
SMCEWS: Binary Robust Multicentre Features


Abstract
:1. Introduction
2. Method
2.1. Binary Encoding
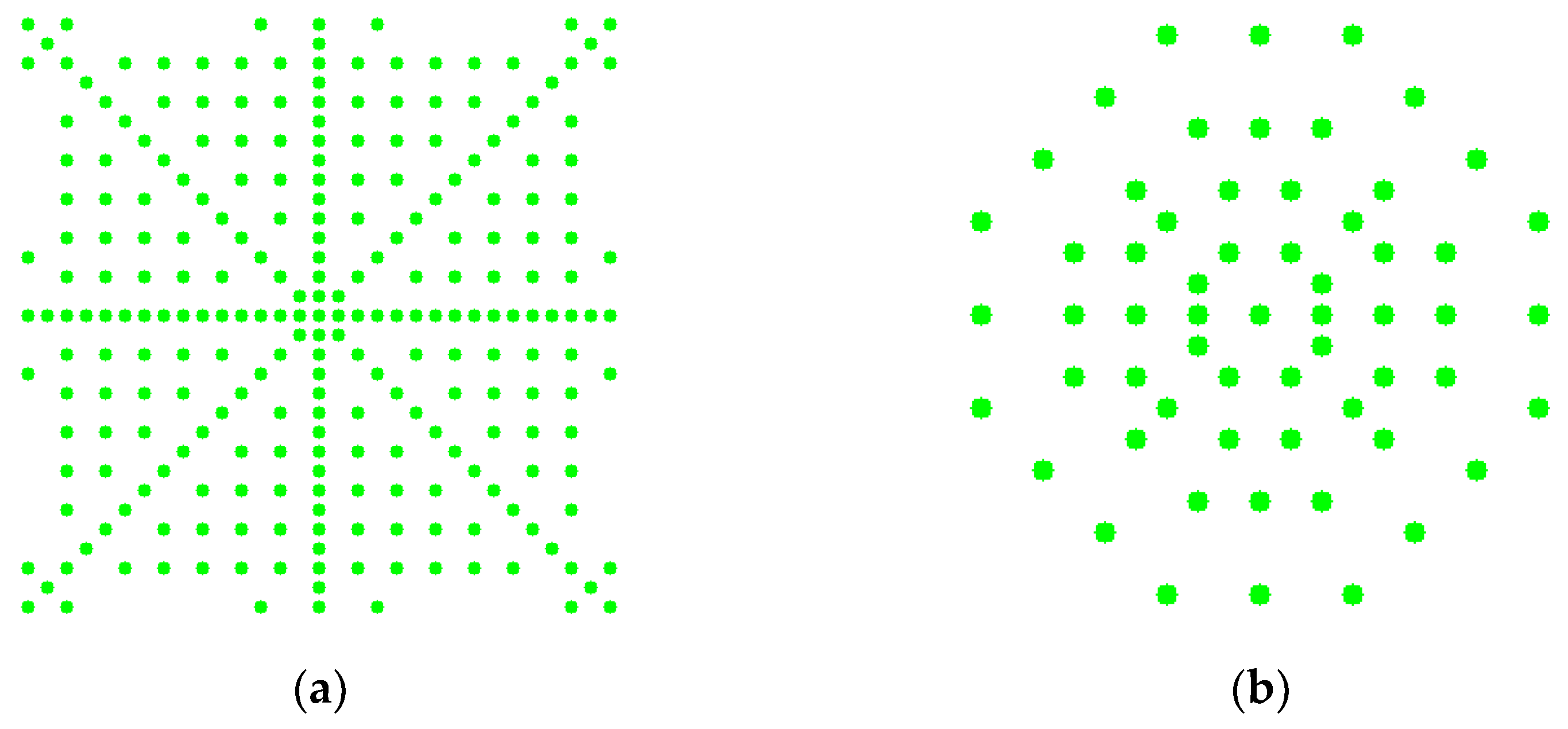
2.2. Patterns of Sampling Distribution of Descriptors
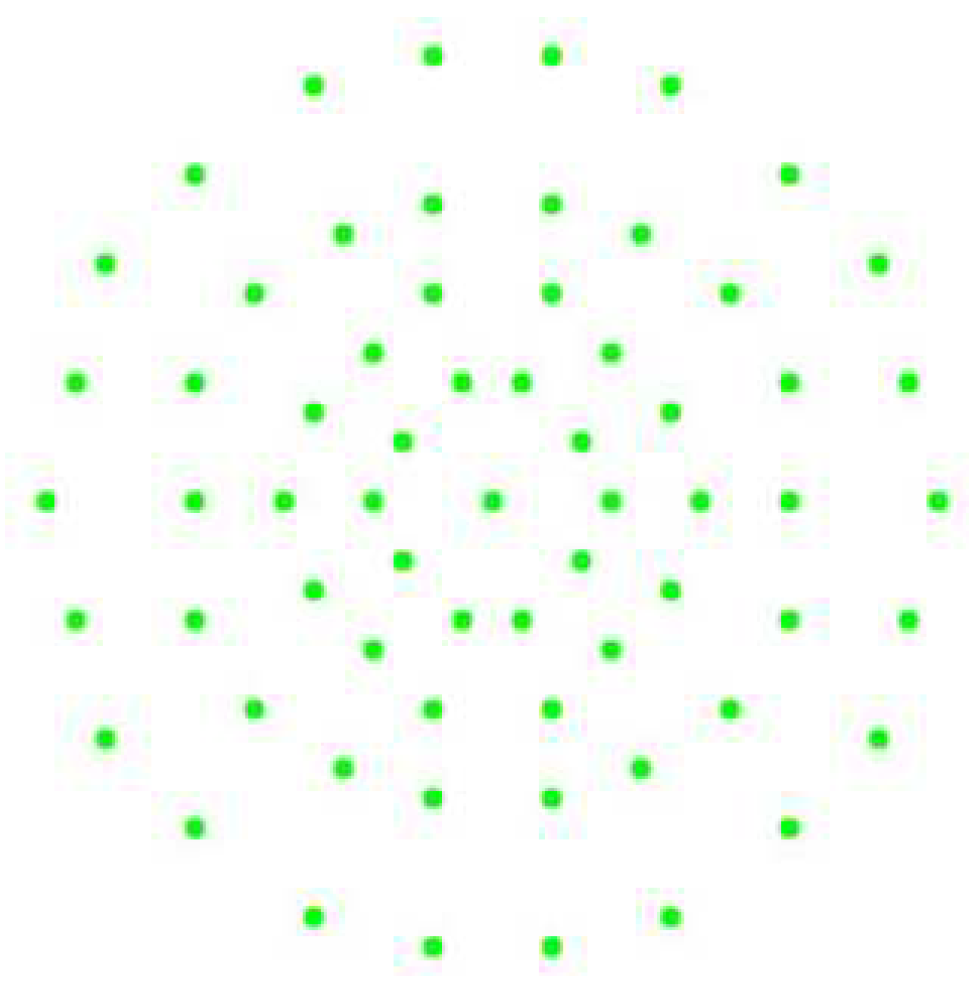
2.3. Coding of Descriptors
- (1)
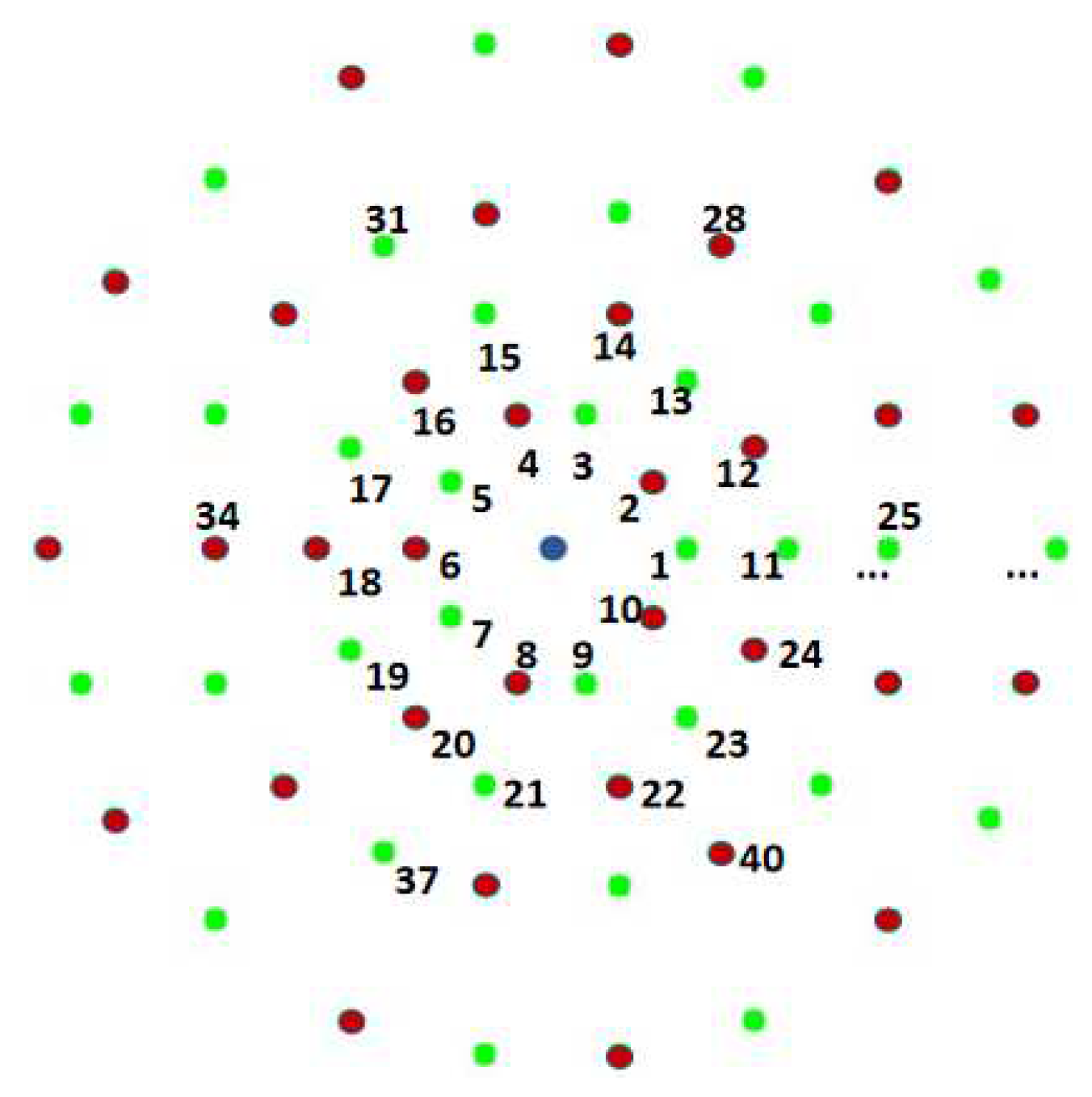
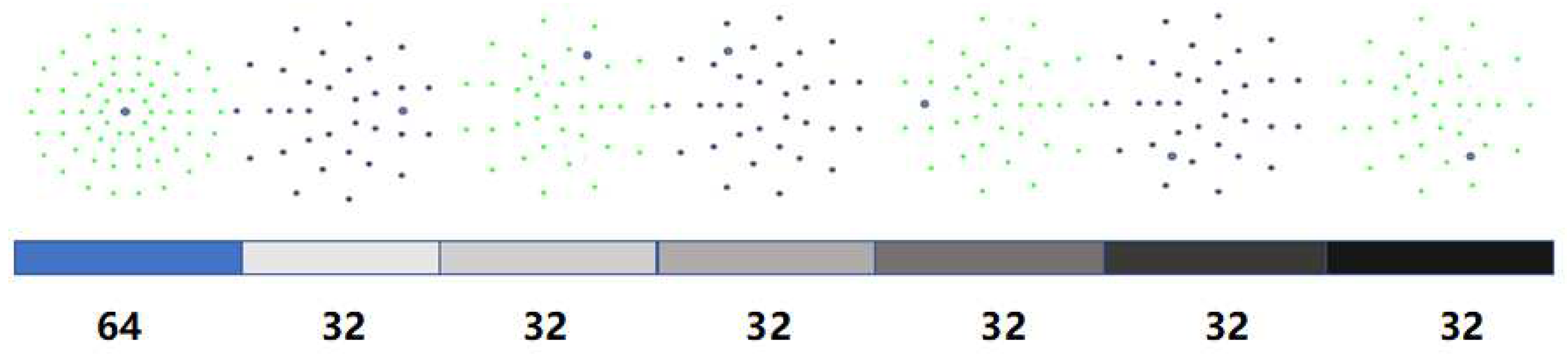
- First, all the points except the centre point are given a serial number and divided into odd and even points, as shown in Figure 5.
- (2)
- Firstly, the grey pixel value is compared using the centre point (blue point) with the points with serial numbers from 1 to 64, in order from smallest to largest, as shown in Equation (1) (where is the coordinate of the centre point and is the coordinate of the other points). A 64-dimensional binary string is obtained.
- (3)
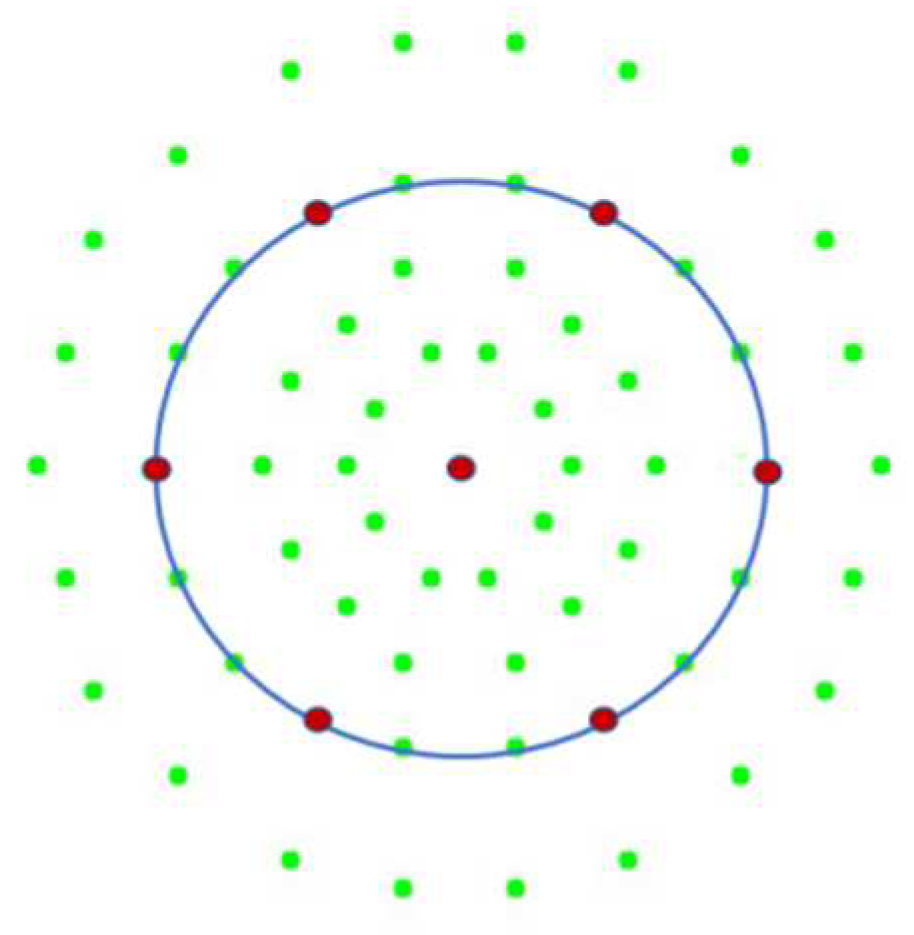
- The third circle, in turn, has been decided to describe the centre: 25, 28, 31, 34, 37, 40.
- (4)
- When the taken description centroid is odd, the grayscale pixel values are compared with all even numbered serial number points 2, 4,……, 64, in order from smallest to largest. When the description centroid is even, the pixel grayscale value is compared with all odd-numbered points 1, 3,……, and 63, from smallest to largest.
- (5)
- The 6 description centroids yield a total of 6 × 32-dimensional binary strings. The 64-dimensional binary string is spliced with the 64-dimensional binary string obtained from the previous main descriptor centre. A 256-dimensional binary descriptor is accepted, as shown in Figure 6.
- (1)
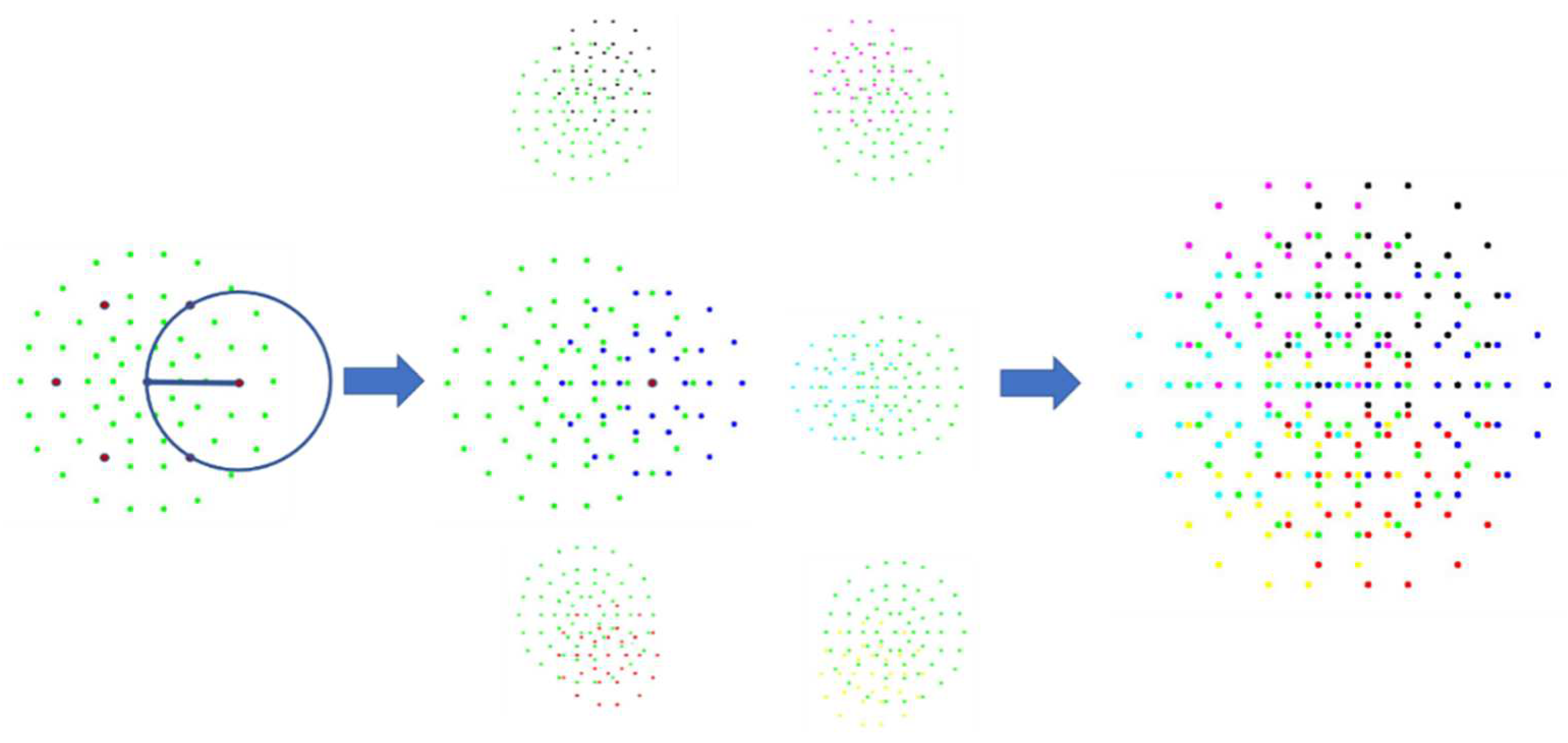
- A 64-dimensional binary string is obtained by first comparing the pixel grayscale values with other sampled pixels using the centroids in descending order.
- (2)
- Then, six symmetric description centroids are taken in turn, and a circle is drawn with a radius from the centroid to the centre as the image block for each description centre.
- (3)
- Each symmetric circumferential sampling is performed in each image block, as shown in Figure 7.
- (4)
- The grayscale values of 32-pixel points obtained from each description center and symmetrical circumferential sampling are compared to obtain a total of the 6 × 32-dimensional binary string. Then the 64-dimensional binary string obtained from the previous main descriptor centre is concatenated to obtain a 256-dimensional binary descriptor.
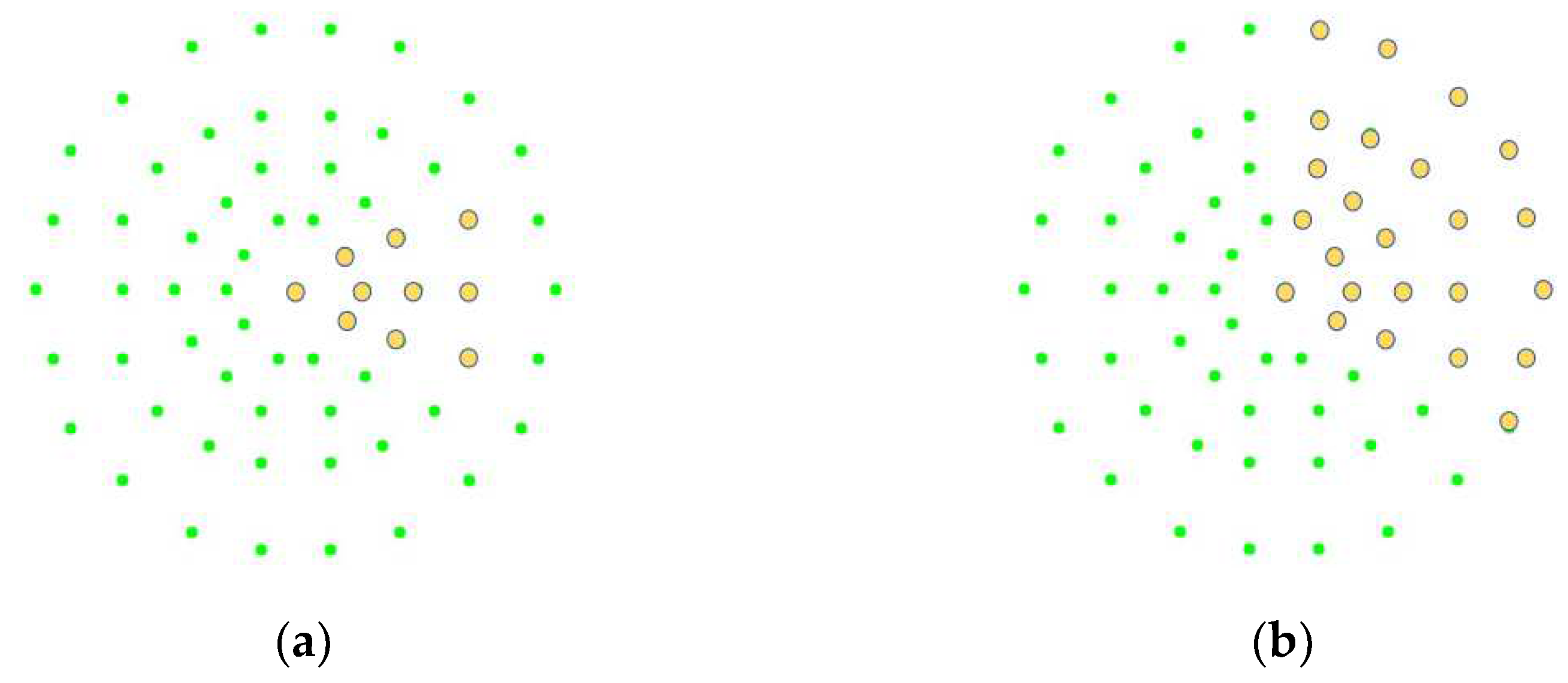
2.4. Weighted Grayscale Values of Sampling Points
3. Experimental Results
- (1)
- Set two Euclidean distance thresholds to determine whether two feature points match correctly. It is characterised by fast speed and low accuracy.
- (2)
- The Brute Force (BF) algorithm first performs the violent matching to obtain the matching points for the optimal solution for each feature point. Then the homography matrix is calculated by the RANSAC algorithm. Finally, the points on the correct match are obtained by reprojecting the homography matrix, characterised by slow speed and high accuracy.
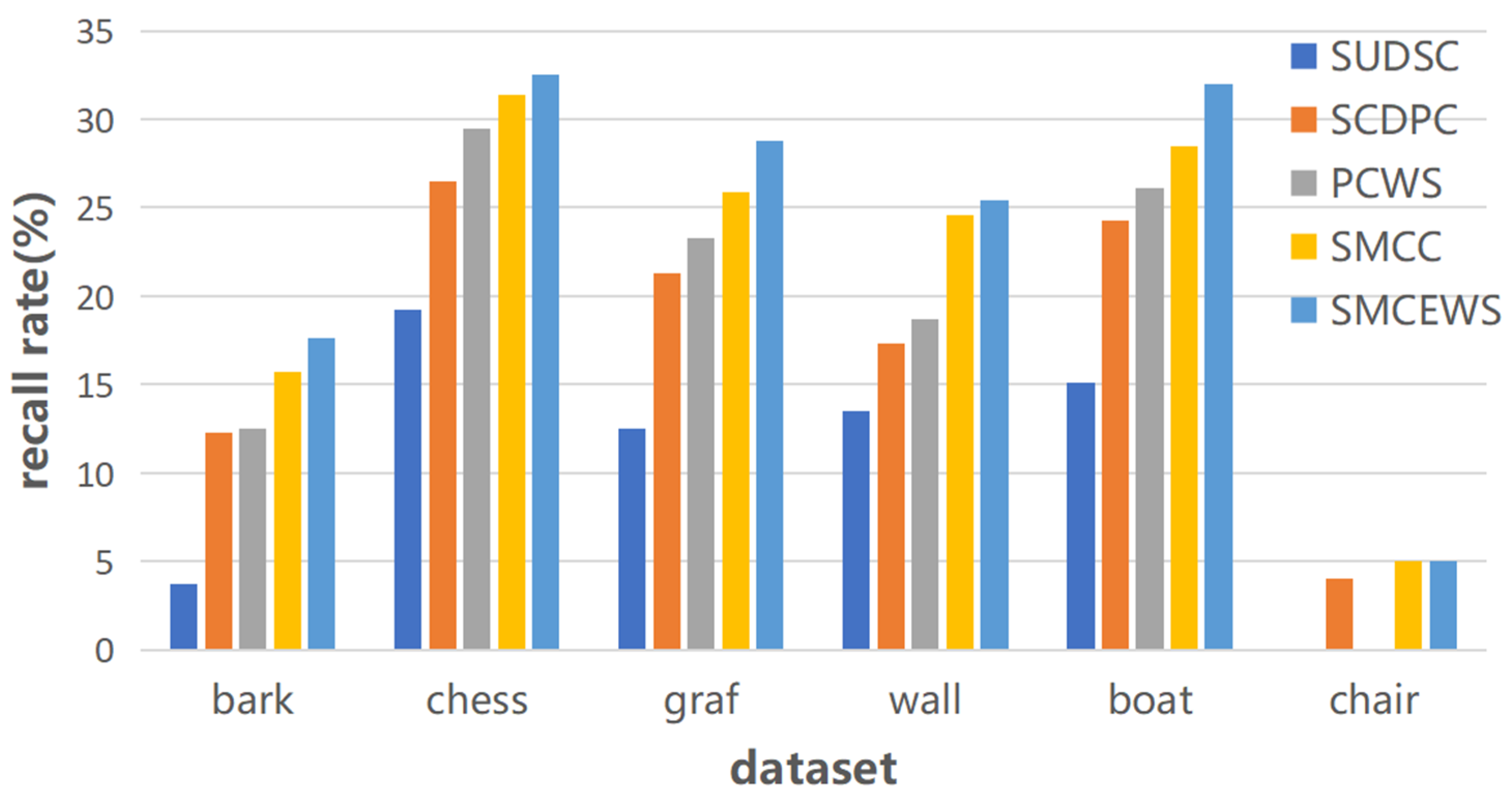
3.1. Comparison between Description Subsampling Methods
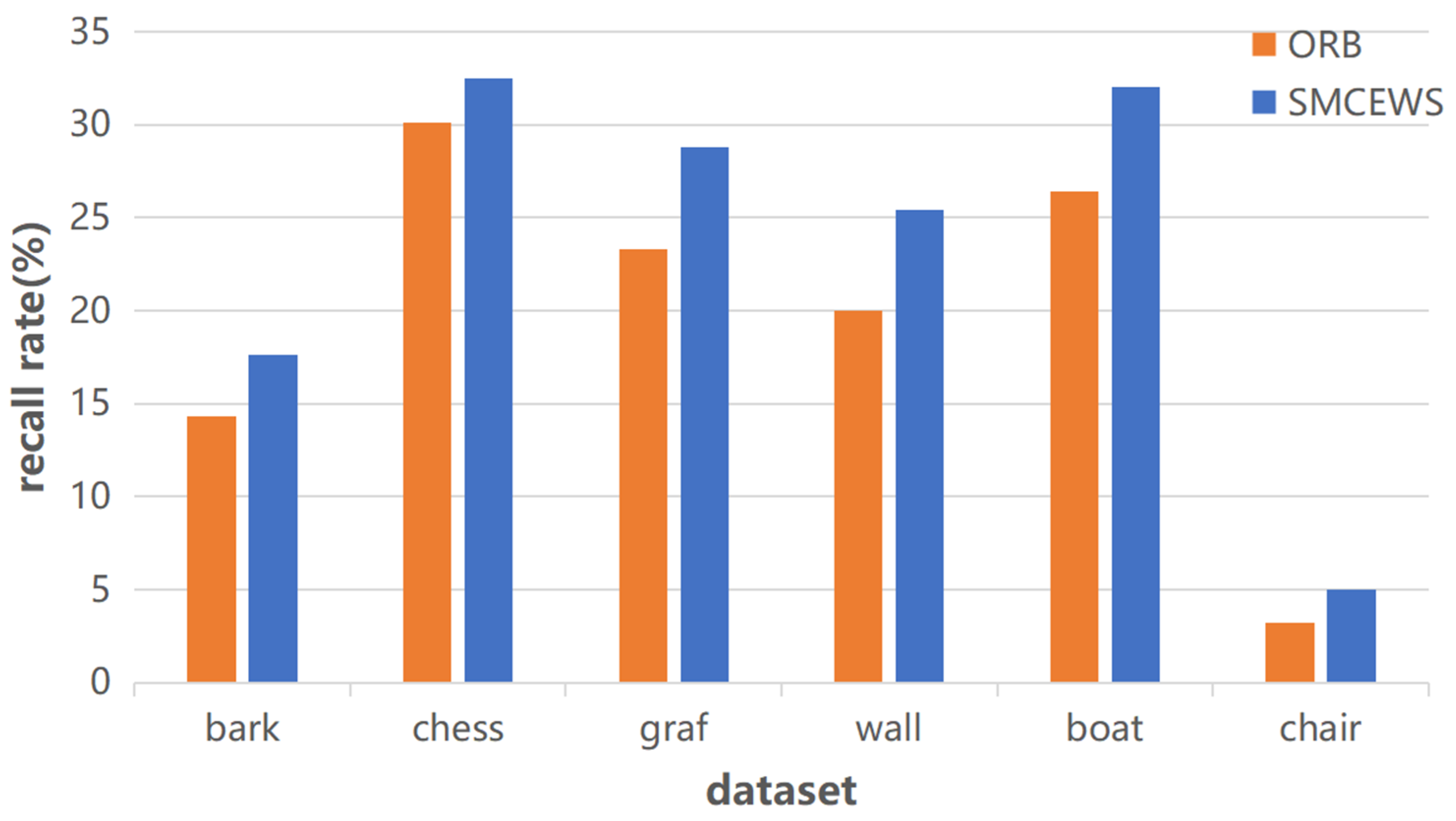
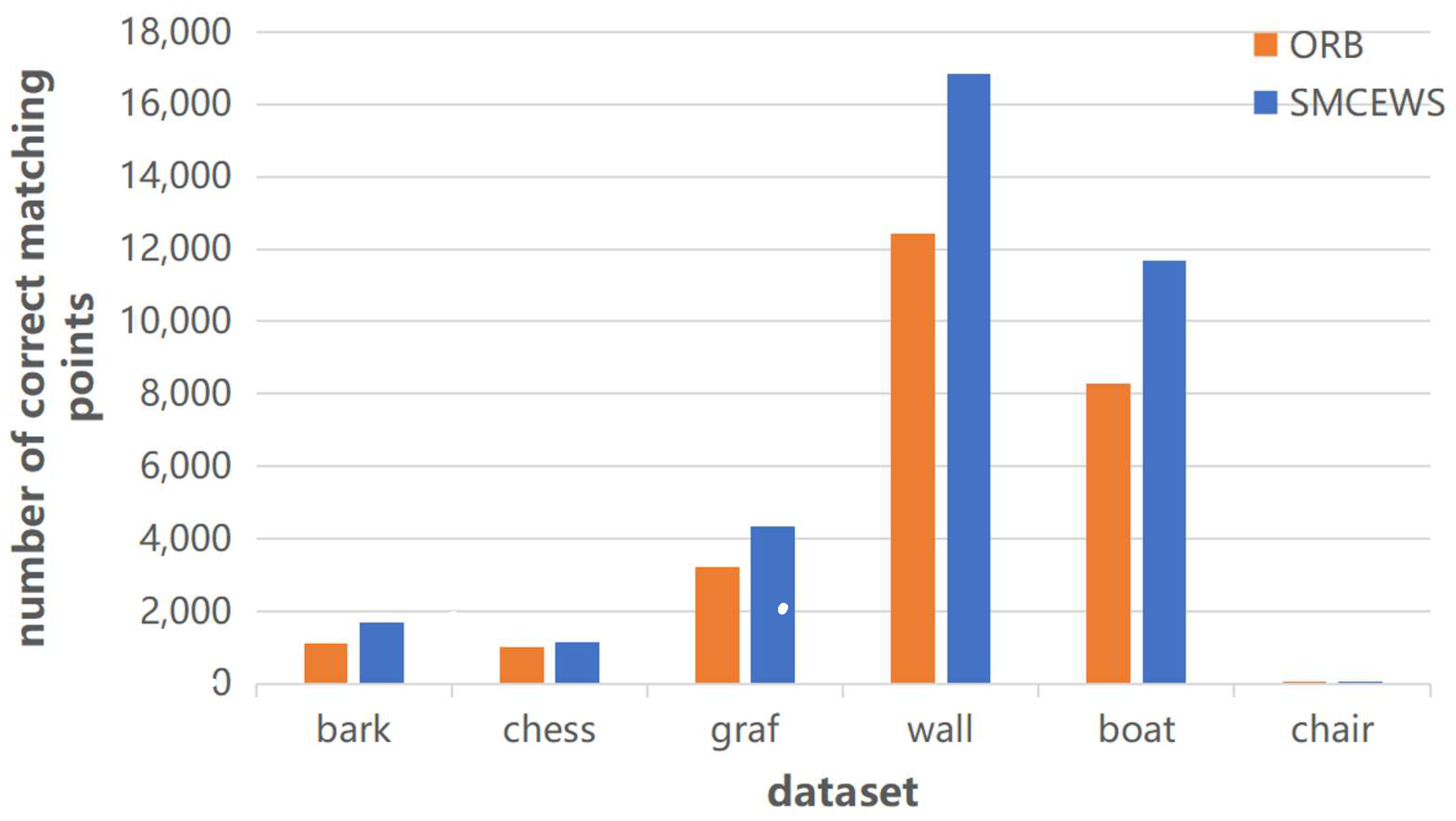
3.2. Comparison with ORB Algorithm
4. Conclusions and Future Work
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Newcombe, R.A.; Izadi, S.; Hilliges, O.; Molyneaux, D.; Kim, D.; Davison, A.J.; Kohi, P.; Shotton, J.; Hodges, S.; Fitzgibbon, A. Kinectfusion: Real-time dense surface mapping and tracking. In Proceedings of the 2011 10th IEEE International Symposium on Mixed and Augmented Reality, Basel, Switzerland, 26–29 October 2011; pp. 127–136. [Google Scholar]
- Wu, H.; Xu, R.; Xu, K.; Zhao, J.; Zhang, Y.; Wang, A.; Iwahori, Y. 3D Texture Reconstruction of Abdominal Cavity Based on Monocular Vision SLAM for Minimally Invasive Surgery. Symmetry 2022, 14, 185. [Google Scholar] [CrossRef]
- Whelan, T.; Kaess, M.; Johannsson, H.; Fallon, M.; Leonard, J.J.; McDonald, J. Real-time large-scale dense RGB-D SLAM with volumetric fusion. Int. J. Robot. Res. 2015, 34, 598–626. [Google Scholar] [CrossRef] [Green Version]
- Zhang, D.; Zhu, J.; Wang, F.; Hu, X.; Ye, X. GMS-RANSAC: A Fast Algorithm for Removing Mismatches Based on ORB-SLAM2. Symmetry 2022, 14, 849. [Google Scholar]
- Newcombe, R.A.; Lovegrove, S.J.; Davison, A.J. DTAM: Dense tracking and mapping in real-time. In Proceedings of the 2011 International Conference on Computer Vision, Barcelona, Spain, 6–13 November 2011; pp. 2320–2327. [Google Scholar]
- Engel, J.; Schöps, T.; Cremers, D. LSD-SLAM: Large-scale direct monocular SLAM. In Computer Vision—ECCV 2014; Springer: Cham, Switzerland, 2014; pp. 834–849. [Google Scholar]
- Fuentes-Pacheco, J.; Ruiz-Ascencio, J.; Rendón-Mancha, J.M. Visual Simultaneous Localization and Mapping: A Survey. Artif. Intell. Rev. 2015, 43, 55–81. [Google Scholar] [CrossRef]
- Ethan, E.; Drummond, T. Scalable monocular SLAM. In Proceedings of the 2006 IEEE Computer Society Conference on Computer Vision and Pattern Recognition (CVPR’06), New York, NY, USA, 17–22 June 2006; IEEE: Piscataway, NJ, USA, 2006; pp. 469–476. [Google Scholar]
- Klein, G.; Murray, D. Parallel Tracking and Mapping for Small AR Workspaces. In Proceedings of the 2007 6th IEEE and ACM International Symposium on Mixed and Augmented Reality, Nara, Japan, 13–16 November 2007; IEEE: Piscataway, NJ, USA, 2008; pp. 225–234. [Google Scholar]
- Labbé, M.; Michaud, F. RTAB-Map as an open-source lidar and visual simultaneous localization and mapping library for large-scale and long-term online operation. J. Field Robot. 2019, 36, 416–446. [Google Scholar] [CrossRef]
- Forster, C.; Zhang, Z.; Gassner, M.; Werlberger, M.; Scaramuzza, D. SVO: Semidirect Visual Odometry for Monocular and Multicamera Systems. IEEE Trans. Robot. 2017, 33, 249–265. [Google Scholar] [CrossRef] [Green Version]
- Engel, J.; Koltun, V.; Cremers, D. Direct sparse odometry. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 40, 611–625. [Google Scholar] [CrossRef] [PubMed]
- Qin, T.; Li, P.; Shen, S. VINS-MONO: A robust and versatile monocular visual-inertial state estimator. IEEE Trans. Robot. 2018, 34, 1004–1020. [Google Scholar] [CrossRef] [Green Version]
- Loo, S.Y.; Amiri, A.J.; Mashohor, S.; Tang, S.H.; Zhang, H. CNN-SVO: Improving the Mapping in Semi-Direct Visual Odometry Using Single-Image Depth Prediction. In Proceedings of the 2019 International Conference on Robotics and Automation (ICRA), Montreal, QC, Canada, 20–24 May 2019; pp. 5218–5223. [Google Scholar] [CrossRef] [Green Version]
- Tang, J.; Folkesson, J.; Jensfelt, P. Geometric Correspondence Network for Camera Motion Estimation. IEEE Robot. Autom. Lett. 2018, 3, 1010–1017. [Google Scholar] [CrossRef]
- Zhan, H.; Weerasekera, C.S.; Bian, J.W.; Reid, I. Visual Odometry Revisited: What Should Be Learnt? In Proceedings of the 2020 IEEE International Conference on Robotics and Automation (ICRA), Paris, France, 31 May–31 August 2020; pp. 4203–4210. [Google Scholar] [CrossRef]
- Lowe, D.G. Distinctive Image Features from Scale-Invariant Keypoints. Int. J. Comput. Vis. 2004, 60, 91–110. [Google Scholar] [CrossRef]
- Herbert, B.; Tuytelaars, T.; Van Gool, L. Surf: Speeded up robust features. In Computer Vision—ECCV 2006; Springer: Berlin/Heidelberg, Germany, 2006; pp. 404–417. [Google Scholar]
- Tola, E.; Lepetit, V.; Fua, P. DAISY: An efficient dense descriptor applied to wide-baseline stereo. IEEE Trans. Pattern Anal. Mach. Intell. 2019, 32, 815–830. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Bakshi, G.; Shukla, R.; Yadav, V.; Dahiya, A.; Anand, R.; Sindhwani, N.; Singh, H. An optimized approach for feature extraction in multi-relational statistical learning. J. Sci. Ind. Res. 2021, 80, 537–542. [Google Scholar]
- Calonder, M.; Lepetit, V.; Strecha, C.; Fua, P. BRIEF: Binary Robust Independent Elementary Features. In Computer Vision—ECCV 2010; Springer: Berlin/Heidelberg, Germany, 2010; pp. 778–792. [Google Scholar]
- Rublee, E.; Rabaud, V.; Konolige, K.; Bradski, G. ORB: An efficient alternative to SIFT or SURF. In Proceedings of the 2011 International Conference on Computer Vision, Barcelona, Spain, 6–13 November 2011; pp. 2564–2571. [Google Scholar]
- Leutenegger, S.; Chli, M.; Siegwart, R.Y. BRISK: Binary Robust invariant scalable keypoints. In Proceedings of the 2011 International Conference on Computer Vision, Barcelona, Spain, 6–13 November 2011; pp. 2548–2555. [Google Scholar]
- Alahi, A.; Ortiz, R.; Vandergheynst, P. FREAK: Fast Retina Keypoint. In Proceedings of the IEEE Conference on Computer Vision & Pattern Recognition, Providence, RI, USA, 16–21 June 2012; pp. 510–517. [Google Scholar]
- Raul, M.-A.; Montiel, J.M.M.; Tardos, J.D. ORB-SLAM: A versatile and accurate monocular SLAM system. IEEE Trans. Robot. 2015, 31, 1147–1163. [Google Scholar]
- Rosten, E.; Porter, R.; Drummond, T. Faster and better: A machine learning approach to corner detection. IEEE Trans. Pattern. Anal. Mach. Intell. 2008, 32, 105–119. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Mur-Artal, R.; Tardós, J.D. ORB-SLAM2: An Open-Source SLAM System for Monocular, Stereo and RGB-D Cameras. IEEE Trans. Robot. 2017, 33, 1255–1262. [Google Scholar] [CrossRef] [Green Version]
- Campos, C.; Elvira, R.; Rodríguez, J.J.G.; Montiel, J.M.M.; Tardós, J.D. ORB-SLAM3: An Accurate Open-Source Library for Visual, Visual-Inertial and Multi-Map SLAM. IEEE Trans. Robot. 2021, 37, 1874–1890. [Google Scholar] [CrossRef]
- Chris, H.; Stephens, M. A combined corner and edge detector. Alvey Vis. Conf. 1988, 15, 10–5244. [Google Scholar]
- Alcantarilla, P.F.; Bartoli, A.; Davison, A.J. KAZE Features. In Proceedings of the European Conference on Computer Vision (ECCV), Fiorenze, Italy, 23–27 October 2012. [Google Scholar]













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Solutions | Number | Bark | Chess | Graf | Wall | Boat | Chair |
|---|---|---|---|---|---|---|---|
| SUDSC | \ | 355 | 570 | 957 | 399 | 459 | \ |
| 1000 | 0.037 | 0.192 | 0.125 | 0.135 | 0.151 | \ | |
| SCDPC | \ | 994 | 942 | 2424 | 9500 | 6746 | 40 |
| 1000 | 0.123 | 0.265 | 0.213 | 0.173 | 0.243 | 0.040 | |
| PCWS | \ | 1081 | 1002 | 3077 | 11166 | 7714 | \ |
| 1000 | 0.125 | 0.295 | 0.233 | 0.187 | 0.261 | \ | |
| SMCC | \ | 1374 | 1112 | 3927 | 14863 | 10527 | 50 |
| 1000 | 0.157 | 0.314 | 0.259 | 0.246 | 0.285 | 0.050 | |
| SMCEWS | \ | 1694 | 1145 | 4330 | 16840 | 11682 | 50 |
| 1000 | 0.176 | 0.325 | 0.288 | 0.254 | 0.320 | 0.050 |
| Solutions | Number | Bark | Chess | Graf | Wall | Boat | Chair |
|---|---|---|---|---|---|---|---|
| ORB | \ | 1116 | 1021 | 3203 | 12410 | 8276 | 32 |
| 1000 | 0.143 | 0.301 | 0.233 | 0.200 | 0.264 | 0.032 | |
| SMCEWS | \ | 1694 | 1145 | 4330 | 16840 | 11682 | 50 |
| 1000 | 0.176 | 0.325 | 0.288 | 0.254 | 0.320 | 0.050 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Xu, Y.; Chen, M.; Zhang, W.; He, L.; Yang, R.; Wang, Y. SMCEWS: Binary Robust Multicentre Features. Symmetry 2023, 15, 809. https://doi.org/10.3390/sym15040809
Xu Y, Chen M, Zhang W, He L, Yang R, Wang Y. SMCEWS: Binary Robust Multicentre Features. Symmetry. 2023; 15(4):809. https://doi.org/10.3390/sym15040809
Chicago/Turabian StyleXu, Ying, Mingwei Chen, Wenjie Zhang, Li He, Rong Yang, and Yun Wang. 2023. "SMCEWS: Binary Robust Multicentre Features" Symmetry 15, no. 4: 809. https://doi.org/10.3390/sym15040809