1. Introduction
One of the most fundamental and significant fields in statistics is predictive analysis, which involves extracting information from historical and current data to predict future trends and behaviors. One of the many possible forms of prediction is the Bayesian predictive approach, which was first introduced by Aitchison [
1], who demonstrated its advantage on the Kullback–Leibler (KL) divergence over plug-in predictive densities. Bayesian predictive-density estimation has been applied to different statistical models, including but not limited to the following: Aitchison and Dunsmore [
2], who obtained Bayesian predictive distributions based on random samples from binomial, Poisson, gamma, two-parameter exponential, and normal distributions; Escobar et al. [
3], who discussed the application of Bayesian inference to density-estimation models, using Dirichlet-process mixtures; and Hamura et al. [
4], who used a number of Bayesian predictive densities to introduce prediction for the exponential distribution. Hamura et al. [
5] studied the Bayesian prediction distribution of a chi-squared distribution, given a random sample from another chi-squared distribution under the Kullback–Leibler divergence.
Another form of prediction is the Wald predictive approach [
6], which follows a non-Bayesian framework. This approach was considered via the concept of predictive likelihood [
7]. Awad et al. [
8] introduced a review of several prediction procedures and a comparison between them. Wald predictive density was among these procedures.
One way to check the validity of the prediction procedure is by testing the closeness between the classical distribution of future statistics and the predictive distribution by using divergence measures between the two probability distributions. Several divergence measures have been defined in the literature and have been used to measure the distance between pairs of probability-density functions.
Considering the two probability distributions
and
, Kullback and Leibler [
9] introduced the Kullback–Leibler divergence measure, which measures the information gain between two distributions. The Kullback–Leibler divergence measure belongs to the family of Shannon-entropy distance measures, defined as
Lin [
10] introduced the Jensen–Shannon divergence, which is a symmetric extension of the Kullback–Leibler divergence that has a finite value. In a similar approach, Johnson and Sinanovic [
11] provided a new divergence measure known as the resistor-average measure. This measure is closely related to the Kullback–Leibler divergence mentioned in (
1), but it is symmetric.
Do et al. [
12] combined the similarity measurement of feature extraction into a joint modeling and classification scheme. They computed the Kullback–Leibler distance between the estimated models. Amin et al. [
13] used the Kullback–Leibler divergence to develop a data-based Bayesian-network learning strategy; the proposed approach captures the nonlinear dependence of high-dimensional process data.
Jeffreys [
14] introduced and studied a divergence measure called the Jeffreys-distance or J-divergence measure, which is considered as a symmetrization of the Kullback–Leibler divergence. The Jeffreys measure is a member of the family of Shannon-entropy distance measures, defined as
Taneja et al. [
15] gave two different parametric generalizations of the Jeffreys measure. Cichocki [
16] discussed the basic characteristics of the extensive families of alpha, beta, and gamma divergences including the Jeffreys divergence. They linked these divergences and showed their connections to the Tsallis and Rényi entropies. Sharma et al. [
17] found the closeness between two probability distributions, using three similarity measures derived from the concepts of Jeffreys divergence and Kullback–Leibler divergence.
Rényi [
18] introduced the Rényi divergence measure, which is related to Rényi entropy and depends on a parameter called
r-order. The Rényi measure of order
r is defined as
Note that In other words, the Rényi measure of order 1 is basically the Kullback–Leibler measure.
The Rényi measure is used in physics and is called Tsallis entropy [
19]. Krishnamurthy et al. [
20] constructed a nonparametric estimator of Rényi divergence between continuous distributions. Their method consists of constructing estimators for certain integral functionals of two densities and transforming them into divergence estimators. Sason et al. [
21] created integral formulas for the Rényi measure. Using these formulas, one can obtain bounds on the Rényi divergence as a function of the variational distance, assuming bounded relative information.
Sharma and Autar [
22] suggested another generalization of Kullback–Leibler’s information, called relative information of type
r, which is given by
Note that
Taneja and Kumar [
23] proposed a modified version of the relative-information-of-type-
r measure as a parametric generalization of the Kullback–Leibler measure and then considered it in terms of Csiszár’s
f-divergence.
Sharma and Mittal [
24] generalized the Kullback–Leibler divergence measure to a measure called the
r-order-and-
s-degree divergence measure, defined as
From Equation (
5), we can see that:
- (i)
which is basically the Rényi measure defined in (
3);
- (ii)
where
- (iii)
which is basically the Kullback–Leibler measure defined in (
1).
Taneja and Kumar [
23] conducted a full study about the
r-order-and-
s-degree divergence measure.
The chi-square divergence measure or Pearson
measure [
25] belongs to a family of measures called squared-
distance measures, defined as
Note that
The symmetric version of chi-square divergence is given in [
23,
26].
Hellinger [
27] defined the Hellinger divergence measure. This measure belongs to the family of squared-chord distance measures, defined as
Note that
González-Castro et al. [
28] estimated the prior probability that minimizes the divergence by using the Hellinger measure to measure the disparity between the test data distribution and the validation distributions generated in a fully controlled manner. Recently, Dhumras et al. [
29] proposed a new kind of Hellinger measure for a single-valued neutrosophic hypersoft set and applied it to dealing with the symptomatic detection of COVID-19 data.
Bhattacharyya [
30] defined the Bhattacharyya measure. This measure belongs to the family of squared-chord distance measures, defined as
The Bhattacharyya measure is closely related to the Hellinger measure defined in (
7).
Aherne et al. [
31] presented the original geometric interpretation of the Bhattacharyya measure and explained the use of the metric in the Bhattacharyya bound. Patra et al. [
32] proposed an innovative method for determining the similarity of a pair of users in sparse data. The proposed method is used to determine how the two evaluated items are relevant to each other. Similar to both Bhattacharyya’s and Hellinger’s measures, Pianka’s measure [
33] between two probability distributions has values between 0 and 1. Recently, Alhihi et al. [
34] introduced Pianka’s overlap coefficient for two exponential populations. A complete study of several divergence measures can be found in [
26,
35,
36].
From the divergence measures (
1)–(
8), one can conclude that:
Each of the divergence measures (
1)–(
6) is positive if
and equals zero if and only if
.
From (
7)
if
and
if and only if
From (
8),
if
and
if and only if
For this paper, we evaluated the Bayesian and the Wald predictive distributions of a future statistic based on a past sufficient statistic from samples taken from the normal density. Several divergence measures were used to test the closeness between the classical distribution of the future statistic and the predictive distributions, including the two approaches: Bayesian and Wald. We used the hypothesis-testing technique to compare the behavior of these divergence measures with respect to the closure test between the two distributions. The main contribution of this work is to provide a comprehensive study of eight divergence measures in a case of normal distribution using both Bayesian and non-Bayesian (Wald) predictive approaches. To the best of our knowledge, this study has not been previously mentioned in the literature.
The rest of this paper is organized as follows: In
Section 2, we evaluate the Bayesian and the Wald predictive distributions of future statistic
V based on past sufficient statistic
W from normal density. In
Section 3, we find divergence measures between the classical distribution of future statistics and the predictive distributions found in
Section 2. In
Section 4, we obtain percentiles of divergence measures and test closures of the predictive distributions, using the two approaches (Bayesian and Wald) to the classical distribution. A real-life application is presented in
Section 5. Finally, we provide a brief conclusion in
Section 6.
2. Predictive Distributions
Let be independent and identically distributed (i.i.d.) past random variables and let be i.i.d. future random variables, where and are independent. Consider a past sufficient statistic and a future statistic . In this section, we construct Bayesian and Wald predictive-density functions of the future statistic V based on the past sufficient statistic W from the normal density.
2.1. Bayesian Predictive Distribution
Let
be
past random variables with probability-density function (pdf)
and let
be
future random variables with pdf
. Assume that
is a random variable with prior density
for
. Consider a past sufficient statistic
with pdf
and a future statistic
with pdf
. The posterior-density function [
37] of
, given
, is defined as
The following theorem provides a Bayesian method to construct predictive distributions.
Theorem 1 ([
37])
. Let be a past sufficient statistic and let θ be a random variable with prior density for Assume that is a future statistic with pdf . The Bayesian predictive-density function of V, given , is given by where is the posterior-density function of θ, given , defined in (10). The next two theorems provide the Bayesian predictive distributions for some statistics. Theorem 2 below presents the Bayesian predictive distribution of the future statistic based on the past sufficient statistic from random samples taken from normal density; the choice of these statistics is based on the fact that we need statistics that best describe the characteristics of the data set, and they are closely related to the mean of the data set. Note that the choice of W is a completely sufficient statistic for the parameter under consideration. A similar result is obtained in Theorem 4 for the same statistics V and W, to obtain the Wald predictive distribution.
We use the following notations to represent some distributions that appear in the results of Theorems 2 and 3 below: the normal distribution with mean and variance is denoted by ; the gamma distribution with shape parameter and scale parameter is denoted by Gamma and the generalized inverted beta distribution with shape parameters , and p is denoted by InBe.
Theorem 2. Let and , where δ is known. Assume that and are independent and that and If is known and is unknown with prior distribution , where a and b are assumed to be known, the Bayesian predictive distribution of V, given , is Proof. It is easy to see that the past sufficient statistic
, given
follows the normal distribution
and that
, given
, follows the normal distribution
. In other words, the classical distribution of the future statistic
V, given
, is
Now, using (
10), the posterior-density function of
, given
, is equal to
Therefore, the posterior-density function of given , is the normal distribution .
Applying Equation (
11), the Bayesian predictive-density function of
V, given
, can be derived as
By evaluating this integral, the Bayesian predictive-density function of
V, given
, is
where
Which represents the normal distribution . □
The following theorem presents the Bayesian predictive distribution of the future statistic based on the past sufficient statistic from random samples taken from normal density. The choice of these statistics is based on the fact that we need statistics that best describe the characteristics of the data set. The choice of V and W is closely related to the variance of the data set, and it is often used to represent data too. Note that a similar result is obtained in Theorem 5 for the same statistics V and W, to obtain the Wald predictive distribution.
Theorem 3. Let and where δ is known. Assume that and are independent and that and If is known and is unknown with prior distribution Gamma, where a and b are assumed to be known, the Bayesian predictive distribution of V, given , is Proof. It is easy to see that the past sufficient statistic
, given
, follows the gamma distribution Gamma
and that
, given
, follows Gamma
Using Equation (
10), the posterior-density function of
, given
, is Gamma
. Applying Equation (
11), the Bayesian predictive-density function of
V, given
, can be derived as
As a result, the Bayesian predictive-density function of
V, given
, follows the generalized inverted beta distribution InBe
. □
2.2. Wald Predictive Distribution
In this subsection, the Wald predictive-density function of the future statistic V based on the past sufficient statistic W from normal density is derived.
Let
be
past random variables with pdf
and let
be
future random variables with pdf
, where {
} is an unknown parameter and
and
are independent. Consider a past sufficient statistic
with pdf
and future statistic
with pdf
. The Wald predictive-density function [
6] of
V, given
, is defined as
where
is the maximum likelihood estimator (MLE) of
based on the distribution of the past sufficient statistic
W, for which
The next two theorems present the Wald predictive distribution for some statistics. Theorem 4 considers the future statistic
and the past sufficient statistic
while Theorem 5 considers the future statistic
and the past sufficient statistic
Theorem 4. Let and , where δ is known. Assume that and are independent and that and If is unknown and is known, the Wald predictive distribution of V, given , is Proof. Using the fact that
follows
, we obtain
As a result, the MLE of
is
Now, the distribution of
is
. By applying Equation (
16), the Wald predictive distribution of
V, given
, is equal to
which represents the normal distribution
as required. □
Theorem 5. Let and where δ is known. Assume that and are independent and that and If is known and is unknown, the Wald predictive distribution of V, given , is Proof. Using the fact that the past sufficient statistic
follows Gamma
, we obtain
As a result, the MLE of
is
Now, the distribution of
follows Gamma
. By applying (
16), we obtain the result that the Wald predictive distribution of
V, given
, follows Gamma
as required. □
3. Divergence Measures between the Classical Distribution of Future Statistic and Predictive Distributions
In this section, several divergence measures between the classical distribution of the future statistic V and the predictive distribution of V, given the past sufficient statistic W, are found for both prediction cases—Bayesian and Wald—by considering the future statistic and the past sufficient statistic , where the Bayesian and Wald predictive distributions are found in Theorems 2 and 4, respectively. The other case, where and can be considered as a possible idea for future research.
The next theorem gives formulas for the following divergence measures between the classical distribution of the future statistic
in Equation (
13) and the Bayesian predictive distribution
in Equation (
14): the Kullback–Leibler measure (
), the Jeffreys measure (
), the Rényi measure (
), the relative-information-of-type-
r measure (
), the
r-order-and-
s-degree measure (
), the chi-square measure (
), the Hellinger measure (
), and the Bhattacharyya measure (
).
For each of the aforementioned measures, we also find its average under the prior distribution of
. For instance, the Kullback–Leibler measure and its average under the prior distribution of
between the two densities
g and
h, respectively, are presented as
Similarly, the average of the divergence measures under the prior distribution of between two probability density functions g and h for each of the remaining divergence measures are denoted as and
Theorem 6. Under the assumption of Theorem 2, let be the classical distribution of the future statistic and let be the Bayesian predictive distribution of V, given , from the normal density. The value of the following divergence measures and their average under the prior distribution of between and —(1) the Kullback–Leibler measure, (2) the Jeffreys measure, (3) the Rényi measure, (4) the relative-information-of-type-r measure, (5) the r-order-and-s-degree measure, (6) the chi-square measure, (7) the Hellinger measure, and (8) the Bhattacharyya measure—are equal to, respectively:
- (1)
and
- (2)
and
- (3)
where and
where
- (4)
where and
where
- (5)
where and
where
- (6)
and
where
- (7)
and
where
- (8)
and
where
where
Proof. By using (
13) and the result of Theorem 2, the following expectations can be calculated easily and will be used in the proof:
and
In addition, using
in (
13) and
in (
14), the following ratios (after simplification) will be used in the proof:
- (1)
By using Equation (
1), the Kullback–Leibler divergence between
and
equals
Now, to find the average of the Kullback–Leibler measure under the prior distribution of between and , we use the assumption . As a result,
Thus,
- (2)
First, we need to find
By applying definition (
1) and using Equations (
22) and (
23) we obtain
From (
2) and
calculated in part (1) above, the Jeffreys divergence and its average under the prior distribution of
between
and
are, respectively, provided by
Now, to find the average of the Jeffreys measure under the prior distribution of between and , we use the assumption . As a result, Thus,
- (3)
First, we find
The average of under the prior distribution of is
Note that
converges if
; that is,
From (
3) we obtain the Rényi divergence measure and its average under the prior distribution of
between
and
as required.
- (4)
From the results of part (3) above and using Equation (
4) we obtain the relative-information-of-type-
r measure and its average under the prior distribution of
between
and
as required.
- (5)
From the results of part (3) above and using Equation (
5) we obtain the
r-order-and-
s-degree divergence measure and its average under the prior distribution of
between
and
as required.
- (6)
Substituting
in the relative-information-of-type-
r measure found in part (4) above, we obtain the chi-square divergence and its average under the prior distribution of
between
and
as required. Note that
converges if
which implies
- (7)
Substituting
in the relative-information-of-type-
r measure found in part (4) above and multiplying by
we obtain the Hellinger measure and its average under the prior distribution of
between
and
as required. Note that
converge if
which implies that
- (8)
Using the relationship of the Bhattacharyya and Hellinger measures described in Equation (
9), we obtain the result of the Bhattacharyya measure and its average under the prior distribution of
between
and
as required.
□
In the same way, Theorem 7 below provides similar results for the same divergence measures considered in Theorem 6, but this time between the classical distribution of the future statistic
in Equation (
13) and the Wald predictive distribution
in Equation (
18).
Theorem 7. Under the assumption of Theorem 4, let be the classical distribution of the future statistic and be the Wald predictive distribution of V, given , from the normal density. The value of the following divergence measures and their average under the distribution of W between and —(1) the Kullback–Leibler measure, (2) the Jeffreys measure, (3) the Rényi measure, (4) the relative-information-of-type-r measure, (5) the r-order-and-s-degree-measure, (6) the chi-square measure, (7) the Hellinger measure, and (8) the Bhattacharyya measure—are equal to, respectively:
- (1)
- (2)
- (3)
- (4)
- (5)
- (6)
- (7)
- (8)
Proof. As the distribution of
is
and by Theorem 4 the Wald predictive distribution of
V, given
, is
, the following ratios (after simplification) will be used in the proof:
- (1)
The Kullback–Leibler measure between
and
, defined in Equation (
1), is equal to
Now, the average of the Kullback–Leibler measure under the distribution of
W between
and
is equal to
- (2)
First, we need to find
By applying definition (
1), we obtain
From the definition in (
2) and
calculated in part (1) above, the Jeffreys divergence between
and
is given by
Now, to find the average of the Jeffreys measure under the distribution of
W between
and
, first we need
and by using
found in part (1) above, we obtain
- (3)
The average of
under the distribution of
w is
Note that
converges if
; that is,
From the definition in Equation (
3), we obtain the Rényi divergence measure and its average under the distribution of
W between
and
as required.
- (4)
From the results of part (3) above, and using the definition in Equation (
4), we obtain the relative-information-of-type-
r measure and its average under the distribution of
W between
and
as required.
- (5)
From the results of part (3) above, and using Equation (
5), we obtain the
r-order-and-
s-degree divergence measure and its average under the distribution of
W between
and
as required.
- (6)
Substituting in the relative-information-of-type-r measure found in part (4) above, we obtain the chi-square divergence and its average under the distribution of W between and as required.
- (7)
Substituting in the relative-information-of-type-r measure found in part (4) above and then multiplying by we obtain the Hellinger measure and its average under the distribution of W between and as required.
- (8)
Using the relationship of the Bhattacharyya and Hellinger measures described in Equation (
9), we obtain the result of the Bhattacharyya measure and its average under the distribution of
W between
and
as required.
□
In the next section, we test the closeness between the classical distribution and the prediction distributions (Bayesian and Wald), using several divergence measures. In addition, we present a simulation study to compare the two prediction approaches based on the power of a test.
4. Simulation Study
In the previous section, we used several divergence measures to determine the distance between the classical distribution of a future statistic g and the predictive distribution using the Bayesian approach, and the predictive distribution using the Wald approach with random samples taken from the normal density. For this section, we used a simulation study to achieve two goals: Firstly, we tested the closeness between g and h, based on the first seven divergence measures found in Theorem 6, and the closeness between g and q, based on the first seven divergence measures found in Theorem 7, and we decided whether there was a difference in the behavior of these divergence measures with respect to the closeness test for each case of the two prediction approaches. Secondly, we decided which of the two prediction approaches was more appropriate in the current setting.
To achieve the first goal, we employed hypothesis testing to test the closeness between the classical distribution and the predictive distribution using the two prediction approaches. This technique consisted of two steps: first, the percentiles were simulated from the divergence measures to be used in making the decision based on the test criteria; next, the hypothesis testing was applied, to test the closeness between the classical and the predictive distributions, and this closeness was measured, based on the divergence measures.
For the second goal, the power of the test was determined numerically, based on the results of the simulation procedure, to decide which of the two prediction approaches was more appropriate in the in the current setting.
Simulation of Percentiles
To find the percentiles of the divergence measures, we applied the following steps:
A random sample of size n was generated from the past underlying distribution and was used to calculate W, where , as defined in Theorem 2.
Based on the obtained values of W, the divergence measures and their averages under the prior distribution of between g and h derived in (1)–(7) of Theorem 6 were calculated for fixed n, m, a, b, and .
Steps (1) and (2) above were repeated times.
The values of each of the simulated divergence measures obtained in step (3) were used to produce simulated percentiles of size and .
Table S1 in the Supplementary Materials presents the percentiles of the divergence measures (1)–(7) found in Theorem 6 between the classical distribution of future statistic
and the Bayesian predictive distribution
based on the past sample from
and the future sample from
for
. The number of simulated samples was
Table S2 in the Supplementary Materials presents the percentiles of the average divergence measures (1)–(7) found in Theorem 6 between between the classical distribution of the future statistic
and the Bayesian predictive distribution
based on the past sample from
and the future sample from
. The number of simulated samples was
The above simulation of percentiles procedure steps (1) through (4) was also performed in the Wald predictive distribution approach. In this case, the divergence measures derived in (1)–(7) of Theorem 7 were calculated for fixed
n,
m, and
.
Table S3 in the Supplementary Materials shows the percentiles of the divergence measures (1)–(7) found in Theorem 7 between
and
based on the past sample from
and the future sample from
for
. The number of simulated samples was
Testing Closeness
At this stage, we tested the closeness of the future density
and the Bayesian predictive density
using the following hypothesis:
at significance level
where
d was the distance between
g and
h and it was measured using the divergence measures (1)–(7) found in Theorem 6. In order to apply the closeness criteria, a simulation was carried out by the following steps:
All parameters, n, m, a, b, and were fixed.
One sample of size n was generated from the underlying distribution, and was used to calculate W.
For w obtained in step (2), a test statistics was calculated, based on each of the divergence measures and their averages under the prior distribution of between g and h.
On the basis of each divergence measure, decisions were made to reject (R) if and to fail to reject (FTR) if , or by using p-value criteria to reject if p-value and to fail to reject if p-value .
Table 1 gives the test statistics
for the divergence measures (1)–(7) of Theorem 6 between
and
, for
, and the decisions (FTR, R) to test the hypothesis in (
24) at
.
Table 2 gives test statistics
for the average divergence measures given in (1)–(7) of Theorem 6 for
, and the decisions (FTR, R) for testing the hypothesis in (
24) at
= 0.01, 0.05, 0.1.
The above testing of closeness procedure steps (1) through (5) was also performed in the Wald predictive distribution approach. In this case, the divergence measures derived in (1)–(7) of Theorem 7 were used to measure the distance between the future density
and the Wald predictive density
for fixed
n,
m, and
, and the percentiles
Table S3 in the Supplementary Materials was used in the comparison criteria, to make a decision.
Table 3 shows test statistics
for the divergence measures given in (1)–(7) of Theorem 7, for
, and the decisions (FTR, R) for testing the hypothesis in (
24), at
= 0.01, 0.05, 0.1.
From
Table 1,
Table 2 and
Table 3, we can see that all the divergence measures gave the same decision for each case in hypothesis (
24). As a result, we could choose any of these divergence measures to test the closeness between the classical distribution and the predictive distribution in a normal case.
The Power of a Test
To simulate the power of a test, as described previously, we applied the following steps:
The percentiles points
were taken from the percentiles
Table S2 in the Supplementary Materials when we dealt with the Bayesian predictive-distribution approach for fixed parameters,
, and
, and from
Table S3 in the Supplementary Materials when we dealt with the Wald predictive-distribution approach for fixed parameters,
and
, at significance level
A random sample of size n was generated from the underlying distribution at , and was used to calculate W.
For w obtained in step (2), we calculated the values of based on each of the divergence measures (1)–(7) of Theorem 6 for the Bayesian predictive-distribution approach and on the divergence measures (1)–(7) of Theorem 7 for the Wald predictive-distribution approach.
The values of obtained in step (3) were compared to in step (1).
Steps (2)–(4) above were repeated times.
The power of a test where , was calculated based on the percentages when
Table 4 and
Table 5 give the values of the power of a test
for testing
vs.
, where
d was measured using divergence measures (1)–(7) of Theorem 6 and Theorem 7, respectively, at significance level
. The number of simulated samples was
= 10,000.
From
Table 4, we can see that the values of
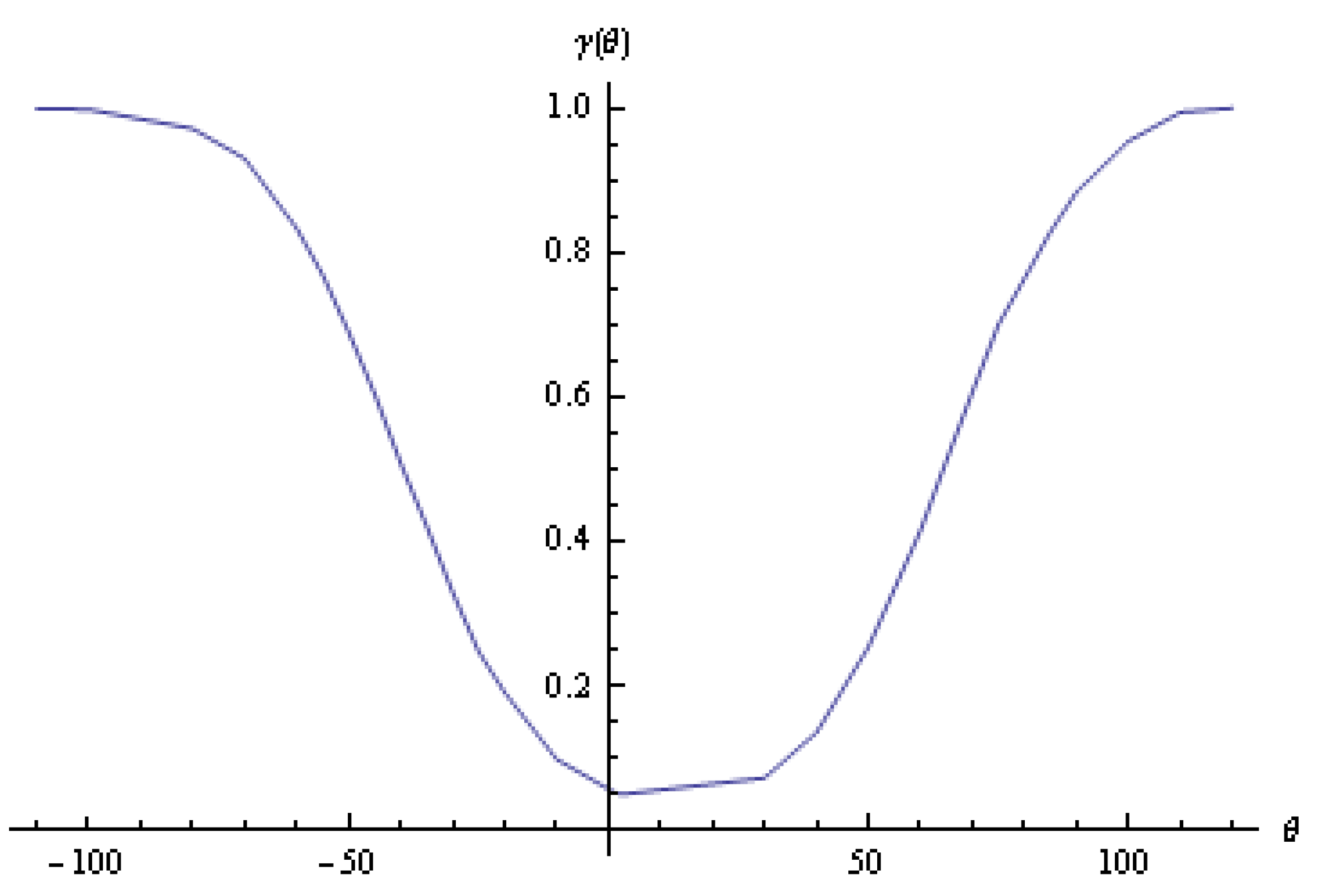
depended on the value of
and as the value of
became larger or smaller,
approached 1. On the other hand,
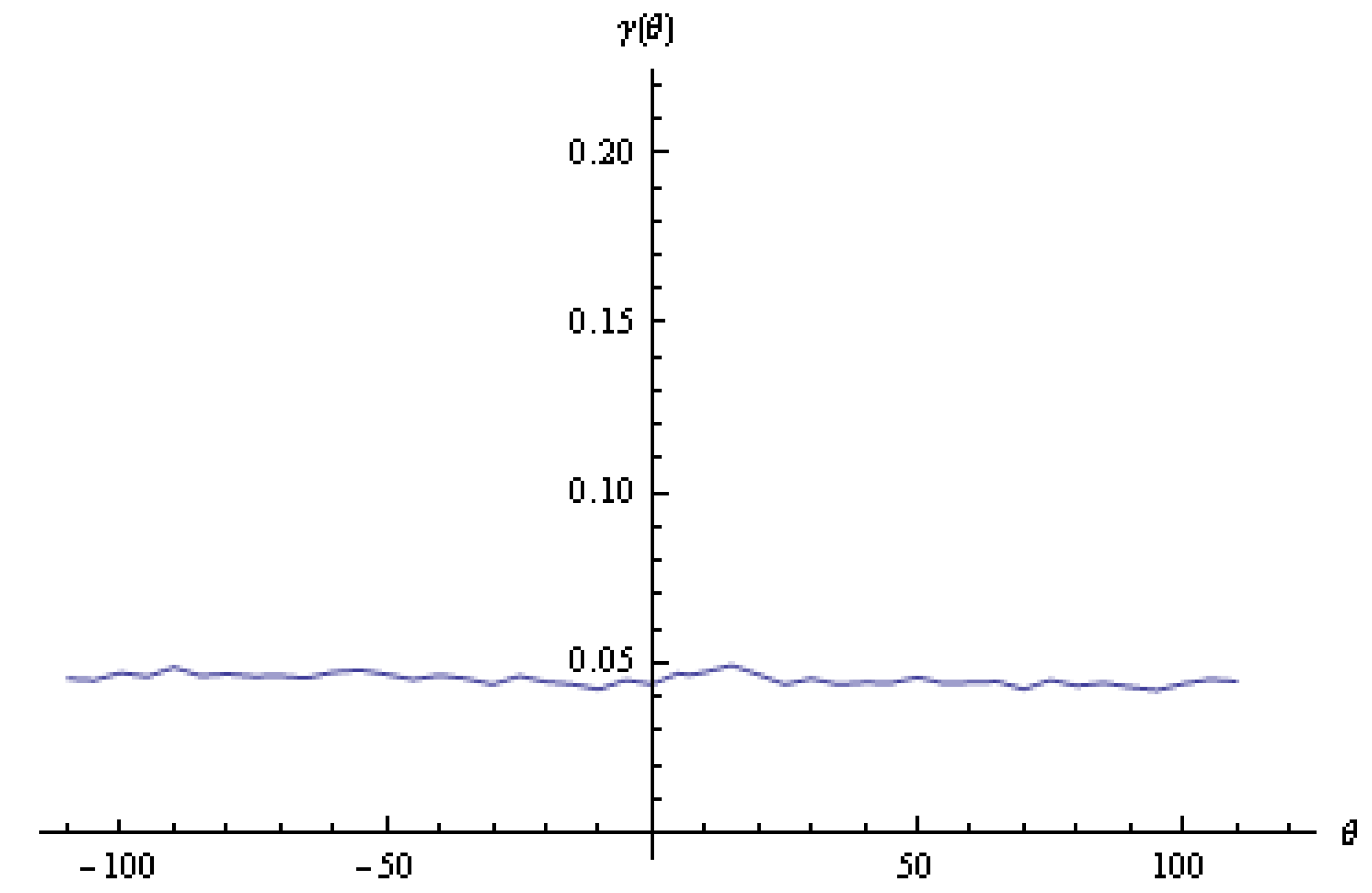
Table 5 shows that the values of
oscillated around
and did not depend on
Thus, the Bayesian predictive distribution was better in predicting future data than the Wald predictive distribution.
To check the validity of the power of a test, plots of
versus
are shown in
Figure 1 and
Figure 2 for the Bayesian predictive-distribution approach and the Wald predictive-distribution approach, respectively.
5. Application
In this section, we present an application of making a prediction using Bayesian predictive density about a future statistic based on a past sufficient statistic calculated from a real data set. In this application, we consider data set number 139 from [
38], which represents the measurements
of the length of the forearms (in inches) taken from 140 adult males. The distribution of this data set is normal, with mean
and variance
;
By using the following transformation,
we transform this data set to
The following data comprise a random sample of size 18 taken from the original transformed data to
when
:
From this data set, the value of the past sufficient statistic
At significance level
we want to test the hypothesis,
As all divergence measures give the same decision regarding the hypothesis testing in (
24), we use the Kullback–Leibler divergence measure in (
1) to calculate the distance
d between the classical distribution
g and the Bayesian predictive distribution
h.
The value of
and from the percentiles
Table S1, we obtain
; as can be seen,
. Furthermore, the value of
and from the percentiles
Table S2, we obtain
as can be seen,
. Thus, the decision is to fail to reject
. In other words, it is appropriate to use the Bayesian predictive distribution to predict the sum of the forearm lengths of males. As a result, we can predict the average length of forearms for males in general.


 ,
, 


{kind=link}
{kind=link}