
Longitudinal Data Analysis Based on Bayesian Semiparametric Method

 ,
,
Abstract
:1. Introduction
2. Theoretical Basis
2.1. A General Linear Hybrid Model Containing an AR Structure
2.2. The Principle for Bayesian Inference
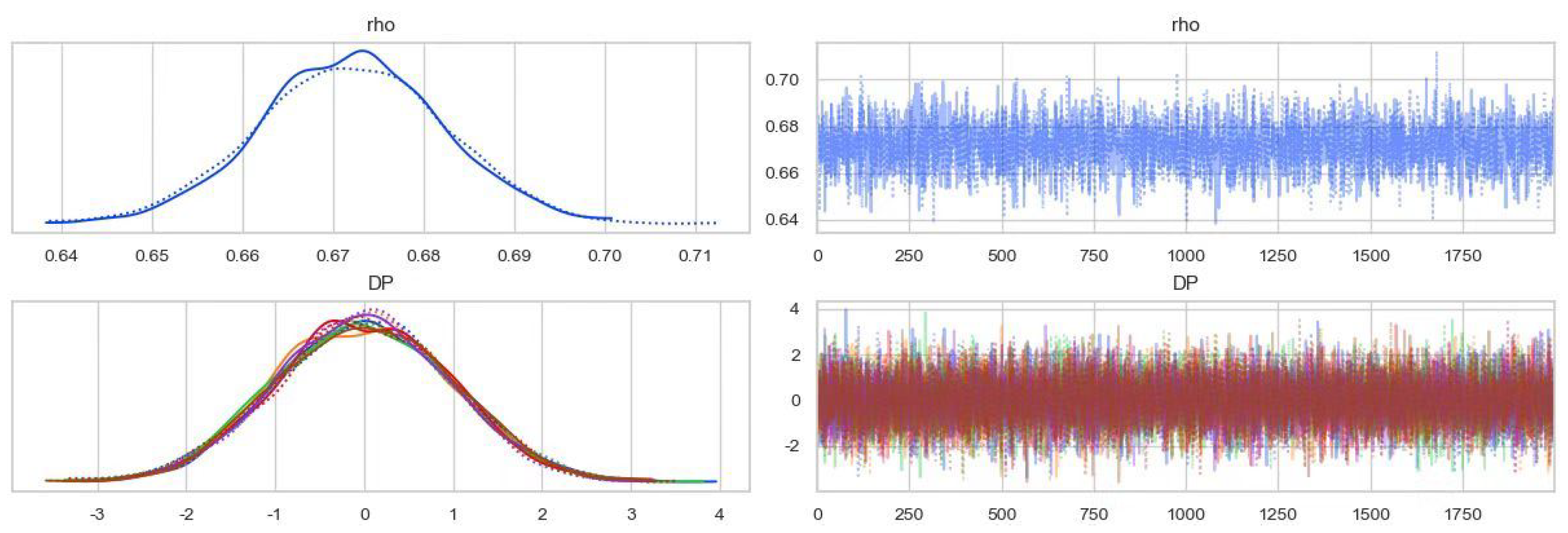
2.3. The MCMC Sampling and Its Convergence
3. The OU Process
4. Dirichlet Process and Dirichlet Process Mixture
4.1. Dirichlet Process
4.2. Dirichlet Process Mixture
5. Formulation of the Semiparametric Autoregressive Model
5.1. The Partial Dirichlet Process Mixture of Stochastic Process
5.2. The Framework of a Hierarchical Model
6. The Marginal Likelihood, Prior Determination, and Posteriori Inference
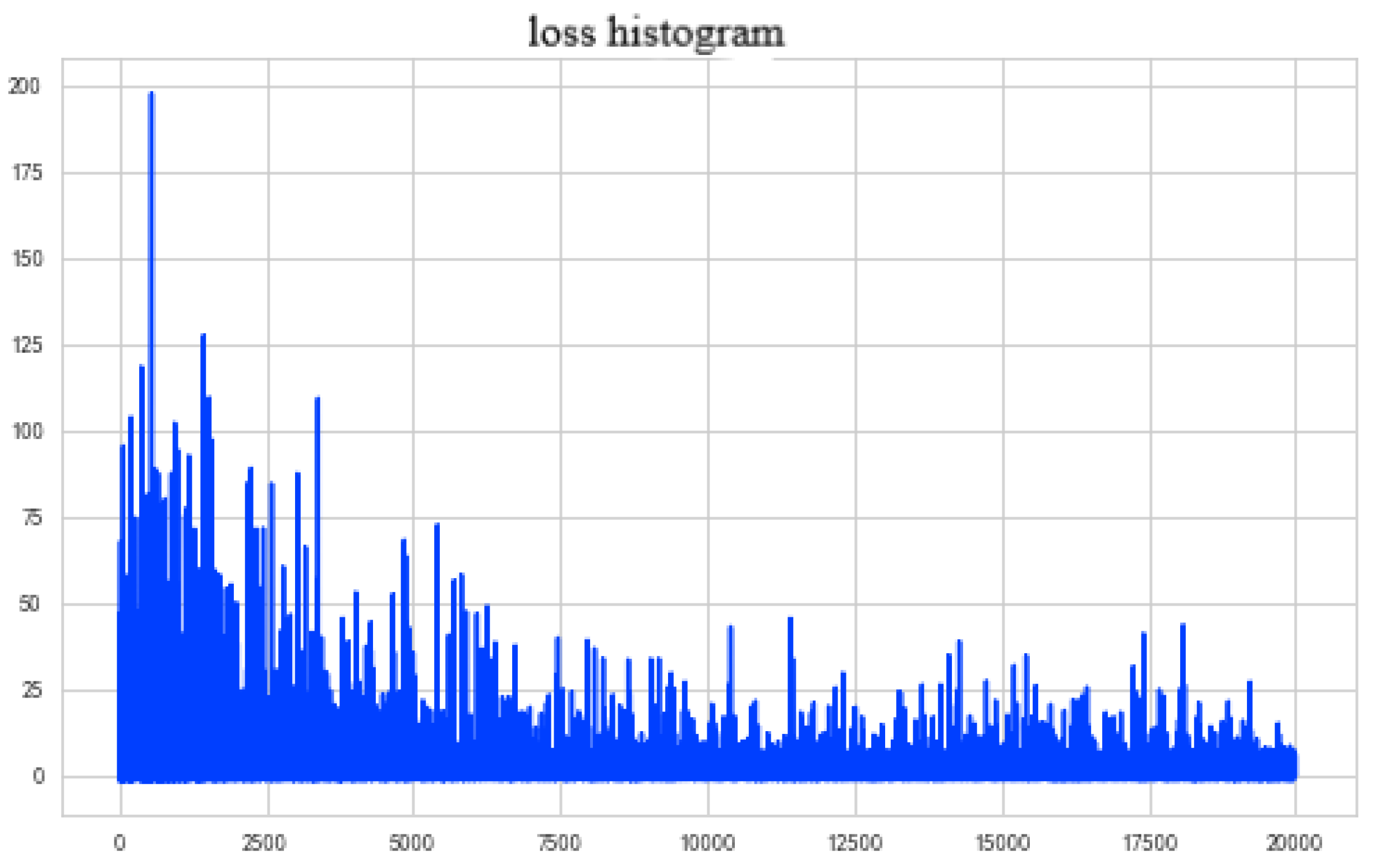
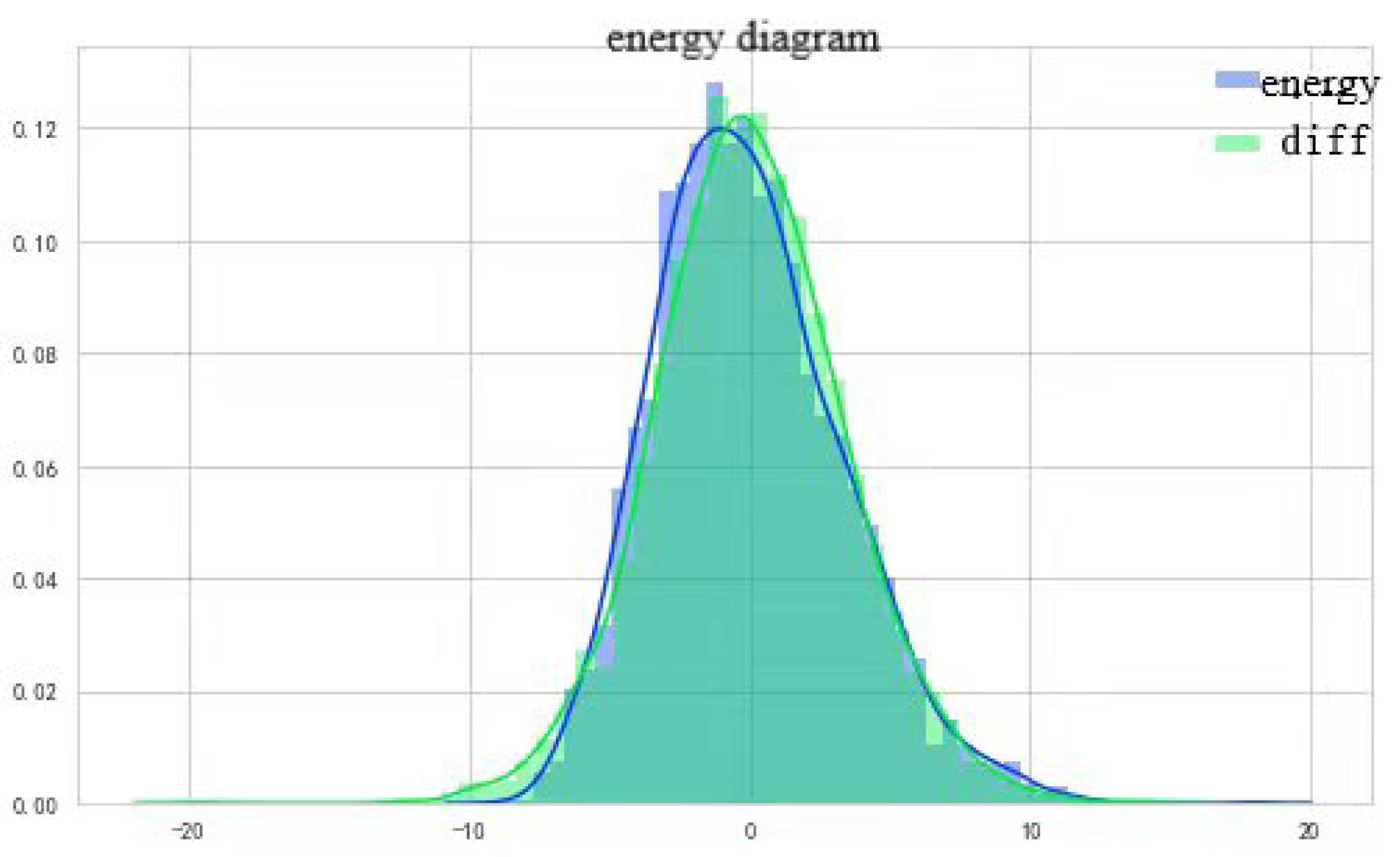
7. A Monte Carlo Study
7.1. Simulation Design
7.2. Simulation Specification and Display of Empirical Results
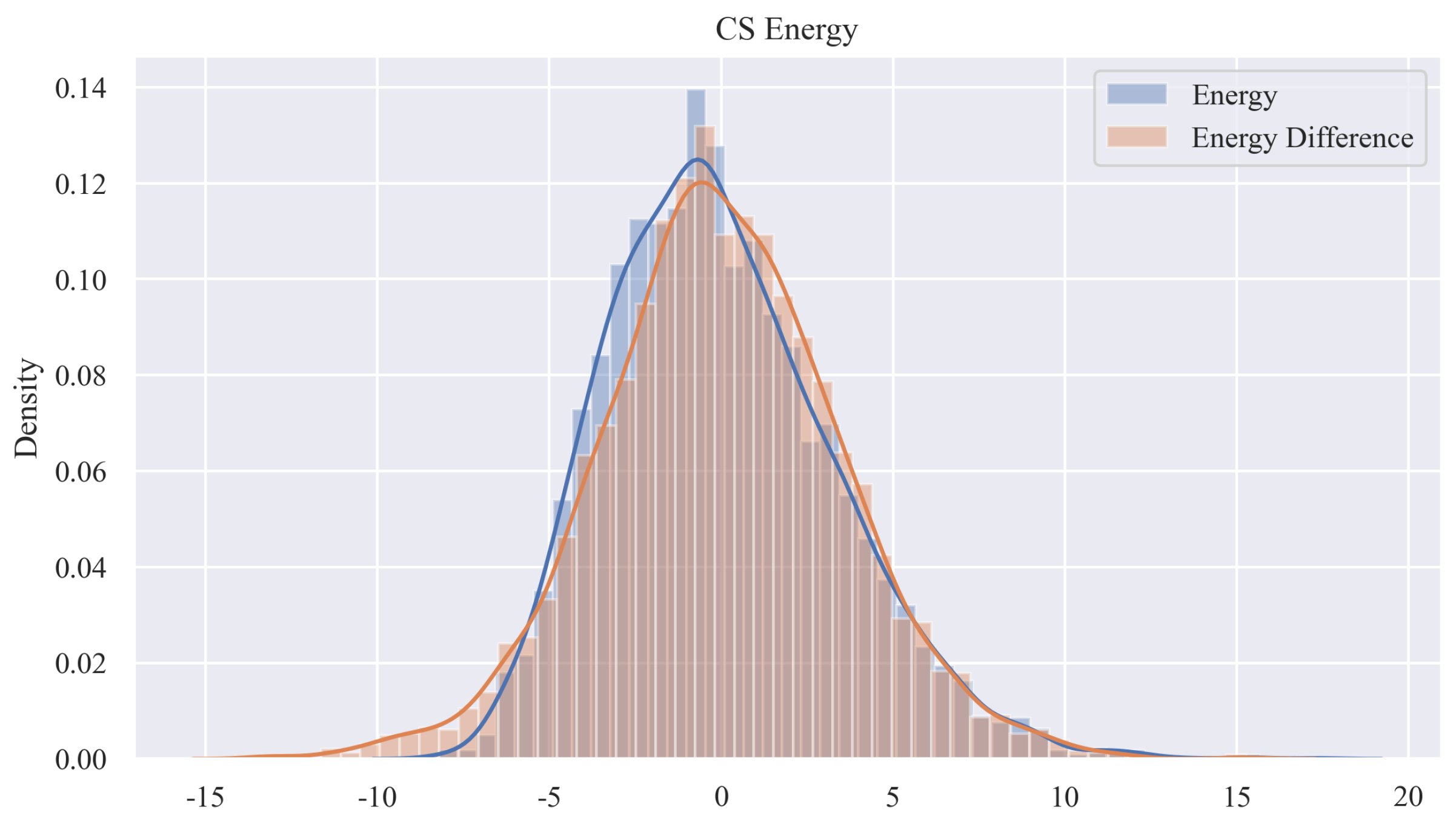
7.3. Analysis of a Real Wind Speed Dataset
8. Concluding Remarks
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
Appendix A. Derivations of Conditional Probability Distributions in Section 7.1
References
- Pullenayegum, E.M.; Lim, L.S. Longitudinal data subject to irregular observation: A review of methods with a focus on visit processes, assumptions, and study design. Statist. Methods Med. Res. 2016, 25, 2992–3014. [Google Scholar] [CrossRef] [PubMed]
- Chakraborty, R.; Banerjee, M.; Vemuri, B.C. Statistics on the space of trajectories for longitudinal data analysis. In Proceedings of the 2017 IEEE 14th International Symposium on Biomedical Imaging (ISBI 2017), Melbourne, VIC, Australia, 18–21 April 2017; pp. 999–1002. [Google Scholar]
- Xiang, D.; Qiu, P.; Pu, X. Nonparametric regession analysis of multivariate longitudinal data. Stat. Sin. 2013, 23, 769–789. [Google Scholar]
- Quintana, F.A.; Johnson, W.O.; Waetjen, L.E.; BGold, E. Bayesian nonparametric longitudinal data analysis. J. Am. Statist. Assoc. 2016, 111, 1168–1181. [Google Scholar] [CrossRef]
- Cheng, L.; Ramchandran, S.; Vatanen, T.; Lietzén, N.; Lahesmaa, R.; Vehtari, A.; Lähdesmäki, H. An additive Gaussian process regression model for interpretable non-parametric analysis of longitudinal data. Nat. Commun. 2019, 10, 1798. [Google Scholar] [CrossRef]
- Kleinman, K.P.; Ibrahim, J.G. A semiparametric Bayesian approach to the random effects model. Biometrics 1998, 54, 921–938. [Google Scholar] [CrossRef] [PubMed]
- Gao, F.; Zeng, D.; Couper, D.; Lin, D.Y. Semiparametric regression analysis of multiple right- and interval-censored events. J. Am. Statist. Assoc. 2019, 114, 1232–1240. [Google Scholar] [CrossRef] [PubMed]
- Lee, Y. Semiparametric regression. J. Am. Statist. Assoc. 2006, 101, 1722–1723. [Google Scholar] [CrossRef]
- Sun, Y.; Sun, L.; Zhou, J. Profile local linear estimation of generalized semiparametric regression model for longitudinal data. Lifetime Data Anal. 2013, 19, 317–349. [Google Scholar] [CrossRef] [PubMed]
- Zeger, S.L.; Diggle, P.J. Semiparametric models for longitudinal data with application to CD4 cell numbers in HIV seroconverters. Biometrics 1994, 50, 689–699. [Google Scholar] [CrossRef] [PubMed]
- Li, Y.; Lin, X.; Müller, P. Bayesian inference in semiparametric mixed models for longitudinal data. Biometrics 2010, 66, 70–78. [Google Scholar] [CrossRef] [PubMed]
- Hunag, Y.X. Quantile regression-based Bayesian semiparametric mixed-effects models for longitudinal data with non-normal, missing and mismeasured covariate. J. Statist. Comput. Simul. 2016, 86, 1183–1202. [Google Scholar] [CrossRef]
- Li, J.; Zhou, J.; Zhang, B.; Li, X.R. Estimation of high dimensional covariance matrices by shrinkage algorithms. In Proceedings of the 2017 20th International Conference on Information Fusion (Fusion), Xi’an, China, 10–13 July 2017; pp. 955–962. [Google Scholar]
- Doss, H.; Park, Y. An MCMC approach to empirical Bayes inference and Bayesian sensitivity analysis via empirical processes. Ann. Statist. 2018, 46, 1630–1663. [Google Scholar] [CrossRef]
- Neal, R.M. Markov chain sampling methods for Dirichlet process mixture models. J. Comput. Graph. Statist. 2000, 9, 249–265. [Google Scholar]
- Kingma, D.P.; Welling, M. Auto-encoding variational Bayes. In Proceedings of the International Conference on Learning Representations (ICLR), Banff, AB, Canada, 14–16 April 2014. [Google Scholar]
- Csiszar, I. I-Divergence geometry of probability distributions and minimization problems. Ann. Probab. 1975, 3, 146–158. [Google Scholar] [CrossRef]
- Rasmussen, C.E.; Williams, C.K.I. Gaussian Processes for Machine Learning; MIT Press: Cambridge, MA, USA, 2006; pp. 63–71. [Google Scholar]
- Barndorff-Nielsen, O.E.; Shephard, N. Non-Gaussian Ornstein–Uhlenbeck-based models and some of their uses in financial economics. J. Roy. Statist. Soc. (Ser. B) 2001, 63, 167–241. [Google Scholar] [CrossRef]
- Griffin, J.E.; Steel, M.F.J. Order-based dependent Dirichlet processes. J. Am. Statist. Assoc. 2006, 101, 179–194. [Google Scholar] [CrossRef]
- Mukhopadhyay, S.; Gelfand, A.E. Dirichlet process mixed generalized linear models. J. Am. Statist. Assoc. 1997, 92, 633–639. [Google Scholar] [CrossRef]
- Zimmerman, D.L.; Núñez-Antón, V.A. Antedependence Models for Longitudinal Data; CRC Press: Boca Raton, FL, USA, 2009. [Google Scholar]
- Hsu, C.W.; Sinay, M.S.; Hsu, J.S. Bayesian estimation of a covariance matrix with flexible prior specification. Ann. Inst. Statist. Math. 2012, 64, 319–342. [Google Scholar] [CrossRef]
- Chen, X. Longitudinal Data Analysis Based on Bayesian Semiparametric Method. Master’s Thesis, Lanzhou University, Lanzhou, China, 2019. (In Chinese). [Google Scholar]































{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
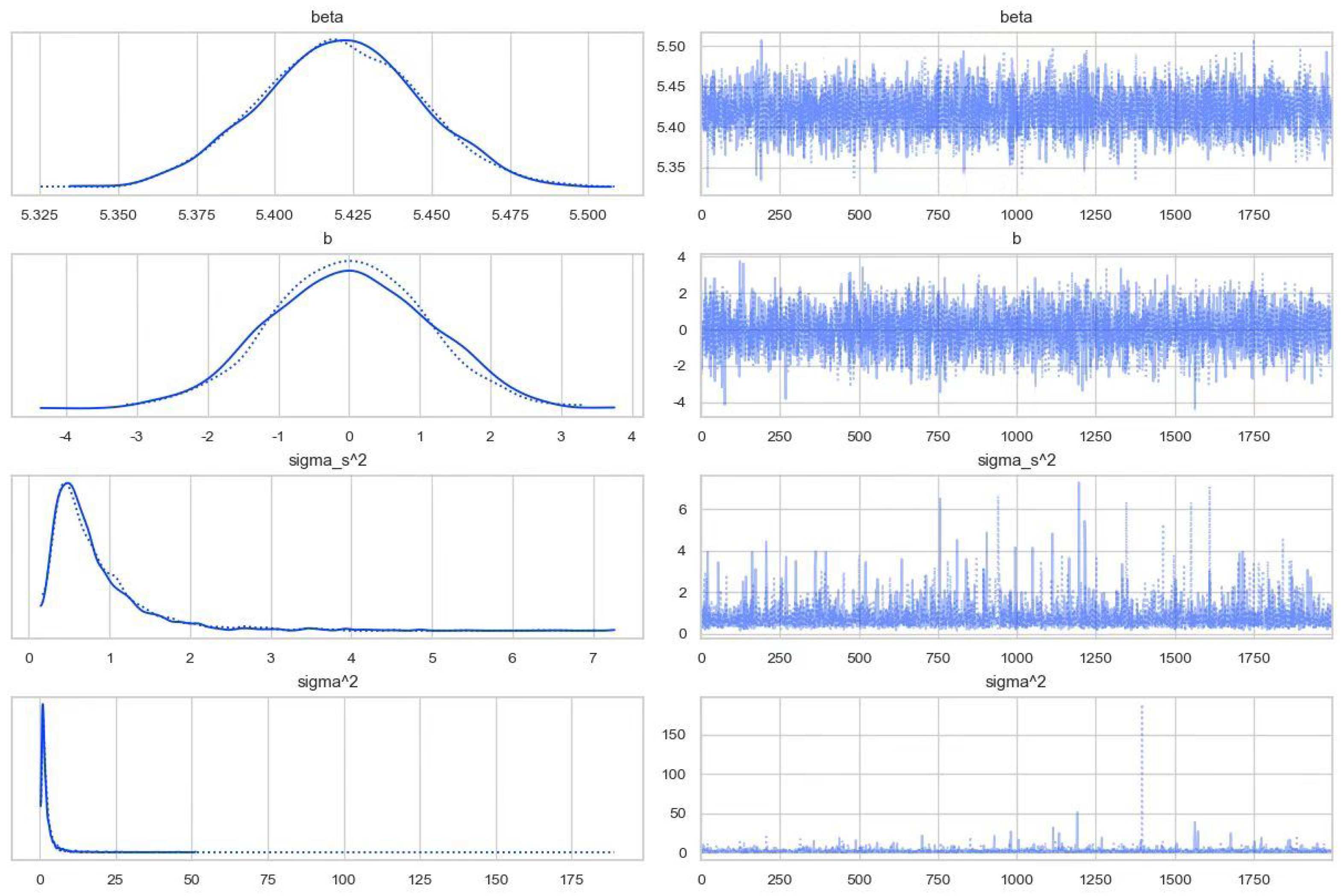{kind=link}
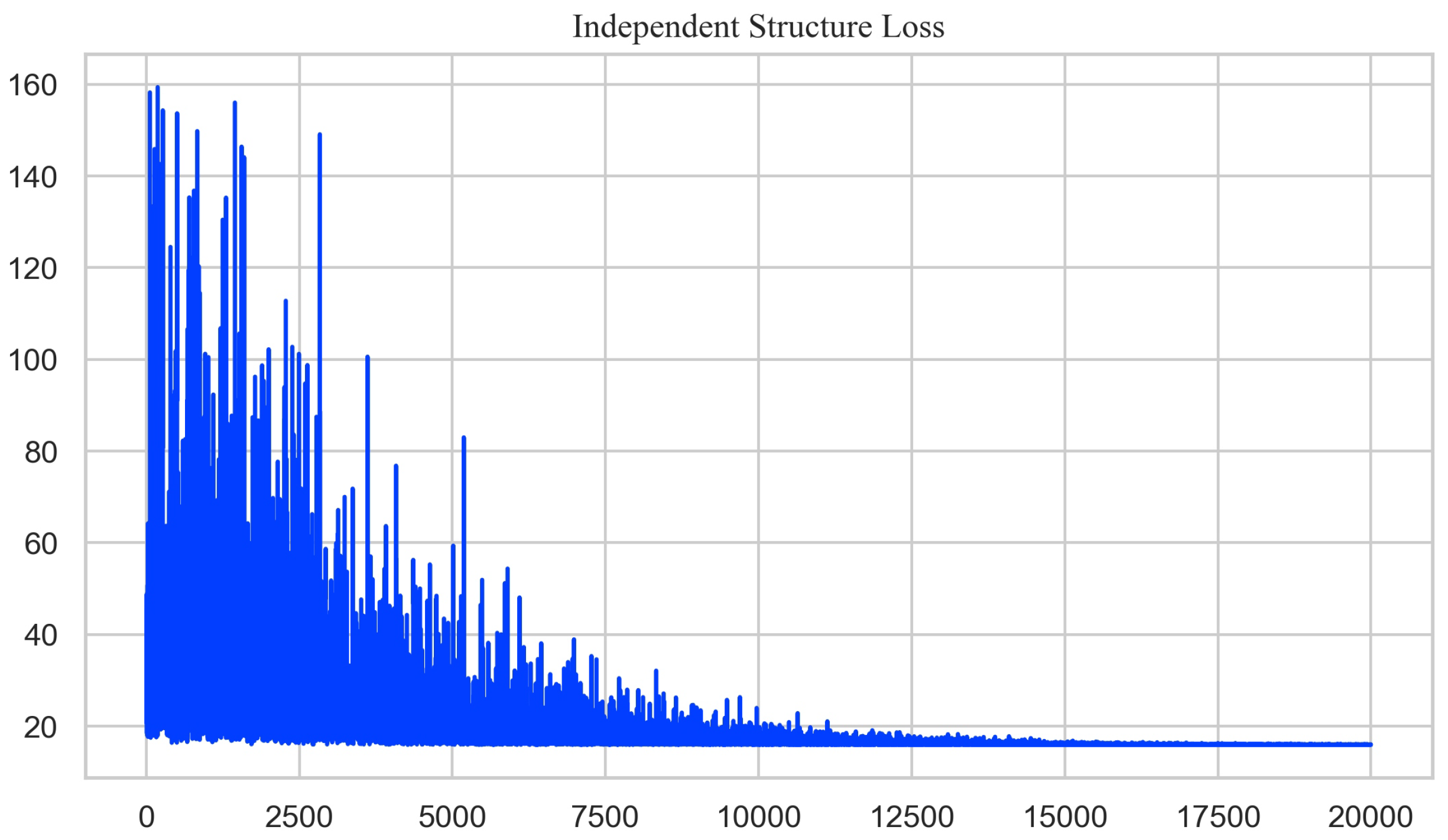{kind=link}
{kind=link}
| Observation Object | Number of Observations | ||
|---|---|---|---|
| 1 | ⋯ | ||
| 1 | ⋯ | ||
| ⋮ | ⋮ | ⋮ | |
| i | … | ||
| ⋮ | ⋮ | ⋮ | |
| n | … | ||
| Loss Function | Model | C1 | C2 | C3 | C4 |
|---|---|---|---|---|---|
| RMSE | SPAR | 0.9960 | 0.1037 | 0.8995 | 1.5358 |
| Inv-W | 2.9691 | 2.9352 | 3.4804 | 3.3285 | |
| SPAR | 0.1810 | 0.1201 | 1.3217 | 0.9558 | |
| Inv-W | 1.8389 | 1.4632 | 3.0516 | 1.2926 | |
| SPAR | 0.1289 | 0.1345 | 1.7575 | 0.6044 | |
| Inv-W | 0.2405 | 0.9576 | 2.8083 | 1.7565 |
| Loss Function | Model | C1 | C2 | C3 | C4 |
|---|---|---|---|---|---|
| RMSE | SPAR | 0.1628 | 1.1417 | 0.3775 | 0.1542 |
| Inv-W | 0.2308 | 2.4152 | 0.9115 | 0.2771 | |
| SPAR | 0.0956 | 0.5482 | 0.0631 | 1.2354 | |
| Inv-W | 0.1519 | 1.1424 | 0.1756 | 1.9137 | |
| SPAR | 0.1013 | 0.9809 | 0.4937 | 0.5854 | |
| Inv-W | 0.1238 | 1.1935 | 0.5205 | 0.6484 |
| Loss Function | Model | C1 | C2 | C3 | C4 |
|---|---|---|---|---|---|
| RMSE | SPAR | 0.0831 | 0.0962 | 0.08837 | 0.0981 |
| Inv-W | 0.4120 | 0.6826 | 0.3181 | 0.4064 | |
| SPAR | 0.1360 | 0.1996 | 0.1465 | 0.2508 | |
| Inv-W | 46.6743 | 16.8967 | 19.0260 | 14.3543 | |
| SPAR | 0.0870 | 0.0826 | 0.2084 | 0.3517 | |
| Inv-W | 661.4643 | 142.3157 | 450.6686 | 340.6994 |
| Loss Function | Model | C1 | C2 | C3 | C4 |
|---|---|---|---|---|---|
| RMSE | SPAR | 0.0187 | 0.5359 | 0.1976 | 0.1985 |
| Inv-W | 0.6585 | 0.6486 | 0.6515 | 0.7580 | |
| SPAR | 0.0066 | 0.1670 | 0.0662 | 0.1846 | |
| Inv-W | 0.0968 | 4.8245 | 0.3174 | 0.8035 | |
| SPAR | 0.0036 | 0.0132 | 0.0080 | 0.0939 | |
| Inv-W | 0.0079 | 1.3683 | 0.1202 | 0.3488 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Jiao, G.; Liang, J.; Wang, F.; Chen, X.; Chen, S.; Li, H.; Jin, J.; Cai, J.; Zhang, F. Longitudinal Data Analysis Based on Bayesian Semiparametric Method. Axioms 2023, 12, 431. https://doi.org/10.3390/axioms12050431
Jiao G, Liang J, Wang F, Chen X, Chen S, Li H, Jin J, Cai J, Zhang F. Longitudinal Data Analysis Based on Bayesian Semiparametric Method. Axioms. 2023; 12(5):431. https://doi.org/10.3390/axioms12050431
Chicago/Turabian StyleJiao, Guimei, Jiajuan Liang, Fanjuan Wang, Xiaoli Chen, Shaokang Chen, Hao Li, Jing Jin, Jiali Cai, and Fangjie Zhang. 2023. "Longitudinal Data Analysis Based on Bayesian Semiparametric Method" Axioms 12, no. 5: 431. https://doi.org/10.3390/axioms12050431