
A Pre-Separation and All-Neural Beamformer Framework for Multi-Channel Speech Separation

Abstract
:1. Introduction
2. Problem Formulation
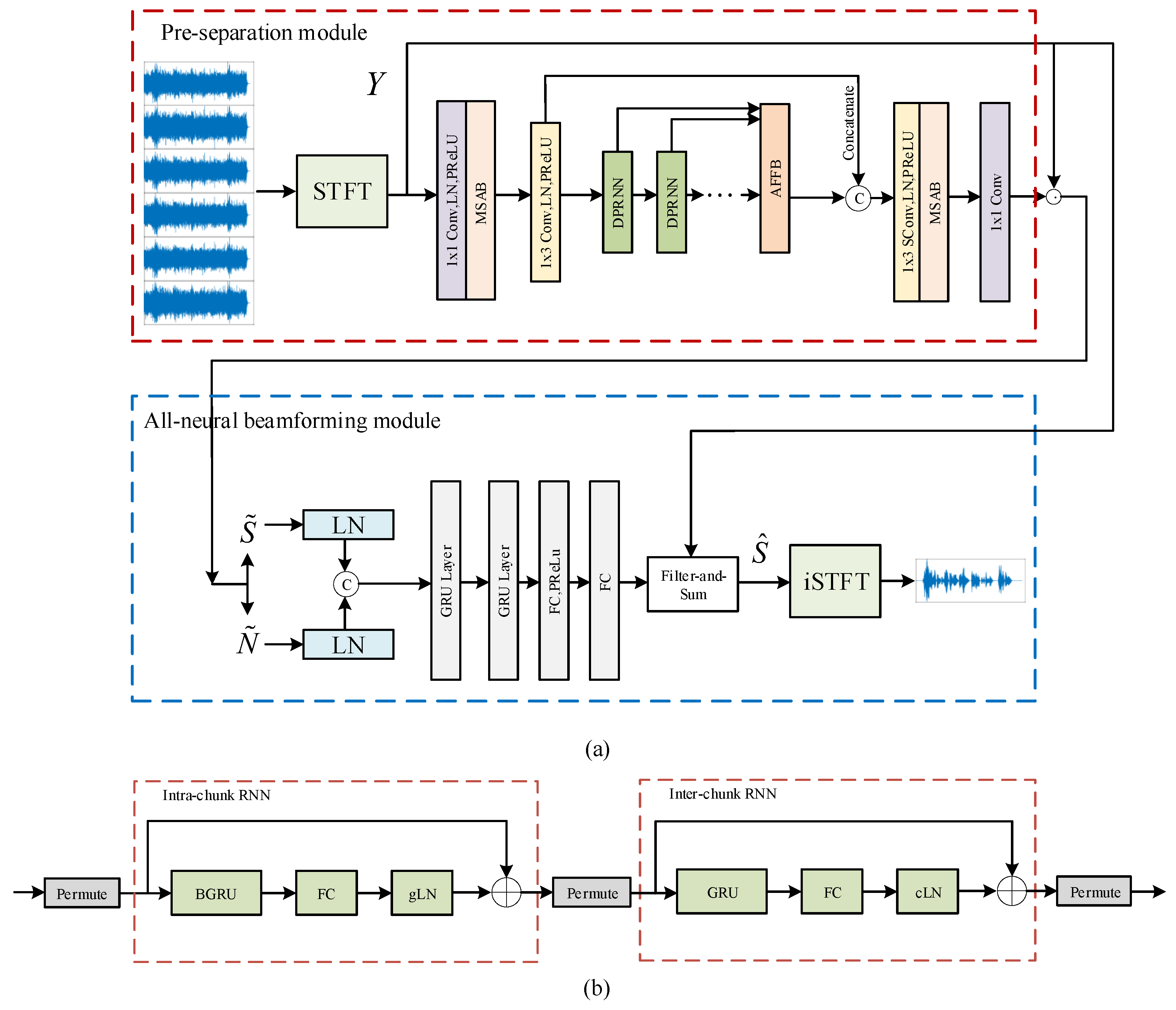
3. Model Description
3.1. Pre-Separation Module
3.2. All-Neural Beamforming Module
3.3. Loss Function
4. Experimental Setup
4.1. Datasets
4.2. Experimental Configurations
4.3. Baseline
5. Results
5.1. Ablation Study
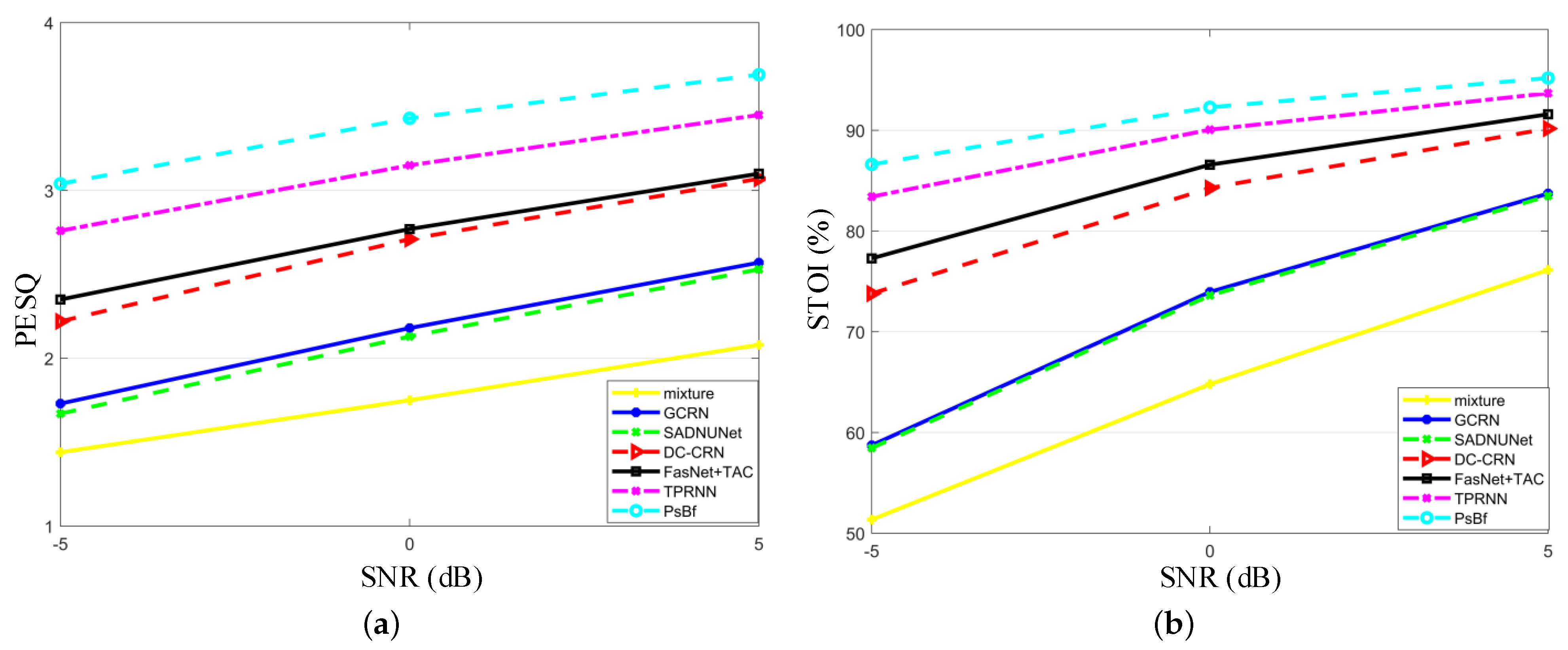
5.2. Speech Enhancement
5.3. Speaker Separation
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Luo, Y.; Mesgarani, N. Conv-TasNet: Surpassing Ideal Time–Frequency Magnitude Masking for Speech Separation. IEEE/ACM Trans. Audio Speech Lang. Process. 2019, 27, 1256–1266. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Xiang, X.; Zhang, X.; Chen, H. A Convolutional Network With Multi-Scale and Attention Mechanisms for End-to-End Single-Channel Speech Enhancement. IEEE Signal Process. Lett. 2021, 28, 1455–1459. [Google Scholar] [CrossRef]
- Pandey, A.; Xu, B.; Kumar, A.; Donley, J.; Calamia, P.; Wang, D. TPARN: Triple-path Attentive Recurrent Network for Time-domain Multichannel Speech Enhancement. In Proceedings of the ICASSP 2022—2022 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Singapore, 23–27 May 2022; pp. 6497–6501. [Google Scholar] [CrossRef]
- Wang, Y.; Narayanan, A.; Wang, D. On Training Targets for Supervised Speech Separation. IEEE/ACM Trans. Audio Speech Lang. Process. 2014, 22, 1849–1858. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Li, A.; Liu, W.; Zheng, C.; Fan, C.; Li, X. Two Heads are Better Than One: A Two-Stage Complex Spectral Mapping Approach for Monaural Speech Enhancement. IEEE/ACM Trans. Audio Speech Lang. Process. 2021, 29, 1829–1843. [Google Scholar] [CrossRef]
- Liu, Y.; Wang, D. Divide and Conquer: A Deep CASA Approach to Talker-Independent Monaural Speaker Separation. IEEE/ACM Trans. Audio Speech Lang. Process. 2019, 27, 2092–2102. [Google Scholar] [CrossRef] [Green Version]
- Liu, Y.; Wang, D. Causal Deep CASA for Monaural Talker-Independent Speaker Separation. IEEE/ACM Trans. Audio Speech Lang. Process. 2020, 28, 2109–2118. [Google Scholar] [CrossRef]
- Li, A.; Liu, W.; Zheng, C.; Li, X. Embedding and Beamforming: All-neural Causal Beamformer for Multichannel Speech Enhancement. In Proceedings of the ICASSP 2022—2022 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Singapore, 23–27 May 2022; pp. 6487–6491. [Google Scholar] [CrossRef]
- Affes, S.; Grenier, Y. A signal subspace tracking algorithm for microphone array processing of speech. IEEE Trans. Speech Audio Process. 1997, 5, 425–437. [Google Scholar] [CrossRef]
- Gannot, S.; Burshtein, D.; Weinstein, E. Signal enhancement using beamforming and nonstationarity with applications to speech. IEEE Trans. Signal Process. 2001, 49, 1614–1626. [Google Scholar] [CrossRef]
- Erdogan, H.; Hershey, J.; Watanabe, S.; Mandel, M.I.; Roux, J.L. Improved MVDR Beamforming Using Single-Channel Mask Prediction Networks. In Proceedings of the Interspeech 2016, San Francisco, CA, USA, 8–12 September 2016; pp. 1981–1985. [Google Scholar] [CrossRef] [Green Version]
- Xiao, X.; Zhao, S.; Jones, D.L.; Chng, E.S.; Li, H. On Time-Frequency Mask Estimation for MVDR Beamforming with Application in Robust Speech Recognition. In Proceedings of the 2017 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), New Orleans, LA, USA, 5–9 March 2017; pp. 3246–3250. [Google Scholar] [CrossRef]
- Qian, K.; Zhang, Y.; Chang, S.; Yang, X.; Florencio, D.; Hasegawa-Johnson, M. Deep Learning Based Speech Beamforming. In Proceedings of the 2018 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Calgary, AB, Canada, 15–20 April 2018; pp. 5389–5393. [Google Scholar] [CrossRef] [Green Version]
- Wang, Z.; Wang, P.; Wang, D. Complex Spectral Mapping for Single- and Multi-Channel Speech Enhancement and Robust ASR. IEEE/ACM Trans. Audio Speech Lang. Process. 2020, 28, 1778–1787. [Google Scholar] [CrossRef]
- Gu, R.; Zhang, S.; Chen, L.; Xu, Y.; Yu, M.; Su, D.; Zou, Y.; Yu, D. Enhancing End-to-End Multi-Channel Speech Separation Via Spatial Feature Learning. In Proceedings of the ICASSP 2020—2020 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Barcelona, Spain, 4–8 May 2020; pp. 7319–7323. [Google Scholar] [CrossRef] [Green Version]
- Wang, Z.; Wang, D. Combining Spectral and Spatial Features for Deep Learning Based Blind Speaker Separation. IEEE/ACM Trans. Audio Speech Lang. Process. 2019, 27, 457–468. [Google Scholar] [CrossRef]
- Zhang, J.; Zorilă, C.; Doddipatla, R.; Barker, J. On End-to-end Multi-channel Time Domain Speech Separation in Reverberant Environments. In Proceedings of the ICASSP 2020—2020 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Barcelona, Spain, 4–8 May 2020; pp. 6389–6393. [Google Scholar] [CrossRef]
- Tan, K.; Xu, Y.; Zhang, S.X.; Yu, M.; Yu, D. Audio-Visual Speech Separation and Dereverberation With a Two-Stage Multimodal Network. IEEE J. Sel. Top. Signal Process. 2020, 14, 542–553. [Google Scholar] [CrossRef] [Green Version]
- Wang, Z.; Wang, P.; Wang, D. Multi-microphone Complex Spectral Mapping for Utterance-wise and Continuous Speech Separation. IEEE/ACM Trans. Audio Speech Lang. Process. 2021, 29, 2001–2014. [Google Scholar] [CrossRef] [PubMed]
- Tan, K.; Zhang, X.; Wang, D. Deep Learning Based Real-Time Speech Enhancement for Dual-Microphone Mobile Phones. IEEE/ACM Trans. Audio Speech Lang. Process. 2021, 29, 1853–1863. [Google Scholar] [CrossRef] [PubMed]
- Tan, K.; Wang, Z.; Wang, D. Neural Spectrospatial Filtering. IEEE/ACM Trans. Audio Speech Lang. Process. 2022, 30, 605–621. [Google Scholar] [CrossRef]
- Zhang, Z.; Xu, Y.; Yu, M.; Zhang, S.X.; Chen, L.; Yu, D. ADL-MVDR: All Deep Learning MVDR Beamformer for Target Speech Separation. In Proceedings of the ICASSP 2021—2021 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Toronto, ON, Canada, 6–11 June 2021; pp. 6089–6093. [Google Scholar] [CrossRef]
- Xu, Y.; Zhang, Z.; Yu, M.; Zhang, S.X.; Yu, D. Generalized Spatio-Temporal RNN Beamformer for Target Speech Separation. In Proceedings of the Interspeech 2021, Brno, Czech Republic, 30 August–3 September 2021; pp. 3076–3080. [Google Scholar] [CrossRef]
- Luo, Y.; Han, C.; Mesgarani, N.; Ceolini, E.; Liu, S.C. FaSNet: Low-Latency Adaptive Beamforming for Multi-Microphone Audio Processing. In Proceedings of the 2019 IEEE Automatic Speech Recognition and Understanding Workshop (ASRU), Singapore, 14–18 December 2019; pp. 260–267. [Google Scholar] [CrossRef] [Green Version]
- Xiang, X.; Zhang, X.; Xie, W. Distributed Microphones Speech Separation by Learning Spatial Information With Recurrent Neural Network. IEEE Signal Process. Lett. 2022, 29, 1541–1545. [Google Scholar] [CrossRef]
- Ba, J.L.; Kiros, J.R.; Hinton, G.E. Layer normalization. arXiv 2016, arXiv:1607.06450. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Delving Deep into Rectifiers: Surpassing Human-Level Performance on ImageNet Classification. In Proceedings of the 2015 IEEE International Conference on Computer Vision (ICCV), Santiago, Chile, 7–13 December 2015; pp. 1026–1034. [Google Scholar] [CrossRef] [Green Version]
- Ballas, N.; Yao, L.; Pal, C.; Courville, A. Delving Deeper into Convolutional Networks for Learning Video Representations. arXiv 2015, arXiv:1511.06432. [Google Scholar]
- Pandey, A.; Wang, D. Dense CNN With Self-Attention for Time-Domain Speech Enhancement. IEEE/ACM Trans. Audio Speech Lang. Process. 2021, 29, 1270–1279. [Google Scholar] [CrossRef]
- Kolbæk, M.; Yu, D.; Tan, Z.H.; Jensen, J. Multitalker Speech Separation With Utterance-Level Permutation Invariant Training of Deep Recurrent Neural Networks. IEEE/ACM Trans. Audio Speech Lang. Process. 2017, 25, 1901–1913. [Google Scholar] [CrossRef] [Green Version]
- Panayotov, V.; Chen, G.; Povey, D.; Khudanpur, S. Librispeech: An ASR Corpus Based on Public Domain Audio Books. In Proceedings of the 2015 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), South Brisbane, QLD, Australia, 19–24 April 2015; pp. 5206–5210. [Google Scholar] [CrossRef]
- Reddy, C.K.A.; Gopal, V.; Cutler, R.; Beyrami, E.; CHENG, R.; Dubey, H.; Matusevych, S.; Aichner, R.; Aazami, A.; Braun, S.; et al. The INTERSPEECH 2020 Deep Noise Suppression Challenge: Datasets, Subjective Testing Framework, and Challenge Results. In Proceedings of the Interspeech 2020, Shanghai, China, 25–29 October 2020; pp. 2492–2496. [Google Scholar] [CrossRef]
- Varga, A.; Steeneken, H.J.M. Assessment for Automatic Speech Recognition: II. NOISEX-92: A Database and an Experiment to Study the Effect of Additive Noise on Speech Recognition Systems. Speech Commun. 1993, 12, 247–251. [Google Scholar] [CrossRef]
- Luo, Y.; Han, C.; Mesgarani, N. Group Communication With Context Codec for Lightweight Source Separation. IEEE/ACM Trans. Audio Speech Lang. Process. 2021, 29, 1752–1761. [Google Scholar] [CrossRef]
- Kingma, D.P.; Ba, J.L. Adam: A method for Stochastic Optimization. In Proceedings of the 3rd International Conference on Learning Representations (ICLR 2015), San Diego, CA, USA, 7–9 May 2015. [Google Scholar]
- Tan, K.; Wang, D. Learning Complex Spectral Mapping With Gated Convolutional Recurrent Networks for Monaural Speech Enhancement. IEEE/ACM Trans. Audio Speech Lang. Process. 2020, 28, 380–390. [Google Scholar] [CrossRef] [PubMed]
- Xiang, X.; Zhang, X.; Chen, H. A Nested U-Net With Self-Attention and Dense Connectivity for Monaural Speech Enhancement. IEEE Signal Process. Lett. 2022, 29, 105–109. [Google Scholar] [CrossRef]
- Luo, Y.; Chen, Z.; Mesgarani, N.; Yoshioka, T. End-to-end Microphone Permutation and Number Invariant Multi-channel Speech Separation. In Proceedings of the ICASSP 2020—2020 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Barcelona, Spain, 4–8 May 2020; pp. 6394–6398. [Google Scholar] [CrossRef] [Green Version]
- Wang, Z.; Wang, D. Multi-Microphone Complex Spectral Mapping for Speech Dereverberation. In Proceedings of the ICASSP 2020—2020 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Barcelona, Spain, 4–8 May 2020; pp. 486–490. [Google Scholar] [CrossRef] [Green Version]
- Luo, Y. A Time-domain Generalized Wiener Filter for Multi-channel Speech Separation. arXiv 2021, arXiv:2112.03533. [Google Scholar]
- Lee, D.; Kim, S.; Choi, J.W. Inter-channel Conv-TasNet for Multichannel Speech Enhancement. arXiv 2021, arXiv:2111.04312. [Google Scholar]
- Rix, A.W.; Beerends, J.G.; Hollier, M.P.; Hekstra, A.P. Perceptual Evaluation of Speech Quality (PESQ)-A New Method for Speech Quality Assessment of Telephone Networks and Codecs. In Proceedings of the 2001 IEEE International Conference on Acoustics, Speech, and Signal Processing, Salt Lake City, UT, USA, 7–11 May 2001; pp. 749–752. [Google Scholar] [CrossRef]
- Taal, C.H.; Hendriks, R.C.; Heusdens, R.; Jensen, J. An Algorithm for Intelligibility Prediction of Time–Frequency Weighted Noisy Speech. IEEE Trans. Audio Speech Lang. Process. 2011, 19, 2125–2136. [Google Scholar] [CrossRef]




{kind=link}
{kind=link}
{kind=link}
| Variant | Causal | MO | BF | X | Par.(M) | PESQ ↑ | STOI ↑ | SI-SNR ↑ |
|---|---|---|---|---|---|---|---|---|
| Variant-1 | ✓ | ✗ | ✗ | 64 | 1.08 | 1.22 | 25.98 | 9.17 |
| Variant-2 | ✓ | ✗ | ✗ | 128 | 1.73 | 1.36 | 28.54 | 9.60 |
| Variant-3 | ✓ | ✓ | ✗ | 128 | 1.73 | 1.51 | 31.28 | 11.90 |
| Variant-4 | ✓ | ✓ | ✓ | 128 | 1.91 | 1.53 | 31.54 | 12.49 |
| Variant-5 | ✗ | ✓ | ✓ | 128 | 2.45 | 1.80 | 35.04 | 14.24 |
| Metrics | Cau. | Par.(M) | STOI (%) | PESQ | ||||||
|---|---|---|---|---|---|---|---|---|---|---|
| Test SNR | - | - | −5 dB | 0 dB | 5 dB | Avg. | −5 dB | 0 dB | 5 dB | Avg. |
| Mixture | - | - | 48.40 | 55.12 | 60.51 | 54.68 | 1.40 | 1.57 | 1.74 | 1.57 |
| GCRN | ✓ | 9.77 | 59.48 | 65.77 | 69.93 | 65.06 | 1.80 | 2.10 | 2.30 | 2.07 |
| SADNUNet | ✓ | 2.63 | 59.61 | 65.66 | 69.81 | 65.03 | 1.82 | 2.04 | 2.24 | 2.03 |
| DC-CRN | ✓ | 12.97 | 70.07 | 74.66 | 77.27 | 74.00 | 2.16 | 2.39 | 2.58 | 2.38 |
| FasNet+TAC | ✓ | 2.76 | 69.45 | 73.86 | 76.67 | 73.33 | 2.09 | 2.25 | 2.39 | 2.24 |
| TPRNN | ✗ | 2.28 | 81.18 | 83.82 | 85.52 | 83.51 | 2.76 | 2.93 | 3.07 | 2.92 |
| PsBf | ✓ | 1.91 | 84.33 | 86.68 | 88.13 | 86.38 | 2.95 | 3.11 | 3.24 | 3.10 |
| Metrics | Par. (M) | Speaker Angle | Overlap Ratio | Avg. | ||||||
|---|---|---|---|---|---|---|---|---|---|---|
| <15° | 15–45° | 45–90° | >90° | <25% | 25–50% | 50–75% | >75% | |||
| TasNet-filter | 2.9 | 8.03 | 8.35 | 8.71 | 8.94 | 13.2 | 9.6 | 6.85 | 4.39 | 8.51 |
| FasNet+TAC | 2.9 | 8.63 | 10.65 | 12.21 | 13.04 | 15.2 | 12.0 | 9.65 | 7.59 | 11.11 |
| DCRN | 18.67 | 9.23 | 9.61 | 9.84 | 10.13 | 14.34 | 10.74 | 7.80 | 5.76 | 9.66 |
| MC-ConvTasNet | 5.09 | 8.47 | 8.89 | 9.31 | 10.06 | 13.03 | 9.90 | 7.76 | 6.02 | 9.18 |
| TD-GWF-TasNet | 2.6 | 10.70 | 11.90 | 12.90 | 13.60 | 16.30 | 13.30 | 11.00 | 8.50 | 12.30 |
| IC-ConvTasNet | 1.74 | 10.27 | 11.68 | 12.45 | 12.54 | 16.44 | 13.19 | 10.67 | 6.65 | 11.74 |
| TPRNN | 2.28 | 11.16 | 13.24 | 14.40 | 15.16 | 17.32 | 14.27 | 12.08 | 10.24 | 13.48 |
| PsBf | 2.27 | 13.83 | 14.51 | 14.63 | 15.30 | 18.52 | 15.55 | 13.46 | 10.74 | 14.57 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Xie, W.; Xiang, X.; Zhang, X.; Liu, G. A Pre-Separation and All-Neural Beamformer Framework for Multi-Channel Speech Separation. Symmetry 2023, 15, 261. https://doi.org/10.3390/sym15020261
Xie W, Xiang X, Zhang X, Liu G. A Pre-Separation and All-Neural Beamformer Framework for Multi-Channel Speech Separation. Symmetry. 2023; 15(2):261. https://doi.org/10.3390/sym15020261
Chicago/Turabian StyleXie, Wupeng, Xiaoxiao Xiang, Xiaojuan Zhang, and Guanghong Liu. 2023. "A Pre-Separation and All-Neural Beamformer Framework for Multi-Channel Speech Separation" Symmetry 15, no. 2: 261. https://doi.org/10.3390/sym15020261