
JKRL: Joint Knowledge Representation Learning of Text Description and Knowledge Graph
Abstract
:1. Introduction
- A KG representation method called Joint Knowledge Representation Learning of Text Description and Knowledge Graph is proposed, which jointly learns the representation of entities and relations based on both structural and textual information, effectively improving the representation of entities and relations.
- An Attention-Bi-LSTM text encoder is designed to encode textual descriptions, which extracts word order features better by introducing word position features and attention mechanisms, and dynamically selects the most relevant information in the textual descriptions by calculating the semantic relevance of words based on different relationships.
- Experimental results on the FB15k dataset demonstrate that the JKRL model has strong competitiveness compared with the baseline model in KG completion tasks and can improve the quality of the vector representation of entities and relationships.
2. Related Work
2.1. Knowledge Representation Model Based on Single Triples
2.1.1. Translational Distance Models
2.1.2. Semantic Matching Models
2.1.3. Neural Network Models
2.2. Knowledge Representation Model Fused with Additional Information
2.2.1. Graph Structure Information
2.2.2. Entity Description Information
2.2.3. Other Information
3. Joint Knowledge Representation Learning of Text Description and Knowledge Graph
3.1. Symbols and Definitions
3.2. The Overall Architecture of the Model
- Representation learning of triple structure (blue area): Learns the structural representation of entities and relationships from the perspective of KG. Based on the universality of the representation learning framework, a simple and efficient TransE model is used to embed the structure vector of the head and tail entities and the structure vector of the relationship, which are denoted as , .
- Representation learning of entity description (green area): A CNN model is used to encode the entity description of the triple to obtain the text representation of the head entity and tail entity, which are denoted as .
- Representation learning of relation description (yellow area): The relation description of the triple refers to the text containing the entity pair . The Attention-Bi-LSTM text encoder is designed to mine the semantic information in the relation description to obtain the text representation of the relation, which is denoted as .
3.3. Representation Learning of Triple Structure
3.4. Representation Learning of Entity Descriptions
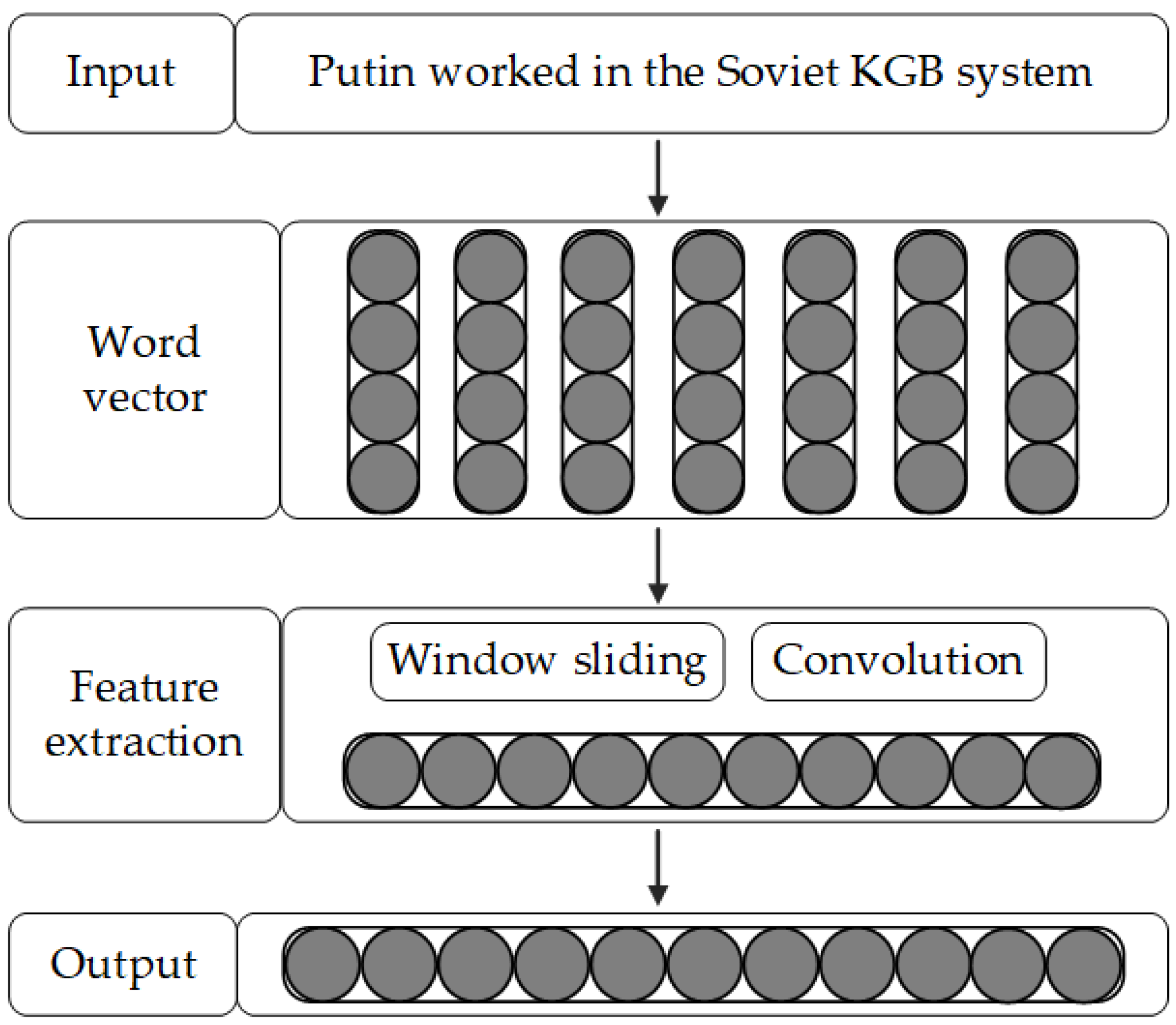
- Input: Firstly, all stop words and punctuations in the entity text description are deleted to construct the expected vocabulary for training. Then, the entity annotation tool is used to automatically annotate the entities in to obtain the annotated text, forming the entity text description related to a specific triple. Finally, the word2vec tool is used to train the word vector to correspond to each word in the text description to form the input vector .
- Convolution layer: The input and output of the convolution layer are represented by and , respectively. Because the length of the text description statement is different, the length of the input vector is inconsistent. After setting the maximum sentence length for the convolution operation, if the sentence length is less than , the end of the embedding vector of the sentence is filled with 0, and if the sentence length is greater than , the redundant words are removed. We need to add 0 to the end of the embedded vector of the sentence. Then, the input vector is processed based on the sliding window mechanism. We define the size of the window as , set the step size of the sliding window as 1, and the content of the sliding window is . The corresponding output vector is extracted by a convolution operation. The specific formula of this process is defined as follows:where represents the convolution kernel, m is the dimension of the output vector, n represents the dimension of the input vector, represents the bias term, and represents the activation function.
- Pooling layer: In order to reduce the number of parameters of the CNN encoder and the influence of noise, the feature vectors’ output by the convolutional layer needs to be pooled. We use the maximum pooling layer to optimize the semantic features in the feature vectors. It is divided into multiple non-overlapping windows, and the maximum value is selected in each window to form a new output vector in order to obtain the most significant features in each dimension:
- Output layer: The text vector of the entity is obtained by multiplying the vector matrix of the input vector. The text vector form of the entity is defined aswhere is the parameter matrix and is the bias term, and finally the head and tail entity text vectors and are obtained.
3.5. Representation Learning of Relation Description
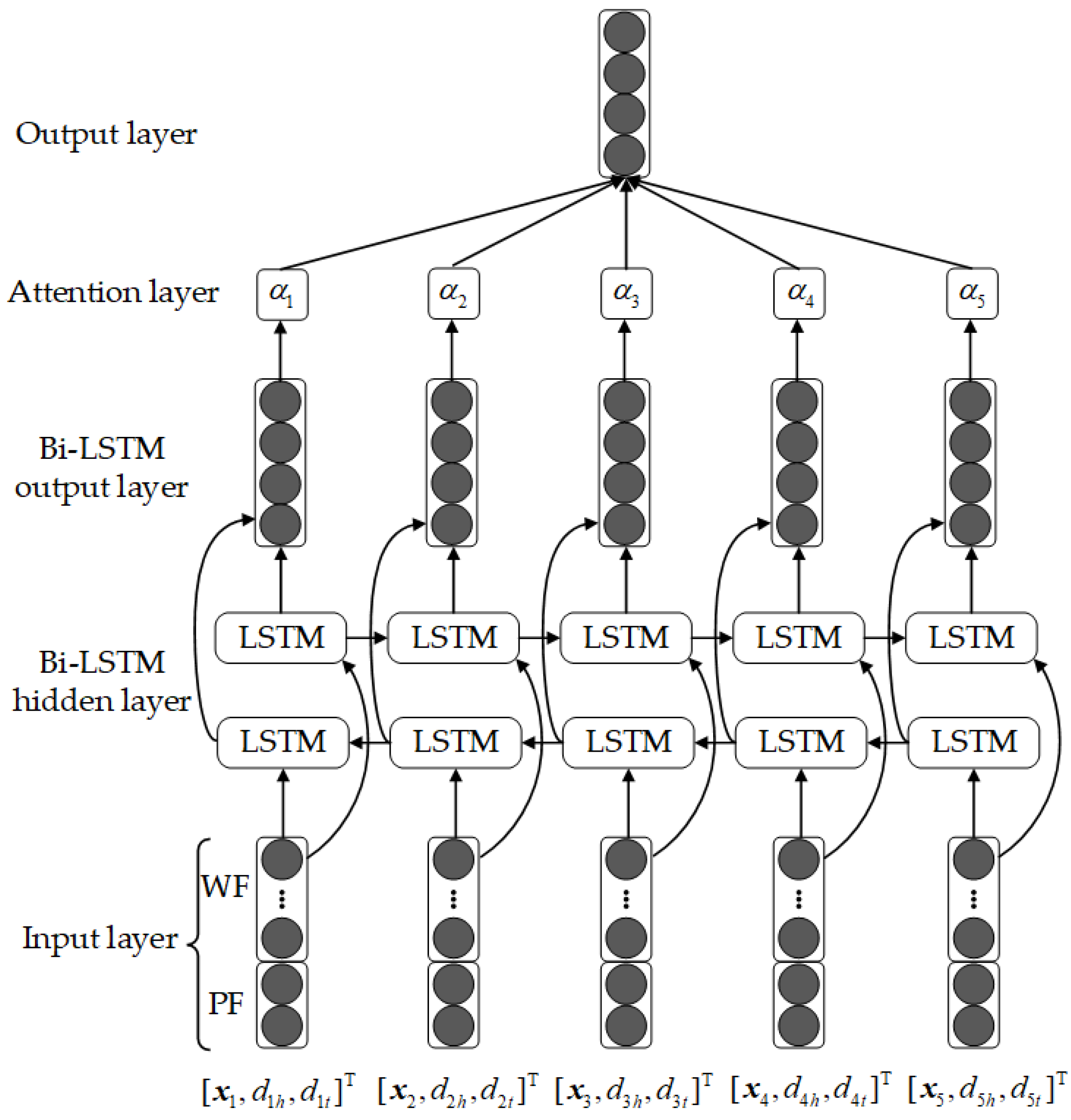
- The relationship description statement is preprocessed and represented by word embedding. The feature vector of each word is obtained by word2vec training. In addition, the relative distance between each word and the head and tail entities in the sentence is calculated.
- In the Attention-Bi-LSTM encoder, the Bi-LSTM hidden layer performs forward and backward LSTM encoding on the input vector.
- In the attention layer of Attention-Bi-LSTM, the corresponding attention weight is calculated according to the correlation degree between each word and the triplet relationship, and finally the text vector of the relationship is obtained in the output layer.
- Word embedding representation
- 2.
- Bi-LSTM coding
- 3.
- Attention mechanism
4. Experiment and Result Analysis
4.1. Experimental Environment
4.2. Dataset
4.3. Evaluation Indicators
- 1.
- Link prediction task
- 2.
- Triple classification task
4.4. Baseline Model
4.5. Experimental Settings
4.6. Analysis of Experimental Results
- 1.
- Entity prediction task
- Joint representation learning models combining structure and text description are better than the Trans series models based on structural representation in Mean Rank and Hits@10, indicating that effectively integrating the text description can provide rich semantic resources for knowledge graph representation, thus improving entity and relationship representation. It plays an important auxiliary role in the optimization of knowledge graph representation learning.
- JKRL outperforms other baseline models that combine structure and text description for joint representation in Mean Rank and Hits@10, indicating that the JKRL model architecture can extract features from the entity description and relationship description, so as to effectively conduct joint representation learning based on structure and text description. Since DKRL and Jointly only consider the fusion of entity description information, and Joint only considers the fusion of relationship description information, they only use text descriptions to enrich the representation of entities or relationships from one perspective, resulting in limited improvement in representation. JKRL combines entity description and relation description to carry out joint representation learning of knowledge graphs. In addition, according to the characteristics of and differences in the two pieces of descriptive information, the corresponding coding model is designed to fully extract the deep semantic features in the text description, thus effectively improving the representation learning ability of knowledge graph.
- In particular, JKRL(A-Bi-LSTM) achieved better experimental results than Jointly(A-Bi-LSTM), which indicates that JKRL can better extract word order features by introducing word position features and using A-Bi-LSTM to encode relationship descriptions. It also shows that combining entity description and relationship description at the same time to improve the knowledge map representation learning is better than using unilateral text description information.
- The data index of JKRL(CNN+A-Bi-LSTM) is significantly better than that of JKRL(CNN+Bi-LSTM). The attention mechanism of JKRL(CNN+A-Bi-LSTM) is to dynamically allocate weights according to different relationships and word correlations. Because the FB15K dataset contains a variety of complex relationships, JKRL(A-Bi-LSTM) can play a better role, which shows the effectiveness of the Attention-Bi-LSTM encoder of the model.
- JKRL(A-Bi-LSTM) adopts the A-Bi-LSTM encoder for both entity description and relation description, and both introduce word location features. However, compared with JKRL(CNN+A-Bi-LSTM), the performance was not improved, and even decreased. This shows that the effect of A-Bi-LSTM in text feature extraction for entity description is not as good as CNN. Since the entity description text may present an entity from various aspects, and the position of the head and tail entities in the text has no direct influence on the semantic expression of the text, the introduction of the attention mechanism and location features in the A-Bi-LSTM encoder does not play an effective role in the representation of the entity description. Noise is even introduced to reduce the entity representation effect, which leads to the overall joint learning performance decline.
- The joint representation model that combines structure and text description is superior to the Trans series model in overall entity prediction results. TransD enables the interaction between entities and relationships and also achieved good entity prediction performance. This shows that in addition to optimizing the knowledge graph representation based on the triple structure, the semantic representation of entities or relationships can be effectively enhanced by fusing the triple structure and text description, and the representation ability of the knowledge graph can be improved.
- Compared with the structure-based Trans series representation methods, JKRL outperforms the Trans series models in all indicators. Compared with joint representation models that fuse structure and textual descriptions, JKRL shows the best predictive performance for most relation types. It shows that JKRL not only effectively encodes the representation of the triplet structure, entity description and relationship description text, but also effectively balances the contribution of each vector representation in the learning process through the joint evaluation function, and jointly promotes the representation ability of the KG, thus improving the performance of entity prediction.
- Joint has the best entity prediction performance among all baseline models. JKRL has similar indexes to Joint in N-1, N-N and 1-N relations and is significantly better than Joint in other multiple indexes, which indicates the importance of introducing entity description and relationship description in the JKRL model. Entity description encoding based on CNN and relationship description encoding based on Attention-Bi-LSTM can effectively extract text features and improve the model’s ability of knowledge representation.
- By comparing JKRL and its variant models, we can rank their entity prediction capabilities as follows: JKRL(CNN+A-Bi-LSTM) > JKRL(A-Bi-LSTM) > JKRL(CNN+Bi-LSTM). This shows that the attention mechanism in A-Bi-LSTM plays an extremely important role in encoding the relational description. The attention mechanism calculates the semantic relevance of each word and different relations in the relational description, so as to dynamically select the most relevant information from the relational description and obtain the accurate relational text representation. However, due to the high correlation between the entity description text and the entity itself, the relative distance between the word and the entity has little connection with the expression of the word semantics. If A-Bi-LSTM is used to encode entity description, the attention mechanism has limited improvement in the extraction of semantic features, and the introduction of position features will bring noise and cause the overall model performance to decline. However, CNN can effectively capture local features in the entity description text by sliding on the text sequence through the convolution kernel and has the advantage of parallel computation with higher computational efficiency.
- 2.
- Triple classification task
- Compared with all baseline models, JKRL has the best performance, with an accuracy rate of 93.2% on the triplet classification task, which greatly exceeds the structure-based Trans series representation models. Compared with DKRL and Joint, it increased by 3.1% and 4.6%, respectively, and the accuracy was significantly improved. Compared to Jointly, the accuracy was improved by 1.7%. This proves the effectiveness of JKRL, which can effectively extract the semantic features of text description to improve the representation of entities and relations.
- The triple classification accuracy of the JKRL(Bi-LSTM) model is 91.8%, which is 1.4% lower than that of the JKRL(A-Bi-LSTM) model. This shows the effectiveness of the Attention-Bi-LSTM encoding the relational description. The attention mechanism is introduced to calculate the weight of each word, which reduces the noise at the word level in the text description, and can dynamically select the most relevant content from the relationship description for modeling, so as to obtain a more accurate text representation of the relationship.
- JKRL(A-Bi-LSTM) uses A-Bi-LSTM to encode both entity description and relationship description. In the case of increased model complexity, the accuracy rate is slightly decreased, decreasing by 0.6% compared with JKRL(CNN+A-Bi-LSTM). This once again verifies the validity of entity description encoding using CNN, which can not only effectively capture the deep semantic features in the entity description text, but also has higher computational efficiency.
- 3.
- Runtime comparison
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Li, M.; Sun, Z.; Zhang, S.; Zhang, W. Enhancing knowledge graph embedding with relational constraints. Neurocomputing 2021, 429, 77–88. [Google Scholar] [CrossRef]
- Li, Z.; Liu, H.; Zhang, Z.; Liu, T.; Shu, J. Recalibration convolutional networks for learning interaction knowledge graph embedding. Neurocomputing 2021, 427, 118–130. [Google Scholar] [CrossRef]
- Gong, F.; Wang, M.; Wang, H.; Wang, S.; Liu, M. SMR: Medical knowledge graph embedding for safe medicine recommendation. Big Data Res. 2021, 23, 100174. [Google Scholar] [CrossRef]
- Gesese, G.A.; Biswas, R.; Sack, H. A Comprehensive Survey of Knowledge Graph Embeddings with Literals: Techniques and Applications. DL4KG@ ESWC 2019, 2377, 31–40. [Google Scholar]
- Wang, M.; Qiu, L.; Wang, X. A survey on knowledge graph embeddings for link prediction. Symmetry 2021, 13, 485. [Google Scholar] [CrossRef]
- Ferrari, I.; Frisoni, G.; Italiani, P.; Moro, G.; Sartori, C. Comprehensive Analysis of Knowledge Graph Embedding Techniques Benchmarked on Link Prediction. Electronics 2022, 11, 3866. [Google Scholar] [CrossRef]
- Xu, Z.; Sheng, Y.; He, l.; Wang, Y. Review on knowledge graph techniques. J. Univ. Electron. Sci. Technol. China 2016, 45, 589–606. [Google Scholar]
- Shu, S.; LI, S.; Hao, X.; Zhang, L. Knowledge graph embedding technology: A review. J. Front. Comput. Sci. Technol. 2021, 15, 2048. [Google Scholar]
- Xie, Q.; Ma, X.; Dai, Z.; Hovy, E. An interpretable knowledge transfer model for knowledge base completion. arXiv 2017, arXiv:1704.05908. [Google Scholar]
- Shi, B.; Weninger, T. Proje: Embedding projection for knowledge graph completion. In Proceedings of the AAAI Conference on Artificial Intelligence, San Francisco, CA, USA, 4–9 February 2017. [Google Scholar]
- Frisoni, G.; Moro, G.; Carlassare, G.; Carbonaro, A. Unsupervised event graph representation and similarity learning on biomedical literature. Sensors 2021, 22, 3. [Google Scholar] [CrossRef]
- Mintz, M.; Bills, S.; Snow, R.; Jurafsky, D. Distant supervision for relation extraction without labeled data. In Proceedings of the Joint Conference of the 47th Annual Meeting of the ACL and the 4th International Joint Conference on Natural Language Processing of the AFNLP, Singapore, 2–7 August 2009; pp. 1003–1011. [Google Scholar]
- Xie, R.; Liu, Z.; Jia, J.; Luan, H.; Sun, M. Representation learning of knowledge graphs with entity descriptions. In Proceedings of the AAAI Conference on Artificial Intelligence, Phoenix, AZ, USA, 12–17 February 2016. [Google Scholar]
- Mikolov, T.; Chen, K.; Corrado, G.; Dean, J. Efficient estimation of word representations in vector space. arXiv 2013, arXiv:1301.3781. [Google Scholar]
- Han, X.; Liu, Z.; Sun, M. Joint representation learning of text and knowledge for knowledge graph completion. arXiv 2016, arXiv:1611.04125. [Google Scholar]
- Wang, Z.; Zhang, J.; Feng, J.; Chen, Z. Knowledge graph and text jointly embedding. In Proceedings of the 2014 Conference on Empirical Methods in Natural Language Processing (EMNLP), Doha, Qatar, 25–29 October 2014; pp. 1591–1601. [Google Scholar]
- Zhong, H.; Zhang, J.; Wang, Z.; Wan, H.; Chen, Z. Aligning knowledge and text embeddings by entity descriptions. In Proceedings of the 2015 Conference on Empirical Methods in Natural Language Processing, Lisbon, Portugal, 17–21 September 2015; pp. 267–272. [Google Scholar]
- Zhang, D.; Yuan, B.; Wang, D.; Liu, R. Joint semantic relevance learning with text data and graph knowledge. In Proceedings of the 3rd Workshop on Continuous Vector Space Models and Their Compositionality, Beijing, China, 26–31 July 2015; pp. 32–40. [Google Scholar]
- He, M.; Du, X.; Wang, B. Representation learning of Knowledge Graphs via fine-grained relation description combinations. IEEE Access 2019, 7, 26466–26473. [Google Scholar] [CrossRef]
- Xu, J.; Chen, K.; Qiu, X.; Huang, X. Knowledge graph representation with jointly structural and textual encoding. arXiv 2016, arXiv:1611.08661. [Google Scholar]
- Bahdanau, D.; Cho, K.; Bengio, Y. Neural machine translation by jointly learning to align and translate. arXiv 2014, arXiv:1409.0473. [Google Scholar]
- Hochreiter, S.; Schmidhuber, J. Long short-term memory. Neural Comput. 1997, 9, 1735–1780. [Google Scholar] [CrossRef] [PubMed]
- Bordes, A.; Usunier, N.; Garcia-Duran, A.; Weston, J.; Yakhnenko, O. Translating embeddings for modeling multi-relational data. In Proceedings of the Advances in Neural Information Processing Systems 26 (NIPS 2013), Lake Tahoe, NA, USA, 5–10 December 2013. [Google Scholar]
- Wang, Z.; Zhang, J.; Feng, J.; Chen, Z. Knowledge graph embedding by translating on hyperplanes. In Proceedings of the AAAI Conference on Artificial Intelligence, Québec City, QC, Canada, 27–31 July 2014. [Google Scholar]
- Lin, Y.; Liu, Z.; Sun, M.; Liu, Y.; Zhu, X. Learning entity and relation embeddings for knowledge graph completion. In Proceedings of the AAAI Conference on Artificial Intelligence, Austin, TX, USA, 25–30 January 2015. [Google Scholar]
- Ji, G.; He, S.; Xu, L.; Liu, K.; Zhao, J. Knowledge graph embedding via dynamic mapping matrix. In Proceedings of the 53rd Annual Meeting of the Association for Computational Linguistics and the 7th International Joint Conference on Natural Language Processing, Beijing, China, 26–31 July 2015; Volume 1, pp. 687–696. [Google Scholar]
- Yang, S.; Tian, J.; Zhang, H.; Yan, J.; He, H.; Jin, Y. TransMS: Knowledge Graph Embedding for Complex Relations by Multidirectional Semantics. In Proceedings of the IJCAI, Macao, China, 10–16 August 2019; pp. 1935–1942. [Google Scholar]
- Yang, B.; Yih, W.-T.; He, X.; Gao, J.; Deng, L. Embedding entities and relations for learning and inference in knowledge bases. arXiv 2014, arXiv:1412.6575. [Google Scholar]
- Nickel, M.; Rosasco, L.; Poggio, T. Holographic embeddings of knowledge graphs. In Proceedings of the AAAI Conference on Artificial Intelligence, Phoenix, AZ, USA, 12–17 February 2016. [Google Scholar]
- Liu, H.; Wu, Y.; Yang, Y. Analogical inference for multi-relational embeddings. In Proceedings of the International Conference on Machine Learning, Sydney, Australia, 6–11 August 2017; pp. 2168–2178. [Google Scholar]
- Trouillon, T.; Welbl, J.; Riedel, S.; Gaussier, É.; Bouchard, G. Complex embeddings for simple link prediction. In Proceedings of the International Conference on Machine Learning, New York, NY, USA, 20–22 June 2016; pp. 2071–2080. [Google Scholar]
- Dettmers, T.; Minervini, P.; Stenetorp, P.; Riedel, S. Convolutional 2d knowledge graph embeddings. In Proceedings of the AAAI Conference on Artificial Intelligence, New Orleans, LA, USA, 2–7 February 2018. [Google Scholar]
- Nguyen, D.Q.; Nguyen, T.D.; Nguyen, D.Q.; Phung, D. A novel embedding model for knowledge base completion based on convolutional neural network. arXiv 2017, arXiv:1712.02121. [Google Scholar]
- Lin, Y.; Liu, Z.; Luan, H.; Sun, M.; Rao, S.; Liu, S. Modeling relation paths for representation learning of knowledge bases. arXiv 2015, arXiv:1506.00379. [Google Scholar]
- Feng, J.; Huang, M.; Yang, Y.; Zhu, X. GAKE: Graph aware knowledge embedding. In Proceedings of the COLING 2016, the 26th International Conference on Computational Linguistics: Technical Papers, Osaka, Japan, 11–16 December 2016; pp. 641–651. [Google Scholar]
- Wang, Z.; Li, J.; Liu, Z.; Tang, J. Text-enhanced representation learning for knowledge graph. In Proceedings of the International joint conference on artificial intelligent (IJCAI), New York, NY, USA, 9–15 July 2016; pp. 4–17. [Google Scholar]
- An, B.; Chen, B.; Han, X.; Sun, L. Accurate text-enhanced knowledge graph representation learning. In Proceedings of the 2018 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, New Orleans, LA, USA, 1–6 June 2018; Volume 1, pp. 745–755. [Google Scholar]
- Yao, L.; Mao, C.; Luo, Y. KG-BERT: BERT for knowledge graph completion. arXiv 2019, arXiv:1909.03193. [Google Scholar]
- Devlin, J.; Chang, M.-W.; Lee, K.; Toutanova, K. Bert: Pre-training of deep bidirectional transformers for language understanding. arXiv 2018, arXiv:1810.04805. [Google Scholar]
- Wang, B.; Shen, T.; Long, G.; Zhou, T.; Wang, Y.; Chang, Y. Structure-augmented text representation learning for efficient knowledge graph completion. In Proceedings of the Web Conference 2021, Virtual, 19–23 April 2021; pp. 1737–1748. [Google Scholar]
- Shen, J.; Wang, C.; Gong, L.; Song, D. Joint language semantic and structure embedding for knowledge graph completion. arXiv 2022, arXiv:2209.08721. [Google Scholar]
- Chen, M.; Tian, Y.; Chang, K.-W.; Skiena, S.; Zaniolo, C. Co-training embeddings of knowledge graphs and entity descriptions for cross-lingual entity alignment. arXiv 2018, arXiv:1806.06478. [Google Scholar]
- Cochez, M.; Garofalo, M.; Lenßen, J.; Pellegrino, M.A. A first experiment on including text literals in KGloVe. arXiv 2018, arXiv:1807.11761. [Google Scholar]
- Wu, Y.; Wang, Z. Knowledge graph embedding with numeric attributes of entities. In Proceedings of the Third Workshop on Representation Learning for NLP, Melbourne, Australia, 20 July 2018; pp. 132–136. [Google Scholar]
- Trisedya, B.D.; Qi, J.; Zhang, R. Entity alignment between knowledge graphs using attribute embeddings. In Proceedings of the AAAI Conference on Artificial Intelligence, Honolulu, HI, USA, 27 January–1 February 2019; pp. 297–304. [Google Scholar]
- Pezeshkpour, P.; Chen, L.; Singh, S. Embedding multimodal relational data for knowledge base completion. arXiv 2018, arXiv:1809.01341. [Google Scholar]
- Xie, R.; Liu, Z.; Sun, M. Representation learning of knowledge graphs with hierarchical types. In Proceedings of the IJCAI, New York, NY, USA, 9–15 July 2016; pp. 2965–2971. [Google Scholar]
- Esteban, C.; Tresp, V.; Yang, Y.; Baier, S.; Krompaß, D. Predicting the co-evolution of event and knowledge graphs. In Proceedings of the 2016 19th International Conference on Information Fusion (FUSION), Heidelberg, Germany, 5–8 July 2016; pp. 98–105. [Google Scholar]
- Guan, S.; Jin, X.; Wang, Y.; Cheng, X. Link prediction on n-ary relational data. In Proceedings of the The World Wide Web Conference, San Francisco, CA, USA, 13–17 May 2019; pp. 583–593. [Google Scholar]
- Rosso, P.; Yang, D.; Cudré-Mauroux, P. Beyond triplets: Hyper-relational knowledge graph embedding for link prediction. In Proceedings of the Web Conference 2020, Taipei, Taiwan, 20–24 April 2020; pp. 1885–1896. [Google Scholar]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, Ł.; Polosukhin, I. Attention is all you need. In Proceedings of the Advances in Neural Information Processing Systems 30 (NIPS 2017), Long Beach, CA, USA, 4–9 December 2017. [Google Scholar]
- Chen, Y. Convolutional Neural Network for Sentence Classification; University of Waterloo: Waterloo, ON, Canada, 2015. [Google Scholar]
- Mikolov, T.; Sutskever, I.; Chen, K.; Corrado, G.S.; Dean, J. Distributed representations of words and phrases and their compositionality. In Proceedings of the Advances in Neural Information Processing Systems 26 (NIPS 2013), Lake Tahoe, NA, USA, 5–10 December 2013. [Google Scholar]
- Wang, J.Q.; Du, Y.; Wang, J. LSTM based long-term energy consumption prediction with periodicity. Energy 2020, 197, 117197. [Google Scholar] [CrossRef]
- Bollacker, K.; Cook, R.; Tufts, P. Freebase: A shared database of structured general human knowledge. In Proceedings of the AAAI, Vancouver, BC, Canada, 22–26 July 2007; pp. 1962–1963. [Google Scholar]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Symbol | Description |
|---|---|
| Head entity, relation entity and tail entity | |
| Structure vector of head entity, relation and tail entity | |
| Text vectors of head entity, relation and tail entity | |
| Word vector | |
| The attention weight of word under relation | |
| Text description statement | |
| Text description statement set |
| Dataset | Number of Entities | Relation Number | Training Set | Validation Set | Test Set |
|---|---|---|---|---|---|
| FB15k | 14,904 | 1341 | 472,860 | 48,991 | 57,803 |
| Evaluating Indicator | Mean Rank | Hits@10 | ||
|---|---|---|---|---|
| Raw | Filter | Raw | Filter | |
| TransE | 243 | 125 | 0.349 | 0.471 |
| TransH | 212 | 87 | 0.457 | 0.644 |
| TransR | 198 | 77 | 0.482 | 0.687 |
| TransD | 194 | 81 | 0.534 | 0.773 |
| DKRL | 181 | 91 | 0.496 | 0.674 |
| Jointly(Bi-LSTM) | 179 | 90 | 0.493 | 0.697 |
| Jointly(A-Bi-LSTM) | 167 | 73 | 0.529 | 0.755 |
| Joint | — | — | — | 0.787 |
| JKRL(CNN+Bi-LSTM) | 162 | 78 | 0.538 | 0.786 |
| JKRL(A-Bi-LSTM) | 154 | 71 | 0.559 | 0.802 |
| JKRL(CNN+A-Bi-LSTM) | 148 | 67 | 0.574 | 0.813 |
| Experiment | Head Entity Prediction | Tail Entity Prediction | Overall | ||||||
|---|---|---|---|---|---|---|---|---|---|
| Relation Classification | 1-1 | 1-N | N-1 | N-N | 1-1 | 1-N | N-1 | N-N | |
| TransE | 0.437 | 0.657 | 0.182 | 0.472 | 0.437 | 0.197 | 0.667 | 0.500 | 0.471 |
| TransH | 0.668 | 0.876 | 0.287 | 0.645 | 0.655 | 0.398 | 0.833 | 0.672 | 0.644 |
| TransR | 0.788 | 0.892 | 0.341 | 0.692 | 0.792 | 0.374 | 0.904 | 0.721 | 0.687 |
| TransD | 0.861 | 0.955 | 0.398 | 0.785 | 0.854 | 0.506 | 0.944 | 0.812 | 0.773 |
| DKRL | — | — | — | — | — | — | — | — | 0.674 |
| Jointly(Bi-LSTM) | 0.813 | 0.889 | 0.188 | 0.452 | 0.801 | 0.254 | 0.896 | 0.524 | 0.697 |
| Jointly(A-Bi-LSTM) | 0.838 | 0.951 | 0.211 | 0.479 | 0.830 | 0.308 | 0.947 | 0.531 | 0.755 |
| Joint | 0.827 | 0.891 | 0.450 | 0.807 | 0.817 | 0.577 | 0.874 | 0.828 | 0.787 |
| JKRL(CNN+Bi-LSTM) | 0.852 | 0.919 | 0.402 | 0.765 | 0.838 | 0.512 | 0.917 | 0.803 | 0.786 |
| JKRL(A-Bi-LSTM) | 0.867 | 0.935 | 0.411 | 0.776 | 0.848 | 0.519 | 0.938 | 0.818 | 0.802 |
| JKRL(CNN+A-Bi-LSTM) | 0.872 | 0.958 | 0.424 | 0.780 | 0.865 | 0.527 | 0.955 | 0.832 | 0.813 |
| Model | Accuracy |
|---|---|
| TransE | 0.798 |
| TransH | 0.877 |
| TransR | 0.839 |
| TransD | 0.880 |
| DKRL | 0.901 |
| Jointly(Bi-LSTM) | 0.905 |
| Jointly(A-Bi-LSTM) | 0.915 |
| Joint | 0.886 |
| JKRL(CNN+Bi-LSTM) | 0.918 |
| JKRL(A-Bi-LSTM) | 0.926 |
| JKRL(CNN+A-Bi-LSTM) | 0.932 |
| Model | Training Time | Triple Classification Accuracy |
|---|---|---|
| JKRL(CNN+Bi-LSTM) | 8.7834 h | 0.918 |
| JKRL(A-Bi-LSTM) | 25.8745 h | 0.926 |
| JKRL(CNN+A-Bi-LSTM) | 10.2359 h | 0.932 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Xu, G.; Zhang, Q.; Yu, D.; Lu, S.; Lu, Y. JKRL: Joint Knowledge Representation Learning of Text Description and Knowledge Graph. Symmetry 2023, 15, 1056. https://doi.org/10.3390/sym15051056
Xu G, Zhang Q, Yu D, Lu S, Lu Y. JKRL: Joint Knowledge Representation Learning of Text Description and Knowledge Graph. Symmetry. 2023; 15(5):1056. https://doi.org/10.3390/sym15051056
Chicago/Turabian StyleXu, Guoyan, Qirui Zhang, Du Yu, Sijun Lu, and Yuwei Lu. 2023. "JKRL: Joint Knowledge Representation Learning of Text Description and Knowledge Graph" Symmetry 15, no. 5: 1056. https://doi.org/10.3390/sym15051056