
RTSDM: A Real-Time Semantic Dense Mapping System for UAVs


Abstract
:1. Introduction
- (1)
- We proposed a real-time semantic mapping system which has faster pose tracking and the ability to build a dense map with object-specific semantic information over a large area.
- (2)
- The front end of the system was accelerated by using the direct method to reduce computational effort, a recent lightweight CNN was embedded into the system framework to perform the semantic segmentation task, and the resulting dense map was represented as a smaller, more flexible OctoMap, which occupies less memory than a point cloud.
- (3)
- The system was tested on a UAV, and its ability to build a semantically dense map in real-time on a small system with limited computational power was experimentally demonstrated.
2. Methods
2.1. Framework of the System
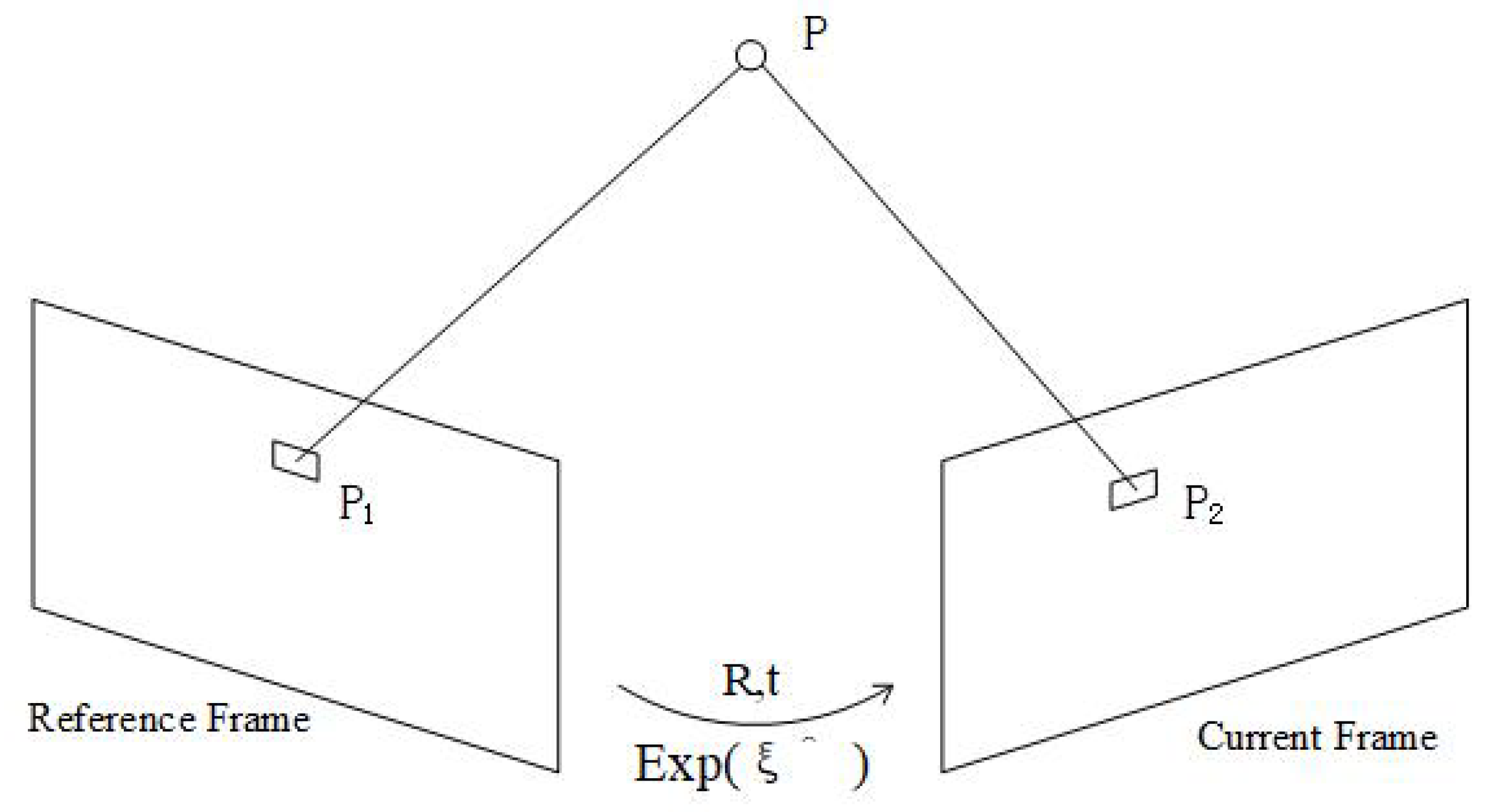
2.2. Pose Estimation by the Direct Method
2.3. Semantic Segmentation
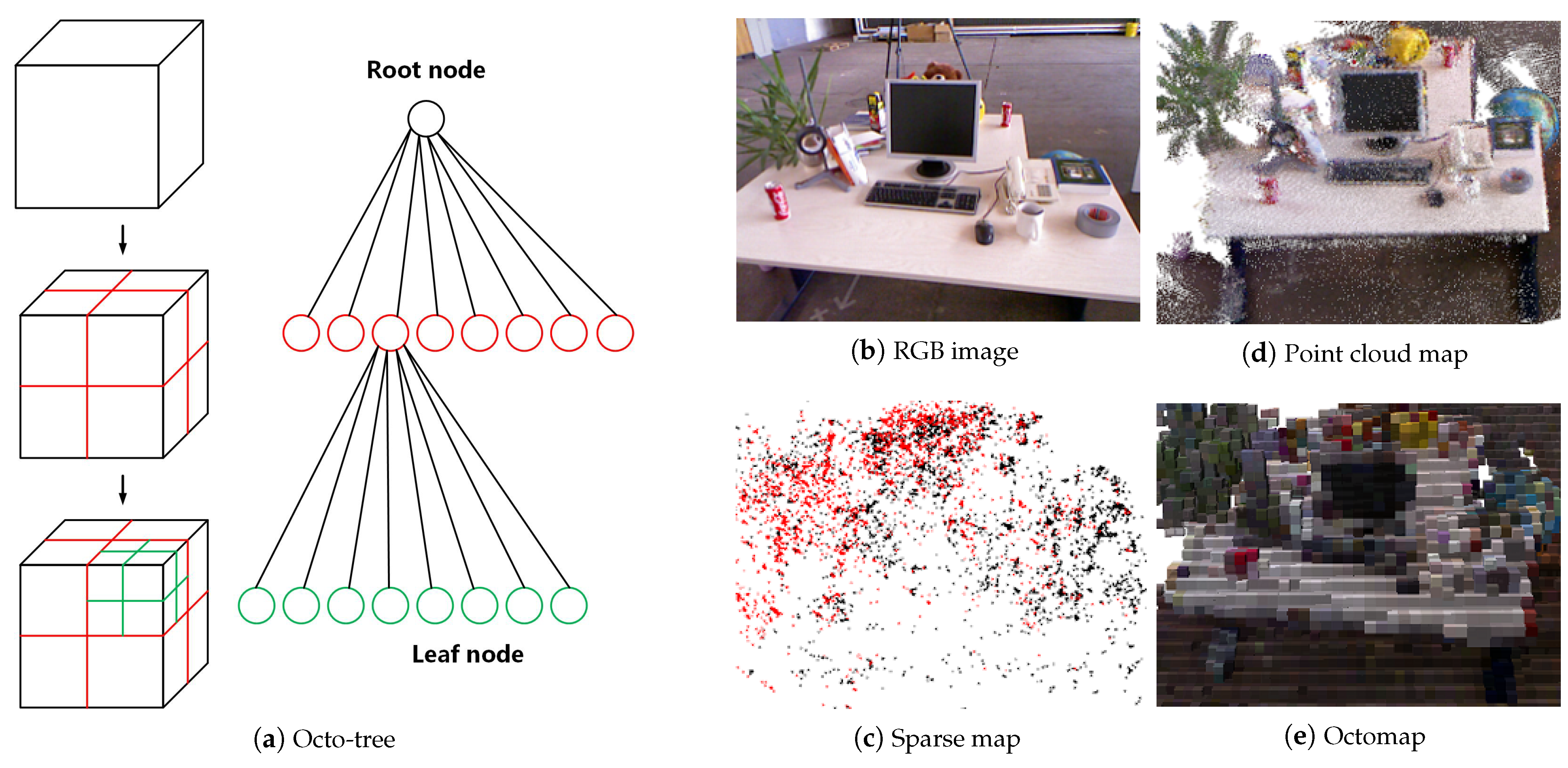
2.4. OctoMap Building
2.5. Experimental Setup
2.5.1. Visual SLAM Pose Accuracy Evaluation
2.5.2. Self-Built Dataset and Network Training
2.5.3. UAV Platform and Operational Performance
3. Experimental Results and Analysis
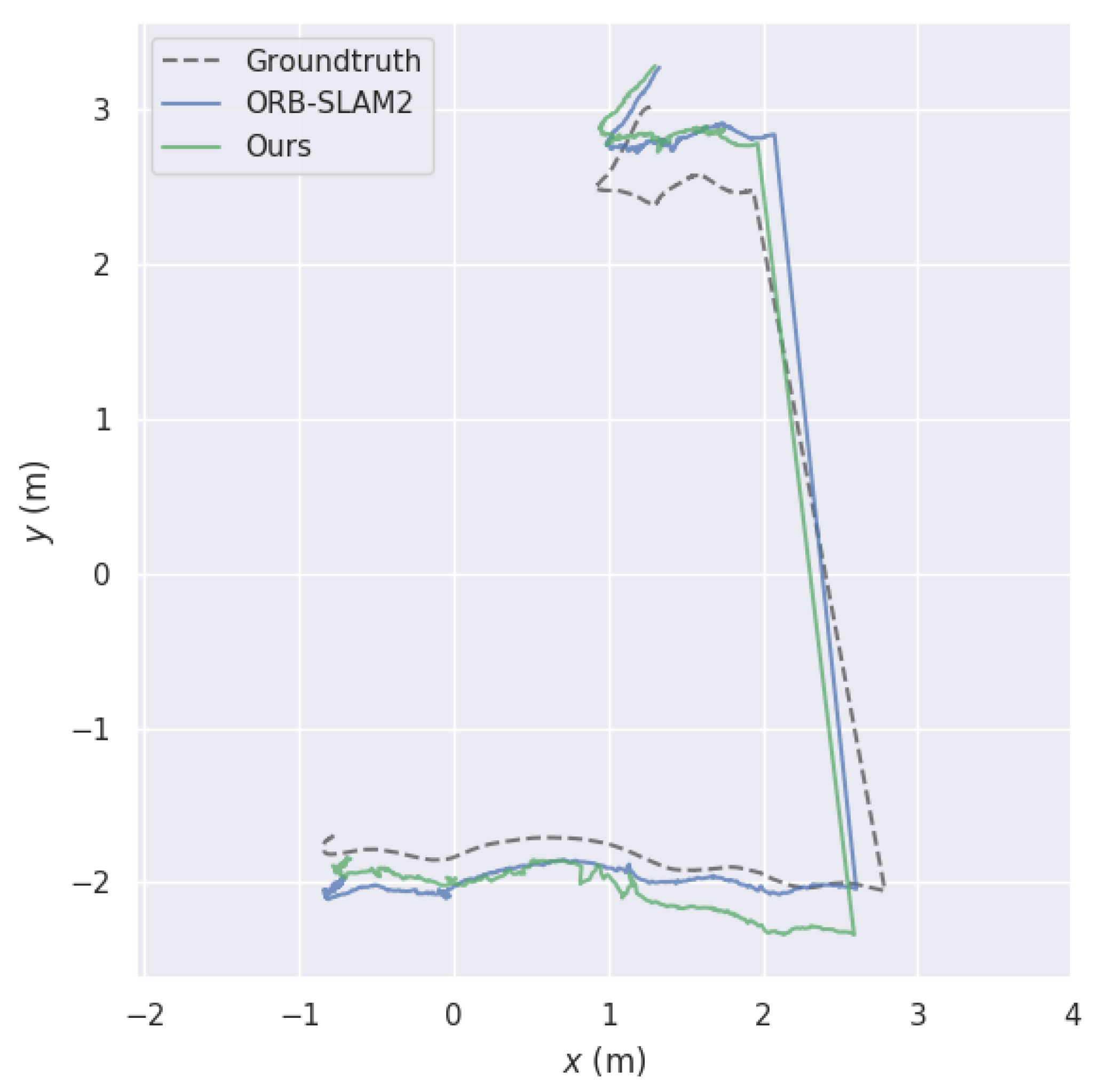
3.1. SLAM Pose Accuracy Evaluation
3.2. Semantic Segmentation Accuracy Evaluation
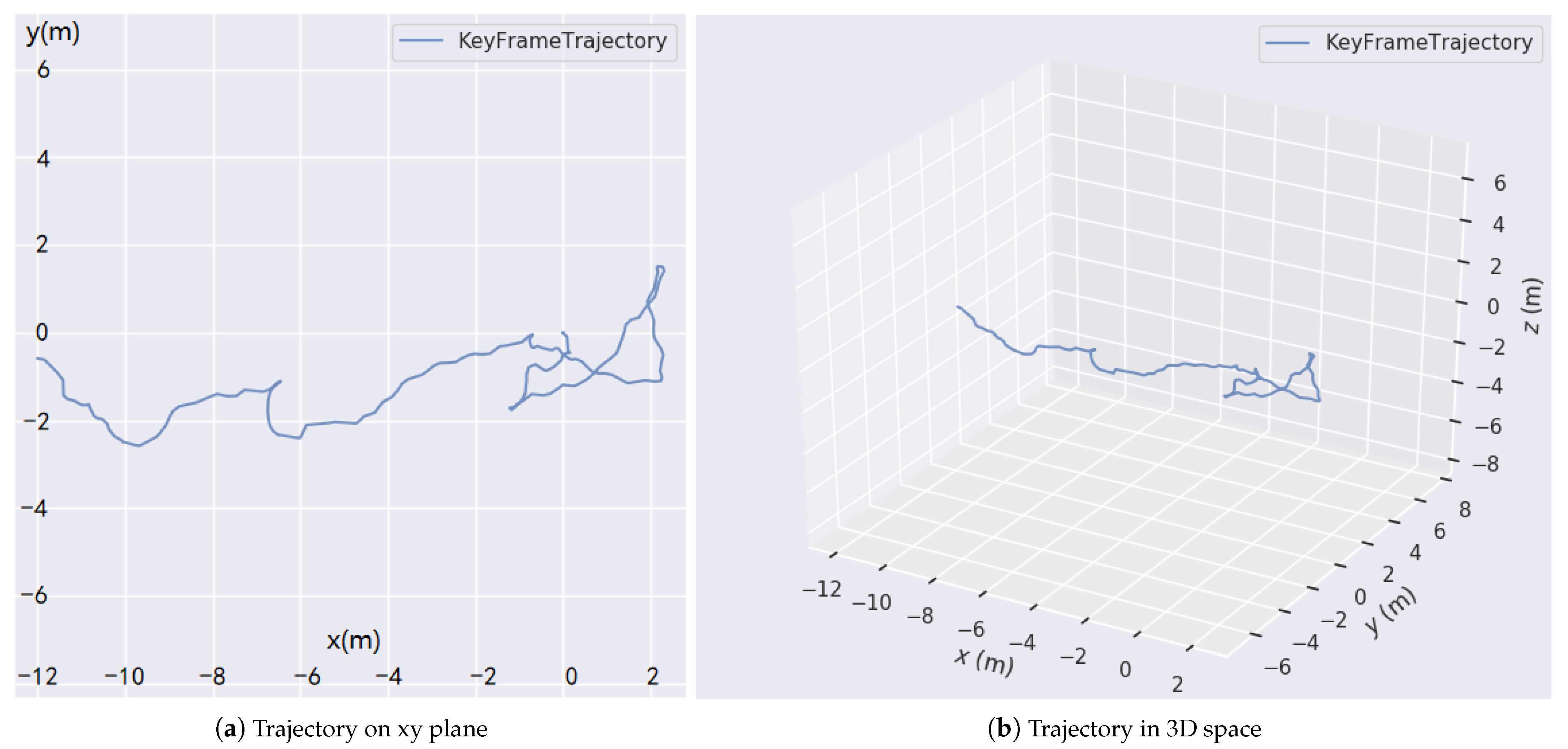
3.3. Operational Performance
4. Discussion
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Yavuz, D.; Akbıyık, H.; Bostancı, E. Intelligent drone navigation for search and rescue operations. In Proceedings of the 2016 24th Signal Processing and Communication Application Conference (SIU), Zonguldak, Turkey, 16–19 May 2016; IEEE: Piscataway, NJ, USA, 2016; pp. 565–568. [Google Scholar]
- Aslan, M.F.; Durdu, A.; Sabanci, K.; Ropelewska, E.; Gültekin, S.S. A comprehensive survey of the recent studies with uav for precision agriculture in open fields and greenhouses. Appl. Sci. 2022, 12, 1047. [Google Scholar] [CrossRef]
- Cadena, C.; Carlone, L.; Carrillo, H.; Latif, Y.; Scaramuzza, D.; Neira, J.; Reid, I.; Leonard, J.J. Past, present, and future of simultaneous localization and mapping: Toward the robust-perception age. IEEE Trans. Robot. 2016, 32, 1309–1332. [Google Scholar] [CrossRef] [Green Version]
- Ji, Z.; Singh, S. Loam: Lidar odometry and mapping in real-time. In Proceedings of the Robotics: Science and Systems Conference, Berkeley, CA, USA, 12–16 July 2014. [Google Scholar]
- Shan, T.; Englot, B. Lego-loam: Lightweight and ground-optimized lidar odometry and mapping on variable terrain. In Proceedings of the 2018 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Madrid, Spain, 1–5 October 2019. [Google Scholar]
- Lin, J.; Zhang, F. Loam livox: A fast, robust, high-precision lidar odometry and mapping package for lidars of small fov. In Proceedings of the International Conference on Robotics and Automation (ICRA), virtually, 31 May–31 August 2020; pp. 3126–3131. [Google Scholar]
- Di, K.; Wan, W.; Zhao, H.; Liu, Z.; Wang, R.; Zhang, F. Progress and applications of visual slam. J. Geod. Geoinf. Sci. 2019, 2, 38. [Google Scholar]
- Jia, Y.; Yan, X.; Xu, Y. A survey of simultaneous localization and mapping for robot. In Proceedings of the 2019 IEEE 4th Advanced Information Technology, Electronic and Automation Control Conference (IAEAC), Chengdu, China, 20–22 December 2019; IEEE: Piscataway, NJ, USA, 2019; Volume 1, pp. 857–861. [Google Scholar]
- Aslan, M.F.; Durdu, A.; Yusefi, A.; Sabanci, K.; Sungur, C. A tutorial: Mobile robotics, slam, bayesian filter, keyframe bundle adjustment and ros applications. In Robot Operating System (ROS); Springer: Cham, Switzerland, 2021; pp. 227–269. [Google Scholar]
- Klein, G.; Murray, D. Parallel tracking and mapping for small ar workspaces. In Proceedings of the IEEE & Acm International Symposium on Mixed & Augmented Reality, Nara, Japan, 13–16 November 2008. [Google Scholar]
- Mur-Artal, R.; Montiel, J.M.M.; Tardos, J.D. Orb-slam: A versatile and accurate monocular slam system. IEEE Trans. Robot. 2015, 31, 1147–1163. [Google Scholar] [CrossRef] [Green Version]
- Mur-Artal, R.; Tardós, J. Orb-slam2: An open-source slam system for monocular, stereo, and rgb-d cameras. IEEE Trans. Robot. 2017, 33, 1255–1262. [Google Scholar] [CrossRef] [Green Version]
- Campos, C.; Elvira, R.; Rodríguez, J.; Montiel, J.; Tardós, J. Orb-slam3: An accurate open-source library for visual, visual-inertial and multi-map slam. IEEE Trans. Robot. 2021, 37, 1874–1890. [Google Scholar] [CrossRef]
- Rublee, E.; Rabaud, V.; Konolige, K.; Bradski, G.R. Orb: An efficient alternative to sift or surf. In Proceedings of the IEEE International Conference on Computer Vision, ICCV 2011, Barcelona, Spain, 6–13 November 2011. [Google Scholar]
- Mur-Artal, R.; Tardós, J. Fast relocalisation and loop closing in keyframe-based slam. In Proceedings of the IEEE International Conference on Robotics & Automation, Hong Kong, China, 31 May–7 June 2014. [Google Scholar]
- Galvez-Lpez, D.; Tardos, J.D. Bags of binary words for fast place recognition in image sequences. IEEE Trans. Robot. 2012, 28, 1188–1197. [Google Scholar] [CrossRef]
- Forster, C.; Pizzoli, M.; Scaramuzza, D. Svo: Fast semi-direct monocular visual odometry. In Proceedings of the IEEE International Conference on Robotics & Automation, Hong Kong, China, 31 May–7 June 2014. [Google Scholar]
- Ruso, D.C.; Engel, J.; Cremers, D. Large-scale direct slam for omnidirectional cameras. In Proceedings of the IEEE/RSJ International Conference on Intelligent Robots & Systems, Hamburg, Germany, 28 September–2 October 2015. [Google Scholar]
- Gurturk, M.; Yusefi, A.; Aslan, M.F.; Soycan, M.; Durdu, A.; Masiero, A. The ytu dataset and recurrent neural network based visual-inertial odometry. Measurement 2021, 184, 109878. [Google Scholar] [CrossRef]
- Yusefi, A.; Durdu, A.; Aslan, M.F.; Sungur, C. Lstm and filter based comparison analysis for indoor global localization in uavs. IEEE Access 2021, 9, 10054–10069. [Google Scholar] [CrossRef]
- Newcombe, R.A.; Izadi, S.; Hilliges, O.; Molyneaux, D.; Fitzgibbon, A.W. Kinectfusion: Real-time dense surface mapping and tracking. In Proceedings of the IEEE International Symposium on Mixed & Augmented Reality, Basel, Switzerland, 26–29 October 2012. [Google Scholar]
- Newcombe, R.A.; Fox, D.; Seitz, S.M. Dynamicfusion: Reconstruction and tracking of non-rigid scenes in real-time. In Proceedings of the 2015 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Boston, MA, USA, 7–12 June 2015. [Google Scholar]
- Whelan, T.; Leutenegger, S.; Salas-Moreno, R.; Glocker, B.; Davison, A.J. Elasticfusion: Dense slam without a pose graph. In Proceedings of the Robotics: Science & Systems, Rome, Italy, 13–17 July 2015. [Google Scholar]
- Matsuki, H.; Scona, R.; Czarnowski, J.; Davison, A.J. Codemapping: Real-time dense mapping for sparse slam using compact scene representations. IEEE Robot. Autom. Lett. 2021, 6, 7105–7112. [Google Scholar] [CrossRef]
- Bloesch, M.; Czarnowski, J.; Clark, R.; Leutenegger, S.; Davison, A.J. Codeslam—Learning a compact, optimisable representation for dense visual slam. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 2560–2568. [Google Scholar]
- Loo, S.Y.; Mashohor, S.; Tang, S.H.; Zhang, H. Deeprelativefusion: Dense monocular slam using single-image relative depth prediction. In Proceedings of the 2021 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Prague, Czech Republic, 27 September–1 October 2021; IEEE: Piscataway, NJ, USA, 2020; pp. 6641–6648. [Google Scholar]
- Long, J.; Shelhamer, E.; Darrell, T. Fully convolutional networks for semantic segmentation. IEEE Trans. Pattern Anal. Mach. Intell. 2015, 39, 640–651. [Google Scholar]
- Badrinarayanan, V.; Kendall, A.; Cipolla, R. Segnet: A deep convolutional encoder-decoder architecture for image segmentation. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 2481–2495. [Google Scholar] [CrossRef] [PubMed]
- Chen, L.-C.; Papandreou, G.; Kokkinos, I.; Murphy, K.; Yuille, A.L. Semantic image segmentation with deep convolutional nets and fully connected crfs. arXiv 2014, arXiv:1412.7062. [Google Scholar]
- Chen, L.C.; Papandreou, G.; Kokkinos, I.; Murphy, K.; Yuille, A.L. Deeplab: Semantic image segmentation with deep convolutional nets, atrous convolution, and fully connected crfs. IEEE Trans. Pattern Anal. Mach. Intell. 2018, 40, 834–848. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Chen, L.C.; Papandreou, G.; Schroff, F.; Adam, H. Rethinking atrous convolution for semantic image segmentation. arXiv 2017, arXiv:1706.05587. [Google Scholar]
- Chen, L.-C.; Zhu, Y.; Papandreou, G.; Schroff, F.; Adam, H. Encoder-decoder with atrous separable convolution for semantic image segmentation. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018. [Google Scholar]
- Zhao, H.; Qi, X.; Shen, X.; Shi, J.; Jia, J. Icnet for real-time semantic segmentation on high-resolution images. arXiv 2017, arXiv:1704.08545. [Google Scholar]
- Yu, C.; Wang, J.; Peng, C.; Gao, C.; Yu, G.; Sang, N. Bisenet: Bilateral segmentation network for real-time semantic segmentation. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 325–341. [Google Scholar]
- Milz, S.; Arbeiter, G.; Witt, C.; Abdallah, B.; Yogamani, S. Visual slam for automated driving: Exploring the applications of deep learning. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR) Workshops, Salt Lake City, UT, USA, 18–23 June 2018. [Google Scholar]
- Mccormac, J.; Handa, A.; Davison, A.; Leutenegger, S. Semanticfusion: Dense 3d semantic mapping with convolutional neural networks. In Proceedings of the 2017 IEEE International Conference on Robotics and Automation (ICRA), Singapore, 29 May–3 June 2016. [Google Scholar]
- Runz, M.; Agapito, L. Co-fusion: Real-time segmentation, tracking and fusion of multiple objects. In Proceedings of the 2017 IEEE International Conference on Robotics and Automation (ICRA), Singapore, 29 May–3 June 2017. [Google Scholar]
- Runz, M.; Buffier, M.; Agapito, L. Maskfusion: Real-time recognition, tracking and reconstruction of multiple moving objects. In Proceedings of the 2018 IEEE International Symposium on Mixed and Augmented Reality (ISMAR), Munich, Germany, 16–20 October 2018. [Google Scholar]
- He, K.; Gkioxari, G.; Dollár, P.; Girshick, R. Mask r-cnn. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 2961–2969. [Google Scholar]
- Wu, S.-C.; Tateno, K.; Navab, N.; Tombari, F. Scfusion: Real-time incremental scene reconstruction with semantic completion. In Proceedings of the 2020 International Conference on 3D Vision (3DV), Fukuoka, Japan, 25–28 November 2020; pp. 801–810. [Google Scholar]
- Li, X.; Belaroussi, R. Semi-dense 3d semantic mapping from monocular slam. arXiv 2016, arXiv:1611.04144. [Google Scholar]
- Dang, Y.; Chen, P.; Liang, R.; Huang, C.; Tang, Y.; Yu, T.; Yang, X.; Cheng, K.T. Real-time semantic plane reconstruction on a monocular drone using sparse fusion. IEEE Trans. Veh. Technol. 2019, 68, 7383–7391. [Google Scholar] [CrossRef]
- Qin, T.; Li, P.; Shen, S. Vins-mono: A robust and versatile monocular visual-inertial state estimator. IEEE Trans. Robot. 2018, 34, 1004–1020. [Google Scholar] [CrossRef] [Green Version]
- Redmon, J.; Farhadi, A. Yolo9000: Better, faster, stronger. arXiv 2016, arXiv:1612.08242. [Google Scholar]
- Yu, C.; Liu, Z.; Liu, X.; Xie, F.; Yang, Y.; Wei, Q.; Fei, Q. Ds-slam: A semantic visual slam towards dynamic environments. In Proceedings of the 2018 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Madrid, Spain, 1–5 October 2018. [Google Scholar]
- Yu, C.; Gao, C.; Wang, J.; Yu, G.; Shen, C.; Sang, N. Bisenet v2: Bilateral network with guided aggregation for real-time semantic segmentation. Int. J. Comput. Vis. 2021, 129, 3051–3068. [Google Scholar] [CrossRef]
- Hornung, A.; Wurm, K.M.; Bennewitz, M.; Stachniss, C.; Burgard, W. Octomap: An efficient probabilistic 3d mapping framework based on octrees. Auton. Robot. 2013, 34, 189–206. [Google Scholar] [CrossRef] [Green Version]
- Nieto, J.; Guivant, J.; Nebot, E. Denseslam: Simultaneous localization and dense mapping. Int. J. Robot. Res. 2006, 25, 711–744. [Google Scholar] [CrossRef]
- Zhang, B.; Zhu, D. A stereo slam system with dense mapping. IEEE Access 2021, 9, 151888–151896. [Google Scholar] [CrossRef]
- Pizzoli, M.; Forster, C.; Scaramuzza, D. Remode: Probabilistic, monocular dense reconstruction in real time. In Proceedings of the 2014 IEEE International Conference on Robotics and Automation (ICRA), Hong Kong, China, 31 May–7 June 2014; IEEE: Piscataway, NJ, USA, 2014; pp. 2609–2616. [Google Scholar]
- Hermans, A.; Floros, G.; Leibe, B. Dense 3d semantic mapping of indoor scenes from rgb-d images. In Proceedings of the 2014 IEEE International Conference on Robotics and Automation (ICRA), Hong Kong, China, 31 May–7 June 2014; pp. 2631–2638. [Google Scholar]
- Henry, P.; Krainin, M.; Herbst, E.; Ren, X.; Fox, D. Rgb-d mapping: Using depth cameras for dense 3d modeling of indoor environments. In Experimental Robotics; Springer: Berlin/Heidelberg, Germany, 2014; pp. 477–491. [Google Scholar]
- Rosten, E. Machine learning for very high-speed corner detection. In Proceedings of the ECCV’06, Graz, Austria, 7–13 May 2006. [Google Scholar]
- Calonder, M.; Lepetit, V.; Strecha, C.; Fua, P. Brief: Binary robust independent elementary features. In Proceedings of the Computer Vision—ECCV 2010, 11th European Conference on Computer Vision, Proceedings Part IV, Heraklion, Greece, 5–11 September 2010. [Google Scholar]
- Gao, X.-S.; Hou, X.-R.; Tang, J.; Cheng, H.-F. Complete solution classification for the perspective-three-point problem. IEEE Trans. Pattern Anal. Mach. Intell. 2003, 25, 930–943. [Google Scholar]
- Lepetit, V.; Moreno-Noguer, F.; Fua, P. Epnp: An accurate o (n) solution to the pnp problem. Int. J. Comput. Vis. 2009, 81, 155. [Google Scholar] [CrossRef] [Green Version]
- Penate-Sanchez, A.; Andrade-Cetto, J.; Moreno-Noguer, F. Exhaustive linearization for robust camera pose and focal length estimation. IEEE Trans. Pattern Anal. Mach. Intell. 2013, 35, 2387–2400. [Google Scholar] [CrossRef] [Green Version]
- Irani, M.; Anandan, P. About direct methods. In International Workshop on Vision Algorithms; Springer: Berlin/Heidelberg, Germany, 1999; pp. 267–277. [Google Scholar]
- Varadarajan, V.S. Lie Groups, Lie Algebras, and Their Representations; Springer Science & Business Media: Berlin, Germany, 2013; Volume 102. [Google Scholar]
- Jia, Y.; Shelhamer, E.; Donahue, J.; Karayev, S.; Long, J.; Girshick, R.; Guadarrama, S.; Darrell, T. Caffe: Convolutional architecture for fast feature embedding. In Proceedings of the 22nd ACM international conference on Multimedia, Orlando, FL, USA, 3–7 November 2014; pp. 675–678. [Google Scholar]
- Sturm, J.; Engelhard, N.; Endres, F.; Burgard, W.; Cremers, D. A benchmark for the evaluation of rgb-d slam systems. In Proceedings of the 2012 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Vilamoura-Algarve, Portugal, 7–12 October 2012. [Google Scholar]
- Garcia-Garcia, A.; Orts-Escolano, S.; Oprea, S.; Villena-Martinez, V.; Garcia-Rodriguez, J. A review on deep learning techniques applied to semantic segmentation. arXiv 2017, arXiv:1704.06857. [Google Scholar]
- Brostow, G.J.; Fauqueur, J.; Cipolla, R. Semantic object classes in video: A high-definition ground truth database. Pattern Recognit. Lett. 2009, 30, 88–97. [Google Scholar] [CrossRef]












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Method | Large Scale | Dense Map | Computational Economic |
|---|---|---|---|
| Semantic Fusion [36] | √ | √ | |
| Co-Fusion [37] | √ | ||
| Mask Fusion [38] | √ | √ | |
| Xupeng’s [41] | √ | √ | |
| Yuanjie’s [42] | √ | √ | |
| DS-SLAM [45] | √ | √ | |
| Ours | √ | √ | √ |
| Method | ATE | |||
|---|---|---|---|---|
| ORB-SLAM2 | Ours | ORB-SLAM2_K | Ours_K | |
| RGBD_f3_longhouse | 0.0112 | 0.0151 | 0.0104 | 0.0145 |
| RGBD_f2_kidnap | 0.0804 | 0.0417 | 0.0554 | 0.0344 |
| RGBD_f2_no_loop | 0.2694 | 0.2577 | 0.3187 | 0.3320 |
| RGBD_f2_hemisphere | 0.1263 | 0.1393 | 0.1204 | 0.1403 |
| Segmentation Method | IoU_Box | IoU_Chair | IoU_Door | mIoU | mPA |
|---|---|---|---|---|---|
| SegNet | 72.7 | 89.7 | 81.8 | 80.0 | 89.3 |
| ICNet | 84.4 | 94.7 | 82.7 | 85.9 | 88.8 |
| DeepLabV3+ | 83.1 | 91.8 | 83.8 | 85.3 | 92.1 |
| BiSeNetV2 | 86.3 | 95.5 | 88.1 | 89.1 | 94.1 |
| Module | Visual SLAM | CNN | ||
|---|---|---|---|---|
| Thread | Tracking | Semantic Segmentation | ||
| Time(ms) | ORB-SLAM2 | 96.98 | SegNet | 173.57 |
| ICNet | 67.76 | |||
| Ours | 57.77 | DeepLabV3+ | 53.73 | |
| BiSeNetV2 | 34.71 | |||
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Li, Z.; Zhao, J.; Zhou, X.; Wei, S.; Li, P.; Shuang, F. RTSDM: A Real-Time Semantic Dense Mapping System for UAVs. Machines 2022, 10, 285. https://doi.org/10.3390/machines10040285
Li Z, Zhao J, Zhou X, Wei S, Li P, Shuang F. RTSDM: A Real-Time Semantic Dense Mapping System for UAVs. Machines. 2022; 10(4):285. https://doi.org/10.3390/machines10040285
Chicago/Turabian StyleLi, Zhiteng, Jiannan Zhao, Xiang Zhou, Shengxian Wei, Pei Li, and Feng Shuang. 2022. "RTSDM: A Real-Time Semantic Dense Mapping System for UAVs" Machines 10, no. 4: 285. https://doi.org/10.3390/machines10040285