This section presents an analysis of two useful applications from the engineering and marketing fields to highlight the usefulness of the proposed estimation methods and the possibility of adapting study objectives to real practice.
5.1. Airborne Communication Transceiver
The airborne communication transceiver is a very high frequency and ultra-high frequency transceiver designed for communication between aircraft via the built-in intercom, in addition to communication with the ground means of air traffic control. In this application, we shall use a data set, reported by Jorgensen [
26], consisting of forty observations of the active repair times (hours) for an airborne communication transceiver (ACT), see
Table 1. In the past decade, this data set has received a lot of attention from several authors; for example, see Saroj et al. [
27], Sharma et al. [
28], Ferreira et al. [
29], among others.
To explain the flexibility of the proposed model, based on the complete ACT data set, the IL distribution is compared to five other common inverted distributions (for
and
) namely; inverse exponential (IE(
)) proposed by Keller et al. [
30], inverse Weibull (IW(
)) proposed by Keller et al. [
31], inverse gamma (IG(
)) discussed by Glen [
32], inverted Nadarajah–Haghighi (INH(
)) proposed by Tahir et al. [
33] and alpha power inverted exponential (APIE(
)) proposed by Ceren et al. [
34] distributions. To determine which distribution has the best fit, different goodness-of-fit measures are considered called: negative log-likelihood (NL), Akaike (A), Bayesian (B), consistent Akaike (CA), Hannan-Quinn (HQ) and Kolmogorov–Smirnov (KS) statistic with its
p-value. To calculate the proposed criteria, the MLE with its standard error (St.E) of
or
is calculated and presented in
Table 2. It is evident, in terms of the smallest of NL, A, B, CA, HQ and KS values as well as the highest
p-value, that the IL lifetime model provides a better fit than IE, IW, IG, INH and APIE distributions. For more investigation, the IL distribution is also compared to the Lindley (L) model. It is quite evident, from
Table 2, that the IL distribution provides the best overall fit compared to L and other inverse models. Further, quantile-quantile plots of IL, IE, IW, IG, INH and APIE distributions are displayed in
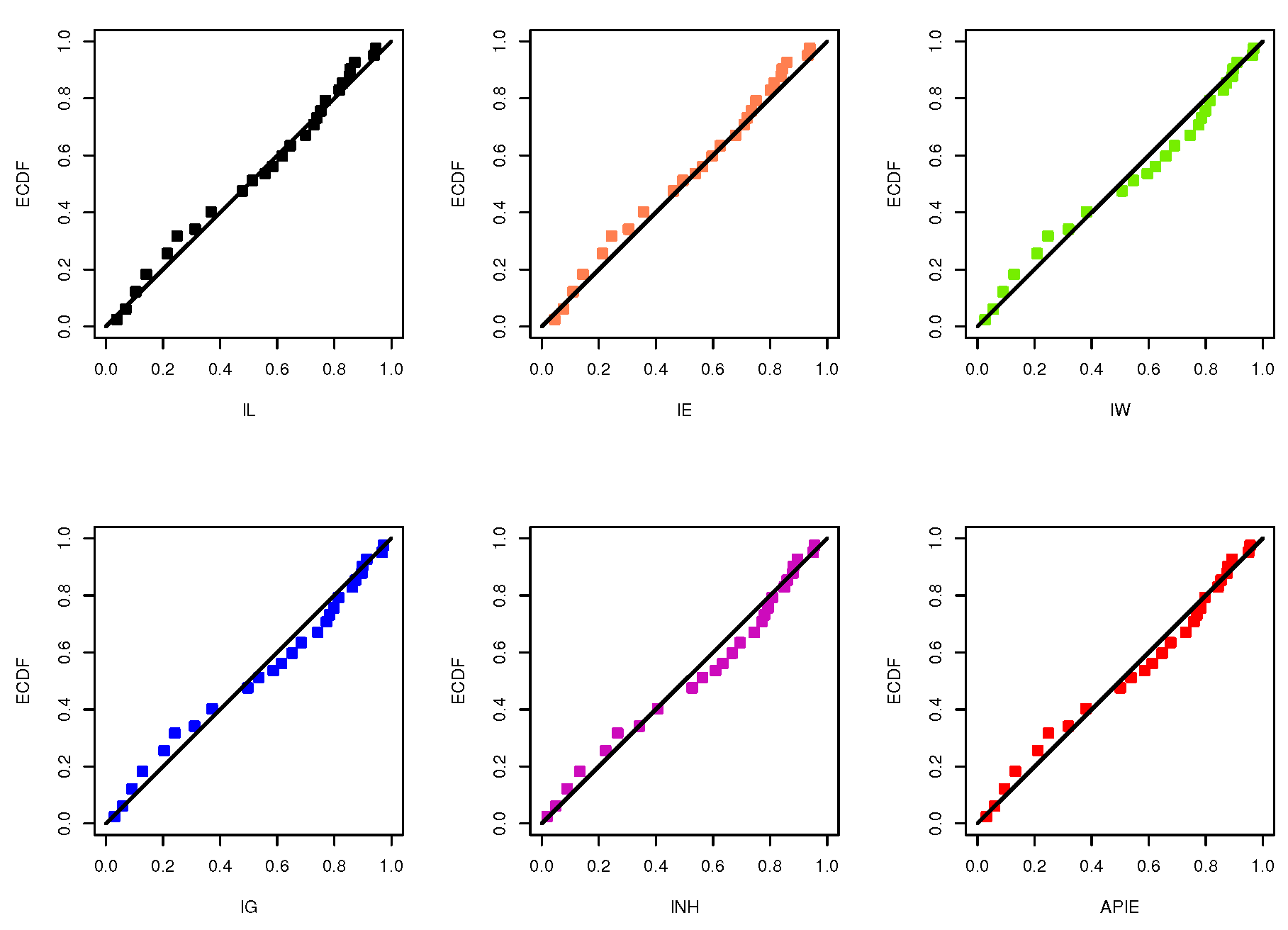
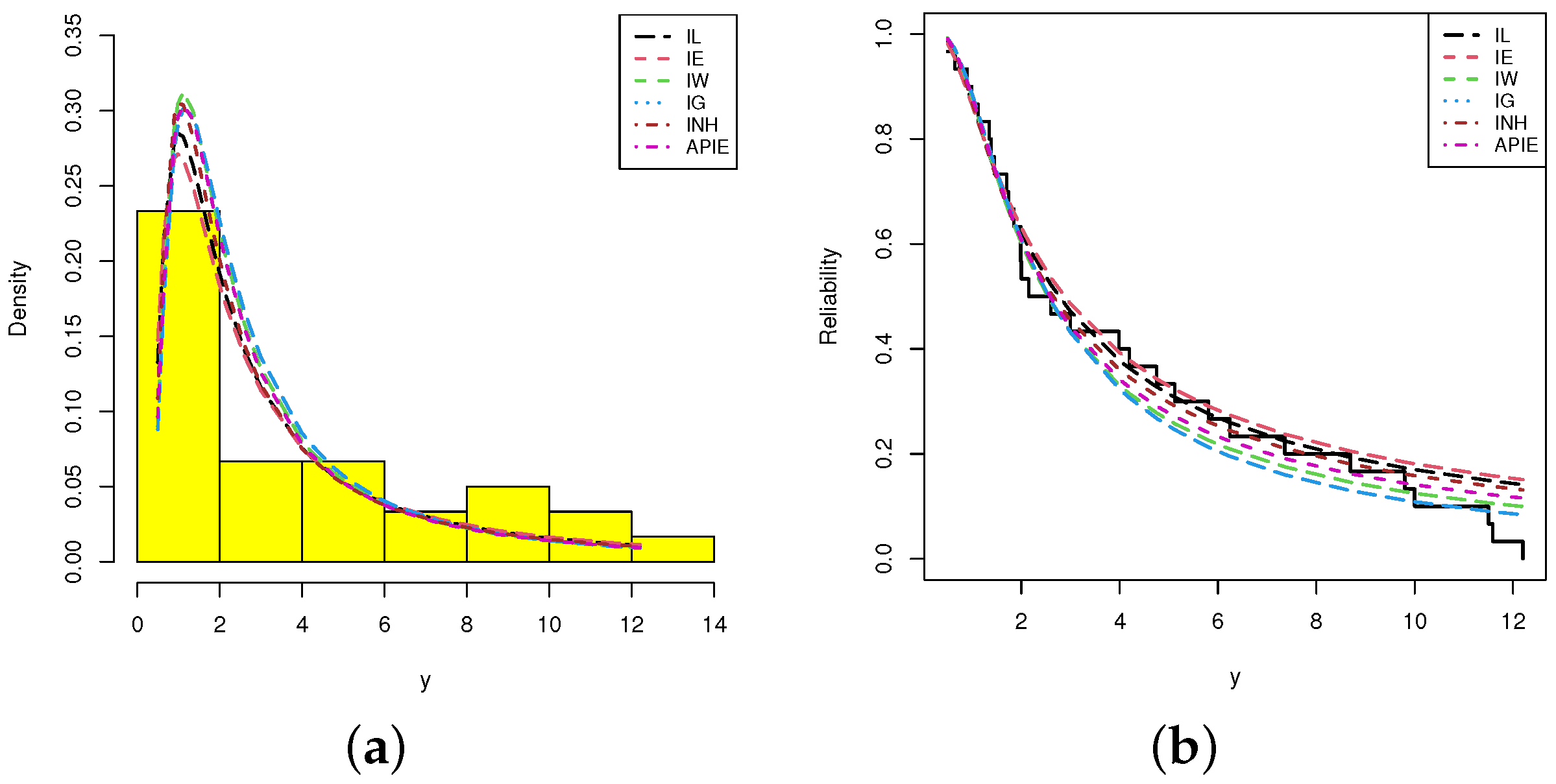
Figure 5. Furthermore,
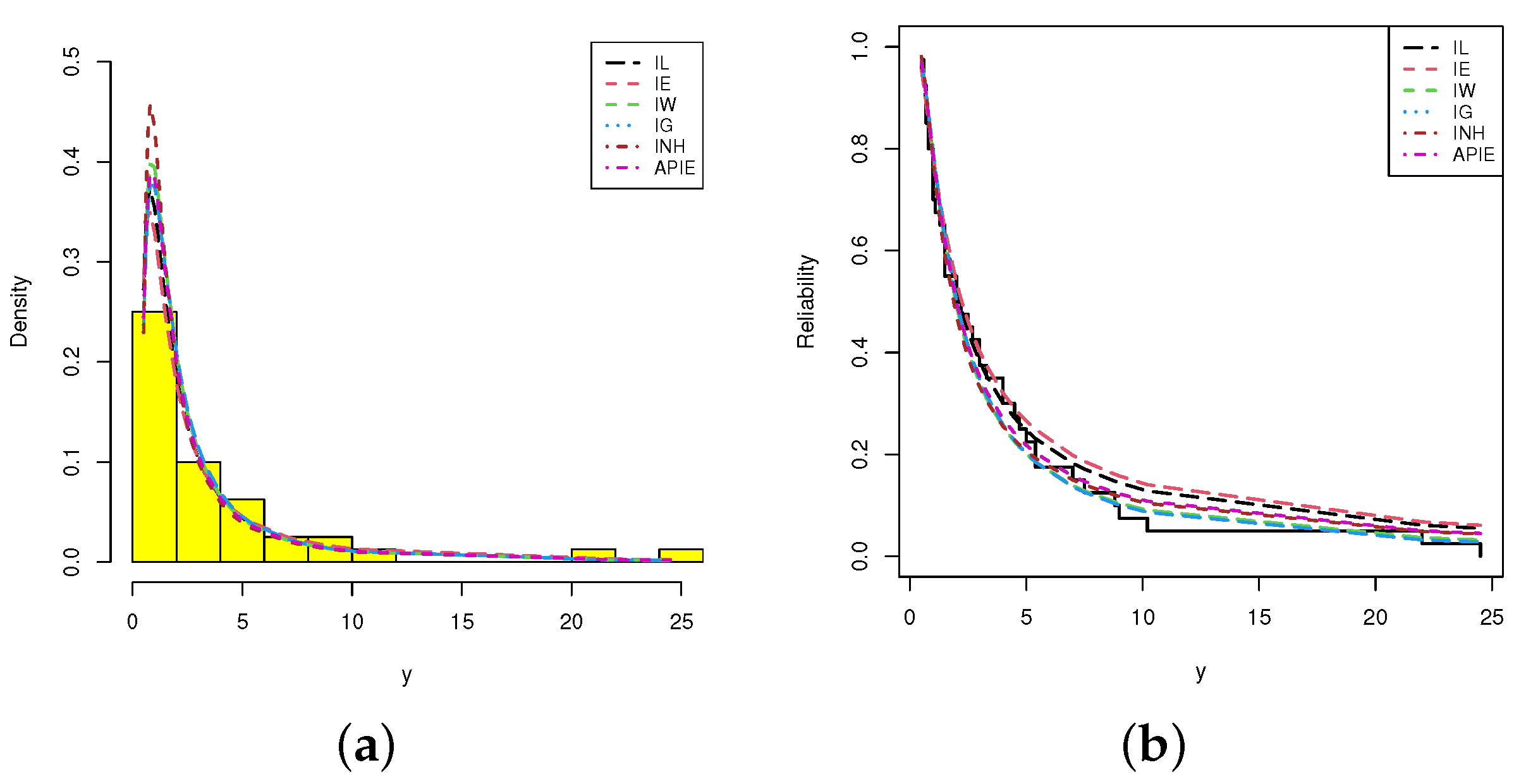
Figure 6 shows the histograms of ACT data and the lines of fitted densities as well as fitted/empirical reliability functions of IL, IE, IW, IG, INH and APIE distributions are displayed. It can be seen, from
Figure 5 and
Figure 6, that the IL distribution can be chosen as an appropriate distribution when compared to other distributions in presence of ACT data.
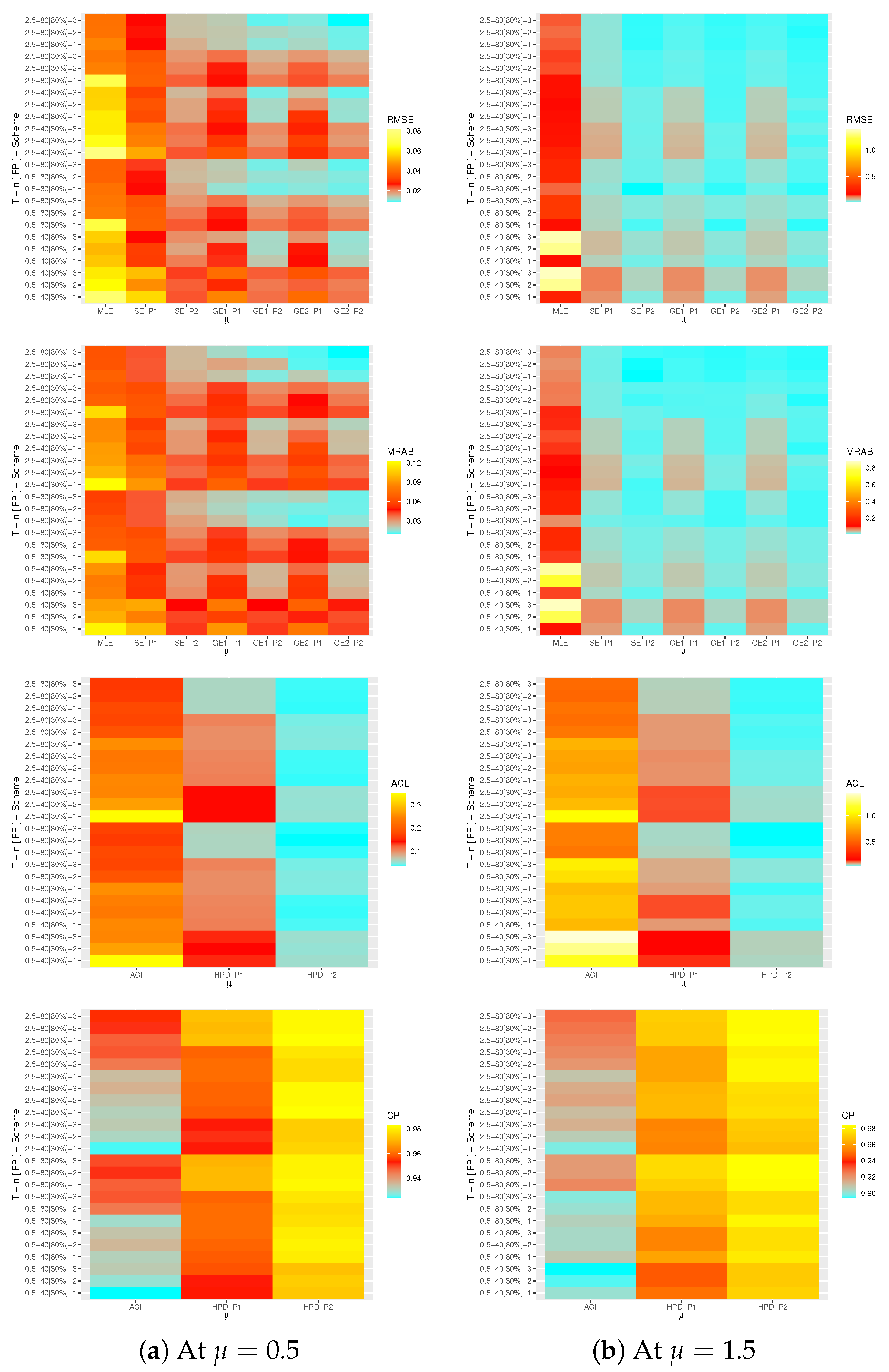
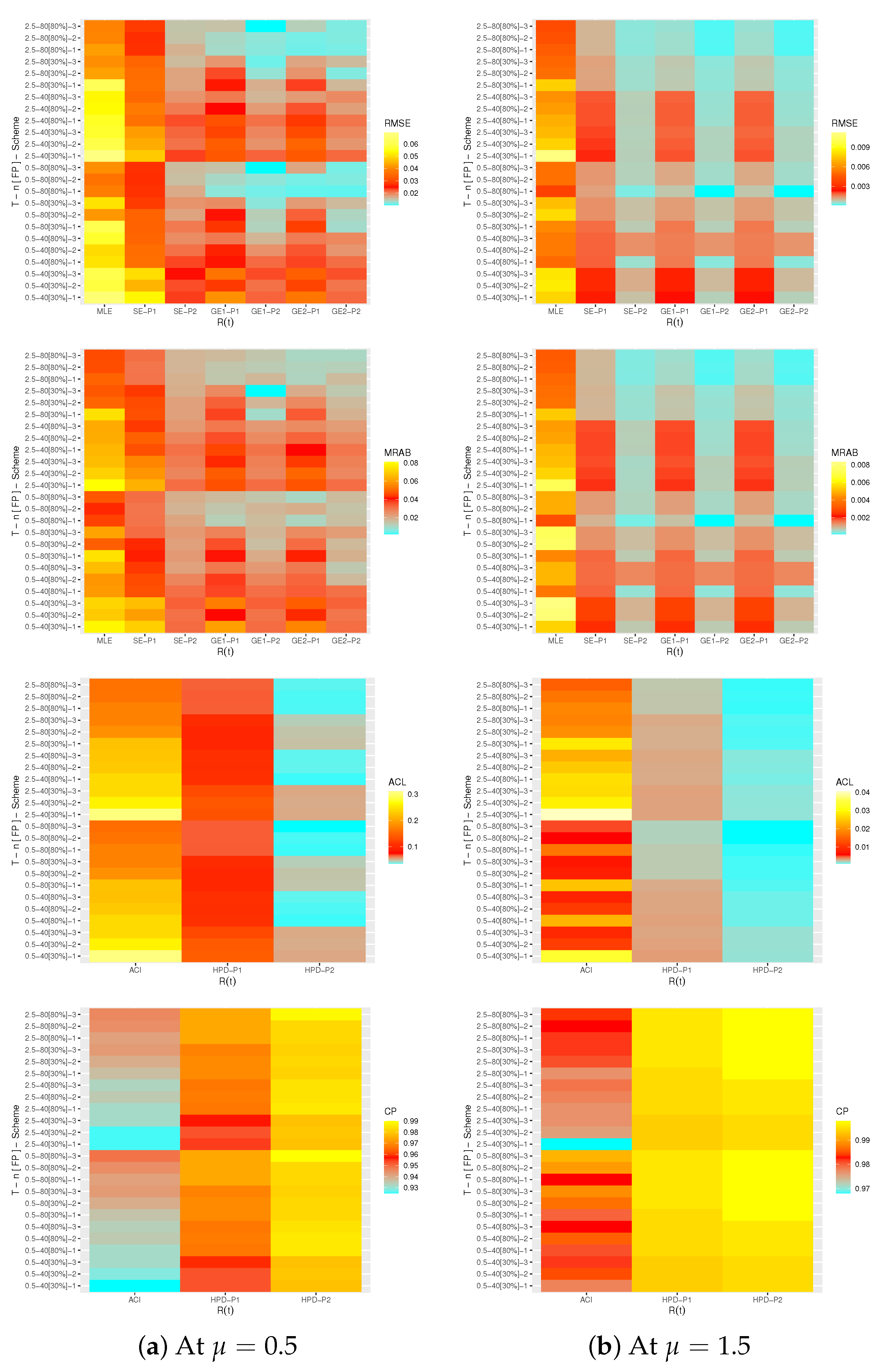
From the complete ACT data, when
, three T2-APHC samples based on different schemes are generated and reported in
Table 3. From
Table 3, the MLEs with their St.Es of
,
and
(at time
) are computed. By running the M-H algorithm 50,000 times with discarding the first 10,000 variates as burn-in, the Bayes estimates with their St.Es under SE and GE (for
) loss functions of
,
and
are calculated using the improper gamma prior. Since there is no a priori information about
from ACT data, we assume that the hyperparameters
a and
b are not available but are set to 0.001 to run computations. Also, the two bounds of the 95% ACI/HPD interval estimates with their lengths of the same parameters are also calculated. To apply the proposed MCMC sampler, the maximum likelihood estimate of
is selected as an initial guess. The point and interval estimates of
,
and
are provided in
Table 4 and
Table 5, respectively. It is clear, from
Table 4 and
Table 5, that the estimates of
,
and
obtained by the MCMC procedure perform better than others. Similar performance is also observed in the case of HPD interval estimates.
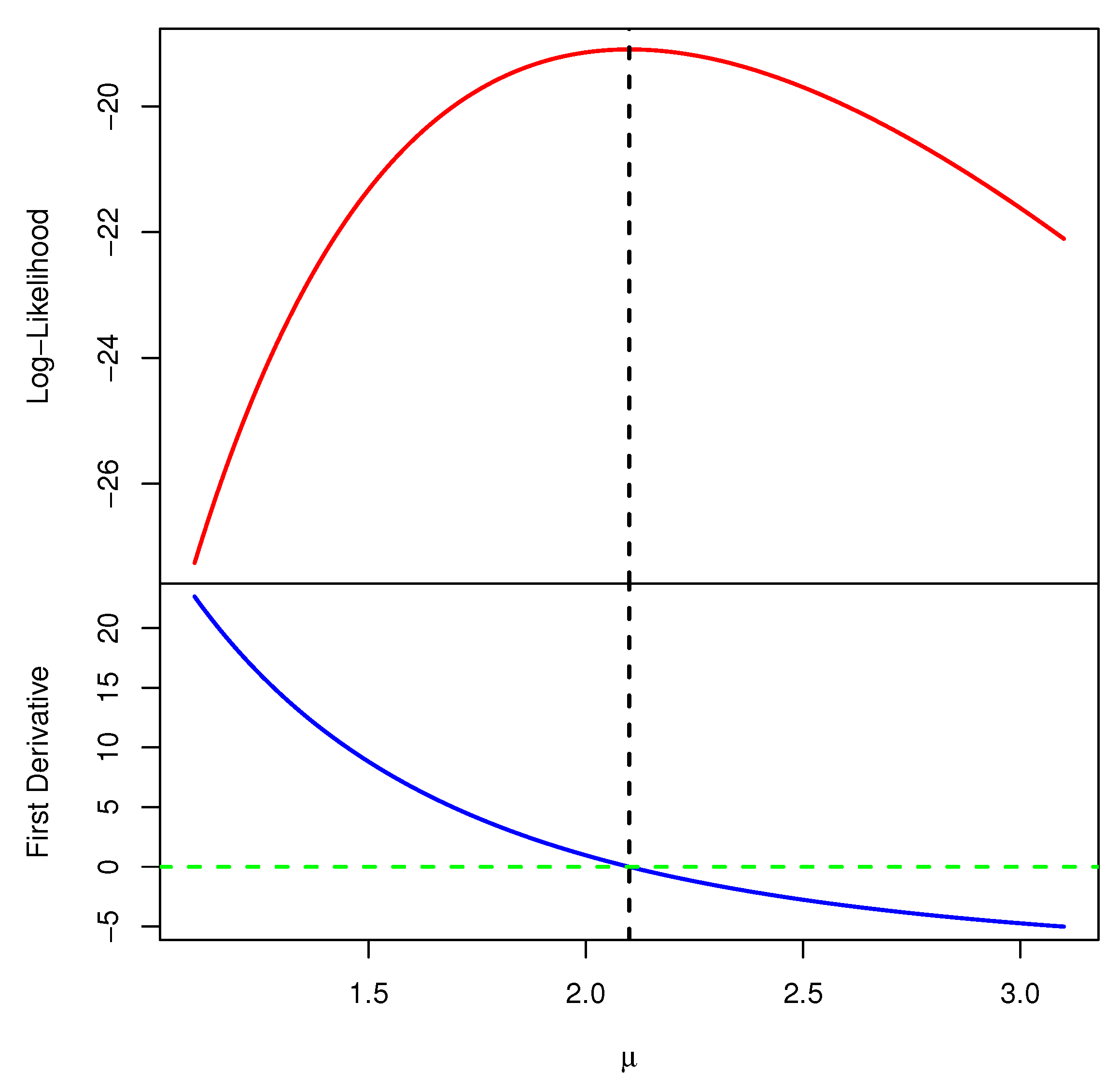
Some common characteristics for the MCMC iterations of
,
and
after burn-in, namely: mean, mode, quartiles (
), standard deviation (St.D) and skewness are computed and provided in
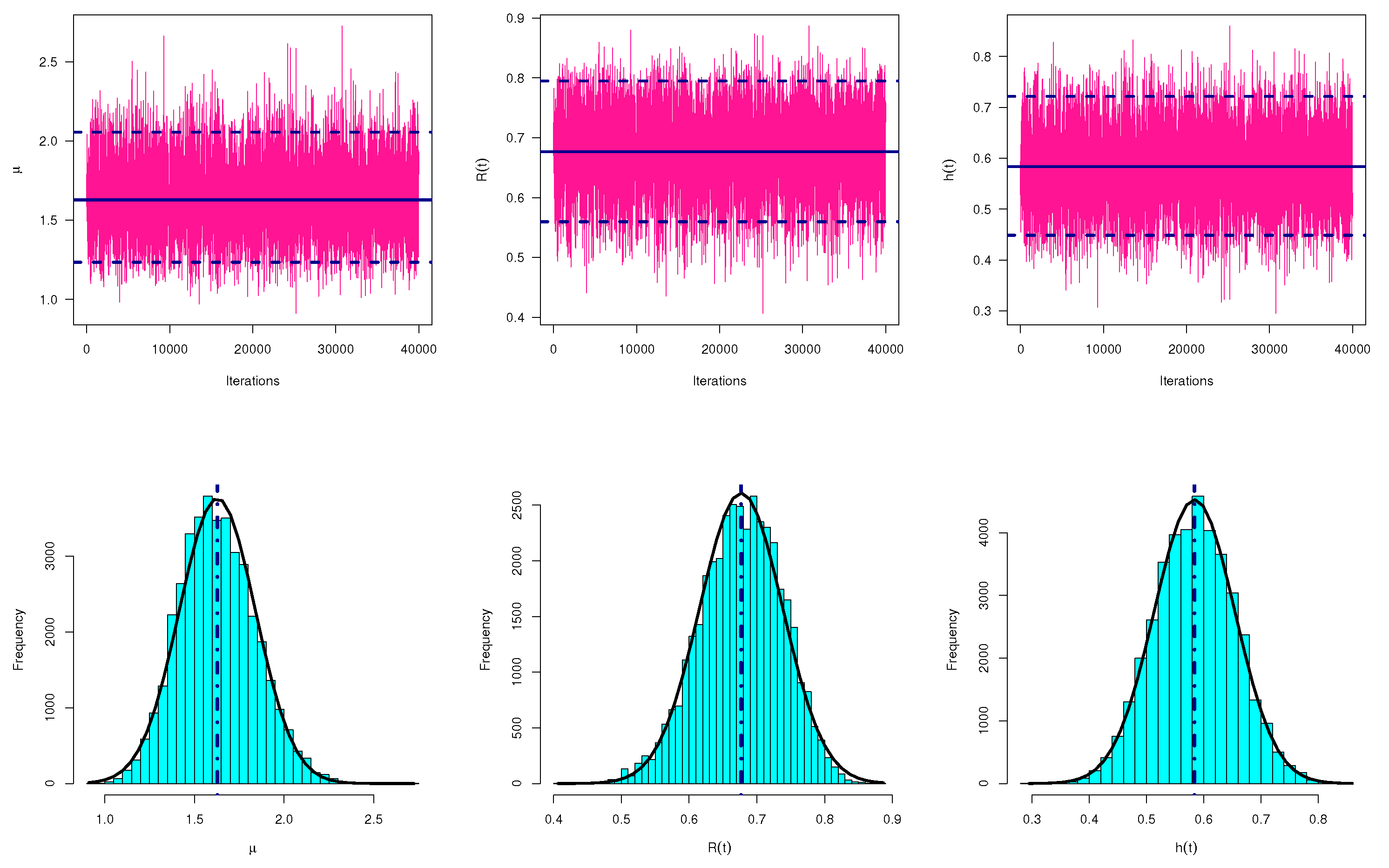
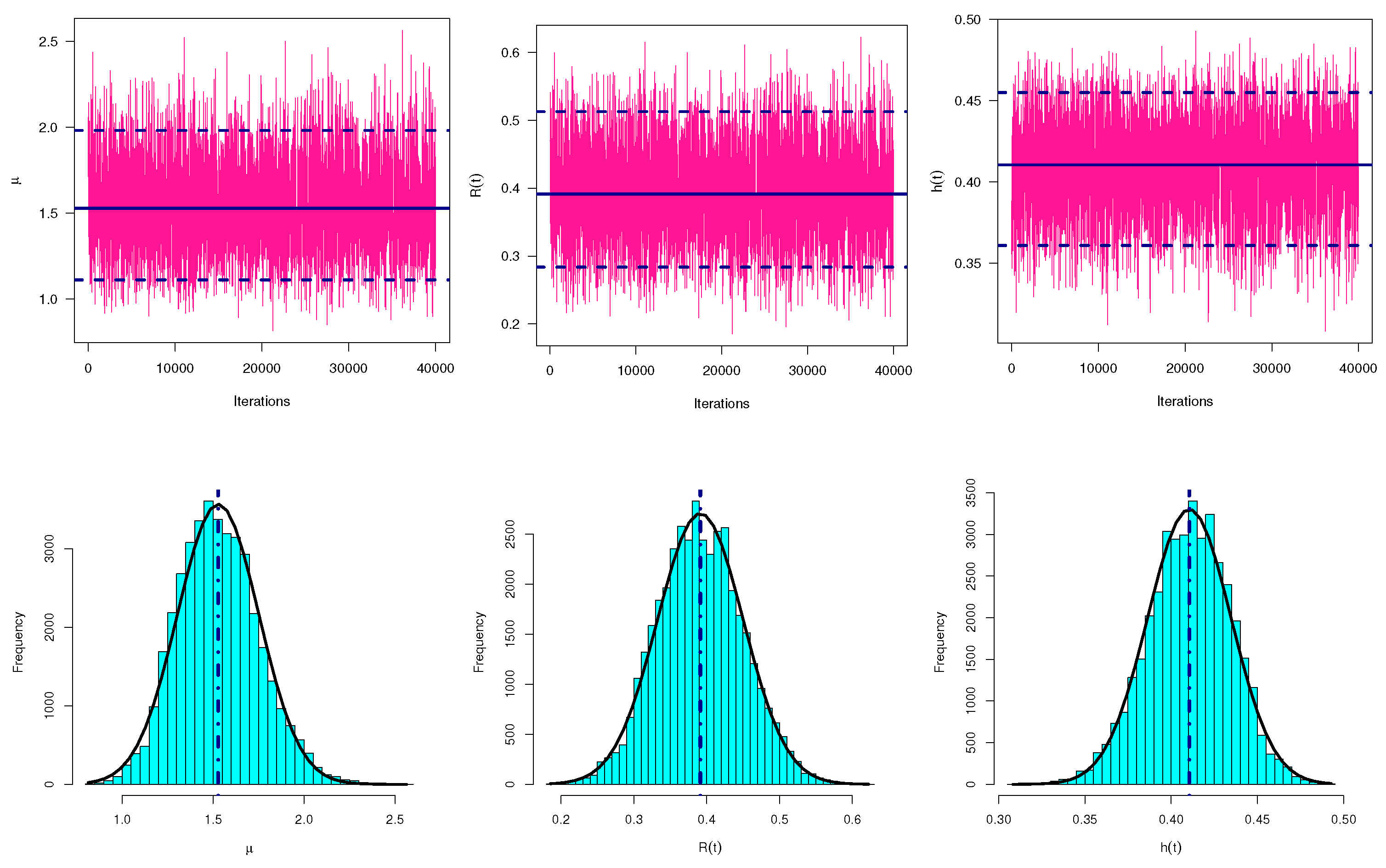
Table 6. To highlight the convergence of MCMC draws, from sample 1 (as an example), MCMC trace plots of
,
and
are displayed in
Figure 7. Additionally, using the fitted Gaussian kernel for sample 1, the histograms of MCMC variates of
,
and
are also shown in
Figure 7. For each trace plot, the sample mean is represented by a solid (—) line as well as the HPD interval bounds are represented by dashed (- - -) lines. For each histogram plot, the sample mean of each unknown parameter is represented with a vertical dotted (:) line.
Figure 7 demonstrates that the MCMC sampler converges quite well and that the burn-in sample has a sufficient size to remove the effect of the starting values. It is also noted, from
Figure 7, that the generated variates of
,
and
are positive-skewed, negative-skewed and fairly symmetrical, respectively. Other trace and histogram plots of
,
and
based on samples 2 and 3 are plotted and displayed in the
Supplementary File.
5.2. Wooden Toys
In this application, from the marketing field, both proposed frequentist and Bayesian estimators of the IL parameters are computed based on the prices of the thirty different children’s wooden toys for sale at a Suffolk craft shop in April 1991, see
Table 7. This data was originally published by The Open University and recently analyzed by Chesneau et al. [
35]. In
Table 8, the calculated values of NL, A, B, CA, HQ and KS(
p-value) of IL and its competitive models are presented. It shows that the IL distribution fits the wooden toys data better compared to the Lindley model with respect to the KS(
p-value) statistic alone. It is also evidence that the IL distribution is the best choice for the wooden toys data compared to other inverse models based on the criteria A, B, CA and HQ whereas the IW, IG, INH and APIE distributions are the next best-fit models based on the NL and KS(
p-value) criteria.
Also, using the complete wooden toys data,
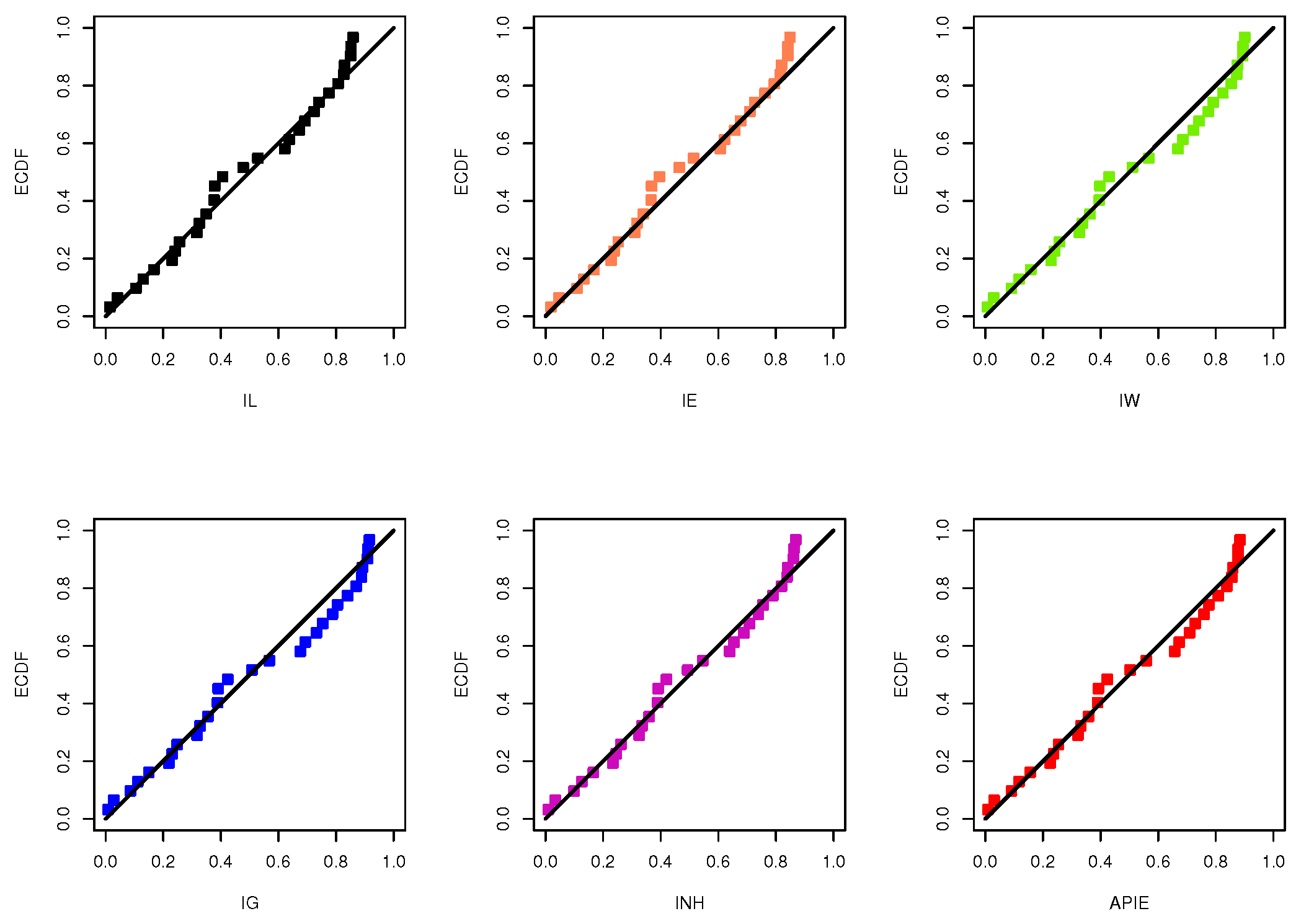
Figure 8 displays the quantile-quantile plots of IL, L, IE, IW, IG, INH and APIE distributions. It also supports the same findings reported in
Table 8. Further, for each model based on the wooden toys data, the plot of histograms of wooden toys data with fitted densities as well as the plot of the fitted and empirical reliability functions are shown in
Figure 9. It is evident that the IL distribution is the best model compared to its competitive models.
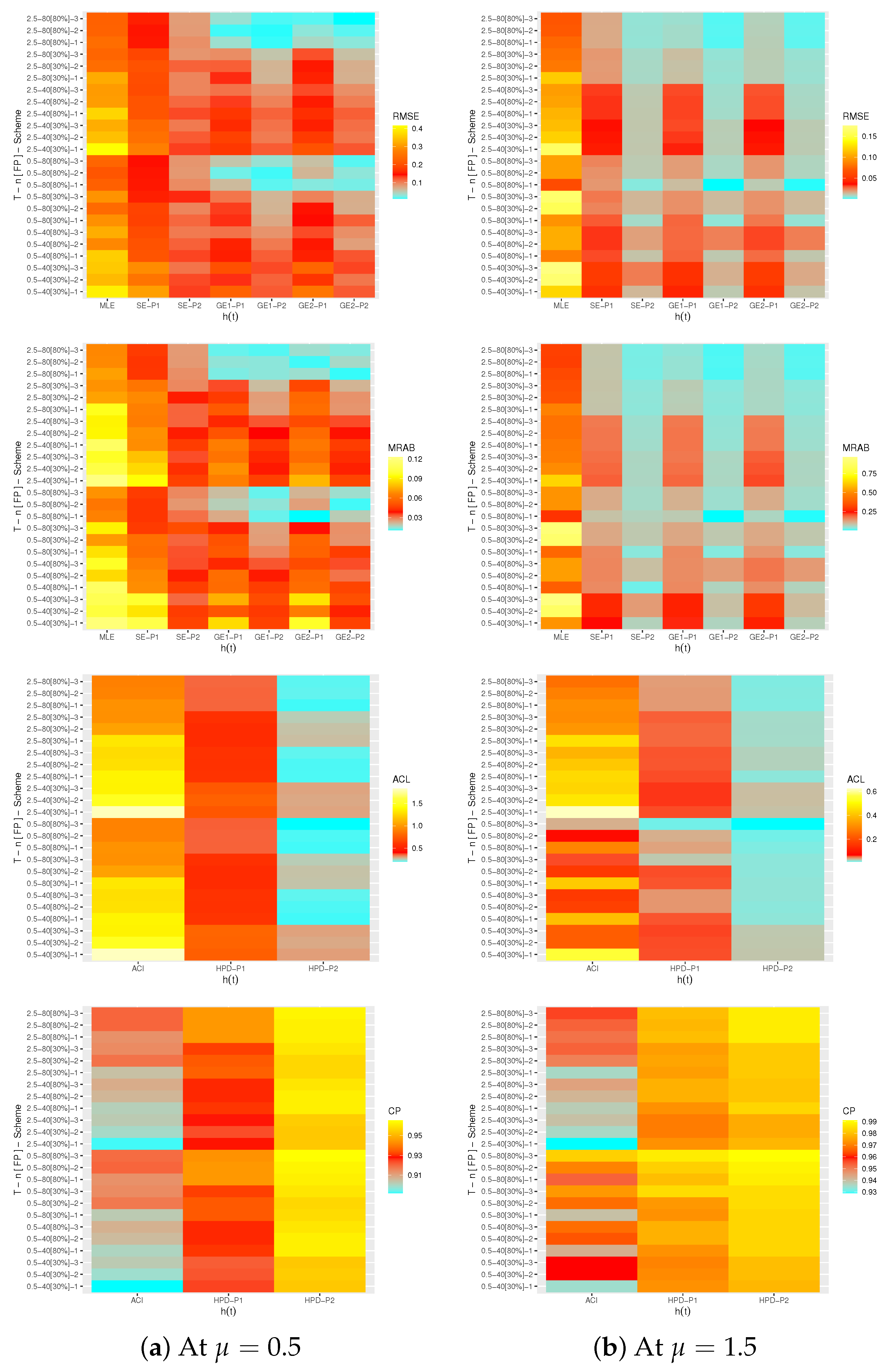
Now, we obtain the calculated values of the derived point and interval estimators of
,
and
based on three different T2-APHC samples with size
from the complete wooden toys data set which are listed in
Table 9. From
Table 9, the classical and Bayes MCMC estimates with their St.Es of
,
and
(at time
) are computed and presented in
Table 10. Moreover, two-sided 95% ACI/HPD interval estimates with their lengths of the same unknown quantities are also calculated, see
Table 11. Utilizing the improper gamma prior under SE and GE (for
) loss functions, from 50,000 MCMC draws with 10,000 burn-in, the MCMC estimates with their St.Es of
,
and
are developed. To run the desired computations, the hyperparameters
a and
b are selected to be 0.001. Moreover, the same properties mentioned in
Table 6 are also reused based on the wooden toys data and reported in
Table 12.
It is observed, from
Table 10 and
Table 11, that the fitted values of the point and interval estimators of
,
and
derived from the Bayes paradigm performed better than those derived from the likelihood approach in terms of the lowest St.Es, as well as, the HPD interval estimates are also performed better than others in terms of the shortest intervals. Using the data set of sample 1 as an example, both trace and histogram plots of the MCMC variates of
,
and
are provided in
Figure 10. It shows that the MCMC mechanism converges well and demonstrates that the MCMC variates of
and
are fairly symmetrical while that associated with
are positive-skewed. Other plots of
,
and
based on samples 2 and 3 are presented in the
Supplementary File. Finally, from both engineering and marketing examples, we can conclude that the proposed methodologies provide a satisfactory interpretation of the IL lifetime model in presence of a sample obtained from an adaptive Type-II progressive hybrid censoring mechanism.















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}