
Online Multiple Object Tracking Using Spatial Pyramid Pooling Hashing and Image Retrieval for Autonomous Driving


Abstract
:1. Introduction
- A spatial pyramidal pooling hash network is designed to generate appearance features. Multiple-level representative features in the SPPHNet are mapped into a similarity-preserving binary space, called hash features. The hash features retain the visual discriminability of high-dimensional features and, at the same time, are of benefit to computational efficiency. The SPPHNet is capable of accommodating various sizes of bounding boxes, thus avoiding information loss caused by resizing;
- We design a two-tier data association scheme consisting of an affinity cost model and a hash-based image retrieval model to address the occlusion issue. The affinity cost model accommodates hash features, disparity, and optical flow as the first tier of data association. The hash-based image retrieval model exploits the hash features and adopts the image retrieval technology of “querying image with image” to handle reappearing objects and reduce ID switches as the second tier of data association;
- The ablation study has proven the effectiveness of various components. The experiments conducted on the public benchmark dataset and our own collected campus scenario sequences demonstrate that the proposed method surpasses state-of-the-art vision-based MOT methods.
2. Related Work
2.1. Tracking by Detection
2.2. Joint Detection and Tracking
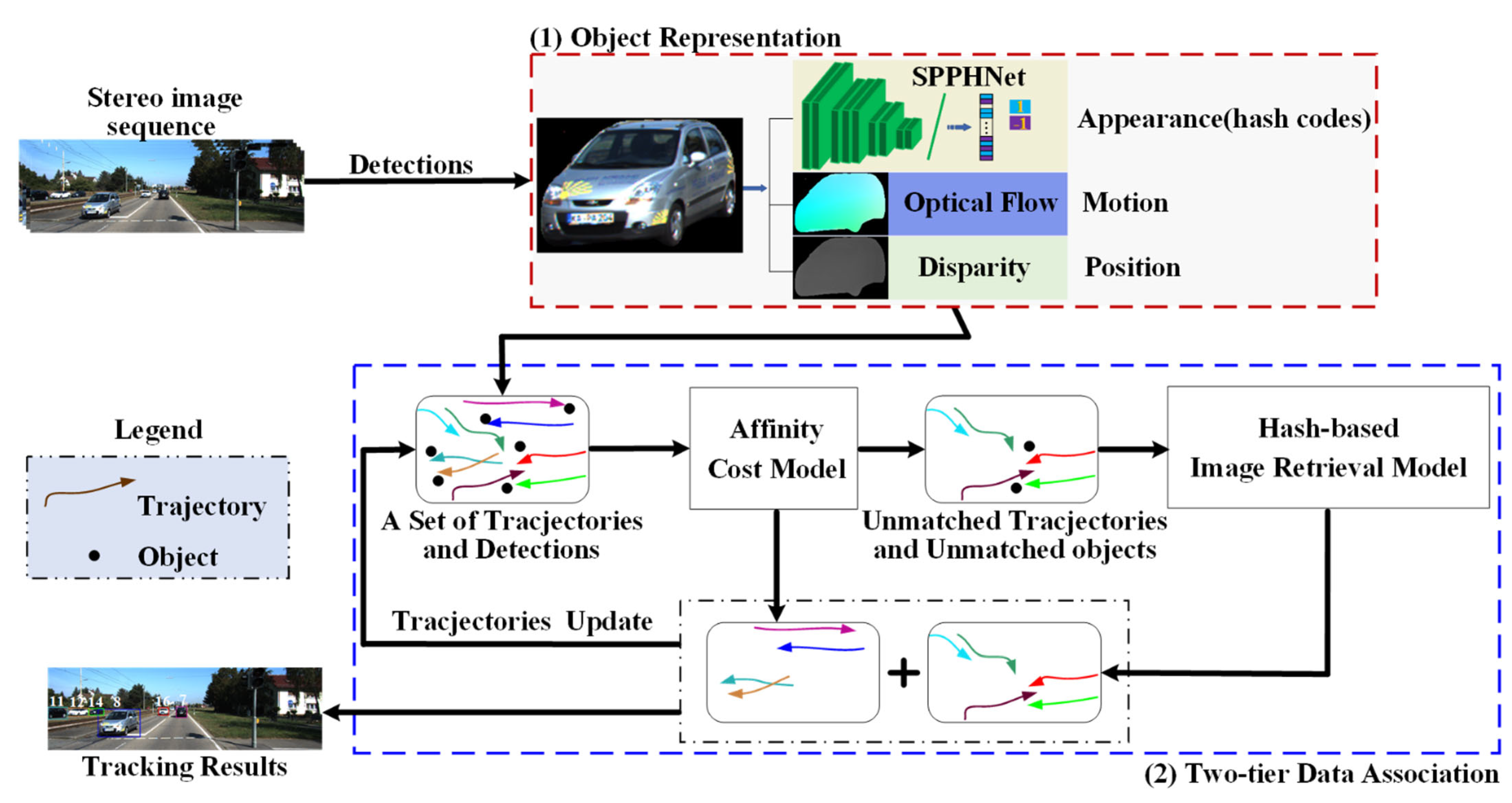
3. Method
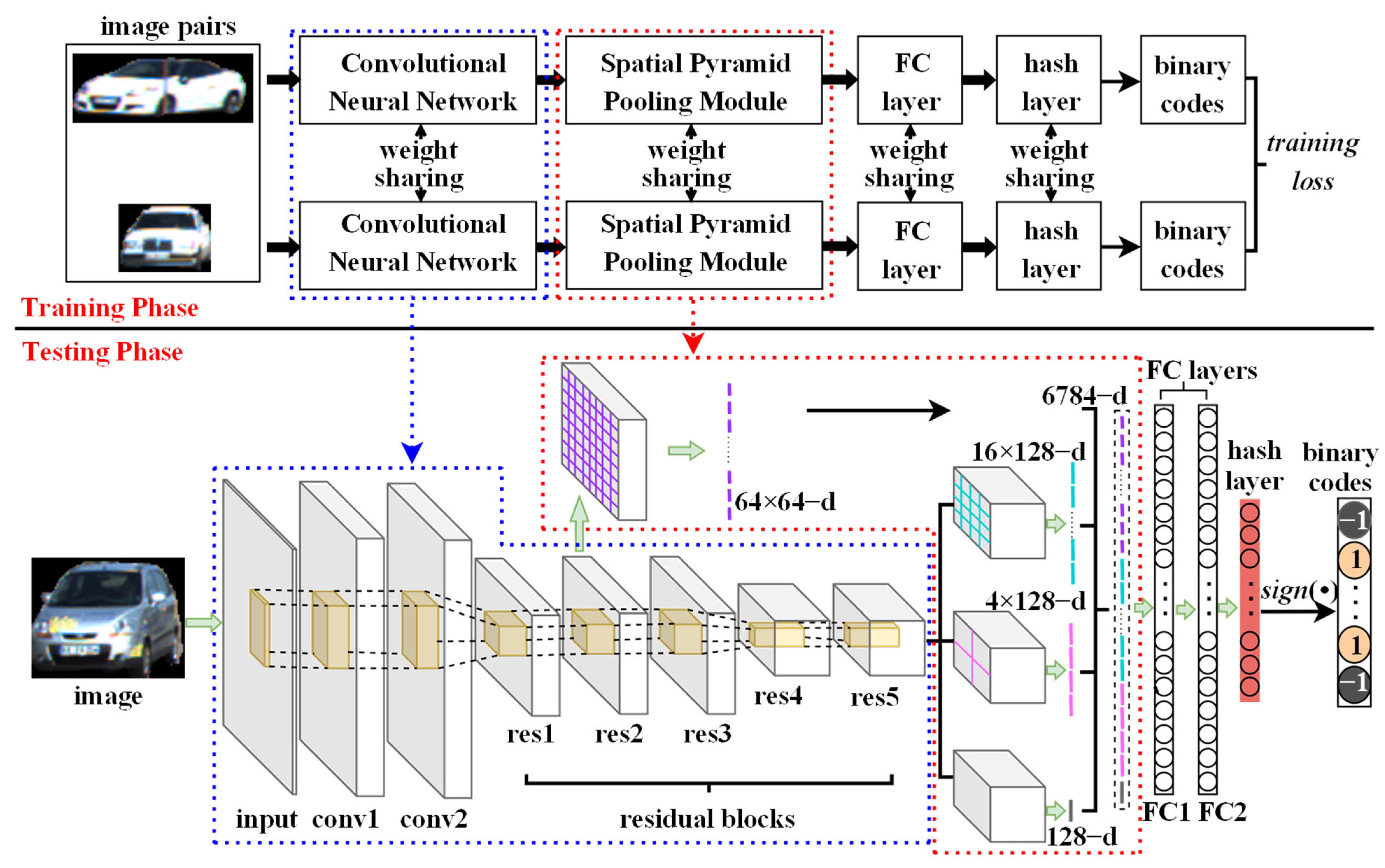
3.1. Object Representation
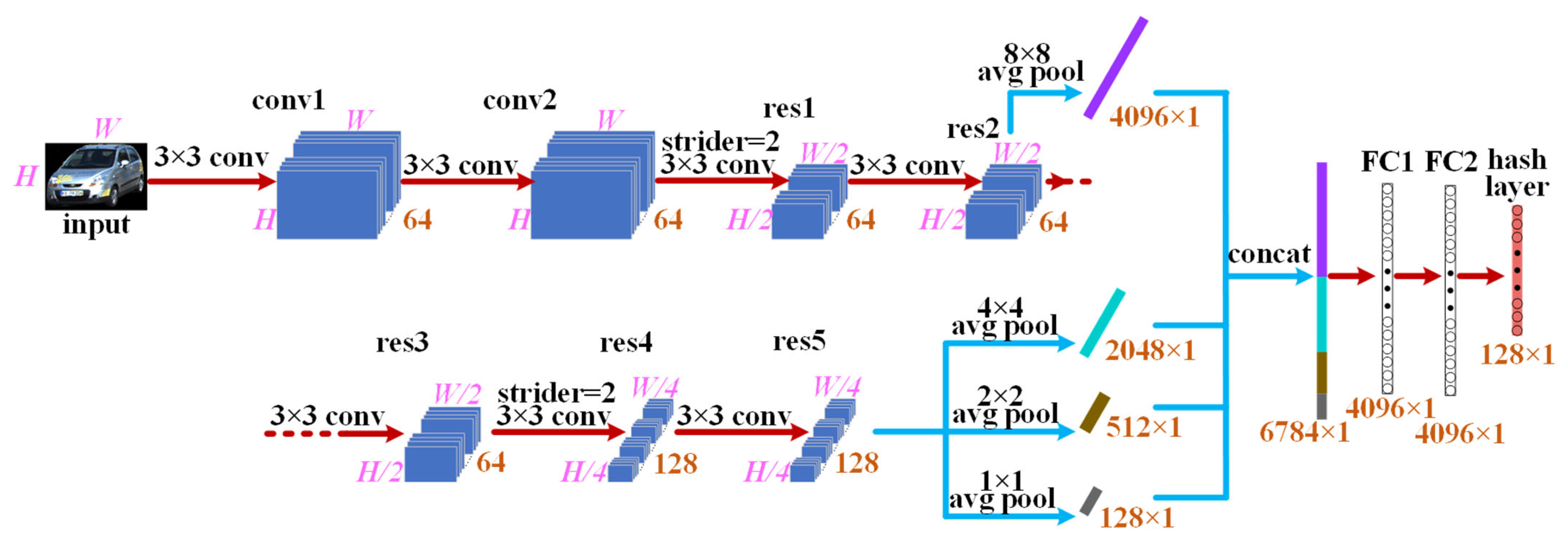
3.1.1. Architecture of Spatial Pyramid Pooling Hash Network for Appearance Feature Extraction
3.1.2. Spatial Pyramid Pooling Hash Network Learning
- (1)
- Cross-Entropy Loss
- (2)
- Quantization Loss
- (3)
- Overall Loss
3.2. Two-Tier Data Association
3.2.1. The First-Tier Data Association: Affinity Cost Model
- (1)
- Appearance Affinity Metric
- (2)
- Motion affinity metric
- (3)
- Position affinity metric
3.2.2. The Second-Tier Data Association: Hash-Based Image Retrieval Model
| Algorithm 1: Implementation flow for our proposed two-tier data association approach |
| Input: The set of objects of frame ; The set of objects of frame ; The set of existing object trajectories from frame to ; Output: The set of object trajectories of frame 1: if and then 2: Calculate between and according to Equation (12); 3: Construct the affinity cost model according to Equation (11); 4: Use the Hungarian algorithm to solve for to obtain the optimal association matching pairs; 5: The affinity of each optimal association matching pair is greater than , and update the corresponding trajectory; 6: For the unmatched objects (, ) and unmatched trajectories 7: if and then 8: for the object do 9: Use the hash code to retrieve the objects in with the smallest Hamming distance and their corresponding trajectories ; 10: For each trajectory in , find the m closest objects to the current frame and calculate the affinity with according to Equation (13); 11: Calculate the affinity of each trajectory in with according to Equation (14); 12: Construct an affinity between and ; 13: if then 14: is matched with the trajectory corresponding to , and update the corresponding trajectory; 15: end if 16: end for 17: else 18: Generate new trajectories; 19: end if 20: Update the trajectories; 21: end if |
4. Experiments
4.1. SPPHNet Training and Performance
4.1.1. SPPHNet Training
4.1.2. SPPHNet Performance
4.2. MOT Evaluation Metrics
4.3. Ablation Study
4.4. Comparison with the State-of-the-Art Methods
4.4.1. Benchmark Evaluation
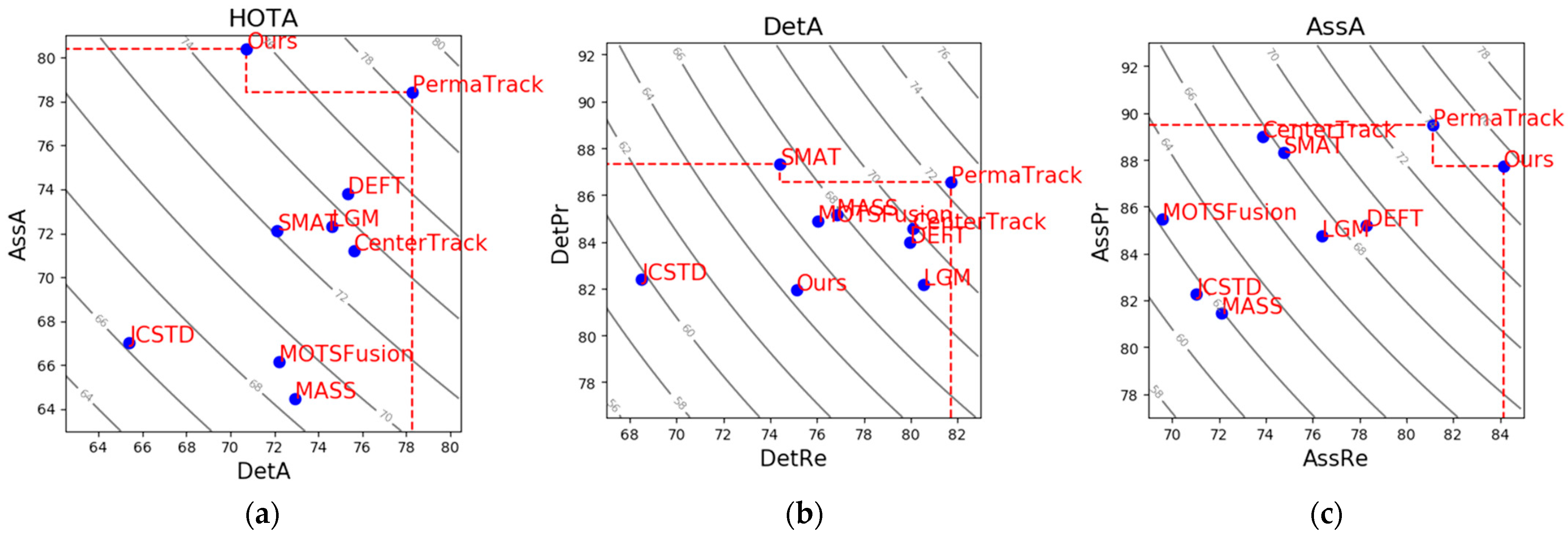
4.4.2. Benchmark Evaluation in Multiple Dimensions
4.5. Visually Intuitive Evaluation
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Ravindran, R.; Santora, M.J.; Jamali, M.M. Multi-Object detection and tracking, based on dNN, for autonomous vehicles: A review. IEEE Sens. J. 2021, 21, 5668–5677. [Google Scholar] [CrossRef]
- Zhang, C.; Yang, Z.; Liao, L.; You, Y.; Sui, Y.; Zhu, T. RPEOD: A real-time pose estimation and object detection system for aerial robot target tracking. Machines 2022, 10, 181. [Google Scholar] [CrossRef]
- Chong, Y.L.; Lee, C.D.W.; Chen, L.; Shen, C.; Chan, K.K.H.; Ang, M.H., Jr. Online obstacle trajectory prediction for autonomous buses. Machines 2022, 10, 202. [Google Scholar] [CrossRef]
- Lee, M.-F.R.; Lin, C.-Y. Object tracking for an autonomous unmanned surface vehicle. Machines 2022, 10, 378. [Google Scholar] [CrossRef]
- Li, J.; Wei, L.; Zhang, F.; Yang, T.; Lu, Z. Joint deep and depth for object-level segmentation and stereo tracking in crowds. IEEE Trans. Multimed. 2019, 21, 2531–2544. [Google Scholar] [CrossRef]
- Karunasekera, H.; Wang, H.; Zhang, H. Multiple object tracking with attention to appearance, structure, motion and size. IEEE Access 2019, 7, 104423–104434. [Google Scholar] [CrossRef]
- Tian, W.; Lauer, M.; Chen, L. Online multi-object tracking using joint domain information in traffic scenarios. IEEE Trans. Intell. Transp. Syst. 2020, 21, 374–384. [Google Scholar] [CrossRef]
- Sun, Z.; Chen, J.; Mukherjee, M.; Liang, C.; Ruan, W.; Pan, Z. Online multiple object tracking based on fusing global and partial features. Neurocomputing 2022, 470, 190–203. [Google Scholar] [CrossRef]
- Lin, X.; Li, C.-T.; Sanchez, V.; Maple, C. On the detection-to-track association for online multi-object tracking. Pattern Recognit. Lett. 2021, 146, 200–207. [Google Scholar] [CrossRef]
- Gonzalez, N.F.; Ospina, A.; Calvez, P. SMAT: Smart multiple affinity metrics for multiple object tracking. In Proceedings of the International Conference on Image Analysis and Recognition, Póvoa de Varzim, Portugal, 24–26 June 2020. [Google Scholar]
- Kim, A.; Ošep, A.; Leal-Taixé, L. EagerMOT: 3D multi-object tracking via sensor fusion. In Proceedings of the 2021 IEEE International Conference on Robotics and Automation (ICRA), Xi’an, China, 30 May–5 June 2021. [Google Scholar]
- Luiten, J.; Fischer, T.; Leibe, B. Track to reconstruct and reconstruct to track. IEEE Robot. Autom. Lett. 2020, 5, 1803–1810. [Google Scholar] [CrossRef] [Green Version]
- Wang, G.; Gu, R.; Liu, Z.; Hu, W.; Song, M.; Hwang, J. Track without appearance: Learn box and tracklet embedding with local and global motion patterns for vehicle tracking. In Proceedings of the 2021 IEEE/CVF International Conference on Computer Vision (ICCV), Montreal, QC, Canada, 10–17 October 2021. [Google Scholar]
- Wei, H.; Huang, Y.; Hu, F.; Zhao, B.; Guo, Z.; Zhang, R. Motion Estimation Using Region-Level Segmentation and Extended Kalman Filter for Autonomous Driving. Remote Sens. 2021, 13, 1828. [Google Scholar] [CrossRef]
- Liu, K.; Hu, R.; Ma, Z. Object Location and Tracking in Binocular Vision System. In Proceedings of the 1st International Conference on Communications and Information Processing, Aveiro, Portugal, 7–11 March 2012. [Google Scholar]
- Haq, Q.M.U.; Lin, C.H.; Ruan, S.J.; Gregor, D. An edge-aware based adaptive multi-feature set extraction for stereo matching of binocular images. J. Ambient. Intell. Human. Comput. 2022, 13, 1953–1967. [Google Scholar] [CrossRef]
- Xiang, J.; Zhang, G.; Hou, J. Online multi-object tracking based on feature representation and bayesian filtering within a deep learning architecture. IEEE Access 2019, 7, 27923–27935. [Google Scholar] [CrossRef]
- Xiong, Z.; Tang, Z.; Chen, X.; Zhang, X.; Zhang, K.; Ye, C. Research on image retrieval algorithm based on combination of color and shape features. J. Sign. Process. Syst. 2021, 93, 139–146. [Google Scholar]
- Yan, C.; Gong, B.; Wei, Y.; Gao, Y. Deep multi-view enhancement hashing for image retrieval. IEEE Trans. Pattern Anal. Mach. Intell. 2021, 43, 1445–1451. [Google Scholar] [CrossRef] [Green Version]
- Simon, M.; Amende, K.; Kraus, A.; Honer, J.; Sämann, T.; Kaulbersch, H.; Milz, S.; Gross, H.M. Complexer-yolo: Real-time 3d object detection and tracking on semantic point clouds. In Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops (CVPRW), Long Beach, CA, USA, 16–17 June 2019. [Google Scholar]
- Cai, Y.; Li, B.; Jiao, Z.; Li, H.; Zeng, X.; Wang, X. Monocular 3d object detection with decoupled structured polygon estimation and height-guided depth estimation. In Proceedings of the AAAI Conference on Artificial Intelligence (AAAI), New York, NY, USA, 7–12 February 2020. [Google Scholar]
- Cai, Y.; Luan, T.; Gao, H.; Wang, H.; Chen, L.; Sotelo, M.A.; Li, Z. YOLOv4-5D: An Effective and Efficient Object Detector for Autonomous Driving. IEEE Trans. Instrum. Meas. 2021, 70, 1–13. [Google Scholar] [CrossRef]
- Kuhn, H.W. The Hungarian method for the assignment problem. Nav. Res. Logist. Q. 1955, 2, 83–97. [Google Scholar] [CrossRef] [Green Version]
- Zhou, X.; Koltun, V.; Krähenbühl, P. Tracking objects as points. In Proceedings of the European Conference on Computer Vision, Online, 23–28 August 2020. [Google Scholar]
- Tokmakov, P.; Li, J.; Burgard, W.; Gaidon, A. Learning to track with object permanence. In Proceedings of the 2021 IEEE/CVF International Conference on Computer Vision (ICCV), Montreal, QC, Canada, 10–17 October 2021. [Google Scholar]
- Chaabane, M.; Zhang, P.; Beveridge, R.; O’Hara, S. DEFT: Detection embeddings for tracking. arXiv 2021, arXiv:2102.02267. [Google Scholar]
- Sun, S.; Akhtar, N.; Song, H.; Mian, A.; Shah, M. Deep affinity network for multiple object tracking. IEEE Trans. Pattern Anal. Mach. Intell. 2021, 43, 104–119. [Google Scholar] [CrossRef] [Green Version]
- Wu, J.; Cao, J.; Song, L.; Wang, Y.; Yang, M.; Yuan, J. Track to detect and segment: An online multi-object tracker. In Proceedings of the 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Nashville, TN, USA, 20–25 June 2021. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Spatial pyramid pooling in deep convolutional networks for visual recognition. IEEE Trans. Pattern Anal. Mach. Intell. 2015, 37, 1904–1916. [Google Scholar] [CrossRef] [Green Version]
- Cao, Y.; Long, M.; Liu, B.; Wang, J. Deep cauchy hashing for hamming space retrieval. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018. [Google Scholar]
- Kang, R.; Cao, Y.; Long, M.; Wang, J.; Yu, P.S. Maximum-Margin hamming hashing. In Proceedings of the 2019 IEEE/CVF International Conference on Computer Vision (ICCV), Seoul, Korea, 27 October–2 November 2019. [Google Scholar]
- Geiger, A.; Lenz, P.; Stiller, C. Vision meets robotics: The KITTI dataset. Int. J. Rob. Res. 2013, 32, 1231–1237. [Google Scholar] [CrossRef] [Green Version]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016. [Google Scholar]
- Simonyan, K.; Zisserman, A. V ery deep convolutional networks for large-scale image recognition. In Proceedings of the 2015 International Conference on Learning Representations, San Diego, CA, USA, 7–9 May 2015. [Google Scholar]
- Luiten, J.; Ošep, A.; Dendorfer, P.; Torr, P.; Geiger, A.; Leal-Taixé, L.; Leibe, B. HOTA: A higher order metric for evaluating multi-object tracking. Int. J. Comput. Vis. 2021, 129, 548–578. [Google Scholar] [CrossRef] [PubMed]
- Bernardin, K.; Stiefelhagen, R. Evaluating multiple object tracking performance: The CLEAR MOT metrics. EURASIP J. Image Video Process. 2008, 2008, 246309. [Google Scholar] [CrossRef] [Green Version]
- Li, Y.; Huang, C.; Nevatia, R. Learning to associate: HybridBoosted multi-target tracker for crowded scene. In Proceedings of the 2009 IEEE Conference on Computer Vision and Pattern Recognition, Miami, FL, USA, 20–25 June 2009. [Google Scholar]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Object ID | Network | (a) | (b) | (c) | (d) | (e) |
|---|---|---|---|---|---|---|
| Car1 | ResNet50 | 0.7295 | 0.7425 | 0.7475 | 0.712 | 0.6659 |
| VGG16 | 0.6809 | 0.7959 | 0.7248 | 0.6976 | 0.6189 | |
| SPPHNet | 0.8359 | 0.875 | 0.9219 | 0.9297 | 0.7653 | |
| Car2 | ResNet50 | 0.4956 | 0.5201 | 0.5174 | 0.5334 | 0.468 |
| VGG16 | 0.4629 | 0.5138 | 0.5389 | 0.5213 | 0.5009 | |
| SPPHNet | 0.1328 | 0.1953 | 0.1719 | 0.1641 | 0.1406 | |
| Car3 | ResNet50 | 0.5177 | 0.504 | 0.5371 | 0.5159 | 0.4143 |
| VGG16 | 0.4602 | 0.4738 | 0.4904 | 0.4506 | 0.4272 | |
| SPPHNet | 0.2422 | 0.1328 | 0.1328 | 0.0938 | 0.1328 |
| Different Versions of Our Method | HOTA | DetA | AssA | MOTA | MT | ML | |
|---|---|---|---|---|---|---|---|
| app + mo + pos + AC + HIR | 82.37 | 80.16 | 85.23 | 90.70 | 96.84 | 0 | 7 |
| mo + pos + AC + HIR | 74.28 | 69.3 | 79.86 | 79.02 | 74.74 | 4.21 | 31 |
| app + pos + AC + HIR | 76.15 | 71.44 | 81.37 | 79.02 | 73.68 | 5.26 | 24 |
| app + mo + AC + HIR | 77.24 | 72.68 | 82.32 | 80.89 | 84.21 | 6.84 | 21 |
| app + mo + pos + AC | 77.27 | 72.89 | 82.16 | 84.18 | 87.89 | 5.26 | 19 |
| HOTA | DetA | AssA | MOTA | MT | ML | Runtime | ||
|---|---|---|---|---|---|---|---|---|
| CenterTrack [24] $ | 73.02 | 75.62 | 71.20 | 88.83 | 82.15 | 2.46 | 254 | 45 |
| DEFT [26] $ | 74.23 | 75.33 | 73.79 | 88.38 | 84.31 | 2.15 | 344 | 40 |
| PermaTrack [25] $ | 78.03 | 78.29 | 78.41 | 91.33 | 85.69 | 2.62 | 258 | 100 |
| JCSTD [7] | 65.94 | 65.37 | 67.03 | 80.24 | 57.08 | 7.85 | 173 | 70 + D |
| MASS [6] | 68.25 | 72.92 | 64.46 | 84.64 | 74.00 | 2.92 | 353 | 10 + D |
| LGM [13] | 73.14 | 74.61 | 72.31 | 87.60 | 85.08 | 2.46 | 448 | 80 + D |
| SMAT [10] | 71.88 | 72.13 | 72.13 | 83.64 | 62.77 | 6.00 | 198 | 100 + D |
| MOTSFusion [12] | 68.74 | 72.19 | 66.16 | 84.24 | 72.77 | 2.92 | 415 | 440 + D |
| Ours | 74.69 | 70.74 | 80.38 | 85.72 | 74.61 | 3.54 | 104 | 37 + D |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wei, H.; Huang, Y. Online Multiple Object Tracking Using Spatial Pyramid Pooling Hashing and Image Retrieval for Autonomous Driving. Machines 2022, 10, 668. https://doi.org/10.3390/machines10080668
Wei H, Huang Y. Online Multiple Object Tracking Using Spatial Pyramid Pooling Hashing and Image Retrieval for Autonomous Driving. Machines. 2022; 10(8):668. https://doi.org/10.3390/machines10080668
Chicago/Turabian StyleWei, Hongjian, and Yingping Huang. 2022. "Online Multiple Object Tracking Using Spatial Pyramid Pooling Hashing and Image Retrieval for Autonomous Driving" Machines 10, no. 8: 668. https://doi.org/10.3390/machines10080668