Object Detection and Distance Measurement in Teleoperation


Abstract
:1. Introduction
2. Object Detection
2.1. Object Detection Structure
2.2. Detection Paradigms
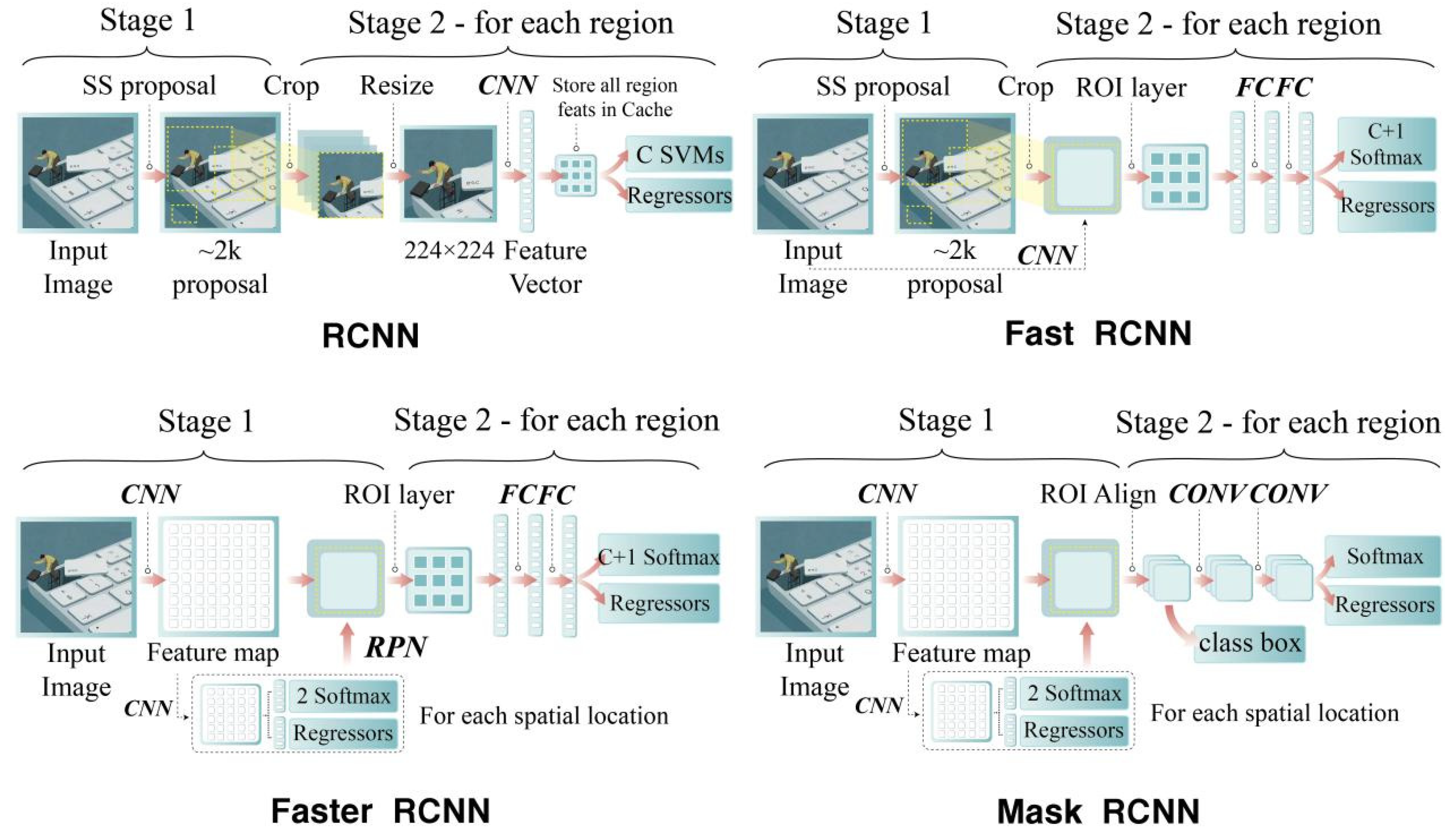
2.2.1. Two-Stage Detectors
- RCNN.
- Fast RCNN.
- Faster RCNN.
- Mask RCNN.
2.2.2. One-Stage Detectors
- OverFeat.
- YOLO.
- SSD.
- RetinaNet.
2.2.3. Detector Structure
2.3. Datasets
- Pascal VOC.
- MSCOCO.
- ImageNet.
- Open Images.
2.4. Others
2.4.1. Three-Dimensional Object Detection
2.4.2. Target Tracking
3. Distance Measurement
3.1. Monocular Vision
3.2. Stereo Vision
3.3. ToF
3.4. Structured Light
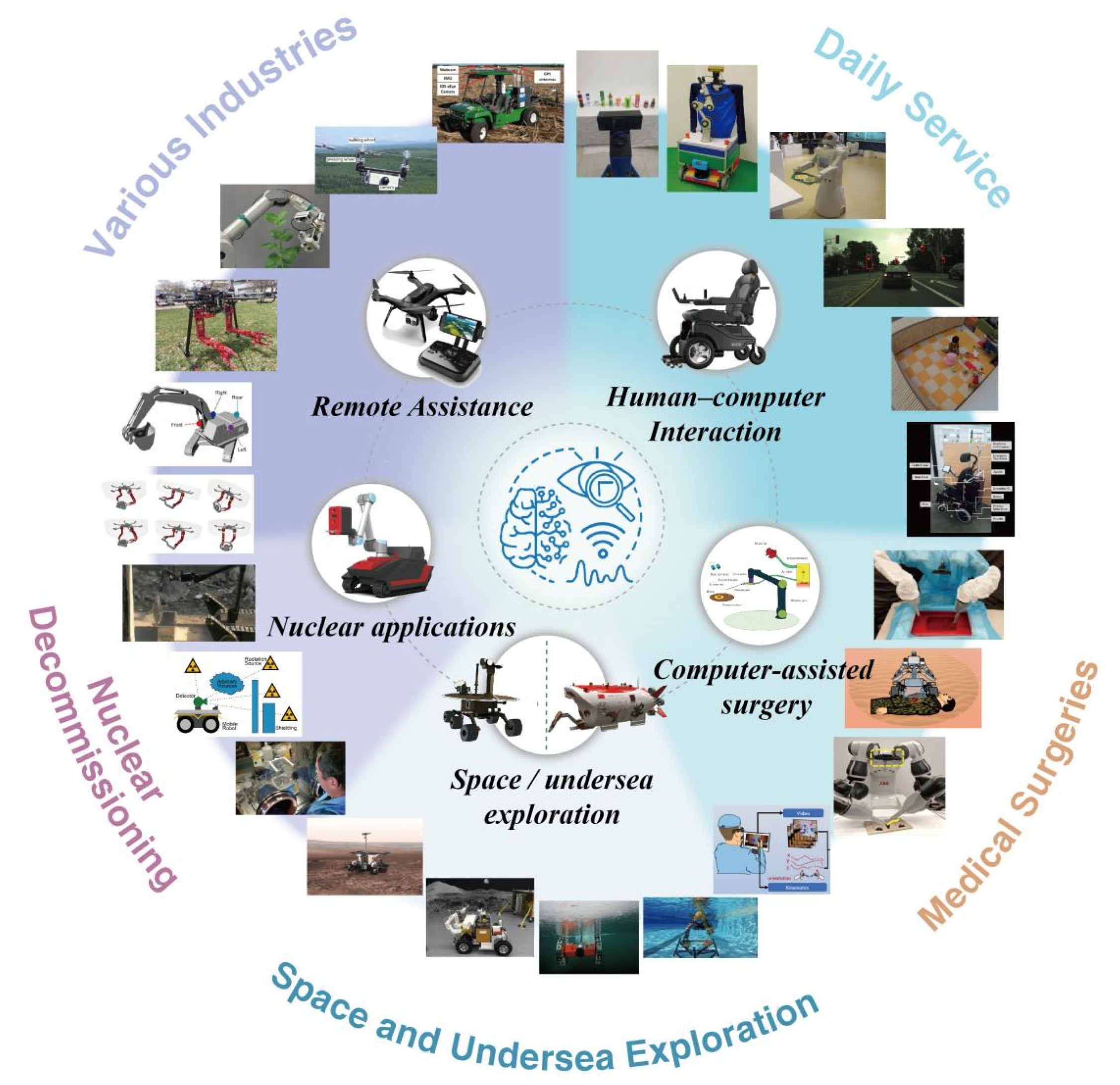
4. Applications
4.1. Medical Surgeries
4.2. Nuclear Decommissioning
4.3. Space and Undersea Exploration
4.4. Various Industries
4.5. Daily Service
5. Challenges
5.1. Challenges in Computer Vision
- Deformation.
- Occlusion.
- Illumination changes.
- Cluttered or textured background.
5.2. Challenges in Human Experience
6. Possible Future Directions and Conclusions
7. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Conflicts of Interest
References
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. Imagenet classification with deep convolutional neural networks. NIPS 2012, 60, 84–90. [Google Scholar] [CrossRef]
- Sermanet, P.; Eigen, D.; Zhang, X.; Mathieu, M.; Fergus, R.; LeCun, Y. Integrated recognition, localization and detection using convolutional networks. arXiv 2013, arXiv:1312.6229. [Google Scholar]
- Vedaldi, A.; Gulshan, V.; Varma, M.; Zisserman, A. Multiple kernels for object detection. In Proceedings of the IEEE 12th International Conference on Computer Vision (ICCV), Kyoto, Japan, 29 September–2 October 2009. [Google Scholar]
- Viola, P.; Jones, M. Rapid object detection using a boosted cascade of simple features. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition (CVPR), Kauai, HI, USA, 8–14 December 2001. [Google Scholar]
- Harzallah, H.; Jurie, F.; Schmid, C. Combining efficient object localization and image classification. In Proceedings of the IEEE 12th International Conference on Computer Vision (ICCV), Kyoto, Japan, 29 September–2 October 2009. [Google Scholar]
- Uijlings, J.R.R.; Van de Sande, K.E.A.; Gevers, T.; Smeulders, A.W.M. Selective Search for Object Recognition. Int. J. Comput. Vis. 2013, 104, 154–171. [Google Scholar] [CrossRef] [Green Version]
- Lowe, D.G. Object recognition from local scale-invariant features. In Proceedings of the 7th IEEE International Conference on Computer Vision (ICCV), Kerkyra, Greece, 20–27 September 1999. [Google Scholar]
- Dalal, N.; Triggs, B. Histograms of oriented gradients for human detection. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition (CVPR), San Diego, CA, USA, 20–25 June 2005. [Google Scholar]
- Hearst, M.A.; Dumais, S.T.; Osuna, E.; Platt, J.; Scholkopf, B. Support vector machines. IEEE Intell. Syst. Their Appl. 1998, 13, 18–28. [Google Scholar] [CrossRef] [Green Version]
- Felzenszwalb, P.F.; Girshick, R.B.; McAllester, D.; Ramanan, D. Object detection with discriminatively trained part-based models. IEEE Trans. Pattern Anal. Mach. Intell. 2009, 32, 1627–1645. [Google Scholar] [CrossRef] [Green Version]
- Opitz, D.; Maclin, R. Popular ensemble methods: An empirical study. J. Artifi. Intel. Res. 1999, 11, 169–198. [Google Scholar] [CrossRef]
- Viola, P.; Jones, M.J. Robust Real-Time Face Detection. Int. J. Comput. Vis. 2004, 57, 137–154. [Google Scholar] [CrossRef]
- Freund, Y.; Schapire, R.E. Experiments with a new boosting algorithm. In Proceedings of the 13th International Conference on International Conference on Machine Learning (ICML), Bari, Italy, 3–6 July 1996. [Google Scholar]
- Girshick, R.; Donahue, J.; Darrell, T.; Malik, J. Rich feature hierarchies for accurate object detection and semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Columbus, OH, USA, 23–28 June 2014. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Spatial pyramid pooling in deep convolutional networks for visual recognition. IEEE Trans. Pattern Anal. Mach. Intell. 2015, 37, 1904–1916. [Google Scholar] [CrossRef] [Green Version]
- Girshick, R. Fast r-cnn. In Proceedings of the IEEE International Conference on Computer Vision (ICCV), Santiago, Chile, 7–13 December 2015. [Google Scholar]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 1137–1149. [Google Scholar] [CrossRef] [Green Version]
- Lin, T.-Y.; Dollár, P.; Girshick, R.; He, K.; Hariharan, B.; Belongie, S. Feature pyramid networks for object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017. [Google Scholar]
- Cai, Z.; Vasconcelos, N. Cascade R-CNN: Delving into High Quality Object Detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–23 June 2018; pp. 6154–6162. [Google Scholar]
- He, K.; Gkioxari, G.; Dollár, P.; Girshick, R. Mask R-CNN. In Proceedings of the IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017. [Google Scholar]
- Pang, J.; Chen, K.; Shi, J.; Feng, H.; Ouyang, W.; Lin, D. Libra R-CNN: Towards Balanced Learning for Object Detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019; pp. 821–830. [Google Scholar]
- Lu, X.; Li, B.; Yue, Y.; Li, Q.; Yan, J. Grid R-CNN. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019; pp. 7363–7372. [Google Scholar]
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Reed, S.; Fu, C.Y.; Berg, A.C. SSD: Single Shot Multibox Detector. In Proceedings of the 14th European Conference on Computer Vision (ECCV), Amsterdam, The Netherlands, 11–14 October 2016. [Google Scholar]
- Fu, C.Y.; Liu, W.; Ranga, A.; Tyagi, A.; Berg, A.C. DSSD: Deconvolutional single shot detector. arXiv 2017, arXiv:1701.06659, 2017. [Google Scholar]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You Only Look Once: Unified, Real-Time Object Detection. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 779–788. [Google Scholar]
- Redmon, J.; Farhadi, A. YOLO9000: Better, Faster, Stronger. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017. [Google Scholar]
- Redmon, J.; Farhadi, A. Yolov3: An Incremental Improvement. arXiv 2018, arXiv:1804.02767. [Google Scholar]
- Bochkovskiy, A.; Wang, C.Y.; Liao, H.Y.M. YOLOv4: Optimal Speed and Accuracy of Object Detection. arXiv 2020, arXiv:2004.10934. [Google Scholar]
- Lin, T.; Goyal, P.; Girshick, R.B.; He, K.; Dollár, P. Focal loss for dense object detection. In Proceedings of the IEEE International Conference on Computer Vision (ICCV), Las Vegas, NV, USA, 22–29 October 2017. [Google Scholar]
- Simonyan, K.; Zisserman, A. Very Deep Convolutional Networks for Large-Scale Image Recognition. arXiv 2014, arXiv:1409.1556. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016. [Google Scholar]
- Xie, S.; Girshick, R.; Doll’ar, P.; Tu, Z.; He, K. Aggregated Residual Transformations for Deep Neural Networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017. [Google Scholar]
- Huang, G.; Liu, Z.; Van Der Maaten, L.; Weinberger, K.Q. Densely Connected Convolutional Networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017. [Google Scholar]
- Howard, A.G.; Zhu, M.; Chen, B.; Kalenichenko, D.; Wang, W.; Weyand, T.; Andreetto, M.; Adam, H. Mobilenets: Efficient Convolutional Neural Networks for Mobile Vision Applications. arXiv 2017, arXiv:1704.04861. [Google Scholar]
- Zhang, X.; Zhou, X.; Lin, M.; Sun, J. ShuffleNet: An Extremely Efficient Convolutional Neural Network for Mobile Devices. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 6848–6856. Available online: https://ieeexplore.ieee.org/document/8578814/ (accessed on 16 May 2022).
- Iandola, F.N.; Han, S.; Moskewicz, M.W.; Ashraf, K.; Dally, W.J.; Keutzer, K. SqueezeNet: AlexNet-level accuracy with 50x fewer parameters and <0.5 mb model size. arXiv 2016, arXiv:1602.07360. [Google Scholar]
- Chollet, F. Xception: Deep Learning with Depthwise Separable Convolutions. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017. [Google Scholar]
- Everingham, M.; Van Gool, L.; Williams, C.K.I.; Winn, J.; Zisserman, A. The Pascal Visual Object Classes (VOC) Challenge. Int. J. Comput. Vis. 2010, 88, 303–338. [Google Scholar] [CrossRef] [Green Version]
- Lin, T.-Y.; Maire, M.; Belongie, S.; Hays, J.; Perona, P.; Ramanan, D.; Doll´ar, P.; Zitnick, C.L. Microsoft coco: Common objects in context. In Proceedings of the 13th European Conference (ECCV), Zurich, Switzerland, 6–12 September 2014. [Google Scholar]
- Deng, J.; Dong, W.; Socher, R.; Li, L.-J.; Li, K.; Fei-Fei, L. Imagenet: A large-scale hierarchical image database. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Miami, FL, USA, 20–25 June 2009. [Google Scholar]
- Kuznetsova, A.; Rom, H.; Alldrin, N.; Uijlings, J.; Krasin, I.; Pont-Tuset, J.; Kamali, S.; Popov, S.; Malloci, M.; Duerig, T.; et al. The open images dataset v4: Unified image classification, object detection, and visual relationship detection at scale. arXiv 2018, arXiv:1811.00982. [Google Scholar] [CrossRef] [Green Version]
- Najafzadeh, N.; Fotouhi, M.; Kasaei, S. Object tracking using Kalman filter with adaptive sampled histogram. In Proceedings of the 23rd Iranian Conference on Electrical Engineering, Tehran, Iran, 10–14 May 2015; pp. 781–786. [Google Scholar]
- Danelljan, M.; Van, G.L.; Timofte, R. Probabilistic Regression for Visual Tracking. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) IEEE, Seattle, WA, USA, 13–19 June 2020; pp. 7183–7192. [Google Scholar]
- Lukezic, A.; Matas, J.; Kristan, M. D3S–A Discriminative Single Shot Segmentation Tracker. In Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPPR), Seattle, WA, USA, 13–19 June 2020. [Google Scholar]
- Hoiem, D.; Efros, A.A.; Hebert, M. Automatic photo pop-up. In Proceedings of the SIGGRAPH05: Special Interest Group on Computer Graphics and Interactive Techniques Conference (ACM SIGGRAPH 2005 Papers, 2005), Los Angeles, CA, USA, 31 July–4 August 2005; pp. 577–584. [Google Scholar]
- Hao, S.; Zhou, Y.; Guo, Y. A brief survey on semantic segmentation with deep learning. Neurocomputing 2020, 406, 302–321. [Google Scholar]
- Lai, Z.; Lu, E.; Xie, W. Mast: A memory-augmented self-supervised tracker. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 14–19 June 2020; pp. 6479–6488. [Google Scholar]
- Wang, K.; Peng, X.; Yang, J.; Lu, S.; Qiao, Y. Suppressing uncertainties for largescale facial expression recognition. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 14–19 June 2020; pp. 6897–6906. [Google Scholar]
- Zeng, N.; Zhang, H.; Song, B.; Liu, W.; Li, Y.; Dobaie, A.M. Facial expression recognition via learning deep sparse autoencoders. Neurocomputing 2018, 273, 643–649. [Google Scholar]
- Chakrabarti, A.; Shao, J.; Shakhnarovich, G. Depth from a single image by harmonizing overcomplete local network predictions. In Proceedings of the 30th International Conference on Neural Information Processing Systems (NIPS), Barcelona, Spain, 5–10 December 2016. [Google Scholar]
- Eigen, D.; Fergus, R. Predicting Depth, Surface Normals and Semantic Labels with a Common Multi-scale Convolutional Architecture. In Proceedings of the 2015 IEEE International Conference on Computer Vision (ICCV), Santiago, Chile, 7–13 December 2015. [Google Scholar]
- Eigen, D.; Puhrsch, C.; Fergus, R. Depth Map Prediction from a Single Image using a Multi-Scale Deep Network. In Proceedings of the 27th International Conference on Neural Information Processing Systems (NIPS), Montreal, QC, Canada, 8–13 December 2014. [Google Scholar]
- Fu, H.; Gong, M.; Wang, C.; Batmanghelich, K.; Tao, D. Deep ordinal regression network for monocular depth estimation. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–23 June 2018. [Google Scholar]
- Laina, I.; Rupprecht, C.; Belagiannis, V.; Tombari, F.; Navab, N. Deeper depth prediction with fully convolutional residual networks. In Proceedings of the 2016 Fourth International Conference on 3D Vision (3DV), Stanford, CA, USA, 25–28 October 2016. [Google Scholar]
- Lee, J.-H.; Heo, M.; Kim, K.-R.; Kim, C.-S. Single-Image Depth Estimation Based on Fourier Domain Analysis. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition CVPR, Salt Lake City, UT, USA, 18–23 June 2018. [Google Scholar]
- Roy, A.; Todorovic, S. Monocular Depth Estimation Using Neural Regression Forest. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016. [Google Scholar]
- Lafferty, J.; McCallum, A.; Pereira, F.C. Conditional random fields: Probabilistic models for segmenting and labeling sequence data. In Proceedings of the 18th International Conference on Machine Learning 2001 (ICML 2001), Williamstown, MA, USA, 28 June–1 July 2001; pp. 282–289. [Google Scholar]
- Heo, M.; Lee, J.; Kim, K.R.; Kim, C.S. Monocular depth estimation using whole strip masking and reliability-based refinement. In Proceedings of the 15th European Conference (ECCV), Munich, Germany, 8–14 September 2018. [Google Scholar]
- Li, B.; Shen, C.; Dai, Y.; Hengel, A.V.D.; He, M. Depth and surface normal estimation from monocular images using regression on deep features and hierarchical CRFs. In Proceedings of the 2015 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Boston, MA, USA, 7–12 June 2015. [Google Scholar]
- Liu, F.; Shen, C.; Lin, G. Deep convolutional neural fields for depth estimation from a single image. In Proceedings of the 15th IEEE International Conference on Computer Vision, Boston, MA, USA, 7–12 June 2015. [Google Scholar]
- Xu, D.; Ricci, E.; Ouyang, W.; Wang, X.; Sebe, N. Multi-scale continuous CRFs as sequential deep networks for monocular depth estimation. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017. [Google Scholar]
- Xu, D.; Wang, W.; Tang, H.; Liu, H.; Sebe, N.; Ricci, E. Structured attention guided convolutional neural fields for monocular depth estimation. Proceedings of IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018. [Google Scholar]
- Qi, X.; Liao, R.; Liu, Z.; Urtasun, R.; Jia, J. Geonet: Geometric neural network for joint depth and surface normal estimation. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–23 June 2018. [Google Scholar]
- Xu, D.; Ricci, E.; Ouyang, W.; Wang, X.; Sebe, N. PAD-Net: Multi-tasks guided prediction-and-distillation network for simultaneous depth estimation and scene parsing. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–23 June 2018. [Google Scholar]
- Yang, Q.; Wang, L.; Yang, R.; Stewenius, H.; Nister, D. Stereo matching with color- weighted correlation, hierarchical belief propagation, and occlusion handling. IEEE Trans. Pattern Anal. Mach. Intell. 2009, 31, 492–504. [Google Scholar] [CrossRef]
- Hirschmuller, H. Stereo processing by semiglobal matching and mutual information. IEEE Trans. Pattern Anal. Mach. Intell. 2008, 30, 328–341. [Google Scholar] [CrossRef]
- Pham, C.C.; Jeon, J.W. Domain transformation-based efficient cost aggregation for local stereo matching. IEEE Trans. Circuits Syst. Video Technol. 2013, 23, 1119–1130. [Google Scholar] [CrossRef]
- Yang, Q.; Wang, L.; Yang, R. Real-time global stereo matching using hierarchical belief propagation. In Proceedings of the British Machine Vision Conference, Edinburgh, UK, 4–7 September 2006; BMVA Press: Guildford, UK, 2006; pp. 101.1–101.10. [Google Scholar] [CrossRef]
- Ohta, Y.; Kanade, T. Stereo by Intra- and Inter-Scanline Search Using Dynamic Programming. IEEE Trans. Pattern Anal. Mach. Intell. 1985, 7, 139–154. [Google Scholar] [CrossRef]
- Boykov, Y.; Veksler, O.; Zabih, R. Fast approximate energy minimization via graph cuts. IEEE Trans. Pattern Anal. Mach. Intell. 2001, 23, 1222–1239. [Google Scholar] [CrossRef] [Green Version]
- Moring, I.; Heikkinen, T.; Myllyla, R.; Kilpela, A. Acquisition of three-dimensional image data by a scanning laser rangefinder. Opt. Eng. 1989, 28, 897–905. [Google Scholar] [CrossRef]
- Beheim, G.; Fritsch, K. Range finding using frequency-modulated laser diode. Appl. Opt. 1986, 25, 1439–1442. [Google Scholar] [CrossRef]
- Schmidt, M. Analysis, Modeling and Dynamic Optimization of 3d Time-of-Flight Imaging Systems. Ph.D. Thesis, Ruperto-Carola University, Heidelberg, Germany, 2011. Available online: http://www.ub.uni-heidelberg.de/archiv/12297/ (accessed on 16 May 2022).
- Gupta, M.; Nayar, S.K.; Hullin, M.B.; Martin, J. Phasor imaging: A generalization of correlation-based time-of-flight imaging. ACM Trans. Graph. (ToG) 2015, 34, 156. [Google Scholar] [CrossRef]
- Whyte, R.; Streeter, L.; Cree, M.J.; Dorrington, A.A. Resolving multiple prop- agation paths in time of flight range cameras using direct and global separation methods. Opt. Eng. 2015, 54, 113109. [Google Scholar] [CrossRef] [Green Version]
- Geng, J. Structured-light 3D surface imaging: A. tutorial. Adv. Opt. Photonics 2011, 3, 128–160. [Google Scholar] [CrossRef]
- Nguyen, H.; Wang, Y.; Wang, Z. Single-shot 3D shape reconstruction using structured light and deep convolutional neural networks. Sensors 2020, 20, 3718. [Google Scholar] [CrossRef]
- Lichiardopol, S. A survey on teleoperation. Tech. Univ. Eindh. DCT Rep. 2007, 20, 40–60. [Google Scholar]
- Su, B.; Yu, S.; Li, X.; Gong, Y.; Li, H.; Ren, Z.; Xia, Y.; Wang, H.; Zhang, Y.; Yao, W.; et al. Autonomous Robot for Removing Superficial Traumatic Blood. IEEE J. Transl. Eng. Heath Med. 2021, 9, 2600109. [Google Scholar] [CrossRef]
- Rahman, M.M.; Balakuntala, M.V.; Gonzalez, G.; Agarwal, M.; Kaur, U.; Venkatesh, V.L.; Sanchez-Tamayo, N.; Xue, Y.; Voyles, R.M.; Aggarwal, V.; et al. SARTRES: A semi-autonomous robot teleoperation environment for surgery. Comput. Methods Biomech. Biomed. Eng. Imaging Vis. 2021, 9, 376–383. [Google Scholar] [CrossRef]
- Bewley, A.; Ge, Z.; Ott, L.; Ramos, F.; Upcroft, B. Simple online and realtime tracking. In Proceedings of the 2016 IEEE International Conference on Image Processing (ICIP), Phoenix, AZ, USA, 25–28 September 2016; pp. 3464–3468. [Google Scholar]
- Cragg, L.; Huosheng, H. Application of mobile agents to robust teleoperation of internet robots in nuclear decommissioning. In Proceedings of the IEEE International Conference on Industrial Technology, Maribor, Slovenia, 10–12 December 2003; Volume 2, pp. 1214–1219. [Google Scholar] [CrossRef]
- Tokatli, O.; Das, P.; Nath, R.; Pangione, L.; Altobelli, A.; Burroughes, G.; Jonasson, E.T.; Turner, M.F.; Skilton, R. Robot-Assisted Glovebox Teleoperation for Nuclear Industry. Robotics 2021, 10, 85. [Google Scholar] [CrossRef]
- Bandala, M.; West, C.; Monk, S.; Montazeri, A.; Taylor, C.J. Vision-Based Assisted Tele-Operation of a Dual-Arm Hydraulically Actuated Robot for Pipe Cutting and Grasping in Nuclear Environments. Robotics 2019, 8, 42. [Google Scholar] [CrossRef] [Green Version]
- Qian, K.; Song, A.; Bao, J.; Zhang, H. Small teleoperated robot for nuclear radiation and chemical leak detection. Int. J. Adv. Robot. Syst. 2012, 9, 70. [Google Scholar] [CrossRef] [Green Version]
- Wang, J.; Li, J.; Wang, S.; Yu, T.; Rong, Z.; He, X.; You, Y.; Zou, Q.; Wan, W.; Wang, Y.; et al. Computer vision in the teleoperation of the Yutu-2 rover. Remote Sens. Spat. Inf. Sci. ISPRS Geospat. Week 2020, 3, 595–602. [Google Scholar] [CrossRef]
- Bird, J.; Petzold, L.; Lubin, P.; Deacon, J. Advances in deep space exploration via simulators & deep learning. New Astron. 2021, 84, 101517. [Google Scholar]
- Lii, N.Y.; Chen, Z.; Pleintinger, B.; Borst, C.H.; Hirzinger, G.; Schiele, A. Toward understanding the effects of visual-and force-feedback on robotic hand grasping performance for space teleoperation. In Proceedings of the 2010 IEEE/RSJ International Conference on Intelligent Robots and Systems, Taipei, Taiwan, 18–22 October 2010; pp. 3745–3752. [Google Scholar]
- Kunz, C.; Murphy, C.; Camilli, R.; Singh, H.; Bailey, J.; Eustice, R.; Jakuba, M.; Nakamurq, K.-I.; Roman, C.; Sato, T.; et al. Deep sea underwater robotic exploration in the ice-covered arctic ocean with AUVs. In Proceedings of the 2008 IEEE/RSJ International Conference on Intelligent Robots and Systems, Nice, France, 22–26 September 2008; pp. 3654–3660. [Google Scholar]
- Song, Y.; Sticklus, J.; Nakath, D.; Wenzlaff, E.; Koch, R.; Köser, K. Optimization of multi-led setups for underwater robotic vision systems. In Proceedings of the International Conference on Pattern Recognition, Federal Republic of (DEU), Kiel, Germany, 10–15 January 2021; Springer International Publishing: Cham, Switzerland, 2021; pp. 390–397. [Google Scholar]
- Lu, H.; Uemura, T.; Wang, D.; Zhu, J.; Huang, Z.; Kim, H. Deep-sea organisms tracking using dehazing and deep learning. Mobile Netw. Appl. 2020, 25, 1008–1015. [Google Scholar] [CrossRef]
- Ramon-Soria, P.; Arrue, B.C.; Ollero, A. Grasp Planning and Visual Servoing for an Outdoors Aerial Dual Manipulator. Engineering 2019, 6, 77–88. [Google Scholar] [CrossRef]
- Hussmann, S.; Liepert, T. Robot vision system based on a 3D-ToF camera. In Proceedings of the 2007 IEEE Instrumentation & Measurement Technology Conference IMTC 2007, Warsaw, Poland, 1–3 May 2007; pp. 1–5. [Google Scholar]
- Wan, S.; Goudos, S. Faster R-CNN for multi-class fruit detection using a robotic vision system. Comput. Netw. 2019, 168, 107036. [Google Scholar] [CrossRef]
- Tian, N.; Chen, J.; Zhang, R.; Huang, B.; Goldberg, K.; Sojoudi, S. A fog robotic system for dynamic visual servoing. In Proceedings of the IEEE International Conference on Robotics and Automation, Montreal, QC, Canada, 20–24 May 2019; pp. 1982–1988. [Google Scholar] [CrossRef] [Green Version]
- Ramalingam, B.; Manuel, V.H.; Elara, M.R.; Vengadesh, A.; Lakshmanan, A.K.; Ilyas, M.; James, T.J.Y. Visual inspection of the aircraft surface using a teleoperated reconfigurable climbing robot and enhanced deep learning technique. Int. J. Aerosp. Eng. 2019, 2019, 5137139. [Google Scholar] [CrossRef]
- Sano, T.; Horii, T.; Abe, K.; Nagai, T. Explainable Temperament Estimation of Toddlers by a Childcare Robot. In Proceedings of the 2020 29th IEEE International Conference on Robot and Human Interactive Communication (RO-MAN), Naples, Italy, 31 August–4 September 2020; pp. 159–164. [Google Scholar] [CrossRef]
- Lecrosnier, L.; Khemmar, R.; Ragot, N.; Decoux, B.; Rossi, R.; Kefi, N.; Ertaud, J.Y. Deep learning-based object detection, localisation and tracking for smart wheelchair healthcare mobility. Int. J. Environ. Res. Public Health 2021, 18, 91. [Google Scholar] [CrossRef]
- Breuer, T.; Giorgana Macedo, G.R.; Hartanto, R.; Hochgeschwender, N.; Holz, D.; Hegger, F.; Jin, Z.; Müller, C.; Paulus, J.; Reckhau, M.; et al. Johnny: An autonomous service robot for domestic environments. J. Intel. Robot. Syst. 2012, 66, 245–272. [Google Scholar] [CrossRef]
- Yu, Q.; Yuan, C.; Fu, Z.; Zhao, Y. An autonomous restaurant service robot with high positioning accuracy. Ind. Robot. Int. J. 2012, 39, 271–281. [Google Scholar] [CrossRef]
- Wang, X.; Shrivastava, A.; Gupta, A. A-Fast-RCNN: Hard Positive Generation via Adversary for Object Detection. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017. [Google Scholar]
- Höfer, T.; Shamsafar, F.; Benbarka, N.; Zell, A. Object detection and Autoencoder-based 6D pose estimation for highly cluttered Bin Picking. In Proceedings of the 2021 IEEE International Conference on Image Processing (ICIP), Anchorage, AK, USA, 19–22 September 2021; pp. 704–708. [Google Scholar]
- Liu, S.; Qi, L.; Qin, H.; Shi, J.; Jia, J. Path aggregation network for instance segmentation. arXiv 2018, arXiv:1803.01534. [Google Scholar]
- Ghiasi, G.; Lin, T.-Y.; Le, Q.V. NAS-FPN: Learning scalable feature pyramid architecture for object detection. In Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019; pp. 7029–7038. Available online: https://ieeexplore.ieee.org/document/8954436/ (accessed on 16 May 2022).
- Xie, C.; Mousavian, A.; Xiang, Y.; Fox, D. Rice: Refining instance masks in cluttered environments with graph neural networks. In Proceedings of the 5th Conference on Robot Learning, New York, NY, USA, 11 January 2022; pp. 1655–1665. [Google Scholar]










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Overall | Selected | Methodology | |
|---|---|---|---|
| Object detection technology | 6000–8000 | 45 | Representative mainstream algorithm with strong universality and high performance, which is suitable for beginners to gain a quick overview of the field |
| Distance measurement technology | More than 10,000 | 36 | |
| Applications | 22 | 22 | All studies that apply object detection and distance measurement to remote control from 2000 to 2021 |
| Name | Year | Author | Type | mAP (%) | Test Time on GPU (s/Image) |
|---|---|---|---|---|---|
| R-CNN [14] | 2014 | Ross Girshick, Jeff Donahue, Trevor Darrell, and Jitendra Malik | Two-Stage | 58.5 on VOC 2007 | 13 |
| SPP-Net [15] | 2014 | Kaiming He, Xiangyu Zhang, Shaoqing Ren, and Jian Sun | Two-Stage | 59.2 on VOC 2007 | 0.14 |
| Fast R-CNN [16] | 2015 | Ross Girshick | Two-Stage | 66.9 on VOC 2007 | 0.32 |
| Faster R-CNN [17] | 2015 | Shaoqing Ren, Kaiming He, Ross Girshick, and Jian Sun | Two-Stage | 73.2 on VOC 2007 | 0.2 |
| YOLOv1 [25] | 2016 | Joseph Redmon, Santosh Divvala, and Ali Farhadi et al. | One-Stage | 63.4 on VOC 2007 | 0.02 |
| SSD [23] | 2016 | Wei Liu, Cheng-Yang Fu 1, and Alexander C. Berg et al. | One-Stage | 74.3 on VOC 2007 | 0.017 |
| Mask R-CNN [20] | 2017 | Kaiming He, Georgia Gkioxari, Piotr Dollár, and Ross Girshick | Two-Stage | 37.1 on COCO | 0.2 |
| FPN [18] | 2017 | Tsung-Yi Lin, Bharath Hariharan, and Serge Belongie et al. | Two-Stage | 33.9 on COCO | 0.2 |
| YOLOv2 [26] | 2017 | Joseph Redmon, Ali Farhadi | One-Stage | 78.6 on VOC 2007 | 0.025 |
| RetinaNet [28] | 2017 | Tsung-Yi Lin, Ross Girshick, and Piotr Dollár et al. | One-Stage | 39.1 on COCO | 0.122 |
| Cascade R-CNN [19] | 2018 | Zhaowei Cai, Nuno Vasconcelos | Two-Stage | 42.8 on COCO | 0.115 |
| YOLOv3 [27] | 2018 | Joseph Redmon, Ali Farhadi | One-Stage | 57.9 on COCO | 0.051 |
| Libra R-CNN [21] | 2019 | Jiangmiao Pang, Huajun Feng, and Dahua Lin et al. | Two-Stage | 43.0 on COCO | 0.2 |
| Grid R-CNN [22] | 2019 | Xin Lu, Junjie Yan, and Quanquan Li et al. | Two-Stage | 43.2 on COCO | 0.2 |
| YOLOv4 [29] | 2020 | Alexey Bochkovskiy, Chien-Yao Wang et al. | Two-Stage | 43.5 on COCO | 0.015 |
| Consideration | Monocular Vision | Structured Light | Stereo Vision | Time-of-Flight (ToF) |
|---|---|---|---|---|
| Working Principle | Focus scenes on the camera’s image plane through the lens | Measure coded optical patterns’ variation through the feedback camera | RGB image feature point matching and indirect triangulation calculation | Measure the time delay or phase delay of the reflected light |
| Response Time (frames per second) | 15–400 | 30–60 | 15–50 | >100 |
| Depth Accuracy | / | 0.01–1 mm | <1 mm | 1–10 cm |
| Work Outdoor | No influence | The influence is large, especially in low power | No influence | There is influence, but little |
| Work in dark conditions | No | Yes | No | Yes |
| Range | / | Within 5 m | Within 20 m | Within 10 m |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhang, A.; Chu, M.; Chen, Z.; Zhou, F.; Gao, S. Object Detection and Distance Measurement in Teleoperation. Machines 2022, 10, 402. https://doi.org/10.3390/machines10050402
Zhang A, Chu M, Chen Z, Zhou F, Gao S. Object Detection and Distance Measurement in Teleoperation. Machines. 2022; 10(5):402. https://doi.org/10.3390/machines10050402
Chicago/Turabian StyleZhang, Ailing, Meng Chu, Zixin Chen, Fuqiang Zhou, and Shuo Gao. 2022. "Object Detection and Distance Measurement in Teleoperation" Machines 10, no. 5: 402. https://doi.org/10.3390/machines10050402