1. Introduction
In the study of time series, autoregressive (AR) models are a fundamental and important statistical tool. The classical AR models only allow for unimodal marginal and conditional densities, which cannot capture conditional heteroscedasticity. To solve this problem, Wong & Li (2000) introduced the
k-component Gaussian mixture AR (GMAR) model that is presented as follows [
1].
Let
be a random variable observed at time
t, and let
be the information set up to time
t.
arises from a
k-component GMAR model of order
p if
has a density of the form
where
,
,
,
for all
,
is an unknown parameter vector, and
is a normal density function with mean
and variance
.
The GMAR model (1) is very useful for modeling nonlinear time series, and it can capture serial correlations, time-varying means, and volatilities [
2]. Furthermore, Wong & Li (2001) and Fong et al. (2007) extended the GMAR model to the AR conditional heteroscedastic (ARCH) model and the vector AR model, respectively [
3,
4]. Since the GMAR model needs the Gaussian assumption, its estimator is not robust to heavy-tailed data or outliers. In order to estimate the occurrence of extreme financial events accurately, Wong et al. (2009) proposed a Student
t-mixture AR model [
2]. Nguyen et al. (2016) introduced the Laplace mixture AR model [
5]. Meitz et al. (2021) considered a mixture of autoregressive models based on the scale mixture of skew-normal distributions [
6]. Meitz et al. (2021) proposed a new mixture autoregressive model based on Student’s t-distribution [
7]. Virolainen (2021) introduced a new mixture autoregressive model that combines Gaussian and Student’s
t mixture components [
8]. Solikhah et al. (2021) studied Fisher’s z distribution-based mixture autoregressive model [
9]. Since the above proposed methods need to assume a specific error distribution, they are not adaptive to the error distributions. A wrong distributional assumption may lead to a decrease in the precision of the model estimate.
In order to develop a robust mixture autoregressive, in this paper, we proposed a robust estimation procedure for mixture AR models by replacing a normal density function in (1) with an asymmetric exponential power (AEP) density function [
10]. The AEP distribution includes many important statistical distributions as special cases, e.g., normal distribution, skew-normal distribution, generalized error distribution, Laplace distribution, asymmetric Laplace distribution, and uniform distribution. This indicates that the proposed method provides a more general approach, which can adapt to much more different error structures and automatically chooses the parameters to achieve both efficiency and robustness of estimators. Meanwhile, we apply an expectation-maximization (EM) algorithm [
11] to implement the proposed optimization problem. In addition, the finite-sample performance of the proposed method is evaluated via some numerical studies and a real-data analysis.
The remainder of the paper is organized as follows. In
Section 2, we introduce an estimation procedure for mixture AR models via an AEP density function and introduce an EM algorithm to solve the proposed methodology. In
Section 3, simulation studies are conducted to evaluate the finite sample performance of the proposed method. In
Section 4, a real data set is analyzed to compare the proposed method with some existing methods. We conclude with some remarks in
Section 5.
2. Methodology
According to Fernandez et al. (1995), an AEP density
is defined as follows [
10].
where
is the location parameter,
is the scale parameter,
controls the skewness,
is the shape parameter, and
is an indicator function. The AEP density function is a flexible and general density function class that can even capture the fat tail and asymmetry of the error term. It also includes some important statistical density functions as its special cases, e.g.,
Normal density function: .
Skew-normal density function: .
Generalized error density function: .
Laplace density function: .
Asymmetric Laplace density function: .
Uniform density function: .
Based on the AEP density function, we propose the
k-component AEP-MAR model, which is defined as follows:
where
is an unknown parameter vector, and
is an AEP density function given in (2). For the
k-component AEP-MAR model, we obtain the conditional expectation and conditional variance as follows:
where
.
Let
be a random sample from the
k-component AEP-MAR model. Then, the sample conditional log-likelihood function can be written as
Therefore, an estimator
for
is defined as
Theoretically, by selecting the proper parameters of location, skewness, shape, and scale, the AEP-MAR model can select the best likelihood function via the data-driven technique. Under some special conditions, the likelihood function of the AEP-MAR model can also be equivalent to the existing statistical methods, e.g., GMAR [
1] and LMAR [
5]. This implies that the AEP-MAR model can provide a more general approach that does not need to assume the error distribution in advance. In addition, the proposed method can adapt to the unknown error structures to improve prediction accuracy.
Algorithm
The EM algorithm is a commonly used algorithm for maximum likelihood estimation in incomplete data proposed by Dempster et al. (1977). Under proper regularity conditions, the EM algorithm has ascent property and global convergence [
11]. In this subsection, we will apply the EM algorithm to solve (3).
Firstly, we define the unobserved random variables
where
and
. Let
. Then, the complete data are
. Thus, the log-likelihood function of the complete data can be obtained as follows:
In the following, we apply an EM algorithm to implement (4).
E-step: Given the
m-th approximation
of
, the expectation of the latent variable
is given by
M-step: By replacing
with
in (4), we obtain the following objective function:
By maximizing
about
, we can yield
For fixed values of
and
, the values of
can be expressed by maximizing
:
where
By replacing
and
with
and
in (5), the objective function about
can be written as
Therefore, the
-th approximation
of
can be obtained by:
Remark 1.
In order to implement the above EM algorithm, we need an initial value . First, we apply the k-means clustering method to the dataset. According to [12], we obtain as follows:where is the random sample in the i-th category, is the quantile check loss function, and . We can use some standard numerical software to obtain and , e.g., quantreg, optim, and optimize in R software. 3. Simulation Studies
Example 1.
In this example, some numerical simulations are carried out to illustrate the finite-sample performance of the proposed method. We compare the proposed method (AEP-MAR) with the following three methods: the method based on the Gaussian mixture autoregressive model (GMAR) [1], the method based on the Student t-mixture autoregressive models (TMAR) [2], and the method based on the Laplace mixture autoregressive model (LMAR) [5]. In this simulation, we consider a following two-component time series model (6). We generate 200 random samples from model (7) with sample sizes of . For the error terms and , in order to demonstrate that the proposed method is robust to unknown error distributions, we consider the following five scenarios:
Scenario 1: The standard normal distribution ().
Scenario 2: The standard Laplace distribution ().
Scenario 3: The t-distribution with degrees of freedom 3 ().
Scenario 4: A mixture of standard normal distribution and standard Laplace distribution ().
Scenario 5: The chi-square distribution (). When the error assumption is correct, the corresponding mixture AR model should have the best performance. Meanwhile, when the error assumption is wrong, the estimation accuracy of this method will also decrease. Therefore, the Scenarios 1–3 are used to compare the performance with the existing methods under correct error assumption, and the performance of the proposed method should be similar to the correct model. The Scenarios 4 and 5 are used to demonstrate that our method is robust to unknown err structures, and the performance of the proposed method should rank first among the four methods.
To assess the finite-sample performance, we calculate the bias and the mean squared error (MSE) of estimators based on 200 simulations. The simulations results are reported in
Table 1,
Table 2,
Table 3,
Table 4,
Table 5,
Table 6 and
Table 7, respectively. In
Table 2 and
Table 4, we also report the estimators of other parameters for the two-component AEP-MAR model. From
Table 1, we find that the GMAR has smaller bias and MSE than other three methods in the case of normal distribution, while the finite-sample performance of the AEP-MAR is better than the other two methods. In
Table 3, the LMAR has the best performance in the case of laplace distribution. Meanwhile, the performance of the AEP-MAR is also similar to that of the LMAR. We can observe from
Table 5 that the TMAR has the smallest bias and MSE in all four methods, while the AEP-MAR and the TMAR have similar performance. In
Table 6 and
Table 7, the AEP-MAR has the smallest bias and MSE in all four methods, and the effectiveness of the other three methods decreases significantly. The estimators of AEP-MAR are also precise as the sample size increases. This illustrates that AEP-MAR is robust and effective to an unknown error structure. In conclusion, the proposed method is more adaptive to the error distribution than the other three methods. If the error structure is unknown, the proposed method should be considered first.
Example 2.
In this example, we apply numerical simulation to illustrate the finite-sample performance of the model selections for the proposed AEP-MAR model via the Akaike information criterion (AIC) and Bayesian information criterion (BIC). The dataset is generated according to Scenario 4 in Example 1. We consider the k-component mixture AR model, where . We calculate the AIC and BIC value of the GMAR model, the TMAR model, the LMAR model, and the proposed AEP-MAR model for each k. The corresponding results are shown in Table 8. From Table 8, we find that the the two-component AEP-MAR model is selected by minimizing AIC and BIC. 4. A Real Data Analysis
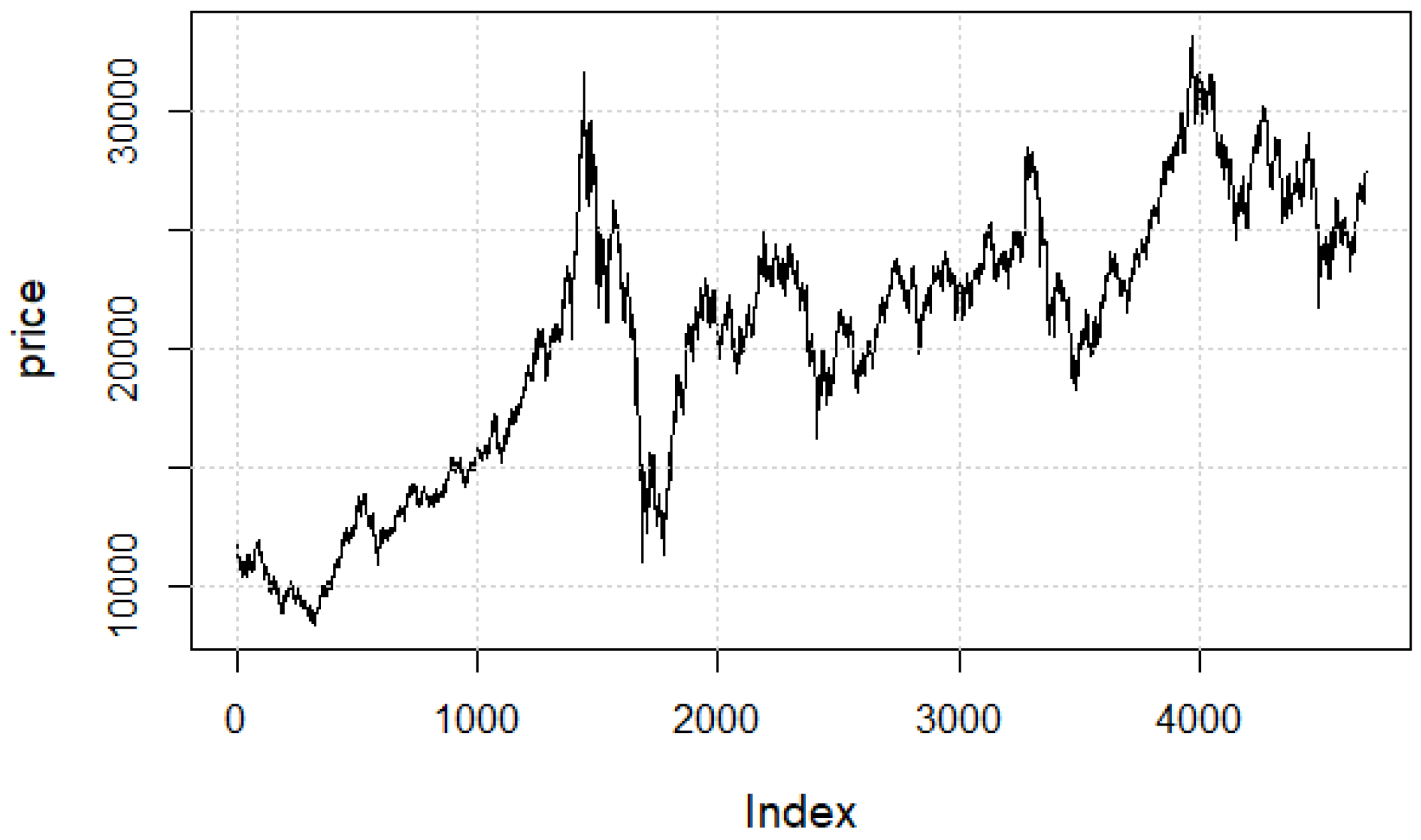
In this section, we will apply the proposed methodology to analyze the daily return series of Hong Kong Hang Seng Index (HSI). The data covers the periods from 2 January 2002 to 31 December 2020, which includes 4689 observations. The original series is shown in
Figure 1. From
Figure 1, we can clearly see that the daily price series is non-stationary. Similar to [
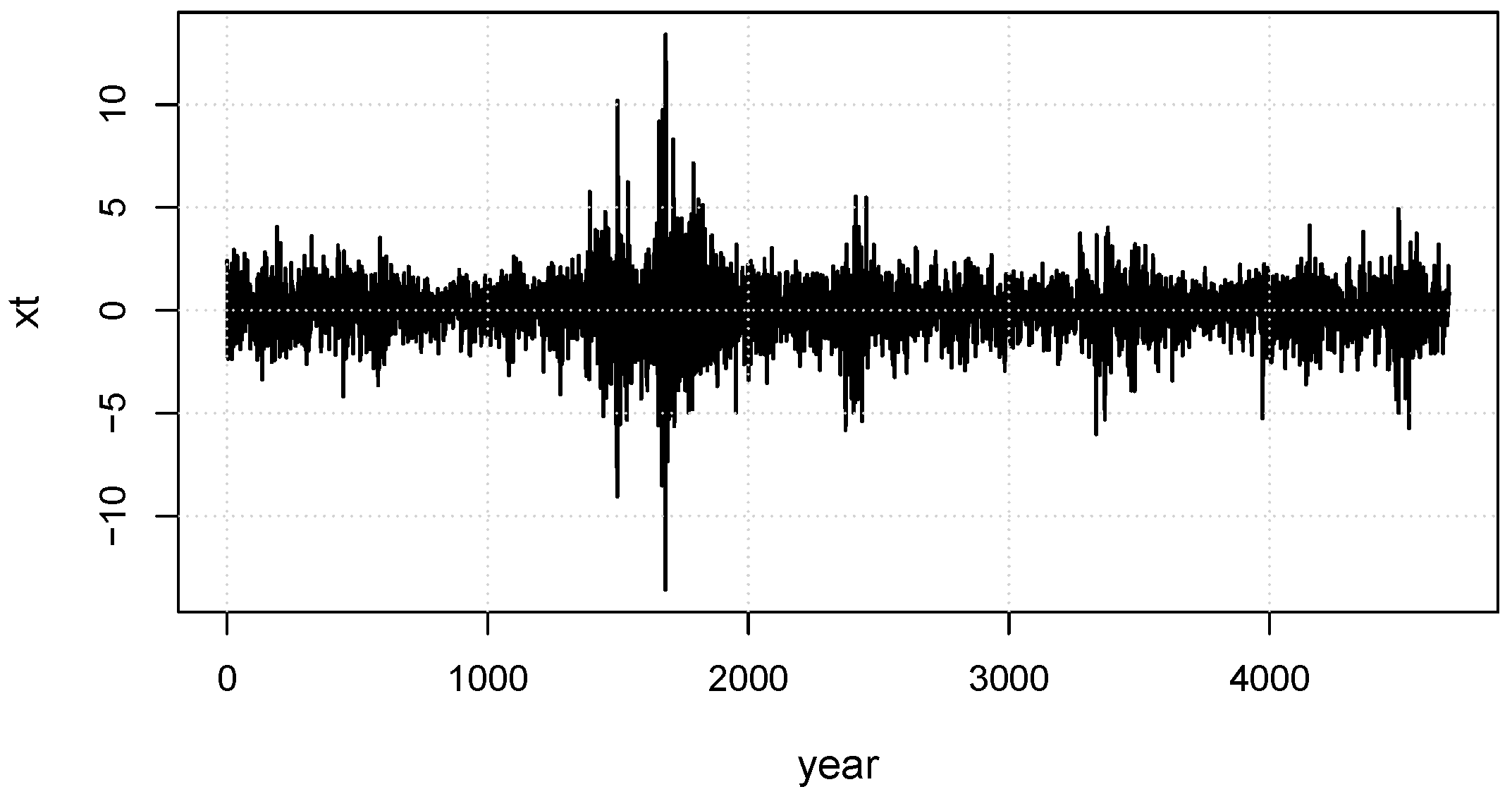
13], we let
, where
is the daily price in
t-th day. The corresponding
series are shown in
Figure 2. We can observe from
Figure 2 that
is stationary. The skewness and excess kurtosis of
are −0.3 and 9.01, respectively, which also means that the
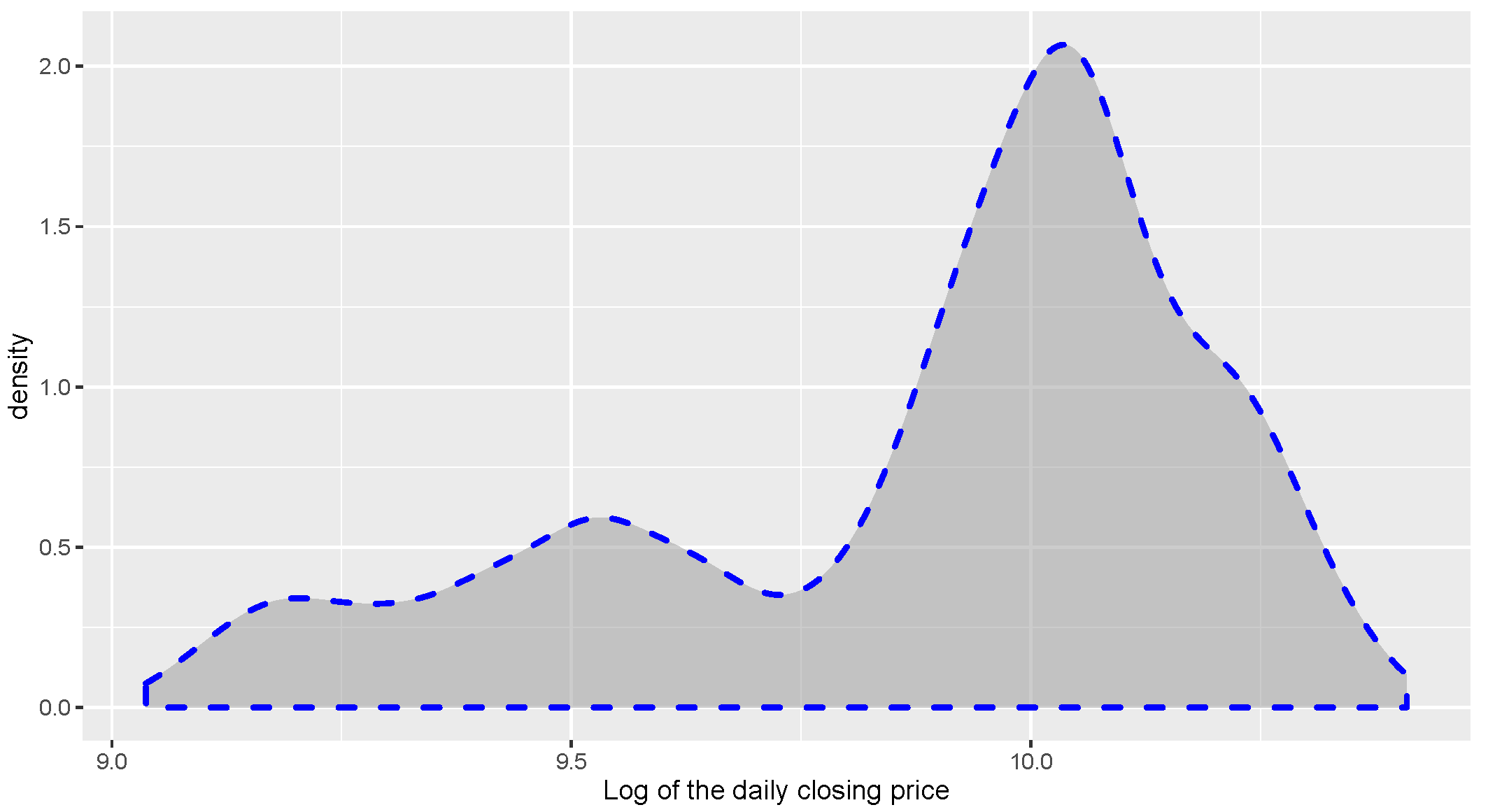
series does not satisfy the normality assumption. Meanwhile, the density of log of the daily closing price of the Hong Kong Hang Seng Index is drawn in
Figure 3. From
Figure 3, we find that the marginal distribution of the series is clearly not symmetric and exhibits multimodality. This indicates that we need to use a mixture AR model rather than an AR model to describe the daily trend of HSI.
In real data analysis, it is important to choose the number of components
k and the order of AR components for the MAR model. According to the distribution characteristics described above, we first consider a two-component mixture AR model and a three-component mixture AR model for this dataset. According to Wong & Li (2000) [
1], we used AIC and BIC as the model-selection criteria. An example of the performances of the model-selection criteria can be seen in the
Example 2 in
Section 3.
The corresponding results are reported in
Table 9. From
Table 9, we can see that all of the methods rank the two-component as the best. Additionally, the best model selected by minimizing AIC and BIC is the two-component and second-order AEP-MAR model; the value of AIC is 5.61, and the value of BIC is 70.14. This shows that the AEP-MAR model can fit the characteristics of high kurtosis and multimodality in the the log-return series of HSI better. The estimation results for the selected model are given in
Table 10. According to
Table 10, we obtain the following the two-component and second-order AEP-MAR model for the daily return series of Hong Kong Hang Seng Index.
We obtain from the model (8) that the first component can be interpreted as the overall trend of the log-returns with relatively small fluctuations, and the second component can be interpreted as the irrational “Unilateral Overshooting Phenomenon” in financial markets.
5. Discussion
In this paper, we introduced a robust mixture autoregressive procedure via an asymmetric exponential power distribution. The proposed method has greater flexibility and can adapt to unknown error structures. Under some specific parameters, our method can also be equivalent to the existing method, e.g., GMAR and LMAR as its special cases. In addition, an EM algorithm was introduced to solve the proposed optimization problem. The merits of the proposed method are illustrated by some numerical simulations and a real data analysis. The results indicated that the proposed method was robust and was adaptive to the error distribution. Finally, we will study the large sample properties of the proposed method as future work.





{kind=link}
{kind=link}
{kind=link}