Using the Choquet Integral in the Fuzzy Reasoning Method of Fuzzy Rule-Based Classification Systems


Abstract
:1. Introduction
2. Preliminaries
2.1. Theoretical Concepts
- Additive if for any disjoint subsets , ;
- Symmetric if for any subsets , implies ;
2.2. Fuzzy Rule-Based Classification Systems
- Knowledge Base: It is composed of both the Rule Base (RB) and the Data Base, where the rules and the membership functions are stored respectively.
- Fuzzy Reasoning Method: It is the mechanism used to classify examples using the information stored in the knowledge base.
2.2.1. Fuzzy Reasoning Method
- Matching degree, that is, the strength of activation of the if-part for all rules in the RB with the example . To compute it we use a t-norm.
- Association degree. The association degree of the example with the class of each rule in the RB.
- Example classification soundness degree for all classes. We use an aggregation function that combines the positive association degrees calculated in the previous step.
- Classification. We apply a decision function F over the example classification soundness degree for all classes. This function determines the class corresponding to the maximum value.
2.2.2. Chi et al. Rule Generation Algorithm
- Establishment of the linguistic partitions. Once the domain of variation of each feature is determined, the Ruspini’s fuzzy partitions are computed using triangular shaped membership functions in this paper.
- Generation of a fuzzy rule for each example applying the following process:
- 2.1.
- To compute the matching degree of the example with all the fuzzy regions using a conjunction operator (usually modelled with the minimum or product t-norm).
- 2.2.
- To assign the example to the fuzzy region with the greatest matching degree.
- 2.3.
- To generate a rule for the example, whose antecedent is determined by the selected fuzzy region and whose consequent is the class label of the example.
- 2.4.
- To compute the rule weight. In this paper, we use the Penalized Certainty Factor (PCF) defined in [24] as:where is the matching degree of the example with the antecedent of the rule that is being generated.
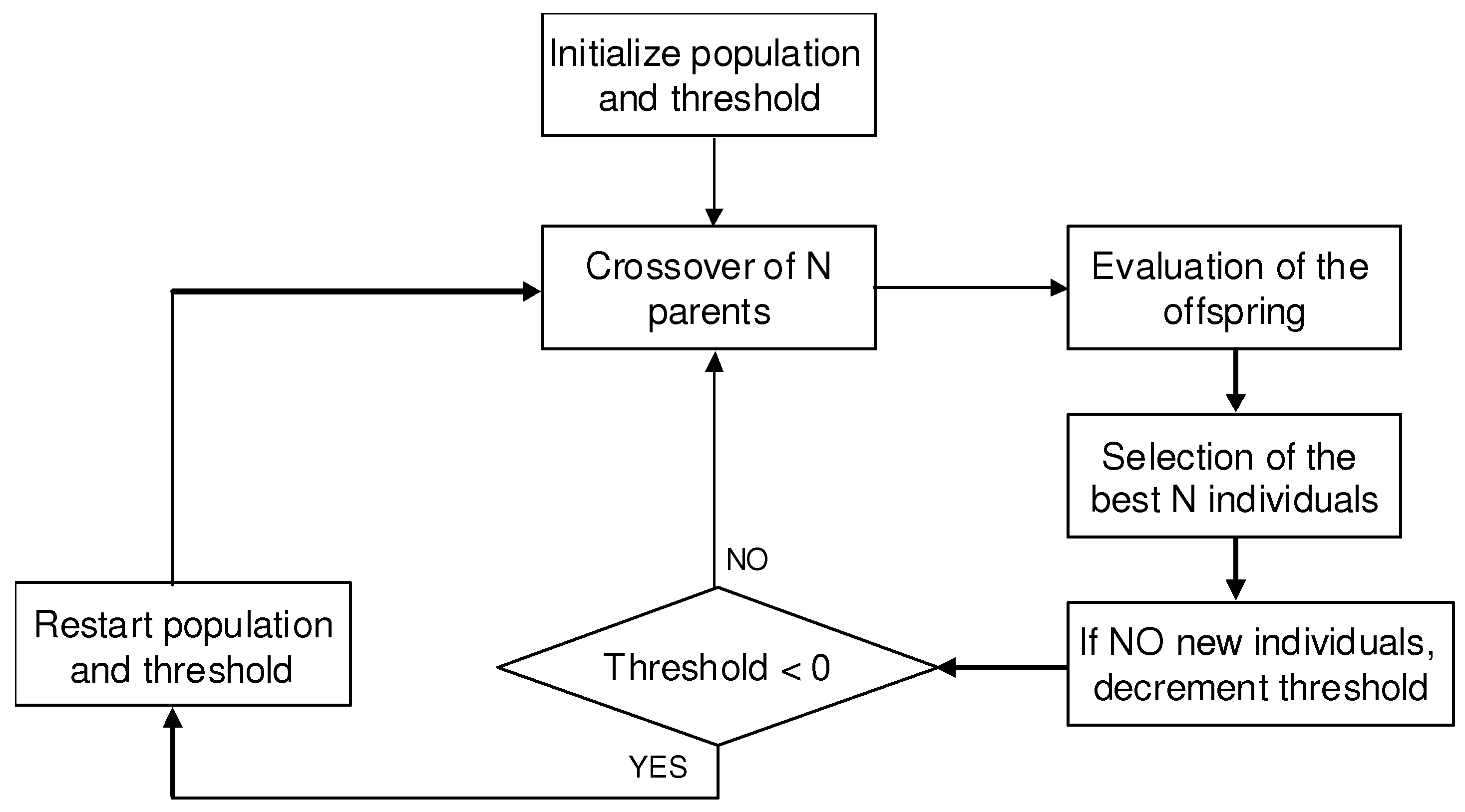
2.3. Evolutionary Model

3. A Novel Fuzzy Reasoning Method Using the Choquet Integral
3.1. Fuzzy Measures
- (1)
- Cardinality or uniform measure.
- (2)
- Dirac’s measure.where is selected beforehand. We must point out that the result of the Choquet integral with this fuzzy measure is the i-th smallest value of X, that is, i-th order statistic.
- (3)
- Weighted mean. We assign the following values for the fuzzy measure: . For the fuzzy measure is
- (4)
- Ordered Weighted Averaging (OWA). We assign the following values for the fuzzy measure: , with i being the j-th largest component to be aggregated, that is, we construct an OWA operator. For the fuzzy measure is
- (5)
- Exponential cardinality
3.2. Fuzzy Measure Learning Method
- Coding scheme. We have a set of real parameters to be optimized (, with ), where the range in which we suggest to vary each one is . However, we do not directly encode them in a chromosome but we adapt them using chromosomes in the form:where with . In order to compute their real values (in the range ) we apply Equation (8).The change of range is provoked because we need to give the same chances to produce offspring in the ranges and after applying the crossover operator. Looking at how the crossover operator works, if we encoded the parameters in the range we would favour the generation of offspring in the range and consequently, we would reduce the probability of the generation of offspring in the range . For this reason, we adapt the range in order to solve this undesirable situation.
- Initial Gene Pool. We include an individual having all genes with value 1. In this manner, at least we obtain the results provided by the cardinality measure.
- Chromosome Evaluation. We use the most common metric for classification, i.e., the accuracy rate that is the percentage of correctly classified examples.
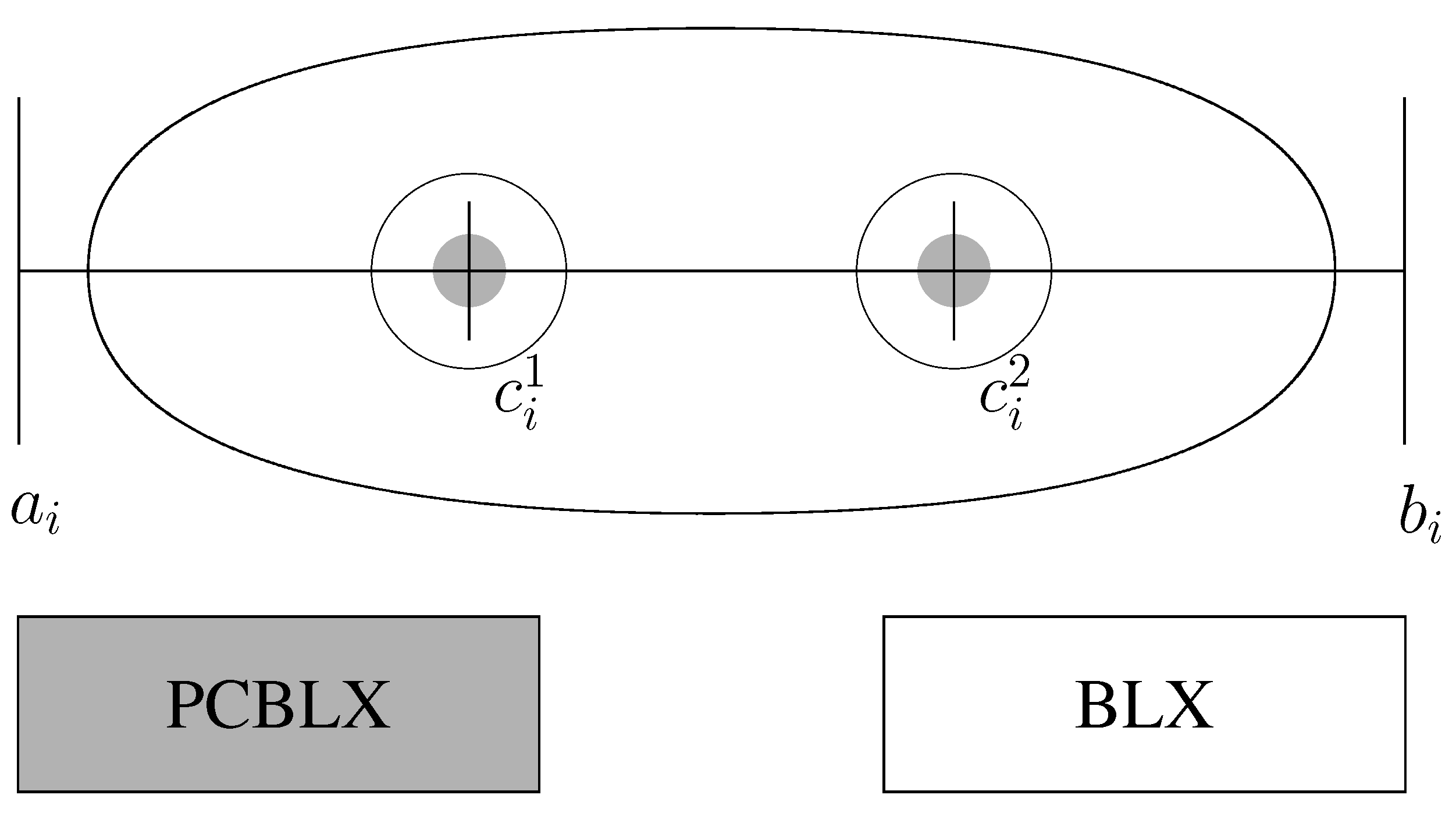
- Crossover Operator. The crossover operator is based on the concept of environments (the offspring are generated around their parents). These kinds of operators present a good cooperation when they are introduced within evolutionary models forcing the convergence by pressure on the offspring (as the case of CHC). Figure 2 depicts the behaviour of these kinds of operators, which allow the offspring genes to be around the genes of one parent, Parent Centric BLX (PCBLX), or around a wide zone determined by both parent genes BLX-α. Specifically, we consider the PCBLX operator that is based on the BLX-α [26].The PCBLX is described as follows. Assuming that and , are two real-coded chromosomes that are going to be crossed. The PCBLX operator generates the two following offsprings:
- –
- , where is a randomly (uniformly) chosen number from the interval , with , , and .
- –
- , where is a randomly (uniformly) chosen number from the interval , with and .
- Restarting Approach. To get away from local optima, this algorithm uses a restarting approach since it does not apply mutation during the recombination phase. Therefore, when the threshold value is lower than zero, all the chromosomes are regenerated randomly to introduce new diversity to the search. Furthermore, the best global solution found is included in the population to increase the convergence of the algorithm as in the elitist scheme.

4. Experimental Framework
4.1. Data-Sets

{kind=link}
{kind=link}
{kind=link}
| Id. | Data-set | #Ex. | #Atts. | #Class. |
|---|---|---|---|---|
| bal | Balance | 625 | 4 | 3 |
| ban | Banana | 5300 | 2 | 2 |
| eco | Ecoli | 336 | 7 | 8 |
| gla | Glass | 214 | 9 | 6 |
| iri | Iris | 150 | 4 | 3 |
| led | Led7digit | 500 | 7 | 10 |
| mag | Magic | 1902 | 10 | 2 |
| new | Newthyroid | 215 | 5 | 3 |
| pho | Phoneme | 5404 | 5 | 2 |
| pim | Pima | 768 | 8 | 2 |
| rin | Ring | 740 | 20 | 2 |
| seg | Segment | 2310 | 19 | 7 |
| tit | Titanic | 2201 | 3 | 2 |
| two | Twonorm | 740 | 20 | 2 |
| veh | Vehicle | 846 | 18 | 4 |
| win | Wine | 178 | 13 | 3 |
| wis | Wisconsin | 683 | 11 | 2 |
4.2. Configuration of the Proposals and Notation
- Conjunction operator: Product t-norm.
- Rule weight: Penalized Certainty Factor.
- Number of linguistic labels: 3.
- Population Size: 50 individuals.
- Number of evaluations: 20,000.
- Bits per gene for the Gray codification (for incest prevention): 30 bits.
| Name | Aggregation function | Fuzzy Measure |
|---|---|---|
| Max. | Maximum | - |
| AC | Sum (This function is not an | - |
| aggregation function as introduced in Definition 3 | ||
| because it does not provide a result in .) | ||
| Card. | Choquet integral | Cardinality |
| Dirac. | Choquet integral | Dirac’s measure |
| WMean. | Choquet integral | Weighted mean |
| OWA | Choquet integral | OWA |
| Card_GA | Choquet integral | Exponential cardinality |
4.3. Statistical Tests for Performance Comparison
5. Experimental Results
| Data | Max. | AC | Card. | Dirac | WMean | OWA | Card_GA | |||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Set | ||||||||||||||
| Bal | 91.52 ± 0.23 | 90.56 ± 1.04 | 91.52 ± 0.23 | 90.56 ± 1.19 | 89.96 ± 1.11 | 86.72 ± 2.57 | 89.48 ± 0.41 | 87.04 ± 1.04 | 90.20 ± 0.93 | 86.72 ± 1.93 | 90.24 ± 1.07 | 86.88 ± 2.37 | 91.52 ± 0.23 | 89.92 ± 0.91 |
| Ban | 60.36 ± 0.39 | 60.32 ± 1.33 | 59.83 ± 0.28 | 60.02 ± 1.30 | 60.68 ± 0.60 | 60.47 ± 1.62 | 62.00 ± 1.18 | 61.77 ± 0.79 | 60.34 ± 0.63 | 60.08 ± 1.44 | 60.55 ± 0.71 | 60.36 ± 1.34 | 63.11 ± 0.90 | 62.36 ± 1.28 |
| Eco | 76.27 ± 1.34 | 71.76 ± 6.69 | 78.42 ± 0.86 | 73.53 ± 5.40 | 75.97 ± 2.03 | 69.71 ± 5.94 | 73.36 ± 2.57 | 67.94 ± 6.01 | 75.60 ± 1.45 | 70.59 ± 6.33 | 75.45 ± 1.73 | 70.88 ± 6.36 | 83.26 ± 2.12 | 75.00 ± 9.24 |
| Gla | 66.01 ± 2.58 | 57.67 ± 1.04 | 66.47 ± 1.84 | 59.07 ± 2.65 | 62.61 ± 3.39 | 58.60 ± 3.82 | 62.15 ± 4.82 | 57.21 ± 2.08 | 61.09 ± 3.97 | 57.21 ± 4.53 | 63.31 ± 2.86 | 59.53 ± 2.65 | 68.23 ± 1.36 | 59.53 ± 3.12 |
| Iri | 93.00 ± 0.75 | 92.67 ± 1.49 | 95.33 ± 1.51 | 94.67 ± 4.47 | 88.50 ± 1.09 | 87.33 ± 1.49 | 84.67 ± 1.73 | 84.00 ± 4.35 | 88.67 ± 1.92 | 87.33 ± 2.79 | 87.00 ± 1.26 | 86.67 ± 2.36 | 96.67 ± 0.83 | 94.67 ± 2.98 |
| Led | 75.90 ± 2.96 | 64.20 ± 5.63 | 75.90 ± 2.96 | 64.20 ± 5.63 | 75.90 ± 2.96 | 64.20 ± 5.63 | 75.90 ± 2.96 | 64.20 ± 5.63 | 75.90 ± 2.96 | 64.20 ± 5.63 | 75.90 ± 2.96 | 64.20 ± 5.63 | 75.90 ± 2.96 | 64.20 ± 5.63 |
| Mag | 76.00 ± 0.61 | 74.75 ± 1.85 | 76.49 ± 0.56 | 75.38 ± 1.51 | 74.11 ± 0.22 | 72.65 ± 1.50 | 71.65 ± 0.43 | 70.81 ± 1.04 | 74.01 ± 0.31 | 72.97 ± 1.65 | 74.29 ± 0.32 | 73.07 ± 1.40 | 79.31 ± 0.93 | 77.80 ± 3.62 |
| New | 86.40 ± 1.06 | 85.12 ± 3.53 | 87.44 ± 1.40 | 86.51 ± 4.16 | 87.79 ± 1.23 | 86.05 ± 3.68 | 89.19 ± 0.88 | 86.98 ± 4.22 | 87.91 ± 1.61 | 87.44 ± 3.53 | 88.02 ± 1.52 | 86.51 ± 3.45 | 94.42 ± 1.27 | 92.56 ± 4.47 |
| Pho | 71.91 ± 0.11 | 71.91 ± 0.37 | 72.82 ± 0.09 | 72.62 ± 0.64 | 71.54 ± 0.18 | 71.23 ± 0.80 | 72.20 ± 0.36 | 72.16 ± 0.71 | 71.79 ± 0.27 | 71.56 ± 0.60 | 72.03 ± 0.26 | 71.93 ± 1.01 | 76.16 ± 0.25 | 75.39 ± 1.28 |
| Pim | 75.46 ± 0.70 | 72.99 ± 0.98 | 74.64 ± 0.50 | 73.25 ± 1.55 | 75.75 ± 0.40 | 73.77 ± 1.75 | 75.36 ± 0.49 | 73.38 ± 1.66 | 75.98 ± 0.48 | 74.55 ± 2.53 | 75.46 ± 0.28 | 74.03 ± 2.43 | 78.39 ± 0.71 | 75.06 ± 1.18 |
| Rin | 59.39 ± 0.44 | 52.70 ± 0.83 | 57.70 ± 0.44 | 52.03 ± 0.48 | 53.75 ± 0.44 | 51.08 ± 0.37 | 51.11 ± 0.28 | 50.68 ± 0.48 | 53.99 ± 0.64 | 51.08 ± 0.37 | 53.72 ± 0.41 | 51.22 ± 0.30 | 81.35 ± 1.69 | 77.70 ± 1.85 |
| Seg | 86.01 ± 1.31 | 85.02 ± 2.26 | 86.03 ± 0.95 | 84.81 ± 1.84 | 84.40 ± 0.92 | 83.51 ± 1.93 | 78.40 ± 1.93 | 77.92 ± 3.93 | 84.43 ± 1.22 | 83.38 ± 2.16 | 83.99 ± 0.91 | 82.94 ± 2.62 | 87.18 ± 0.74 | 85.06 ± 2.23 |
| Tit | 78.33 ± 0.41 | 78.32 ± 1.71 | 78.33 ± 0.41 | 78.32 ± 1.71 | 78.33 ± 0.41 | 78.32 ± 1.71 | 78.33 ± 0.41 | 78.32 ± 1.71 | 78.33 ± 0.41 | 78.32 ± 1.71 | 78.33 ± 0.41 | 78.32 ± 1.71 | 78.33 ± 0.41 | 78.32 ± 1.71 |
| Two | 87.13 ± 0.77 | 83.78 ± 1.72 | 94.97 ± 0.51 | 93.24 ± 1.85 | 73.34 ± 1.23 | 70.41 ± 4.39 | 63.68 ± 1.44 | 62.57 ± 4.91 | 73.01 ± 1.33 | 69.19 ± 4.29 | 74.02 ± 2.23 | 70.68 ± 3.59 | 91.45 ± 0.44 | 87.57 ± 1.83 |
| Veh | 66.11 ± 0.80 | 61.41 ± 3.66 | 64.16 ± 0.70 | 61.29 ± 3.26 | 64.21 ± 0.56 | 60.94 ± 4.29 | 57.54 ± 1.25 | 53.41 ± 3.29 | 64.18 ± 0.85 | 60.12 ± 3.56 | 63.95 ± 0.58 | 59.65 ± 3.26 | 67.85 ± 0.48 | 60.59 ± 3.53 |
| Win | 98.74 ± 0.58 | 92.78 ± 5.41 | 98.74 ± 0.59 | 93.33 ± 5.76 | 96.21 ± 0.62 | 91.11 ± 5.69 | 89.61 ± 1.32 | 85.56 ± 4.12 | 95.93 ± 0.76 | 91.11 ± 5.69 | 96.21 ± 1.07 | 90.00 ± 4.65 | 99.86 ± 0.31 | 92.22 ± 4.56 |
| Wis | 98.17 ± 0.29 | 95.62 ± 1.37 | 97.99 ± 0.45 | 95.77 ± 1.31 | 98.21 ± 0.27 | 96.06 ± 1.42 | 98.13 ± 0.24 | 95.91 ± 1.60 | 98.24 ± 0.28 | 95.77 ± 1.66 | 98.21 ± 0.27 | 96.06 ± 1.42 | 98.54 ± 0.13 | 95.33 ± 1.42 |
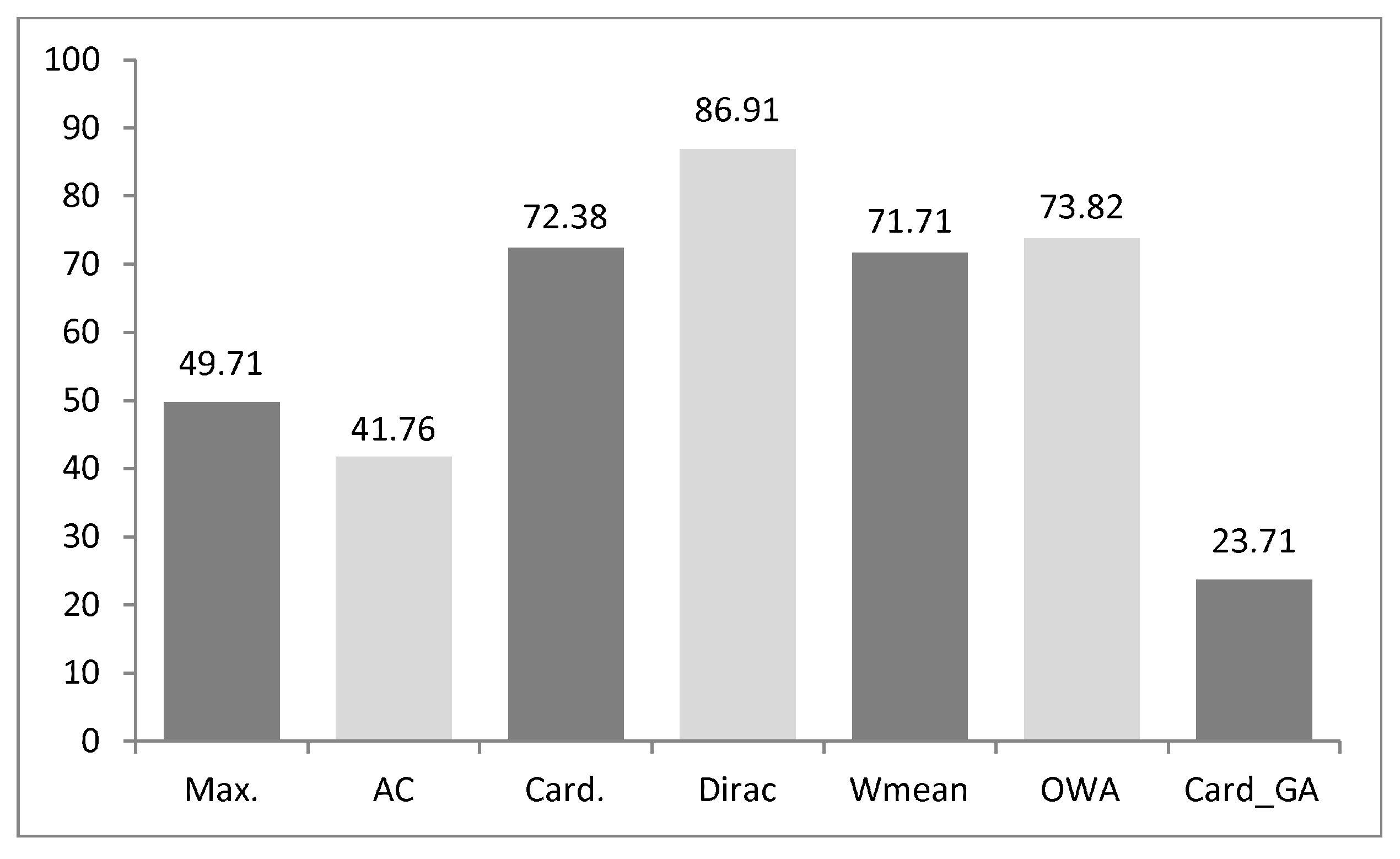
| Mean | 79.22 ± 0.90 | 75.98 ± 2.41 | 79.81 ± 0.84 | 76.98 ± 2.63 | 77.13 ± 1.04 | 74.24 ± 2.86 | 74.87 ± 1.33 | 72.34 ± 2.80 | 77.03 ± 1.18 | 74.21 ± 2.96 | 77.10 ± 1.11 | 74.29 ± 2.74 | 83.03 ± 0.93 | 79.02 ± 2.99 |

| i | Algorithm | APV |
|---|---|---|
| 1 | Dirac | 5.52E–7 |
| 2 | OWA | 1.14E–4 |
| 3 | Card. | 1.56E–4 |
| 4 | WMean | 1.56E–4 |
| 5 | Max. | 0.06 |
| 6 | AC | 0.13 |
6. Conclusions
Acknowledgements
References
- Duda, R.O.; Hart, P.E.; Stork, D.G. Pattern Classification, 2nd ed.; John Wiley: Hoboken, NJ, USA, 2001. [Google Scholar]
- Alpaydin, E. Introduction to Machine Learning, 2nd ed.; MIT Press: Cambridge, MA, USA, 2010. [Google Scholar]
- Ishibuchi, H.; Nakashima, T.; Nii, M. Classification and Modeling with Linguistic Information Granules: Advanced Approaches to Linguistic Data Mining; Springer-Verlag: Berlin/Heidelberg, Germany, 2004. [Google Scholar]
- Samantaray, S.R.; El-Arroudi, K.; Joós, G.; Kamwa, I. A fuzzy rule-based approach for islanding detection in distributed generation. IEEE Trans. Power Deliv. 2010, 25, 1427–1433. [Google Scholar] [CrossRef]
- Kuncheva, L.I. On the equivalence between fuzzy and statistical classifiers. Int. J. Uncertain. Fuzziness Knowl.-Based Syst. 1996, 4, 245–253. [Google Scholar] [CrossRef]
- Mandal, D.; Murthy, C.; Pal, S. Formulation of a multivalued recognition system. Syst. Man Cybern. IEEE Trans. 1992, 22, 607–620. [Google Scholar] [CrossRef]
- Ishibuchi, H.; Nozaki, K.; Tanaka, H. Distributed representation of fuzzy rules and its application to pattern classification. Fuzzy Sets Syst. 1992, 52, 21–32. [Google Scholar] [CrossRef]
- Chi, Z.; Yan, H.; Pham, T. Fuzzy Algorithms with Applications to Image Processing and Pattern Recognition; World Scientific: Singapore, 1996. [Google Scholar]
- Ray, K.S.; Ghoshal, J. Approximate reasoning approach to pattern recognition. Fuzzy Sets Syst. 1996, 77, 125–150. [Google Scholar] [CrossRef]
- Beliakov, G.; Pradera, A.; Calvo, T. Aggregation Functions: A Guide for Practitioners. What is an aggregation function; Studies in Fuzziness and Soft Computing; Springer: San Mateo, CA, USA, 2007; pp. 1–37. [Google Scholar]
- Calvo, T.; Kolesarova, A.; Komornikova, M.; Mesiar, R. Aggregation Operators New Trends and Applications: Aggregation Operators: Properties, Classes and Construction Methods; Physica-Verlag: Heidelberg, Germany, 2002; pp. 3–104. [Google Scholar]
- Choquet, G. Theory of capacities. Ann. I’Inst. Fourier 1953, 5, 131–295. [Google Scholar] [CrossRef]
- Klement, E.P.; Mesiar, R. Discrete integrals and axiomatically defined functionals. Axioms 2012, 1, 9–20. [Google Scholar] [CrossRef]
- Sugeno, M. Theory of Fuzzy Integrals and It’s Applications. Ph.D. Thesis, Tokyo Institute of Techonology, Tokyo, Japan, 1974. [Google Scholar]
- Holland, J.H. Genetic algorithms. Sci. Am. 1992, 267, 66–72. [Google Scholar] [CrossRef]
- Alcalá-Fdez, J.; Sánchez, L.; García, S.; del Jesus, M.J.; Ventura, S.; Garrell, J.; Otero, J.; Romero, C.; Bacardit, J.; Rivas, V.; et al. KEEL: A software tool to assess evolutionary algorithms for data mining problems. Soft Comput. 2009, 13, 307–318. [Google Scholar] [CrossRef]
- Alcalá-Fdez, J.; Fernández, A.; Luengo, J.; Derrac, J.; García, S.; Sánchez, L.; Herrera, F. KEEL data-mining software tool: Data set repository, integration of algorithms and experimental analysis framework. J. Mult.-Valued Logic Soft Comput. 2011, 17, 255–287. [Google Scholar]
- Demšar, J. Statistical comparisons of classifiers over multiple data sets. J. Mach. Learn. Res. 2006, 7, 1–30. [Google Scholar]
- García, S.; Fernández, A.; Luengo, J.; Herrera, F. Advanced nonparametric tests for multiple comparisons in the design of experiments in computational intelligence and data mining: Experimental analysis of power. Inf. Sci. 2010, 180, 2044–2064. [Google Scholar] [CrossRef]
- Zadeh, L.A. Fuzzy sets. Inf. Control 1965, 8, 338–353. [Google Scholar] [CrossRef]
- Ishibuchi, H.; Nakashima, T. Effect of rule weights in fuzzy rule-based classification systems. IEEE Trans. Fuzzy Syst. 2001, 9, 506–515. [Google Scholar] [CrossRef]
- Cordón, O.; del Jesus, M.J.; Herrera, F. A proposal on reasoning methods in fuzzy rule-based classification systems. Int. J. Approx. Reason. 1999, 20, 21–45. [Google Scholar] [CrossRef]
- Wang, L.X.; Mendel, J.M. Generating fuzzy rules by learning from examples. IEEE Trans. Syst. Man Cybern. 1992, 25, 353–361. [Google Scholar] [CrossRef]
- Ishibuchi, H.; Yamamoto, T. Rule weight specification in fuzzy rule-based classification systems. IEEE Trans. Fuzzy Syst. 2005, 13, 428–435. [Google Scholar] [CrossRef]
- Eshelman, L. The CHC Adaptive Search Algorithm: How to Have Safe Search When Engaging in Nontraditional Genetic Recombination. In Foundations of Genetic Algorithms; Morgan Kaufman: San Francisco, CA, USA, 1991; pp. 265–283. [Google Scholar]
- Herrera, F.; Lozano, M.; Sánchez, A.M. A taxonomy for the crossover operator for real-coded genetic algorithms: An experimental study. Int. J. Intell. Syst. 2003, 18, 309–338. [Google Scholar] [CrossRef]
- Galar, M.; Fernandez, A.; Barrenechea, E.; Bustince, H.; Herrera, F. A review on ensembles for the class imbalance problem: Bagging-, boosting-, and hybrid-based approaches. IEEE Trans. Syst. Man Cybern. Part C: Appl. Rev. 2012, 42, 463–484. [Google Scholar] [CrossRef]
- Galar, M.; Fernndez, A.; Barrenechea, E.; Bustince, H.; Herrera, F. An overview of ensemble methods for binary classifiers in multi-class problems: Experimental study on one-vs-one and one-vs-all schemes. Pattern Recognit. 2011, 44, 1761–1776. [Google Scholar] [CrossRef]
- Bardossy, A.; Duckstein, L. Fuzzy Rule-Based Modeling with Applications to Geophysical, Biological, and Engineering Systems; CRC Press: Boca Raton, FL, USA, 1995. [Google Scholar]
- Sanz, J.; Fernandez, A.; Bustince, H.; Herrera, F. Improving the performance of fuzzy rule-based classification systems with interval-valued fuzzy sets and genetic amplitude tuning. Inf. Sci. 2010, 180, 3674–3685. [Google Scholar] [CrossRef]
- García, S.; Fernández, A.; Luengo, J.; Herrera, F. A study of statistical techniques and performance measures for genetics-based machine learning: Accuracy and interpretability. Soft Comput. 2009, 13, 959–977. [Google Scholar] [CrossRef]
- Sheskin, D. Handbook of Parametric and Nonparametric Statistical Procedures, 2nd ed.; Chapman & Hall/CRC: Boca Raton, FL, USA, 2006. [Google Scholar]
- Hodges, J.L.; Lehmann, E.L. Ranks methods for combination of independent experiments in analysis of variance. Ann. Math. Stat. 1962, 33, 482–497. [Google Scholar] [CrossRef]
- Holm, S. A simple sequentially rejective multiple test procedure. Scand. J. Stat. 1979, 6, 65–70. [Google Scholar]
- García, S.; Herrera, F. An extension on “statistical comparisons of classifiers over multiple data sets” for all pairwise comparisons. J. Mach. Learn. Res. 2008, 9, 2677–2694. [Google Scholar]
© 2013 by the authors; licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution license (http://creativecommons.org/licenses/by/3.0/).
Share and Cite
Barrenechea, E.; Bustince, H.; Fernandez, J.; Paternain, D.; Sanz, J.A. Using the Choquet Integral in the Fuzzy Reasoning Method of Fuzzy Rule-Based Classification Systems. Axioms 2013, 2, 208-223. https://doi.org/10.3390/axioms2020208
Barrenechea E, Bustince H, Fernandez J, Paternain D, Sanz JA. Using the Choquet Integral in the Fuzzy Reasoning Method of Fuzzy Rule-Based Classification Systems. Axioms. 2013; 2(2):208-223. https://doi.org/10.3390/axioms2020208
Chicago/Turabian StyleBarrenechea, Edurne, Humberto Bustince, Javier Fernandez, Daniel Paternain, and José Antonio Sanz. 2013. "Using the Choquet Integral in the Fuzzy Reasoning Method of Fuzzy Rule-Based Classification Systems" Axioms 2, no. 2: 208-223. https://doi.org/10.3390/axioms2020208