

Intelligent Computing Collaboration for the Security of the Fog Internet of Things

Abstract
:1. Introduction
1.1. Related Work
1.2. Contributions of This Paper
- We construct a comprehensive resource decision-making model in which the sensing data are transmitted to the fog layer under the physical layer security protection, and the security of unloading to the cloud layer is ensured through encryption.
- To settle the NP-hard resource planning problem, we propose an intelligent method on the basis of deep reinforcement learning to realize the rapid allocation of transmission power, channels and of deciding whether to process the data in the cloud.
- Through generating a large number of snapshots corresponding to the scenario, we train the proposed model and verify the performance of the proposed method through the test set.
2. System Model and Problem Formulation
2.1. System Model
2.2. Problem Formulation
3. Preliminaries
3.1. Reinforcement Learning
3.2. Deep Reinforcement Learning
4. Proposed Intelligent Method
4.1. Preliminary Exploration of the Method
4.2. Lightweight Decision-Making Method
State Space
4.3. Action Space
4.4. Action Reward
4.5. Method Summary
| Algorithm 1 The proposed S-LFRA method | |
| 1: | Input: . |
| 2: | Output: , , and . |
| 3: | Initialize replay memory , random parameters of models , , |
| training rounds I, learning threshold , update frequency of the target network | |
| F, and . | |
| 4: | Run Algorithm 1 in [34], and obtain the output as well as , . |
| 5: | While Do |
| 6: | |
| 7: | For Do |
| 8: | Take a random value from 0 to 1, and execute Equation (11); |
| 9: | Execute the selection of action a, calculate the reward received, and store the |
| quad into ; | |
| 10: | If Do |
| 11: | Take a batch of experience samples randomly from ; |
| 12: | Calculate using Equation (12); |
| 10: | Let ; |
| 10: | End If |
| 15: | If j mod F = 0 Do |
| 16: | ; |
| 17: | Let ; |
| 18: | End If |
| 19: | End For |
| 20: | End While |
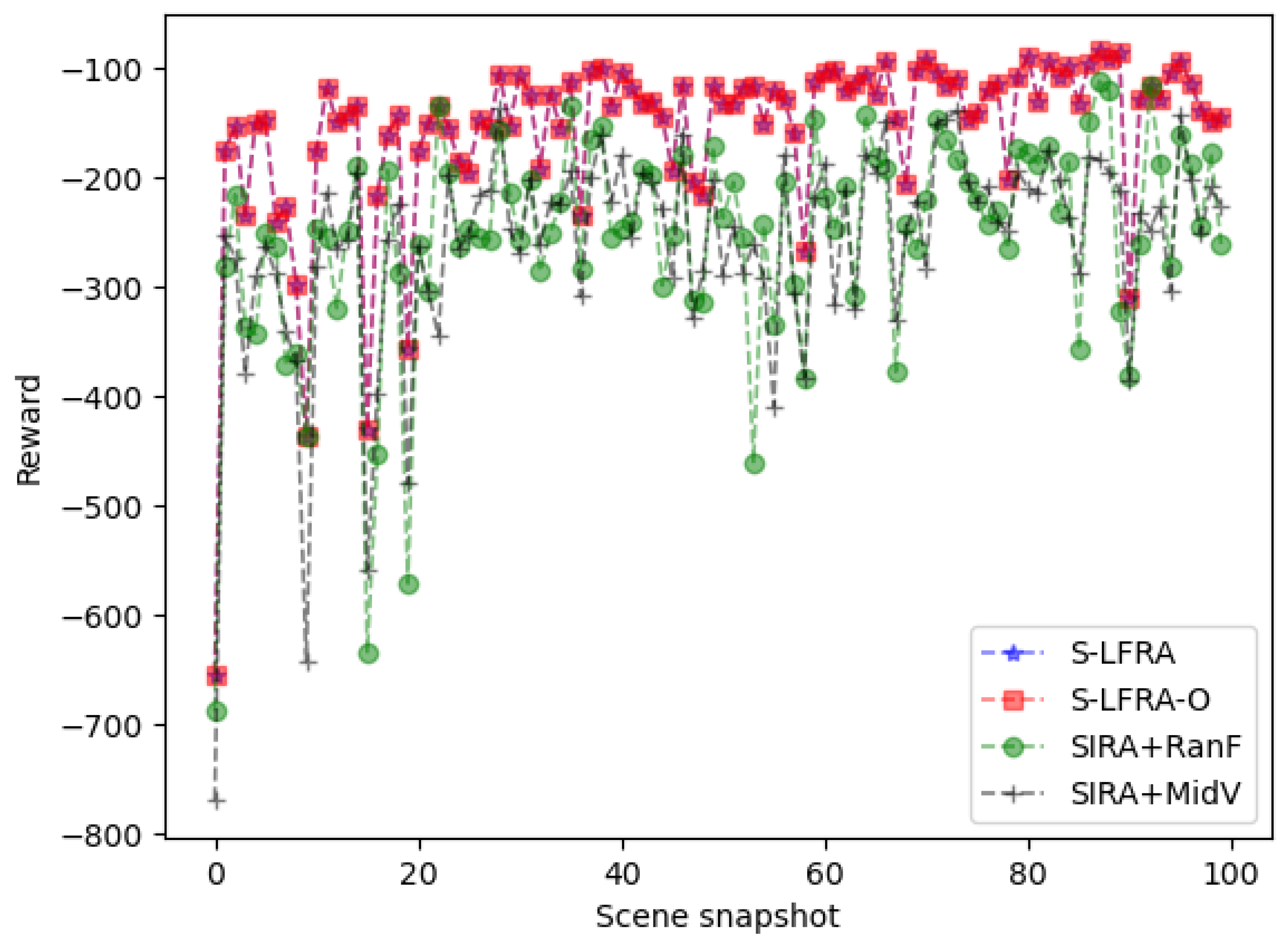
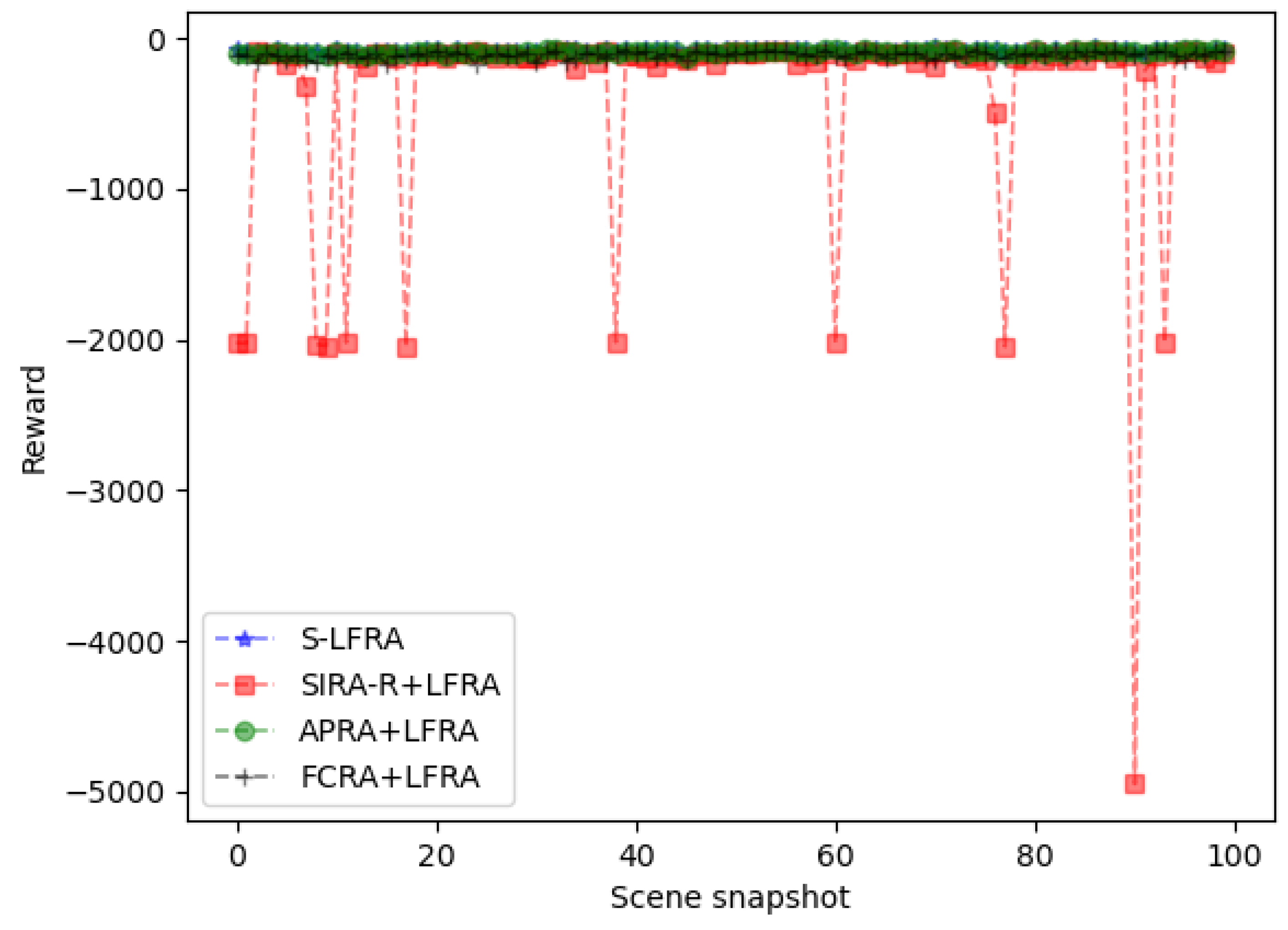
5. Simulation and Performance Analysis
- LFRA: This method corresponds to Method S-LFRA that does not perform Step 4.
- SIRA: The method proposed in [34].
- FCRA: A variation of SIRA. This method finds the optimal power allocation through traversal operation on the basis of using a randomly specified connection relationship between sensing devices and fog nodes.
- APRA: A variation of SIRA. This method finds the optimal connection matching relationship through traversal operation on the basis of using uniform power allocation mode.
- RanF: This method randomly determines whether the sensing data are processed in the cloud or in the fog layer.
- MidV: This method takes the average value of all the sensing data to be processed as the threshold value. Data exceeding this threshold value are processed in the cloud; otherwise, it is processed in the fog layer.
- S-LFRA-O: This method obtains the optimal solution for selecting whether to process in the cloud layer through traversal. It has a high complexity and is not practical in application.
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
Abbreviations
| IoT | Internet of Things |
| DRL | deep reinforcement learning |
| UAV | unmanned aerial vehicle |
| NOMA | non-orthogonal multiple access |
| DQN | deep Q-Network |
| SNR | signal-to-noise ratio |
| MDP | signal-to-interference-noise ratio |
| ResNet | residual network |
| MDP | Markov decision process |
| DNN | deep neural network |
| FL | federal learning |
| QoS | quality of service |
| UE | user equipment |
References
- You, X.; Wang, C.X.; Huang, J.; Gao, X.; Zhang, Z.; Wang, M.; Huang, Y.; Zhang, C.; Jiang, Y.; Wang, Y.; et al. Towards 6G wireless communication networks: Vision, enabling technologies, and new paradigm shifts. Sci. China Inf. Sci. 2021, 64, 1–74. [Google Scholar] [CrossRef]
- Zhang, Z.; Xiao, Y.; Xiao, M.; Ding, Z.; Lei, X.; Karagiannidis, G.K.; Fan, P. 6G Wireless Networks: Vision, Requirements, Architecture, and Key Technologies. IEEE Veh. Technol. Mag. 2019, 14, 28–41. [Google Scholar] [CrossRef]
- Tran-Dang, H.; Krommenacker, N.; Charpentier, P.; Kim, D.-S. Toward the Internet of Things for Physical Internet: Perspectives and Challenges. IEEE Internet Things J. 2020, 7, 4711–4736. [Google Scholar] [CrossRef]
- Nguyen, D.C.; Seneviratne, A.; Li, J.; Niyato, D.; Dobre, O.; Poor, H.V. 6G Internet of Things: A Comprehensive Survey. IEEE Internet Things J. 2022, 9, 359–383. [Google Scholar] [CrossRef]
- Alsharif, M.H.; Jahid, A.; Kelechi, A.H.; Kannadasan, R. Green IoT: A Review and Future Research Directions. Symmetry 2023, 15, 757. [Google Scholar] [CrossRef]
- Cui, T.; Yang, R.; Fang, C.; Yu, S. Deep Reinforcement Learning-Based Resource Allocation for Content Distribution in IoT-Edge-Cloud Computing Environments. Symmetry 2023, 15, 217. [Google Scholar] [CrossRef]
- Kanellopoulos, D.; Sharma, V.K. Dynamic Load Balancing Techniques in the IoT: A Review. Symmetry 2022, 14, 2554. [Google Scholar] [CrossRef]
- Abbas, G.; Mehmood, A.; Carsten, M.; Epiphaniou, G.; Lloret, J. Safety, Security and Privacy in Machine Learning Based Internet of Things. J. Sens. Actuator Netw. 2022, 11, 38. [Google Scholar] [CrossRef]
- Wu, T.-Y.; Guo, X.; Chen, Y.-C.; Kumari, S.; Chen, C.-M. SGXAP: SGX-Based Authentication Protocol in IoV-Enabled Fog Computing. Symmetry 2022, 14, 1393. [Google Scholar] [CrossRef]
- Alomari, A.; Subramaniam, S.K.; Samian, N.; Latip, R.; Zukarnain, Z. Resource Management in SDN-Based Cloud and SDN-Based Fog Computing: Taxonomy Study. Symmetry 2021, 13, 734. [Google Scholar] [CrossRef]
- Bani-Bakr, A.; Hindia, M.N.; Dimyati, K.; Hanafi, E.; Tengku Mohmed Noor Izam, T.F. Multi-Objective Caching Optimization for Wireless Backhauled Fog Radio Access Network. Symmetry 2021, 13, 708. [Google Scholar] [CrossRef]
- Aazam, M.; Islam, S.U.; Lone, S.T.; Abbas, A. Cloud of Things (CoT): Cloud-Fog-IoT Task Offloading for Sustainable Internet of Things. IEEE Trans. Sustain. Comput. 2022, 7, 87–98. [Google Scholar] [CrossRef]
- Martinez, I.; Hafid, A.S.; Jarray, A. Design, Resource Management, and Evaluation of Fog Computing Systems: A Survey. IEEE Internet Things J. 2021, 8, 2494–2516. [Google Scholar] [CrossRef]
- Tange, K.; De Donno, M.; Fafoutis, X.; Dragoni, N. A Systematic Survey of Industrial Internet of Things Security: Requirements and Fog Computing Opportunities. IEEE Commun. Surv. Tutor. 2020, 22, 2489–2520. [Google Scholar] [CrossRef]
- Hassija, V.; Chamola, V.; Saxena, V.; Jain, D.; Goyal, P.; Sikdar, B. A Survey on IoT Security: Application Areas, Security Threats, and Solution Architectures. IEEE Access 2019, 7, 82721–82743. [Google Scholar] [CrossRef]
- Puthal, D.; Mohanty, S.P.; Bhavake, S.A.; Morgan, G.; Ranjan, R. Fog Computing Security Challenges and Future Directions [Energy and Security]. IEEE Consum. Electron. Mag. 2019, 8, 92–96. [Google Scholar] [CrossRef]
- Wazid, M.; Das, A.K.; Shetty, S.; Rodrigues, J.J.P.C.; Guizani, M. AISCM-FH: AI-Enabled Secure Communication Mechanism in Fog Computing-Based Healthcare. IEEE Trans. Inf. Forensics Secur. 2023, 18, 319–334. [Google Scholar] [CrossRef]
- Feng, W.; Zhang, N.; Lin, S.; Li, S.; Wang, Z.; Ai, B.; Zhong, Z. Energy-Efficient Collaborative Offloading in NOMA-Enabled Fog Computing for Internet of Things. IEEE Internet Things J. 2022, 9, 13794–13807. [Google Scholar] [CrossRef]
- Huang, X.; Yang, X.; Chen, Q.; Zhang, J. Task Offloading Optimization for UAV-Assisted Fog-Enabled Internet of Things Networks. IEEE Internet Things J. 2022, 9, 1082–1094. [Google Scholar] [CrossRef]
- Jia, B.; Hu, H.; Zeng, Y.; Xu, T.; Yang, Y. Double-matching resource allocation strategy in fog computing networks based on cost efficiency. J. Commun. Netw. 2018, 20, 237–246. [Google Scholar] [CrossRef]
- Tran-Dang, H.; Bhardwaj, S.; Rahim, T.; Musaddiq, A.; Kim, D.-S. Reinforcement learning based resource management for fog computing environment: Literature review, challenges, and open issues. J. Commun. Netw. 2022, 24, 83–98. [Google Scholar] [CrossRef]
- Fei, Z.; Wang, Y.; Zhao, J.; Wang, X.; Jiao, L. Joint Computational and Wireless Resource Allocation in Multicell Collaborative Fog Computing Networks. IEEE Trans. Wirel. Commun. 2022, 21, 9155–9169. [Google Scholar] [CrossRef]
- Junejo, A.K.; Komninos, N.; McCann, J.A. A Secure Integrated Framework for Fog-Assisted Internet-of-Things Systems. IEEE Internet Things J. 2021, 8, 6840–6852. [Google Scholar] [CrossRef]
- Khashan, O.A. Hybrid Lightweight Proxy Re-Encryption Scheme for Secure Fog-to-Things Environment. IEEE Access 2020, 8, 66878–66887. [Google Scholar] [CrossRef]
- Deb, P.K.; Mukherjee, A.; Misra, S. CEaaS: Constrained Encryption as a Service in Fog-Enabled IoT. IEEE Internet Things J. 2022, 9, 19803–19810. [Google Scholar] [CrossRef]
- Oh, J.; Lee, J.; Kim, M.; Park, Y.; Park, K.; Noh, S. A Secure Data Sharing Based on Key Aggregate Searchable Encryption in Fog-Enabled IoT Environment. IEEE Trans. Netw. Sci. Eng. 2022, 9, 4468–4481. [Google Scholar] [CrossRef]
- Wu, D.; Ansari, N. A Cooperative Computing Strategy for Blockchain-Secured Fog Computing. IEEE Internet Things J. 2020, 7, 6603–6609. [Google Scholar] [CrossRef]
- Ren, J.; Li, J.; Liu, H.; Qin, T. Task offloading strategy with emergency handling and blockchain security in SDN-empowered and fog-assisted healthcare IoT. Tsinghua Sci. Technol. 2022, 27, 760–776. [Google Scholar] [CrossRef]
- Liu, Y.; Dong, Y.; Wang, H.; Jiang, H.; Xu, Q. Distributed Fog Computing and Federated-Learning-Enabled Secure Aggregation for IoT Devices. IEEE Internet Things J. 2022, 9, 21025–21037. [Google Scholar] [CrossRef]
- Krichen, M.; Lahami, M.; Cheikhrouhou, O.; Alroobaea, R.; Maâlej, A.J. Security Testing of Internet of Things for Smart City Applications: A Formal Approach. In Smart Infrastructure and Applications; EAI/Springer Innovations in Communication and Computing; Mehmood, R., See, S., Katib, I., Chlamtac, I., Eds.; Springer: Cham, Switzerland, 2020. [Google Scholar] [CrossRef]
- Keerthi, K.; Roy, I.; Hazra, A.; Rebeiro, C. Formal Verification for Security in IoT Devices. In Security and Fault Tolerance in Internet of Things; Internet of Things; Chakraborty, R., Mathew, J., Vasilakos, A., Eds.; Springer: Cham, Switzerland, 2019. [Google Scholar] [CrossRef]
- Krichen, M. Anomalies Detection Through Smartphone Sensors: A Review. IEEE Sens. J. 2021, 21, 7207–7217. [Google Scholar] [CrossRef]
- Stojanović, B.; Božić, J. Robust Financial Fraud Alerting System Based in the Cloud Environment. Sensors 2022, 22, 9461. [Google Scholar] [CrossRef] [PubMed]
- Zuo, P.; Sun, G.; Li, Z.; Guo, C.; Li, S.; Wei, Z. Towards Secure Transmission in Fog Internet of Things Using Intelligent Resource Allocation. IEEE Sens. J. 2023. to be published. [Google Scholar]
- Sutton, R.S.; Barto, A.G. Reinforcement Learning: An Introduction; MIT Press: Cambridge, MA, USA, 2018. [Google Scholar]
- Zhao, X.; Yang, R.; Zhang, Y.; Yan, M.; Yue, L. Deep Reinforcement Learning for Intelligent Dual-UAV Reconnaissance Mission Planning. Electronics 2022, 11, 2031. [Google Scholar] [CrossRef]
- Ud Din, A.F.; Mir, I.; Gul, F.; Mir, S.; Saeed, N.; Althobaiti, T.; Abbas, S.M.; Abualigah, L. Deep Reinforcement Learning for Integrated Non-Linear Control of Autonomous UAVs. Processes 2022, 10, 1307. [Google Scholar] [CrossRef]
- Zhan, G.; Zhang, X.; Li, Z.; Xu, L.; Zhou, D.; Yang, Z. Multiple-UAV Reinforcement Learning Algorithm Based on Improved PPO in Ray Framework. Drones 2022, 6, 166. [Google Scholar] [CrossRef]
- Zuo, P.; Wang, C.; Wei, Z.; Li, Z.; Zhao, H.; Jiang, H. Deep Reinforcement Learning Based Load Balancing Routing for LEO Satellite Network. In Proceedings of the 2022 IEEE 95th Vehicular Technology Conference: (VTC2022-Spring), Helsinki, Finland, 19–22 June 2022; pp. 1–6. [Google Scholar]
- Yu, Y.; Wang, T.; Liew, S.C. Deep-Reinforcement Learning Multiple Access for Heterogeneous Wireless Networks. IEEE J. Sel. Areas Commun. 2019, 37, 1277–1290. [Google Scholar] [CrossRef]
- Lange, S.; Riedmiller, M. Deep auto-encoder neural networks in reinforcement learning. In Proceedings of the The 2010 International Joint Conference on Neural Networks (IJCNN), Barcelona, Spain, 18–23 July 2010; pp. 1–8. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar] [CrossRef]
- Keras: Deep Learning for Humans. Available online: https://keras.io/ (accessed on 26 February 2023).
- Ziegler, J.L.; Arn, R.T.; Chambers, W. Modulation recognition with GNU radio, keras, and HackRF. In Proceedings of the 2017 IEEE International Symposium on Dynamic Spectrum Access Networks (DySPAN), Baltimore, MD, USA, 6–9 March 2017; pp. 1–3. [Google Scholar] [CrossRef]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Ref. | Application Area | Complexity | Potential Contribution |
|---|---|---|---|
| [23] | fog layer | moderate | trust management |
| [24] | fog/cloud layer | high | data security sharing |
| [25] | perceptual layer | moderate | encryption scheme selection |
| [26] | cloud layer | high | ciphertext retrieval |
| [28] | fog/cloud layer | moderate | task offloading |
| [29] | fog/cloud layer | moderate | secret sharing |
| [30,31] | ensemble | moderate | formal methods for detecting security anomalies |
| [32,33] | ensemble | moderate | anomaly detection |
| [34] | fog/perceptual layer | moderate | wireless secure transmission |
| Hyper-Parameter | Value |
|---|---|
| , , , | 0.9, 0.6, 0.01, 7 |
| Decay rate of , | 0.99 |
| The minimal value of , | 0.001 |
| Experience-replay memory capacity | 2000 |
| Update frequency F of the target network | 500 |
| Experience–replay minibatch size | 32 |
| U, K, M | 5, 2, 8 |
| for training/test set | 5000/1000 |
| Channel bandwidth B | 1 MHz |
| −5∼10 dBm | |
| 10∼50 Mbit | |
| 20∼30 dBm | |
| −80∼−120 dB | |
| , | 2000, 500 |
| Number of layers of the used RESNET | 8 |
| Number of neurons in each layer of RESNET | 64 |
| , | 2∼5, 3∼8 Mbit/s |
| , | 10∼20, 15∼40 Mbit/s |
| r, | 3∼10 Mbit/s, 0.1∼0.5 |
| , | 5∼15, 20∼60 Mbit/s |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhao, H.; Sun, G.; Li, W.; Zuo, P.; Li, Z.; Wei, Z. Intelligent Computing Collaboration for the Security of the Fog Internet of Things. Symmetry 2023, 15, 974. https://doi.org/10.3390/sym15050974
Zhao H, Sun G, Li W, Zuo P, Li Z, Wei Z. Intelligent Computing Collaboration for the Security of the Fog Internet of Things. Symmetry. 2023; 15(5):974. https://doi.org/10.3390/sym15050974
Chicago/Turabian StyleZhao, Hong, Guowei Sun, Weiheng Li, Peiliang Zuo, Zhaobin Li, and Zhanzhen Wei. 2023. "Intelligent Computing Collaboration for the Security of the Fog Internet of Things" Symmetry 15, no. 5: 974. https://doi.org/10.3390/sym15050974