1. Introduction
Purchasing power parity (PPP) is one of the most commonly considered hypotheses in economics. The foundation of the purchasing power parity hypothesis lies in the law of one price, which expresses that the price of an asset (or a bunch of goods) should be the same in every country when indicated in a single currency, meaning that the same goods are sold for the same price in two distinct countries. Permitting the PPP hypothesis, nominal exchange rates move one-to-one at relative prices in the long run. Thus, the theory can be seen as a clustered version of the law of one price. The PPP theory assumes that there are no transaction costs, taxes, and trade barriers in international trade, and for some markets, it also assumes imperfect competition between two markets.
The importance of the PPP hypothesis for policymakers relies mainly on the following reasons: First, it is an anchor for real exchange rates in the long-term equilibrium, allowing policymakers to assess the balance in nominal exchange rates and take proper policy actions. Next, policymakers need to know the degree of persistence of real exchange rates. Shocks that have permanent effects on the economy are caused by the near unit root problem in the exchange rate arising from the real economy (high persistency or near unit root means that the autoregressive parameter takes a value close to 1) [
1]. Conversely, if real exchange rates are less persistent, i.e., if the autoregressive parameter is high, the shocks come primarily from the total demand side. More importantly, as Taylor and Sarno [
2] argue, the stationarity of the real exchange rate is an essential assumption in open economy macroeconomics; therefore, the nonstationarity of the real exchange rate renders open economy macroeconomic theories questionable. One final point to consider is that real exchange rates are used to compare the actual revenues of countries, and if there is no valid PPP hypothesis, such comparisons will become invalid. Consequently, it is vital to test the PPP hypothesis precisely.
Empirical assessments of the PPP hypothesis are usually based on the unit root test of the real exchange rate series. When looking at previous studies, it is clear that there is a great deal of work that does not support the PPP hypothesis [
2,
3,
4]. These negative results stem from traditional unit root tests’ low power when used on a small sample. For this reason, researchers have started to search for alternative methods to test the stationarity of real exchange rates [
5].
Three methods have been attempted to increase the power of traditional tests. The first is to improve the structure of real exchange rates by developing unit root tests with nonlinear forms. The second alternative is unit root tests that take into account the structural breaks. The third way is to increase the power of unit root tests by expanding the data sample size with panel methods. Finally, we come across nonlinear panel unit root test methods that combine these three methodologies.
Purchasing power parity may show nonlinear behavior for many reasons. The transaction costs might lead to the nonlinear convergence of real exchange rates to their mean [
6,
7,
8,
9]. Whereas minor deviations from the real exchange rate’s equilibrium level cannot be removed by commodity arbitrage, a large deviation will cause the PPP to return to the equilibrium level because it may cover the transaction costs. This behavioral structure shows a band around the mean of PPP. Along with transaction costs and trade barriers, official interventions in the foreign exchange markets, speculative attacks, the interaction of heterogeneous traders and price stickiness, and the presence of target regions can also lead to a nonlinear structure in the real exchange rate data-generating process. Most of the nonlinear studies reported that the results support the PPP hypothesis after permitting nonlinearity in unit root testing.
There was also some criticism of the PPP hypothesis, specifically for its long data set. When considering a long sample, the linear models may once again be insufficient, as the above-mentioned nonlinear structure may emerge in this long period. Hegwood and Papell [
10] state that a very long data range covers both fixed and flexible exchange rate regimes, and therefore, linear models can produce false results due to regime changes. In addition, various exogenous shocks can cause the real exchange rate’s mean value to change over time. For example, oil price shocks in 1973 and the collapse of the socialist bloc in the 1990s may have changed these countries’ equilibrium real exchange rates. Perron [
11] shows that when structural breaks occur, traditional unit root tests have yielded incorrect unit root test results even though the data were stationary. Hegwood and Papell [
10] and Papell and Prodan [
12] provide proof for approving the PPP hypothesis after permitting probable structural breaks in the real exchange rate series. More recently, Lundbergh et al. [
13], Sollis et al. [
14], and Christopoulos and Leon-Ledesma [
15] debate that structural breaks and nonlinearity are not mutually exclusive, and that synchronized structural breaks and nonlinearity can better explain the realization of the real exchange rate. Indeed, Sollis et al. [
14], Koop and Potter [
16], Omay et al. [
17], and similar studies in the literature reveal that both structural breaks and nonlinearity can adopt the time-series behavior of many economic variables. In this sense, Leybourne et al. [
18] (henceforth, LNV) model the structural breaks in the real exchange rate with the logistic transition variable. The advantage of this approach over other types of structural break tests lies in its ability to capture a smooth transition from one regime to another, which may occur when individuals or countries do not move simultaneously, and the sharp transition with which they move together. Moreover, the nonlinear mean reversion explained above can best be captured by the Kapetanios et al. [
19] (henceforth, KSS) unit root test. These two models are combined in the Omay and Yıldırım test [
20] (hereafter, the OY test).
The first-generation panel unit root tests contribute to extending the sample size by considering both cross section and time observations. However, O’Connell [
21] state that some deficiencies in the panel data approach were employed to test the PPP hypothesis. Moreover, Banerjee et al. [
22] evaluated the small sample efficiency of the existing tests and found that once the errors were allowed to be correlated in the cross section, all the tests had serious type 1 errors. Therefore, the unit root test null hypothesis is frequently rejected, which falsely serves empirical results such that the real exchange rate follows a stationary process. Depending on the cross-section dependency (CSD), the asymptotic distributions of traditional panel unit root tests will be incorrect, and alternative distributions must be provided since the cross-section dependency exists in the data. Therefore, new (second-generation) panel tests have been developed for unit root tests that resolve this CSD problem. Different methods have been implemented to overcome the cross-section dependency problem in the testing process. Of these, unobserved and observed factors are included as additional regressors in the regression equation (see Refs. [
23,
24,
25,
26]). Alternatively, Maddala and Wu [
27], Chang [
28], Smith et al. [
29], Cerrato and Sarantis [
30], Ucar and Omay [
31] (henceforth, UO), and Palm et al. [
32] all employed bootstrap methods to solve the CSD problem and gather unbiased parameter estimations. The key idea behind the bootstrap technique is to resample the residuals to preserve the cross-section dependency pattern in the panel to converge to the sampling distribution of the original series (see Ref. [
26]). An advantage of the bootstrap method over factor-based methodologies is the applicability to any unknown cross-section dependency form without knowing the functional structure of cross-section dependency [
32]. For instance, in the study of Omay, Hasanov, and Shin [
33] (henceforth, OHS), the advantages of using the sieve bootstrap method instead of factor methods in the logistics smooth transition panel unit root test are also extensively studied. One of the primary deficiencies of factor models is that the factor variable interacts with structural break trends and decreases the power of the test. In light of these issues, we used the sieve bootstrap methodology of Ucar and Omay [
31]; Emirmahmutoğlu and Omay [
34] (henceforth, EO); Çorakcı, Omay, and Emirmahmutoğlu [
35] (henceforth, COE); Omay, Hasanov, and Shin [
33]; and Omay, Çorakcı, and Emirmahmutoğlu [
36] (henceforth, OCE). As a follow-up to these studies, we propose a new unit root testing procedure that considers both smooth transition structural breaks and nonlinear adjustment toward equilibrium to test the stationarity of the REER series. The proposed test solves the problems that may arise when testing the PPP hypothesis as described so far.
Moreover, this newly proposed unit root test procedure has robust features compatible with many economic time series’ theoretical and empirical dynamics, including real exchange rates’ dynamics. Small sample performances of the proposed tests are examined with Monte Carlo simulations; the results show that the proposed tests have very satisfactory size and power characteristics and perform better than other similar tests in reel exchange dynamics, which is extensively studied in the small sample performance section (
Section 3). We use these and other tests to examine the stationarity of the REER series of selected world countries. The results provide evidence in favor of the PPP hypothesis of the REER series for the period 2010:7–2020:3 and 1994:1–2020:3 when using the newly proposed test. Moreover, the approximate limiting distribution of the newly proposed test is obtained in
Appendix A.
The subsequent sections are as follows:
Section 2 of this study develops the proposed test statistics and represents their critical values.
Section 3 provides the small sample performance of the newly proposed test compared with nonlinear and linear panel unit root tests.
Section 4 presents empirical applications, and
Section 5 concludes.
2. The Model and Testing Framework
Let
be a panel with changing trend function with smooth transition on the time domain
for the entities
.
produced by the subsequent model:
where
is the fixed effect. Here,
represents the smoothly changing nonlinear trend function. Initially, we assume that the errors
are a zero mean process distributed independently across both
and
; that is,
and
cross-sectionally and serially uncorrelated,
for
and
. Considering the null hypothesis of unit root in
for all
i in Equation (2), we rewrite Equation (2) as
where
. Now, the null hypothesis of unit root becomes:
, for all
i, while the alternative hypothesis of stationarity
for some i. Following Schmidt and Phillips [
37], we represent the model as in Equation (1), which enables models to maintain the same deterministic trend under the null and alternative. Until here, we assume linear convergence to nonlinear trend; however, as stated in the introduction, we propose nonlinear convergence following the Kapetanios et al. [
19] test. We will derive the nonlinear convergence to the nonlinear attractor in the second step using the ESTAR function. For the nonlinear trends, we used the following forms:
where
is a logistic smooth transition function defined as follows:
In this modeling methodology, the structural break is designed as a smooth transition between different states rather than an instantaneous structural break (see [
18]). (See also Sandberg [
38] for another type of nonlinear trend. It is also very useful in and flexible in catching up to the smooth breaks.) The transition function
is a continuous function bounded between 1 and 0. Therefore, the smooth transition (ST) regression can be seen as a state-dependent model that permits for two regimes, accompanying the extreme values of the transition function,
and
, while the transition from one regime to the other is slow. The parameter
controls the smoothness of the transition and, accordingly, the smoothness of transition from one state to the other. The two states are related to small and large values of the transition variable
relative to the threshold
. For the large values of
,
passes through the interval
very rapidly, and as
approaches
, this function changes value from 0 to 1 rapidly at time
. Therefore, if we assume that
is a zero mean
process, and in the model A,
is a stationary process around a mean that changes from initial value
to final value
; the LNV approach also provides the same conditions for the models B and C. In these models, no change and one instantaneous structural change are limiting cases, whereas this model is more general in that it includes a gradual structural break as well (for further discussion, see [
19]).
Thus, we adapt their approach to the panel data, and our test is to have a two-step procedure.
Step 1. Run
on the deterministic regressors via the nonlinear least squares (NLS) procedure, and hold the residuals for models A, B, and C, respectively.
Step 2. Construct panel logistic smooth transition trend model, i.e., LSTT-PESTAR (1), by imposing the residuals into the regression as the variables given below:
where
speed of transition is positive for all
i. Following the UO testing framework, we set
for all
i, which leads to a unit root process in the middle regime (please see Ucar and Omay [
31] for further details). Hence, the model becomes:
Notice here that the nonlinear panel data unit root test based on Equation (12) is simply to test
for some
i under the alternative. However, direct testing of
is somewhat problematic because
is not identified under the null
(see Ucar and Omay [
31] and Kapetanios et al. [
19] for further details). This problem is achieved by applying first-order Taylor series approximation to the PESTAR (1) model around
. This leads us to arrive at the auxiliary regression as follows:
where
and
, where
is residuals from Taylor approximation.
Use the simple test statistics for each cross-section observation,
to test the hypothesis
under the null, and the alternative is to be
as they can be written formally,
where
is the consistent estimator such that
,
. Notice here also that
,
and
.
Calculate the data average
t-statistic as below:
The asymptotic distribution of individual t-statistic is to be in the following theorem:
Theorem 1. Under the null hypothesis of unit root, the approximate asymptotic distribution of is as follows:where is the Wiener process as defined over the interval . for is a de-meaned and de-trended Brownian motion, respectively. We serve the critical values of the average
t-test for each model in the following
Table 1,
Table 2 and
Table 3. These critical values can be used appropriately for the case that the researchers do not observe the cross-section dependency in the data.
3. Finite Sample Performance
We evaluate the size of the test statistics by designing the following data generating process (DGP):
where
with
We generate both the low and high levels of cross-section dependency with factor loadings
and
. We present the empirical size of the panel exponential smooth transition model with logistic smooth transition trend (i.e, LSTTESTAR (1)) unit root test in the
Table 4 given below.
The size analysis was conducted by following the methodology of Pesaran [
25]. He conducted the size analysis with employing of the IPS test [
39], truncated IPS test, p-test DF, and Z-test DF, and tried to show the size distortion resulting from these tests under cross-section dependency. IPS, truncated IPS, p-test DF, and Z-test DF are first-generation panel unit root tests that do not cover cross-section dependency remedies. As a result of his study, Pesaran found that no size distortion results occur in weak cross-section dependency, but all tests tend to over-reject, often by a substantial amount, in high cross-section dependency. Likewise, the PLSTTESTAR (1) test also suffers from oversize problems when no remedy is applied. However, this oversize situation is less than what is encountered in the study [
25]. There are two reasons why the PLSTTESTAR (1) test has lesser size problems than the tests in the paper [
25]. The first reason is a nonlinear time-varying trend; the other is state-dependent nonlinearity, which is included in the unit root testing model.
First of all, we discuss why the nonlinear treatment of the deterministic trend reduces the cross-section dependency, and then it will be debated how the nonlinear modeling of the stochastic part contributes to this. Looking at the size analysis of the work [
25], the null hypothesis rejection rate for nominal size 5% for the IPS test N = 50 is around 34%, and for N = 100, it is 39%. These rates are 25% for the PLSTTESTAR (1) model A N = 50 and 30% for N = 100. As can be seen, the rate of rejecting the null hypothesis has decreased. The above-mentioned time-varying nonlinear trend is the first reason for reducing the oversize problem due to cross-section dependency. The explanations on this subject were first discussed by Fuertes and Smith [
40] and Omay et al. [
33]. In the study of [
40], the cross-section dependency caused by common shocks can be confused with structural breaks. On the other hand, in the work of [
33], a unit root test of the panel LSTT model type was proposed, and it was shown in simulation studies that the nonlinear trend reduces cross-section dependency. To strengthen this argument, we applied the same size analysis to PLSTTESTAR (1) models B and C. Interested researchers can see the results of this study in
Table 5 below. For N = 50 T = 30, it was 24% in model B and 23% in model C. The most significant decrease occurred in N = 100 T = 100 model A at 36%, while model B decreased to 34% and model C to 30%. Similar results to what we found here can also be found in [
33]. Therefore, we confirm the findings of the studies [
33,
40]. In addition to this evidence, it is useful to know that there will be decreases due to the state-dependent nonlinear model. Until here, we explain the time-dependent nonlinear structure that may eliminate cross-section dependency, but other sources eliminate CSD, such as the panel smooth transition model used in the study of Omay and Kan [
41].
Their study is based on the model misspecification tests. They employed the Pesaran [
42] CDLM test in the models, in which they put the linear model, linearized model, nonlinear model, and the factors considered in the Pesaran [
43] model into nonlinear PSTR estimation. As a result of this model misspecification test, they showed that the degree of cross-section dependency falls slightly when the model is to have a nonlinear structure. However, it is seen from the diagnostic check that cross-section dependency cannot be eliminated without adding factors to the nonlinear model. In the study [
41], the linearized model has the same structure as our proposed nonlinear panel unit root test’s ESTAR (1) part. They have shown that the linearized nonlinear model slightly reduces cross-section dependency. Therefore, it is evident that the linearized model will reduce cross-section dependency without adding factors. The size analysis confirms the facts we have explained here in light of this information.
Table 6 and
Table 7 report the rejection probabilities of the null hypothesis for the newly proposed unit root test. Empirical sizes of both the panel LSTTESTAR (1) unit root test with the common correlated effect estimator and the bootstrap procedure are reasonably close to nominal size for weak and high cross-section dependency. The sieve bootstrap methodology tends to be slightly oversized concerning the CCE version of the proposed test. Overall, the version of CCE-based test statistics tends to display better size properties.
We perform simulation studies whose methodologies are summarized in the Technical Annex
Appendix A. Fortunately, we see almost the same size analysis results in Omay et al. [
33]. The size analysis employed here,
Appendix A, and the analysis in [
33] size analysis are consistent. Considering this situation, if an adjusted power analysis is performed, the proposed test’s sieve bootstrap and CCE versions will show the same power characteristics.
Considering these reasons, it is thought that a comparison with other tests will contribute more to the existing nonlinear panel unit root literature. In addition, this research will shed better light on which tests can better test the PPP hypothesis we examined.
Therefore, we will concentrate on contributing to the economic theory of how the proposed test behaves in different parameter regions by using very extensive parameter regions. This power analysis is primarily designed to shed light on the alleged behavioral pattern in financial markets. The economic events that cause financial markets’ nonlinear convergence behavior are listed as market friction, transaction cost, spread between financial prices, short sales, borrowing restrictions, the interaction of heterogeneous agents, herd behavior, and momentum trading. These economic events make arbitrage unprofitable in small changes and converge to equilibrium for large arbitrages [
19]. Therefore, a return to equilibrium only occurs when the deviations from this equilibrium are large, and thus, arbitrage activities are profitable [
19]. That is to say, the dynamic behavior of financial variables will differ according to the size of the deviation from equilibrium, regardless of the sign of this deviation. Band TAR and ESTAR functions are available in the literature as functional structures to consider such behaviors.
For this reason, the ESTAR function has been used in many studies to test the exchange rates and PPP hypothesis. Power analysis, which we will discuss below, is primarily designed to compare this behavior at first. The advantages and disadvantages of the proposed test in contrast to other panel unit root tests will be compared. This analysis will be handled when there is a moderate break structure, and how the ESTAR model behaves in high persistence and more nonlinear behavior regions or vice versa will be examined. In order to make comparisons of the proposed new test, initially, the tests closest to the ESTAR convergence containing the logistic trend were selected. The power analysis included in [
36] for the panel unit root test considers TAR convergence with a logistics smooth trend. As can be seen, this study is the closest study to the band TAR study mentioned above. In addition, it is the closest test to the proposed test in this study. The sieve bootstrap method was used to eliminate the cross-section dependency as in [
33]. Leybourne et al. [
18] suggested including intercept and trend test versions when they have not covered any structural break in the UO test. The linear Im, Pesaran, and Shin [
39] panel unit root test, which is the initiator of panel unit root tests, was included in the power analysis to compare the parameter regions where linearity increased. Finally, the analysis included the Omay, Hasanov, and Shin [
33] panel unit root test with the logistic trend. In this way, all components of the proposed test were also included in the power comparison separately. In their panel unit root test, sieve bootstrap and common correlated error methods were used for remedying cross-section dependency, and it was discussed in detail that the sieve bootstrap method is a better remedy. In light of these explanations, it is clear that if the selected parameters provide high persistence and nonlinearity in power comparison, these parameter regions are the regions where we observe real exchange behavior. When we decrease the high persistence and nonlinearity parameters, the power of the proposed test is expected to decrease and vice versa. Therefore, by using the below data-generating process, we employ an extensive power analysis:
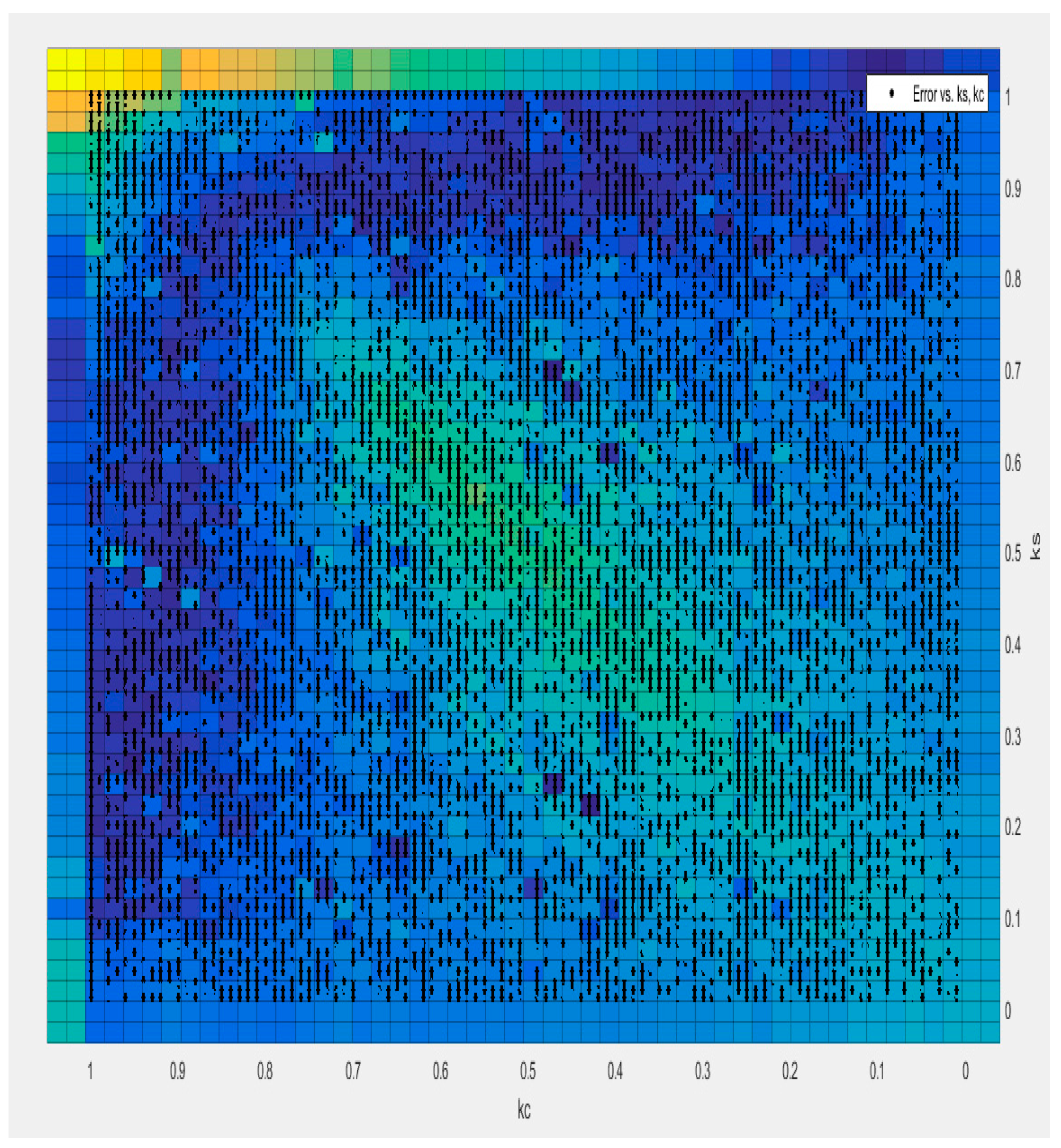
The parameter regions are given in
Table 8. This table is devoted to the ESTAR (1) component of the newly proposed test: state-dependent nonlinear behavior around a nonlinear attractor, namely, a logistic smooth transition trend. Therefore, in the first part of the power analysis, we investigate the financial variable behaviors in high persistence and nonlinearity regions.
As the transition speed parameter delta
in the ESTAR (1) part of the newly proposed test becomes smaller, the power increases in the newly proposed test are greater than the linear models. This situation increases the power of the panel unit root test, independent of other parameters that determine the structure of the test. Kapetanios et al. [
19] observed this power relationship between the KSS and ADF tests. Among the panel unit root tests we discussed here, this relationship is similar to that between the proposed and OHS tests (panel logistic smooth transition trend). For example, power analysis results were obtained as 0.224 and 0.136 for N = 5, T = 100, and
= 0.01 values for PLSTTESTAR (1) and PLSTT unit root tests, respectively. Meanwhile, 0.451 and 0.398 were obtained for N = 5, T = 100, and
= 1.0 values. If the ratio of the power result obtained for the new test and the OHS test results is 1.64 times higher when
is small (N = 5, T = 100 and gamma 0.01), it decreases to 1.13 times when
is large (N = 5, T = 100 and gamma 1.0). This relationship is seen in all parameters and N and T combinations. The generated series converges toward a linear process as
grows, so the remaining part in the nonlinear de-trend series becomes linear. In addition, the persistence of the series increases as
increases. As the transition rate parameter
in the ESTAR (1) part of the proposed test increases, the power increases more than all other tests. This situation increases the power of the newly proposed panel unit root test, independent of other parameters that determine the structure of the test. Therefore, the proposed test has higher power in more persistent data generation areas. The power analysis reveals that the proposed test captures the financial data’s high persistence and nonlinear characteristics well. Power analysis will be continued within the framework of the economic relationship of the PPP hypothesis with structural breaks. Most empirical studies accepted the PPP hypothesis by using structural break unit root testing.
Regarding this issue, Hegwood and Papell [
10] state that a very long data range covers both fixed and floating exchange rate regimes and may produce spurious results due to regime changes. In another example, Edison and Kloveland [
44] note that, although the homogeneity assumption behind the standard view of PPP is valid only in the long run, long data streams can encounter regime changes in tastes and technology, which means permanent movements in the equilibrium of exchange rates. However, they stated that if the equilibrium reel exchange rate deviations are permanent, it will cause the quasi-PPP hypothesis.
Nevertheless, they emphasize that the standard PPP will still be valid under the temporary break condition. In addition, various external shocks may cause the equilibrium value of the real exchange rate to change over time and continue at a different equilibrium real exchange rate. For example, the oil price shocks of 1973 and the collapse of the socialist bloc in the 1990s may have altered the equilibrium real exchange rates of oil-importing and transition countries, respectively. Even though these structural changes come with shocks, the changes in the exchange rate take time. Thus, they can be better captured by smooth transition models. This power analysis section will show that the PPP hypothesis can be tested more strongly with the correct structural break test. Hegwood and Papell [
10] stated that another crucial structural break model is the model in which the long-term PPP hypothesis remains valid by proposing a temporary structural break instead of the quasi-PPP hypothesis. Sollis [
14] modeled the pre-appreciation and post-depreciation periods with a temporary break using the exponential smooth transition trend (ESTT) model. Çorakcı et al. [
35] evaluated the ESTT model as a monotone function and criticized the Fourier function used in the article [
14]. The main goal of these studies is to determine the long-term PPP hypothesis when there is a temporary break. However, since break structures will be found in a wide variety of structures, they are insufficient to analyze short-term data. For the long-run PPP hypothesis, the sample needs to be very long, and the structural break is expected to cause a temporary change in the exchange rate equilibrium. The validity of the test remains very limited under these restrictive assumptions. The hypothesis of Hegwood and Papell [
10] and their follower Sollis [
14] that the real exchange rate should have an equal, constant mean before and after the structural change is a very limiting hypothesis compared with the quasi-PPP hypothesis. The logistic smooth transition model C we use can capture such structures, albeit partially, and shows whether the long-term PPP hypothesis is valid or not. In this respect, additional information on this subject will be given in the empirical part. In the power analysis section, we will examine the power performances of our test by comparing it with some other tests for different logistic smooth transition parameters.
There are three parameters of the logistic smooth transition trend. The first of these parameters, the
parameter, determines the magnitude of the structural break; the transition speed
parameter determines the speed of the transition from one real exchange rate equilibrium to the next (it determines the duration); and, finally, the threshold
parameter determines the location of the structural break. Smooth, moderate, and sharp breaks can be obtained from combinations of these three parameters. In addition, the permanent break can be obtained with the LST trend, and the model C structure has the flexibility to imitate the temporary break structure. As we mentioned above, the quasi- PPP hypothesis is a more general hypothesis that reveals the superiority of the LSTT function in testing this hypothesis. We mentioned that smooth-transition breaks have better test properties than instant structural breaks because heterogeneous agents cannot take action simultaneously in financial markets. Therefore, this structure leads to a smooth or rather long-duration break structure. In the LSTT function, this feature is provided by the transition speed parameter
. As shown in
Table 9, the power of unit root tests with the LSTT function increases as the transition speed parameter
becomes smaller. In addition, as the size of the break parameter
increases, the power performance of the tests with the LSTT function increases, compared with the tests without structural breaks. Another interesting result is that while the structural break parameters approach the middle of the sample, the power performance of panel unit root tests, including LSTT, increases. In the
Table 9, we consider three different cases depending on the magnitudes of the structural break parameter
. For the small or moderate break with
= 5.0, the IPS or any other panel unit root test without any structural component has better power features than higher structural break parameters. See also similar results documented in Leybourne et al. [
18], Sollis [
14], and Omay and Yıldırım [
20]. The power of all the tests is negatively associated with the
parameter. Furthermore, the threshold location parameter,
, also negatively affects the power of the smooth transition-type tests. In particular, when the threshold is located at the beginning of the sample, LST trend unit root tests tend to display lower power performance with respect to
= 0.5. As expected, in all of the parameter region, the panel LSTTESTAR (1) test becomes more powerful than the other tests in which the ESTAR (1) parameter is selected to imitate the high persistency and nonlinear structure of financial markets. Hence, we may conclude that the logistic smooth transition function can capture the small, moderate, and sharper breaks. Finally, when the structural break parameter is substantially large, the IPS and UO tests lose power. The performance of the smooth transition-type de-trending tests improves when the value of the structural break parameter increases. Therefore, the panel LSTTESTAR (1), PLSTT, and panel threshold autoregressive with logistic smooth transition trend (i.e PLSTTTAR) test should become more powerful in this region. Therefore, the PLSTTESTAR (1) test outperforms other tests for the cases with moderate, high structural breaks and high transition speeds with the threshold located in the middle. The unit root test procedures proposed in this article have excellent features compatible with the theoretical and empirical dynamics of many economic time series, including real exchange rates. The proposed tests allow for permanent and temporary structural breaks, whereas shifts between regimes might be relatively gradual.
4. Cross-Section Dependency (CSD)
A generally faced problem in panel regression models is the presence of CSD. CSD can arise because of spatial correlations, spill-over effects, economic distance, omitted global variables, and common unobserved shocks. Correlated errors through individuals make the classical unit root and cointegration testing procedure invalid in panel data models. Banerjee et al. [
22] assess the finite sample performance of the available tests and find that all tests experience severe size distortions when panel members are cointegrated. To overcome this issue, some tests based on the regression equation, including the unobserved or observed factors as the additional regressors, have been suggested in recent years (e.g., [
23,
24,
25,
41,
45,
46]).
On the other hand, Maddala and Wu [
27], Chang [
28], and Ucar and Omay [
31] consider the bootstrap-based tests to obtain good size properties. In this study, we used two methods to deal with the cross-section dependency problem. One is the common correlated effect (henceforth, CCE) estimator proposed by Pesaran [
25], and the other is the bootstrap method. In the bootstrap method, we impose the methodology of the UO test.
The CCE estimation procedure has the advantage that the least number of squares can compute it to auxiliary regression, where the observed regressors are augmented with cross-sectional averages of the dependent variable, individual-specific regressors, and state-dependent variables. This augmentation leads to a new set of estimators mentioned in Pesaran (2006), referred to as the common correlated effects (CCE) estimators, that can be computed by running smooth transition panel regressions augmented with cross-section averages of the dependent and independent variables. The CCE procedure applies to panels with single or multiple unobserved factors so long as the number of unobserved factors is fixed.
Let
be a panel exponential smooth transition autoregressive process de-trended by the logistic smooth transition trend of order 1 (PESTAR (1)) on the time domain
t = 1, 2, …, T for the cross-section units
i = 1, 2, …, N. Consider
generated by the following PESTAR (1) process:
where
is the delay parameter and
represents the speed of transition for all units, and
is a serially and cross-sectionally uncorrelated disturbance term with zero mean and variance
.
By considering the previous literature, Ucar and Omay [
31] set
for all
i and
, which gives the specific PESTAR (1) model:
A nonlinear panel data unit root based on regression (19) with augmented lag variables in empirical application is simply to test the null hypothesis for all i against for some i under the alternative.
However, directly testing the null is problematic since
is not identified under the null. This problem can be solved by taking first-order Taylor series expansion to the PESTAR (1) model around
for all
i. Hence, the obtained auxiliary regression is given by:
In empirical application, Equation (18) was augmented by lagged variables of a dependent variable by using Akaike information criteria (AIC) and Schwarz–Bayesian information criteria (SBC). Now, if we include the factor structure into the nonlinear model with a single factor:
Notice here that
is the unobserved common factor,
are the factor loadings, and
s are idiosyncratic error terms assumed to be independently distributed across
i and
t. Note that
are de-trended series from Equations (8)–(10). Thus, following the article of Pesaran [
25], we obtain the below auxiliary regression for approximating the unobserved factors:
Now we can obtain the critical values by using this transformation to eliminate cross-section dependency for the statistic:
Table 10,
Table 11 and
Table 12 provide the critical values for different models since the true DGP is generated with cross sectionally dependent data.
In this paper, we also examine the UO test and hence apply the sieve bootstrap method to deal with the cross-section dependency problem. Note that are de-trended series from Equations (8)–(10); therefore, the deterministic term is also included in our computations.
The following OLS regression is considered for each entity, which allows for different lag orders
The null of no unit root is imposed to generate samples of residuals. Errors are estimated as below:
Stine (1987) offers that the residuals have to be centered with
where
and
. Moreover, we construct the
matrix from these residuals. We select the residuals column randomly with replacement at a time to preserve the cross-section structure of the errors. The bootstrap residuals are denoted as
, where
and
.
We first generate stationary bootstrap samples
recursively from
where the initial values of
are set to zero. We then generate
as the partial sum process
The bootstrap statistics
are computed for each bootstrap replication by running the regression equation
The empirical distribution of these statistics is produced through 2000 replications. Thus, their p-values are generated using this methodology.
5. Empirical Application
In this study, we selected European and worldwide countries to represent the categories of developed and developing countries. The 34 countries selected are as follows: Argentina, Australia, Austria, Belgium, Brazil, Canada, Colombia, Denmark, France, Germany, Greece, Hungary, Iceland, India, Ireland, Italy, Japan, Malaysia, Mexico, Netherlands, New Zealand, Poland, Portugal, Romania, Russia, Saudi Arabia, South Korea, Slovakia, Spain, Sweden, Switzerland, Thailand, Turkey, and the UK, covering the period 2010:7–2020:3 for the short T panel and 1994:1–2020:3 for the long T panel. Our primary concern in this section is to assess the unit root features of the European and selected representative countries’ real exchange rate, thereby, the PPP hypothesis.
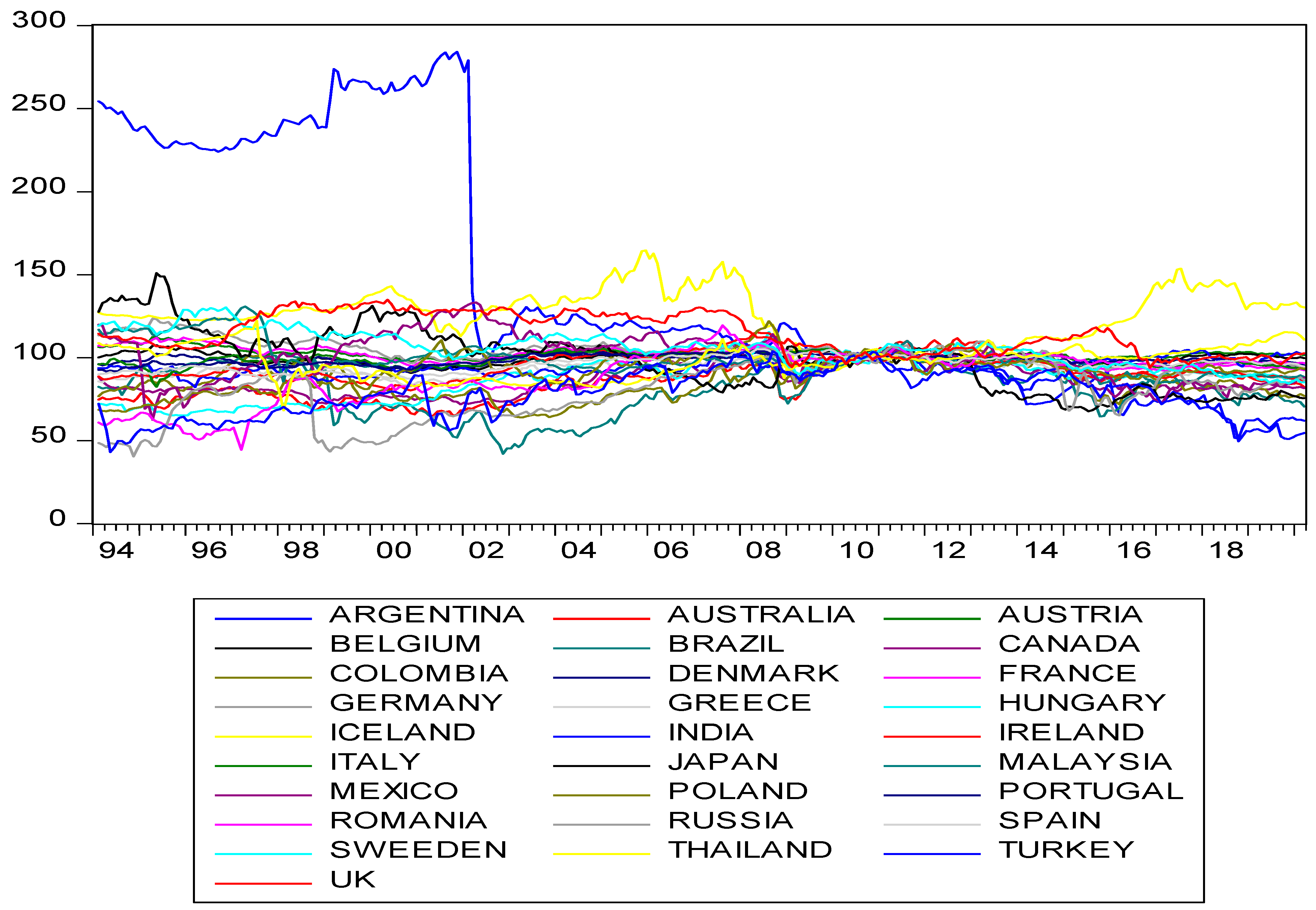
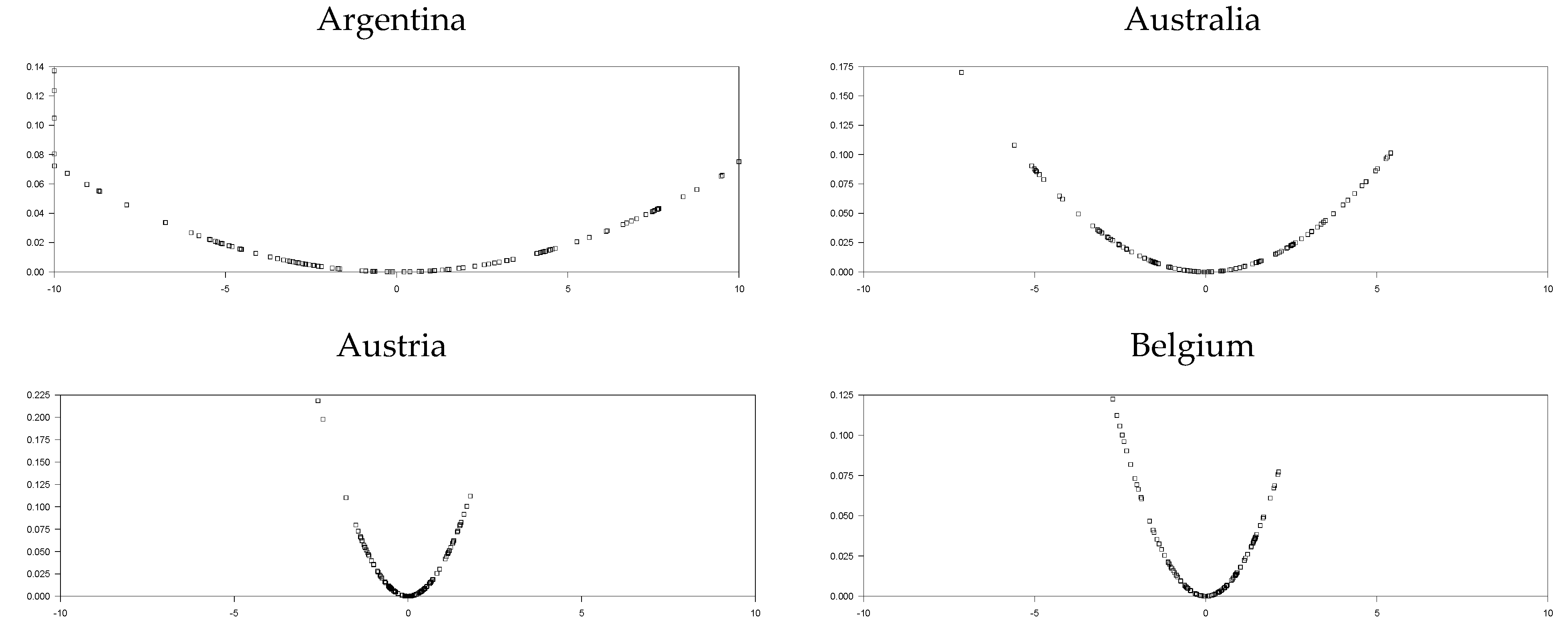
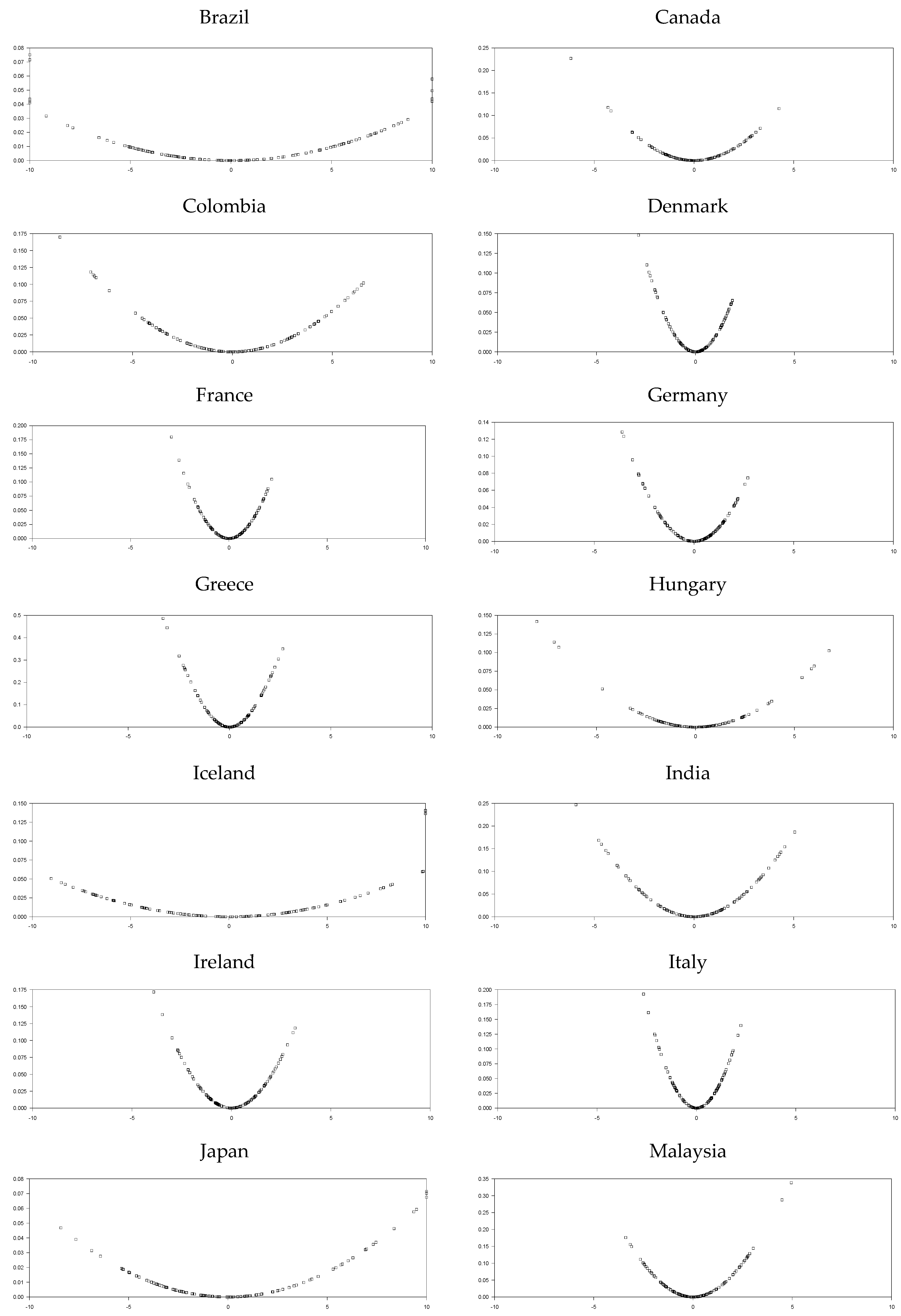
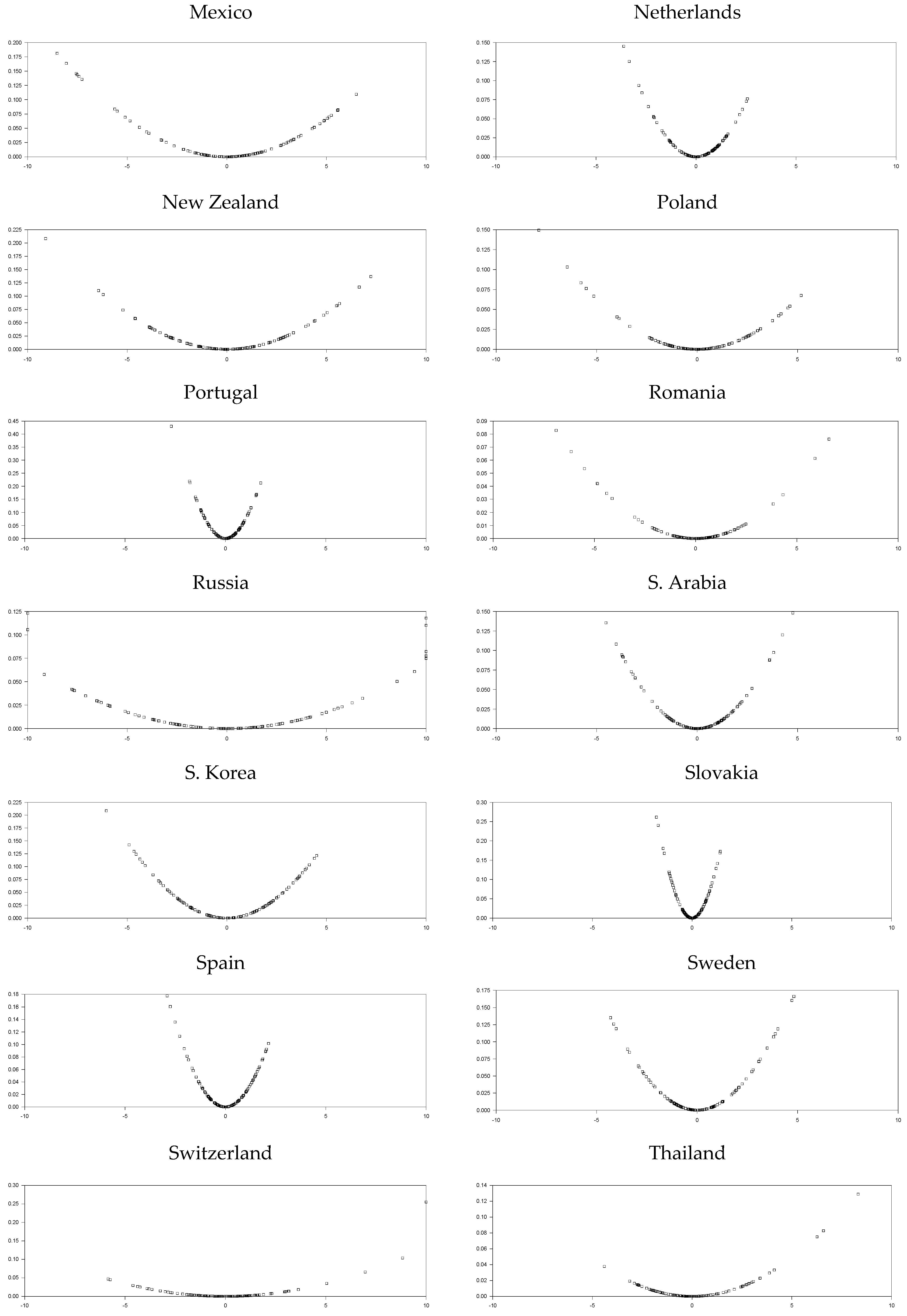
The base year is 2010, which is obviously depicted from
Figure 1. We used the sample period of 2010:7–2020:3 in order to remove the base year effect for the short T panel. In the empirical part of the study, we will use different types of panel unit root tests. In addition to the tests we employ in the power analysis section, other panel unit root tests already recommended in the literature will better reveal the REER series structure. In addition to the test we proposed in this study, we will make some comparisons using EO, UO, IPS, OHS, and OCE tests. The EO test does not use the CCE estimator for remedying cross-section dependency. In addition, as stated in Omay et al. [
33] (OHS), the CCE estimator catches structural breaks if there are homogeneous structural breaks. In short, it captures the structural break instead of correcting the cross-section dependency. The problem of incorrect decomposition in this estimator (CCE) will lead to difficulties in interpreting the results. Ultimately, a test without a structural break will work as a test with a structural break, giving us false information about the real exchange rate series under consideration. For these reasons, we will compare the results of tests using the sieve bootstrap method in the empirical part to control the cross-section dependency problem.
As can be seen from
Table 13, all tests accepted the PPP hypothesis except for the linear sieve bootstrap IPS test. However, it is not known from these results which countries cause significant stationarity. For this reason, it is necessary to understand which test captures the dynamics of the real exchange rate series more meaningfully and differentiates the countries as stationary and nonstationary. Abuaf and Jorion [
47], Frankel and Rose [
48], Oh [
49], Wu [
50], and Papell [
51], among others, used panel data to increase the number of observations and, thus, the power of the unit root tests. However, Taylor [
3] pointed out that conventional panel unit root tests do not provide explicit guidance on the identity of the stationary panel members. They argue that rejecting the null hypothesis of a unit root in panel data implies that at least one of the series is mean reverting but not that all the series under consideration are stationary. In addition, testing stationarity in panels may be complicated by cross-sectional correlation and possible cross-unit cointegration. It is now well established that ignoring cross-sectional correlation or cross-unit cointegration may lead to severe size and power distortions, invalidating inferences drawn from panel tests [
52]. In time-series unit root tests, which will be considered individually, common shocks or spillover effects can be seen as structural breaks or nonlinear data generation processes, since they do not control cross-section dependency. Therefore, time-series analysis poses a problem due to this cross-section dependency, which is not controlled by the real exchange rate dynamics.
To consider the cross-section dependency problem, we will continue the empirical part by combining the sequential panel selection method (SPSM) suggested by Chortareas and Kapetanios [
53] for our sieve bootstrap estimation. If the panel unit root test finds the full sample stationary, we can continue with SPSM. First, we applied the SPSM method to the tests without a break. Since the sieve bootstrap IPS test without a break in the test procedure did not have a stationary, the SPS method was abandoned, and it was concluded that it did not accept the PPP hypothesis. Fortunately, state-dependent tests were stationary in the full sample for only intercept, intercept, and trend cases. For the validity of the PPP hypothesis, the intercept-only case is consistent with the theory; hence, we continue SPSM with the intercept-only case. As seen from the UO test, only the test, including the intercept, gave more significant results than the intercept and trend case. Selecting a more significant test value for the SPS methodology will increase the number of stationary countries obtained. However, we considered it appropriate to include the SPS methodology to test structures following economic theory rather than statistical significance. Therefore, while the intercept and trend form of the EO test is more significant than the intercept-only case, we performed SPSM by considering the case with intercept-only, as we explained above.
For the short T panel, the UO test with symmetrical state-dependent size nonlinearity ESTAR (1) matched with more country data than the EO test, including asymmetric state-dependent size nonlinearity AESTAR (1), and the validity of the PPP hypothesis was accepted for 5 countries with the EO test and for 12 countries with the UO test. By applying the SPS methodology, we saw how many countries in the ESTAR (1)-type state-dependent size nonlinearity panel sample are compatible with this functional structure. This good fit, provided in 12 of 34 countries, corresponds to approximately 35% of the entire sample. Distributions of empirical test results are given in the bottom row of each test in
Table 14. Among these distributions, the nonlinearity of the ESTAR (1) structure explains the real exchange rate dynamics better than the nonlinearity of the AESTAR (1) type, which shows itself with the UO test results being closer to the normal distribution, while the EO test results are skewed to the left.
In
Section 3, where we detailed the small sample characteristics, we explained why tests with structural breaks should be used, and the quasi-PPP and PPP hypotheses were met in the case of permanent and temporary breaks. The PPP hypothesis is valid under the fixed mean condition depending on the theoretical findings. It is well known that the quasi-PPP hypothesis may emerge if the sample data faced crises or other economic phenomena, such as rapid technology change, leading to a structural break in the real exchange rate variable.
This structural break change leads to permanent long-run mean change as well. Finally, it is also discussed in Sollis’s [
14] study that a temporary break structure due to appreciation and depreciation of the real exchange rate that returns to the same fixed long-run means can provide the original PPP hypothesis. In this study, we tried to evaluate the results by model C of the logistic smooth transition trend that best captures temporary and permanent breaks. The model C structure, by its nature, can model the permanent break, while it can also model temporary break behaviors. Therefore, the model C structure will better compare the obtained results, such as original PPP, quasi-PPP (permanent break), or quasi-PPP (temporary break), which can be classified as original PPP. Therefore, the SPS method employed model C of the panel unit root test, including the structural break in their testing procedure. In
Table 15, SPSM results of the tests based on model C, including the structural break, are given as mentioned above. The full sample results show that the PLSTTESTAR and PLSTTTAR models are significant at 1%, and the PLSTT unit root test is significant at the 5% level. However, when the SPS methodology is applied, the number of stationary and nonstationary countries shows that the PLSTTESTAR test fits the data much better than the other two tests.
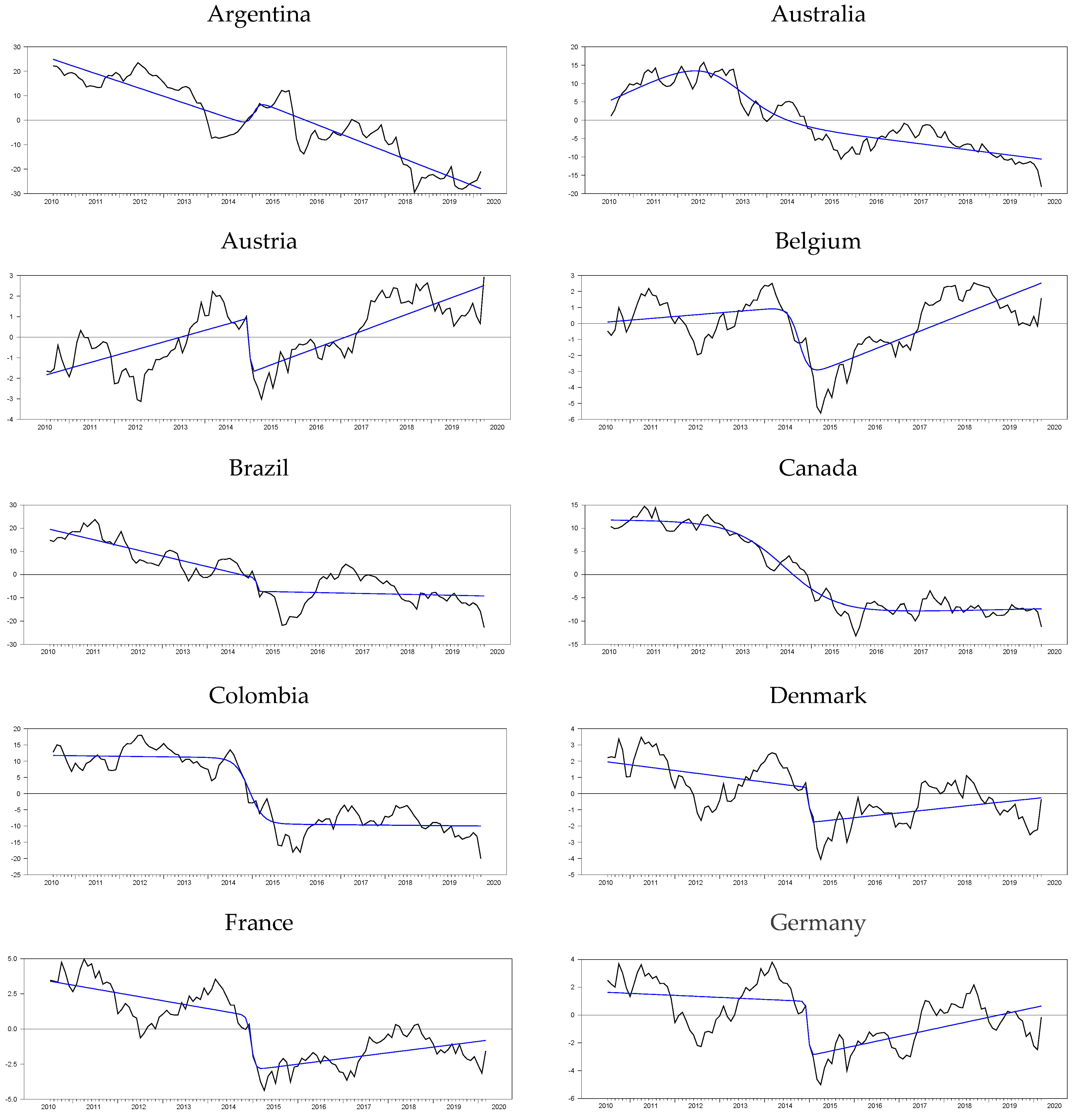
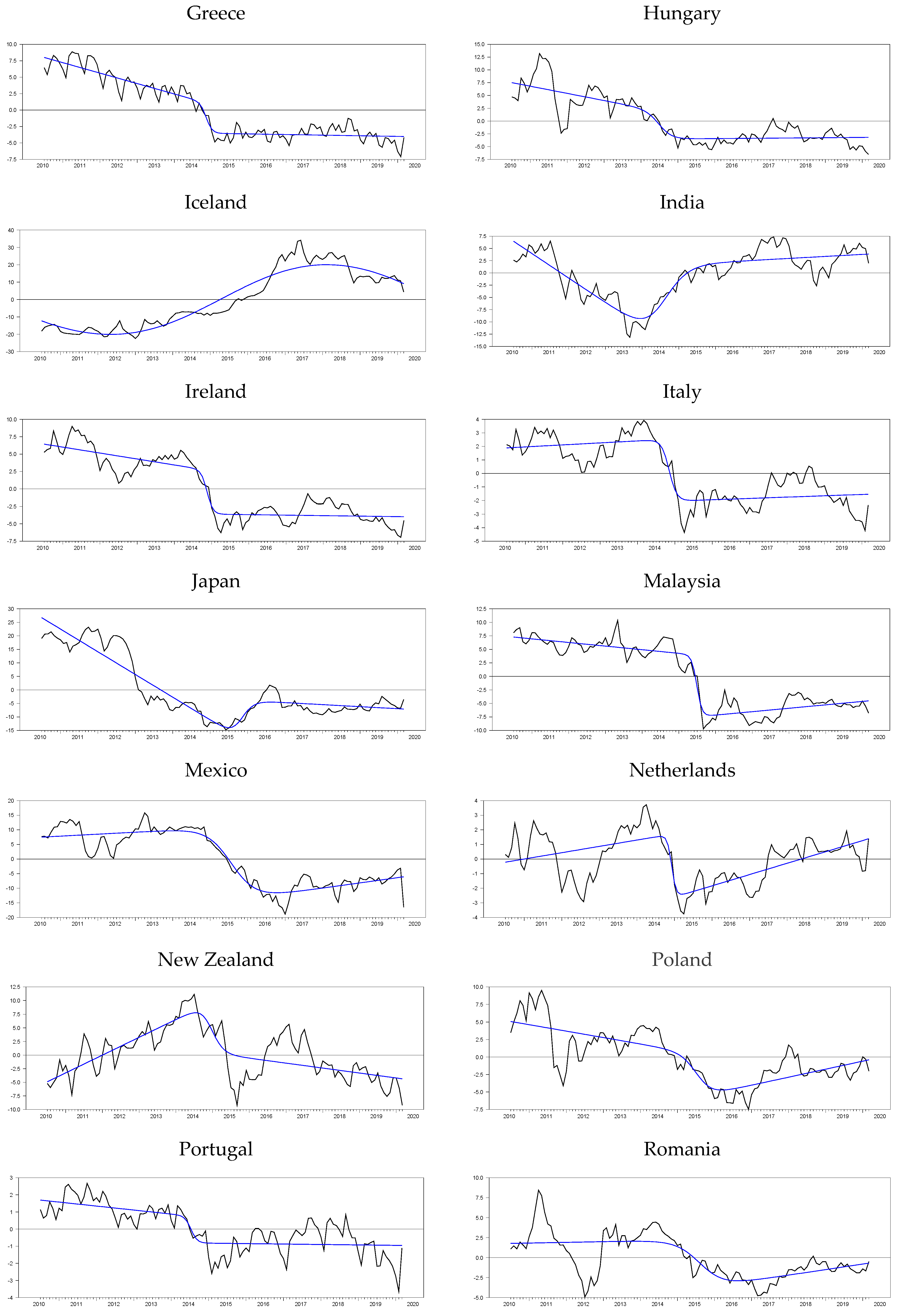
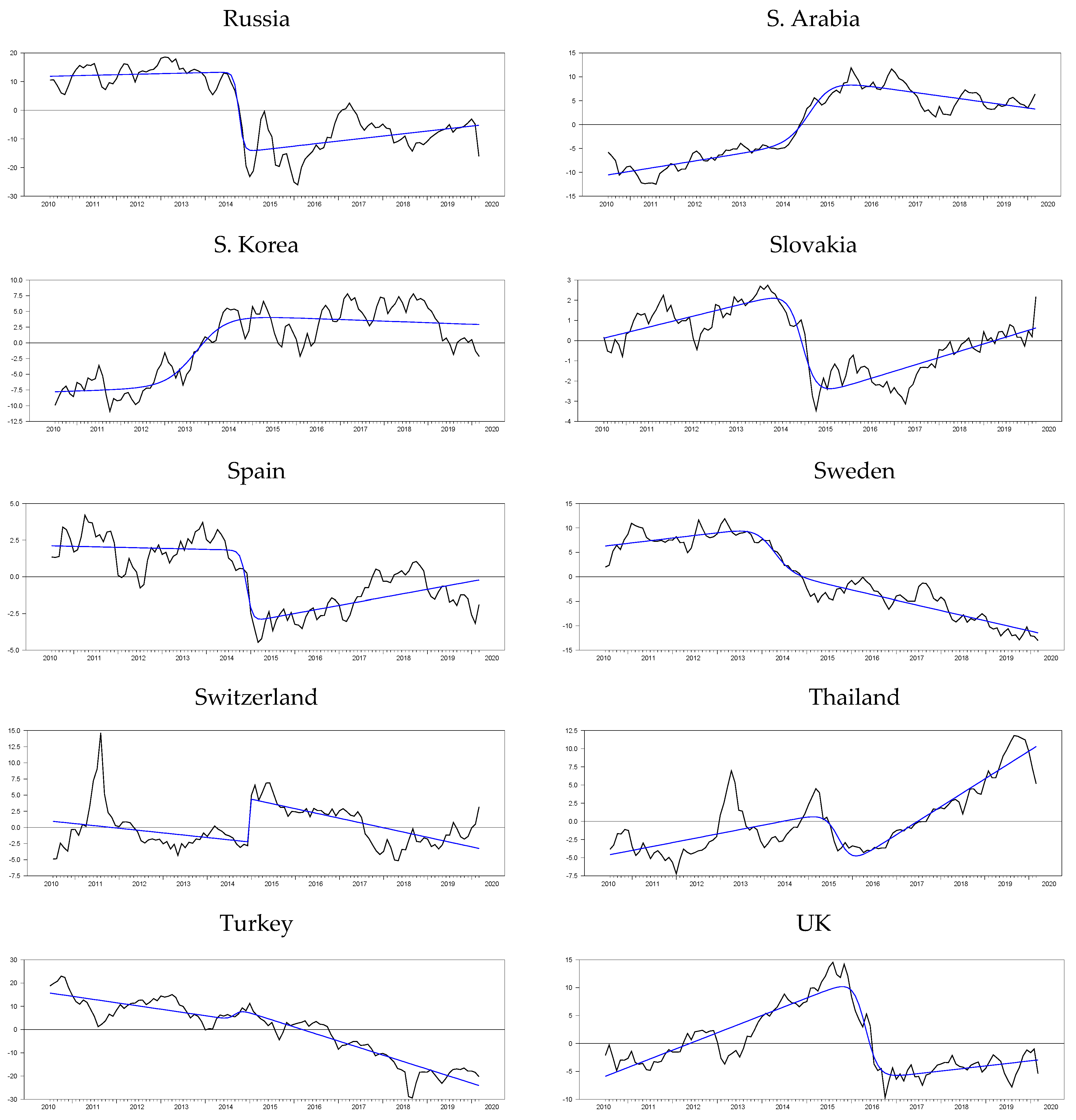
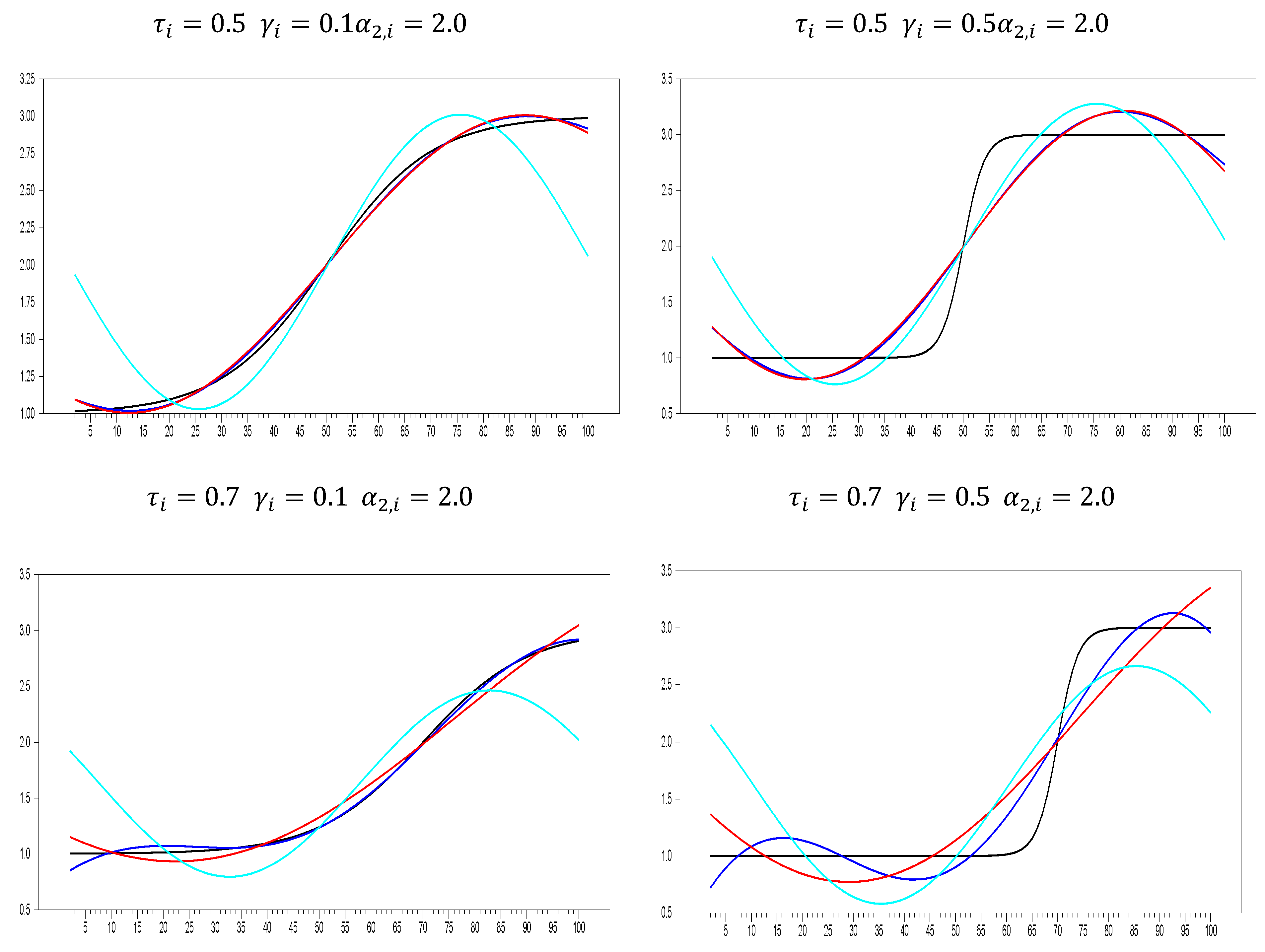
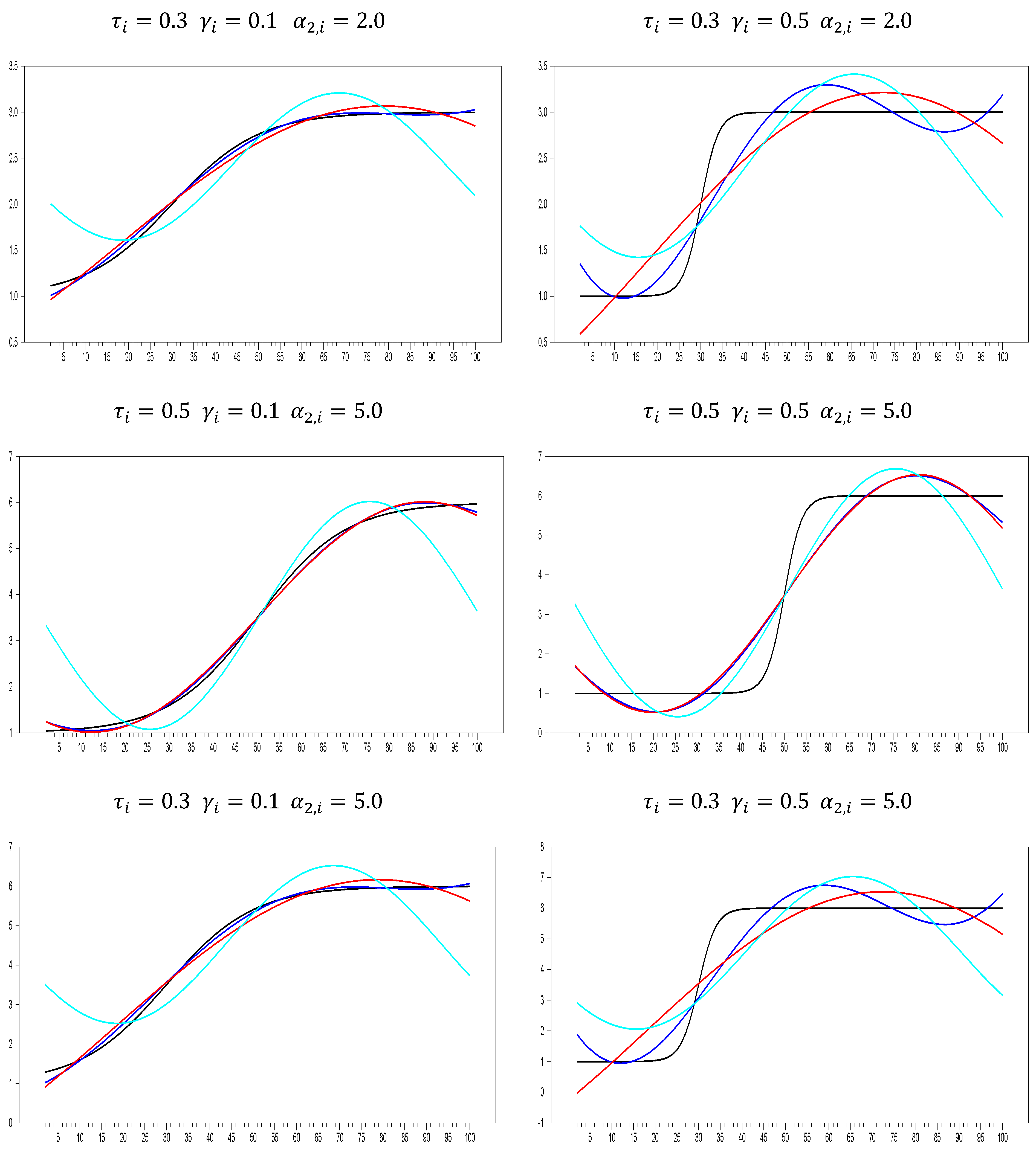
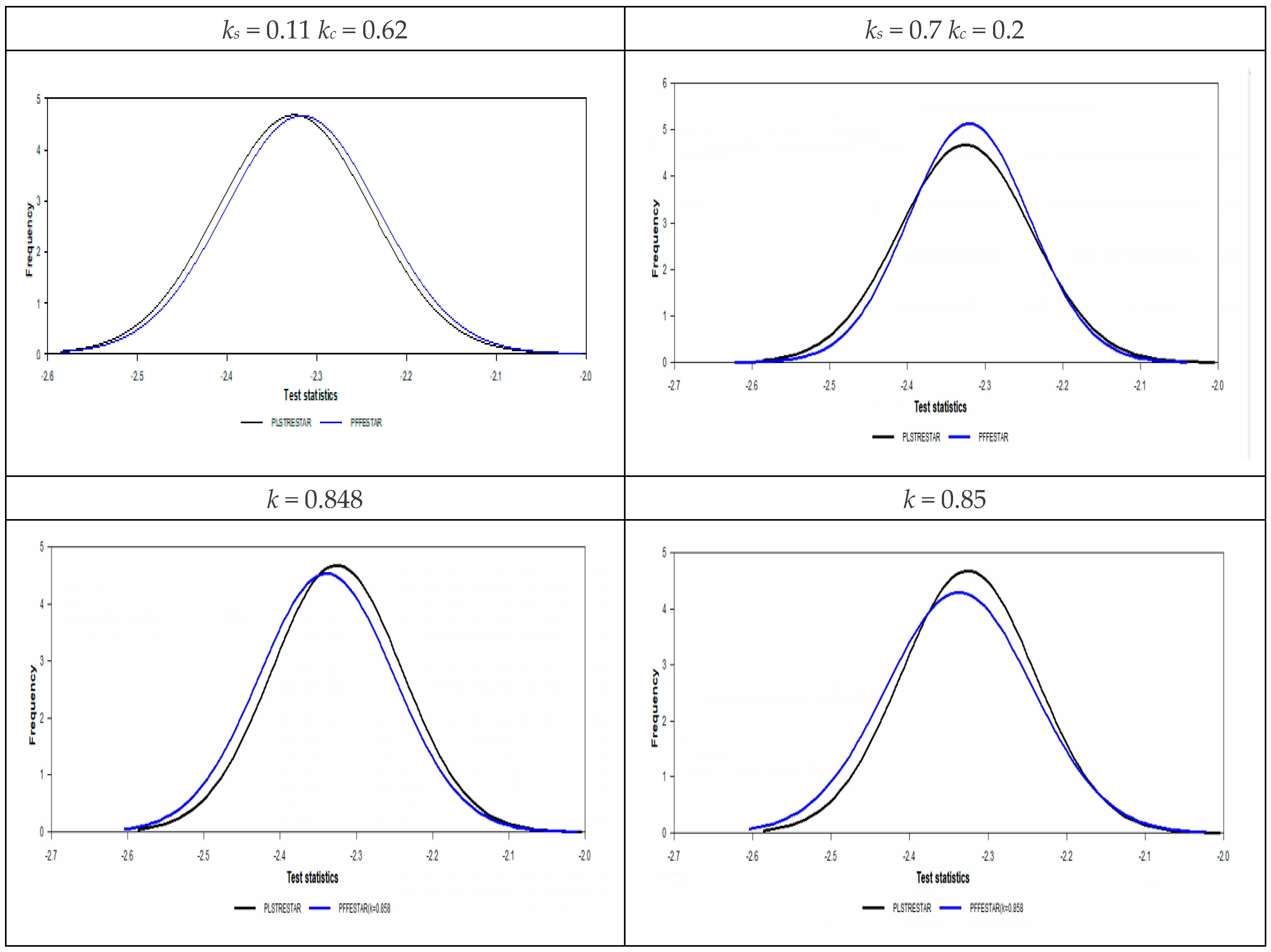
Although it is also seen that the logistic smooth transition model C structure better captures the features of the real exchange rate data as represented graphically in
Figure 2, this good fit is not general enough to cover all countries. In addition, it is seen that TAR-type nonlinearity is very insufficient to explain the real exchange rate dynamics compared with ESTAR (1) nonlinearity. While the PLSTTESTAR test found 23 stationary countries, five-country stationary is found in the PLSTTTAR unit root test. These countries are almost identical to those in the PLSTT test (Greece, Canada, Sweden, and the UK). Here, TAR nonlinearity had a significant effect only on Iceland, and while it was the worst significant in the PLSTT test, it ranked the second-best significant test result in the PLSTTTAR test. Therefore, it is seen that the TAR structure is only a good fit for the Icelandic real exchange rate data. If we compare the SPSM results of the UO and EO tests with the PLSTTESTAR test, the situation does not change much; it is understood that the model or functional structures that provide the best compatibility with the real exchange rate series are in the PLSTTESTAR unit root test. PLSTTESTAR explains about 67% of the full sample, while its closest follower, the UO test, explains 35%. In order to better interpret these results, it is useful to make nonlinear parameter estimations of the sample at hand. If we show its consistency with the results in the section where we discussed the power analysis, it will be evident that the unit root test we propose fits better with the real exchange rate dynamics than the current linear or nonlinear panel unit root tests. For this purpose, the break parameters obtained from the structural break tests will be evaluated according to the results we obtained in the power analysis. Later, whether the PLSTTESTAR test in power analysis is close to the estimated parameters in the high-power regions will be discussed. Depending on the two-stage test procedure, in the second stage, after removing the nonlinear trend, how well the real exchange series fit the ESTAR (1)-type structure will be investigated by making nonlinear parameter estimations.
In the power analysis section, we saw that different parameters of the logistic smooth transition trend increase the power of the proposed test. A break size of 5 units is used for the moderate break and 10 for the higher break in the power analysis. When we look at the country-by-country estimates here, the value of the break parameter is very high in almost all countries as shown in
Table 16.
The average of 34 countries for the break parameter was 23.983. The result obtained in
Table 16 signifies to a high break parameter vlue. With this break parameter, it is evident that the tests without a structural break, especially the IPS test, have very little power against this data structure. As a matter of fact, as a result of the test, the bootstrap IPS test could not provide stationarity either in the intercept or in the intercept and trend models. The second parameter we will examine is the transition rate parameter. As the transition speed parameter decreases, the power of the tests with logistic smooth transition increases. The first thing to note here is that the larger the break parameter, the higher the value of the gamma parameter, which adjusts the smoothness of this transition speed. For break magnitude values of 5 and 10, 5 transition slopes correspond to a relatively high transition speed, while in the case of a higher break size such as 24, 5 transition slopes correspond to a relatively low value. In this sense, 2.259 average transition speeds indicate a smooth transition according to the size of the break.
For this reason, the power of the PLSTTESTAR test and the other tests, including logistic smooth transition, is increasing. Finally, we observed that the threshold value being relatively in the middle of the sample increases the power of the tests containing the logistic smooth transition trend. Therefore, we see that almost all countries experience a break around 0.5, that is, at the midpoint of the sample. As for the threshold location, the country with the break structure at the beginning of the sample is Australia, at 0.280 points of the sample, while the latest break day belongs to UK data with 0.604. The average of the 34 countries was found to be 0.465. The break size is 23.983, the transition rate is 2.259, and the threshold value is 0.465. According to these results, the power of the tests, including logistic smooth transition, will be high. If we look at the empirical test results, the tests, including logistic smooth transition, have rejected the null hypothesis more significantly than any other test structure. The most significant of these tests is the model C structure, in which they reject the null hypothesis. PLSTT, PLSTTAR, and PLSTESTAR tests rejected the null hypothesis at 0.021, 0.000, and 0.000 significance levels. Likewise, while the state-dependent unit root tests UO and EO rejected the null hypothesis at 0.047 and 0.063 significance levels, the IPS test could not reject the PPP hypothesis with 0.299. These results show us that logistic smooth transition alone can capture the dynamics of the PPP hypothesis or real exchange data. In addition, when we compare the tests that include structural breaks with those that do not, it is understood that the tests containing breaks yield results in line with the above-mentioned power analysis and reject the null hypothesis at a higher significance level. The EO and UO tests are asymmetrical and symmetrical versions of the ESTAR (1) structure. When the test results are examined, it is seen that the EO test can reject the null hypothesis at a 0.063 significance level, while the UO test provides a better fit with the data with a 0.047 significance level. The explanation for this situation shows that the behavior of the real exchange rate variable is more suitable for the symmetrical ESTAR (1) structure and the power of the EO test is lower than the UO test, which has the ESTAR (1) structure in the symmetrical structure since unnecessary parameter estimation is made. The rejection of the null hypothesis by the UO test indicates that some countries in the panel sample can be modeled with the ESTAR (1) structure, and thus, the PPP hypothesis can be confirmed for these countries.
The fact that six countries are stationary in the PLSTTTAR model C with SPS methodology shows that nonlinearity in TAR type does not comply with exchange rate dynamics. In addition, the UO test, which includes the ESTAR (1) model, showed that 12 countries have stationary in SPSM analysis and better adapt to exchange rate dynamics. For this reason, it is useful to investigate how much ESTAR (1)-type nonlinear structure remains in the remaining part after the logistic smooth transition de-trend series is estimated. Accordingly, estimations were performed as suggested in the article [
19] and discussed in the power analysis of the ESTAR (1) structure. The results obtained in
Table 17 support the power analysis.
The transition rate parameter
estimate average is 0.01 for 34 countries. This situation corresponds to the area of high power of the proposed test. In addition, the low transition speed rate in nonlinearity in the state-dependent structure increases the power of the tests with ESTAR (1) nonlinearity. The graphs of the ESTAR (1) estimations given in
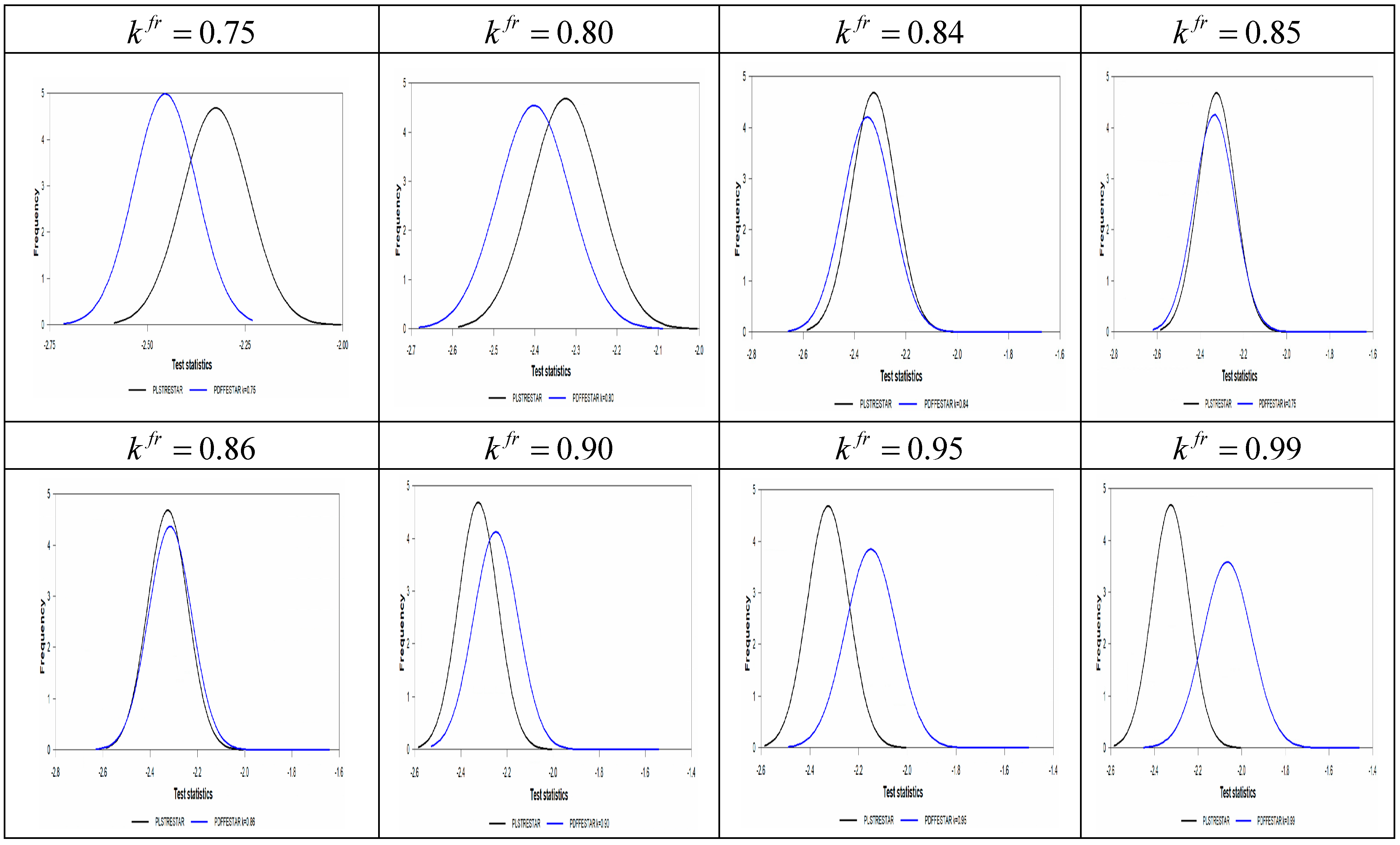
Figure 3 strikingly demonstrate this low transition speed (slope) rate. As discussed in Kapetanios et al. [
19], it has been shown that for low transition speed rates, the power is low for Enders and Granger [
54] (EG) tests, which deal with TAR-type nonlinearity, and the ADF test, which has a linear structure. In the analysis here, the linear ADF test corresponds to the PLSTT test, while the EG test corresponds to the PLSTTAR test. In line with the nonlinear model estimates obtained in
Table 16 and
Table 17, it can be easily understood that both the PLSTT test and the PLSTTAR test face data with a low power structure, with their testing procedure including linear and TAR-type nonlinearity for the stochastic process. SPSM test results also confirm this result.
With the sequential panel selection method (SPSM), although the null hypothesis was rejected at the border, the number of countries rejecting this hypothesis can be determined. Thus, it can be concluded that other methodologies should be proposed to enable more realistic testing of the PPP hypothesis. How many countries contributed to rejecting the null hypothesis in a panel data sample that concludes that the model under consideration increases the power of explaining economic events that much? In this sense, whether or not the newly proposed test has undertaken this task, it has tried to examine it using SPSM methodology. It is evident from the test results (
Table 13,
Table 14,
Table 15,
Table 16 and
Table 17) that the functional structures of both the logistics smooth transition trend and the exponential smooth transition type play an active role in the real exchange rate dynamics. However, more importantly, the PLSTTESTAR test, which includes both functional structures at a significance level of less than 1%, leads to the acceptance of the PPP hypothesis that supports the proposed test. We cannot see the same success from its closest competitor, the PLSTTTAR model. When the SPSM comparison of these two tests is made, it is understood that the PLSTTTAR test is high due to the individual test results obtained in Greece, Iceland, and Canada, which are 27,084, 15,699, and 14,776, respectively.
On the other hand, when we return back to the
Table 16, it is indeed serving empiriacal distribution which is a left-skewed so that many test values are small. The last two rows of
Table 16 show the distribution of empirical test results for PLSTTESTAR and PLST tests. Since these two tests are t-tests, higher test values are seen as values that go to the left of the distribution. PLST empirical test results are also relatively right-skewed and have extreme values. The empirical test value distribution of the PLSTTESTAR test is nearly normally distributed and has no extreme value. This empirical test value distribution shows that the PLSTTESTAR test homogeneously obtains empirical test value results close to high values, thus conducive to the stationarity of many more countries in the SPSM methodology. The UO test is relatively high in all countries, with a balance similar to the empirical test result distribution in the PLSTTESTAR test, and provided the PPP hypothesis in 12 countries, while the PLSTT model provided the PPP hypothesis in only 6 countries. While the PLSTT and UO tests separately provided the PPP hypothesis in 6 and 12 countries, the PLSTTESTAR test, which was used together, provided the PPP hypothesis in 23 countries. This case shows us that the functional structures proposed in the PLSTTESTAR test in the short T panel better adapt to the real exchange rate dynamics. In order to better illustrate this situation, the ESTAR (1) model estimates and nonlinear parameter estimates of the PLSTT model are discussed in [
18]. In the section where we explained the small sample characteristics, we explained why tests with structural breaks should be used, and the quasi-PPP and PPP hypotheses were met in the case of permanent and temporary breaks. We mentioned this issue at the beginning of the empirical part.
In order to better understand this issue, we add a column named as“difference” in
Table 16. Estimates in this column are obtained by subtracting the start and endpoints of the nonlinear trends for the logistic smooth transition model C. As this difference value grows, it is understood that the nonlinear trend catches a permanent break, and as it becomes smaller, a temporary break occurs. Moreover, examples of the temporary break structure can be seen in
Figure 3. Belgium, India, Slovakia, and the UK are a good example of this temporary break situation. If we look at the logistics and smooth transition trends of these countries, they all have a temporary break structure in such a way that the starting and ending points are close to each other and form a U shape. To illustrate this better, we compute the differences of the logistic smooth transition start and endpoints from the last column of
Table 16, which are −2.436, 2.598, −0.503, and −2.921 for Belgium, India, Slovakia, and the UK, respectively. While these countries exhibit a temporary break structure, Canada and Colombia are good examples of the permanent break, with difference values of 28,733 and 19,088, respectively. Although countries such as Belgium, India, Slovakia, and the UK are stationary with the PLSTTESTAR (1) model, it can be concluded that the original PPP hypothesis is met within the temporary break structure proposed in the article. The results obtained based on these distinctions are summarized in
Table 18.
We repeated the short T panel analysis in the long T panel, provided as
Appendix A. The results for this period covering the years 1994:1–2020:3 are the same as those obtained for the short T panel. In the long term, the significance levels of all tests increased, and even in the linear model, the sieve-bootstrap IPS test resulted in the acceptance of the PPP hypothesis in 11 countries. If we look at the summary tables, PLSTTESTAR accepted the PPP hypothesis in 31 of 34 countries, while its closest follower, the UO test, remained in 25 countries. In terms of ranking, the status of the other tests remained the same as in the short panel T. The EO test results increased from 5 to 25 stationary countries, while the PLSTT test result went from 6 to 17 stationary countries, and the PLSTTTAR test results from 6 to 17 countries. Estimations for the nonlinear parameters of the logistic smooth transition gave results similar to those of the short T panel. The mean break size was found to be 15,152 for 34 countries, the mean of the transition speed parameter was 0.688, and the mean of the threshold was 0.443. This parameter combination belongs to a more powerful PLSTTESTAR test region; hence, the acceptance rate increased from 23 countries to 31 countries. All the comments we made in the short T panel are valid in the long T panel. The transition speed of the ESTAR (1) function is also almost the same as the 0.01 value we found for the short T panel. It is evident that the PLSTTESTAR test reflects the real exchange rate dynamics better than other tests. In the long T panel, the temporary break search is performed over the difference value. The results are indicated as quasi-PPP* in the
Table 18. The results obtained from the long T panel show that the unit root test in the PLSTTESTAR structure we recommend best captures the real exchange rate dynamics, regardless of whether they are short (local) or long term. Therefore, we have clearly shown that the quasi-PPP* hypothesis and the logistic smooth transition trend structure can be used in theoretical and empirical studies for the real exchange rate dynamics. In addition to the ESTAR (1) structure, this logistic smooth transition model C structure has been identified as a significant complementary functional structure for testing the validity of PPP hypothesis.



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
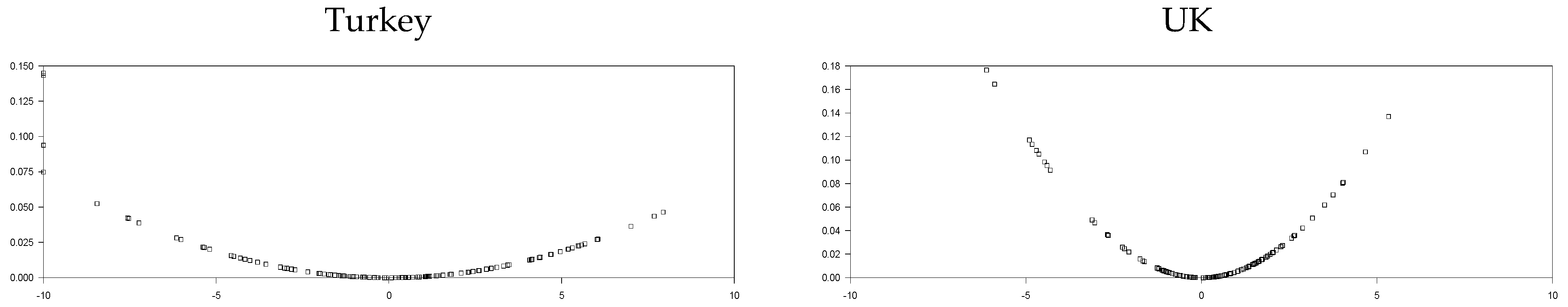{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}


















