1. Introduction
Mobile robots have various applications in various fields, and their autonomous navigation in ambient space is crucial [
1]. When robots have a priori information about the environment, they can plan a global path from the starting point to the endpoint and optimize some certain goals, an ability which has received much attention [
2]. However, it is difficult for robots to have a priori environmental information, especially about the dynamically changing factors, such as climatic conditions [
3], unknown obstacles [
4], and unfamiliar terrain [
5]. The robot needs to detect the surrounding environment in real-time and make multiple plans to obtain a feasible, safe path. Good results have been achieved in path planning research for solving unknown static environments [
6,
7,
8,
9], while the unknown dynamic factors [
3,
4,
5,
10] constrain the reliable and robust motion of the robot in general environments and present a significant challenge.
As the complexity of the environment and the difficulty of robot tasks increase, traditional path planning methods are challenging to achieve the desired results. Ant colony optimization (ACO) has strong robustness and adaptability for solving global path planning problems [
11]. In recent years, related scholars have proposed many improvement strategies and methods. Luo et al. [
12] introduced optimal and worst solutions in pheromone updating to expand the influence of high-quality ants and weaken the power of worst ants, which accelerates the algorithm’s convergence. Dai et al. [
13] proposed a smoothing ACO that optimizes the number of path turns and path length. You et al. [
14] designed a new heuristic operator to improve the diversity and convergence of the population search. To improve the solution accuracy of the algorithm, Xu et al. [
15] proposed a mutually collaborative two-layer ant colony algorithm, using the outer ant colony for global search and the inner ant colony for local search. Ao et al. [
16] took the motion characteristics of the USV into account for smoothing the paths, the continuous functions in orientation and curvature achieved, which reduced the fuel consumption and space-time overhead of USV to a certain extent.
In theory, such algorithms ensure an optimal global path obtained, but it may not be of high practical value due to the unpredictability of local information. Local path planning based on real-time sensor information is efficient and highly adaptable to local environments, such as the BUG algorithm [
9], DWA [
10], the fuzzy logic algorithm [
11], and the artificial potential field algorithm [
17]. Due to the lack of global information, it is challenging to guarantee accessibility and path optimality. Hybrid path planning methods have received extensive research and attention [
6], with global paths as guides and local planning executed online. The fusion algorithms A*–DWA [
7,
18,
19] and Dijkstra–DWA [
20,
21,
22] are the most widely studied hybrid algorithms. To achieve global path tracking and local unknown obstacle avoidance for the robot in complex and unfamiliar environments, Chi et al. [
7] use the improved A* algorithm to plan the robot’s navigation path and the DWA for local obstacle avoidance. Some scholars [
18] also considered obstacles with motion properties in the fusion algorithm. The mechanism of Dijkstra-DWA studied by Liu et al. [
22] is similar to Chi et al. [
7]. Differently, Liu et al. [
22] take the mobile objects interfering robot’s motion and verify the algorithm’s obstacle avoidance performance in a natural environment. Some scholars [
23,
24] have recently fused ACO with DWA for dynamic obstacle avoidance studies. Shao et al. [
23] exploit improved ACO to plan the robot’s path and use DWA for dynamic obstacle avoidance. Still, the robot uses a priority strategy for obstacle avoidance where obstacle passage is prioritized. If there are many mobile obstacles in the environment, the robot’s safety cannot be guaranteed. Jin et al. [
24] consider a variety of motion states obstacles to interfere with the robot’s motion without assuming their volume and size. Although a good obstacle avoidance effect has been achieved, it is impractical. In addition, the hybrid algorithm for Rapidly-exploring Random Trees (RRT)–DWA has been investigated by several scholars [
25].
With the rise of artificial intelligence, this type of path planning has received much attention. Chen et al. [
26] proposed a bidirectional neural network to solve the path planning problem in an unknown environment. Wu et al. [
27] transformed the path planning task into an environment classification task, using Convolutional Neural Network (CNN) to perform path planning. Reinforcement learning is a class of algorithms applied to unknown environments. As one of the three major branches of machine learning, reinforcement learning [
28] does not need to provide data, unlike supervised and unsupervised learning. All the learning material will be obtained from the environment. By continuously exploring the environment and learning the model based on the other feedback generated by various actions, the intelligence will eventually complete the task in the specified environment with the optimal strategy. Since V. Mnih et al. [
29] proposed Deep Q-Network (DQN), deep reinforcement learning has continued to make breakthroughs, and some researchers now try to solve path planning problems by deep reinforcement learning. In the grid environment, Piotr Mirowski et al. [
30] exploit multimodal perceptual information as input and make decisions by reinforcement learning to accomplish navigation tasks in grid space. Panov et al. [
31] utilize the Neural Q-Learning algorithm to achieve the path planning task. Lei et al. [
32] combined CNN with DDQN to investigate path planning in dynamic environments. Lv et al. [
33] proposed an improved DQN-based learning strategy that builds an experience-valued evaluation network in the beginning phase and uses a parallel exploration structure when the path roaming phenomenon occurs. The study also considered exploring other points than the roaming points to improve the experience pool’s breadth further.
Robots in unknown and complex dynamic environments require global navigation and dynamic obstacle avoidance capabilities. This paper proposes an effective ACO hybrid DWA dynamic path planning algorithm, and the planning ability and dynamic obstacle avoidance ability of the hybrid algorithm in complex environments have been further enhanced by the following improvements:
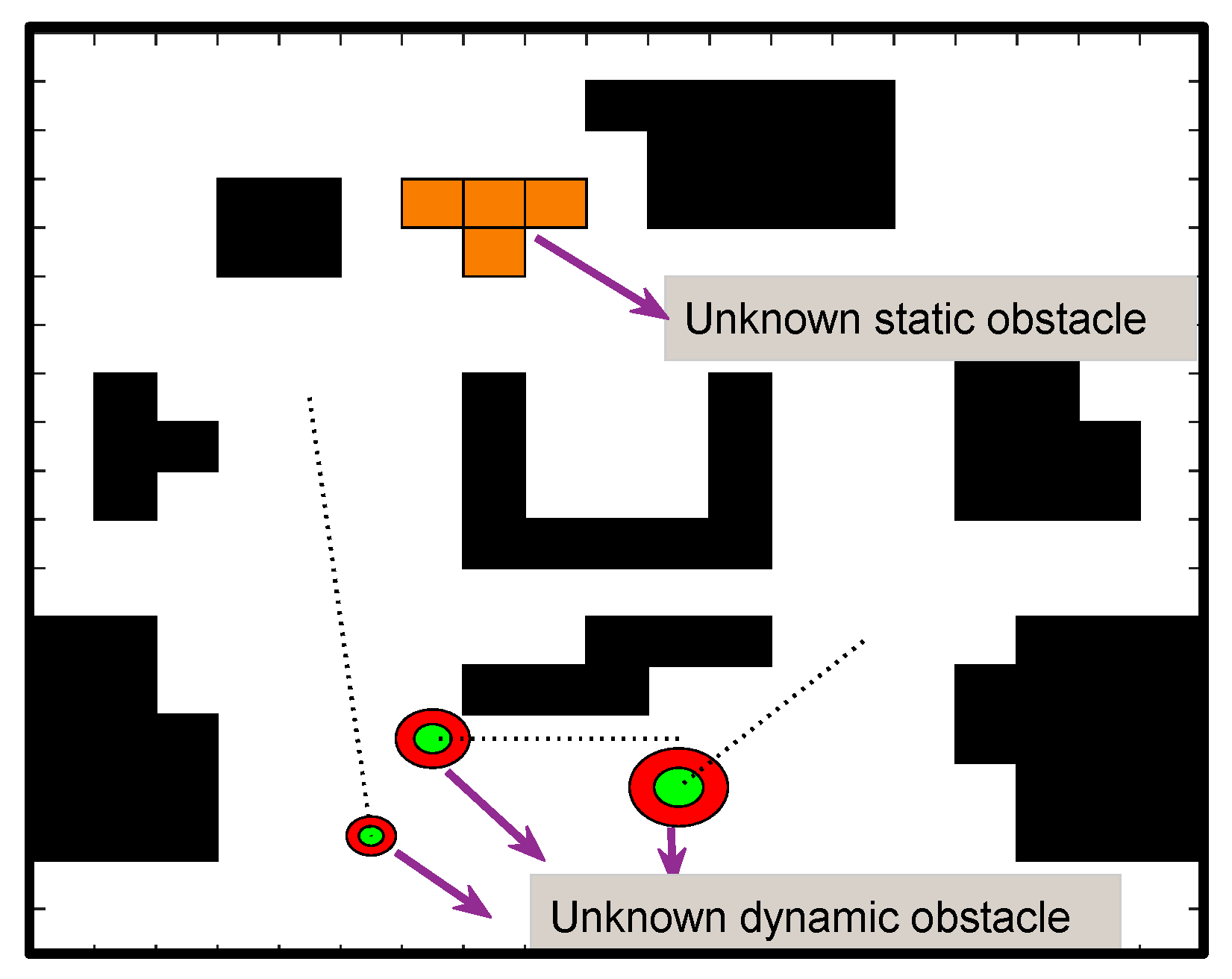
A new dynamic environment construction method is proposed to address the lack of practical dynamic factors in current path planning research.
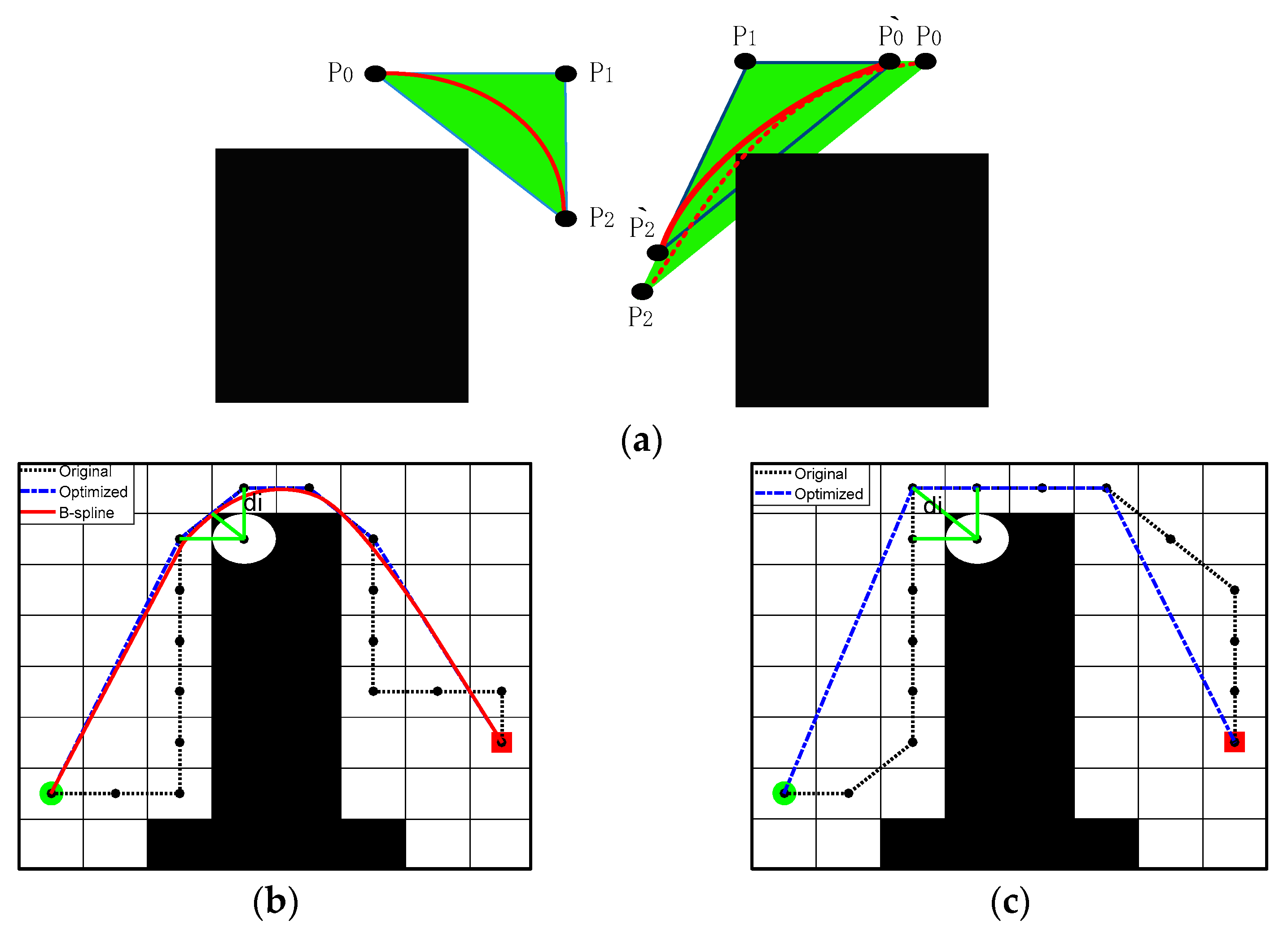
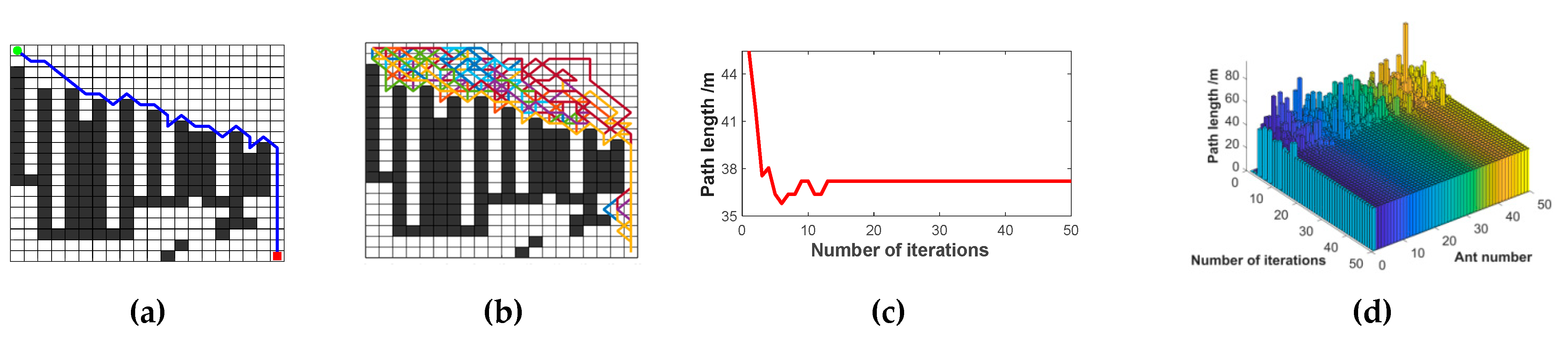
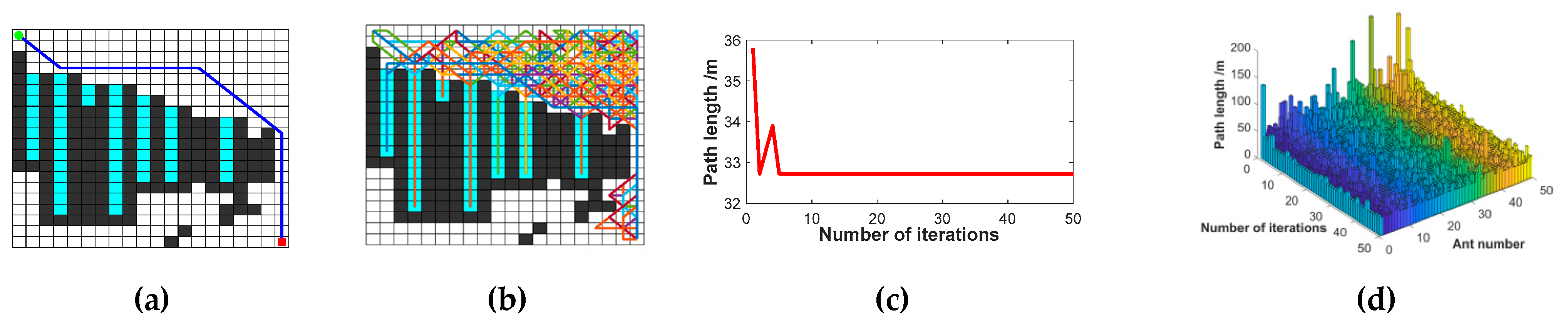
The robot’s navigation trajectory is planned by the improved ACO, which improves the robot’s adaptability to complex environments in the grid map. We propose a non-uniform initial pheromone method to avoid the blindness of the ants’ initial search and improved heuristic functions using corner suppression factors to enhance the smoothing ability of the ants’ paths of exploration. To improve the algorithm’s convergence, we updated the pheromone hierarchically according to the quality of the ants. In addition, the deadlock problem is solved by the retraction mechanism we designed. Considering the actual path requirements of the robot, we smoothed and optimized the paths.
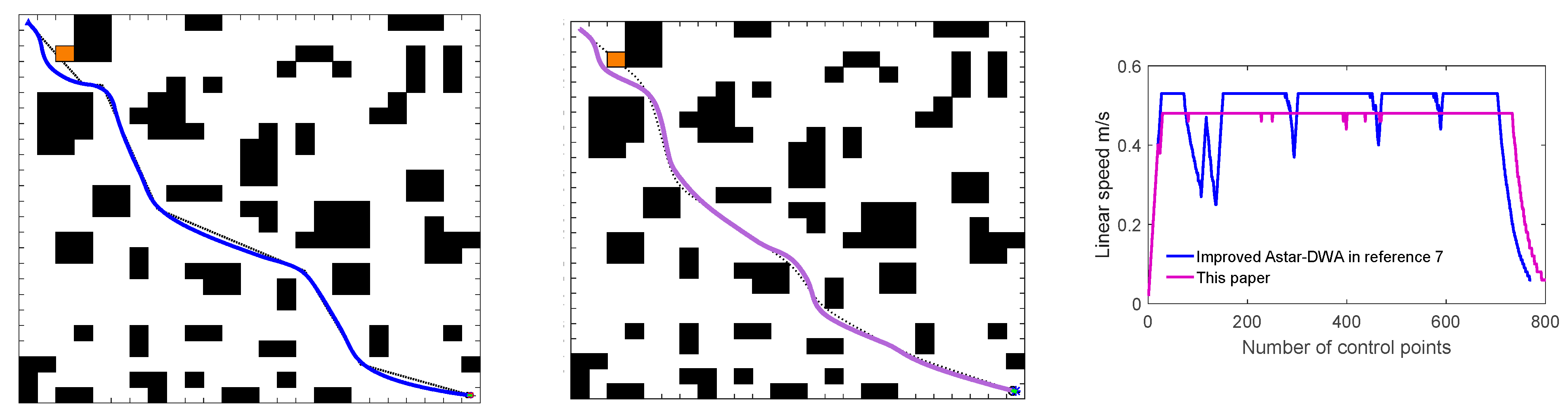
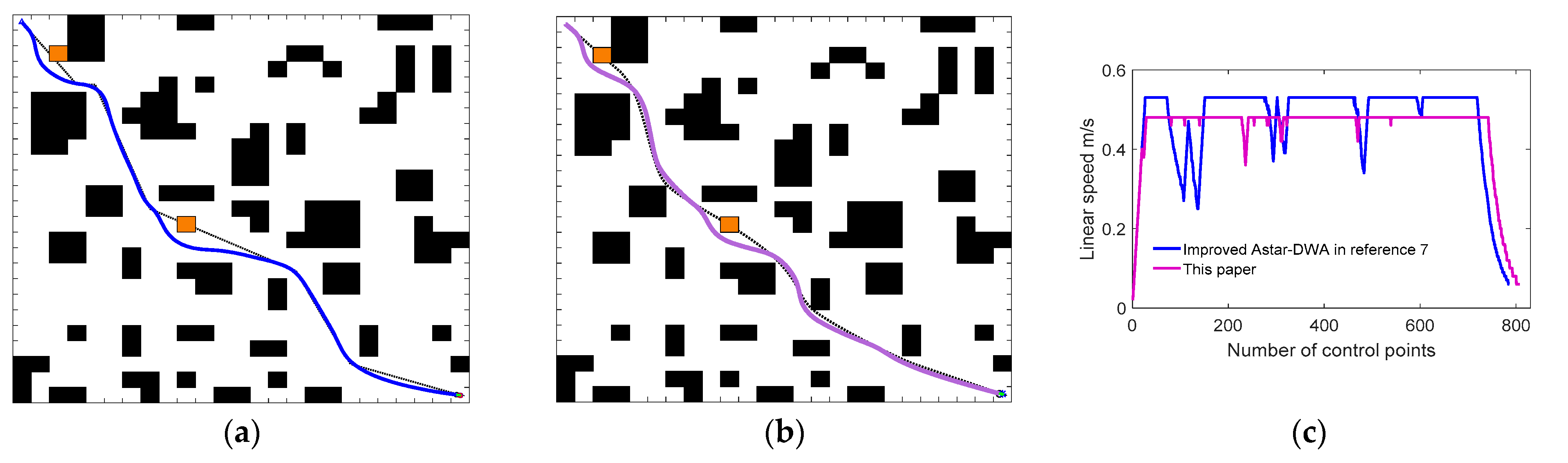
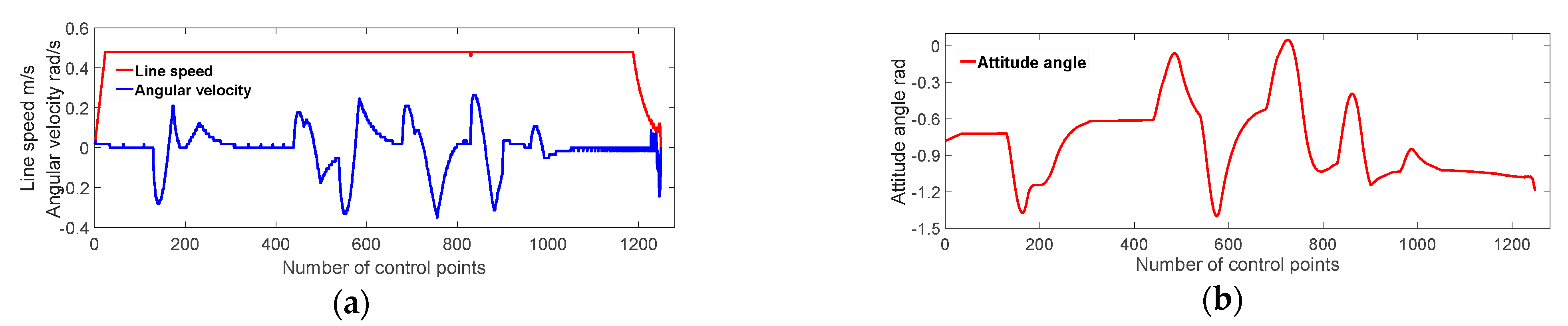
Constructing the robot model based on improved DWA, our primary focus is to utilize the global path planned by IACO as the robot’s navigation information, then analyze and improve the robot’s sampling window and evaluation function to enhance the path tracking capability, dynamic obstacle avoidance capability, and motion stability. Finally, we have verified the effectiveness of the fusion algorithm through extensive simulation experiments.
5. Hybrid Path Planning
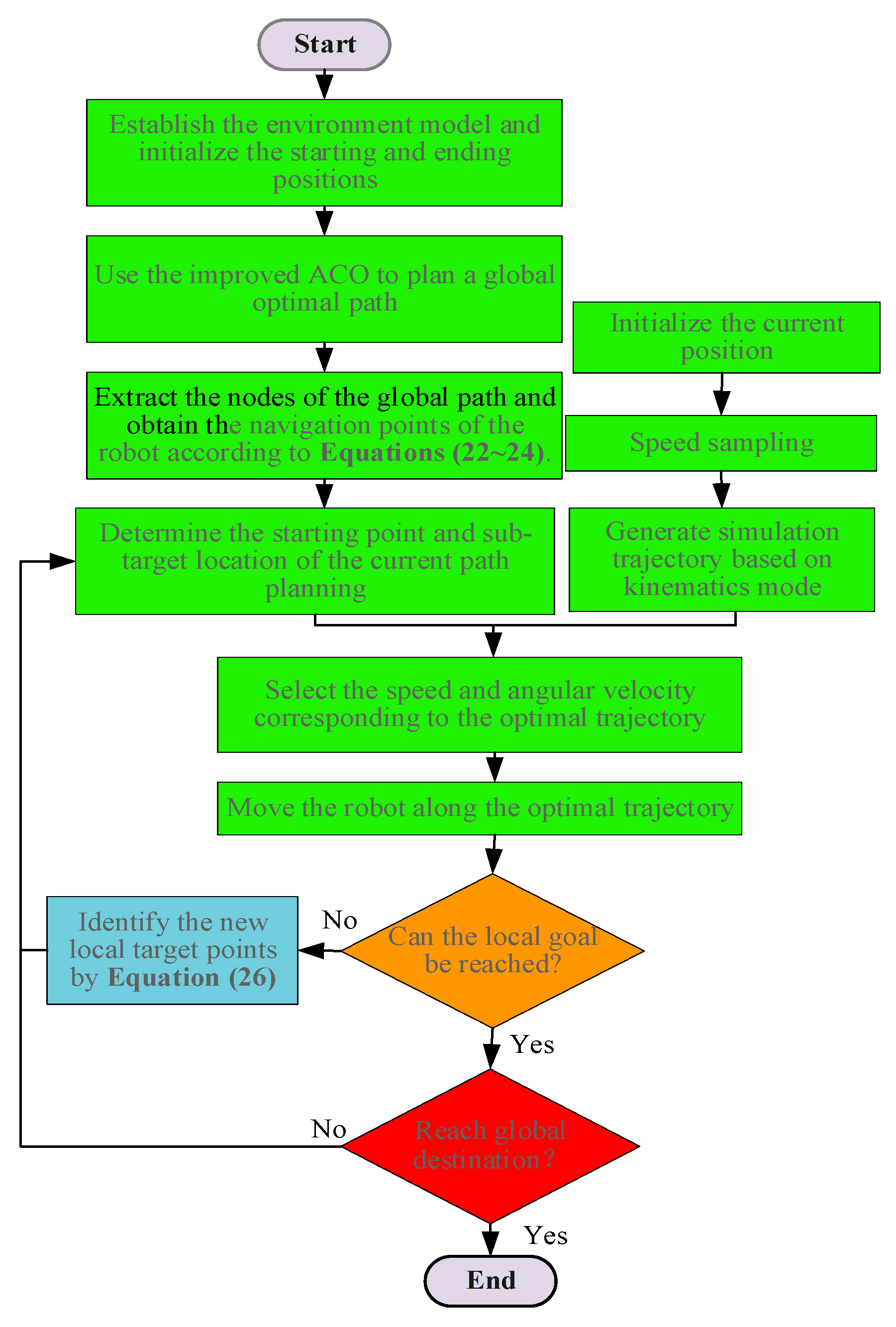
In this paper, ACO and DWA are fused to obtain the robot’s global navigation path using IACO and construct a robot’s kinematic model for dynamic path planning using IDWA. The basic process of the hybrid path planning method is as follows:
Step 1. Build a grid map for the mobile robot.
Step 2. Plan a global path based on the IACO with smoothing optimization.
Step 3. Extract the nodes of the global path and obtain the navigation points of the robot according to Equations (22)–(24). The distance and azimuth angle from the current position to the local target will be calculated in the IDWA.
Step 4. When the robot moves towards the position of the local target point, once a new obstacle appears in the environment and is within the detection range of the robot, the information (position, volume size, and speed of movement) will be sensed by the robot and the corresponding strategy will be executed to avoid the obstacle.
Step 5. When the robot approaches the local target point, or a new obstacle appears on the original path that prevents the robot from approaching the local target point, a new target point will be reacquired according to Equation (26).
Step 6. The path planning and movement process will stop when the mobile robot reaches the global target point or when the global target point is unreachable due to obstacles occupying.
A flow chart of the hybrid path planning algorithm is shown as
Figure 10:
7. Conclusions and Future Work
This paper investigates a new hybrid algorithm for dynamic path planning in view of the ant colony algorithm’s excellent robustness and search capability and the dynamic window approach’s local obstacle avoidance advantages. To further refine the dynamic factors of the robot in the natural environment, a new dynamic environment construction method is proposed. The robot obtains a global reference trajectory based on an improved ant colony algorithm in unknown territory and uses mounted sensors to gain information about the strange environment for dynamic obstacle avoidance.
We are taking into account the poor adaptability of traditional ACO to complex environments and the difference between the path and the actual requirements of the robot. We propose a non-uniform initial pheromone method to avoid the blindness of the ant’s initial search. Then, the smoothing heuristic function with corner suppression and the improved retraction strategy is used to optimize the ant’s ability to explore paths in complex environments. To address the inefficiencies of the ACO, pheromones are updated in layers. Moreover, we present a path smoothing method to satisfy the motion requirements of the robot better in a grid environment.
Considering the poor navigation capability and poor dynamic obstacle avoidance capability of the traditional DWA, we construct the robot model with kinematic constraints using IDWA and utilize the global path planned by IACO as the robot’s navigation information. Then we improve the sampling window and evaluation function, which eventually enhances the robot’s path tracking capability, dynamic obstacle avoidance capability, and motion stability. The experiment shows that the proposed method enables the robot to efficiently and safely navigate in global static environments and better dynamic obstacle avoidance in complex dynamic environments.
In this paper, the robot is kinematically constrained, but this is neglected when planning global paths, and we will consider it in path planning and path smoothing processes in the subsequent studies. Moreover, the dynamic environment considered in this paper is limited to a two-dimensional environment, and it is hoped that our proposed approach will be of some use to subsequent researchers in studying three-dimensional dynamic environments.































{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}