1. Introduction
We must protect forests to keep the planet healthy. Forest fires are uncontrollable disasters. Forest fires have increased in frequency and damage. Forest fires destroy millions of acres of forest and cause a cascade of environmental disasters, including global warming, costing governments USD tens of billions [
1]. Forest fires harm the ecosystem and threaten human lives and progress [
2]. Forest fires spread swiftly and randomly. Forest fires can develop swiftly without early warning, endangering the environment, and firefighters [
3]. Smoking debris starts forest fires. Smoke precedes forest fires. Smoke detection early and accurately reduces forest firefighting response times and damage.
Forest-fire smoke-detection procedures need urgent improvements. One smoke puff from a forest fire’s smoke angle indicates the wind direction and the fire’s origin. Horizontal detection boxes missed details and were not accurate, mistaking non-smoke for smoke. In the dynamic, ever-changing forest, smoke-like phenomena such as shifting clouds and fog are widespread. These occurrences are similar to smoke, making standard feature extraction networks difficult to differentiate. Smoke is too far away to see. When the burning point is far from the camera, the detection box’s confidence drops, filtering out smoke and making smoke detection harder.
L Tian et al.’s [
4] smoke tilt detection system uses an image augmentation module and a dense feature-reuse module to handle distant sensing objects’ densely ordered properties. W. Huang et al. [
5] suggested a cross-scale feature-fusion pyramid network and a multioriented detection box for remote sensing tilted ships. The remote sensing scene’s multioriented detection strategy was encouraging, and the multioriented detection box captured smoke drifting in the wind well. Thus, we propose a multioriented detection method where the target box adaptively describes smoke direction and is used to determine the fire source direction. The forest-fire multioriented detection dataset uses PolyIOU to evaluate anchor box overlap as an adaptation to multioriented detection.
Delayed wildfire identification and suppression can cause severe forest damage. Forest monitoring systems must promptly and correctly detect fire and smoke. Early fire-monitoring systems focused on flame detection. Smoke detection is better than fire detection in forest monitoring systems because fires develop slowly and are hard to detect early. Thus, smoke-based security monitoring systems outperform fire-based ones. Thus, forest-fire monitoring algorithms are better at smoke detection than fire detection [
4].
Sensor-based smoke detectors detect particulate particles from smoke ionization. A sensor-based smoke detector cannot be used in woodlands due to their size and geography [
5]. Therefore, numerous computer vision-based smoke-detection algorithm efforts have addressed this issue.
Early smoke detectors could not locate smoke and firefighting devices can deliver more precise signals if smoke is confined. Thus, precise smoke localization has become a computer vision task in recent years and smoke detectors are the focus of this article. Most early vision-based smoke detectors used inference techniques with simple feature representations [
4,
6]
These methods show smoke’s hue, velocity, opacity, and orientation graphically. Due to the lack of feature representation-based procedures for characterizing smoke motion and exterior morphology, conventional smoke-detection algorithms perform poorly when the running environment changes [
2]. Thus, smoke-detection algorithms can improve generality and interference suppression.
Some forest objects resemble smoke, rendering the model open to misinterpretation under typical settings. Smoke contains distinct visual properties at different combustion phases, making it hard for detection models to acquire high-dimensional features adaptable to different stages. A reliable wildfire smoke-detection technology should be able to locate smoke sources.
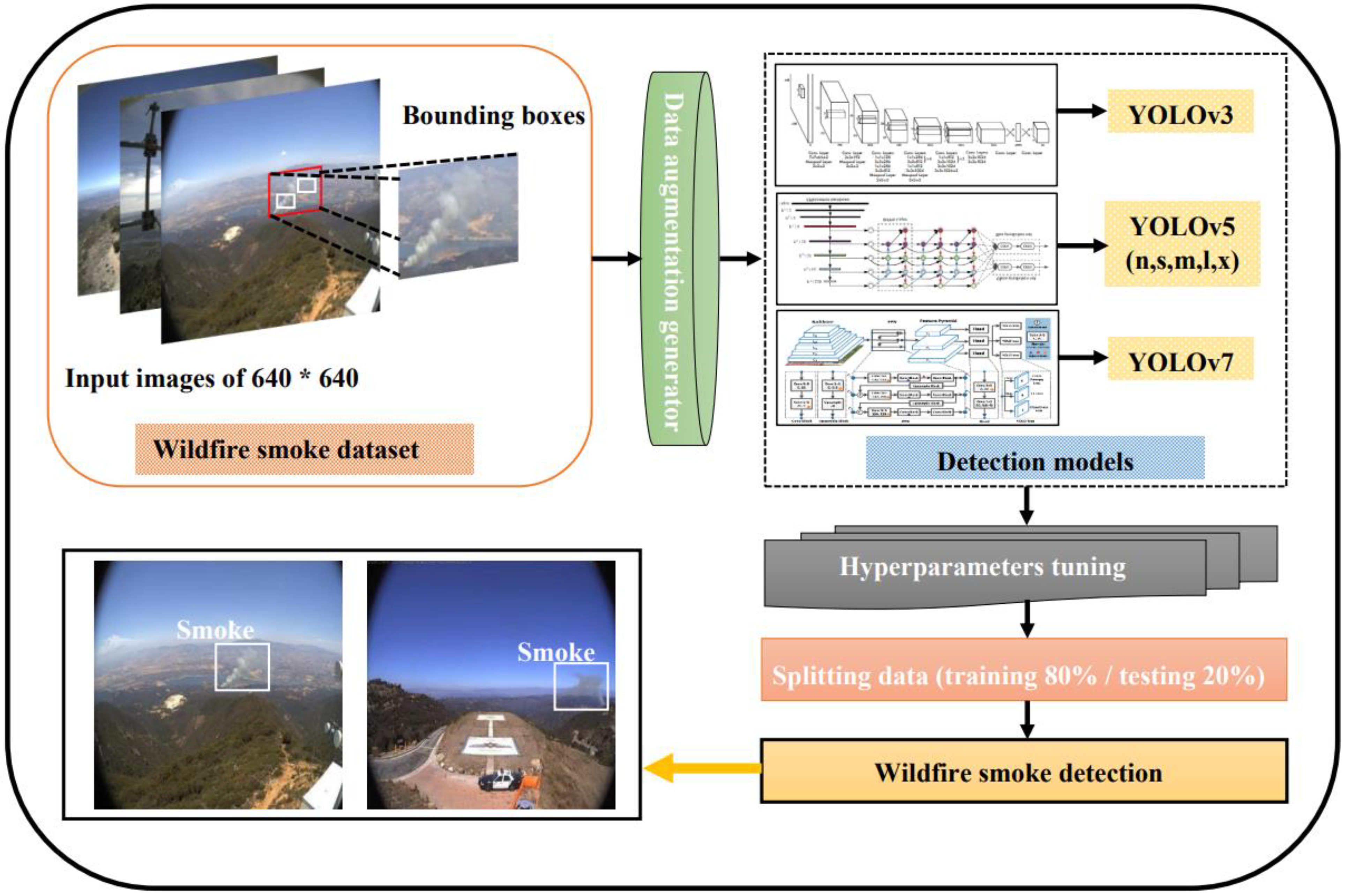
Figure 1 shows a general wildfire smoke-detection operation using deep learning.
The key contributions are as follows: (1) Comparing the performance and detection accuracy of different YOLO models, such as YOLOv3, YOLOv5n, YOLOv5s, YOLOv5m, YOLOv5l, YOLOv5x, and YOLOv7, for wildfire smoke detection from different detection ranges; (2) Using several data-augmentation techniques to reduce the sensitivity of detection models; (3) Comparing YOLO models with other detection models such as Fast R-CNN, Faster R-CNN, and YOLOv4; (4) Improving performance and shortening detection times using the stochastic gradient descent optimizer.
The rest of the paper is organized as follows:
Section 2 shows the state-of-the-art related works in the area.
Section 3 illustrates the proposed wildfire smoke-detection methodology, data gathered, used detection models, and data-augmentation techniques.
Section 4 shows the evaluation metrics used for detection model assessment. Moreover,
Section 5 discusses the experimental results, shows the hyperparameter tuning process, and simulation device setup. Lastly,
Section 6 concludes the study and suggests future directions.
2. Review of Related State-of-the-Art Works
In the event that there is a forest fire in an area, massive plumes of smoke will be sent into the atmosphere. A smoke alarm that is in good working order is essential for avoiding loss in the case of a fire. If they are not located and contained in a timely manner, rapidly spreading wildfires, which are made worse by climate change, have the potential to have far-reaching repercussions on human populations, ecosystems, and the economy. Two different methods may be used to monitor wildfires to detect smoke and flames. The presence of smoke is the primary indicator of a wildfire nearby. Consequently, an early warning and detection system for wildfires, such as deep-learning models, have to be sensitive to the smoke in the environment in which it operates. However, with the development of technology, previous studies presented many modern methods that can be used to detect smoke and fires in light of the availability of many processed data. Swin-YOLOv5, a novel framework that enhances feature extraction in the original YOLOv5 architecture, was suggested in [
7].
The designed framework can detect fire and smoke to a satisfactory degree. The notion of Swin-fundamental YOLOv5 is to employ a transformer across three headers. A dataset of 16,503 photos from two target classes was used for comparative reasons. Additionally, seven hyperparameters were modified. According to the statistics, Swin-YOLOv5 beat the original with a 0.7% mean average accuracy improvement at an IOU of 0.5 and a 4.5% mean average precision improvement for an IOU of 0.5 to 0.95.
In [
8], an improved version of YOLOv5, including dynamic anchor learning using the K-means++ algorithm, was produced. The suggested strategy aimed to reduce fire damage by enhancing detection speed and performance. In addition, loss functions including CIOU and GIOU were applied to three separate YOLOv5 models: YOLOv5 small, YOLOv5 medium, and YOLOv5 big. A self-created dataset of 4815 photos was subjected to a synthetic system to raise the number of images to 20,000. According to the results, the improved model beat the original YOLOv5 by 4.4% in mean average accuracy. In addition, it was revealed that YOLOv5 performs better when utilizing the CIoU loss function, with a recall of 78% and an average mean accuracy of 87%.
The study in [
9] presented a novel approach for identifying flames using aerial images. The equivalent of 6000 photographs illustrating forest fires and smoke were gathered from Kaggle and Google libraries. Furthermore, the developed technique intended to employ the YOLOv5 model with the K-means++ algorithm to find the anchor squares. To improve detection accuracy, procedures such as rotation and flipping were developed, reducing the sensitivity of detection models in future detection operations. The assessment criteria application demonstrated that the provided technique beat several other methods, such as upleNet and SSD, with an average accuracy of 73.6%. However, it is worth mentioning that the described technique has several drawbacks, such as misclassifying clouds as smoke from flames. In [
6], the researchers highlighted the issue of a lack of sufficient and high-quality data for detecting fires and smoke in research archives. One of the most serious issues is a shortage of labeled data suitable for development and utilization. As a result, a novel approach was given to create NEMO (Nevada Smoke Detection Benchmark), a first-of-its-kind data repository that comprises a set of aerial pictures gathered from detection stations to identify forest fires. NEMO provides data sets with 7023 fire detection photos taken using many cameras at various times and places. Various detection models were utilized to evaluate the data, including Faster R-CNN and RetinaNet. The results revealed an average detection accuracy of 42.3% and a detection rate of 98.4% within 5 min. It is worth mentioning that NEMO was designed for photographs of various sizes, including horizontal, distant, and medium.
In [
2], a novel framework was presented to identify forest fires using ensemble learning. In the first layer, the suggested technique employs Yolov5 and EfficientDet as the primary learners, followed by the introduction of EfficientNet, which is in charge of detection and classification based on publicly available data. Furthermore, a collection of 10,581 images was compiled from well-known datasets such as FD-dataset and VisiFire. When compared to other models such as the Yolov4, the findings revealed an improvement in fire detection accuracy, with an average precision of 79.7% at an intersection over the union of 50%. However, several of the study’s constraints suggest that the suggested model defines the sun as a fire at sunset.
Other studies focused on using detection models to develop special methods for detecting and classifying internal and external objects that can be developed and used to detect fires and smoke. In [
10], a novel framework for recognizing interior occupancy objects was introduced. The proposed framework maximizes using YOLOv5 by using the anchor-free method for parameter reduction and VariFocal loss for data balancing. In addition, a newly constructed dataset including 11,367 samples was provided, which was separated into training, testing, and validation sets. In addition, Pascal-VOC2012, a well-known dataset, was used throughout the experiment. As part of the YOLOv5 upgrade, the head’s layer was decoupled to improve detection precision and performance. A 640-by-640 pixel resolution is also employed. Eleven prior models using YOLO in various forms were compared with the new framework’s outcomes. The test results determined the model’s average accuracy of 93.9 at an intersection over union (IOU) of 0.9.
In the study in [
3], a real-time experiment was carried out to recognize inside and outside things by building an engineering system that uses camera sensors such as OS1-64 and OS0-128 that are used in the Lidar gadget. On the other hand, the primary contribution was made using complete 360-degree images with a resolution of 2048 x 128. In the developed system, the performance of FasterR-CNN, MaskRCNN, YOLOx, and YOLOv5 was compared. Sensor pictures identified four target kinds for indoor and outdoor applications, including a person, bicycle, chair, and automobile. YOLOx outperformed the competition, detecting over 80% of indoor and outdoor items with 100% accuracy and 95.3% recall. Furthermore, they claimed that YOLOx exceeds YOLOv5 in detection performance and speed.
The study in [
4] presented a novel approach based on the enhanced YOLOv3 model, to detect fires in the day and night with the least amount of time and the broadest detection area feasible. Furthermore, the research highlighted the lack of high-quality data to identify fires. As a result, a data collection of 9200 photos was gathered and built from Google repositories and remotely accessible resources, in addition to gathering a collection of photos derived from video clips. Moreover, data-augmentation methods such as image rotation were used to make new copies of current data and enhance the size of the data set. Furthermore, the given technique was based on employing a unique collection of cameras coupled to the YOLOv3 model for real-time fire detection. Compared to other detection methods, the experimental investigation yielded an average accuracy of 98.9. The identification of certain factors on flames that are not truly fire, such as strong light and high-beam lamp light, is a hindrance to the research.
Other studies revealed techniques for detecting objects using satellites, which is one of the fire-detection stations used in conjunction with video cameras and drones. As a result, these technologies may be utilized and refined to identify large-area fires. A technique for locating suitable landing spots for unmanned aerial vehicles was presented in [
5]. The established framework compared the effectiveness of several YOLO versions, including YOLOv3, YOLOv4, and YOLOv5, in pinpointing optimal landing locations to reduce flying system failure and increase safety. Yet, the DOTA, a database of 11,268 satellite photos with a maximum image resolution of 20,000 by 20,000 pixels and a total of 15 labels, was used. With a 70% accuracy rate, a 61% recall rate, and a 63% mean average accuracy rate, the results show that YOLOv5 with big network weights performs better than its competitors.
On top of that, YOLOv4 outperforms YOLOv3 with a recall of 57% and an average accuracy of 60%. In addition, additional research has shown the capability and efficacy of YOLO models in detecting illnesses such as cancer by image processing. The research in [
11] suggested a different approach to enhancing YOLOv5′s capacity to detect breast cancer. All four YOLOv5 weight models (small, medium, big, and extra-large) were evaluated for their usefulness in the context of this study. Furthermore, 10,239 unique 1000 × 2000-pixel photos from the CBIS-DDSM collection were used. It indicated whether or not the breast cancer was malignant. The results of the tests showed that modified YOLOv5x is superior to the small, medium, and big weights, with an MCC of 93.6%. In addition, competing models such as YOLOv3 and quicker RCNN were compared to the anticipated YOLOv5m upgrade. With an accuracy of 96.5% and mAP of 96%, it was shown that modified YOLOv5m beat YOLOv3 and faster RCNN.
Table 1 summarizes the state-of-the-art related works.
5. Experimental Results and Discussion
Detecting forest fires is a delicate procedure with enormous economic consequences. Furthermore, it is important to note the persistence of climate change, which significantly impacts the spread and intensification of flames. In this section, we compare several YOLO models and their performance in detecting forest-fire smoke with the shortest feasible detection time. However, this is not considered adequate for determining the optimum fire-detection model, particularly given several competing models based on very efficient neural networks, such as Faster R-CNN. As a result, one of the objectives of this study is to evaluate the performance of YOLO models compared to earlier models.
Furthermore, in terms of detection speed, it is fully dependent on the speed of image processing to identify its constituents such as smoke and flames. Detection stations play a vital role in this case by delivering high-quality images such as satellite or drone photos. Here, the problem of the inequality of comparisons of the different YOLO detection models with previous models such as fast R-CNN and faster R-CNN appears. In order to properly overcome this problem, we suggest in this study that high-quality simulation devices be provided to boost detection. However, in this paper, we confine ourselves to the parameters of the device employed in this study, as shown in
Table 3. Additionally, the most significant factors of fire smoke-detection activities, which are centered on the difficulty of detecting distant areas based on the size of the detection zones, should be underlined. On the other hand, some components with intense light are among the most notable obstacles in erroneous detections. As a result, the objective of this study is to provide light on the variations in performance amongst YOLO models for identifying faraway regions.
YOLO models include roughly 29 different parameters for hyperparameter adjustment. However, we set up twelve parameters, as shown in
Table 4. The parameters are loss gain functions, learning rates, optimizers, and IoU threshold. All pictures were downsized to 640 × 640 as the input image size for all models. However, because of the low weight of networks such as nano and small models, we increased the number of epochs in YOLOv5 to 100 iterations to boost detection results. To make the comparison more realistic, we set all other YOLOv5 models to 100 epochs, including medium, large, and x-large. As with YOLOv5, we picked 100 epochs to train the YOLOv3 model and 100 epochs to train the YOLOv7 model. However, all models were built up in 16 batches compatible with the tiny, selected learning rates and device qualifications in terms of RAM and GPU. In each iteration, just four photos were input into the model once for clarity. In the YOLOv3 and YOLOv5 models, we applied the stochastic gradient descent (SGD) optimizer. To our knowledge, the SGD optimizer outperformed the ADAM optimizer, despite the Adam optimizer converging quicker [
23].
The findings from our experiments demonstrate that the YOLOv5x model is superior, since it has a detection accuracy of 96.8% at a threshold of 50% higher than the union intersection. In addition, the model’s accuracy was 95%, earning it the best grade possible on scales measuring precision and recall. This should not come as a surprise considering that the YOLOv5x model is the most comprehensive of all the models and achieves an average accuracy rate of 68.9% on the COCO dataset. In addition, YOLOv5 models are differentiated from their predecessors by their ability to recognize three-dimensional objects inside a single picture. The speed of detection, on the other hand, has to be considered since we found that the extremely large (YOLOv5x) model had the slowest rate of detection compared to the other models. The findings of the experiment as well as a comparison of several detection models are shown in
Table 5. When the intersection over union was set at 50%, the YOLOv7 model, on the other hand, revealed comparable results with an average accuracy of 95%. When contrasted with the YOLOv5x model, however, we discovered that this one achieves the best results by cutting down on the number of loss functions. This is due to the fact that YOLOv7 has the benefit of lowering the number of computing operations required since it uses just a single stage rather than numerous stages like RCNN does. Because of the new network architecture, also known as the extended efficient layer aggregation network (E-ELAN), the computational speed has decreased, while the accuracy rate has increased [
24]; this is due to the YOLOv7 mechanism, which aims to reduce the number of parameters that are used.
On the other hand, the YOLOv5n model showed precise detection results, with an average detection accuracy of 95% at an intersection over a union of 50%. This should not come as a surprise considering that only one entry in the data set corresponds to the goal, which stands for smoke. This is where the power of this model becomes apparent, as it can perform well in detecting operations even in areas with little space and components. On the other hand, when the size of the YOLOv5 models increased, the model’s capacity to identify more items in more image dimensions also increased. This is because the size of the neural networks increased.
Illustrating the feasibility of smoke-detection models from various detection areas, the detection accuracy varied between 70% and 100%.
Figure 6,
Figure 7,
Figure 8,
Figure 9,
Figure 10,
Figure 11 and
Figure 12 show samples of YOLO model detection findings in three dimensions: close, medium, and distance. In addition, this study aims to minimize the sensitivity of detection models to future data while increasing detection accuracy in different locations and dimensions. Consequently, in this work, we used data-augmentation methods such as cropping images and altering their color tone, which increased the capacity of models to recognize distinct scenarios properly.
To emphasize the state-of-the-art of the recommended proposed methodology in comparison to the methodologies used in prior research, this study aims to evaluate and contrast the capabilities of various YOLO models in terms of how quickly and accurately they can spot smoke from forest fires. We have found that some of the data sets that are accessible online have certain issues. These issues include a lack of data labels and a disorganization of the data, making it very time-consuming to generate a new data set. As a result, in this study, we used a set of methods to increase the data, which ultimately led to an increase in the number of training elements in the data set that was used, a decrease in the classification sensitivity of the detection models, and a decrease in the proportion of overfitting. Additionally, we highlighted one of the most prominent challenges in detecting smoke and forest fires, which is represented by the appearance of some elements with high illumination that can be detected as fires or smoke, but in reality, are not fires or smoke. As a result, we adhered to using a dataset from the Kaggle repository. This dataset describes three distinct detection zones, including proximal, middle, and distant.
On the other hand, given the presence of a large number of previously developed detection models using a variety of neural network types, one of the goals of this work is to identify the kind of detection model that is most effective for the early detection of fires. Consequently, we compared the performance results of several detection models with the findings of the study technique that was devised and carried out on an altered data set to detect fire smoke. The findings of prior detection models are compiled in
Table 6, along with a comparison of those results with those of YOLO detection models. With this due consideration, the YOLO models demonstrated superior performance in terms of both accuracy and speed.
The finite detection approach in the Fast R-CNN model being a static method sheds light on the reasons why YOLO detection models outperform some prior models. As a result, no simultaneous learning takes place, which may result in the generation of poor proposals for the bounding box [
25]. Moreover, in the Faster R-CNN detection model, detecting many components with comparable characteristics in the same picture is a time-consuming procedure for neural networks, which may result in detection delays and incorrect classification processes [
26]. It is, nevertheless, still quite effective for real-time detection. Nonetheless, neural networks do not generate enough features in the SSD detection model to detect small items [
27], for example, detecting smoke from flames, if the data sets contain one or two target items for detection, such as fires and smoke. As a result, we proposed in this study to employ numerous data-augmentation strategies to increase the amount and quality of training objects. On the other hand, several prior YOLO detection models, such as YOLOv4 and YOLOv2, lack the capacity to identify many small objects in one location [
28]. Yolo models, for example, partition a picture into grids and then identify the components within each grid. As a result, the problem arises in recognizing little or distant features if there are many inside the image’s single grid.
Table 6.
Performance of YOLOv3, YOLOv5, and YOLOv7 compared to prior models.
Table 6.
Performance of YOLOv3, YOLOv5, and YOLOv7 compared to prior models.
| Detection Model | Mean Average Precision (mAP) at IoU of 50% |
|---|
| Fast R-CNN [25] | 68.3% |
| Faster R-CNN [26] | 70.6% |
| YOLOv4 [29] | 77.5% |
| EfficientDet [30] | 77.4% |
| SSD [31] | 71.3% |
| YOLOv5n | 95.04% |
| YOLOv5s | 94.9% |
| YOLOv5m | 93.5% |
| YOLOv5l | 94.3% |
| YOLOV5x | 96.8% |
| YOLOv3 | 94.8% |
| YOLOv7 | 95.08% |
Now, some light will be shed on the study’s shortcomings. Some reduction functions, such as the classification loss gain function, whose value was zero in all models, were not utilized to compare detection models. This is due to the dataset only having one classification class. We also note that a small sample of forest-fire smoke detection data is erroneous.
Figure 13 shows where the clouds were recognized as smoke from fires in daylight mode. The detection models’ power rests in their ability to be trained on additional data sets representing fire smoke in day and night modes and extracts from climate change in the areas. Furthermore, altering the parameters in the detection models may vary from experiment to experiment depending on the amount and quality of the data collected and the speed of the detectors employed. However, to solve the problem of misclassifying clouds as smoke, it is suggested to add another distinct element to the data set that represents clouds. Although this solution will be effective, some physical properties of the common substance between smoke and clouds will be specified in the detection operations and it is an expensive process. Therefore, we shed light on the problem of detecting fire smoke, especially smoke from fires, which tends to be white, as opposed to black, which will be easier to distinguish from clouds. Additionally, we noticed that the number of clouds in the images of the available and used dataset is not sufficient in all cases to redefine a new discrimination element. However, a radical solution to this problem is to develop fractional detection models to analyze smoke properties and separate them from elements that have similar properties.
On the other hand, it should be noted that searching for the optimum detection model might be challenging, if not impossible. This is owing to the numerous constraints, such as a lack of appropriate labeled data sets to conduct experiments on assessing the effectiveness of many detection models to identify smoke from fires in various conditions, such as internal and outdoor flames, daylight fires, and nocturnal fires [
31]. This is due to the high expense of addressing data sets [
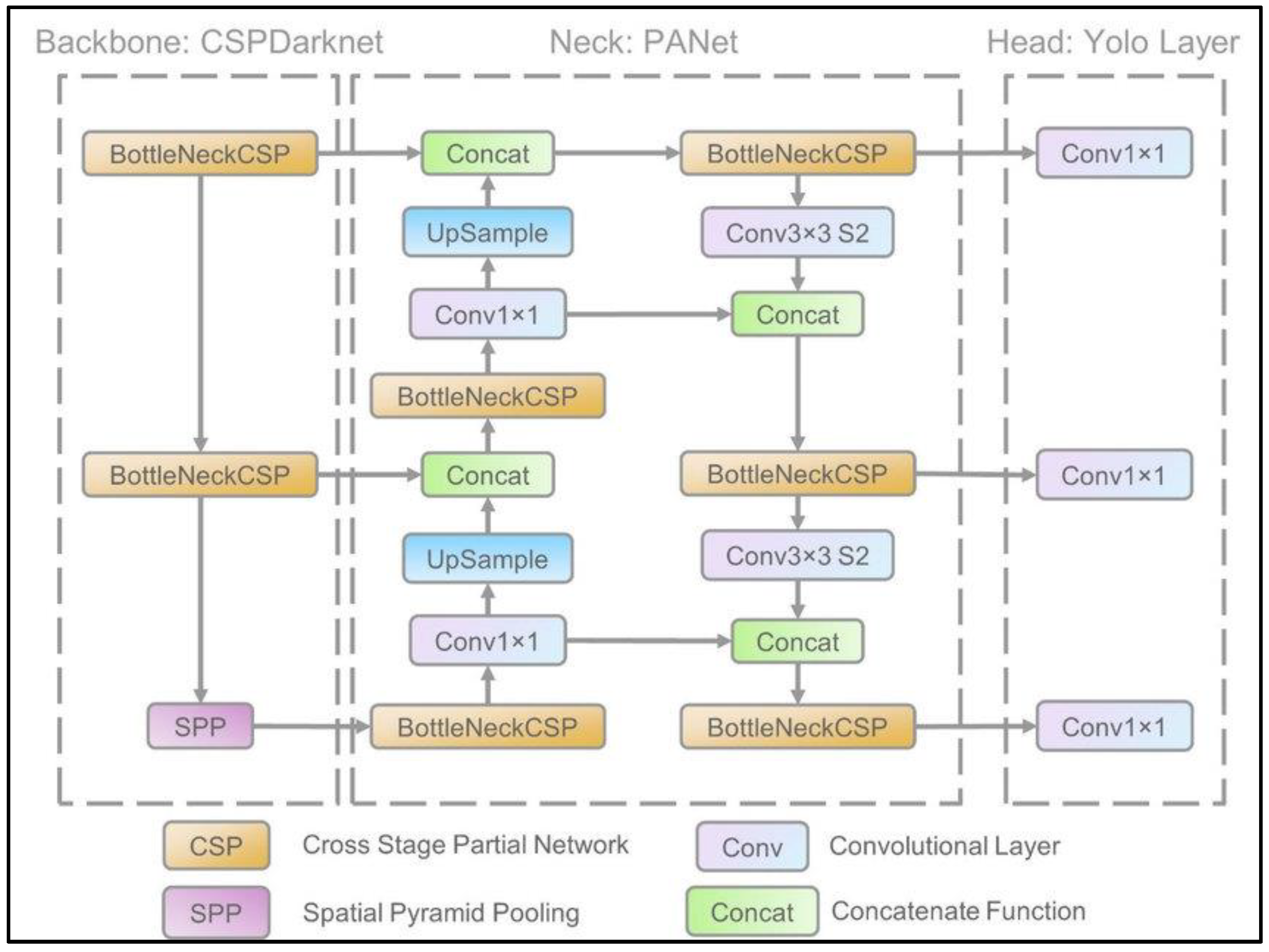
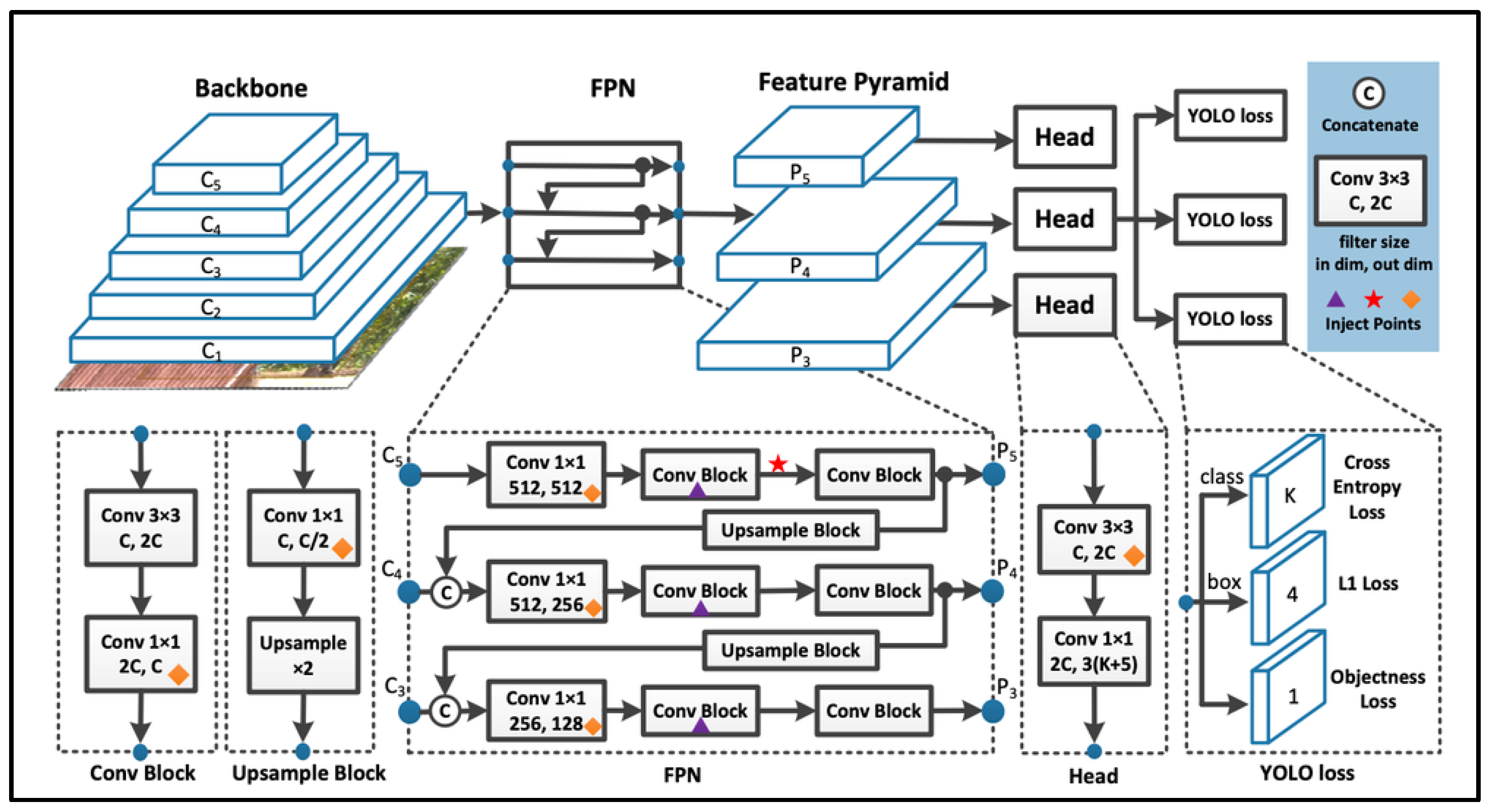
32], as well as the technology required to detect fire smoke early and distinguish it under climate change circumstances. In this paper, however, we described the distinctions between common technologies, such as optimization algorithms, which can be utilized in all sorts of detection models and play a key role in enhancing and modifying detection speed. Furthermore, the comparisons in this paper aim to highlight the molecules and components of detection model networks that differ from one detection model to another, such as YOLOv5 that uses the PANet network and YOLOv7 that uses the E-ELAN network, and to demonstrate the differences in performance in forest fire detection operations. As a result, determining the best detection model is entirely dependent on the state of the available environment, the detection areas and their dimensions, the speed of polarization of the detection devices and their effectiveness, the quality of the collected data, and the accuracy of the data set.


 ,
, 
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}












