1. Introduction
Let
E stand for Banach space and
for an open set. Suppose that
is a continuous operator. A plethora of applications are thus reduced to solving the equation
A solution to this equation is needed in closed form. But this is attainable only in special situations. That is why most solution approaches are iterative when a sequence is developed that is convergent to under some conditions of the operator P and the starting point .
The existence and uniqueness of the solution’s results are usually developed for an equation like (
1). In this case, Equation (
1) has solutions and so it is needed to present and analyze iterative methods (ITs).
No matter which IT is utilized, there are three concerns. First, the iterations must exist in the domain
D. That is, if the IT requires the evaluation of an IT at all
, it must be assured that these iterates remain in the domain of the operator
P. If we refer to Newton’s method, the Fréchet derivative
which is a linear operator as well as the inverse
must be well defined at all
. That is why we usually provide conditions that ensure that the iterates exist provided that the IT initiates from an initial point
. Another more challenging concern is the convergence of the sequence
, and if their limits are indeed solutions to Equation (
1). A plethora of such results exists [
1,
2]. The first one is usually called local convergence, where we start by assuming the existence of some
, and then we provide some neighborhoods of
called convergence balls such that all of the initial points are in it, and all of the iterates produced by the IT exist and converge to
. The second type of convergence, usually called semilocal, does not rely on the existence of the solution
, but it shows certain, usually difficult to verify, conditions of the operator
P and the initial point
. However, under these conditions, the convergence of the sequence to
is assured. In the semilocal case, we also provide computable error estimates for the distances
or
, which are not given in the local convergence theorems. However, even these estimates are usually pessimistic.
A widely used single-step method is Newton’s (NA), defined as [
1,
3]
The convergence order of (NA) is two [
1]. But the inversion of the derivative
is required at each step. This inversion may not be possible or may very expensive to carry out.
The modified Newton’s method [
1,
2] is defined by
This method requires only the inversion of . But the convergence order of it is only one.
To avoid the generally expensive computation of the Fréchet derivative
of the operator
P and increase the convergence to be higher than one other ITs have been developed [
1,
3,
4,
5,
6,
7] using divided differences of order one [
1,
2]. The methods of chords or Regula falsi or the Secant method are some of the most used ITs for solving Equation (
1). They are defined by
where
denotes the space for mappings of
E into
E for linear operators that are bounded, and
is called a divided difference of order one. But the R-order of convergence is
which is larger than one but smaller than two. However, it is possible to still use divided differences and obtain a convergence order greater than
.
By utilizing the symmetric difference formula
we derive the Symmetric-Steffensen-type method (SSTM)
which is also of convergence order two [
4,
5]. But the divided difference
is used instead of the derivative
. Other Steffensen-type methods are studied in [
6,
7,
8,
9]. Generalizations of the SSTM have been suggested to increase the convergence order in combination with weight operators, and frozen derivatives.
Symmetries play a central role in the dynamics of physical systems. Quantum physics are at the core of symmetry principles. Symmetries do not only naturally appear in geometry. They appear every time that a mathematical object stays unchanged under transformations. Even and odd functions studied in calculus are examples of symmetry. Symmetric matrices or graphs are another example. Symmetries characterize the solutions of differential or integral equations. That is why it makes sense to consider iterative methods of a symmetric nature to solve such equations.
Let us revisit the family of methods defined by [
5]
where
is the number of iterations;
m is the number of steps;
are real numbers; and
is a linear weight operator [
10,
11]. The weight
is any real matrix function that satisfies
,
and
The convergence order 2
m is proven in [
5] using the Taylor series for
. A detailed favorable comparison with other competing methods using similar information has been carried out in [
5,
10,
11]. This includes the computation of the CPU time. It is because of these advantages that we picked method (
2) to demonstrate our technique. But, we noticed that there are also limitations to the approach [
5,
10,
11].
Motivation
Although method (
2) is derivative free, Theorem 1 in [
5] can be used provided that
and
exist. But these derivatives do not appear in (
2). Let us consider the real function
defined by
, for
and
for
provided that
are real parameters satisfying
and
. Choose
D to be any interval containing 0 and 1. Then,
solves the equations
. But the function
is not continuous at
. Hence, there is no assurance from Theorem 1 in [
5] that the sequence
is convergent to
. However, this sequence converges to
if, for example,
, and
Hence, the conditions of Theorem 1 in [
5] can be weakened.
There are no computable a priori estimates for . So, the number of iterations to be carried out to reach a desired error tolerance is not known in advance.
The uniqueness of the solution is not known in a neighborhood containing it.
The radius of convergence is unknown. Thus, the selection of assuring the convergence of the sequence to is a very difficult task.
The results in [
5] are restricted by
.
The more important and challenging semi-local analysis of the method (
2) has not been studied previously.
The limitations are the motivation for writing this article. Addressing these limitations is the novelty of this paper:
Novelty
The local analysis of convergence only uses conditions based on the operators in (
2).
The required number of iterations to reach an error tolerance is known in advance since a priori error estimates for become available.
A neighborhood of is determined containing no other solution.
A computable radius of convergence is provided, Thus, the solution of becomes possible.
The results are valid in the more Banach space.
The semi-local analysis of convergence is provided making use of the majorizing sequence.
It is worth noting that the concerns
–
always appear in the study of iterative methods using the Taylor series to show convergence such as the ones in [
1,
3,
4,
5,
6,
8,
9,
10,
11,
12,
13,
14,
15]. But our technique avoids the Taylor series and uses conditions only for the operators in the method. This way, the benefits
-
become possible.
Both types of analysis of convergence rely on the concept of the generalized continuity of the divided difference. This is how we extend the applicability of the method (
2). It this worth noting that the approach in this paper may be used to extend the applicability of other methods making use of inverses of linear operators along the same lines [
1,
3,
4,
12,
13,
14]. A similar approach was used for studying the convergence of some methods in [
15].
The divided difference in both the local and semilocal convergence analysis is controlled by a majorant real function. In particular, semilocal convergence relies on the scalar majorizing sequences being constructed a priori. The frozen derivatives replace the expensive in the general inversion of the linear operators at each substep of the iteration and still increase the convergence order. This way, the convergence of the method is governed by real functions and sequences that are easier to handle. The monotone convergence of the method in (
2) has not been addressed in this paper for Banach space valued operators. But we plan to study this type of convergence in future research in the setting of Hilbert space or partially ordered topological spaces using the extension of the fixed point theory in these spaces. The results are expected to be fruitful, since it has already been established in [
4,
5,
6,
7,
8,
9] that STMs have advantages over existing methods.
Notice also that, due to the a priori estimates we have provided, the minimum number of iterations needed to reach a desired tolerance is known in advance (see the error estimates (
7) and (
8) in Theorem 1, and (
19) and (
20) in the Theorem 2).
The rest of the article is divided as follows:
Section 2 and
Section 3 deal with local followed by semilocal analyses of convergence. The numerical experimentations appear in
Section 4 and the Concluding remarks in
Section 5.
2. Convergence 1: Local
Some concepts related to the order of convergence of iterative methods should be mentioned.
Let
be a sequence in
E which converges to
. Then, the convergence is of order
q,
if there exist a constant
and a natural number
, such that
or for
The convergence is said to be linear if
, and
C exists such that
Moreover, the error in the
iteration for
is defined by
where
q is the order of convergence and
M is a
linear function, i.e.,
.
The computational efficiency of an iterative method is
or
where
q is the order of convergence and
p is the computational cost per iteration. Moreover, if
are four consecutive iterates of an iterative method approximating the solution
of the equation
, then the following types of convergence have been suggested in [
16] and [
3], respectively
The former is usually called the computational order and the latter the approximate computational order of convergence. It is worth noticing that, since the solution is usually unknown, the second formula is more useful.
Define the open ball , where stands for the center of the ball and is the radius. Moreover, define the closed ball .
Let
. We give the definition of the proof of the local analysis of convergence for the method (
2) which relies on some conditions.
Suppose:
There exist continuous as well as nondecreasing functions (CND) , such that the equation admits the smallest solution which is positive (SSP). Denote such a solution by . Set .
There exists
solving the equation
and an invertible linear operator
T such that for all
,
and
Set .
The definition of
, and the condition
imply
Thus, the operator
is invertible by the Banach perturbation Lemma [
2] on linear operators (see also Lemma 1).
There exist CND
and
and
, such that, for each
,
,
, and provided that
is a weight function
and
Define the functions
on the interval
by
and for
The equations
admit SPS in the interval
. Thus, we denote such solutions with
, respectively.
These definitions assure that for each
and
Remark 1. (1) The functions and can be defined as follows:and The justification for these choices follows, in turn, from the calculations: Thus, it follows thatwhich justifies the choice of the function . Similarly, we can writeleading towhich justifies the choice of the function . (2) A popular pick for But this implies the invertibility of the function . Moreover, is a simple solution in this case. We do not assume the invertability of and it is not necessarily implied by any of the conditions.
This way, method (
2) can be employed to approximate solutions for the equation
which are not necessarily simple [
5]. Other choices are possible (see also the Numerical Section).
The following is a useful lemma [
2].
Lemma 1. Let Q be a linear operator satisfying . Then, the linear operator is invertible and Recall that is an approximate inverse of Q is , provided that is also a linear operator. Moreover, in this case, the following hold Q and are both invertible andand This result is also mentioned as the Banach lemma [
2].
Next, the local analysis of convergence for the method (
2) uses the conditions
–
as well as the preceding notation.
Theorem 1. Suppose that the conditions – hold and pick . Then, the following assertions holdfor and In particular for where . Proof. Mathematical induction shall establish these assertions. According to the hypothesis,
so the assertions (
6) holds if
. The application of conditions
and
give, in turn,
Thus,
exists, and
It also follows that the iterate
is well defined by the first substep of the method (
2). We can also write
leading, using (
3), (
11), and
, to
Hence, the iterate
, and the assertion (
7) holds provided that
.
Concerning the rest of the substeps in method (
2), since the iterates
are well defined, we obtain, in turn,
from which we deduce
The induction for assertion (
8) is completed for
. In particular, for
, we obtain
resulting in (
6) and (
10) provided that
. The inductions for (
6)–(
8) and (
10) are completed for
. But these calculations can be repeated if
replaces
in the preceding estimations.
Therefore, we have as in (
14) that
which implies that the iterate
, and
The uniqueness of the solution is discussed in the following result.
Proposition 1. Suppose that the condition holds in the ball for some ; there exists such that the last condition in holds and Set Then, the equation is uniquely solvable by in the region .
Proof. Suppose that there exists
, solving the equation
, and
, Then, define the divided difference
. Then, the condition
and (
16) imply
Hence, exists. Finally, from the identity , concluding that . □
Remark 2. It is clear that provided that all the conditions of Theorem 1 hold in Proposition 1.
3. Convergence 2: Semi-Local
The semi-local analysis of convergence relies on majorizing sequences and similar computations. But the solution and the function “” are exchanged by , and the function “”, respectively.
Recall that, a sequence
for which
holds is majorizing for
. Moreover, suppose that
exist.
Then, it follows that
and
Therefore, the study of the convergence of the sequence
is reduced to the study of the scalar sequence
[
2].
Suppose:
There exist CND such that the equation has a SPS. Denote such a solution by . Set
There exist CND , and .
Define the scalar sequences for
, some
,
and each
by
and
This sequence is shown to be majorizing for in Theorem 2. But first, a convergence condition is required for this sequence.
There exist a parameter such that for each ,
and
This condition and the formula (
17) imply that the sequence
is nonnegative, nondecreasing, and bounded from above by
. Consequently, the sequence
is convergent to its least upper bound which is a unique number. Denote such a number with
.
As in the local analysis, the scalar parameters and sequences relate to the functions in method (
2).
A point
and an invertible function
T exist, such that, for each
,
,
,
and
Set .
This condition and the definition of
imply, for
, that
Thus, . Hence, we can take
For each
and
and
.
Remark 3. The functions and can be chosen to beand As in the local analysis, the motivational calculations are:sojustifying the choice of the function . Similarlythus,which justifies the choice of the function . A popular choice for . The rest of the comments are omitted as they are similar to the ones in Remark 1.
The semilocal analysis of convergence is provided in the next result.
Theorem 2. Suppose that the conditions - hold. Then, the sequence is well defined in , remains in for each and is convergent to a solution on the equation such that Proof. As in the local analysis, mathematical induction is utilized to show the assertions
and
The assertion (
19) holds if
since
and the iterate
. Then, we have the estimates
Hence, the iterate
and the assertion (
20) hold for
.
Then, we can write
thus,
leading to
and
Hence, the iterates
and the iteration (
20) holds.
But
and similarly
leading to
so
and
Hence, the induction for the assertions (
19) and (
20) is completed and all the iterates of the method (
2) belong in
. The condition
implies that the sequence
is complete as it is convergent to
. Then, using (
19) and (
20), the sequence
is also complete in
E and, as such, it is convergent to some
. Then, by letting
in (
21) and the continuity of
P, we deduce that
. Finally, the assertion (
18) follows from the estimate
by letting
. □
The uniqueness of the solution follows.
Proposition 2. Suppose that there exists a solution to the equation for some ;
the last condition in holds in the ball and exists, such that Set .
Then, the only solution to the equation in the region is .
Proof. Suppose that
exists, solving the equation
and satisfying
. Define
. It follows from the last condition in
and (
22) that
so,
exists. Then, similarly to Proposition 1, from the identity
we conclude
. □
Remark 4. Under all the conditions of Theorem 2, take and in Proposition 2.
The limit can be replaced by in Theorem 2.
4. Numerical Experiments
In this section, we present numerical examples that confirm the local theoretical results and show the results of testing the method on systems of nonlinear equations. The calculations are carried out in GNU Octave 7.3.0. Systems of nonlinear algebraic and transcendental equations arise as a result of applying the difference method for solving boundary value problems or the quadrature method for solving integral equations.
Let us compute the radii of convergence for the Algorithm 1 for different values of the real parameter a and b. For this, consider the following nonlinear equation.
| Algorithm 1: The algorithm from method (2) for solving the system of nonlinear equation consists of the following steps: |
1. Select the starting approximation , real parameters a, b and the tolerance .
2. For while or (and) do:
2.1. calculate ;
2.2. calculate ;
2.3. calculate ;
2.4. calculate ;
if then
2.5. calculate ;
2.6. calculate and ;
2.7. calculate ;
2.8. for
2.8.1. calculate ;
2.8.2. calculate ;
2.9. set . |
Example 1. Let , , and the exact solutions is . Let
and
. Then, for the function
we have
and
. To define functions
and
we use the following equalities:
and
respectively. For
we obtain the following radii:
for , ;
for , ;
for , .
Now let us analyze the behavior of the method depending on the choice of function . We considered the following cases:
- (a)
If
, then this method was considered in [
5];
- (b)
If , then we have a multi-step Steffensen-type method.
Example 2. Consider the system of n equations Here , and the exact solution .
Let us choose
,
, and starting approximation
. We use the following stopping criterion for an iterative process
Here denotes the Euclidean norm.
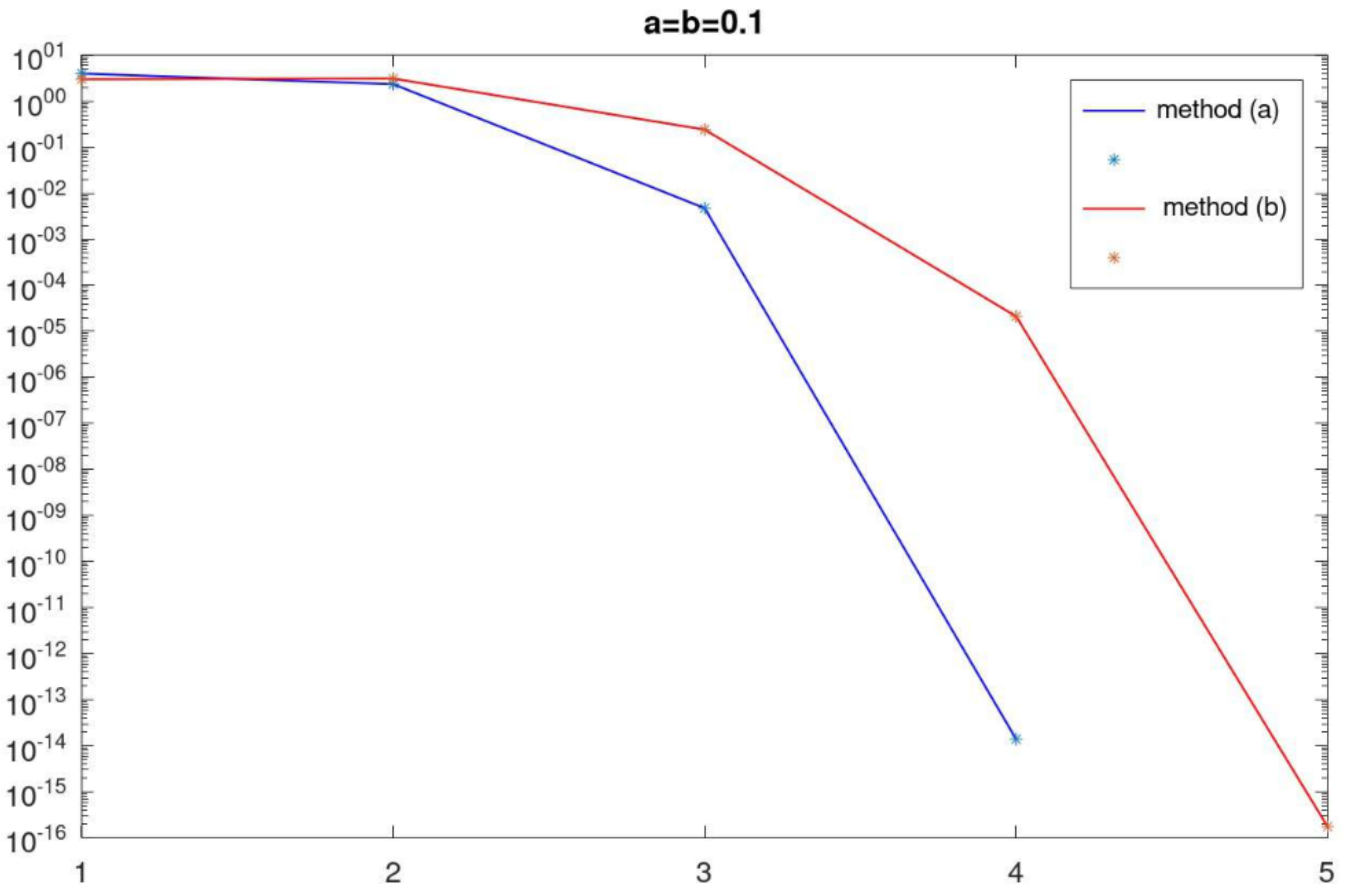
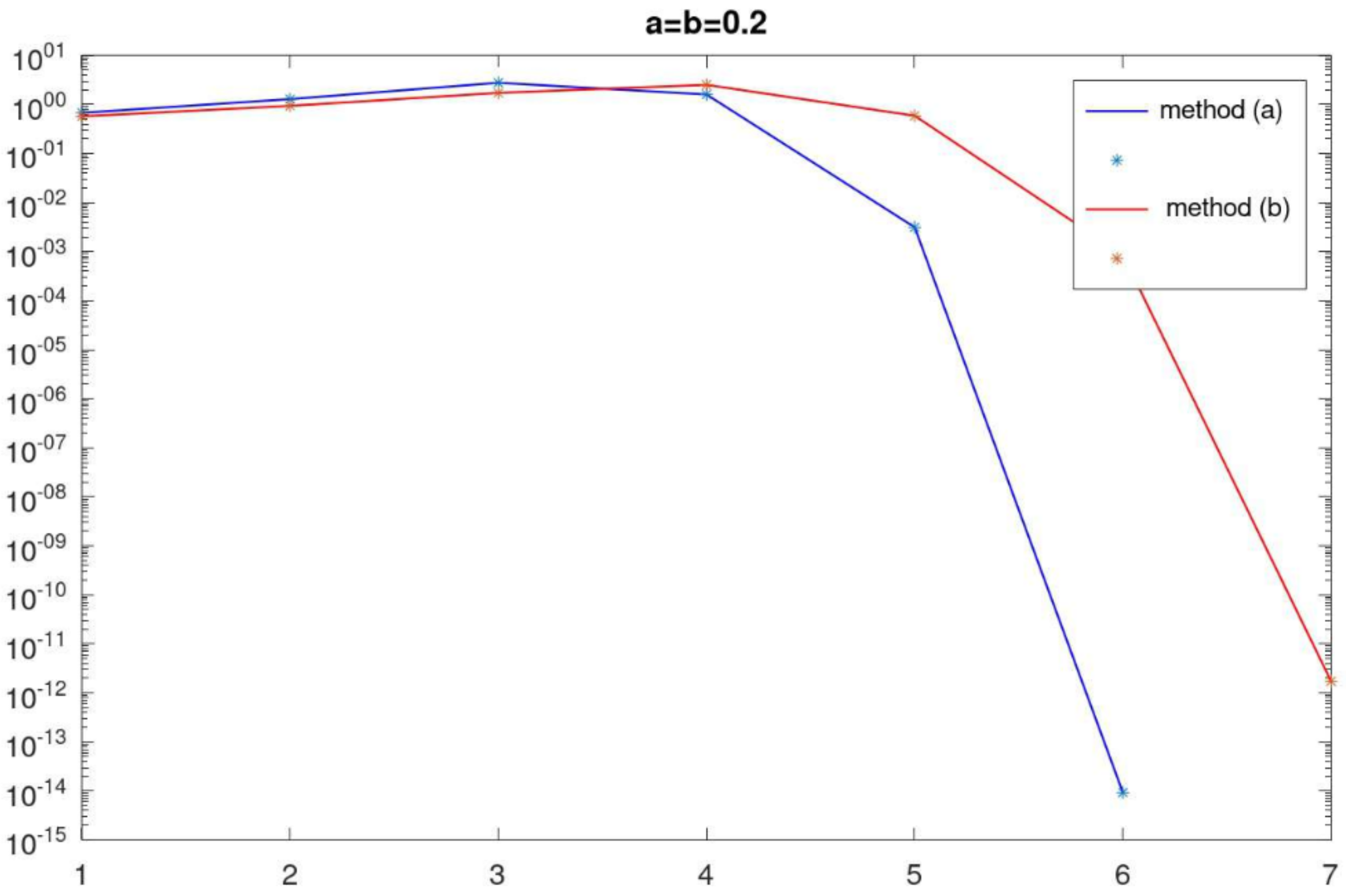
Figure 1 and
Figure 2 show the change in the correction’s norm at each iteration. The results are given for different values of parameters
a and
b.
The number of iterations of the method (
2) differs little for the considered function
. However, the following differences can be noted. Method (
2)-(a) converges no slower than method (
2)-(b); however, the computational complexity of one iteration is higher by
operations. Starting from a certain iteration, the correction rate of the method (
2)-(a) decreases faster than for the method (
2)-(b). In addition, the study of the considered method on different examples showed that it is advisable to choose parameters
a and
b close to zero. In this case, method (
2) converges for a larger number of initial approximations.
Example 3. Consider the boundary value problem One of the exact solutions is
. Denote
,
, where
and
. Using the approximation for the first and second-order derivatives
we obtain the following system of the nonlinear equations
with
. Let
,
and the initial approximation be
,
. We use
as the stopping criteria for this problem. The norm of residuals at each iteration is presented in
Table 1.



 ,
, 


{kind=link}
{kind=link}