3. Problem Formulation and Methodology
The governing laws of the Physics Informed Neural Networks framework are provided as mathematical equations. This section covers the development and evaluation of the key mathematical models of focus. The mathematical model serve as the assumed physics laws that the model should adhere to.
The Susceptible–Infected–Recovered–Deceased (SIRD) model used assumes that the population can assume four states, Susceptible (S), Infected (I), Recovered (R) and Deceased (D). The susceptible population is the group which can contract the virus, this contraction occurs at the rate
. The infected population is the population group that has contacted the virus and it is still active. The infected group can be removed to either assume a recovered population at the rate
or deceased population at the rate
. This means
is the death rate,
is the infection rate and
is the recovery rate.
Figure 1 shows the resulting COVID-19 transmission SIRD flow diagram.
From the flow diagram in
Figure 1 we obtain the system:
The model is subjected to the initial values, , , and .
The system in general reflects the mathematical behaviour of the virus. Equation (
23) indicates the change in the number of susceptible individuals
with respect to time
t; which is a reduction by a factor of the product of the spreading rate
, the susceptible population at the time
and the Infected population at time
divided by the total population
N. Equation (
24) shows that the change in the number of active infections
with respect to time
t; which is an addition by size at which the susceptible population was reduced. This is then reduced by a factor of the product of the recovery rate
and the Infected population at the time
and a product of the death rate
and the Infected population at the time
. Equation (
25) shows that the change in the number of recoveries is an addition by a factor of the product of the recovery rate
and the Infected population at the time
. Equation (
26) shows that the change in the number of deaths is and a product of the death rate
and the Infected population at the time
. The model also assumes that initially the are no recoveries or deaths and that the infected and susceptible populations are greater than zero.
Studies and implementations of neural networks have shown that using numbers less than one improves accuracy and optimisation. As a result, we must use the non-dimentionalisation technique to rescale the provided data to values between 0 and 1.
We let
To rescale the SIRD model, we make these assumptions, with the goal of reducing the number of variables and so obtaining new SIRD model values, thus:
. Substituting in the SIRD model we obtain:
Hence the resulting system is:
3.1. The Neural Network
The neural network we create, as a consequence, takes a single input value of time
t. The input is processed through the layers with weights
, where
i is the start node position and
j is the finishing node position. The product of the weight and time is applied to an activation function
denoted by
at every node, forming a matrix. The model’s output nodes, which make up the output layer, are
,
,
, and
.
The representation of a neural network matrix with m layers and n nodes per layer.
3.1.1. Residual of Model’s Equations
The difference between the right and left sides of an ODE is the residual error. The residual error is utilized to determine the neural network’s loss function in the construction of PINNs. We get four residual error functions from the SIRD model. We get
, the residual error of the susceptible population, from Equation (
23), which is the margin of how wrong the mathematically predicted susceptible population change is. We get
from Equation (
24), which is the residual error of the infected population, or the margin of error in the mathematically estimated active infection change. The residual error of the recovered population
is given by Equation (
25). We get
the residual error of the deceased population from Equation (
26), which is the margin of how much wrong the mathematically predicted deceased population change is.
3.1.2. The Loss Function
A loss function must first be constructed before back propagation can be used to optimize a neural network. We derive the loss function for the PINNs we constructed by adding the total of two loss functions and . The total of the mean square errors of the susceptible population is . The gap between the actual and forecast population sizes is the total of the sensitive population’s mean square error. The total of the difference between the actual size of the infected population and the values predicted by the ANNs is the mean square errors of the infected population . The difference between the actual size of the recovered population and the anticipated recovered population size, as well as the mean square errors of the deceased population , make up the recovered population mean square errors . is the mean square error of the difference of the predicted deceased and the actual data value .
The sum of the mean square errors of the susceptible population residual error
, the mean square errors of the infected population residual error
, the mean square errors of the recovered population residual error
, and the mean square errors of the deceased population residual error
is
.
We get a neural network that looks like
Figure 2 using the time input, the layer matrix, the output layer, and the residual functions.
3.2. Basic Model Properties
The analysis of the mathematical model is presented in the next part. This part examines the model’s features and expected behaviour, such as determining the reproduction number, which is the minimal number of transmissions required for a pandemic to occur, and the sensitivity analysis of the ODE system.
3.2.1. Basic Reproduction Number
To comprehend COVID-19, which has now become a pandemic, we must first estimate the minimal rate of secondary infections required for a pandemic to arise. The reproduction number
is also the rate at which a spread would be stopped if it fell below it. Its derivation is as follows:
The change described by the left hand side, obtained after non-dimentionalization, must be strictly greater than 0 for a pandemic to occur, according to Equation (
51). Equation (
52) is produced by dividing both sides by
, and Equation (
53) is obtained by moving the term containing the spreading rate to the left hand side. We can deduce from Equation (
54) that the lowest needed spreading rate for a pandemic is equal to the left hand side divided by the right hand side.
3.2.2. SIRD Model Analysis
The mathematical model’s sensitivity analysis also reveals some of the model’s essential aspects, such as the estimated maximum number of infections
. Equations (
23)–(
26), which are all part of the SIRD model, are used to calculate the maximum number of infected individuals that can occur at any given time.
To obtain this we first divide Equation (
23) by Equation (
24) to obtain Equation (
55) and integrate it to obtain Equation (
56).
To obtain the maximum possible value of infection, we find a point where the Equation (
56) is equal to zero. It was determined that this occurs when
.
In Equation (
59), we substitute the value of
S, to obtain the equation. In Equation (
60), the model is simplified and rearranged. In Equation (
61), the value
is substituted where possible such that the remaining equation is attained.
We now have the estimated number of persons who will become infected. Individuals infected with the virus either recover
or die
, thus we calculate the predicted number of persons who will either recover or die.
According to the created SIRD model, the whole number of people who will be infected will either recover from the disease or die from it, therefore the total number of persons affected will be equal to the sum of the recoveries
and the deceased
illustrated in Equation (
62). We estimate the total infected at the conclusion of the virus spreading period to be equal to the sum of the original susceptible and infected populations minus the Susceptible population at the end of the period, as shown in Equation (
63).
where
S,
I,
R and
D, respectively, represents susceptible, infectious, recovered and deceased individuals and
is the total population. The parameters
,
and
, respectively, represent the infection, recovery rate and death rates. Since in the analysis or in the model recovered and deceased individuals have the same effects on the model, we group them as
R representing removed with the removal rate of
; such that we have,
Which can be rewritten as:
The results of the simulations of the Physics Informed Neural Networks framework are presented in this section. It also includes a full analysis of the results, as well as changes in accuracy as parameters like data size change. The information was gathered through national daily updates and a Google studio analysis website created by the University of Eswatini and Wits Ithemba Labs [
33]. Due to location/resource constraints, the model was constructed using Python 3 on a Spyder interface running in offline mode. Numpy, Mathplotlib, and Tensorflow were the main packages utilized.
3.3. Simulation Using Mathematica Generated Data
To test the model and validate the PINNs, we used Mathematica to create fictional data for an SIRD model. The benefit of this type of data was that it was less noisy. We started the model with a 100,000-person susceptible population, 0 recoveries and deaths, and five infections. In order to acquire the data shown in
Figure 3, the average infection rate was set to be 0.14, the average healing rate was 0.037, and the average mortality rate was 0.005.
The traditional behaviour of a SIR mode is seen in
Figure 3, where the size of the vulnerable population decreases as the size of active illnesses increases. The size of the recoveries and deaths then increases until they reach a maximum or stabilize.
PINNs Model of Mathematica Results
The aforementioned model produced data from a PINNs of three layers, each with 30 nodes.
The findings provided after the model was trained were compared to the susceptible population, which was also utilized as the training dataset. There is only a small error between the two plots because they are so tightly aligned.
Figure 4 depicts the resulting findings, which compare active infections from the dataset used to train the model to the values obtained by the trained model. This graph is well-fitting, indicating that it has a low degree of error. The graph in
Figure 5 depicts the results of the recovered dataset used for training, as well as the produced results following the training process, which have a strong match and hence less errors.
Figure 6 shows the outcome of comparing the actual deceased with the results acquired after the training procedure; this graph has a good match but is less accurate than the others.
3.4. PINNs Simulations of Alabama State Data
We used a dataset from the American state of Alabama to test the SIRD model for further validation. The dataset spanned roughly 300 days, and the simulation used a three-layer neural network with 30 nodes per layer, with 1,000,000 iterations.
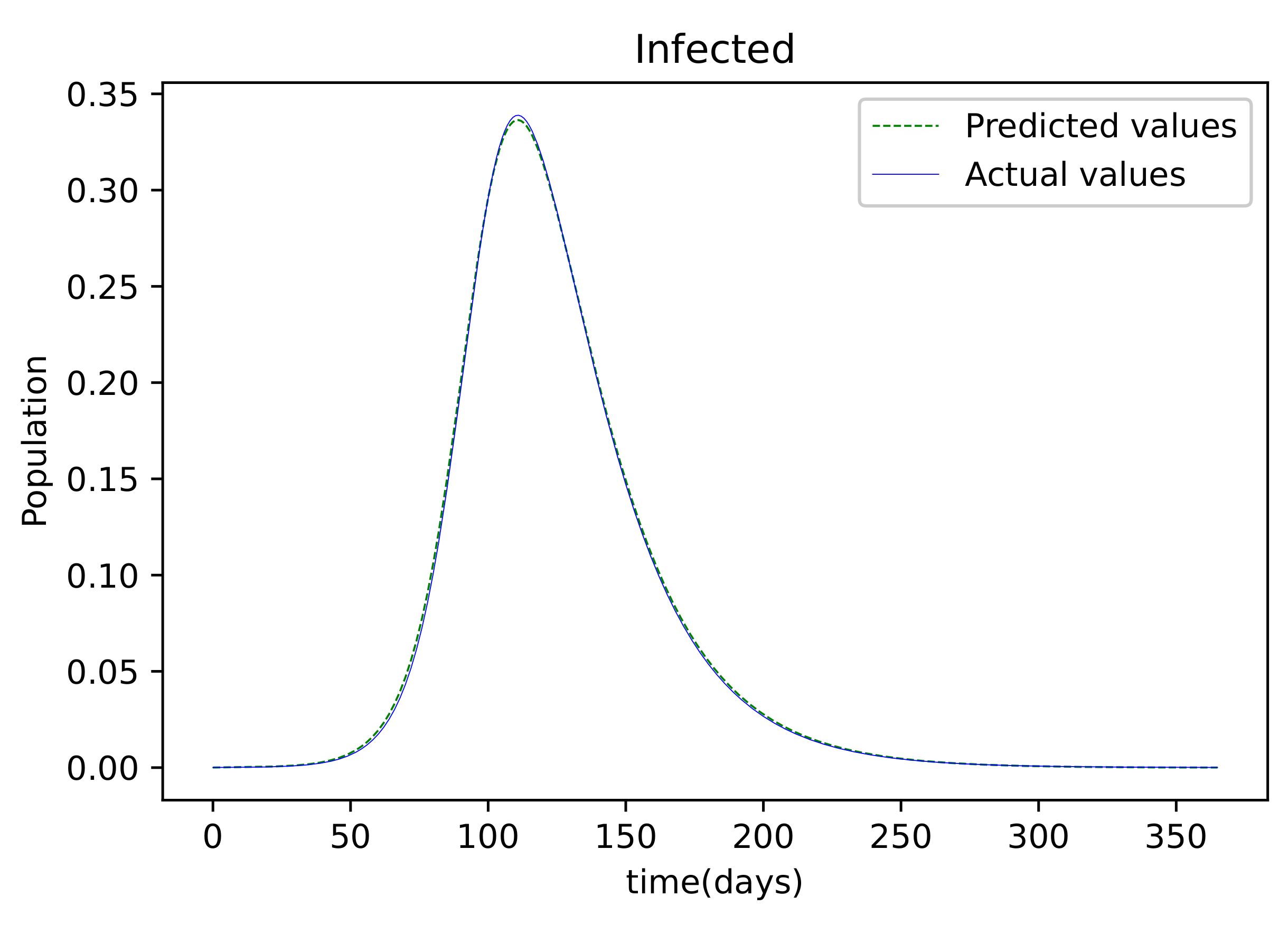
Figure 7 shows the outcome of data fitting, which compares the susceptible population data from the real data to that obtained by the trained PINNs model, and shows that there is a decent fit, implying that there is a little inaccuracy. The resulting graph of the data fitting is shown in
Figure 8; it has a good fit, implying that there is a little error. The graph in
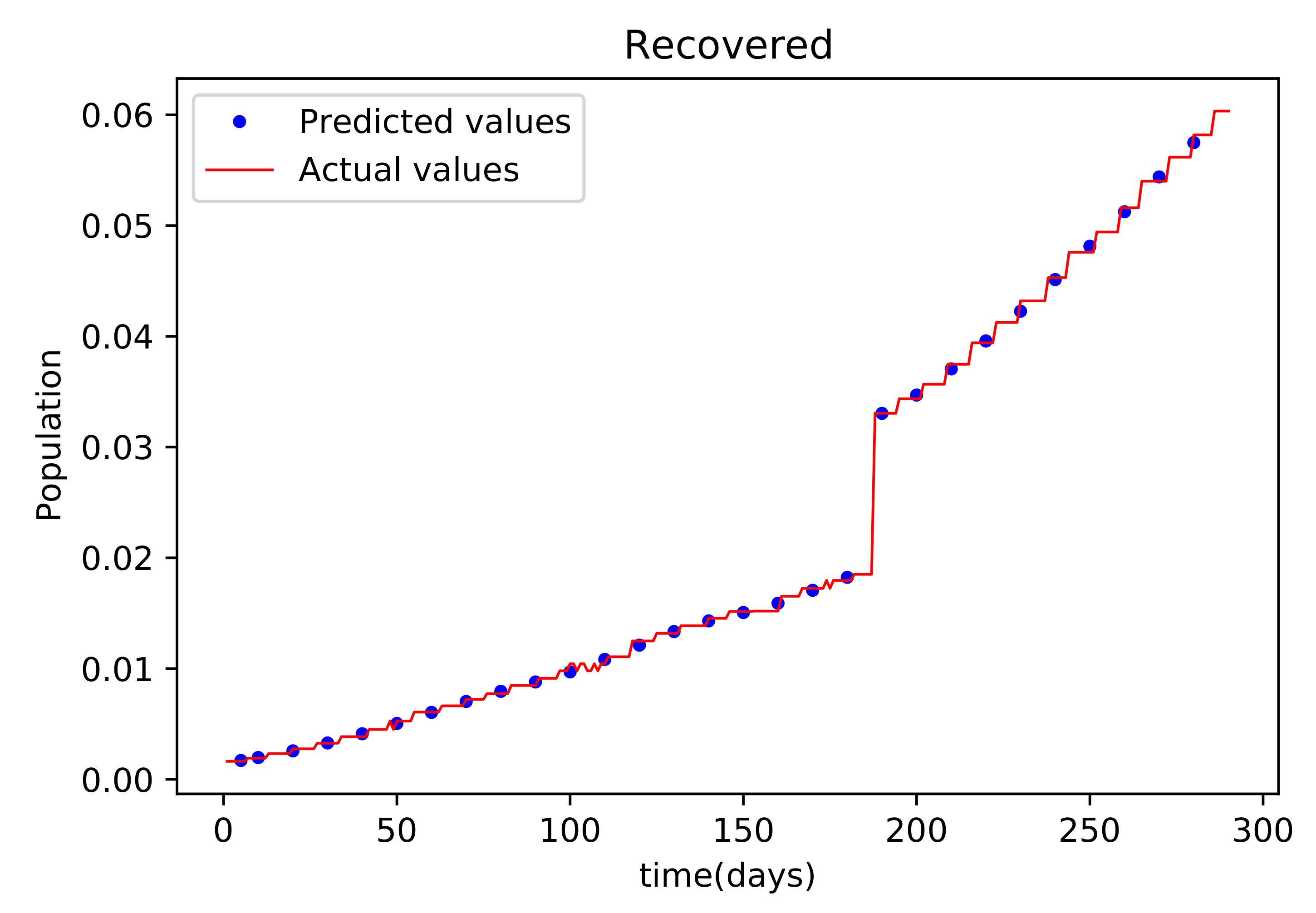
Figure 9 compares the values acquired by the training model to the original data used in the recoveries, and it likewise has a strong match and less mistakes.
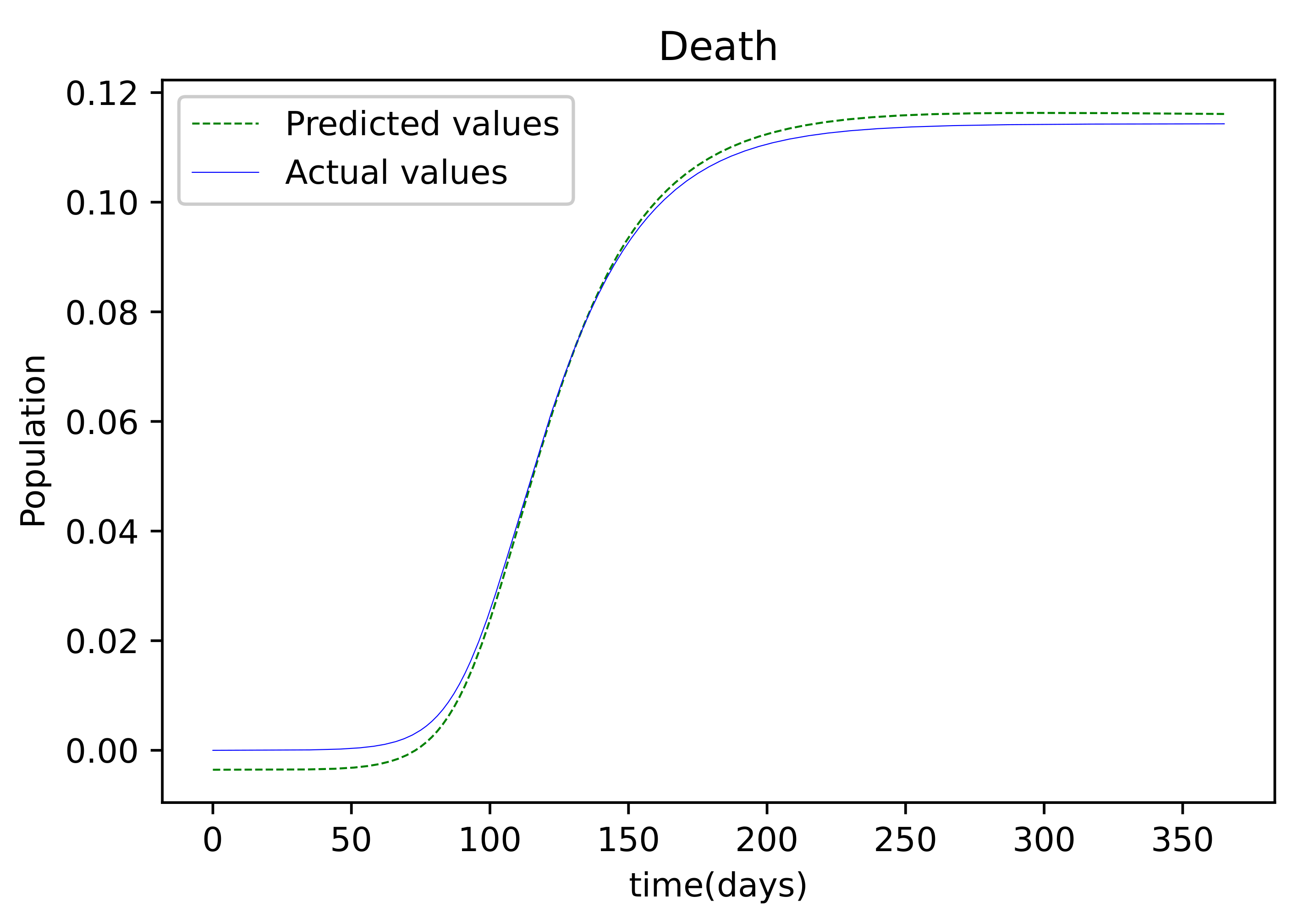
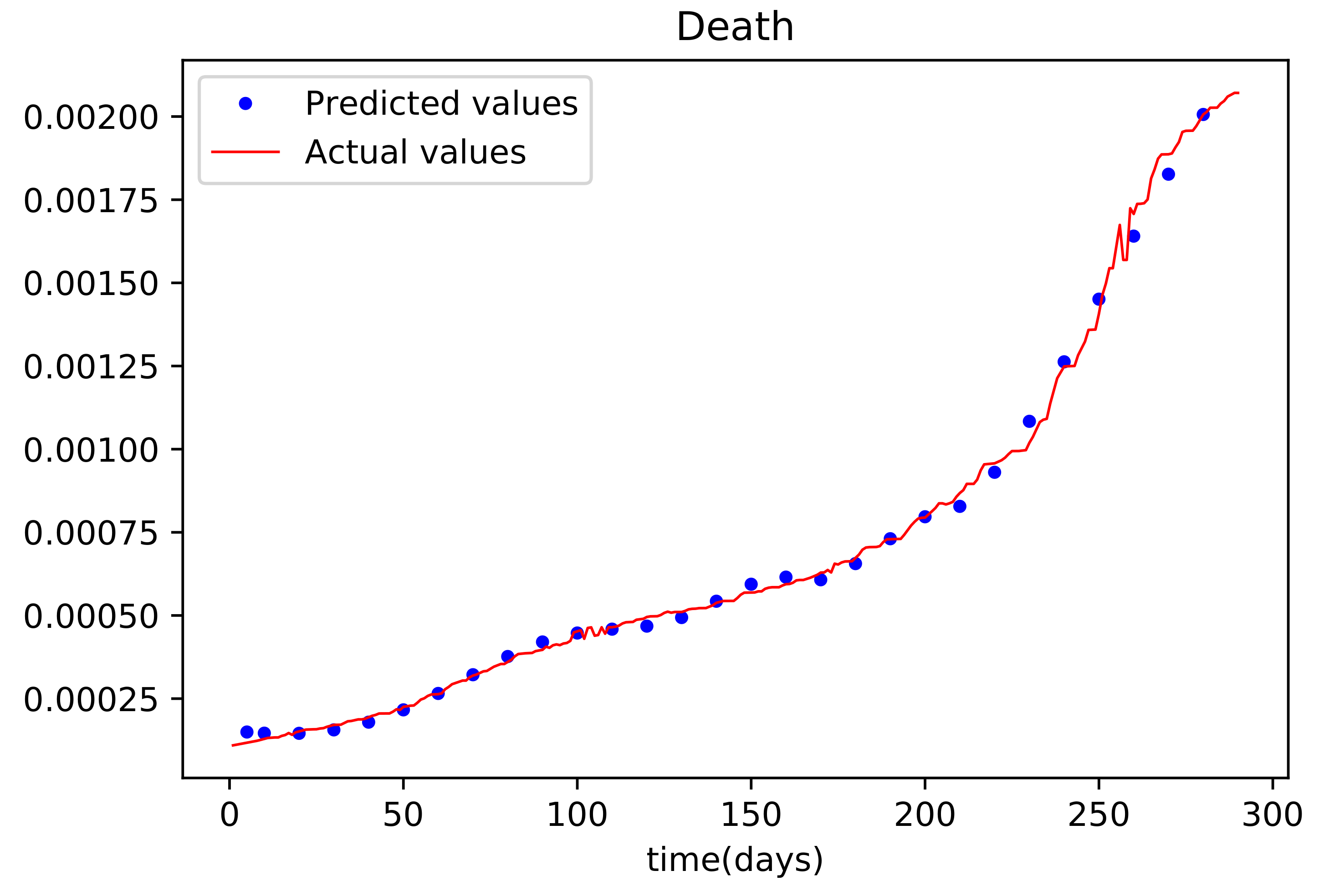
Figure 10 is the last graph that compares the findings received after the model was trained to the actual data of the deceased population. This graph has a good match, but it is more erroneous than the others.
3.5. PINNs Simulation of a Model Using 170 Data Points
To put the model to the test and further test the potential of the PINNs model, a simulation using a smaller dataset was conducted. To conduct the simulation a dataset derived from the existing data to fully stretch over the period making up only 30% of the available data results were obtained.
The resulting graph, in
Figure 11, compares the values acquired by the trained model to the actual data for the data fitting purposes of the vulnerable population and finds a good match, resulting in a tiny sized error. The obtained graph of data fitting is shown in
Figure 12; it has a good fit, which indicates it has a minimal error. The graph in
Figure 13 shows the recovered population results, which are a comparison of the trained model results and the real data, with a strong match and less mistakes. This graph has a good fit, but it has a larger error than the other graphs.
Figure 14 is the resulting graph of the deceased population, which is a comparison of the trained model results and the actual data. The total result reveals that while the fitting has less mistakes, they are larger when compared to scenarios where larger data was employed.
3.6. PINNs Simulation of a Model Using All Available Data Points at the Time (576 Data Points)
The simulation was carried out with 5,000,000 iterations and four layers, each with 30 nodes. The dataset used was 576 days long, which was the maximum number of days accessible at the time.
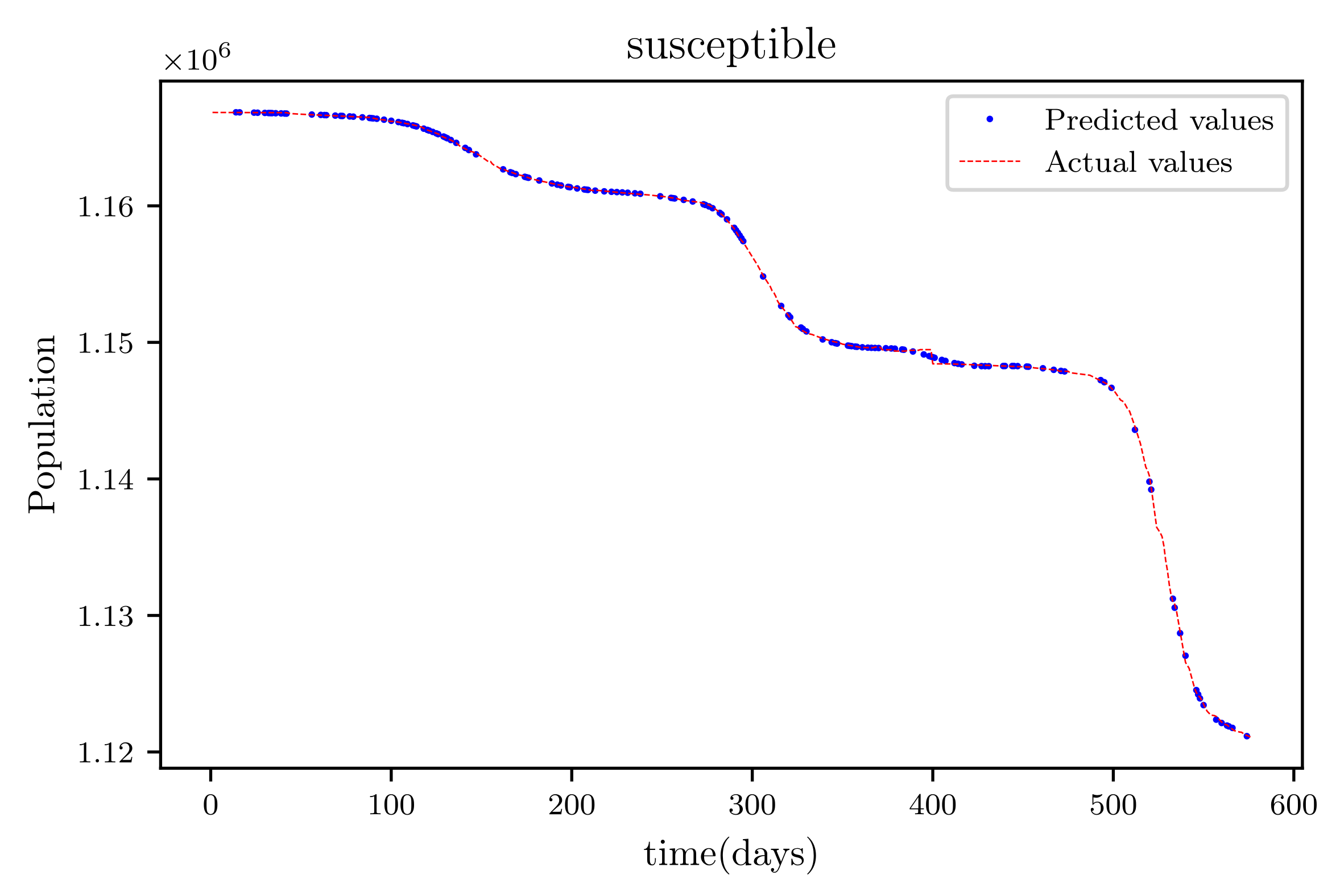
In this situation, the best simulation is carried out utilizing all of the data available; the training data account for 70% of the data, while the testing sample accounts for just 30% of the data and is chosen at random. The resulting graph for data fitting purposes for the sensitive population is shown in
Figure 15, and there is a tiny sized error and good fitting. The obtained graph of data fitting is shown in
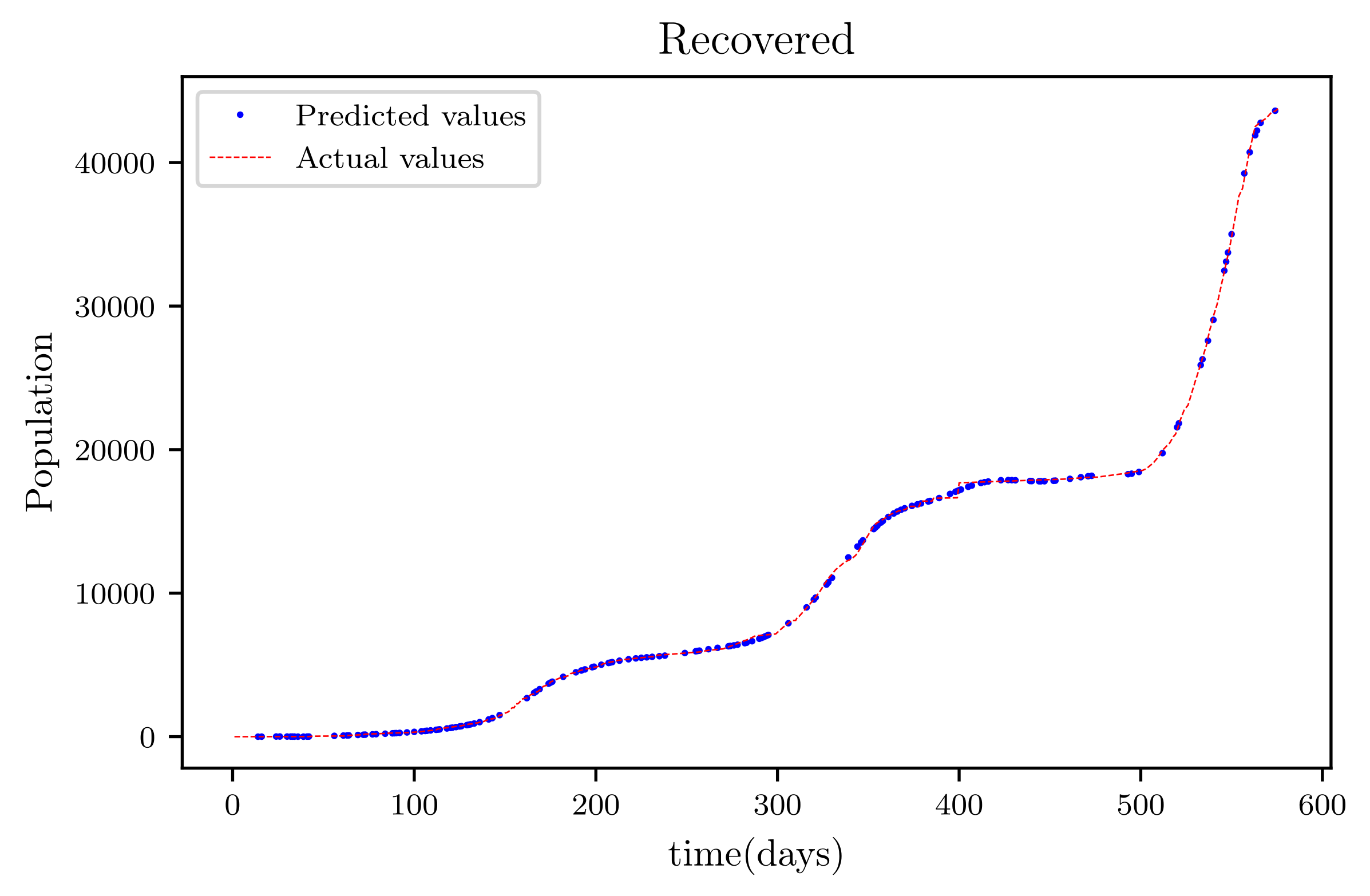
Figure 16; it has a good fit, which indicates it has a minimal error. The graph in
Figure 17 depicts the recovered findings, and it has a strong fit and few mistakes. The resulting graph of deceased is shown in
Figure 18; this graph has a decent fit, although it has a larger error than the other graphs. The overall result demonstrates that, while the fitting has less mistakes, they are larger than in circumstances when additional data was employed.
3.7. PINNs Simulation Forecasting 30 Days
Simulations using the three layers of 30 nodes per layer was conducted and there were 5,000,000 iterations made during the training.
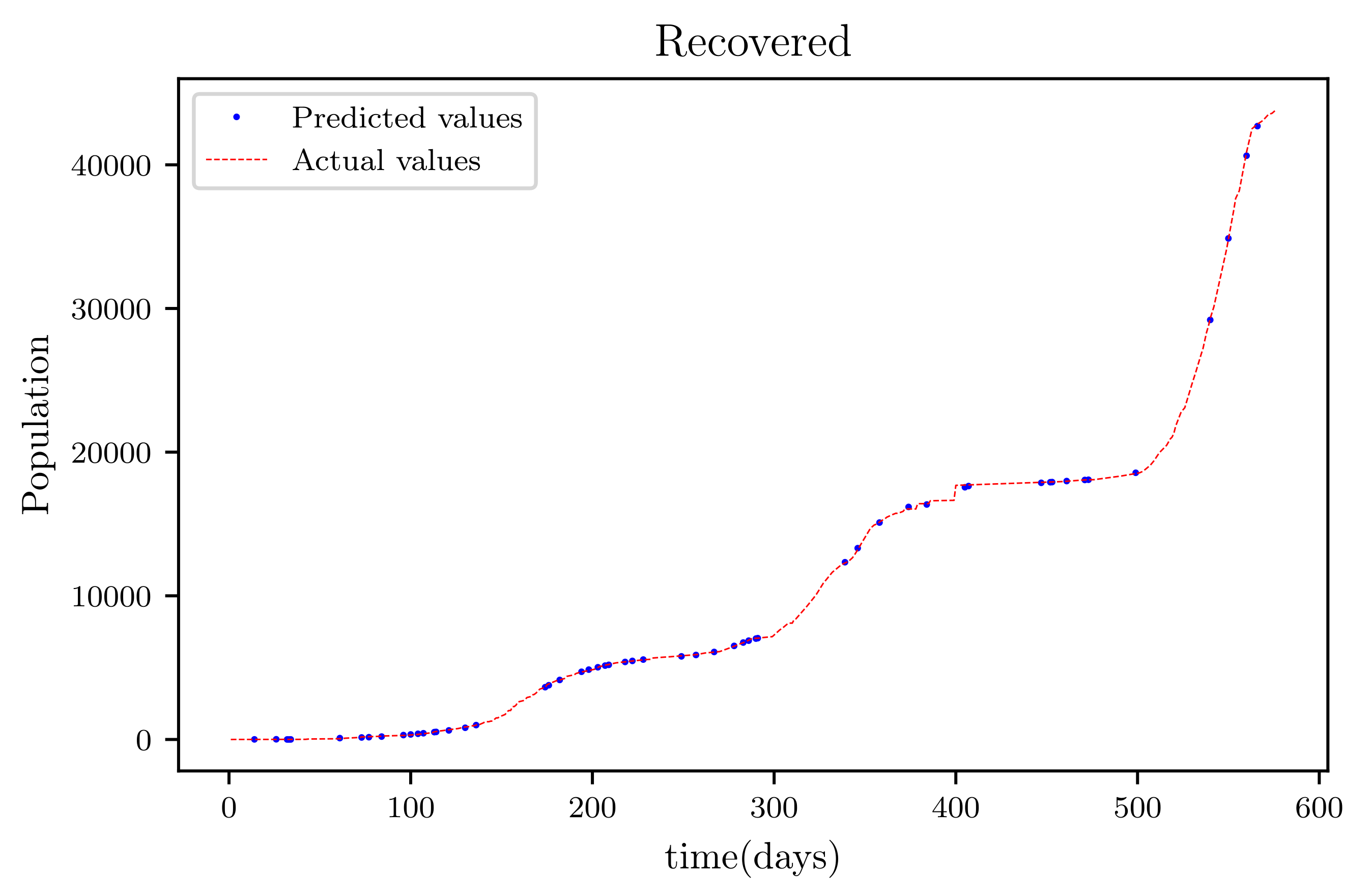
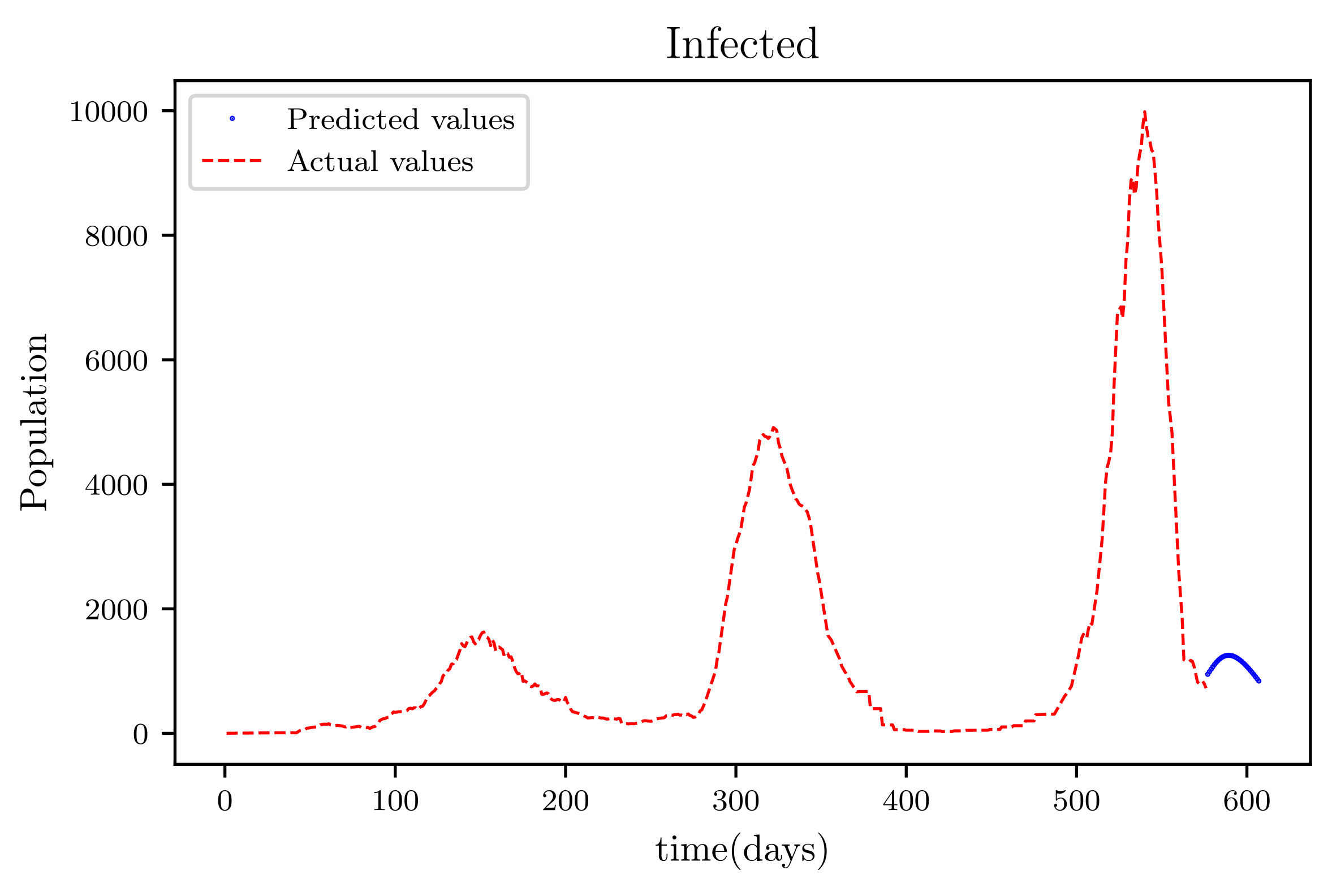
Figure 19 is a result graph based on the forecasting of the sensitive population for the next 30 days; the numbers appear to be declining, as expected. The resultant graph, shown in
Figure 20, provides the anticipated data of active infections in a curved shape. The results of the anticipated recoveries are depicted in
Figure 21. The resulting graph of the anticipated deceased population is shown in
Figure 22. The prediction also determined the total predicted recoveries
, as well as the maximum expected infections
, susceptibles population expected at the end of the disease’s spread
, and the maximum expected infections
. Using the estimated parameter values, we obtained
72,121,
1,094,719, and
70,274.
3.8. Deep Learning Sensitivity Analysis
The study’s Physics Informed Neural Network framework is primarily influenced by four elements. The number of iterations conducted during training, the quantity of the training data utilized, the total number of layers in the model, and the number of nodes in each layer are all variables to consider. To begin the sensitivity analysis, the default model is set up with the following parameters: number of iterations 200,000, amount of training data 400, number of layers 3 and number of nodes 30.
Then, many simulations were run, with all model variables set to default, only two parameters changed, and all mean square errors recorded. The model setup is only subjected to a single simulation. Because the beginning values for each scenario are set at random, there are certain uncontrollable margins of error. A contingency only enables one further simulation trial in such instances.
The number of layers in the neural network and the number of performed iterations were the parameters that were varied in
Table 1. The number of layers was varied between two, four and eight, while the number of iterations was varied between 100, 200, 400, and 800,000. The simulation results show that increasing the number of iterations reduces the amount of the error for the same number of layers. When the number of iterations is kept constant, the margin of error is reduced as well. This means that, as the number of iterations and layers increases, the accuracy improves.
Table 2 compares the correlation impacts that the number of nodes per layer and the number of layers included in the neural network have. The number of nodes utilized in this test were 10, 20, 40, and 80, respectively, and the number of layers employed were two, four and eight. The data obtained, which are also displayed on the table of concern, show that increasing the number of nodes improves the margin of error given a constant number of layers. However, increasing the number of layers for a given number of layers reduces the margin of error. This means that, as the number of layers and nodes per layer are raised, the lowest margin of error is achieved for the physics informed neural network model established for this study.
The results of an analysis and simulations studying the correlation of the data size and the number of layers are shown in
Table 3. The data sizes were 100, 150, 200, and 350, while the number of layers tested was two, four and eight. The results show that increasing the number of layers while keeping the data size constant reduces the margin of error. The investigation of a variety of data sizes on a fixed number of layers reveals that the values do not vary in a predictable way, but rather shift within a tiny margin. These findings reveal that data size has no effect on the number of layers, however data size has an effect on the number of layers, which reduces the margin of error.
The results of an investigational analysis on the number of nodes per layer and the number of iterations are shown in
Table 4. 10,000, 400,000, and 800,000 iterations were completed. The numbers 10, 20, 40, and 80 were used to test the nodes. The results show that increasing the number of iterations reduces the amount of the error while the number of nodes remains constant. The findings also reveal that increasing or decreasing the number of nodes has no effect on the amount of money spent. As a result, increasing the number of iterations reduces the amount of the error while having no effect on the number of nodes.
The results of simulations undertaken to determine the correlation between the data size used during the training process and the number of iterations are shown in
Table 5. The experiment included data sizes of 100, 150, 200, and 350, as well as iterations of 100, 400, and 800,000. The results show that increasing the number of iterations while keeping the training data size constant minimizes the margin of error. The results also show that changing the data size while maintaining a constant number of iterations has no effect on the number of iterations. As a result, increasing the number of iterations decreases the amount of the error, whereas changing the size of the training data has no effect.
The data size used during the training process and the number of nodes per layer are shown in
Table 6. The experiment used 100, 150, 200, and 350 data sizes, as well as 100, 150, 200, and 350 iterations. The results suggest that increasing the number of nodes while keeping the training data size constant lowers the margin of error. The results also reveal that changing the data size while keeping the number of nodes fixed has no effect on the number of nodes. As a result, increasing the number of nodes lowers the amount of the error, however changing the size of the training data has no effect.
5. Conclusions
The study’s goal was to examine current data in order to determine COVID-19’s behavioural dynamics. The Physics Informed Neural Networks framework was used to accomplish this analysis and to be able to estimate the dynamics of COVID-19. The focus of the research was to establish the number of patients who were susceptible, infected, recovered, and deceased in a timely manner. The study also intended to establish the disease’s dissemination rate, death rate, and recovery rate based on this information. The rates were to be calculated on an average basis. The study attempted to take advantage of neural networks’ ability to uncover hidden patterns in data, such as prospective increases and falls in dynamics, because they have this capability.
The Physics Informed Neural Networks framework used in the study is an ANN model that trains a neural network by exposing it to both the training data and the governing equations of the underlying problem. The Susceptible–Infected–Recovered–Deceased model was the mathematical model introduced as the governing equations of the PINNs training model. The underlying data for the simulations was collected between March 2020 and September 2021 in the kingdom of Eswatini. The main advantage of adopting the PINNs model was that it outperformed all other data analysis models even when given minimal quantities of training data, which was important given the disease’s newness and the lack of data and knowledge [
8].
The generated PINNs model was used to run simulations, and the results were presented in the form of tables and graphs. The study’s first model was created artificially and had the advantage of being both accurate and covering a disease spread that lasted the entire life of the simulated disease spread. The acquired result had a modest margin of error, with the sole exception being the forecasts for the deceased population, which had a larger margin of error. This demonstrated that the proposed model could produce accurate findings and that the model could be used to assess the model over its entire life cycle. Another experiment was carried out with data from the state of Alabama in the United States. With a minimal margin of error, the constructed model was able to produce reliable results.This test was primarily performed to determine whether there was no overfitting; overfitting occurs when a created ANN can only handle a problem in the context of that specific data. As a result, while the study focused on using data from Eswatini, the results demonstrated that the data can be transferred and used with data from any country, region, continent, or sample of specification.
Only 170 data points were included in the first simulation results provided in the study using the main Eswatini dataset. The goal of this simulation was to see if the model could produce viable findings with limited amounts of data. This would be particularly useful in formulating predictions about the virus’s behaviour in circumstances where data were sparingly collected or big gaps of missing data existed. The results collected revealed some positive outcomes with few faults. However, the results were less accurate when compared to those obtained when bigger datasets were employed. There were also substantially larger margins in the death forecasts, which was a problem that persisted across all simulations. This contradicts the conclusions of the sensitivity analysis, which found that increasing the size of the training dataset had a minimal margin of change.
To build the training and testing datasets, a bigger dataset encompassing all of the data available at the time was also employed. The results were similar to those obtained during the training of the smaller dataset, but with a far higher level of precision. This enormous dataset was also used to create forecasts for the future. These predictions were found to be quite accurate, but as the number of days forecasted increased, the accuracy declined. Even while making these future predictions, the determined dynamics demonstrated that they can both account for the creation of a wave, which was a critical and extremely unusual aspect that was found. This suggests that the model was able to adjust the dynamics both positively and negatively without any external help based on the data patterns.
The model was created over a long period of time, with early tests and simulations carried out when there were few data available. Although it is not displayed in the findings, it was discovered that the model was unable to forecast the major changes in the wave—namely the crust and thrust—during the first wave. However, as the data grew larger, the model began to recognize these patterns, and the results improved, eventually leading to those that were reached. The results produced during these simulations and tests were more accurate than those obtained during research that used the mathematical model [
35,
36] to conduct tests. This is because, while average rates are employed in both cases, the generated PINNs model gradually learned to modify these rates or dynamics based on hidden patterns in the data. In comparison to [
6,
8], the results had similar margins of error, primarily due to data fitting because no future predictions were offered in these research.
The results show that the model is well adapted to making value predictions during the training period. As a result, the model is highly adapted to data fitting in situations when data were not gathered, were incorrectly input, or were lost. Another advantage of the architecture is that it returns the spreading rate, death rate and recovery rate, which were set up to function as modifying variables for the neural network’s PINNs component. However, as the number of projected days grows larger, the accuracy of the forecast decreases. This happens because the projections are based on the spread rate, mortality rate and recovery rate trends, all of which are based on outdated data. The wave format produced by active infections is also predicted by the model. The results show that the model is well equipped to make decisions. As a result, while the model is well-suited to making short-term predictions, it may also be used to make long-term predictions with a manageable margin of error.
The study had the misfortune of only lasting a few weeks. As a result, the model was unable to make a number of jumps, including the inability to forecast when a potential wave would occur. There have also been some new developments, such as the discovery that some infected individuals can become re-affected. As a result, the SIRD model would be more accurate than the SIRD model currently in use. Thus, future research into these areas, which are currently understudied, is necessary.
The lack of data and processing power was a major stumbling block during the project. As a result, we advocate developing a model that groups each of the SIRD populations by age for future research, as it has been proven that different age groups are impacted by the disease differently. Each of the metrics or rates can then be defined per age group using the well segmented data. We also suggest testing a model identical to the one employed in the study, but on a larger scale with more processing capacity.



























{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}