1. Introduction
In the field of reliability analysis, the stress–strength model plays a pivotal role. This model characterizes the lifespan of a component with a stochastic strength denoted as
X, which is influenced by a random stress represented as
Y. Component failure occurs when applied stress surpasses the strength threshold (
), while component functionality is maintained when the strength exceeds the stress (
). Consequently, equation
serves as an indicator for evaluating component reliability. Stress–strength models are widely used in various fields of research, especially engineering, including the simulation of the degradation of concrete pressure vessels, degradation of rocket engines, persistent fatigue of ceramic components and degradation of aircraft frames (see [
1]). For further applications in engineering, quality control, medicine, psychology, and mechanics of materials, see [
2,
3,
4,
5].
In recent decades, numerous scholars have extensively explored the reliability estimation of single-component stress–strength models under various data types and distribution assumptions related to stress and strength. Kotz et al. [
3] provided a comprehensive review of the research development on the reliability issues of stress–strength models up to the year 2003. Baklizi [
6] investigated the reliability issues of single-component stress–strength models when stress and strength follow exponential distributions based on recorded values, employing Bayesian methods. Kundu and Gupta [
7] discussed the reliability issues of single-component stress–strength models when stress and strength follow Weibull distributions with the same shape parameter but different scale parameters, using both maximum likelihood estimation and asymptotic maximum likelihood estimation. Lio and Tsai [
8], based on progressive Type I censoring samples, obtained point estimates of reliability parameters for single-component stress–strength models using maximum likelihood estimation. They also derived asymptotic confidence intervals and Bootstrap confidence intervals for the parameters, where stress and strength follow double-parameter Burr XII distributions. Al-Mutairi et al. [
9] employed methods such as consistent unbiased minimum variance, maximum likelihood estimation, Bayesian estimation, and Bootstrap to study point estimates and interval estimates of parameters and reliability for single-component stress–strength models, where stress and strength follow Lindley distributions with different shape parameters. Nadar et al. [
10] obtained point estimates and interval estimates of parameters for single-component stress–strength models when stress and strength follow Kumaraswamy distributions with different parameters, using classical statistical methods and Bayesian methods. Bai et al. [
11], assuming stress and strength follow truncated proportional hazard rate distributions, provided maximum likelihood estimates and pivotal quantity estimates for model parameters, along with the calculation of asymptotic confidence intervals, corrected generalized confidence intervals, and Bootstrap confidence intervals for the parameters. de la Cruz et al. [
12] discussed the reliability issues of single-component stress–strength models when stress and strength follow independent unit-half-normal distribution models, using both maximum likelihood estimation and bootstrap techniques to construct confidence intervals of model parameters. Recently, Yousef et al. [
13] obtained various point and interval estimators based on independent progressive type-II censored samples from two-parameter Burr-type XII distributions when the strength variable was subjected to the step-stress partially accelerated life test.
In the context of the stress–strength model, the relationship between stress and strength is not inherently independent, a variety of dependencies exist between them. These varying dependencies consequently have diverse impacts on the system’s reliability. Primarily, there are two methods to characterize the dependency between stress and strength. One approach is based on the joint distribution function between stress and strength, such as the bivariate Weibull distribution (see [
14]), bivariate conditional exponential distribution (see [
15]), and bivariate log-normal distribution (see [
16]). However, a drawback of this method is that the joint distribution often assumes that both marginal distributions are of the same type. The other approach involves the use of copula functions between stress and strength. Domma and Giordano [
17] were the first to employ the Farlie Gumbel Morgenstern (FGM) copula to characterize dependence in stress–strength models, where stress and strength follow Burr III distributions with different parameters. Domma and Giordano [
18], based on stress and strength following different parameters of the Dagum distribution, utilized the Frank copula to characterize the dependence and studied the reliability of stress–strength models. Recently, James et al. [
19] assumed that the dependence between stress and strength is characterized by the FGM copula, with marginal distributions being different parameter Rayleigh distributions. They employed maximum likelihood estimation, marginal inference methods, and semi-parametric methods to conduct statistical analysis on the reliability of single-component stress–strength models.
The aforementioned studies have assumed that the strength
X should be smaller than the stress
Y. However, as investigated by Kotz et al. [
3], many electronic devices exhibit functional limitations at both high and low temperatures. In this paper, we consider the reliability
, where
and
are bivariate random stress variables and X is a random strength variable. The strength
X should not only be greater than stress
but also be smaller than stress
. It may be a useful relationship in many areas.
Reliability engineering: this model is capable of predicting the probability that a certain system or component will fail under a specific predetermined load. Engineers are then able to optimize the design and implement appropriate precautions to minimize the risk of failure. For example, X can be a measure of design performance, such as energy efficiency or cost-effectiveness, and can represent the minimum and maximum limits of target performance, and R can assess the probability that the current design meets these performance targets.
Supply chain Management: Enterprises can use this model to assess demand fluctuations in the supply chain. For example, ensuring that inventory levels are maintained within a safe range can meet customer demand while avoiding resource overhang.
Finance field: we can use this model to quantify financial risks. By calculating the probability of the price fluctuations of a certain stock or asset within a given range in a specific period of time, investors can assess and manage risks more accurately and formulate more effective investment strategies.
Medical field: when evaluating the effectiveness of a drug or therapy, X can represent a medical indicator after treatment, such as blood pressure, cholesterol levels, or the percentage of tumor shrinkage. and are defined as clinically significant improvement thresholds.
Estimation of this reliability, predicated on independent sampling, has been explored in studies, see [
20,
21,
22,
23,
24]. Emura and Konno [
25] derived the probability
assuming a trivariate normal distribution for
, with conditional independence between
. Additionally, Burcu and Selim [
26] investigated the stress–strength reliability model
, utilizing a copula-based approach to account for dependencies between stresses, under the assumption that the component’s strength lies within these stresses.
To the best of our knowledge, until now a similar task has never been attempted for the evaluation of R, where are statistics interdependent. However, this problem is common in daily life, for example, the component strength and stresses are often interdependent due to shared environmental factors, and a stronger system or component can tend to withstand higher levels of stress. Thus, in this study, we investigate the stress–strength reliability model R under the assumption that the strength of a component is between dependent stresses, and stresses and are also dependent through a copula-based approach. We model the dependence between stresses and strength variables by Clayton copula functions. Initially, we estimate the dependence parameter using the method of moments. Subsequently, maximum likelihood estimation (MLE) and Bayesian estimation techniques are employed to obtain point estimates and interval estimates for model parameters. Finally, through numerical simulations and real data analysis, we further validate the accuracy and practicality of our findings. Our work primarily contributes to two main areas: First, under the conditions of bivariate stress, we have not only taken into consideration the dependence of stress and strength but also the mutual dependence between stresses. Second, using the method of concomitant order statistics, we have obtained the progressive Type II censored sample of the ternary distribution. These novel contributions augment the understanding of bivariate stress, offer new tools for analyzing censored samples in ternary distributions, and lay a solid foundation for future research on general dependence structures and multi-component stress–strength issues.
The subsequent sections of this paper are structured as follows.
Section 2 provides an exposition on copula theory (Archimedean copula), model description and progressive Type II censored scheme. In
Section 3, we introduce the method-of-moment for the dependence parameter and the inference of
R and model parameters, using MLE, and Bayesian methods. Illustrative simulations and the presentation of real data analysis are found in
Section 4 and
Section 5, respectively. Concluding remarks are outlined in
Section 6.
4. Simulation
This section presents simulation results to evaluate the effectiveness of the aforementioned techniques. By considering various combinations of
and different censoring schemes (as shown in
Table 1), and using a Clayton copula model with varying levels of dependence (
), we assess the performance of point and interval estimations based on mean bias (AB), mean square error (MSE), interval length (IL), and coverage probability (CP). Regarding the parameters, maintaining generality, we assign (
) as (0.2, 0.4, 0.5) and based on (
6), the real values of
R are (0.43, 0.50, 0.55, 0.60).
Under progressive type II censored schemes, the stress–strength dependent samples can be generated by taking the following Algorithm 2, first, let
Note, that steps 1–3 in Algorithm 2 can be implemented using the “rcopula” package in R language. Please refer to Listing A1 in the
Appendix A for the specific code.
For
and the obtained lifetime data, using the moment method (
Section 3.1), we obtain
, which is shown in
Table 2.
| Algorithm 2 The algorithm of generated progressive type II censored scheme sample. |
- Input:
the progressive type II censored schemes , and - Output:
the progressive type II censored sample
- 1:
Generate independent n dimension uniform vectors: , and - 2:
Calculate and where and are the pseudo-inverse of and respectively; - 3:
Set and then is a random sample from - 4:
Under the progressive type II censored schemes , obtain the censored sample
where is progressive type II censored order statistic and and are concomitants of order statistics.
|
According to Algorithm 2, the observed data of progressive type II censored scheme were obtained. For MLE, we employ the Newton–Raphson and Delta techniques to derive point estimators and interval estimations of unknown parameters and reliability, respectively. The entire process is replicated 10,000 times. Occasionally, the previously derived asymptotic confidence intervals may exhibit a negative lower limit; therefore, we utilize logarithmic transformation to develop asymptotic confidence intervals (see sub
Section 3.2.2). For Bayesian estimation, following Congdon’s recommendations (see [
41]), we have evaluated nearly non-informative proper priors by setting hyperparameters as
and
. In the Metropolis–Hastings algorithm (Algorithm 1), we set N = 10,000 and A = 1000 for simulation purposes with 1000 iterations performed.
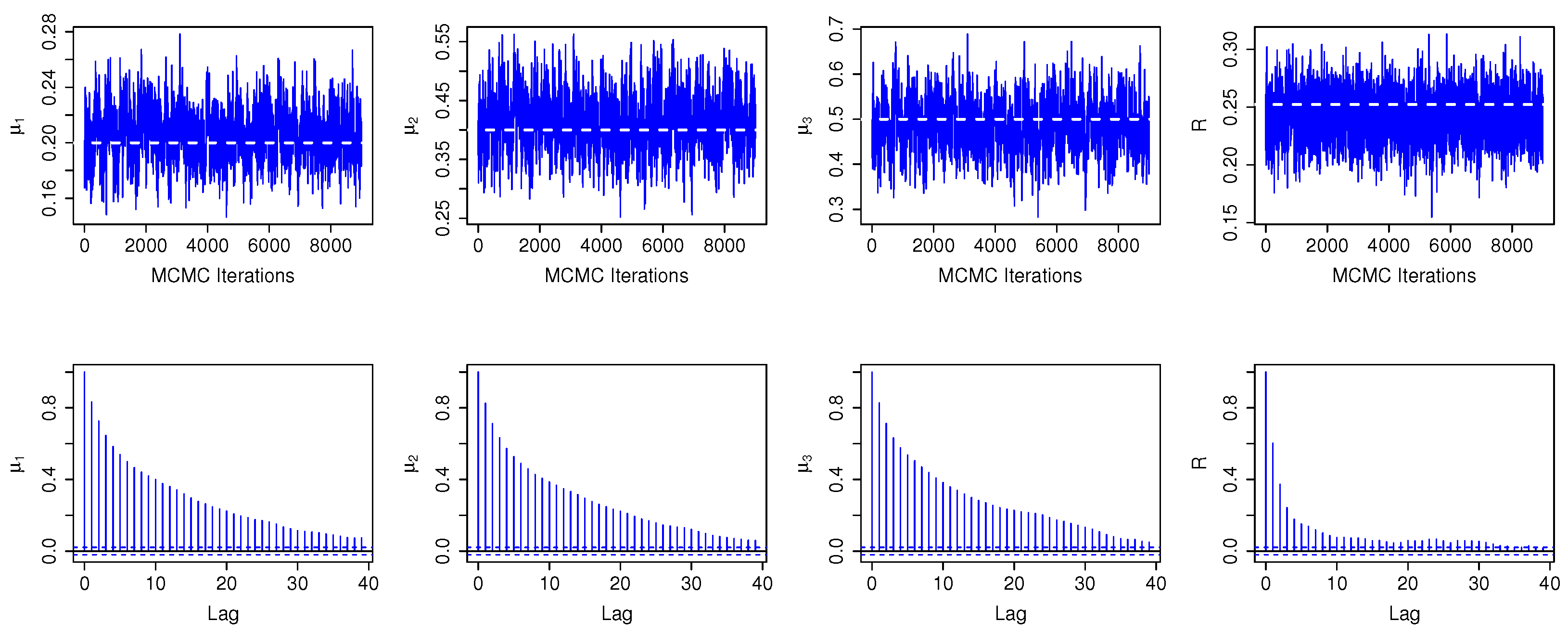
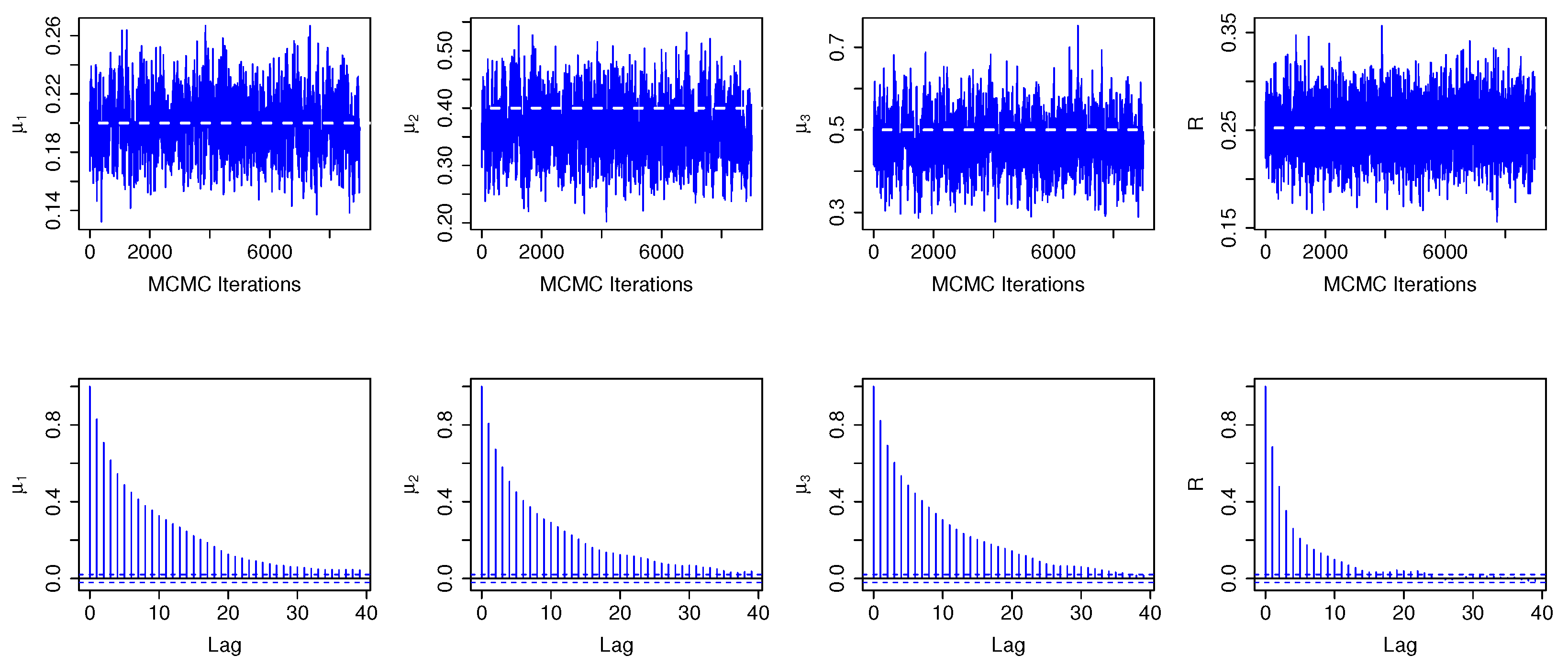
It should be noted that MCMC output analysis is necessary for assessing the convergence of the iteration process in the M-H algorithm, and partial results are presented in
Figure 1 and
Figure 2 (when n = 100, m = 20; CS = S1 and S2).
It can be seen from
Table 3 and
Table 4 that when the dependent parameters and the censored scheme are given time, the deviation and MSE of the maximum likelihood estimation and Bayes estimation of the model parameters and reliability
R gradually decrease with the increase in sample n. When the sample, dependent parameters, and censored scheme are given time, the Bayesian estimation results are better than the maximum likelihood estimation. When the sample and the censored scheme are given, the model parameters and reliability R do not change significantly with the increase in the dependent parameters. When samples and dependent parameters are given, the estimated values of parameters and reliability under scheme S2 are significantly better than those under censored S1, which provides suggestions for our actual data analysis.
As can be seen from
Table 5 and
Table 6, when the dependent parameters and censored scheme are given, ACI and IL of HPD CIs of model parameters and reliability
R gradually decrease with the increase in the sample size, but CP changes are not obvious. When samples, dependent parameters and censored schemes are given, the IL of HPD CIs is smaller than that of ACI. When the sample and the censored scheme are given, the IL of the model parameters and reliability R interval estimation decreases with the increase in the dependent parameters. When samples and dependent parameters are given, the interval IL of parameters and reliability estimated in scheme S2 is significantly smaller than that in scheme S1, but CP changes insignificantly.
Through the above analysis, it is found that better estimation results can be obtained by using Bayesian estimation under the S2.
5. Real Data Application
In this section, we conduct a practical investigation using three actual datasets. Data 1 and Data 2 were examined by [
42] for stress–strength reliability analysis and Data 3 was explored by [
43] for stress–strength reliability estimations. All the datasets underwent analysis conducted by [
44]. In this instance, the three datasets serve as illustrative examples of the aforementioned techniques. The specific details of these four datasets are outlined below.
Data 1: 693.73, 704.66, 323.83, 778.17, 123.06, 637.66, 383.43, 151.48, 108.94, 50.16, 671.49, 183.16, 727.23, 257.44, 291.27, 101.15, 376.42, 163.40, 141.38, 700.74, 262.90, 353.24, 422.11, 43.93, 590.48, 212.13, 303.90, 506.60, 530.55, 177.25
Data 2: 71.46, 419.02, 284.64, 585.57, 456.60, 688.16, 662.66, 113.85, 187.85, 45.58, 578.62, 756.70, 594.29, 166.49, 707.36, 99.72, 765.14, 187.13, 145.96, 350.70, 547.44, 116.99, 375.81, 119.86, 581.60, 48.01, 200.16, 36.75, 244.53, 83.55
Data 3: 6.53, 7, 10.42, 14.48, 16, 10, 22.70, 34, 41.55, 42, 45.28, 49.40, 53.62, 63, 83, 84, 91, 108, 112, 129, 133, 133, 139, 140, 140, 146, 149, 154, 157, 160, 160, 165, 173, 176, 218, 225, 241, 248, 273, 277, 297, 405, 417, 420, 440, 523, 583, 594, 1101, 1146, 1417
To ensure a more efficient analysis of dependencies, it is crucial to maintain a uniform sample size across all datasets. Currently, the sample sizes for Data 1 and Data 2 are both 30, while those for Data 3 exceed this number. To address this issue, we utilized the ’sample()’ function in R to randomly select two sets of 30 data points each from Data 3, which were labeled as Data∗3.
Data∗3: 173.00, 16.00, 140.00, 49.40, 22.70, 133.00, 146.00, 273.00, 583.00, 112.00, 523.00, 277.00, 241.00, 10.42, 42.00, 176.00, 218.00, 1417.00, 417.00, 14.48, 140.00, 1146.00, 594.00, 297.00, 53.62, 154.00, 10.00, 7.00, 165.00, 45.28
Without loss of generality, let Data 1 represent stress
, Data 2 represent strength
X, and Data
∗3 represent stress
. For ease of calculation, all the data are divided by 1000, and sorted by COS; the transformed complete data are as follows in
Table 7.
Assuming that X follows the PRHR model with distribution function , follows the PRHR model with distribution function , and follows the PRHR model with distribution function , where the baseline distribution is given by .
First, it was checked whether the PRHR model can be used or not to analyze the three data sets separately. With the estimated parameters, for
X,
and
, the Kolmogorov–Smirnov statistics and the corresponding
p-value and AD statistics and the corresponding
p-value are given in
Table 8; the empirical distribution functions are given in
Figure 3. The
p-value indicates that the PRHR model adequately fits these data sets.
By employing the moment method (
Section 3.1), we determine that the dependent parameter
for
is estimated as
. Furthermore, we utilize a goodness-of-fit test for copula to discern the dependence structure between
X,
, and
. This test is rooted in the multiplier central limit theorems and was introduced by [
45]. We present the goodness-of-fit test results for Clayton, Gumbel and Frank copula applied to
X and
and
in
Table 9. The
p-value indicates that the Clayton copula provides an adequate fit for the dependence of these data sets.
Based on complete data sets (
Table 7), the MLEs and Bayesian estimator and 95% ACIs and HPD CIs of
and
R are given in
Table 10, and trace plots are given in
Figure 4. As can be seen from
Figure 4, the estimated value has good convergence and stability.
For illustrative purposes, two different progressive type II censored samples have been generated from the above sets:
Based on schemes
and
the data sets are as follows in
Table 11 and
Table 12, respectively. The MLEs and Bayesian estimator and 95% ACIs and HPD CIs of
and
R are given in
Table 13, and trace plots are given in
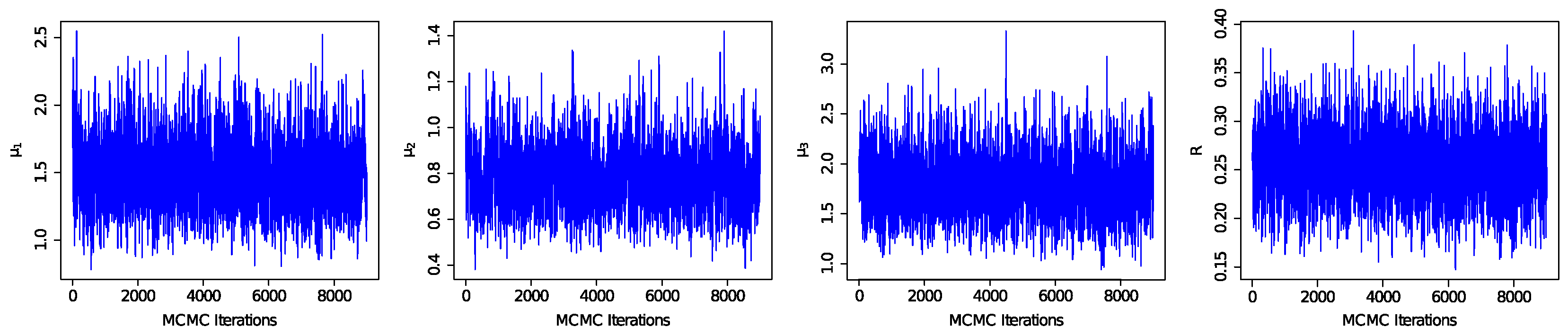
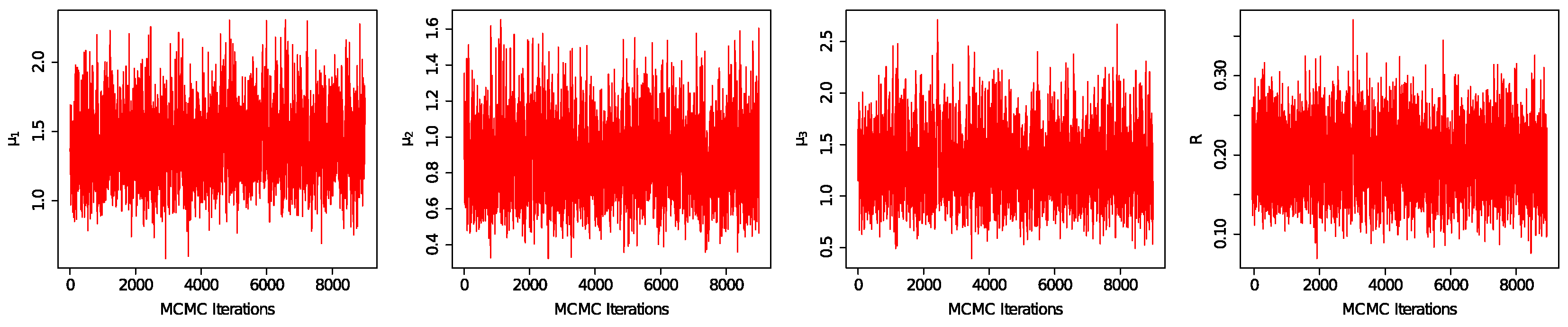
Figure 5 and
Figure 6, respectively. As can be seen from
Figure 5 and
Figure 6, the estimated value has good convergence and stability. By comparing the complete sample and
and
, it is easy to find that the estimated results of scheme
are very close to the complete sample.











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}