1. Introduction
A new one-parameter Xgamma (XG
) distribution has been introduced by Sen et al. [
1] as a special, finite mixture of exponential and gamma distributions. Recently, using the XG density, Yousof et al. [
2] proposed and studied a new extension of the one-parameter Weibull distribution named the two-parameter Xgamma–Weibull (XGW
) distribution. They derived several properties of the XGW distribution and also showed that its density can be represented as a mixture of exponentiated Weibull densities. Moreover, they estimated the XGW parameters using uncensored samples via the maximum likelihood estimation method. Cordeiro et al. [
3] further proposed the three-parameter XGW distribution as a member of the XG family of distributions. However, we assume here that
X is a lifetime random variable of an experimental unit(s) test that follows a two-parameter XGW distribution denoted by
, where
is the parameter vector. Consequently, the respective probability density function (PDF), cumulative distribution function (CDF), reliability function (RF) and hazard function (HF) for
X are given, respectively, by
and
where
and
are the scale and shape parameters, respectively. Using Equation (
1), Yousof et al. [
2] stated that the XGW distribution may be used as a generalized form of three new one-parameter lifetime distributions, which act as sub-models, namely:
Xgamma–Rayleigh distribution if setting ;
Xgamma–exponential type-I distribution if setting ;
Xgamma–exponential type-II distribution if setting .
Utilizing various parameter choices for
and
based on their domains, several shapes for density and hazard functions for the XGW distribution are shown in
Figure 1. This shows that the XGW density can be concave-down or left- or right-skewed, while the XGW hazard shapes can be bathtub-shaped or decreasing or increasing.
Censored data are commonly used in studies on reliability and life testing. Due to factors like preserving working experimental units for future use, reducing overall time for the test and financial limits, investigators have to gather data using censored samples. Time-censoring (type-I) and failure-censoring (type-II) strategies are the two widely used censoring strategies in life-testing and reliability studies (see, for additional details, the work by Bain and Engelhardt [
4]). These methods are not flexible enough to allow units to be removed from the experiment at any point other than the terminal point. To overcome this shortcoming, a more adaptable censoring scheme known as progressive type-II censoring has been developed. Kundu and Joarder [
5] proposed a progressive type-I hybrid censoring (P-I-HC) scheme in which
n identical products undergo testing via a specific progressive censoring scheme
and the examination terminates at an arbitrary time
, where
T is a time that is predetermined. The drawback of the P-I-HC plan is that the effective sample size is random and it may be a very small number or equal to zero. As a consequence of this, statistical inference techniques will be ineffective. To address this limitation, Ng et al. [
6] presented an adaptive progressive type-II hybrid censoring (AP-II-HC) strategy to improve statistical examination efficiency. In this framework, the number of failures
m is specified in advance, and the duration of the test is allowed to exceed the predetermined time
T. Furthermore, we have the progressive censoring scheme
, but the values of some of the
may change as a result of the test. This scheme can be summarized as follows: Suppose that
n units are subjected to a life test and
is the desired total number of failures. At the time of the
ith failure
,
units are eliminated from the test at random. If the
mth failure occurs before time
T (i.e.,
), the experiment terminates and we have the regular progressive type-II censoring. If, on the other hand,
, where
and
correspond to the
dth failure time and occur before time
T, then we will not remove any living item from the experiment by placing
and
. This setting assures that we finish the test when we attain the desired number of failures
m and that the overall test duration does not deviate too much from the optimal time
T.
Figure 2 presents a diagrammatic representation of the AP-II-HC strategy.
Let
be an AP-II-HC sample from a population with a PDF
and CDF
; then, the LF for the observed data can be written according to Ng et al. [
6] as
where
C is a constant. Numerous studies have been conducted based on the AP-II-HC scheme; for example, the work by Al Sobhi and Soliman [
7], Nassar et al. [
8,
9], Panahi and Moradi [
10], Elshahhat and Nassar [
11], Panahi and Asadi [
12], Alotaibi et al. [
13] and Nassar et al. [
14].
A very competitive estimating technique, the maximum product of spacing estimation method, has lately acquired prominence as an alternative to the standard maximum likelihood approach. Cheng and Amin [
15] initially presented the maximum product of spacing technique, demonstrating that the maximum product of spacing estimators (MPSEs) and maximum likelihood estimators (MLEs) have identical asymptotic sufficiency, consistency and efficiency features. The MPSEs are calculated by maximizing the product of the differences between the CDF values at close-ordered locations. Anatolyev and Kosenok [
16] investigated the invariance property of MPSEs and discovered that it is the same as that of MLEs. The spacing function (SF) to be maximized can be written using an observed AP-II-HC sample as
Among others, Basu et al. [
17,
18], Nassar et al. [
19] and Okasha and Nassar [
20] have all used the maximum product of spacing estimation approach to estimate the unknown parameters of several lifetime distributions.
Though the XGW distribution is very useful in reliability analysis because its hazard shapes can be bathtub-shaped or decreasing or increasing, the problem of estimating the XGW parameters and/or the reliability and hazard rate parameters in the presence of incomplete data, such as the proposed censored sampling, has yet to be investigated. Therefore, the impetus for this study stemmed from (i) the XGW distributions’ applicability to modeling various data types with varying HRFs; (ii) the AP-II-HC scheme’s capacity to improve the accuracy of statistical estimates; and (iii) the fact that statistical and reliability scientists are interested in the performance of various estimation methods for unknown parameters, as well as the reliability and hazard rate functions of the XGW distribution. Our research objectives were as follows:
Derive and explore the MLEs and MPSEs of unknown parameters, as well as the reliability metrics and accompanying approximate confidence intervals (ACIs);
Investigate the Bayes estimators and Bayes credible intervals (BCIs) when observed data are gathered using both LFs and SFs and develop the MCMC method based on the squared error (SE) loss function;
Carry out a full simulation examination to analyze the performance of the various estimations, as it is impossible to tell which approach theoretically generates the best estimates;
Discuss the best progressive sampling plane for the AP-II-HC scheme when dealing with the XGW distribution;
Present two applications based on real-life engineering and medical datasets to show the superiority and flexibility of the XGW model compared to five lifetime distributions (as competitors); namely, Xgamma, gamma, generalized exponential, Weibull and exponential Weibull distributions.
The remainder of the article is organized as follows: The MLEs and the associated ACIs of the model parameters, as well as the reliability indices, are provided in
Section 2.
Section 3 presents the MPSEs and ACIs using the maximum product of spacing approach.
Section 4 discusses Bayesian estimations using the LF and SF.
Section 5 summarizes the simulation outcomes. In
Section 6, optimal censoring plans based on three optimality criteria are presented.
Section 7 examines two applications to real data. Finally, in
Section 8, some final observations are made.
2. Likelihood Estimation
Let
be an AP-II-HC sample taken from a population with a CDF, as given by Equation (
2), with a progressive censoring scheme
. Then, based on Equations (
1), (
2) and (
5), the LF, ignoring the constant term, can be written as
where
,
,
and
.
Taking the natural logarithm of Equation (
7), the log-LF can be expressed as
By solving the following two normal equations simultaneously with respect to
and
, one can obtain the MLEs of
and
, denoted by
and
, respectively, as:
and
where
,
and
. It is noted that the MLEs cannot be acquired from Equations (
9) and (
10) explicitly. Therefore, one can utilize any numerical procedure to obtain the needed estimates.
Upon obtaining the MLEs
and
, and based on the invariance property of the MLEs, the MLEs of the RF and HRF can be derived directly from Equations (
2) and (
4) at mission time
t, respectively, as given below
and
Remark 1. Using Equation (7), several results from the literature can be easily obtained as special cases, such as The estimation results presented by Sen et al. [21] in the case of the XG distribution based on progressive type-II censored sampling by setting and ; The estimation results presented by Sen et al. [1] and Saha et al. [22] in the case of the XG distribution based on complete sampling by setting , , and for ; The estimation results presented by Elshahhat and Elemary [23] in the case of the XG distribution based on AP-II-HC sampling by setting ; The estimation results presented by Yousof et al. [2] in the case of the XGW distribution by setting , and for .
Regarding the interval estimation of the unknown parameters, as well as the RF and HRF, we employ the asymptotic properties of the MLEs to construct the ACIs of various parameters. We first use the observed Fisher information matrix to estimate the variance-covariance matrix, which is expressed as
and given by
where
and
where
,
,
and
.
Based on the asymptotic normality of the MLEs, one can construct the ACIs of
and
at the
confidence level as follows
where
is the upper
th percentile point of the standard normal distribution. In order to create the ACIs for the RF and HRF, we must also establish the variances for their estimators. In our case, the delta technique is used to approximate the variances of
and
(see the work by Greene [
24] for additional information). We must first obtain the quantities
and
, which are the first-order derivatives of the RF and HRF with respect to
and
, respectively, to achieve the necessary estimated variances as follows
and
where
.
Now, let
and
as evaluated at the MLEs
and
. Then, we can obtain the approximate estimates of the variances of
and
, respectively, as
Consequently, the
ACIs of RF and HRF can be expressed as
respectively.
3. Product of Spacing Estimation
Let
be an AP-II-HC sample from the XGW population with a CDF as given by Equation (
2). Then, from Equations (
2) and (
6), the SF, without the constant term, can be expressed as follows with
where
. The natural logarithm of Equation (
17) is expressed as
The MPSEs of the parameters
and
, denoted by
and
, can be acquired by solving the following normal equations
and
where
,
,
and
. As in the case of the MLEs, one should utilize numerical procedures to solve Equations (
19) and (
20) to determine the MPSEs of
and
. According to Cheng and Traylor [
25], the MPSEs possess the same invariance property as the MLEs. Therefore, we can obtain the MPSEs of the RF and HRF using this property as follows
and
Cheng and Amin [
15] and Cheng and Traylor [
25] stated that MPSEs have the same asymptotic properties as MLEs. As a result, we can employ these properties to obtain the ACIs of the different unknown parameters based on the MPSEs. We first estimate the variance-covariance matrix based on
and
, denoted by
, as follows
where
and
where
,
,
and
.
Now, the
ACIs of
and
can be computed respectively as
By approximating the estimated variances of the RF and HRF using the delta method, we can obtain the
ACIs of
and
, respectively, as follows
where
and
are evaluated at the MPSEs of
and
as defined in Equation (
16).
4. Bayesian Estimation
In this section, we look at the Bayesian estimation approach to estimate the XGW distribution’s parameters (the RF and HRF). The point and interval estimates of the various parameters are obtained in this section using both the LF and SF. The Bayes estimates are calculated by taking into account the SE loss function and assuming that the parameters
and
are independent and a priori distributed as gamma distributions. The combined prior distribution of
and
, where
, can be expressed as follows
Here, we assume gamma priors, which adapt to the support of the XGW distribution’s parameters and are thought to be more flexible than other prior distributions. Based on the LF given by Equation (
7) and the joint prior in Equation (
22), one can write the joint posterior distribution of
and
based on the LF as
where
Similarly, by combining the SF given by Equation (
17) and the joint prior in Equation (
22), one can write the joint posterior distribution of
and
using the SP as follows
where
Under the SE loss function, the Bayes estimator of any function of the unknown parameters—say,
—using both posterior distributions can be derived, respectively, as follows
and
The integrals offered by Equations (
25) and (
26) are not available in closed forms. As a result of this, in this scenario, we must think about using the MCMC approach to generate samples from the posterior distributions and then compute the Bayes estimates for the unknown parameters, as well as the related credible intervals. To use the MCMC technique, we first need to derive the full conditional distributions of the various parameters. Based on the posterior distribution derived based on the LF as displayed in Equation (
23), the full conditional distributions of
and
are given, respectively, by
and
In a similar way, we can derive the full conditional distributions of the unknown parameters
and
from the posterior distribution obtained based on the SF as given by Equation (
24) as follows
and
respectively.
Although the full conditional distributions derived based on both the LF and SF cannot be represented in standard forms, their graphs are equivalent to the normal distribution. Using, for example,
,
,
and progressive censoring
(where
means that 1 is repeated 50 times),
Figure 3 shows that the full conditional distributions in Equations (
27)–(
30) of
and
behave like normal densities. Therefore, we can employ the Metropolis–Hastings (M-H) technique with a normal proposal distribution to generate random samples from these distributions in order to obtain the required estimates.
The procedures below demonstrate how to obtain the necessary samples and the required point and credible interval estimates. It is important to mention here that the following steps are evaluated based on the LF, and one can easily use the same steps to obtain the Bayes estimates using the SF, as follows
- Step 1.
Start with the first chain ;
- Step 2.
Specify the initial values
- Step 3.
Employ Equation (
27) to simulate
with a normal proposal distribution with mean
and variance
by using the M-H algorithm;
- Step 4.
Use Equation (
28) and the M-H steps to obtain
with a normal proposal distribution with mean
and variance
;
- Step 5.
Use the obtained samples to compute and ;
- Step 6.
Set ;
- Step 7.
Redo steps 3–6
M times to obtain
where
or
;
- Step 8.
Compute the Bayes estimate of
using the SE loss function as
where
is the burn-in period.
5. Monte Carlo Simulations
To highlight the actual behavior of the offered estimators of
,
,
and
, based on 1000 AP-II-HC samples generated from the
distribution, extensive simulations were conducted. For the distinct time
, the plausible values for
and
were taken as 0.9854 and 0.1087, respectively. Various choices for
T (the threshold point),
n (the full sample size) and
m (the effective censored size) and different censoring schemes
were also utilized, such as
,
and
m being determined as a failure percentage (FP) for each
n as
and
. Remember that, as soon as the number of failed units reached a specific value
m, the experiment was stopped. Moreover, to highlight the performance of removal methods, several designs for
…
were used as follows
To obtain AP-II-HC data from the XGW model, for pre-specific values of T, n, m and , we implemented the following generation process:
- Step 1:
Simulate traditional progressive type-II censored order statistics as follows:
- a.
Create independent variates of size m from a uniform distribution;
- b.
Set ;
- c.
Obtain for ;
- d.
Obtain
from Equation (
2);
- Step 2:
Find d, where , and ignore the other staying items ;
- Step 3:
From , obtain the first-order statistics.
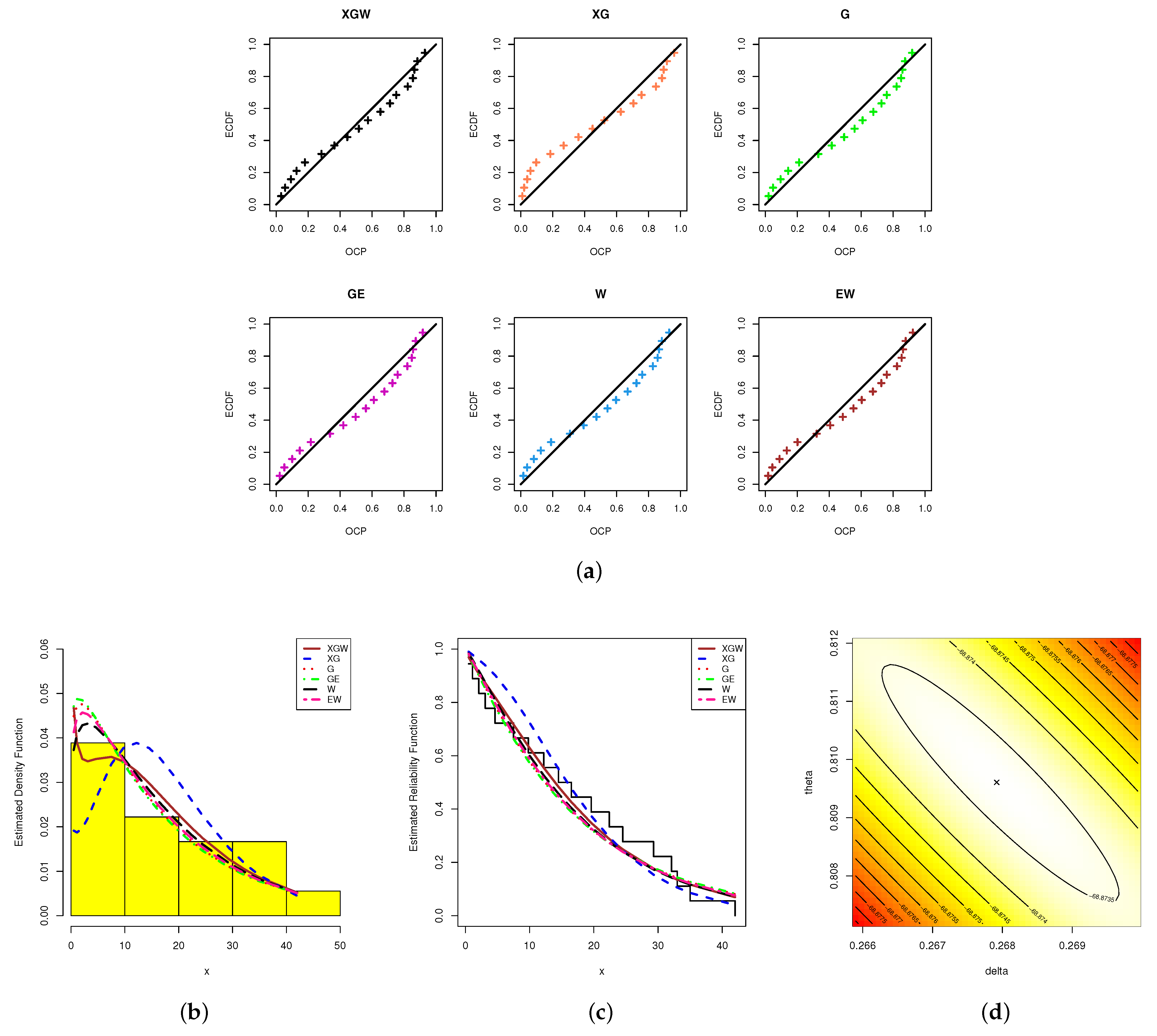
Once the 1000 desired AP-II-HC samples were obtained, the classical point estimates (including ML and MPS estimates), as well as 95% classical interval estimates (including ACI-LF and ACI-SF estimates), were developed. To judge the performance of the proposed density priors, we considered two separate informative sets for the hyperparameters namely:
Prior one: ;
Prior two: .
Following
Section 4, we repeated the MCMC procedure 12,000 times and eliminated the first 2000 times as burn-in. After collecting 10,000 MCMC samples, based on the Bayes procedures from both likelihood-based and spacings-based estimates, the Bayes and 95% credible interval estimates of
,
,
and
were obtained. Using
4.2.2 software, all frequentist and Bayes evaluations were performed using the "
" (developed by Henningsen and Toomet [
26]) and "
" (developed by Plummer et al. [
27]) packages.
Specifically, the comparison between point estimates of (as an example) was undertaken based on the following criteria:
Root-mean-squared error (RMSE):
Mean relative absolute bias (MRAB):
where
is the calculated estimate of
at
ith simulated sample.
Furthermore, the comparison of the interval estimates of was undertaken based on the following criteria:
Average confidence length (ACL):
Coverage percentages (CPs):
where
is the indicator, and (
,
) denotes the two-sided asymptotic (or Bayes credible) interval estimates of
. In the same way, the simulated RMSE, MRAB, ACL and CP results for
,
or
can be easily calculated.
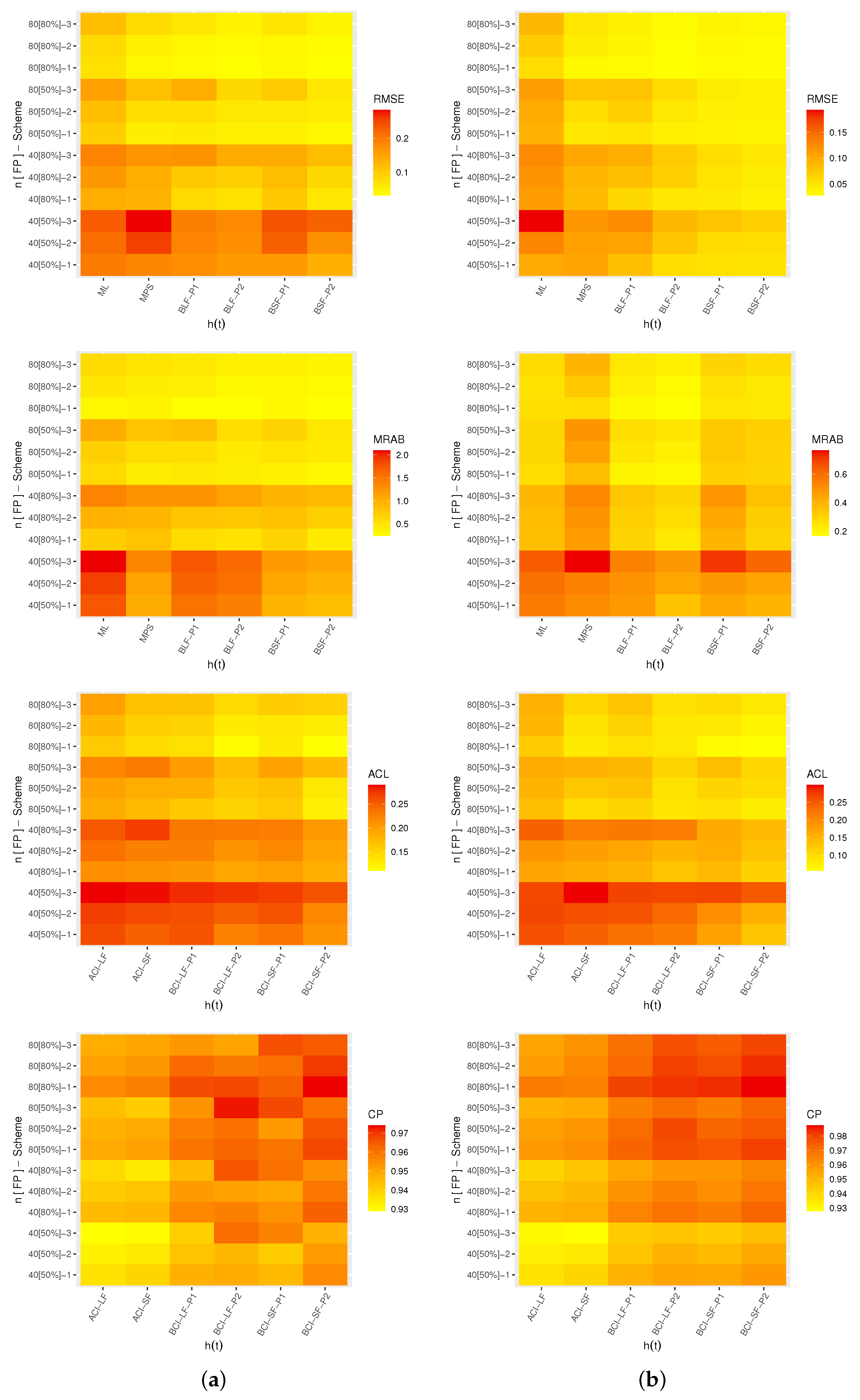
A heat map is a graphical representation of data where the individual values contained in a matrix can be represented by some specific colors. Thus, in
Figure 4,
Figure 5,
Figure 6 and
Figure 7, the simulated results for
,
,
and
are plotted, respectively. Also, all simulation tables are provided in the
Supplementary File. For instance, for prior one (P1), some abbreviations are used in
Figure 4,
Figure 5,
Figure 6 and
Figure 7, such as: Bayes estimates from likelihood function (BLF-P1), Bayes estimates from spacings function (BSF-P1), Bayes credible interval from likelihood function (BCI-LF-P1) and Bayes credible interval from spacings function (BCI-SF-P1).
As a general note, when n (or m) increased, all proposed point/interval estimates performed better. A similar finding was also noted when was narrowed down;
As T increased, it can be seen that:
- –
Both the RMSEs and MRABs for and increased while those associated with and decreased;
- –
The ACLs for , and decreased while those associated with decreased;
- –
The opposite behavior was observed for all unknown parameters based on CP values;
Comparing the proposed censoring plans, the calculated estimates of , , and were more efficient with Scheme-1 than with the others;
Comparing the Bayesian and frequentist estimates of , , and , it is clear that the point (or interval) estimates from the former were better than those obtained from the latter;
Considering the behavior of the suggested priors, the Bayes inferences from prior two were better than those created from prior one since prior two’s variance was smaller than prior one’s;
Comparing the proposed point estimation approaches, in most cases, the simulation results showed that:
- –
For estimating the reliability time parameters and , it was noted that the MPS (along with its "BSF" ) method performed better than the likelihood estimation (along with its "BLF") method;
- –
For estimating the shape parameter , the ML and BSF methods performed better than the others;
- –
For estimating the scale parameter , the MPS and BLF methods performed better than the others;
Comparing the proposed interval estimation approaches, based on the product of spacings methodology, the simulation results showed that the interval estimates obtained from both asymptotic and credible interval methods for , , and were better than the others.
















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}