The conducted simulation consists of three main components: departure process, environment, and arrival process, similar to the previous AQM simulations. The departure process is simulated as a geometric distribution controlled with a departure probability β, while the arrival is simulated using the Bernoulli process (BP) and the Markov-modulated Bernoulli process (MMBP).
4.1. Traffic Classes
The arrival process is simulated in two forms: the Bernoulli process (BP), which models a single traffic class, and the Markov-modulated Bernoulli process (MMBP), which captures traffic burstiness using multiple classes [
53]. These stochastic processes, BP and MMBP, characterize sequences of binary events with success or failure options. In this context, the binary events represent the packet arrival event. The BP models an independent sequence of events, each with a specific probability of success. The number of successes for a given trial follows a binomial distribution. On the other hand, the MMBP extends the BP by incorporating principles from Markov chains to model probabilities with varying values based on the current state of the Markov chain. As a result, the success probability fluctuates based on the existing state of a hidden Markov chain.
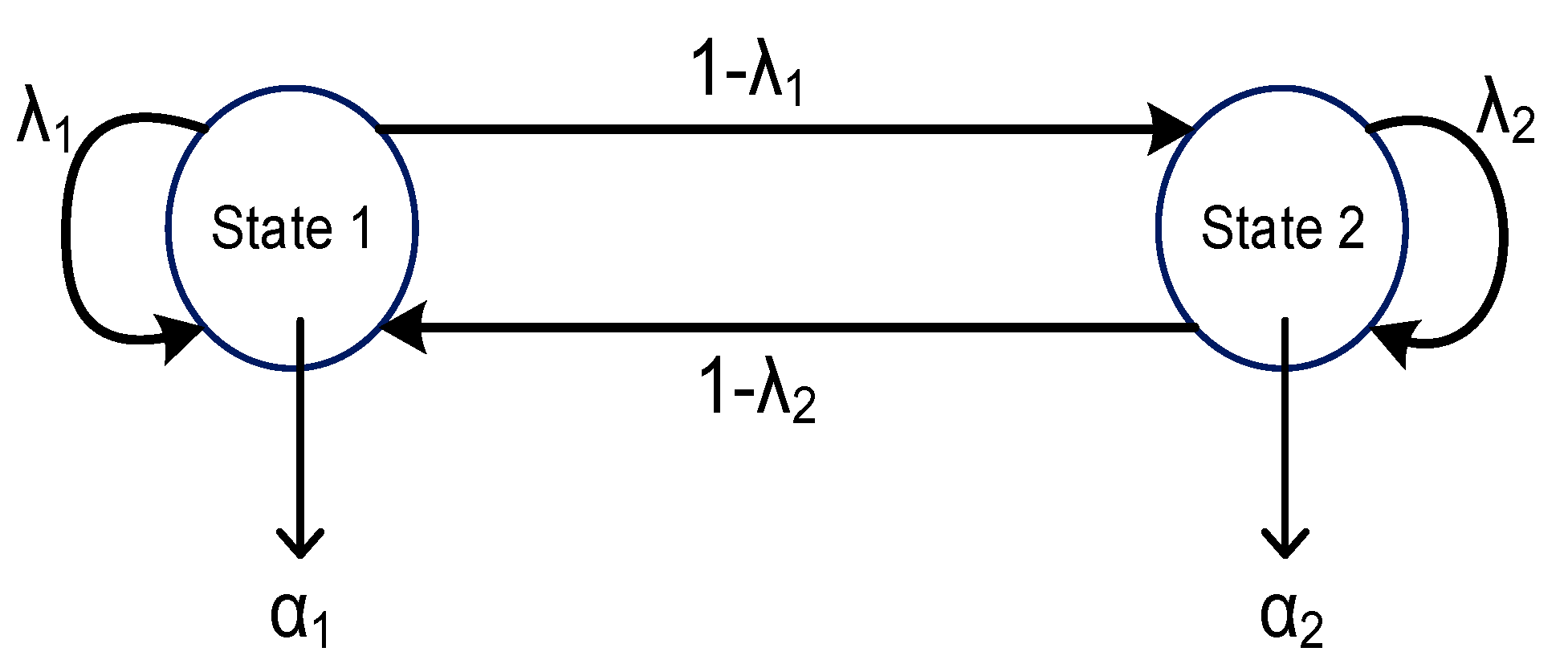
As such, BP represents a sequence of independent trials with a constant probability while the MMBP extends this concept by incorporating a Markov chain to model time-varying success probabilities. Both processes are valuable for modeling binary events in various scenarios, offering insights into the dynamics and characteristics of systems influenced by probabilistic outcomes. In the BP, the simulation utilizes an arrival probability, α, in a straightforward mechanism. The MMBP is modeled using a two-state model, as illustrated in
Figure 10. The process starts with state 1 with an arrival probability of α
1. In the next time slot, the process remains in state 1 with a probability of λ
1 or is transmitted to state 2 with a probability of 1 − λ
1. On the other hand, if the current state is state 2, then the arrival probability is α
2. The process remains in state 2 in the next time slot with the probability of λ
2 or transmitted to state 1 with probability 1 − λ
2. Accordingly, the arrival process is characterized by the arrival diagonal matrix (R), and the transmission probability is characterized by the matrix T, as given in Equation (11).
where R is the arrival probability matrix for the MMBP of two states, and T is the transmission matrix for the MMBP states represented by R.
4.2. The Simulation Environment
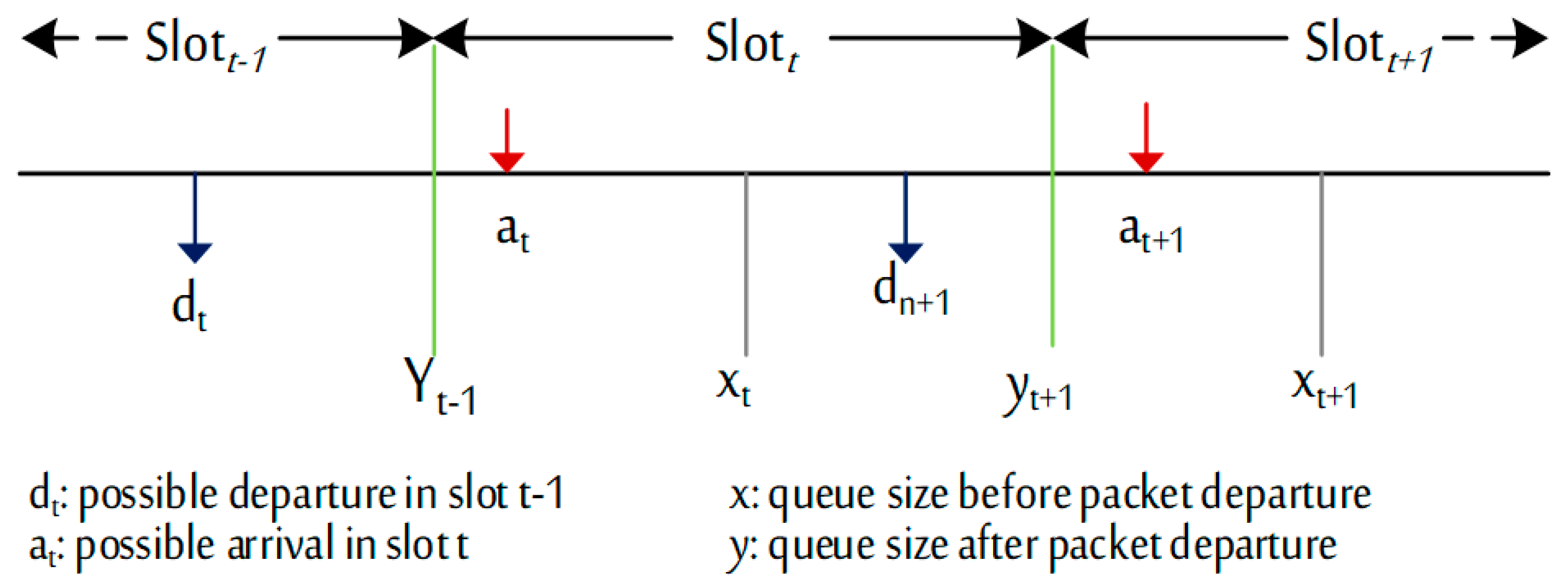
The simulation environment is the widely used discrete-time queue, which allows for evaluating the performance based on network events. The discrete-time queue model consists of time slots for unequal periods. A packet arrival and/or packet arrival occur in each slot. The departure event occurs before the arrival process, as illustrated in
Figure 11. The simulated network events take place (stochastically) over a single router with a limited capacity buffer. The buffer is modeled using first in first out (FIFO) with a capacity of 20 packets, regardless of its type and size [
54].
Using the discrete-time queue model in the conducted simulation provides a significant advantage by ensuring the reproducibility of the simulation process, regardless of the tools or programming language employed. This reproducibility is crucial as it guarantees consistent results that can be used to evaluate future methods, including real-world implementations. By adhering to this approach, simulation outcomes can serve as benchmarks for assessing novel techniques, enabling researchers and practitioners to make informed decisions based on reliable and consistent simulation results. However, it is important to recognize that the discrete-time queue model does have certain limitations, particularly when applied to real-world scenarios, such as computer networks. The primary limitation is related to the inherent simplifications and assumptions that the model entails. As such, the model might overlook external influences that significantly affect the network performance. Accordingly, the real-world implementation shall re-evolve the model using the GA and create a new rule set.
The simulation is conducted on a machine operated with 64-bit Windows 10 with an Intel Core i7 2.0 GHz processor and 16 GB of RAM. The simulation used Java programming language in Apache NetBeans Integrated Development Environment (IDE) 11.2. The simulation parameters are summarized in
Table 7. Among the 2,000,000 slots implemented in the simulated environment, 800,000 are used as a warm-up period. The arrival probability α holds 14 values in the range [0.3–0.95] to create various congested and non-congested scenarios.
In evaluating the proposed method, the loss, drop, and delay are presented alongside the time required for the simulation. The results of the proposed method are compared to the well-known RED, ERED, and BLUE methods, together with the recently proposed LRED and IRED, which are crisp-based. In addition, the proposed method is also compared with early and recently developed fuzzy-based methods: Fuzzy RED (FRED), FGRED, FBLUE, and FCRED.
Table 7 shows the compared methods’ parameters [
55].
4.4. AQM Results
The proposed method is implemented and evaluated in two experiment sets with a single traffic class. The first experiment was conducted with a β value of 0.5 and all α values. The second experiment is conducted with a β value of 0.3.
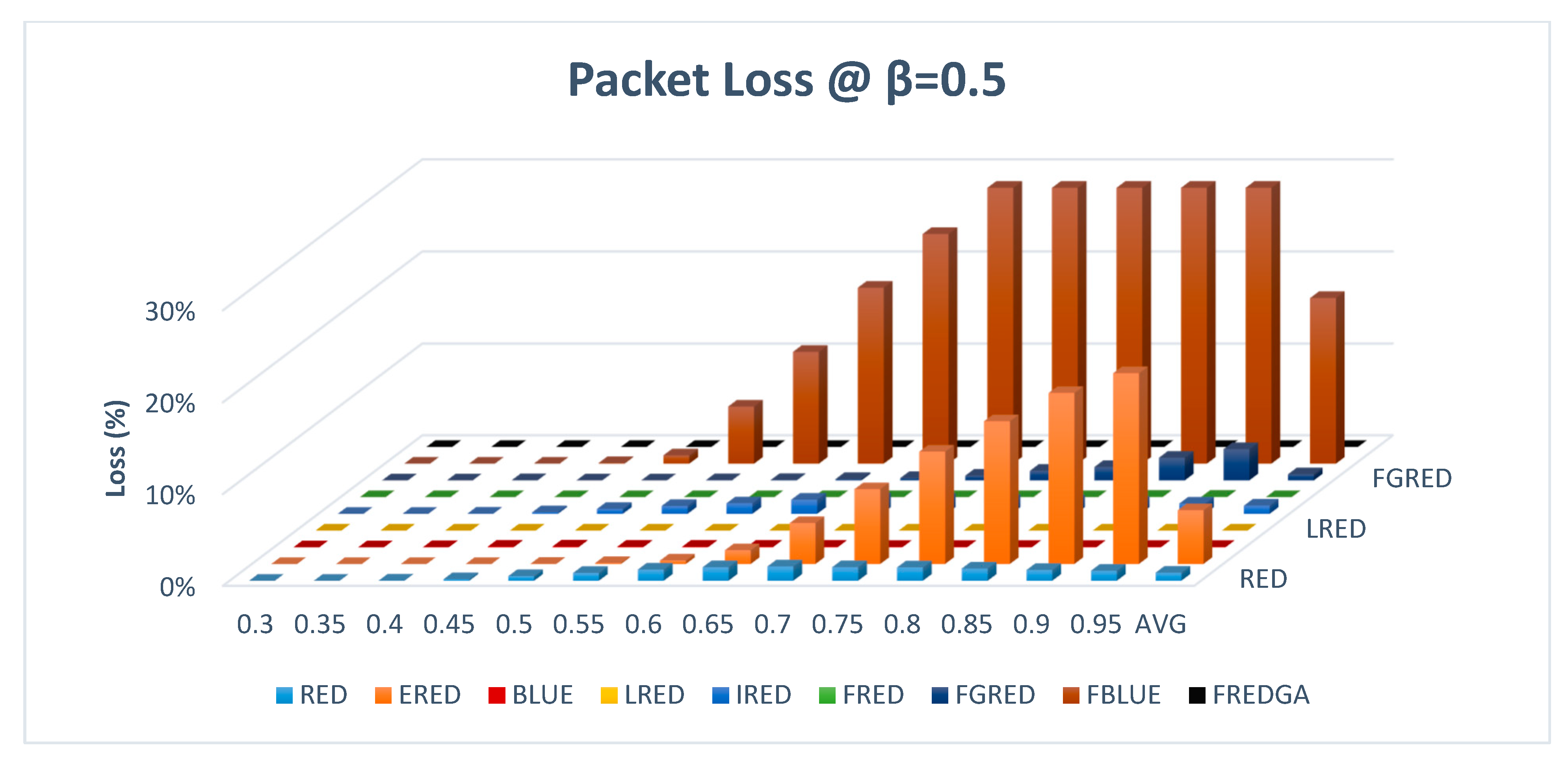
Figure 13 illustrates the evaluation based on loss, with β value of 0.5 and a single traffic class.
As results showed, the proposed FREDGA method lost no packets regardless of the arrival rate, similar to BLUE, LRED, FRED, and FCRED. FBLUE and ERED, on the other hand, had suffered significant losses of 18% and 6% of the total number of packets sent across the simulated network, respectively. An amount of 1% of the transmitted packets were lost using the RED, IRED, and FGRED methods.
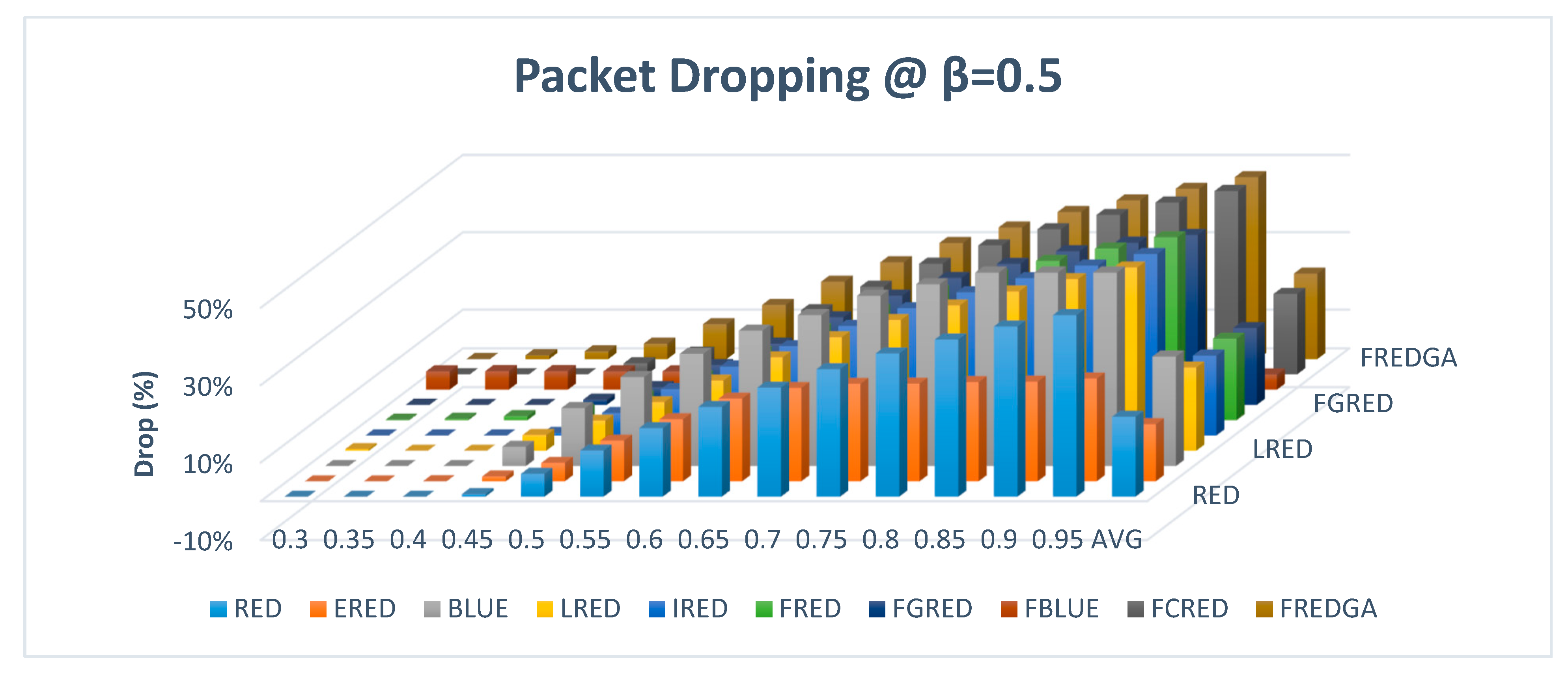
Figure 14 illustrates the evaluation results based on dropping with β value of 0.5 and a single traffic class.
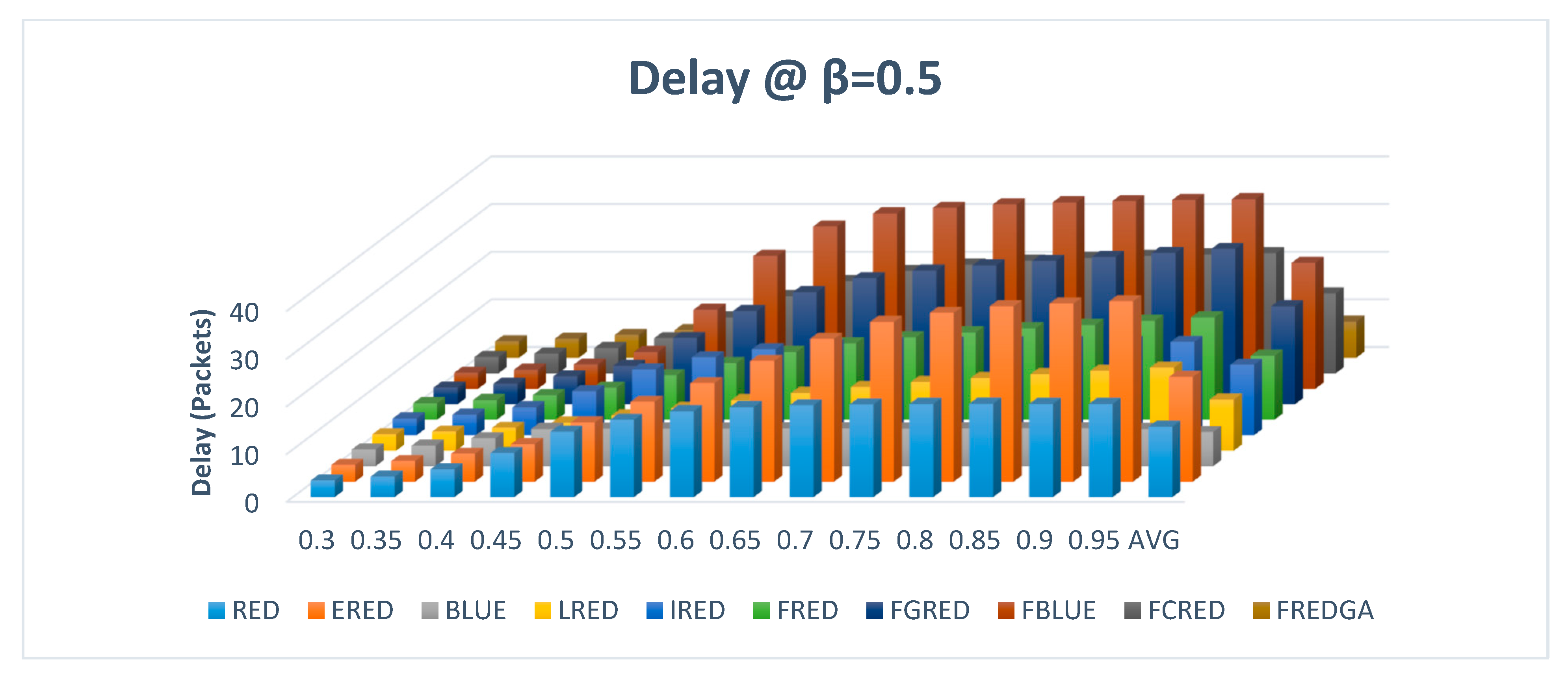
For the dropping, the proposed FREDGA method had a rate of 22%, which is better than the results of the BLUE, which drops an average of 28% of the transmitted packets. As for the rest of the methods that had no loss, LRED, FRED, and FCRED had a drop rate of 21%, which is equivalent to the results obtained by the FREDGA method. However, it was realized that the modest increase in the intended dropping rate of the proposed FREDGA had greatly reduced the delay, as illustrated in
Figure 15.
The average delay of the proposed FREDGA method for each packet was 7.57 while it was 10.74 for LRED, 13.42 for FRED, and 16.74 for FCRED. As a result, compared to the best methods, the proposed FREDGA method decreases the delay while maintaining no loss and low drop.
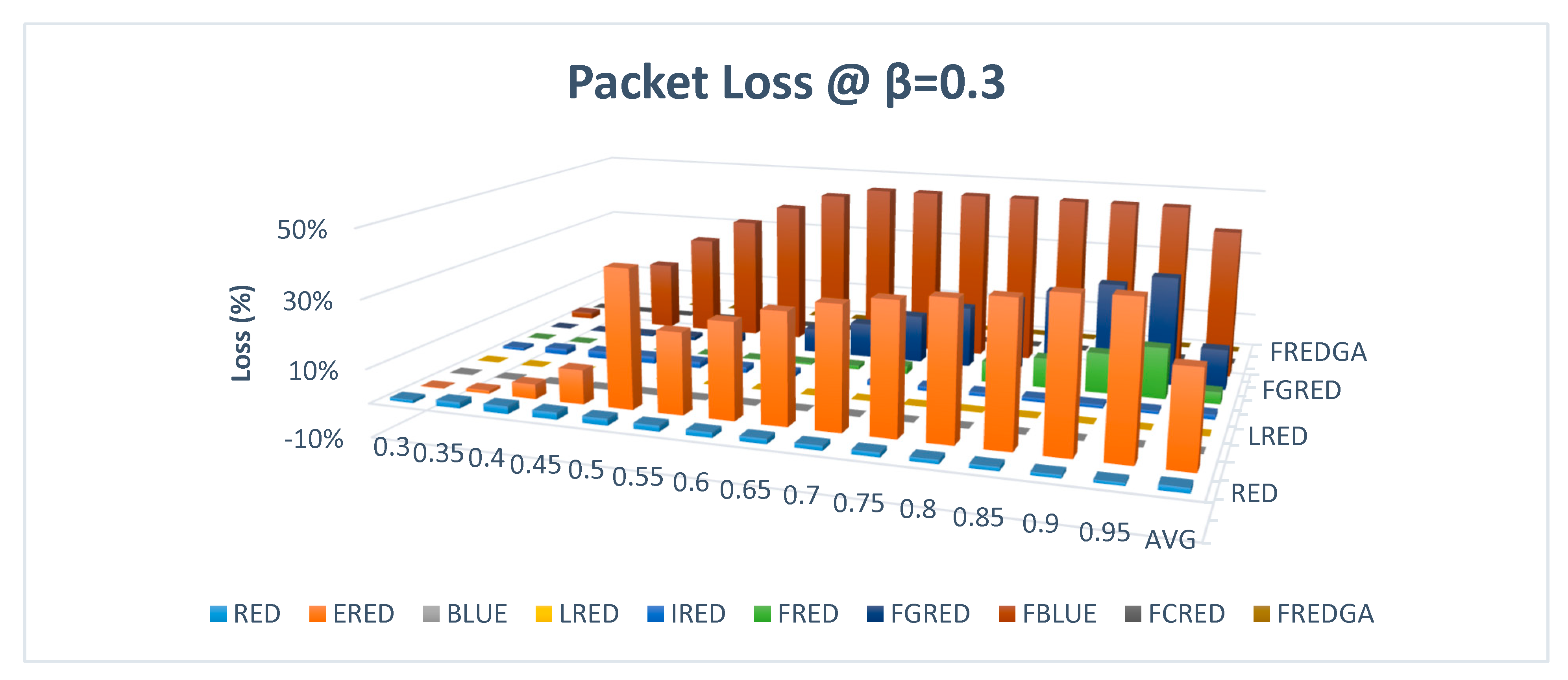
Figure 16 illustrates the loss-based evaluation results under heavy load for the second set of experiments with a low packet departure of 0.3.
As reported in the previous experiment, the results with a more congested network at a departure rate of 0.3 showed that the proposed method FREDGA lost no packets, similar to BLUE, LRED, and FCRED. A significant loss of 44% and 27% of the packets transmitted across the simulated network, respectively, is experienced by the FBLUE and ERED methods. While the FRED method lost 4% of the transmitted packets, FGRED lost 12%, and the RED and IRED methods lost an average of 1%.
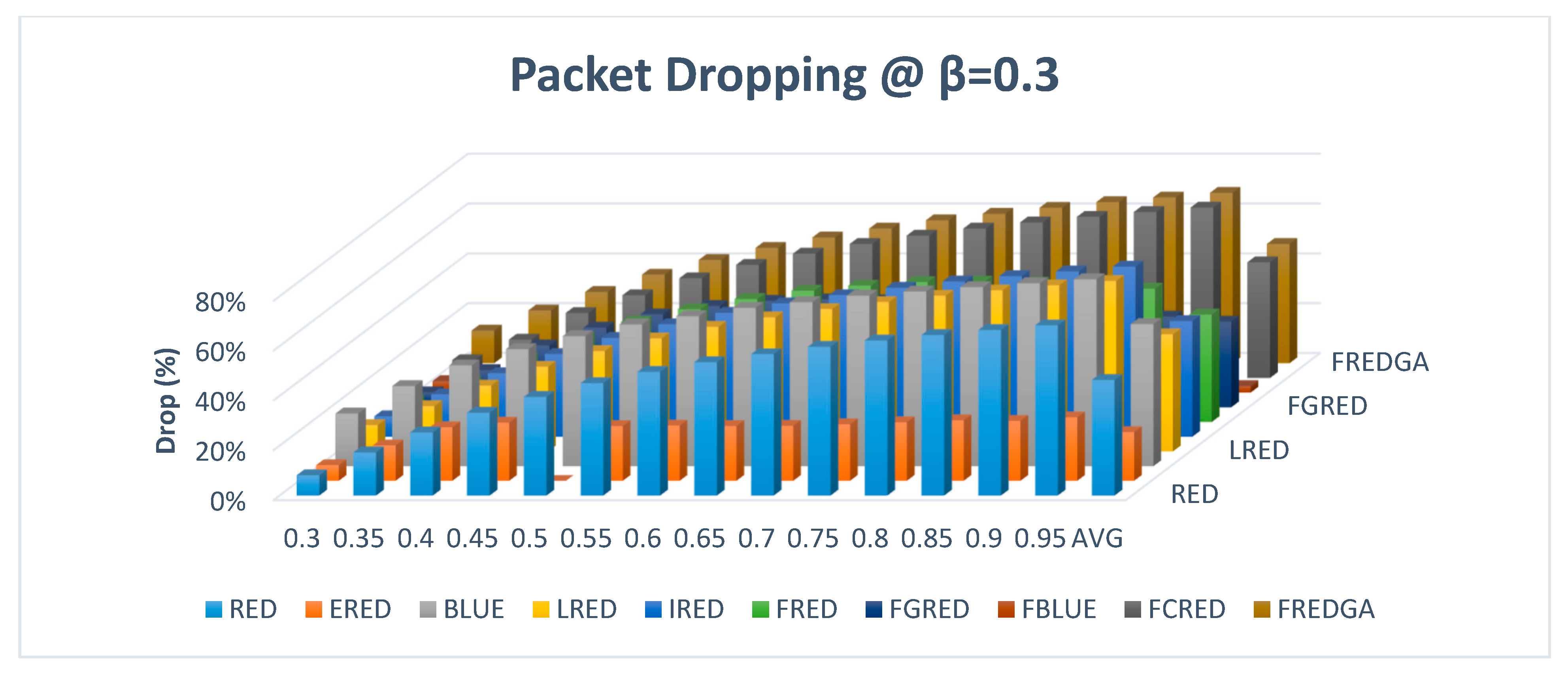
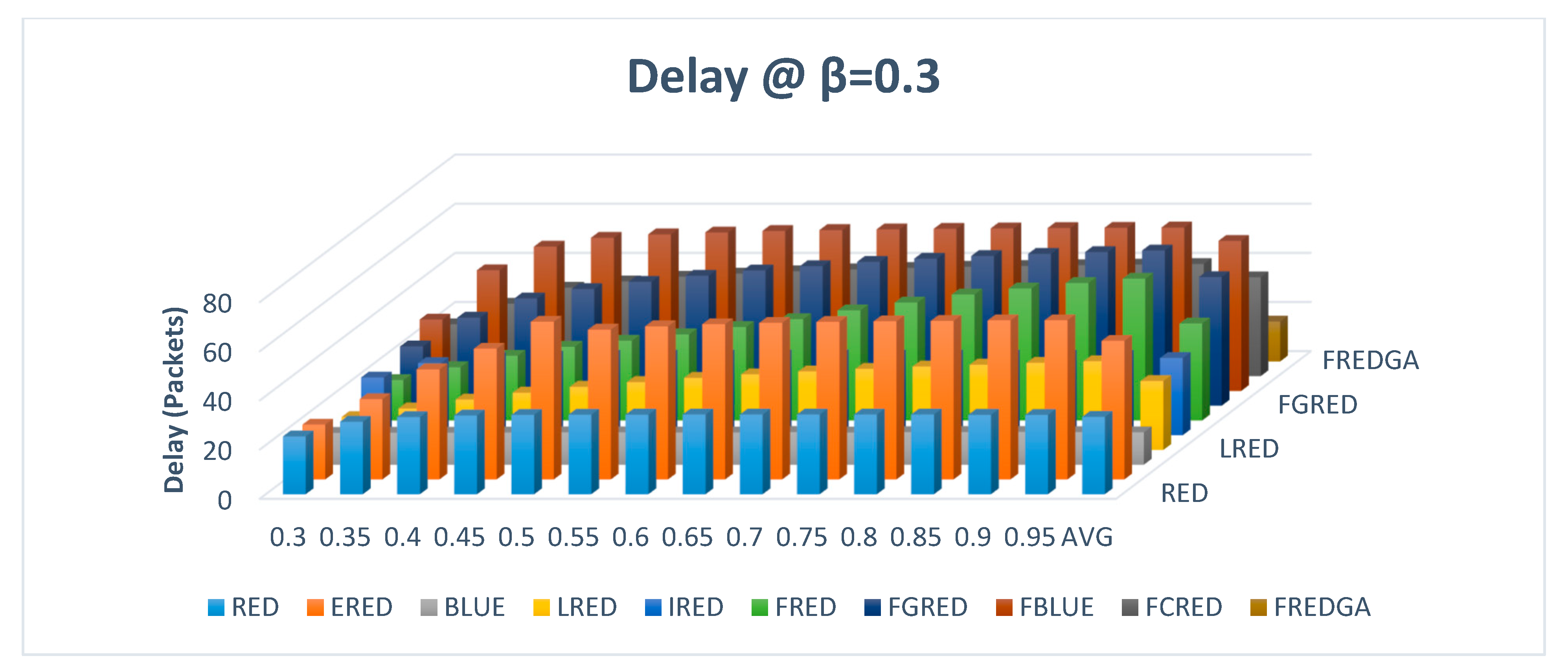
Figure 17 illustrates the evaluation results based on dropping with β value of 0.3 and a single traffic class.
For the dropping rate, in
Figure 17, the proposed FREDGA dropped 48% of the transmitted packets while BLUE dropped an average of 57%. As for the rest of the methods, which had no loss, LRED and FCRED dropped 47% and 46% of the packets, respectively. Again, it was realized that the modest increase in the intended dropping rate of the proposed FREDGA had greatly reduced the delay, as illustrated in
Figure 18.
As given in
Figure 18, the average delay of the proposed FREDGA method was 16.23 while it was 28.04 for LRED and 40.23 for FCRED.
Similarly, for MMBP, the proposed method is implemented and evaluated with various values for the arrival controller α
1, with a single value for α
2 of 0.5 and β set to 0.5.
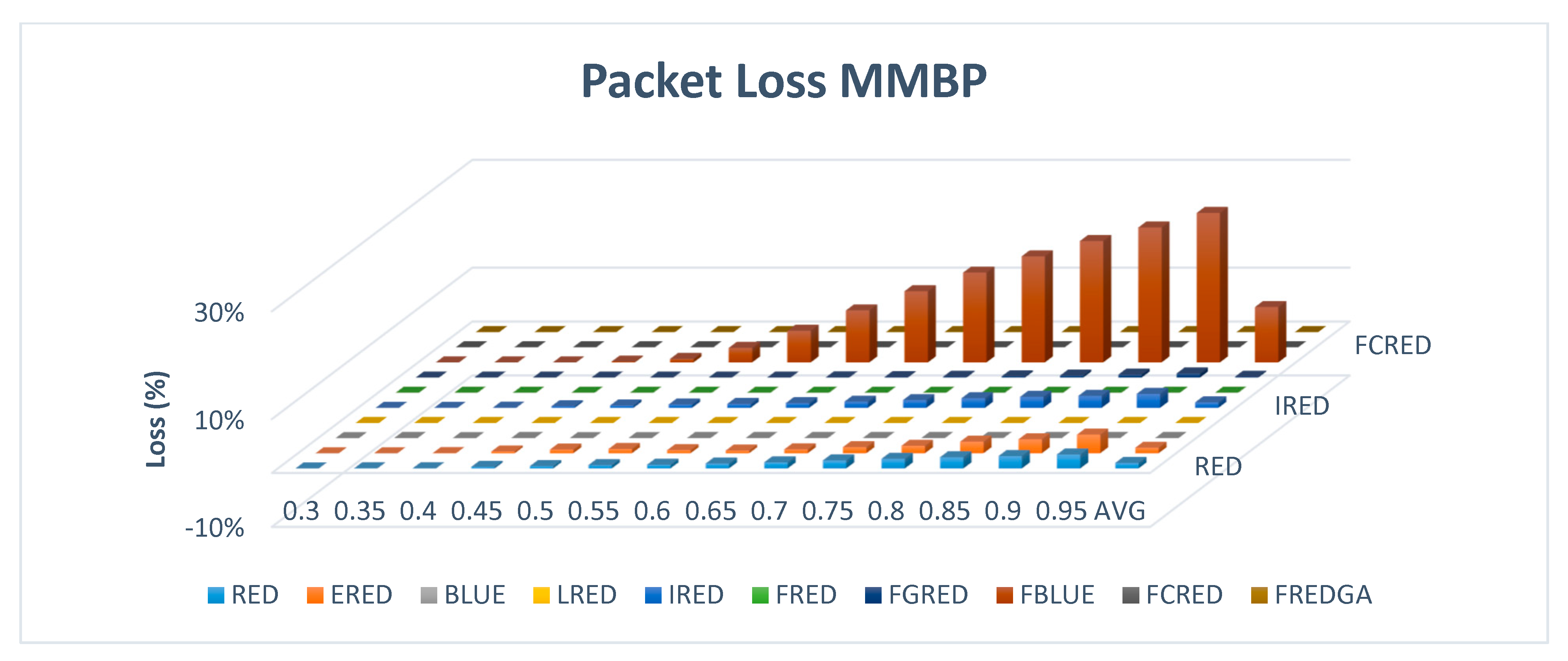
Figure 19 illustrates the evaluation results of the packet loss with 2-stated MMBP.
The results of the MMBP-based simulation confirmed the findings of the previous experiments. For the loss, as illustrated in
Figure 19, the proposed FREDGA method did not lose any packets, similar to BLUE, LRED, FRED, FGRED, and FCRED. The FBLUE method suffered a loss of 10% while RED, ERED, and IRED only lost 1% of the transmitted packets.
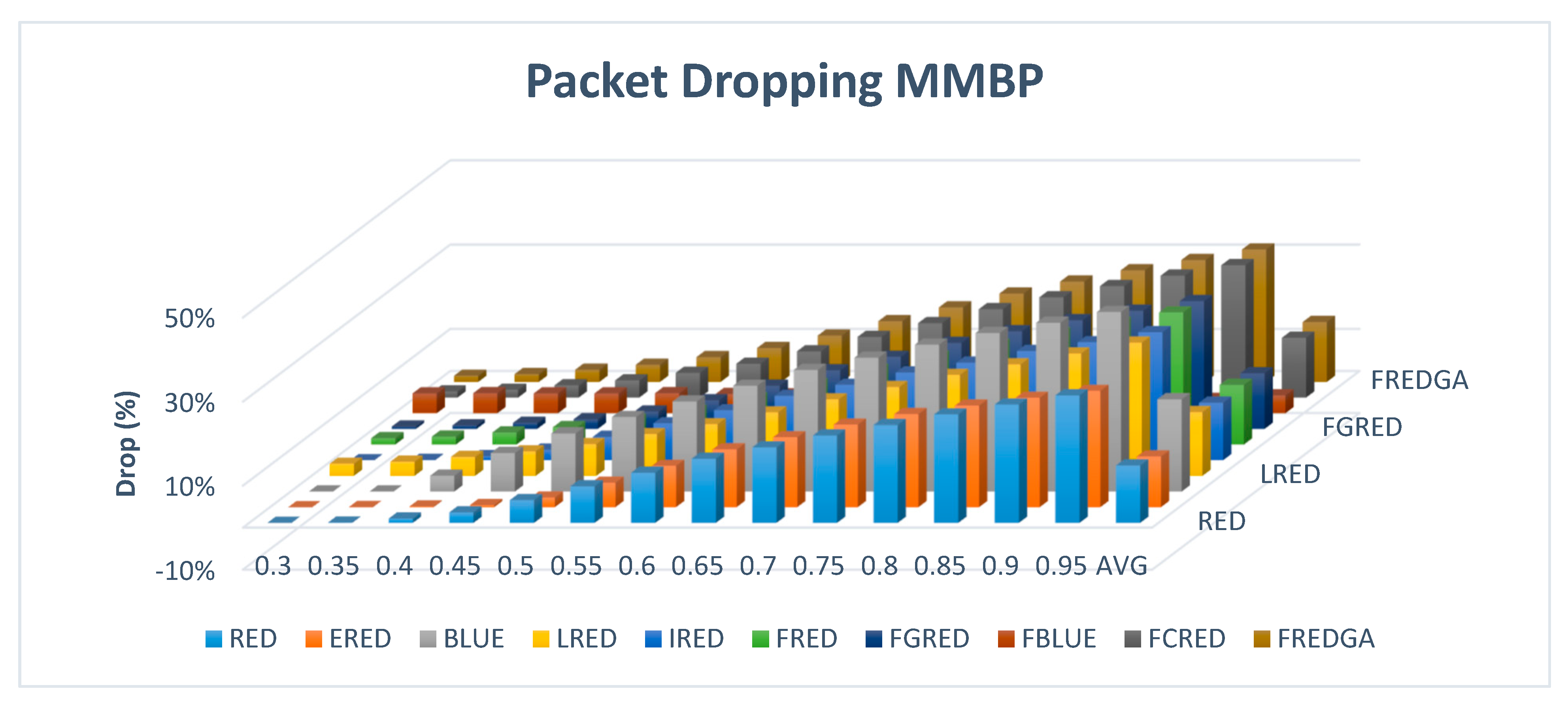
Figure 20 illustrates the evaluation results based on dropping with β value of 0.5 and two-class traffic.
The dropping rate of the proposed FREDGA method is 14%, which is much better than the results of the BLUE, which dropped an average of 22%. As for the rest of the methods that had zero loss, LRED had a dropping rate of 15%, FRED reported a 14% drop, FGRED reported a 13% drop, and FCRED reported a 14% drop.
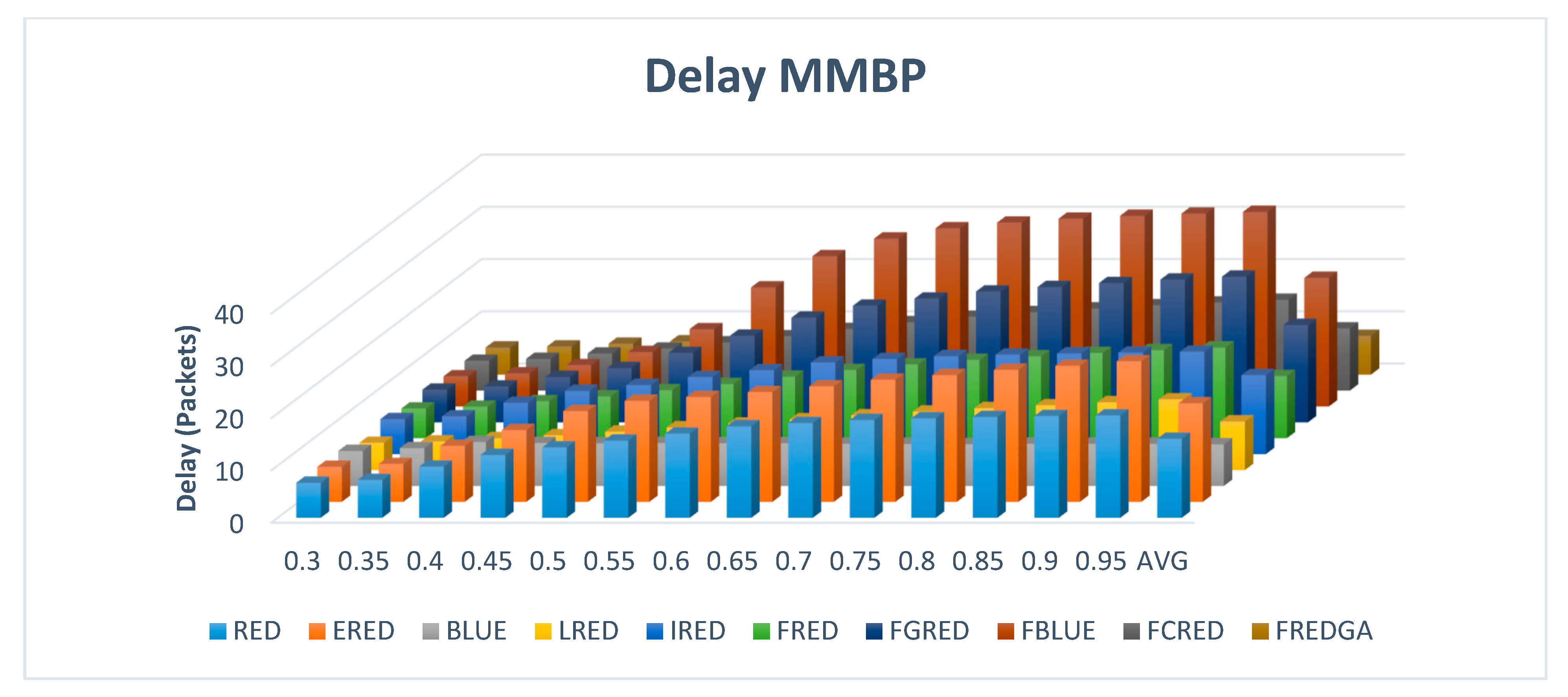
The delay based on dropping with β value of 0.5 and two-class traffic is illustrated in
Figure 21.
The average delay of the FREDGA method was 7.43 for each packet, 9.28 for LRED, and 11.9 for FCRED.
The time for running the whole experiment for each method is reported in
Table 8. As noted, the proposed FREDGA required significantly less time compared to the linguistic fuzzy-based methods, excluding the optimization time.
In summary, the proposed FREDGA method improved the delay and maintained zero loss and a low dropping rate compared to the best methods reported in the literature. Moreover, the proposed FREDGA method required significantly less time than the linguistic fuzzy-based methods, reducing the round-trip delay as the processing delay reduced significantly.



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}




















