

Multidimensional Epidemiological Survey Data Aggregation Scheme Based on Personalized Local Differential Privacy

Abstract
:1. Introduction
1.1. Related Work
- For users’ personalized privacy protection requirements, we improve the uOUE protocol that conforms to the ULDP model based on the OUE mechanism. By proving that the uOUE protocol satisfies the ULDP model and calculating the theoretical variance of the frequency estimation results, the proposed protocol has been deemed to have a low communication cost and high data utility;
- Considering the collection and processing of data in the EI scenario, we design a multidimensional ESD aggregation scheme based on PLDP. This scheme ensures the security and integrity of personal privacy data while maintaining the availability of data and achieves the secure, efficient, and accurate aggregation of ESD;
- Through the comparative analysis of mean square error (MSE) and communication cost with the other five LDP protocols, as well as the experimental results on two data sets, our scheme shows higher practicability and performance in ESD aggregation. In terms of multidimensional data aggregation, the scheme shows strong computing performance and more comprehensive functions and cleverly balances computing efficiency and privacy protection in the ESD aggregation scenario, providing a valuable practical solution for this field.
1.2. Organization
2. Preliminary Knowledge
2.1. Utility Optimization LDP
- (1)
- For any , there is only one:
- (2)
- For any input , obtain any output and satisfy the following:
2.2. PHE Algorithm
- Key generation: randomly select two large primes and and calculate , , then select generator ; let satisfy , quorum . Obtain the public key and private key ;
- Encryption: for any plaintext , select a random number , and make it satisfy . Encrypt to obtain ciphertext: ;
- Decryption: the plaintext is obtained by the formula: .
2.3. Utility Evaluation
3. uOUE Mechanism
3.1. Introduction to uOUE
3.2. Mechanism Description
- uOUE encoding
- 2.
- uOUE perturbation method
- 3.
- uOUE aggregation
4. ESD Aggregation Scheme Based on uOUE
4.1. Scheme Model
- ESOs : individuals or institutions in the EI survey send locally perturbed, encrypted, and signed data to ESWs. To protect ESO privacy, we apply the uOUE mechanism from Section 4. This involves mapping ESD to binary vectors and applying UE encoding to obtain perturbed data. ESOs then use identity-based signatures to safeguard the perturbed and signed data, ensuring data confidentiality and integrity;
- ESW : a personal, system, or private cloud that pre-aggregates ESD and receives perturbed and signed data from ESOs. aggregates these data after verifying signatures, employs the PHE algorithm, and forwards the report to the data control center, streamlining interactions and communication with the EDCC;
- EDCC : the EDCC is central to the ESD aggregation scheme, acting as the aggregator. It possesses a pair of public and private keys for homomorphic encryption and semantic security, as well as a pair of identity-based public and private keys. Its responsibilities include generating public and private key pairs for ESOs and ESWs, as well as managing the transmission and verification of their data. To facilitate the separation of aggregated ESD, the EDCC constructs a super-increasing sequence for this purpose.
4.2. Scheme Contents
4.2.1. Scheme Initialization
- EI user owns the attribute set ,. Each user has a -dimensional attribute value candidate set , which is the candidate value of the attribute . Value is 1 or 0; 1 is the candidate value, 0 indicates that it does not have the candidate value, and indicates the position corresponding to the candidate value;
- The EDCC selects safety parameter and two primes , and calculates and , where , , ; and are also two primes. Then, it selects generator , defines function , and calculates the public key and private key of the PHE algorithm, where ;
- The EDCC generates a super-increasing sequence , , which satisfies ; the length of is , , ;
- and are cyclic multiplicative groups with the same prime order , where is generated by , and is a bilinear map. The EDCC randomly selects a scheme private key and calculates the scheme public key ;
- The EDCC selects three hash functions: , and ( is SHA-256 hash algorithm);
- The EDCC publishes the scheme parameters, as follows:
4.2.2. Public–Private Key Pair Generation
- obtains the current timestamp , calculates the hash value using their own real identity , and sends a registration request to the EDCC;
- After receiving the user’s registration request, the EDCC checks whether is established. If yes, the EDCC computes pseudonym for user based on their real identity : the EDCC randomly selects , computes , , and returns pseudonyms and to ;
- verifies pseudonym : . If equal, use the pseudonym. (7) proves the process.
- ESO selects a random number as its private key and publishes its corresponding public key ;
- also selects private key and computes public key .
4.2.3. uOUE Perturbation
- fills in and converts into vector of length , as shown in (8).
- perturbs according to (5) obtain data , that is, perturbs each candidate value according to its sensitivity to obtain data : for sensitive data , the probability remains unchanged, and the probability of deflects. is thus obtained;
- computes , signs , and is the current timestamp, which can resist message replay attacks;
- sends report to through a secure channel.
4.2.4. Data Pre-Processing
- After receives the report, the effectiveness of is checked. The report is sent to at time point to check whether is established, and is the allowed delay of the scheme. If it holds, then is valid, otherwise it terminates;
- verifies the signature: . If it is equal, this indicates that the report from legal is received by , otherwise it is terminated. (9) proves the correctness of signature verification:
- obtains frequency statistics: . They are stored in the form of an array, , ;
- randomly selects and calculates the ciphertext according to (10):
- calculates , ;
- sends reports to the EDCC through a secure channel.
4.2.5. Data Aggregation
- The EDCC receives report to check the effectiveness of . If is valid, signature is verified; if it is invalid, this indicates that a replay attack was detected and the process is terminated;
- The correctness of is verified and compared with . If the equation is equal, the EDCC receives the report;
- The EDCC aggregates the data according to (11) and (12) to obtain ciphertext .
4.2.6. Data Acquisition
- Let in , , , , using to decrypt according to (13):
- 2.
- The EDCC performs frequency statistics on the ESD.
- is sensitive data:
- is non-sensitive data:
5. Scheme Analysis
5.1. Theoretical Analysis of uOUE Protocol
- is sensitive:
- is non-sensitive:
5.2. Comparative Analysis of uOUE Protocol
5.2.1. Comparison of Theoretical Results
5.2.2. Comparison of Experimental Results
- Experimental Settings:
- 2.
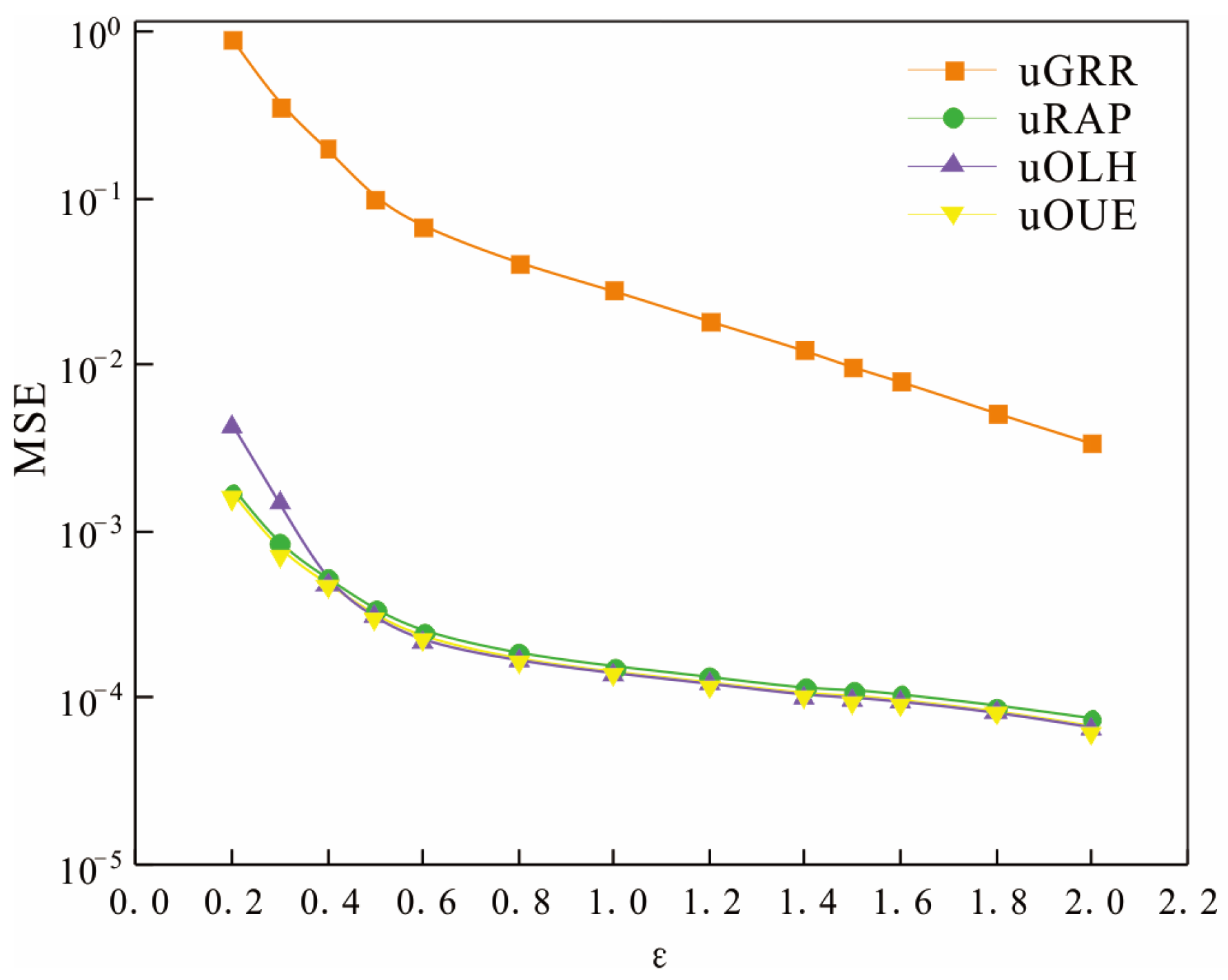
- The effect of on MSE
- 3.
- The effect of on MSE
5.3. Security Proof and Analysis
- 1.
- Initialization: sends generator and public key of multiplicative group to , where . The private key corresponding to is . In addition, is randomly selected as one of its guess values. This -query of corresponds to the final forgery result of ;
- 2.
- -inquiry (up to times): creates a , initially empty, with the element type of triple . When starts the -th query (set the query value to ), answers as follows:
- (1)
- If there is a term corresponding to in , then is the answer;
- (2)
- Otherwise, randomly selects .
if , then is calculated. Otherwise, is calculated.is taken as the response to the query, and is stored in the table; - 3.
- Signature query (up to times): When requests a signature of message , let satisfy ; represents the query value of the -th query. answers the question as follows:
- (1)
- If , then there is a triple in . is calculated and the reply to is . Because of , so is the signature of with secret ;
- (2)
- If , the process is interrupted;
- 4.
- Output: output . If , interrupts; otherwise, outputs as . .
- (1)
- Each of the queries of is answered by a random value, and the response to is as follows:
- When is answered by , it is known that is distributed in according to the randomness of ;
- When is answered by , is also distributed in .
- (2)
- The response obtained by to the signature query of is signed by the private key corresponding to the public key ( has obtained this), so the signature response obtained by is valid (relative to the public key it obtains).
5.4. Performance Analysis
5.4.1. Functional Comparison
5.4.2. Computational Overhead
6. Summary
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Giabicani, M.; Le Terrier, C.; Poncet, A.; Guidet, B.; Jean-Philippe, B. Limitation of life-sustaining therapies in critically ill patients with COVID-19: A descriptive epidemiological investigation from the COVID-ICU study. Crit. Care 2023, 27, 103. [Google Scholar] [CrossRef] [PubMed]
- Song, Q.X. New Coronavirus Pneumonia Epidemic-related Rumors and Its Mechanism of Generation and Dissemination—Discussion on the Cooperative Principle of Emergency Information Release. Lang. Plan. Res. 2021, 57–66. [Google Scholar]
- Feng, B.; Chao, L. Analysis of epidemic prevention and control behavior and influencing factors of employees in public places in the normalized prevention and control stage of COVID-19. Anhui J. Prev. Med. 2022, 28, 406–409. [Google Scholar]
- Blumenberg, C.; Barros, A.J. Electronic data collection in epidemiological research. Appl. Clin. Inform. 2016, 7, 672–681. [Google Scholar] [PubMed]
- Dong, E.; Ratcliff, J.; Goyea, T.D.; MS, A.K. The Johns Hopkins University Center for systems science and engineering COVID-19 Dashboard: Data collection process, challenges faced, and lessons learned. Lancet Infect. Dis. 2022, 22, e370–e376. [Google Scholar] [CrossRef] [PubMed]
- Sperber, A.D.; Bor, S.; Fang, X. Face-to-face interviews versus Internet surveys: Comparison of two data collection methods in the Rome foundation global epidemiology study: Implications for population-based research. Neurogastroenterol. Motil. 2023, 35, e14583. [Google Scholar] [CrossRef] [PubMed]
- Dwork, C.; Roth, A. The algorithmic foundations of differential privacy. Found. Trends Theor. Comput. Sci. 2014, 9, 211–407. [Google Scholar] [CrossRef]
- Lecuyer, M.; Atlidakis, V.; Geambasu, R.; Hsu, D.; Jana, S. Certified robustness to adversarial examples with differential privacy. In Proceedings of the 2019 IEEE Symposium on Security and Privacy (SP), San Francisco, CA, USA, 19–23 May 2019; IEEE: Piscataway, NJ, USA, 2019; pp. 656–672. [Google Scholar]
- Erlingsson, Ú.; Feldman, V.; Mironov, I.; Raghunathan, A.; Talwar, K.; Thakurta, A. Amplification by shuffling: From local to central differential privacy via anonymity. In Proceedings of the Thirtieth Annual ACM-SIAM Symposium on Discrete Algorithms, San Francisco, CA, USA, 6–9 January 2019; Society for Industrial and Applied Mathematics: Philadelphia, PA, USA, 2019. [Google Scholar]
- Duchi, J.C.; Jordan, M.I.; Wainwright, M.J. Local privacy and statistical minimax rates. In Proceedings of the 2013 IEEE 54th Annual Symposium on Foundations of Computer Science, Berkeley, CA, USA, 26–29 October 2013; IEEE: Piscataway, NJ, USA, 2013. [Google Scholar]
- Dwork, C. Differential privacy: A survey of results. In Proceedings of the International Conference on Theory and Applications of Models of Computation, Berlin, Germany, 25–29 April 2008. [Google Scholar]
- Wang, T.; Blocki, J.; Li, N.H. Locally differentially private protocols for frequency estimation. In Proceedings of the 26th USENIX Security Symposium (USENIX Security 17), Proceedings of the 26th USENIX Security Symposium (USENIX Security 17), Vancouver, BC, Canada, 16–18 August 2017. [Google Scholar]
- Liu, X.; Xia, G.; Xia, X.; Zong, C.; Zhu, R.; Li, J. Personalized privacy protection for spatio-temporal data. J. Comput. Appl. 2021, 9, 643–650. [Google Scholar]
- Tian, F.; Wu, Q.Z.; Lu, L.F.; Liu, H.; Gui, X.L. Personalized differential privacy protection mechanism for trajectory data publishing. Chin. J. Comput. 2021, 44, 709–723. [Google Scholar]
- Murakami, T.; Kawamoto, Y. Utility-optimized local differential privacy mechanisms for distribution estimation. In Proceedings of the 28th USENIX Security Symposium (USENIX Security 19), Santa Clara, CA, USA, 14–16 August 2019. [Google Scholar]
- He, X.Y.; Zhu, Y.W.; Zhang, Y. Utility optimization of local differential privacy mechanism based on OLH. J. Cryptogr. 2022, 9, 820–833. [Google Scholar]
- Cao, Y.R.; Zhu, Y.W.; He, X.Y.; Zhang, Y. Utility-optimized local differential privacy set data frequency estimation mechanism. Comput. Res. Dev. 2022, 59, 2261–2274. [Google Scholar]
- Gentry, C. Fully homomorphic encryption using ideal lattices. In Proceedings of the Forty-First Annual ACM Symposium on Theory of Computing, Bethesda, MD, USA, 31 May–2 June 2009. [Google Scholar]
- Paillier, P. Public-key cryptosystems based on composite degree residuosity classes. In Proceedings of the EUROCRYPT’99, Prague, Czech Republic, 2–6 May 1999; pp. 223–238. [Google Scholar]
- Boneh, D.; Lynn, B.; Shacham, H. Short signatures from the weil pairing. J. Cryptol. J. Int. Assoc. Cryptologic Res. 2004, 17, 297–319. [Google Scholar] [CrossRef]
- Jihoo, K. Data Science for COVID-19 (DS4C). Available online: https://www.kaggle.com/datasets/kimjihoo/coronavirusdataset (accessed on 18 May 2023).
- World Health Organization. Coronavirus 2019 (COVID-19). Available online: https://covid19.who.int/ (accessed on 3 May 2023).
- U.S. National Library of Medicine, ClinicalTrials.gov. Available online: https://www.clinicaltrials.gov/ (accessed on 6 June 2023).
- Hugging Face. Available online: https://huggingface.co/datasets?sort=trending&search=SARS (accessed on 13 May 2023).
- Chen, Y.W.; Martínez-Ortega, J.F.; Castillejo, P.; López, L. A homomorphic-based multiple data aggregation scheme for smart grid. IEEE Sens. J. 2019, 19, 3921–3929. [Google Scholar] [CrossRef]
- Chien, H.Y.; Su, C. A fault-tolerant and flexible privacy-preserving multisubset data aggregation in smart grid. Comput. Sci./Intell. Appl. Inform. 2020, 848, 165–175. [Google Scholar]
- Xu, S.H. Research on Privacy Protection Data Aggregation Scheme for Smart Grid. Master’s Thesis, Zhejiang Gongshang University, Hangzhou, China, 2022. [Google Scholar]
- Ren, H.; Li, H.W.; Liang, X.H.; He, S.B.; Dai, Y.S.; Zhao, L. Privacy-Enhanced and Multifunctional Health Data Aggregation under Differential Privacy Guarantees. Sensors 2016, 16, 1463. [Google Scholar] [CrossRef] [PubMed]
- Thantharate, P.; Thantharate, A. GeneticSecOps: Harnessing Heuristic Genetic Algorithms for Automated Security Testing and Vulnerability Detection in DevSecOps. In Proceedings of the 2023 6th International Conference on Contemporary Computing and Informatics (IC3I), Gautam Buddha Nagar, India, 14–16 September 2023. [Google Scholar]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Mechanism | MSE | Mechanism | MSE |
|---|---|---|---|
| GRR | uRAP | ||
| RAPPOR | uOLH | ||
| uGRR | uOUE |
| Mechanism | MSE | Mechanism | MSE |
|---|---|---|---|
| GRR | uRAP | ||
| RAPPOR | uOLH | ||
| uGRR | uOUE |
| Synthetic Data Set | COVID-19 Data Set | SARS Virus Data Set |
|---|---|---|
| Data size N | 100K | 50K |
| Data domain size d |
| Scheme | HB-MDA | FF-PPMA | DP-MMDA | Our Scheme | |
|---|---|---|---|---|---|
| Function | |||||
| Multidimensional data aggregation | √ | × | √ | √ | |
| Multidimensional and multisubset data aggregation | × | × | √ | √ | |
| Identity anonymity | × | × | √ | √ | |
| Eavesdropping attack | √ | √ | √ | √ | |
| Active threat | √ | × | √ | √ | |
| Differential attack | × | × | √ | √ | |
| EUF-CMA | × | × | × | √ | |
| Sign | Description | Time (ms) |
|---|---|---|
| Exponential operation on | 11.256 | |
| Multiplication operation on | 1.032 |
| Scheme | Encryption Stage | Decryption Phase | Aggregation Phase |
|---|---|---|---|
| HB-MDA | |||
| FF-PPMA | |||
| DP-MMDA | |||
| Our scheme |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Liu, X.; Liu, Q.; Wang, J.; Sun, H. Multidimensional Epidemiological Survey Data Aggregation Scheme Based on Personalized Local Differential Privacy. Symmetry 2024, 16, 294. https://doi.org/10.3390/sym16030294
Liu X, Liu Q, Wang J, Sun H. Multidimensional Epidemiological Survey Data Aggregation Scheme Based on Personalized Local Differential Privacy. Symmetry. 2024; 16(3):294. https://doi.org/10.3390/sym16030294
Chicago/Turabian StyleLiu, Xueyan, Qiong Liu, Jia Wang, and Hao Sun. 2024. "Multidimensional Epidemiological Survey Data Aggregation Scheme Based on Personalized Local Differential Privacy" Symmetry 16, no. 3: 294. https://doi.org/10.3390/sym16030294