In this section, we focus on how wavelets can be used for the purpose of monitoring and what the important issues that arise are. We start with a brief description of wavelets and the wavelet decomposition, focusing on the parts that are relevant for monitoring. There is a large literature on wavelets and their uses, and this is beyond the scope of this work.
Wavelets are a method for representing a time-series in terms of coefficients that are associated with a particular time and a particular frequency [
9]. The wavelet decomposition is widely used in the signal processing world for denoising signals and recovering underlying structures. Unlike other popular types of decompositions, such as the Fourier transform, the wavelet decomposition yields localized components. A Fourier transform decomposes a series into a set of sine and cosine functions, where the different frequencies are computed globally from the entire duration of the signal, thereby maintaining specificity only in frequency. In contrast, the wavelet decomposition offers a localized frequency analysis. It provides information not only on what frequency components are present in a signal, but also when or where they are occurring [
10]. The wavelet filter is long in time when capturing low-frequency events and short in time when capturing high-frequency events. This means that it can expose patterns of different magnitude and duration in a series, while maintaining their exact timing.
Wavelet decompositions have proven especially useful in applications where the series of interest is not stationary. This includes long-range-dependent processes, which include many naturally occurring phenomena, such as river flow, atmospheric patterns, telecommunications, astronomy and financial markets ([
11], Chap 5). Also, the wavelet decomposition highlights inhomogeneity in the variance of a series. Furthermore, data from most practical processes are inherently multiscale, due to events occurring with different localizations in time, space and frequency [
4]. With today’s technology, many industrial processes are measured at very high frequencies, yielding series that are highly correlated and sometimes non-stationary. Together with the advances in mechanized inspection, this allows much closer and cheaper inspection of processes, if the right statistical monitoring tools are applied. The appeal of Shewhart charts has been its simplicity, both in understanding and implementing them, and their power to detect abnormal behavior when the underlying assumptions hold. On the other hand, the growing complexity of the measured processes has lead to the introduction of various methods that can account for features, such as autocorrelated measurements, seasonality and non-normality. The major approach has been to model the series by accounting for these features and monitoring the model residuals using ordinary control charts. One example is fitting Autoregressive Integrated Moving Average (ARIMA) models to account for autocorrelation [
12]. A more popular approach is using regression-type models that account for seasonality, e.g., the Serfling model [
13] that is widely used by the Centers for Disease Control and Prevention (CDC). A detailed modeling approach is practical when the number of series to be monitored is small and when the model is expected to be stable over time. However, in many cases, there are multiple series, each of differing nature, that might change their behavior over time. In such cases, fitting a customized model to each process and updating the model often is not practical. This is the case of biosurveillance.
An additional appeal of wavelet methods is that the nature of the abnormality need not be specified
a priori. Unlike popular control charts, such as Shewhart, Cumulative Sum (CuSum), Moving Average (MA) and EWMA charts that operate on a single scale and are most efficient at detecting a certain type of abnormality ([
17]), wavelets operate on multiple scales simultaneously. In fact, the Multiscale Statistical Process Control (MSSPC) wavelet-based method ([
4]) subsumes the Shewhart, MA, EWMA and CuSum charts. Scales are inversely proportional to frequencies, and thus, cruder scales are associated with higher frequencies.
2.1. The Discrete Wavelet Transform (DWT)
The discrete wavelet transform (DWT) is an orthonormal transform of a real-valued time-series
X of length
n. Using the notation of Percival and Walden [
9], we write
, where
is an
vector of DWT coefficients and
W is an
orthonormal matrix defining the DWT. The time-series can be written as:
where
is the detail associated with changes in
at scale,
j, and
is equal to the sample mean. This representation is called the multi-resolution analysis (MRA) of
.
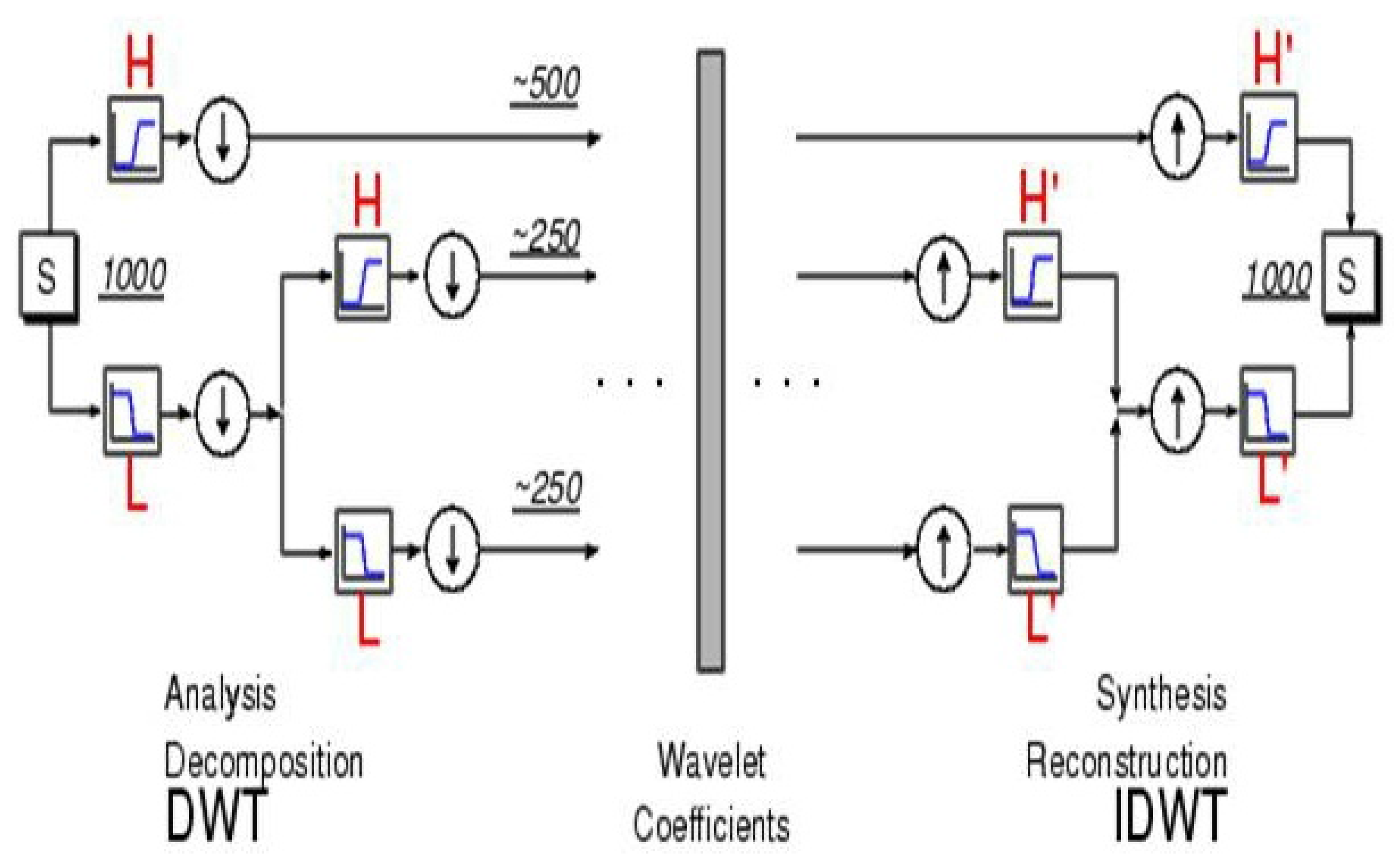
The process of performing DWT to decompose a time-series and the opposite reconstruction step are illustrated in
Figure 2. The first scale is obtained by filtering the original time-series through a high-pass (wavelet) filter, which yields the first-scale detail coefficient vector,
, and through a low-pass (scaling) filter, which gives the first-scale approximation coefficient vector,
. In the next stage, the same operation is performed on
to obtain
and
, and so on. This process can continue to produce as many as
scales. In practice, however, a smaller number of scales is used. The standard DWT includes a step of down-sampling after each filtering, such that the filtered output is subsampled by two. This means that the number of coefficients reduces from scale to scale by a factor of two. In fact, the vector of wavelet coefficients,
, can be organized into
vectors:
, where
and
correspond to the detail and approximation coefficients at scale,
j, respectively. To reconstruct the series from its coefficients, the opposite operations are performed: starting from
and
, an upsampling step is performed (where zeros are introduced between each two coefficients) and “reconstruction filters” (or “mirror filters”) are applied in order to obtain
and
. This is repeated, until the original series is finally reconstructed from
and
.
Figure 2.
The process of discrete wavelet transform (DWT) (from Matlab’s Wavelet Toolbox Tutorial). The time-series (S) is decomposed into three scales.
Figure 2.
The process of discrete wavelet transform (DWT) (from Matlab’s Wavelet Toolbox Tutorial). The time-series (S) is decomposed into three scales.
Notice that there is a distinction between the wavelet approximation and detail coefficients and the wavelet reconstructed coefficients, which are often called approximations and details. We denote the coefficients by and (corresponding to approximation and detail coefficients, respectively) and their reconstruction by A and D. This distinction is important, because some methods operate directly on the coefficients, whereas other methods use the reconstructed vectors. The reconstructed approximation, , is obtained from by applying the same operation as the series reconstruction, with the exception that it is not combined with . An analogous process transforms to .
To illustrate the complete process, consider the Haar, which is the simplest wavelet. In general, the Haar uses two operations: averaging and taking differences. The low-pass filter takes averages (
), and the high-pass filter takes differences (
). This process is illustrated in
Figure 3. Starting with a time-series of length,
n, we obtain the first level approximation coefficients,
, by taking averages of every pair of adjacent values in the time-series (and multiplying by a factor of
). The first-level detail coefficients,
, are proportional to the differences between these pairs of adjacent values. Downsampling means that we drop every other coefficient, and therefore,
and
are each of length
. At the next level,
coefficients are obtained by averaging adjacent pairs of
coefficients. This is equivalent to averaging groups of four values in the original time-series.
coefficients are obtained from
by taking the difference between adjacent pairs of
coefficients. This is equivalent to taking the difference between pairwise-averages of the original series. Once again, a downsampling step removes every other coefficient, and therefore,
and
are each of length,
. These operations are repeated to obtain the next scales. In summary, the detail coefficient at scale
j, at time
t reflects the difference between the averages of
values before and after time
t (the time-series is considered to be at scale
).
Figure 3.
Decomposition (left) and reconstruction (right) of a signal to/from its coefficients. Decomposition is done by convolving the signal (S) of length with a high-pass filter (H) and low-pass filter (L) and then downsampling. The next scale is similarly obtained by convolving the first level approximation with these filters, etc. Reconstruction is achieved by upsampling and then convolving the upsampled vectors with “mirror filters”. (from Matlab’s Wavelet Toolbox Tutorial).
Figure 3.
Decomposition (left) and reconstruction (right) of a signal to/from its coefficients. Decomposition is done by convolving the signal (S) of length with a high-pass filter (H) and low-pass filter (L) and then downsampling. The next scale is similarly obtained by convolving the first level approximation with these filters, etc. Reconstruction is achieved by upsampling and then convolving the upsampled vectors with “mirror filters”. (from Matlab’s Wavelet Toolbox Tutorial).
The Haar reconstruction filters are given by and . These are used for reconstructing the original series and the approximation and details from the coefficients.
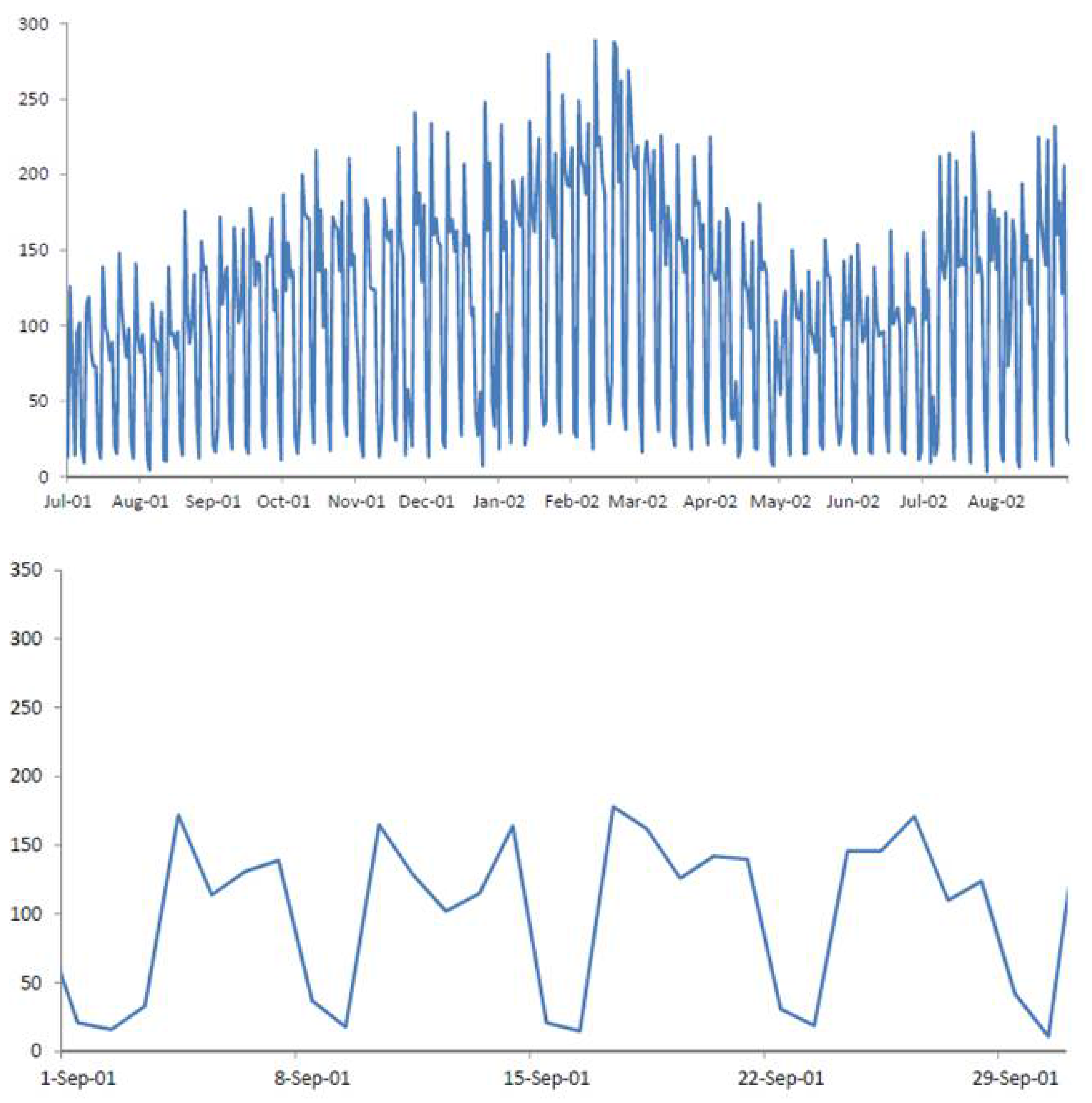
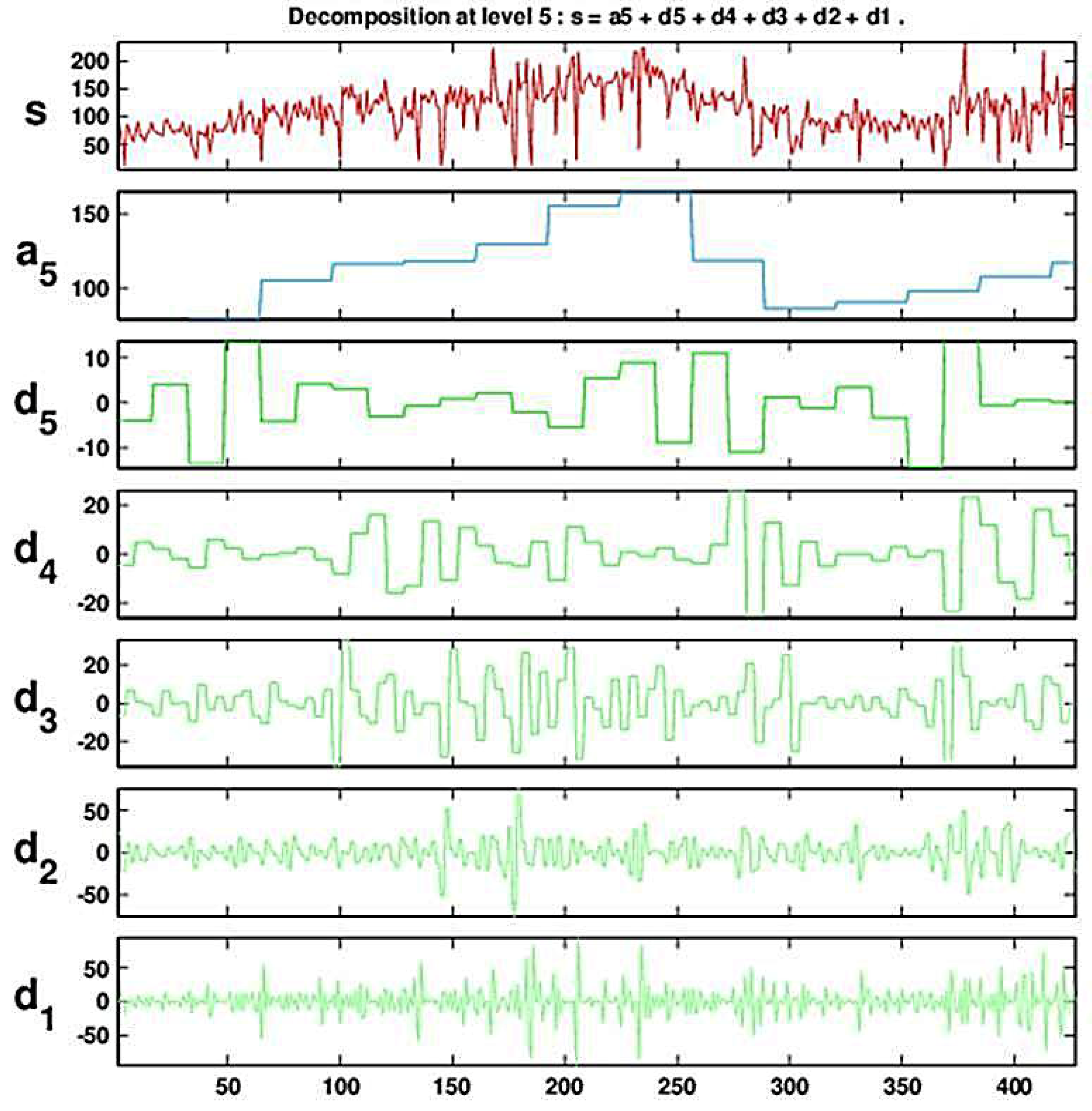
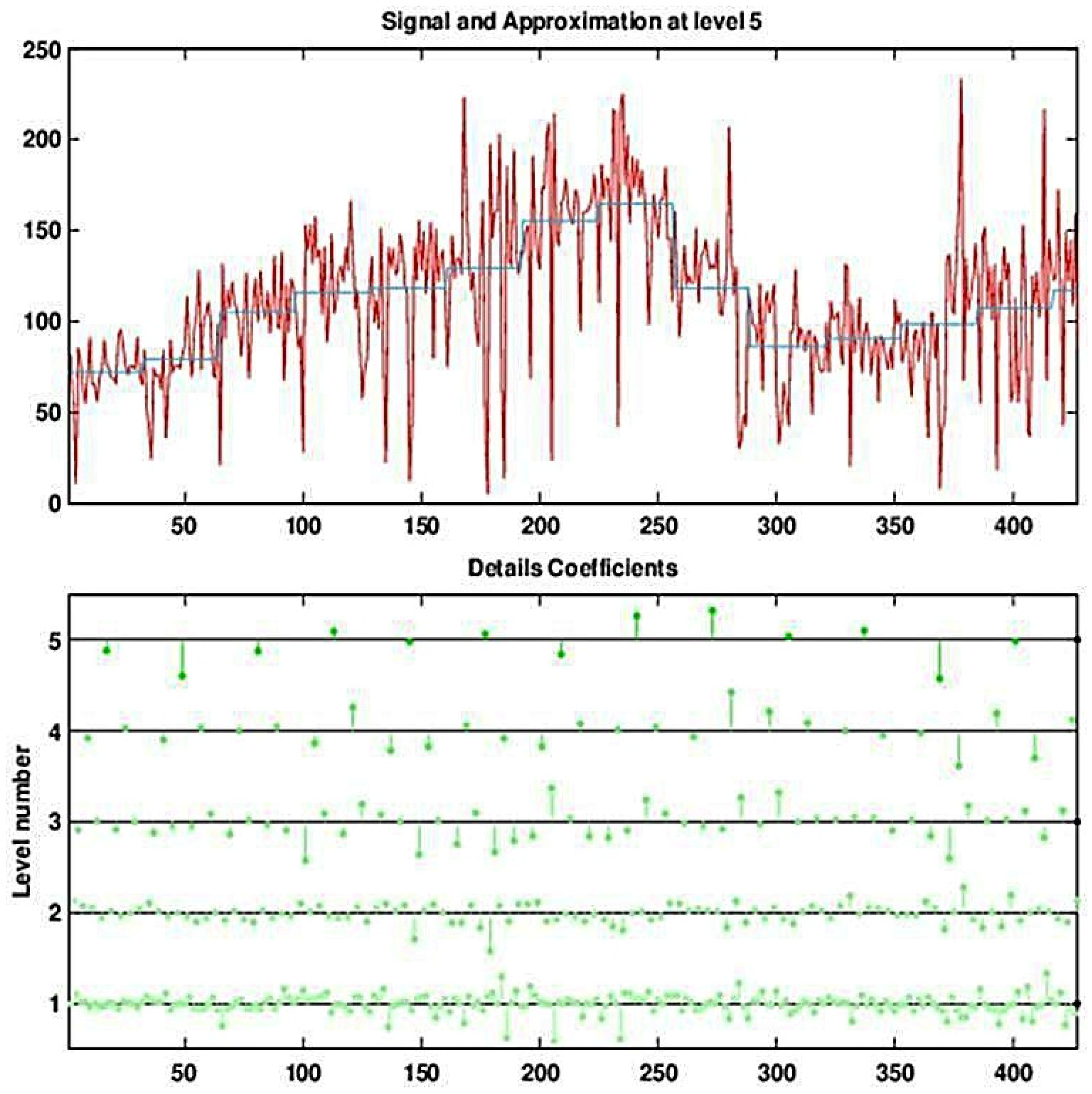
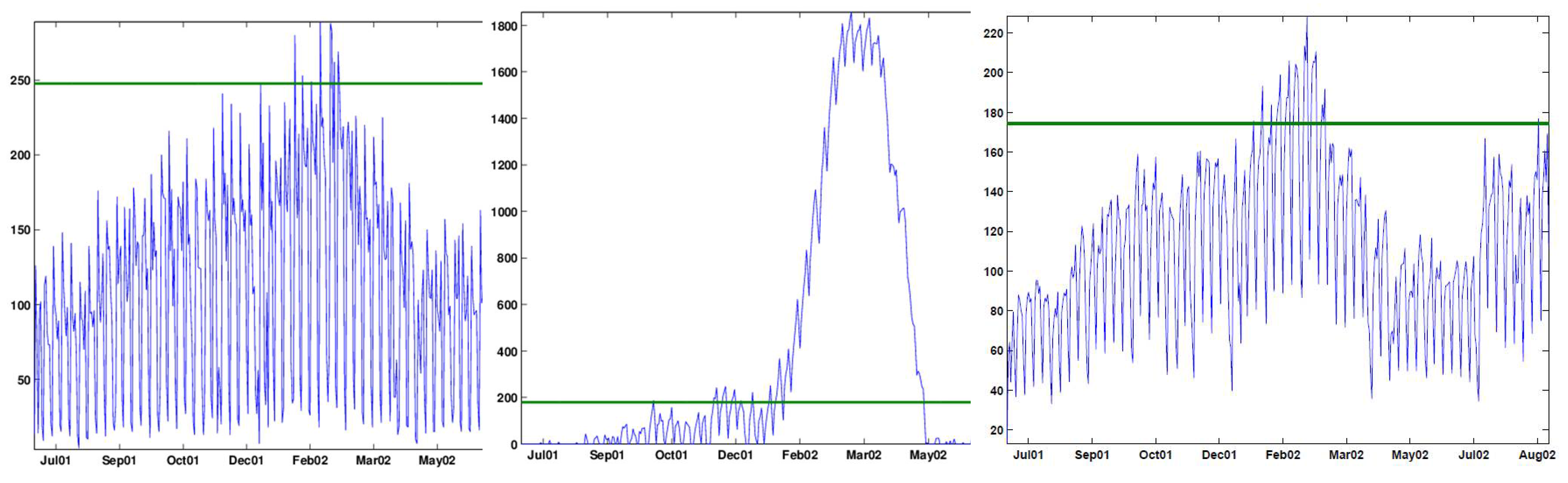
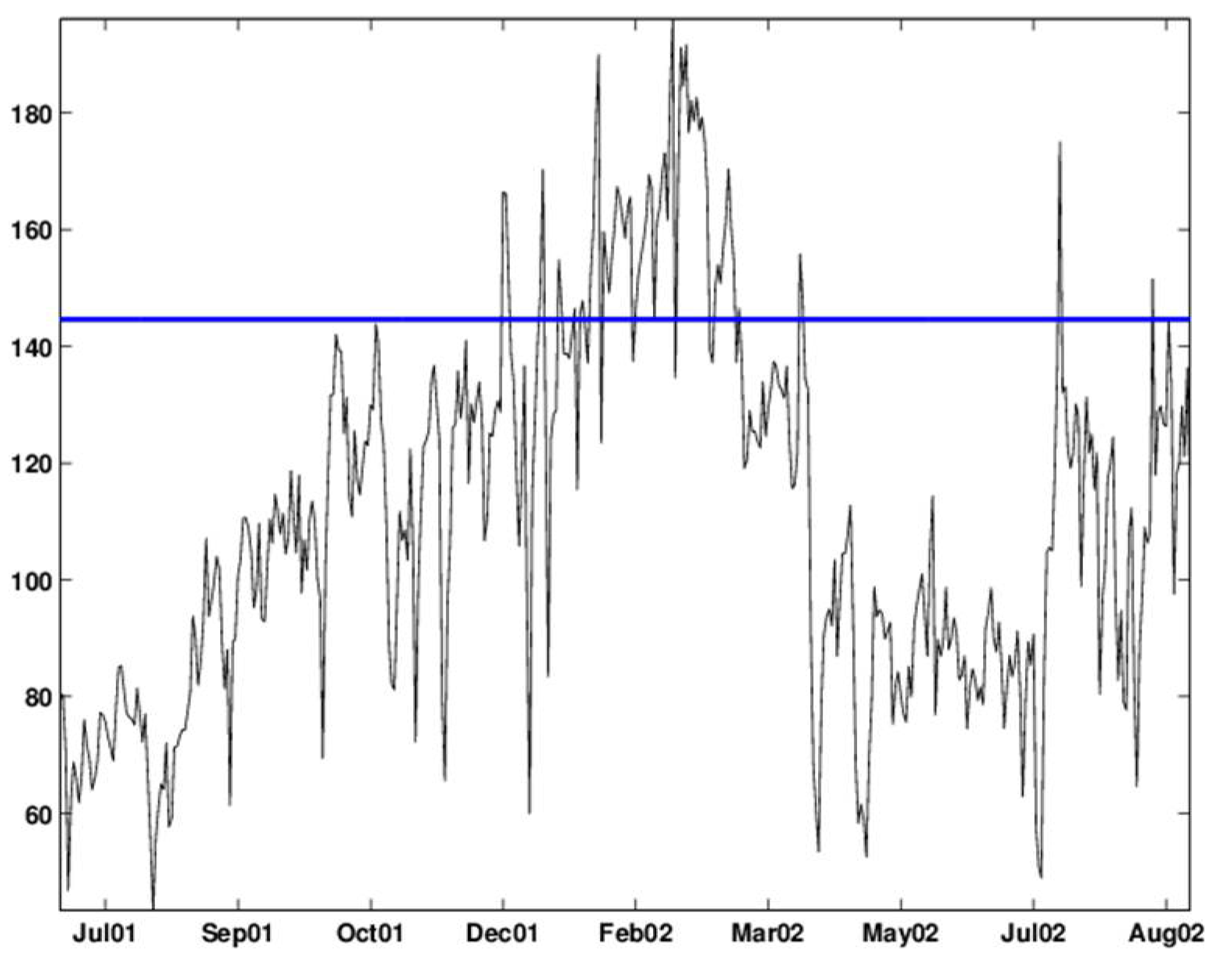
Figure 4 and
Figure 5 show the result of a DWT with five levels for the (deseasonalized) daily number of visits to military outpatient clinics dataset (deseasonalization is described further in
Section 3).
Figure 4 displays the Multiresolution Analysis, which includes the reconstructed coefficients (
).
Figure 5 shows the set of five detail coefficients (
) in the bottom panel and the fifth level approximation (
) overlayed on top of the original series.
The next step is to utilize the DWT for monitoring. There have been a few different versions of how the DWT is used for the purpose of forecasting or monitoring. In all versions, the underlying idea is to decompose the signal using DWT and then operate on the individual detail and approximation levels. Some methods operate on the coefficients, e.g., [
4], while others use the reconstructed approximation and details [
18]. There are a few other variations, such as [
19], who use the approximation to detrend the data in order to remove extremely low data points, due to missing data. Our goal is to describe a general approach for
monitoring using a wavelet decomposition. We therefore distinguish between retrospective and prospective monitoring, where, in the former, past data are examined to find anomalies retrospectively and, in the latter, the monitoring is done in real-time for new incoming data, in an attempt to detect anomalies as soon as possible. Although this distinction has not been pointed out clearly, it turns out that the choice of method, its interpretation and performance are dependent on the goal.
Figure 4.
Decomposing the series of daily visits to military outpatient clinics into five levels using the Haar wavelet. The top panel displays the time-series. Below it is the multiresolution analysis that includes the fifth approximation and the five levels of detail.
Figure 4.
Decomposing the series of daily visits to military outpatient clinics into five levels using the Haar wavelet. The top panel displays the time-series. Below it is the multiresolution analysis that includes the fifth approximation and the five levels of detail.
Figure 5.
Decomposing the (deseasonalized) series of daily visits to military outpatient clinics into five levels using the Haar wavelet. The top panel displays the time-series overlaid with the fifth approximation (the blocky curve). The bottom panel shows the five levels of detail coefficients.
Figure 5.
Decomposing the (deseasonalized) series of daily visits to military outpatient clinics into five levels using the Haar wavelet. The top panel displays the time-series overlaid with the fifth approximation (the blocky curve). The bottom panel shows the five levels of detail coefficients.
2.2. Retrospective Monitoring
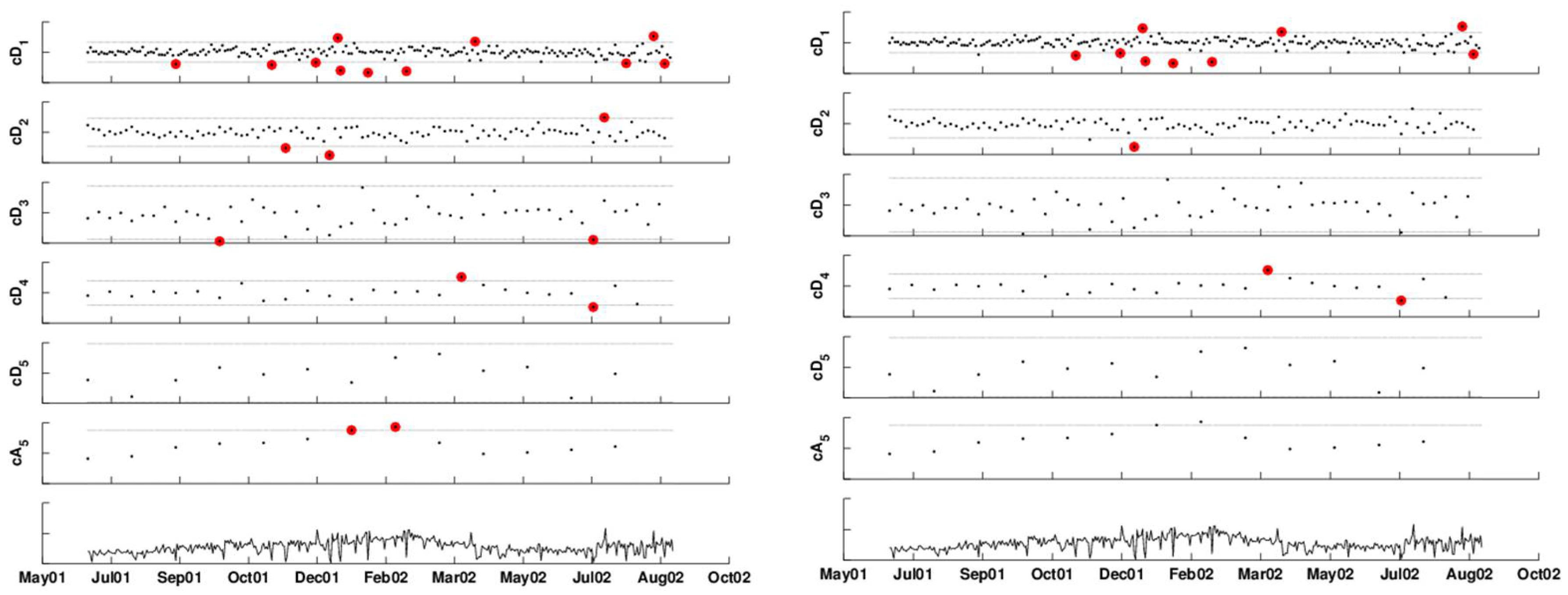
Using wavelets for retrospective monitoring is the easier task of the two. The goal is to find anomalous patterns at any time points within a given time-series. This can be done by constructing thresholds or “control limits” that distinguish between natural variation and anomalous behavior. Wang [
20] suggested the use of wavelets for detecting jumps and cusps in a time-series. He shows that if these patterns are sufficiently large, they will manifest themselves as extreme coefficients in the high detail levels. Wang uses Donoho’s universal threshold [
21] to determine an extreme coefficient. This threshold is given by
, where
σ is estimated by the median absolute deviation of the coefficients at the finest level, divided by 0.6745 [
20].
Another approach that is directly aimed at statistical monitoring was suggested by Bakshi [
22]. The method, called Multiscale Statistical Process Control (MSSPC), is comprised of three steps:
Decompose the time-series using DWT.
For each of the detail scales and for the coarsest approximation scale, construct a Shewhart (or other) control chart with control limits computed from scale-specific coefficients. Use each of the control charts to threshold coefficients so that coefficients within the control limits are zeroed out.
Reconstruct the time-series from the thresholded coefficients and monitor this series using a Shewhart (or other) control chart. The control limits at time t are based on estimated variances from scales, where coefficients exceeded their limits at time t.
The method relies on the decorrelation property of DWT, such that coefficients within and across scales are approximately uncorrelated. It is computationally cheap and easy to interpret. Using a set of real data from a chemical engineering process, Aradhye
et al. [
4] show that this method exhibits better average performance compared to traditional control charts in detecting a range of anomalous behavior when autocorrelation is present or void. Its additional advantage is that it is not tailored for detecting a certain type of anomaly (e.g., single spike, step function, exponential drift) and, therefore, on average, performs better than pattern-specific methods.
MSSPC is appealing, because its approach is along the line of classical SPC. However, there are two points that need careful attention: the establishment of the control limits and the triggering of an alarm. We describe these next.
2.2.1. Two-Phase Monitoring
We put MSSPC into the context of two-phase monitoring: Phase I consists of establishing control limits based on a period with no anomalies. For this purpose, there should be a period in the data that is known to be devoid of anomalies. Phase II uses these control limits to detect abnormalities in the remainder of the data. Therefore, a DWT is performed twice: once for the purpose of estimating standard deviations and computing control limits (using only the in-control period) and once for the entire series, as described in steps 2–3.
2.2.2. Accounting for Multiple Testing
MSSPC triggers an alarm only if the reconstructed series exceeds its control limits. The reconstruction step is essentially a denoised version of the original signal with hard thresholding. An alternative, which does not require the reconstruction step and directly accounts for the multiple tests at the different levels, is described below. When each of the levels is monitored at every time point, a multiple testing issue arises: For an
m-level DWT, there are
tests being performed at every time point in step 2. This results in an inflated false alarm rate. When these tests are independent (as is the case, because of the decorrelation property) and each has a false alarm rate
α the combined false alarm rate at any time point will be
. We suggest correcting for this multiple testing by integrating the False Discovery Rate (FDR) correction [
23,
24] into step 2, above. Unlike Bonferroni-type corrections that control for the probability of any false alarm, the FDR correction is used to control the average proportion of false alarms among all detections. It is therefore more powerful in detecting real outbreaks. Adding an FDR correction means, in practice, that instead of setting fixed control limits, the
p-values are calculated at each scale, and the thresholding then depends on the collection of
p-values.
Finally, using DWT for retrospective monitoring differs from ordinary control charts in that it compares a certain time point not only to its past, but also to its future; depending on the wavelet function, the type and strength of the relationship with neighboring points (e.g., symmetric vs. non-symmetric wavelets and the width of the wavelet filter).
2.3. Prospective Monitoring
The use of DWT for prospective monitoring is more challenging. A few wavelet-based prospective monitoring algorithms were suggested and applied in biosurveillance [e.g.,
3,
19]. However, there has not been a rigorous discussion of the statistical challenges associated with the different formulation. We therefore list some main issues and suggest possible solutions.
Time lag: Although DWT can approximately decorrelate highly correlated series (even long memory with slow decaying autocorrelation function), the downsampling introduces a time lag for calculating coefficients, which becomes more and more acute at the coarse scales. One solution is to use a “redundant” or “stationary” DWT (termed SWT), where the downsampling step is omitted. The price is that we lose the decorrelation ability. The detail and approximation coefficients in the SWT are each a vector of length
n, but they are no longer uncorrelated within scales. The good news is that the scale-level correlation is easier to handle than the correlation in the original time-series, and several authors have shown that this dependence can be captured by computationally efficient models. For example, Goldenberg
et al. [
3] use redundant DWT and scale-specific autoregressive (AR) models to forecast one-step-ahead details and approximation. These forecasts are then combined to create a one-step-ahead forecast of the time-series. Aussem and Murtagh [
25] use a similar model, with neural networks to create the one-step-ahead scale-level forecasts. From a computational point of view, the SWT computational complexity is
, like that of the Fast Fourier Transform (FFT) algorithm, compared to
for DWT. Therefore, it is still reasonable.
Dependence on starting point: Another challenge is the dependence of the decomposition on what we take as the starting point of the series [
9]. This problem does not exist in the SWT, which further suggests the adequacy of the redundant DWT for prospective monitoring.
Boundaries: DWT suffers from “boundary problems”. This means that the beginning and end of the series need to be extrapolated somehow in order to compute the coefficients. The amount of required extrapolation depends on the filter length and on the scale. The Haar is the only wavelet that does not impose boundary problems for computing DWT coefficients. Popular extrapolation methods are zero-padding, mirror- and periodic-borders. In the context of prospective monitoring of a time-series, the boundary problem is acute, because it weakens the most recent information that we have. To reduce the impact of this problem, it is better to use wavelets with very short filters (e.g., the Haar, which has a length of two), and to keep the depth of the decomposition to a minimum. Note that an SWT using the Haar does suffer from boundary problems, although minimally (
values at scale
j are affected by the boundary). Renaud
et al. [
18] and Xiao
et al. [
26] suggest a “backward implemented” SWT that uses a non-symmetric Haar filter for the purpose of forecasting a series using SWT with the Haar. This implementation only uses past values of the time-series to compute coefficients. Most wavelet functions, excluding the Haar, use future values to compute the coefficients at time
n. Examining this modification, we find that it is equivalent to using an ordinary SWT, except that coefficients at scale
j are shifted in time by
points. For instance, the level 1 approximation and detail coefficients will be aligned with the second time point, rather than the first time point. This means that at scale
j the first
coefficients are missing, so that we need a phase I that is longer than
. The great advantage of this modification is that new data-points do not affect past coefficients. This means that we can use this very efficiently in a roll-forward algorithm that applies SWT with every incoming point.
These challenges all suggest that a reasonable solution is to use a Haar-based redundant DWT in its “backward” adaptation as a basis for prospective monitoring. This choice also has the advantage that the approximation and details are much smoother than the downsampled Haar DWT and, therefore, more appealing for monitoring time-series that do not have a block-type structure. Furthermore, the redundant-DWT does not require the time-series to be of special length, as might be required in the ordinary DWT. Finally, the Haar is the simplest wavelet function and is therefore desirable from a computational and parsimonious perspective.
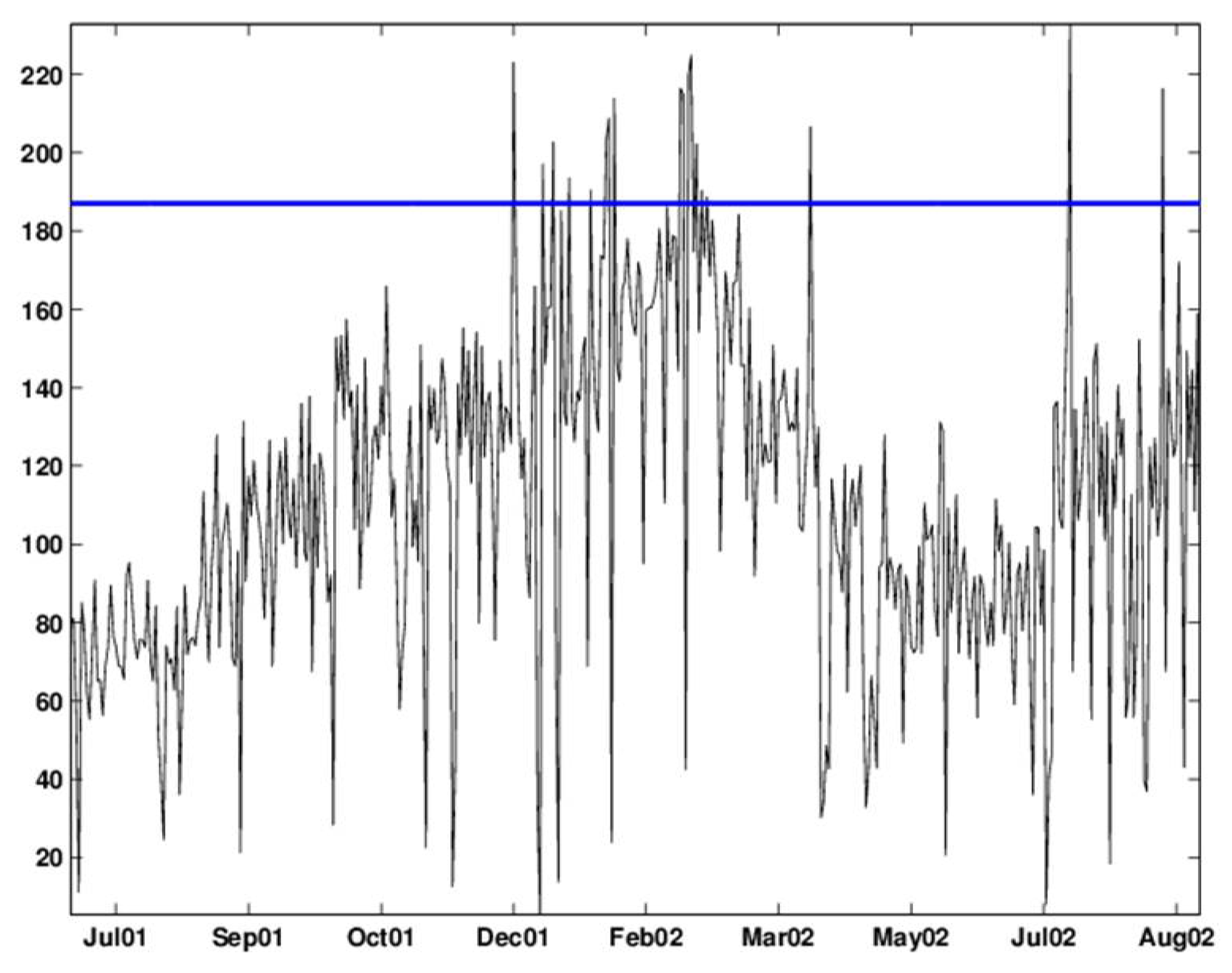
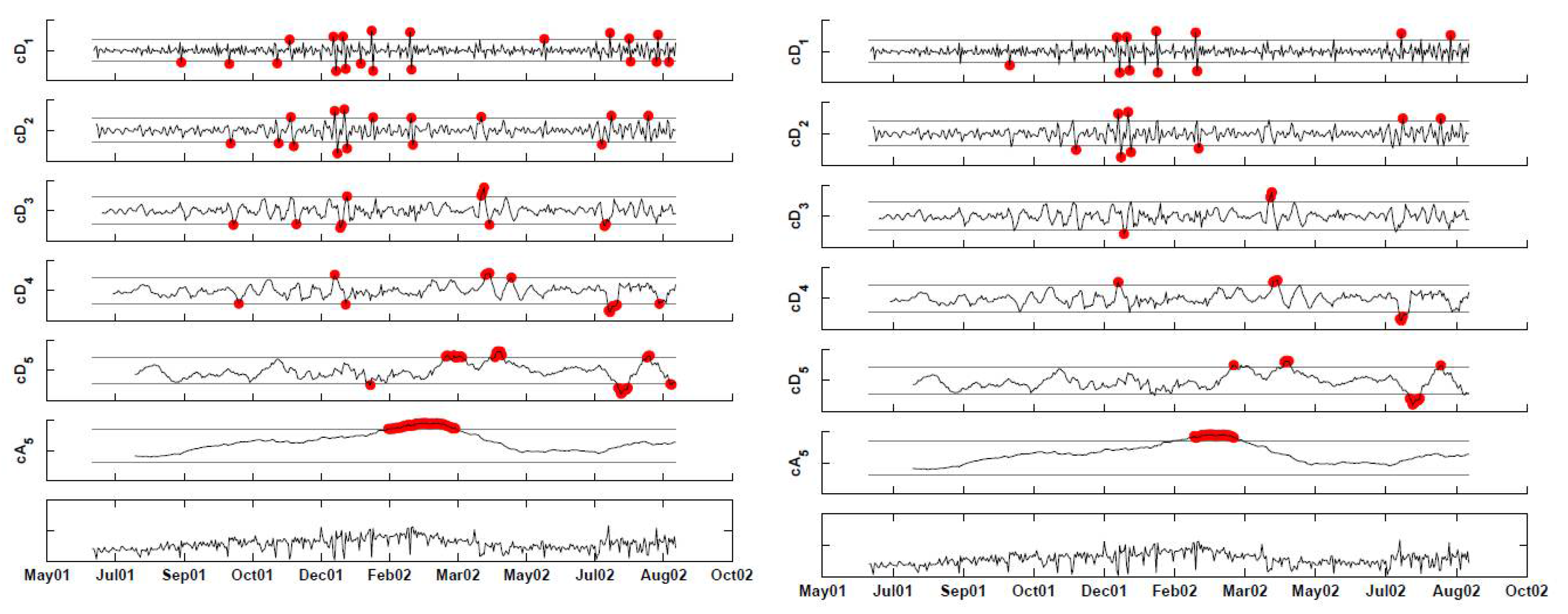
Figure 6 illustrates the result of applying a “backward” redundant Haar wavelet decomposition to the military clinic visits data. It can be seen that the series of coefficients starts at different time-points for the different scales. However, for prospective monitoring, this is not important, because we assume that the original time-series is sufficiently long and that our interest focuses on the right-most part of the series.
Two-stage monitoring should also be implemented in this case: first, a period that is believed to be devoid of any disease outbreak of interest is used for estimating scale-specific parameters. Then, these estimates are used for determining control limits for the alerting of anomalous behavior.
The redundancy in wavelet coefficients now leads to an inflated false alarm rate. Aradhye
et al. [
4] approached this by determining empirically the adjustment to the control limits in MSSPC when using the redundant DWT. The disadvantage of using the redundant DWT is that the high autocorrelation in the coefficients increases the false alarm rate in highly non-stationary series [
4]. An FDR correction can still be used to handle the correlation across scales. In the following, we suggest an approach to handling the autocorrelation within scales directly.
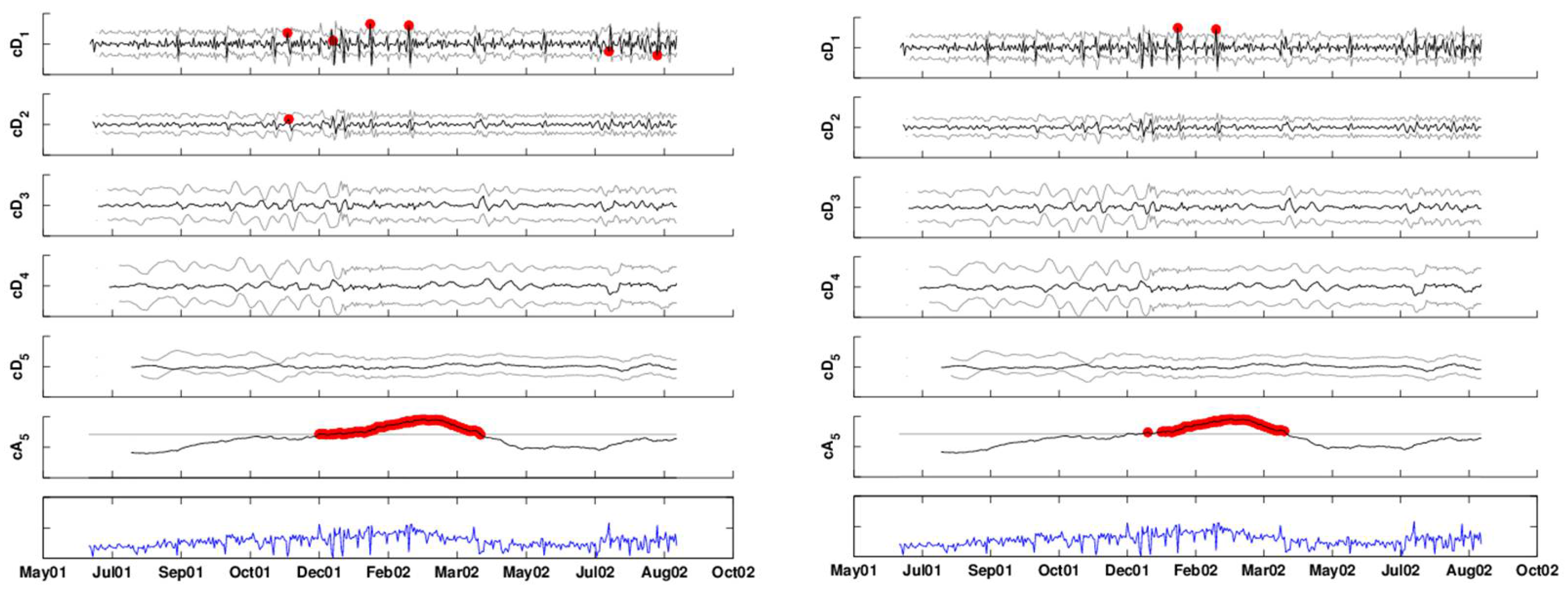
2.3.1. Handling Scale-Level Autocorrelation
As can be seen in
Figure 6, the coefficients within each scale are autocorrelated, with the dependence structure being different for the detail coefficients compared with the approximation coefficients series. In addition to autocorrelation, sometimes, after deseasonalizing there remains a correlation at a lag of seven. This type of periodicity is common in many syndromic datasets. The underlying assumption behind the detail coefficients is that in the absence of anomalous behavior, they should be zero. From our experience with syndromic data, we found that the detail coefficient series are well approximated by an autoregressive model of the order of seven with zero-mean.
Figure 6.
Decomposing the (deseasonalized) series of daily visits to military outpatient clinics into five levels using the “backward” Haar wavelet, without downsampling. The bottom panel displays the time-series. Above it are the fifth approximation () and the five levels of detail ().
Figure 6.
Decomposing the (deseasonalized) series of daily visits to military outpatient clinics into five levels using the “backward” Haar wavelet, without downsampling. The bottom panel displays the time-series. Above it are the fifth approximation () and the five levels of detail ().
A similar type of model was also used by Goldenberg
et al. [
3] to model series arising from a redundant wavelet transform of over-the-counter medication sales. Using an autoregressive model to forecast detail levels has also been suggested in other applications [e.g.,
18,
26]. The autoregressive model is used to forecast the coefficient (or its reconstruction) in the next point. In the context of monitoring, we need to specify how the AR parameters are estimated and how to derive forecast error measures. The following describes a roll-forward algorithm for monitoring the coefficients on a new day:
Using the phase I period, estimate the scale-specific AR(7) model coefficients () by using the first part of the phase I period and the associated standard deviation of the forecast error () using the second part of the phase I period.
For the phase II data, forecast the next-day detail coefficient at level
j (
), using the estimated AR(7) model:
Using the estimated standard deviation of the forecast error at level
j (
), create the control limits:
where
is the
percentile from the standard normal distribution.
Plot the next day coefficients on scale-level control charts with these control limits. If they exceed the limits, then an alarm is raised.
The approximation level captures the low-frequency information in the series or the overall trend. This trend can be local, reflecting background noise and seasonality rather than an outbreak. It is therefore crucial to have a sense of what is a “no-outbreak” overall trend. When the outbreak of interest is associated with a bio-terrorist attack, we will most likely have enough “no-outbreak” data to learn about the underlying trend. However, to assess the sampling variability of this trend, we need several no-outbreak seasons. For the case of “ordinary” disease outbreak detection, such as in our example, we have data from a single year, the trend appears to vary during the year, and this one year contains an outbreak period. We therefore do not know whether to attribute the increasing trend to the outbreak or to seasonal increases in outpatient visits during those months. A solution would be to obtain more data for years with no such outbreaks (at least not during the same period) and to use those to establish a no-outbreak trend and its related sampling error. Of course, medical and epidemiological expertise should be sought in all cases in order to establish what is a reasonable level at different periods of the year.
Two methods for evaluating whether there is anomalous behavior using the scale-level forecasts are to add these forecasts to obtain a forecast for the actual new data point (as in [
3]). Alternatively, we can compare the actual
vs. forecasted coefficient at each scale and determine whether the actual coefficient is abnormal. In both cases, we need estimates of the forecast error variability, which can be obtained from the forecast errors during phase I (the no-outbreak period). For the first approach of computing a forecast of the actual data, the standard deviation of forecast errors can be estimated from the forecasts generated during phase I and used to construct an upper control limit on the original time-series. For the second approach, where scale-level forecasts are monitored directly, we estimate scale-specific standard deviations of the forecast errors from phase I (at scale
j, we estimate
) and then construct scale-specific upper control limits on the coefficients at that scale. This is illustrated in the next section for our data.
In both cases, the algorithm is implemented in a roll-forward fashion: the scale-level models use the phase I data to forecast the next-day count or coefficients. This is then compared to the actual data or coefficients to determine whether an alarm should be raised. The new point is added to the phase I data, and the forecasting procedure is repeated with the additional data point.
Finally, an important factor for infiltrating new statistical methods into a non-statistician domain is software availability. Many software packages contain classic control charts, and they are also relatively easy to program. For this reason, we make our wavelet-monitoring Matlab code freely available at
galitshmueli.com/wavelet-code. The code includes a program for performing retrospective DWT monitoring with Shewhart control limits and a program for performing prospective SWT monitoring with Shewhart or AR-based control limits. In both cases, it yields the control charts and lists the alarming dates. Outputs from this code are shown in the next section.















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
