 317–335. [Google Scholar] [CrossRef]
- Barthelmé, S.; Chopin, N. Expectation propagation for likelihood-free inference. J. Am. Stat. Assoc. 2014, 109, 315–333. [Google Scholar] [CrossRef] [Green Version]
- Goodfellow, I.; Pouget-Abadie, J.; Mirza, M.; Xu, B.; Warde-Farley, D.; Ozair, S.; Courville, A.; Bengio, Y. Generative adversarial nets. In Advances in Neural Information Processing Systems; MIT Press: Cambridge, MA, USA, 2014; pp. 2672–2680. [Google Scholar]
- Radford, A.; Metz, L.; Chintala, S. Unsupervised representation learning with deep convolutional generative adversarial networks. arXiv 2015, arXiv:1511.06434. [Google Scholar]
- Gutmann, M.U.; Corander, J. Bayesian optimization for likelihood-free inference of simulator-based statistical models. J. Mach. Learn. Res. 2016, 17, 4256–4302. [Google Scholar]
- Martin Arjovsky, S.C.; Bottou, L. Wasserstein Generative Adversarial Networks. In Proceedings of the 34th International Conference on Machine Learning, Sydney, Australia, 6–11 August 2017. [Google Scholar]
- Grover, L.K. Quantum mechanics helps in searching for a needle in a haystack. Phys. Rev. Lett. 1997, 79, 325. [Google Scholar] [CrossRef] [Green Version]
- Narayanan, A.; Moore, M. Quantum-inspired genetic algorithms. In Proceedings of the IEEE International Conference on Evolutionary Computation, Nagoya, Japan, 20–22 May 1996; pp. 61–66. [Google Scholar]
- Han, K.H.; Park, K.H.; Lee, C.H.; Kim, J.H. Parallel quantum-inspired genetic algorithm for combinatorial optimization problem. In Proceedings of the 2001, Congress on Evolutionary Computation (IEEE Cat. No. 01TH8546), Seoul, Korea, 27–30 May 2001; Volume 2, pp. 1422–1429. [Google Scholar]
- Arpaia, P.; Maisto, D.; Manna, C. A Quantum-inspired Evolutionary Algorithm with a competitive variation operator for Multiple-Fault Diagnosis. Appl. Soft Comput. 2011, 11, 4655–4666. [Google Scholar] [CrossRef]
- Schuld, M.; Sinayskiy, I.; Petruccione, F. The quest for a quantum neural network. Quantum Inform. Process. 2014, 13, 2567–2586. [Google Scholar] [CrossRef] [Green Version]
- Njafa, J.P.; Engo, S.N. Quantum associative memory with linear and non-linear algorithms for the diagnosis of some tropical diseases. Neural Netw. 2018, 97, 1–10. [Google Scholar] [CrossRef] [Green Version]
- Santoro, G.E.; Tosatti, E. Optimization using quantum mechanics: quantum annealing through adiabatic evolution. J. Phys. A Math. Gen. 2006, 39, R393. [Google Scholar] [CrossRef]
- Boixo, S.; Albash, T.; Spedalieri, F.M.; Chancellor, N.; Lidar, D.A. Experimental signature of programmable quantum annealing. Nat. Commun. 2013, 4, 1–8. [Google Scholar] [CrossRef] [PubMed]
- Ramezanpour, A. Optimization by a quantum reinforcement algorithm. Phys. Rev A 2017, 96, 052307. [Google Scholar] [CrossRef] [Green Version]
- Biamonte, J.; Wittek, P.; Pancotti, N.; Rebentrost, P.; Wiebe, N.; Lloyd, S. Quantum machine learning. Nature 2017, 549, 195–202. [Google Scholar] [CrossRef] [PubMed]






{kind=link}
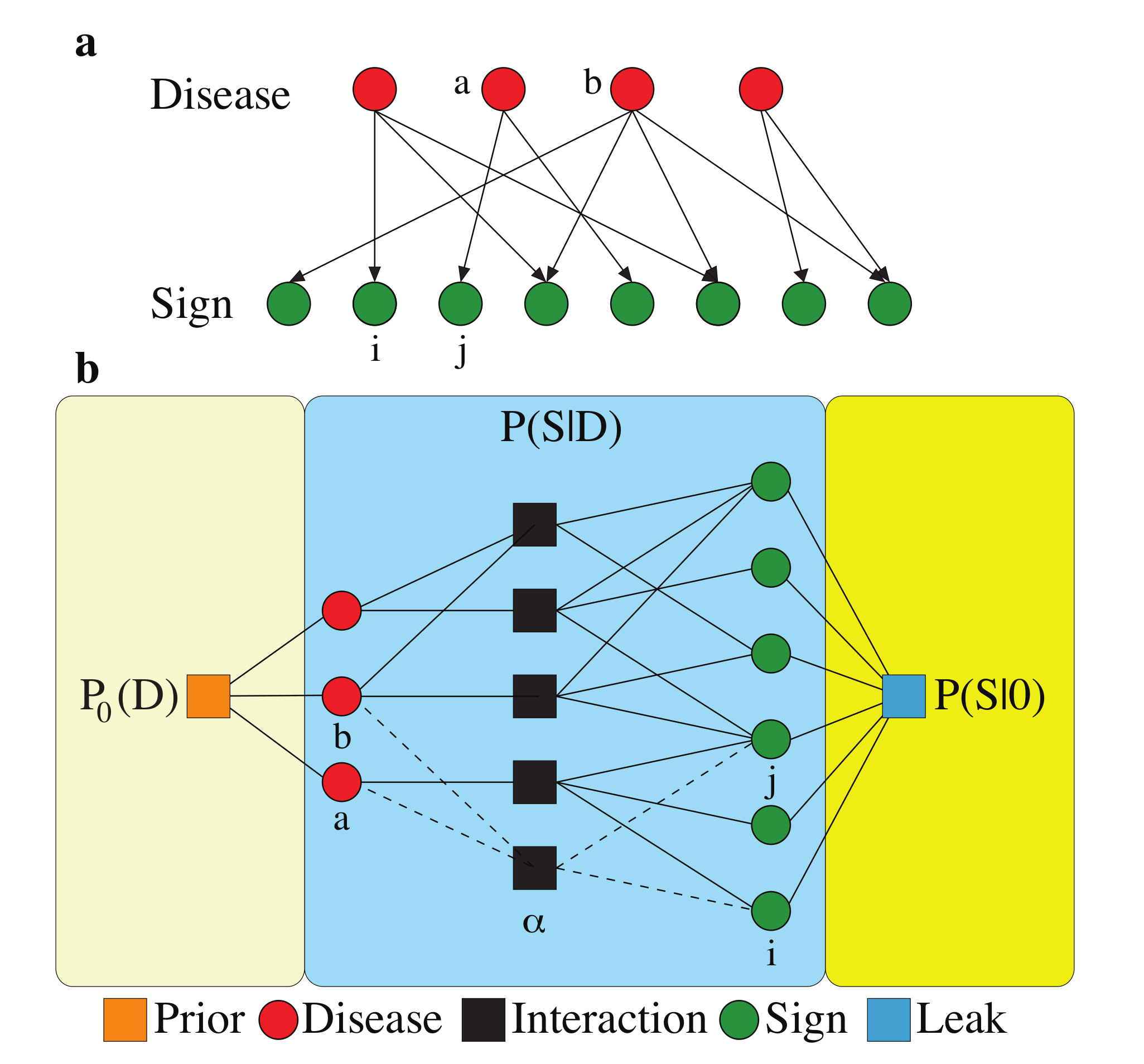{kind=link}
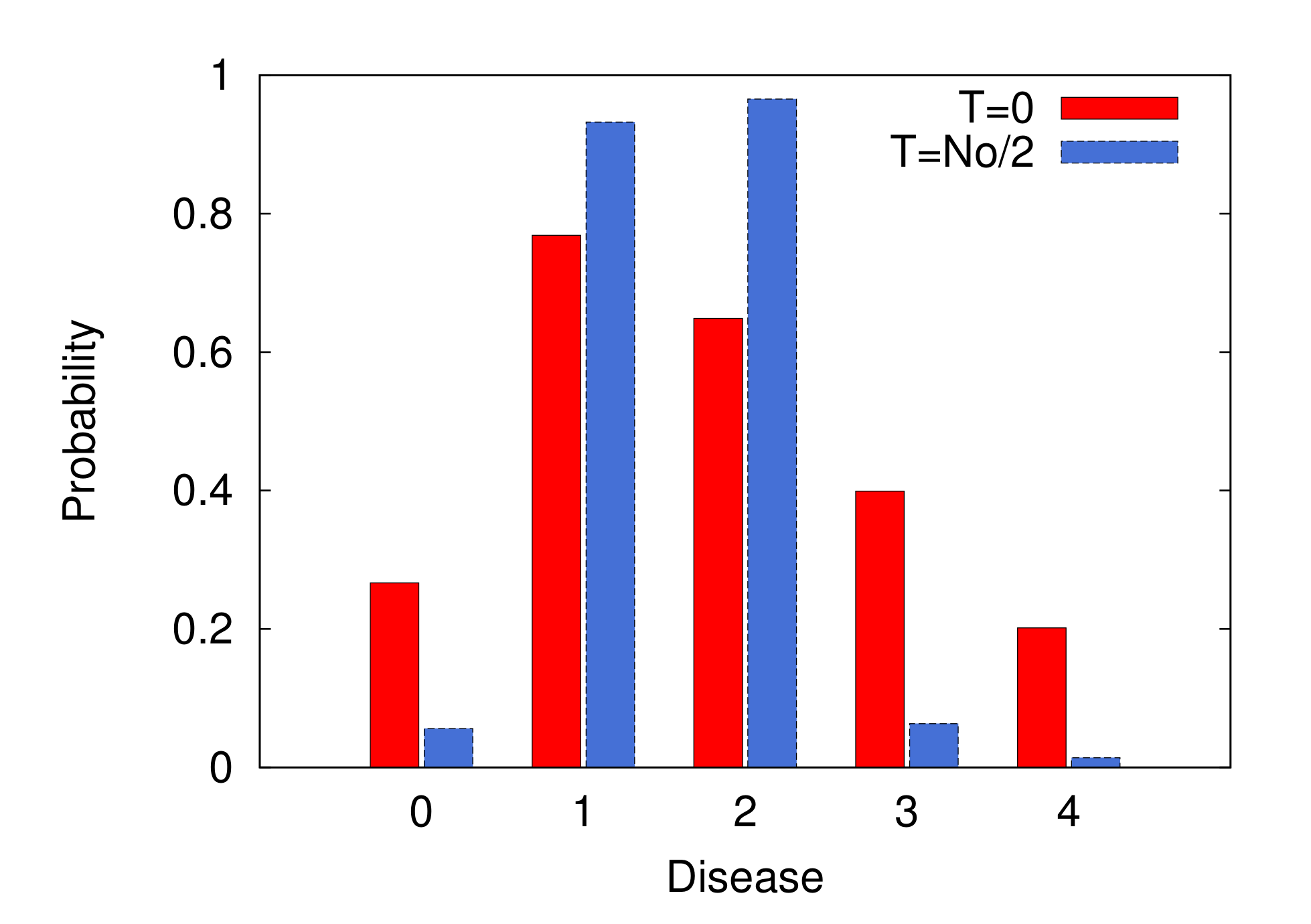{kind=link}
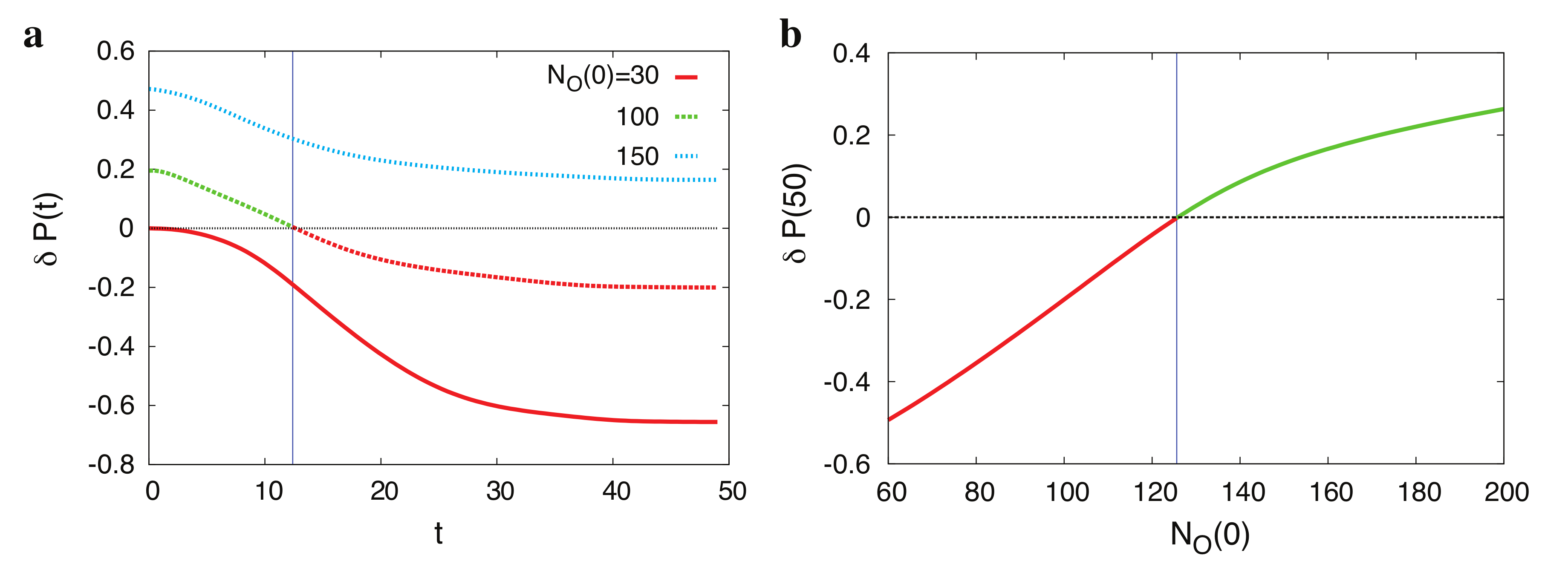{kind=link}
{kind=link}
| Medical Diagnostics | Statistical Physics | Description |
|---|---|---|
| signs | microscopic variables | binary genotypes as two-state spins in a magnetic system |
| causal dependencies | Hamiltonian interactions | influencing factors as interactions with external fields and other spins |
| uncertainty and noise | temperature | stochastic variability from thermal fluctuations |
| healthy and disease states | thermodynamic phases | emergent phenotypes as macroscopic features of Gibbs states |
| observed signs | pinned microscopic variables | related to random pinning transitions |
| diagnosis | phase detection | similar to the phase classification problem |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ramezanpour, A.; Beam, A.L.; Chen, J.H.; Mashaghi, A. Statistical Physics for Medical Diagnostics: Learning, Inference, and Optimization Algorithms. Diagnostics 2020, 10, 972. https://doi.org/10.3390/diagnostics10110972
Ramezanpour A, Beam AL, Chen JH, Mashaghi A. Statistical Physics for Medical Diagnostics: Learning, Inference, and Optimization Algorithms. Diagnostics. 2020; 10(11):972. https://doi.org/10.3390/diagnostics10110972
Chicago/Turabian StyleRamezanpour, Abolfazl, Andrew L. Beam, Jonathan H. Chen, and Alireza Mashaghi. 2020. "Statistical Physics for Medical Diagnostics: Learning, Inference, and Optimization Algorithms" Diagnostics 10, no. 11: 972. https://doi.org/10.3390/diagnostics10110972